Replication
기본구성
- 데이터를 실질적으로 저장하는 소스서버 (Master)
- 소스서버(Master)의 데이터를 복제해서 저장하는 레플리카서버(Slave)
Replication시 장점
- 스케일 아웃 → 레플리카서버를 늘려서 트래픽을 감당 가능하게 동적으로 규모를 늘릴 수 있음
- 데이터 백업시 소스 서버에서 하면 실제 서버에 부담을 줄 수 있기 때문에 레플리카 서버에서 백업을 진행하여 부담을 줄인다.
- 데이터 분석용 서버를 구성해서 특정용도를 위한 서버를 따로 구축할 수 있다.
- 데이터의 지리적 분산: 특정 지역에 레플리카 서버를 구축해 응답속도를 개선 가능
바이너리 로그
MySQL에서 모든 변경 사항을 순서대로 저장하고 있음 다음 명령어로 볼 수 있다.
show binary logs
show mater status;소스 서버의 바이너리 로그가 레플리카 서버로 저장되고 그것을 통해 데이터의 동기화가 진행됨
바이너리 로그 저장방식
- Statement 방식: SQL문을 바이너리 로그에 그대로 기록함
- 트랜잭션 격리 수준이 REPEATABLE-READ 이상이어야 데이터가 일치함
- 비 확정적으로 실행되는 쿼리(order by limit delete같은 매번 다르게 평가되는)가 있으면 데이터가 달라질 수 도 있음
- Row 방식: 변경된 데이터 자체를 기록하는 Row 방식
- 가장 일관적인 데이터 저장 방식 → 안전함
- 단시간에 로그파일이 커짐
- Mixed: statement와 row방식을 혼합함
- statement로 기록했을때 안전하지 않을것같으면 row방식으로 기록함
복제과정
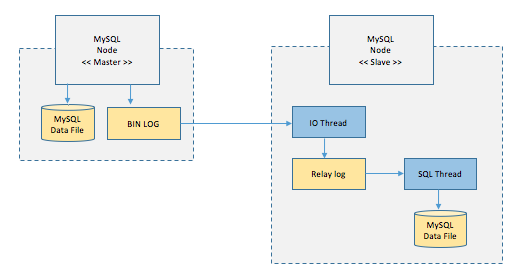
이러한 복제 과정은 3개의 스레드를 통해 복제되는데
-
소스서버의 Binary Log Dump Thread가 바이너리 로그를 레플리카서버에 전송함
-
레플리카서버의 Replication I/O Thread 바이너리 로그 이벤트를 레플리카 서버에 Relay Log파일로 저장
(연결시 사용정보는connection metadata에 있고, slave_master_info에 저장됨)
-
레플리카서버의 Replication SQL Thread는 Replication I/O Thread에 의해 작성된 Relay Log파일을 읽고 실행함
(릴레이 로그 이벤트를 서버에 적용하는 컴포넌트를 applier라고 하는데 이벤트가 저장된 릴레이로그 파일명,위치와 소스서버에 연결할 때 사용하는 정보가 저장되어있다. slave_relay_log_info테이블에 저장됨)
변경 내용식별
- 바이너리 로그 파일 위치 기반
- 레플리카 서버에서 소스 서버의 바이너리 로그 파일명과 파일내에서 위치로 바이너리 로그 이벤트를 식별해서 복제함
- server-id={n}으로 서버를 식별함 각 서버마다 넘버링을 해줘야함 → 이벤트가 처음 발생한 위치를 식별하기 위해 서버 아이디를 지정해야함
- 글로벌 트랜잭션 ID 기반(GTID)
-
MySQL 버전 5.5까지는 바이너리 로그 파일 위치 기반으로만 가능했음 → 식별과정이 소스서버에서만 유효함 , 레플리카서버에 동일한 위치에 저장된다고 보장할 수 없음
-
복제 동기화 방식
- 비동기 복제
- 제대로 적용됬는지 확인하지 않음 ,데이터가 100% 일치하지 않음
- 반동기 복제
- 소스 서버는 레플리카 서버가 소스 서버로부터 전달 받은 변경 이벤트를 릴레이 로그에 기록 후 응답을 보내면 그때 트렌잭션을 커밋함
- 비동기 방식보다 트랜젝션 처리가 느려짐, 응답이안오면 무제한으로 기다릴수있으니 일정시간지나면 비동기 복제로 젼환
Replication 종류
싱글 레플리카 복제
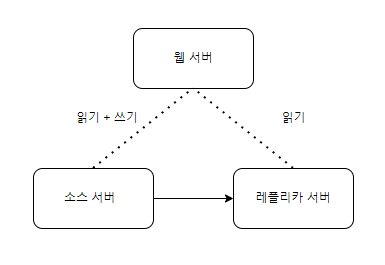
- 하나의 소스 서버에 하나의 레플리카서버
- 소스 서버에 문제가 생길 경우 예비서버 역할, 데이터 백업 수행을 위한 용도
멀티 레플리카 복제
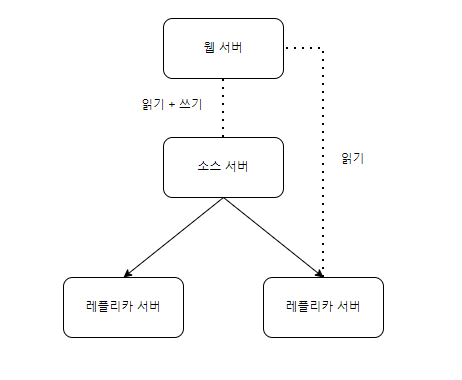
- 하나의 소스 서버에 두 개의 레플리카 서버
- 하나는 백업용, 하나는 읽기 요청 분산
체인 복제
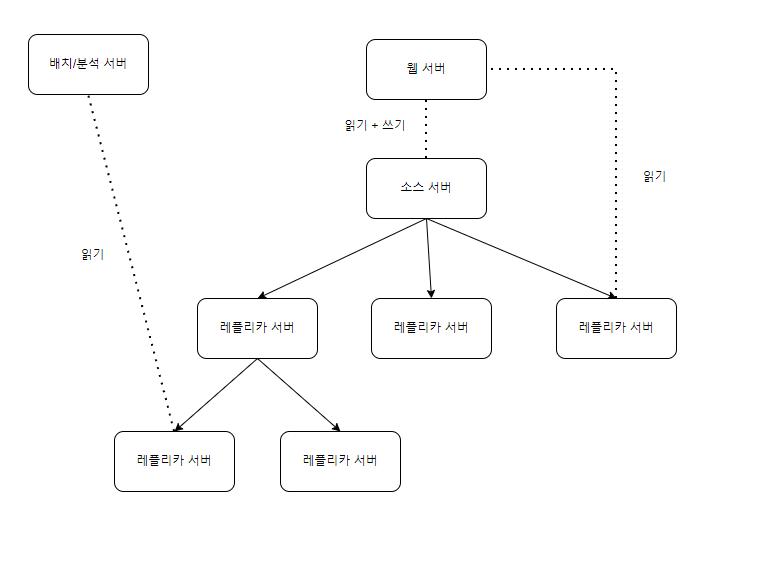
- 하나의 소스 서버에 레플리카가 여러개 달리면 바이너리 로그 복사작업이 부담이 될 수 있음
- 소스 서버가 해야할 로그 배포역할을 다른서버로 넘길수있음
듀얼 소스 복제
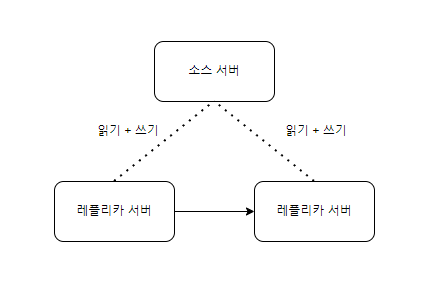
- 두개의 서버가 소스이자 레플리카
- 각 서버에서 변경한 데이터는 각 서버에 전달되어서 동일한 데이터를 갖게됨
- Active -Active(항상가동) 형태, Activae - Standby(일부는 대기)형태로 가능
- 그냥 레플리케이션 방식과 달리 한서버에서 문제가 생기면 바로 전환가능
멀티 소스 복제
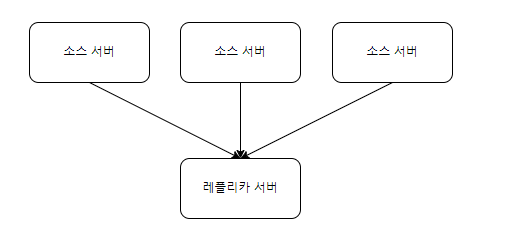
- 하나의 레플리카 서버가 여러개의 소스서버를 가짐
- 여러 서버에 존재하는 다른 데이터를 통합하거나 샤딩 되어있는 테이블을 하나의 테이블로 통합할 때 사용함
Clustering
- 레플리케이션은 저장소 + 서버가 개별로 생성되지만 클러스터링은 db스토리지 하나와 다수의 서버로 구성됨
연결방식
Active-Active 방식
- 클러스터를 구성하는 컴포넌트들이 동시에 가동되는 방식, 하나의 저장소를 공유함
장점
- 시스템이 다운되어 있는 시간이 짧기 때문에 시스템 전체가 정지하는 것을 방지할 수 있음
- 동시에 가동하기 때문에 전체 cpu,메모리등이 증가해 성능 향상도 기대할 수 있음
단점
- 저장소에서 병목이 일어날 수 있어서 높은 성능향상을 기대하기 어려울 수도 있다.
- Active-Active 방식을 지원 하는 데이터 DBMS가 한정적이다.
- ( Oracle = RAC(Real Application Cluster, DB2 = pureScale 라는 이름의 Active-Active 클러스터링이 가능하고, 다른 DBMS에서는 Active-Standby 클러스터링만 대응하고 있다.
- MySQL에서는 지원해주지 않는 걸로 보임 → MySQL Cluster를 사용하는 것 같은데 InnoDB가 아니라고 함 , 아래에 작성한 Galera cluster를 솔루션으로 사용한다고함
- 서버를 여러대 한꺼번에 운영하므로 비용이 증가함
Active-Standby 방식
- 클러스터를 구성하는 컴포넌트중 Active만 사용하다가 장애가 생기면 standby가 작동하는 구성
- Cold-Standby:평소에 DB가 작동하지 않다가 Active DB에 장애 작동하는 구성
- Hot-Standby: 평소에 Standby DB가 작동되는 구성이다.
- Hot-standby는 라이선스료를 많이 지급 한다는점에서 단점이 있음
- Standby DB 서버는 일정 간격으로 Active DB에 이상이 없는지를 조사하기 위한 통신을 하고 있다. 이 통신을 'Heartbeat'라고 한다. Active DB에 장애가 발생하면 이 신호가 끊기기 때문에Standby 측은 Active가 '죽었다'는 것을 알 수 있다.
Galera cluster
- 동기방식의 clustering을 지원해주는 오픈소스로 보임
참고 자료
-
레플리케이션 참고
-
데이터베이스의 다중화
[Database] DB 서버의 다중화 클러스터링(Multiplexing Clustering)과 리플리케이션(Replication)
-
레플리케이션 소개 영상: 작동원리, 장단점, 종류 -> 정말좋은 영상!
-
레플리케이션 설정
-
DB 아키텍쳐 종류 및 설명 (데이터베이스 첫걸음 책)
