
위상 정렬(Topological Sort)
위상 정렬은 순서가 정해져 있는 일을 차례대로 해야 할 때 그 순서를 정해주는 알고리즘이에요. 예를 들어, 학교에서 수강 신청할 때 A 수업을 듣기 전에 B 수업을 꼭 들어야 하는 선수 과목 제도를 생각해보세요. A를 듣기 전에 B를 들어야 하니까, 이처럼 순서가 정해진 작업을 정리하는 데 쓰는 방법이에요.
위상 정렬을 사용하기 위한 조건
- 정점들 사이에 방향이 정해져 있어야 해요. (유향 그래프)
- 순환하지 않아야 해요. (비순환 그래프)
예를 들어, "물건을 넣기 전에 상자를 준비해야 해"라는 규칙처럼, 순서가 정해져 있어야 해요. 하지만 "A 일을 한 다음에 다시 B를 하고, 또 다시 A를 해야 해" 같은 식으로 순환이 생기면 안 돼요!
위상 정렬에서는 각 작업(정점)을 하기 전에 필요한 다른 작업이 있는지 확인하기 위해 진입 차수(inDegree)를 사용해요. 진입 차수는 어떤 정점에 연결된 들어오는 선의 개수를 의미해요. 이게 0이면 먼저 해도 되는 일이에요!
위상 정렬을 구현하는 방법
- DFS(깊이 우선 탐색) 방식
- BFS(너비 우선 탐색) 방식
1. DFS 방식으로 구현하기
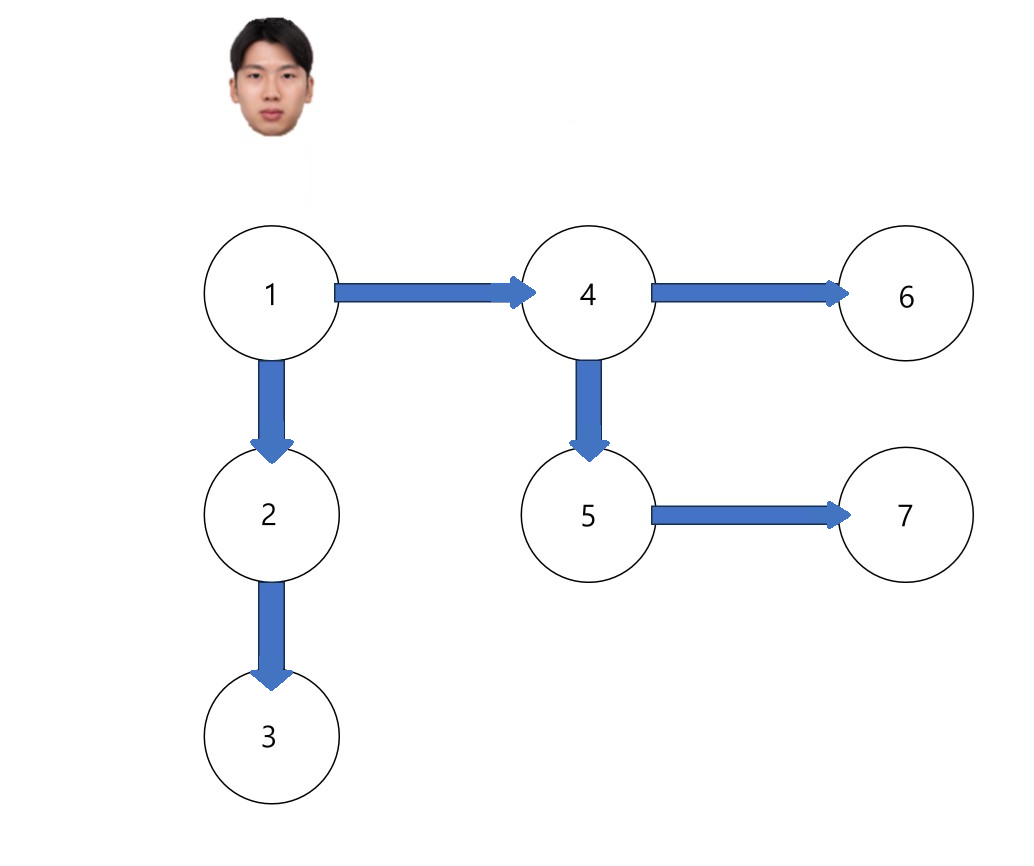
DFS는 한 방향으로 깊이 들어가며 탐색하는 방식이에요. 우리가 하나의 일(정점)에서 다음 일(정점)로 계속 이동하다가 더 이상 할 일이 없으면 돌아와서 다른 일을 탐색하는 거예요.
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.LinkedList;
import java.util.Stack;
import java.util.StringTokenizer;
public class TopologicalSort_DFS {
public static int V, E;
public static boolean[] visited;
public static LinkedList<Integer>[] nodeList;
public static Stack<Integer> stack = new Stack<>();
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = new StringTokenizer(br.readLine());
V = Integer.parseInt(st.nextToken()); // 정점의 개수
E = Integer.parseInt(st.nextToken()); // 간선의 개수
// 각 정점별로 다음 정점리스트를 만듭니다.
nodeList = new LinkedList[V + 1];
for (int i = 1; i <= V; i++) {
nodeList[i] = new LinkedList<Integer>();
}
// 간선 입력받기
for (int i = 0; i < E; i++) {
st = new StringTokenizer(br.readLine());
int from = Integer.parseInt(st.nextToken());
int to = Integer.parseInt(st.nextToken());
nodeList[from].add(to);
}
visited = new boolean[V + 1];
topologicalSort();
while (!stack.isEmpty()) {
System.out.print(stack.pop() + " ");
}
}
public static void topologicalSort() {
for (int i = 1; i <= V; i++) {
if (!visited[i])
dfs(i);
}
}
public static void dfs(int node) {
visited[node] = true;
for (int next : nodeList[node]) {
if (!visited[next])
dfs(next);
}
stack.push(node);
}
}
입력 예시
7 6 // 정점 수, 간선 수
1 2
2 3
1 4
4 5
4 6
5 7
출력 예시
1 4 6 5 7 2 3
이 방법은 먼저 갈 수 있는 최대한 깊은 곳까지 가서 작업을 하고, 더 이상 갈 곳이 없으면 스택에 쌓아둡니다. 쌓아둔 순서대로 꺼내면 그게 바로 위상 정렬이에요.
2. BFS 방식으로 구현하기
이번에는 BFS를 사용해볼 거예요. BFS는 한 번에 가까운 정점(일)을 모두 확인하고 그다음 단계로 넘어가는 방식이에요. 이때, 진입 차수를 이용해서 아직 수행할 수 없는 일을 구별해요. 예를 들어, 선행 작업이 끝나야 할 수 있는 일이 있다면, 그 일을 하기 전까지는 기다려야 해요.
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.ArrayDeque;
import java.util.LinkedList;
import java.util.Queue;
import java.util.StringTokenizer;
public class TopologicalSort_BFS {
public static int V, E;
public static int[] inDegree;
public static LinkedList<Integer>[] nodeList;
public static LinkedList<Integer> result = new LinkedList<>();
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = new StringTokenizer(br.readLine());
V = Integer.parseInt(st.nextToken()); // 정점의 개수
E = Integer.parseInt(st.nextToken()); // 간선의 개수
// 각 정점별로 다음 정점리스트를 만듭니다.
nodeList = new LinkedList[V + 1];
for (int i = 1; i <= V; i++) {
nodeList[i] = new LinkedList<Integer>();
}
// 간선 입력받으며 inDegree 체크
inDegree = new int[V + 1];
for (int i = 0; i < E; i++) {
st = new StringTokenizer(br.readLine());
int from = Integer.parseInt(st.nextToken());
int to = Integer.parseInt(st.nextToken());
nodeList[from].add(to);
inDegree[to]++;
}
topologicalSort();
for (int node : result) {
System.out.print(node + " ");
}
}
public static void topologicalSort() {
Queue<Integer> queue = new ArrayDeque<>();
// 진입 차수가 0인 노드를 큐에 넣는다.
for (int i = 1; i <= V; i++) {
if (inDegree[i] == 0)
queue.add(i);
}
while (!queue.isEmpty()) {
int node = queue.poll();
result.add(node);
for (int next : nodeList[node]) {
if (--inDegree[next] == 0)
queue.add(next);
}
}
}
}
입력 예시
7 6 // 정점 수, 간선 수
1 2
2 3
1 4
4 5
4 6
5 7
출력 예시
1 2 4 3 5 6 7
이 방법은 먼저 진입 차수(inDegree)가 0인 노드를 큐에 넣고, 이 노드를 꺼내면서 연결된 선을 없애고 다른 노드들의 진입 차수를 줄이는 방식이에요. 줄어든 진입 차수가 0이 되면 그 노드를 큐에 넣어서 반복해요.
정리
위상 정렬은 순서가 정해진 일을 차례로 정리하는 방법이에요. 두 가지 방식(DFS, BFS) 모두 모든 정점과 간선을 탐색하기 때문에 시간 복잡도는 O(V + E)로 같아요.
위상 정렬의 결과는 항상 일정하지 않을 수 있어요. 입력값이 같더라도 다른 순서의 결과가 나올 수 있지만, 그것들이 모두 올바른 위상 정렬 결과라는 점을 알 수 있어요!
연습 문제
