
그래프 탐색
그래프는 여러 개의 점(정점)들이 선(간선)으로 연결된 구조예요. 예를 들어, 여러 도시가 길로 연결된 지도를 떠올려보면 돼요. 각각의 도시는 정점이 되고, 도시를 연결하는 길은 간선이 돼요. 이 그래프에서는 각 도시마다 연결된 길이 몇 개인지, 길이 어느 방향으로 가는지, 길을 지날 때 드는 비용 등을 고려할 수 있어요.
이번에는 방향과 비용을 잠시 빼고, 모든 정점(도시)들을 어떻게 탐색(방문)할 수 있는지 알아볼게요.
- 깊이 우선 탐색(DFS, Depth-First Search)
- 너비 우선 탐색(BFS, Breadth-First Search)
1. 깊이 우선 탐색(DFS, Depth-First Search)
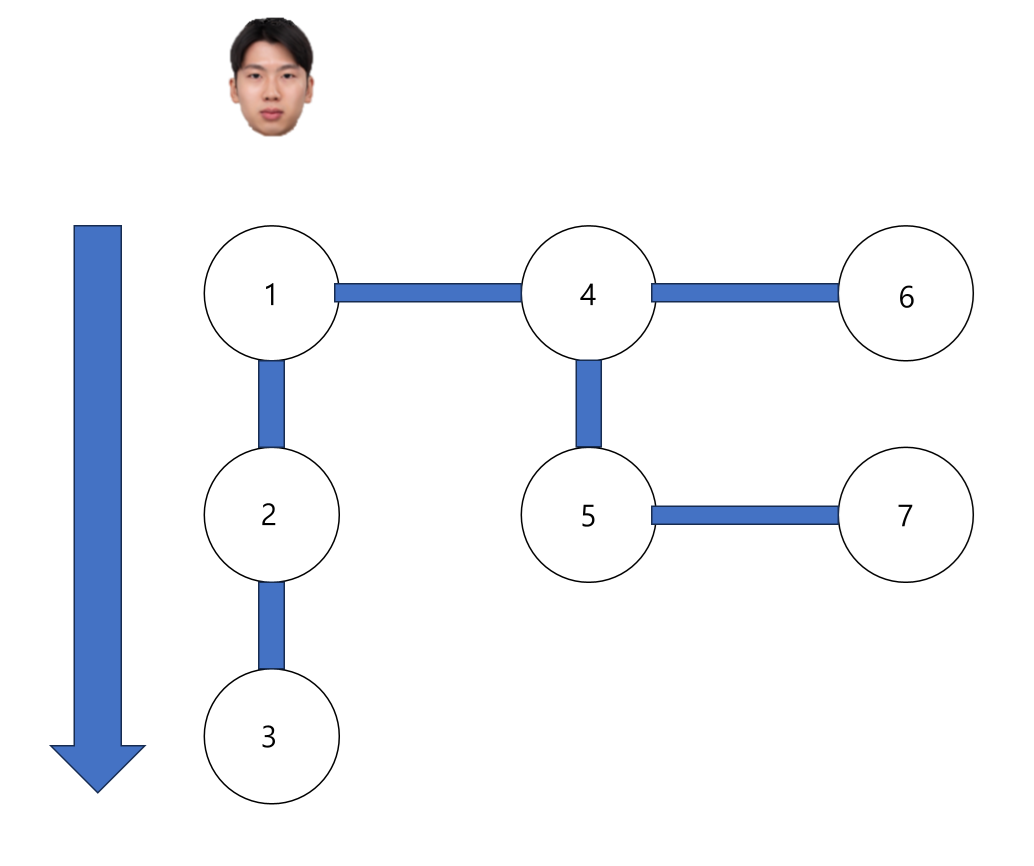
- 1 → 2 → 3 → 4 → 5 → 7 → 6
1번 도시에서 출발해서 최대한 멀리 가보고 더 이상 갈 곳이 없으면 돌아와서 다른 길로 가는 방식이에요. 이 탐색 방법은 스택(Stack)이라는 자료구조를 사용하거나, 재귀 함수를 통해 구현할 수 있어요.
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.Collections;
import java.util.LinkedList;
import java.util.StringTokenizer;
public class DFS {
public static int V, E;
public static boolean[] visited;
public static LinkedList<Integer>[] nodeList;
public static StringBuilder sb = new StringBuilder();
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = new StringTokenizer(br.readLine());
V = Integer.parseInt(st.nextToken()); // 정점의 개수
E = Integer.parseInt(st.nextToken()); // 간선의 개수
// 각 정점별로 인접한 정점리스트를 만듭니다.
nodeList = new LinkedList[V + 1];
for (int i = 1; i <= V; i++) {
nodeList[i] = new LinkedList<Integer>();
}
// 간선 입력받기
for (int i = 0; i < E; i++) {
st = new StringTokenizer(br.readLine());
int node1 = Integer.parseInt(st.nextToken());
int node2 = Integer.parseInt(st.nextToken());
nodeList[node1].add(node2);
nodeList[node2].add(node1);
// 같은 레벨일 때 낮은 숫자를 먼저 탐색하도록 정렬합니다.
Collections.sort(nodeList[node1]);
Collections.sort(nodeList[node2]);
}
visited = new boolean[V + 1];
dfs(1); // 1번 정점부터 탐색 시작
System.out.println(sb);
}
public static void dfs(int node) {
visited[node] = true;
sb.append(node + " ");
for (int nextNode : nodeList[node]) {
if (!visited[nextNode])
dfs(nextNode);
}
}
}
입력 예시
7 6 // 정점 수, 간선 수
1 2
2 3
1 4
4 5
4 6
5 7
출력 예시
1 2 3 4 5 7 6
이 예제는 도시들(nodeList)을 연결하고, 방문한 도시는 기록(visited 배열)하며 재귀적으로 탐색해 나가는 방식이에요.
2. 너비 우선 탐색(BFS, Breadth-First Search)
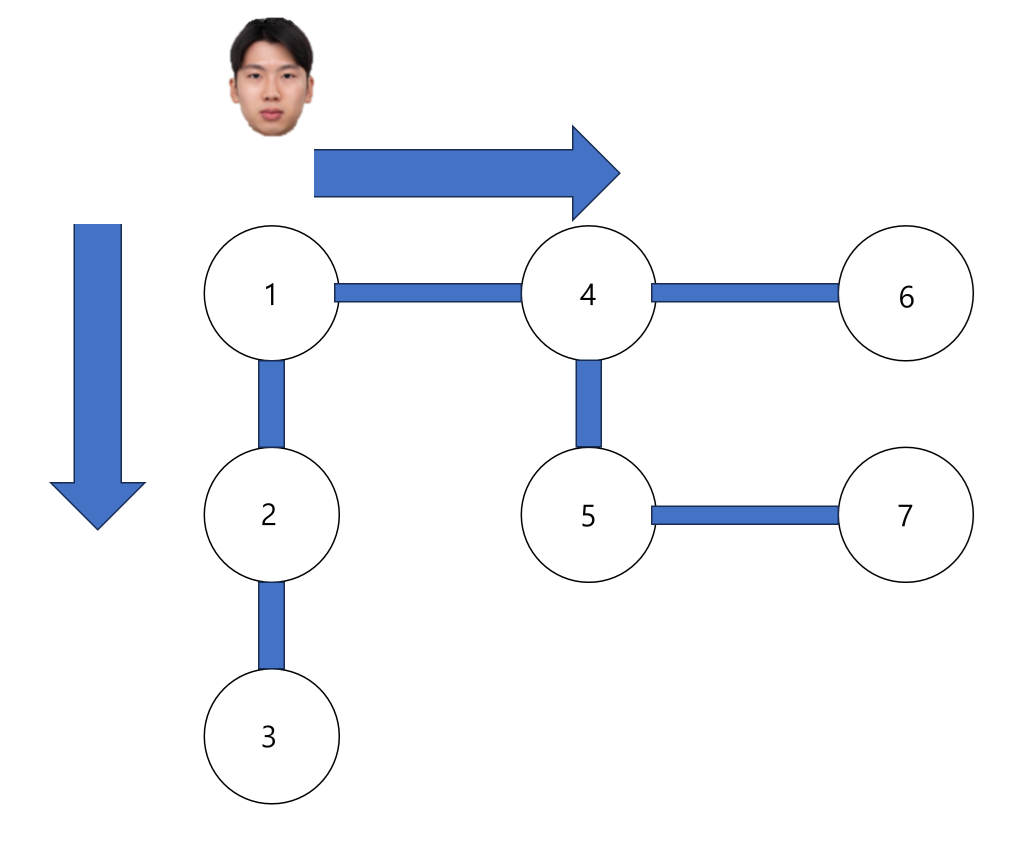
BFS는 시작 정점과 가까운 정점부터 차례로 방문하는 방식이에요. 예를 들어, 1번 도시에서 출발하면 그와 연결된 2번과 4번을 먼저 탐색해요. 그다음에는 2번과 4번 도시와 연결된 도시들을 차례로 방문해요.
- 1 → 2 → 4 → 3 → 5 → 6 → 7 순서로 탐색해요.
이 방법은 정점의 거리가 가까운 순서로 탐색하므로, 큐(Queue)라는 자료구조를 사용해요. 큐는 먼저 들어온 것이 먼저 나가는 자료구조예요.
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.ArrayDeque;
import java.util.Collections;
import java.util.LinkedList;
import java.util.Queue;
import java.util.StringTokenizer;
public class BFS {
public static int V, E;
public static boolean[] visited;
public static LinkedList<Integer>[] nodeList;
public static StringBuilder sb = new StringBuilder();
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = new StringTokenizer(br.readLine());
V = Integer.parseInt(st.nextToken()); // 정점의 개수
E = Integer.parseInt(st.nextToken()); // 간선의 개수
// 각 정점별로 인접한 정점리스트를 만듭니다.
nodeList = new LinkedList[V + 1];
for (int i = 1; i <= V; i++) {
nodeList[i] = new LinkedList<Integer>();
}
// 간선 입력받기
for (int i = 0; i < E; i++) {
st = new StringTokenizer(br.readLine());
int node1 = Integer.parseInt(st.nextToken());
int node2 = Integer.parseInt(st.nextToken());
nodeList[node1].add(node2);
nodeList[node2].add(node1);
// 같은 레벨일 때 낮은 숫자를 먼저 탐색하도록 정렬합니다.
Collections.sort(nodeList[node1]);
Collections.sort(nodeList[node2]);
}
visited = new boolean[V + 1];
bfs(); // BFS 탐색 시작
System.out.println(sb);
}
public static void bfs() {
Queue<Integer> queue = new ArrayDeque<>();
queue.add(1); // 1번 정점부터 시작
visited[1] = true;
while (!queue.isEmpty()) {
int node = queue.poll(); // 큐에서 하나를 꺼냄
sb.append(node + " ");
for (int nextNode : nodeList[node]) {
if (!visited[nextNode]) {
queue.add(nextNode);
visited[nextNode] = true;
}
}
}
}
}
입력 예시
7 6 // 정점 수, 간선 수
1 2
2 3
1 4
4 5
4 6
5 7
출력 예시
1 2 4 3 5 6 7
이 예제는 큐를 이용해서 정점의 가까운 순서대로 차례로 탐색해 나가요.
정리
DFS와 BFS는 그래프의 모든 정점을 탐색하는 방법이에요. 둘 다 모든 정점과 간선을 고려하기 때문에 시간 복잡도는 O(V + E)가 돼요.
어떤 문제를 풀 때 DFS와 BFS를 선택하는 기준이 있는데, 예를 들어 A에서 B까지 가는 모든 경우의 수를 찾는 문제는 DFS를 쓰고, A에서 B까지의 가장 빠른 길을 찾는 문제는 BFS를 쓰는 게 좋아요.
하지만 문제마다 다를 수 있기 때문에 여러 문제를 풀어보며 더 효율적인 방법을 찾는 것이 중요해요!
