
1. Now this will run on my 486?
바이너리의 동작을 분석해 필요한 입력값을 구해야 하는 유형의 문제였다.
이 바이너리의 고유한 특징으로는 명령어 언패킹을 코드를 실행하기 전에 수행하는 게 아니라, illegal instruction 시그널에 핸들러 함수를 등록해 한 코드 가젯씩 언패킹한다는 점이다. 이 점 때문에 코드를 분석하는 과정이 조금 더 복잡했다.
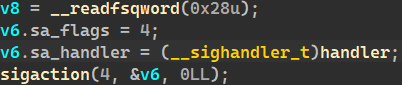
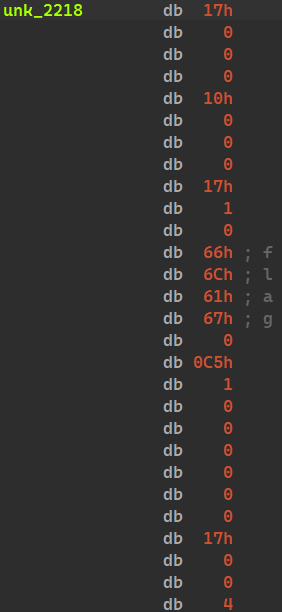
이 영역의 코드를 하나씩 실행시켜 illegal instruction을 낸다.
그래도 IDA의 동적 분석 기능과 시그널 처리 옵션을 커스터마이징하는 기능을 활용해 코드를 읽을 수 있게 띄울 수 있었다. 동작 자체는 단순 xor이었기 때문에 따로 익스플로잇 코드를 짜지 않고 문제를 해결할 수 있었다.
2. Crispy Kelp
Golang으로 작성된 바이너리가 주어진다.
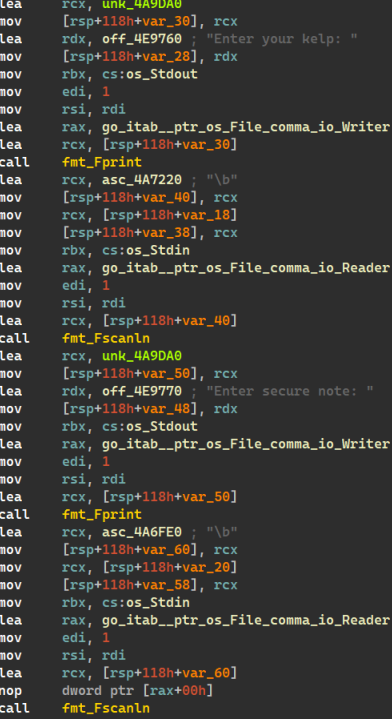
이 바이너리는 처음 시작할 때 kelp(정수)값과 secure note(4바이트 유니코드 문자열)를 입력하라고 하는데, 이 두 값을 입력받고 encodeString으로 넘겨주어 인코딩을 수행한다.

이 함수에서는 일단 secure note 길이만큼의 4바이트 문자열을 랜덤으로 생성하고, 다음과 같은 규칙에 따라 (secure note의 길이)*2+1 길이의 문자열을 생성한다.
일단 다음과 같은 규칙으로 secure note 길이만큼의 문자열을 생성한다.
encoded[i]=(secure_note[i]^rand[i])+kelp
이후 kelp값을 붙이고, 다음과 같은 규칙으로 한 번 더 secure note 길이의 문자열을 생성한다.
encoded[i+note_len+1]=(rand[i]^encoded[i])+kelp
이를 활용하면 뒤에 붙여진 encoded 문자열로 rand 값을 알아낼 수 있고, 이 rand 값으로 secure_note까지 알아낼 수 있다.
res=b'\xeb\xb3\x98\xeb\xb5\x8c\xeb\xb5\x94\xeb\xb3\x89\xeb\xb3\xa4\xeb\xb4\xb1\xeb\xb6\x93\xeb\xb2\xb4\xeb\xb5\x8f\xeb\xb3\x8d\xeb\xb5\xa3\xeb\xb5\x9c\xeb\xb3\xa2\xeb\xb6\x82\xeb\xb6\x8e\xeb\xb3\x9d\xeb\xb4\x85\xeb\xb3\xb3\xeb\xb4\x88\xeb\xb4\x80\xeb\xb2\xac\xeb\xb5\x80\xeb\xb3\x9f\xeb\xb5\x8d\xeb\xb5\x9c\xeb\xb5\xb5\xeb\xb4\xab\xeb\xb3\xa4\xeb\xb6\xa2\xeb\xb5\xbf\xeb\xb6\x9a\xeb\xb4\x8c\xeb\xb5\xb2\xeb\xb4\x86\xeb\xb3\xb7\xeb\xb5\xb6\xeb\xb4\xb1\xeb\xb5\x8f\xeb\xb6\xa4\xeb\xb5\x87\xeb\xb4\x8a\xeb\xb5\x83\xeb\xb3\x82\xeb\xb5\x9a\xeb\xb3\x85\xeb\xb3\x95\xeb\xb3\x84\xeb\xb2\xac\xeb\xb2\xa6\xf0\x97\xa4\xa9\xf0\x97\xa8\xbe\xf0\x97\xa8\xb9\xf0\x97\xa4\xbf\xf0\x97\xa5\x9f\xf0\x97\xa9\xb4\xf0\x97\xa6\xbe\xf0\x97\xa5\xa7\xf0\x97\xa8\xb3\xf0\x97\xa5\xbf\xf0\x97\xa9\x98\xf0\x97\xa9\x80\xf0\x97\xa4\xa7\xf0\x97\xa8\x95\xf0\x97\xa6\xbb\xf0\x97\xa5\x9b\xf0\x97\xa8\x94\xf0\x97\xa6\x87\xf0\x97\xa6\xa8\xf0\x97\xa8\x8f\xf0\x97\xa5\x84\xf0\x97\xa9\x9c\xf0\x97\xa4\xb8\xf0\x97\xa8\xa8\xf0\x97\xa8\xb9\xf0\x97\xaa\x8b\xf0\x97\xaa\x82\xf0\x97\xa6\x8f\xf0\x97\xa7\x94\xf0\x97\xa9\xb0\xf0\x97\xa8\x80\xf0\x97\xa6\xaf\xf0\x97\xa8\xb3\xf0\x97\xa6\xb1\xf0\x97\xa4\xbb\xf0\x97\xa9\xae\xf0\x97\xa8\xb3\xf0\x97\xa9\x9f\xf0\x97\xa7\xa2\xf0\x97\xa9\xbc\xf0\x97\xa7\x82\xf0\x97\xa8\xa7\xf0\x97\xa5\xa3\xf0\x97\xa8\xac\xf0\x97\xa6\x91\xf0\x97\xa4\xb0\xf0\x97\xa6\x95\xf0\x97\xa5\xbd'.decode('utf-8')
res_rune=[(ord(c)) for c in res]
print(res_rune)
input_len=len(res_rune)//2
secret_note=res_rune[input_len]
print('secret note : ', secret_note)
for i in range(input_len):
cur_rand=(res_rune[i+input_len+1]-secret_note)^res_rune[i]
print(chr((res_rune[i]-secret_note)^cur_rand), end='')3. Bunny Jumper!

문제 사이트에 접속하면 이렇게 플래그 체커가 나온다.
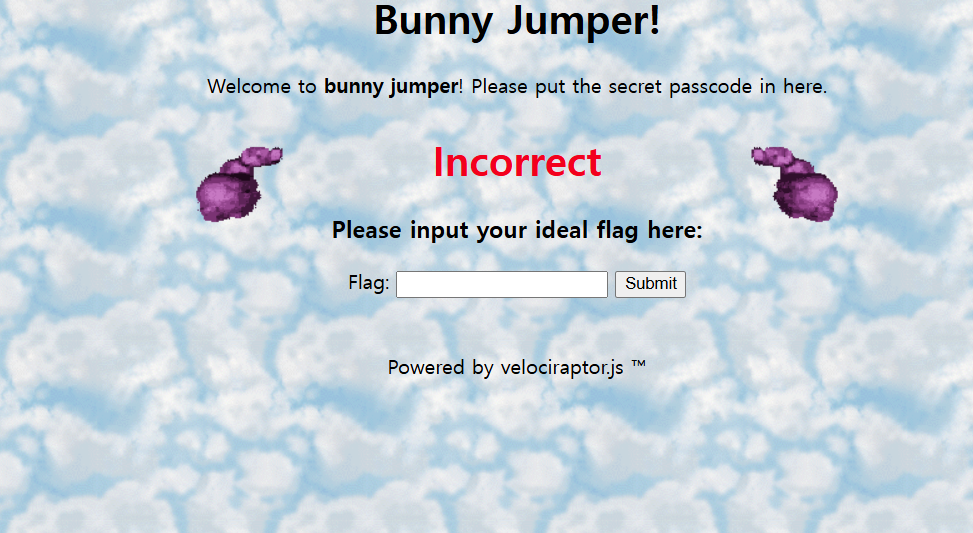
일단 플래그 체커의 로직을 알아내기 위해 코드를 찾아봤더니 점프 테이블 난독화가 되어 대략 1800줄 가까이 되는 로직을 발견했다. 보이는 순서대로 읽을 수 있는 코드가 아니었기 때문에 일단 실행되는 과정을 출력하게 하는 코드를 생성하는 파이썬 스크립트를 작성했다.

total_code=open('code.js', 'r').read().split('\n')
new_code=""
for i in range(len(total_code)):
token=total_code[i].lstrip(' ').split(' ')[0]
tmp_token=""
if len(total_code[i].lstrip(' ').split(' '))>1:
tmp_token=total_code[i].lstrip(' ').split(' ')[1]
if token!="for" and token!="if" and token!="continue" and token!="break" and token!="}" and token!="function" and token!="var" and token[-1]!=':' and ((token!='C' or tmp_token!='=')):
new_code+="console.log(\'"+total_code[i].lstrip(' ')+"\')\n"
new_code+=total_code[i]+"\n"
open("new_code.js", "w").write(new_code)위 코드를 실행하면 다른 점프 테이블로 넘어가는 코드를 제외한 모든 코드를 console.log로 찍어준다. 그리고 이를 실행시키면
이렇게 실행 과정을 한 눈에 볼 수 있게 출력되었다.
정리하면, 전체 플래그 중 4개의 문자를 뽑고, 뽑은 문자 중복 집합 내에서 각 문자들이 나온 횟수에 따라 트리를 생성한다.
그 후 각 문자의 트리 내부의 상대적인 높이에 따라 번호를 부여하고 jumpjump...jump를 비트 단위로 쪼개 다음 규칙으로 인코딩한다.
위에서 생성한 번호가 부여된 각 문자의 아스키코드번째 인덱스부터 그 문자에 부여된 번호와 위 문자열을 xor한다.
익스플로잇 코드는 다음과 같다.
from base64 import b64decode
table=[ord(i) for i in 'jumpjumpjumpjumpjumpjumpjumpjumpj']
base_table=["dW1wQtXNWGp", "dW1xKnVFcS9", "dW1xKnVFWH5", "dW1xLHXNcGp", "dW1wCnVFcG9", "dW1x6PVtWGp", "dW1xL3VucGp", "dW1xKn9ucGp", "dW1xKtVtdmp", "dW1xKiVtdmp", "dW1xKPZtcGp", "dW1wanfucH5", "dW1x6nVFcH5", "dW1wfnVtEG9", "dW1xL3ZtcGp", "dW1waXVv+mp", "dW1wCnVt1Wp", "dW1x6zVv8Gp", "dW1wQnBtaGp", "dW1wOnVsMAp", "dW1xKhU9cGp", "dW1xKnVucSp", "dW1wcn89cGp", "dW1x6nVtcGp", "dW1wanVtEGp", "dW1wahVtcGp", "dW1wanZtcGp", "dW1wanVrcGp"]
idx_table=[170208564, 303307048, 320086583, 387656501, 286799160, 236723758, 185603370, 168895531, 153103667, 152903206, 135141663, 119284279, 118959923, 253767992, 102047534, 84281399, 85665324, 68360487, 51782960, 51128620, 35464242, 18095146, 268849, 219753011, 202515241, 143414, 168894767, 151986214]
poss=[[] for i in range(58)]
used_table=[]
ref_table=[]
for bl in range(len(idx_table)):
cur=[i for i in b64decode('anVtcGp1bXBq'+base_table[bl]+'1bXBqdW1wanVtcGp1bXBq')]
diff_arr=[]
for i in range(8*len(cur)):
bidx, sidx=i>>3, i&7
f, s=(table[bidx]>>(7-sidx))&1, (cur[bidx]>>(7-sidx))&1
if f!=s:
diff_arr.append(i)
sum=0
used=[]
for i in range(0, len(diff_arr), 2):
if diff_arr[i+1]-diff_arr[i]==1:
used.append([diff_arr[i]-sum, 1])
elif diff_arr[i+1]-diff_arr[i]==2:
used.append([diff_arr[i]-sum, 2])
sum+=4
cidx=len(used_table)
used_table.append(used)
ref_table.append(0)
vst=[0]*58
for i in range(4):
ii=idx_table[bl]&255
idx_table[bl]>>=8
if ii>=58 or vst[ii]:
continue
poss[ii].append(cidx)
ref_table[len(ref_table)-1]+=1
vst[ii]=1
for i in range(len(used_table)):
cur=used_table[i]
cur.sort(key=lambda each: each[1])
new_cur=[]
if len(cur)==1:
new_cur=[cur[0][0]]*ref_table[i]
elif len(cur)==3:
if ref_table[i]==4:
new_cur=[cur[0][0], cur[0][0], cur[1][0], cur[2][0]]
else:
new_cur=[cur[0][0], cur[1][0], cur[2][0]]
else:
new_cur=[cur[0][0], cur[1][0], cur[2][0], cur[3][0]]
used_table[i]=new_cur
target_cnt=57
flag_arr=[0]*58
idx=0
while target_cnt:
max_cnt, max_idx=0, -1
ccnt=[0]*256
for i in poss[idx]:
vst=[0]*256
for j in used_table[i]:
if vst[j]==0:
ccnt[j]+=1
if ccnt[j]==len(poss[idx]):
max_cnt+=1
max_idx=j
vst[j]=1
if max_cnt==1:
flag_arr[idx]=max_idx
for i in poss[idx]:
used_table[i].remove(max_idx)
target_cnt-=1
idx=(idx+1)%58
for i in flag_arr:
print(chr(i), end='')
니얼굴