⚙️ 회원가입하면 프로필 자동 생성
이전
공통 준비 단계에서 공통 트리거 함수(set_updated_at) 를 만들어뒀다.
이번에는 회원가입 시 자동으로 프로필이 만들어지도록
같은 SQL 파일 안에 새로운 함수(handle_new_user) 와 트리거 연결 코드를 추가했다.이렇게 하면
auth.users테이블에 새 유저가 추가될 때마다,
profiles테이블에도 자동으로 같은 id로 한 줄이 들어가게 된다.
1. 함수 코드 추가하기 (handle_new_user)
🔍 handle_new_user
handle_new_user는 회원가입 직후(auth.users에 레코드가 INSERT 될 때) 자동 실행되는 트리거 함수다.
새로 생성된 유저의id를 그대로 사용해profiles에 한 줄을 만들고, 이 단계에서는 최소 정보인id,
name(또는 display_name)은 회원가입 폼에서 사용자가 직접 입력하는 값이기 때문에, 여기서는 임의의 값(이메일 앞부분 등)으로 채우지 않는다.
이미 같은id가 있을 경우엔on conflict do nothing으로 중복 삽입을 안전하게 무시한다. (security definer로 동작해 권한 이슈 없이 수행)
Supabase 대시보드 → Database → SQL Editor로 이동.⚠️ 주의:
새 쿼리를 따로 만들지 않는다.
이미set_updated_at()함수를 만들어뒀던 SQL 파일(Auto-update updated_at Trigger Function)을 열고,
맨 아래에 아래 코드를 이어서 추가했다.
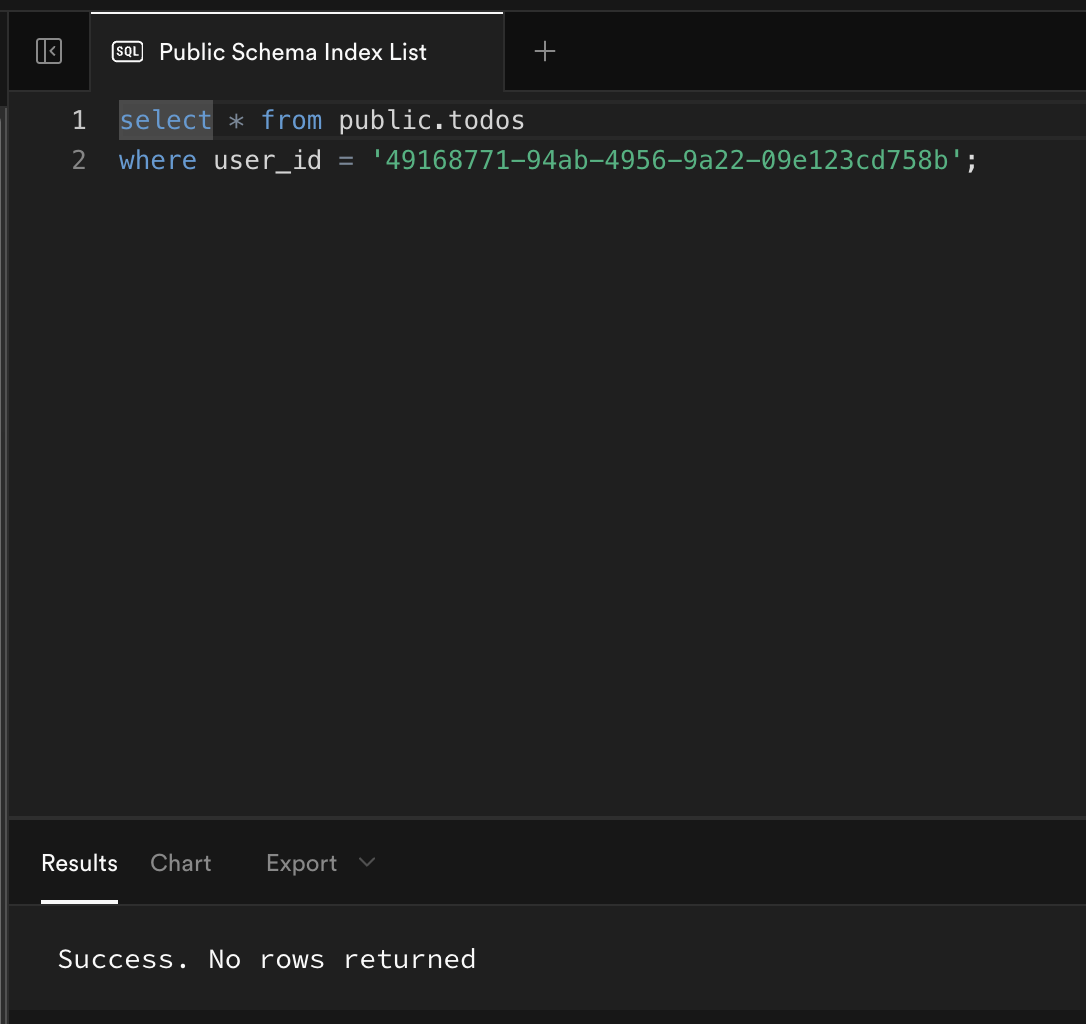
SQL Editor 하단 Role이postgres인지 확인 후 Run ▶ 클릭.-- 새 유저가 추가될 때 자동으로 profiles에 생성되는 함수 create or replace function public.handle_new_user() returns trigger language plpgsql security definer set search_path = public as $$ begin insert into public.profiles (id, email) values ( new.id, lower(new.email) ) on conflict (id) do nothing; return new; end; 💲💲; -- 이상해서 이모지로 대체💬 정리 메모
security definer
→ 함수 소유자 권한으로 실행되어 회원가입 직후RLS에 막히지 않음
profiles에는 회원가입 순간에 최소 레코드만 생성
id,name/display_name은 회원가입 폼에서 입력받아 UPDATE
on conflict (id) do nothing
→ 중복 삽입 방지용 안전 장치
2. 트리거 연결하기 (auth.users → profiles 자동 생성)
🔎
auth.users가 뭐예요?“내가 만든 적도 없는데 갑자기 테이블이 생겼다고?” 싶을 수 있다 😅
하지만 이건 Supabase가 Authentication 기능을 켜면 자동으로 만들어주는 시스템 테이블이다.
항목 설명 스키마 auth(일반 데이터베이스와 구분됨)테이블명 users역할 회원가입/로그인 시 계정 정보를 저장하는 Auth 전용 테이블 주요 컬럼 id,created_at,last_sign_in_atid의 의미로그인한 유저의 고유 식별자, auth.uid()와 동일💡 즉:
auth.users는 “회원가입이 일어나는 곳”이고,
profiles는 “그 계정의 개인 정보를 저장하는 곳”이다.
그래서 회원가입 시점을 잡기 위해 트리거를auth.users에 연결하는 것이다.
이제 위에서 만든 공통 트리거 함수를auth.users테이블과 연결한다.이번에도 새로운 쿼리를 만들어,
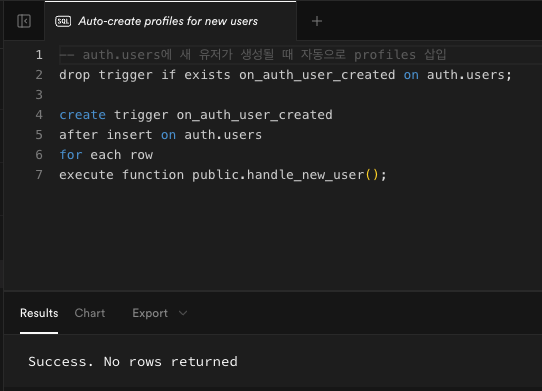
SQL 파일 하단에 아래 코드 추가 후 실행한다.-- auth.users에 새 유저가 생성될 때 자동으로 profiles 삽입 drop trigger if exists on_auth_user_created on auth.users; create trigger on_auth_user_created after insert on auth.users for each row execute function public.handle_new_user();위 코드를 통해 연결함으로써 흐름은 다음과 같다.
1. 사용자가 회원가입을 한다
2.auth.users에 레코드가INSERT된다
3.on_auth_user_created트리거가 실행된다
4.handle_new_user()함수가 호출된다
5.profiles테이블에 자동으로 한 줄이 생성된다
💬 정리 메모
auth.users테이블은 Supabase 기본 인증 테이블이다.- 새 계정이 생기면
handle_new_user()함수가 자동으로 실행된다.profiles.id는auth.users.id를 FK로 참조하고 있으므로
삭제 시에도 함께 정리된다 (on delete cascade).
3. 테스트 (⚠️ 이전 방식 기준 / 현재 구현 변경 안내)
⚠️ 테스트 방식 변경 안내
아래 테스트는 초기 구현 단계에서 사용하던 방식을 기준으로 작성된 내용이다.
당시에는 회원가입 시profiles테이블에 이메일 앞부분을display_name(또는nickname)으로 자동 저장하는 구조였다.하지만 이후 리팩토링을 통해,
- 회원가입 시점에는
profiles에 최소 정보(id,name/display_name은 회원가입 폼 단계에서 사용자가 직접 입력하여 UPDATE하는 구조로 변경했다.
즉, 현재 구현에서는
display_name이 자동으로 채워지지 않는 것이 정상이며- 이 단계의 목적은
👉profiles레코드가 자동 생성되는지 여부만 확인하는 것이다.※ 아래 테스트 결과와 예시는 이전 구현 기준 화면을 그대로 유지했으며,
현재 구현과의 차이를 보여주기 위한 참고용이다.
이제 직접 테스트해본다.
이전로그인 기능 켜기 단계에서 계정을 하나 만들어놨기 때문에 새 유저를 만드는 과정은 생략한다.
새로운 유저를 생성하고 아래 쿼리를 통해 결과를 확인해보자.
(Supabase 대시보드 → Authentication → Users 탭)
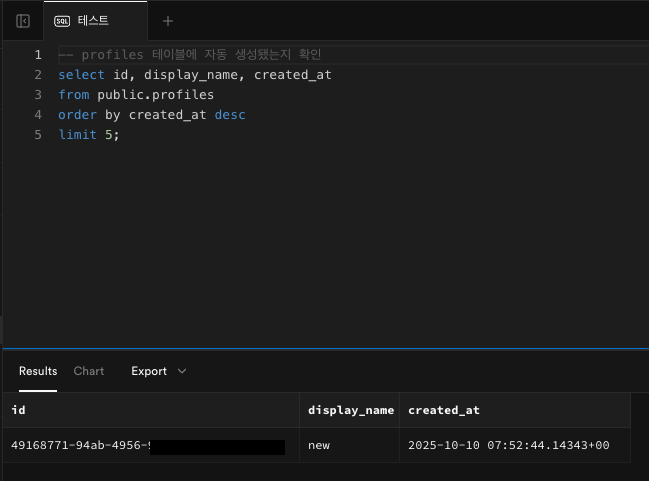
위에서 나온
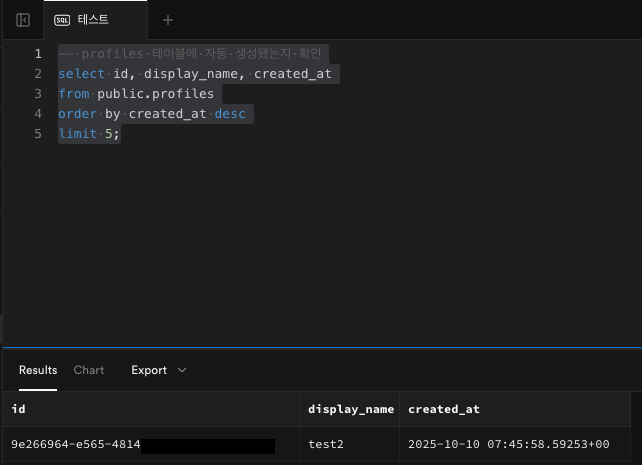
id중 하나를 기억해두고 아래 쿼리로 확인한다.-- profiles 테이블에 자동 생성됐는지 확인 select id, display_name, created_at from public.profiles order by created_at desc limit 5;📌 정상 결과 예시
id nickname created_at 77383342-a5cf-4762-8beb-835b8b2bd1d testuser 2025-10-10 05:11:23+00
✅
nickname이 이메일의 앞부분으로 자동 채워져 있다면 성공.

4. 점검 및 확인 사항
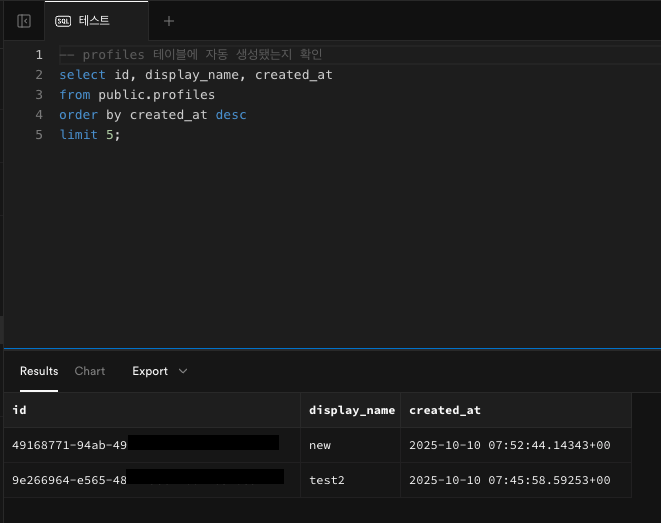
확인 항목 기대 결과 새 유저 생성 시 profiles에 자동으로 1행 추가 기존 유저( auth.users) 삭제 시profiles에서도 자동 삭제 ( on delete cascade)중복 ID 시 에러 없이 무시됨 ( on conflict do nothing)새 유저 생성시
Users탭에서 사용자를 새로 생성한 다음
SQL Editor에서 다시 실행해보았다.
기존 유저 삭제시
Users탭에서 기존 사용자를 삭제한 다음
SQL Editor에서 다시 실행해보았다.
✅ 이 단계 완료 기준
- 기존 SQL 스크립트에 함수/트리거 코드 추가 및 실행 완료
- 회원가입 시 프로필 자동 생성 정상 확인
- 기존 유저 삭제 → 프로필 자동 삭제 확인
- 중복 삽입 방지(
on conflict) 정상 작동
🔒 접근 권한 잠그기 (RLS 정책 설정)
이전
프로필 자동 생성 단계에서 회원가입 시 자동으로profiles가 만들어지도록 설정했다.
이제는 로그인한 사용자 본인만 자신의 데이터에 접근할 수 있도록
모든 테이블에 “행 단위 접근 제어(Row Level Security, RLS)”를 적용한다.
RLS를 설정하면 다른 사용자가 로그인해도 내 데이터는 절대 보이지 않는다.
즉, 데이터베이스 레벨에서 작동하는 “보안 잠금 장치🔒”를 추가하는 셈이다.
1. RLS(Row Level Security)란?
RLS는 “Row Level Security (행 단위 접근 제어)” 기능으로,
PostgreSQL이 제공하는 테이블 단위 보안 정책 시스템이다.
RLS를 활성화하면 각 사용자별로 접근 가능한 행을 제한할 수 있다.
즉, 로그인한 사용자(auth.uid())의 데이터만 조회·수정할 수 있고
다른 사용자의 데이터는 완전히 차단된다.
구분 설명 목적 사용자별로 접근 가능한 데이터 범위를 제한 기본 상태 RLS를 켜면 기본적으로 아무도 접근 불가 활성화 방식 alter table ... enable row level security;허용 방식 create policy명령으로 접근 조건을 명시
2. 모든 테이블에 RLS 켜기 (Enable Row Level Security)
Supabase 대시보드 → Database → SQL Editor로 이동한다음
상단의+버튼을 눌러 새로운 쿼리 파일(New query tab)을 만든 뒤,
아래 코드를 붙여넣고 실행한다.-- RLS 활성화 (모든 테이블에 적용) alter table public.profiles enable row level security; alter table public.todos enable row level security; alter table public.events_daily enable row level security; alter table public.events_weekly enable row level security; alter table public.events_monthly enable row level security; alter table <public.habits enable row level security; alter table public.notes enable row level security; alter table public.dashboard_layouts enable row level security;💡 기본 동작 원리
RLS를 켜면, 기본적으로
❌ 아무도 볼 수 없고, ❌ 아무도 수정할 수 없다.
즉, 이후 단계에서 “누가 어떤 조건으로 접근 가능한지”를 정책(policy)으로 지정해야 한다.
3. 공통 접근 정책 만들기 (내 데이터만 허용)
SQL Editor에서 아래 코드를 실행한다.
마찬가지로+버튼을 눌러 새로운 쿼리 파일(New query tab)을 만든 뒤,
아래 코드를 붙여넣고 실행한다.
예시 대상은todos테이블이며, 나머지 테이블도 동일한 구조로 만들면 된다.
🔎 왜 필요한가
- 2번에서 RLS를 켠 순간 기본값은 “❌ 아무도 접근 불가”.
- 그래서 정책(policy) 으로 “누가(로그인 사용자) 어떤 행(본인 소유) 무엇을 할 수 있는지(조회/생성/수정/삭제)”를 허용해야 한다.
USING은 대상 행 필터(SELECT/UPDATE/DELETE),WITH CHECK는 새/수정된 행의 제약(INSERT/UPDATE)으로 이해하면 끝.- 결론적으로 내
user_id가 아닌 데이터는 조회도, 쓰기도, 수정도, 삭제도 불가능해진다.-- drop (재실행 안전) drop policy if exists "Users can view their own data" on public.todos; drop policy if exists "Users can insert their own data" on public.todos; drop policy if exists "Users can update their own data" on public.todos; drop policy if exists "Users can delete their own data" on public.todos; -- create -- ✅ todos SELECT (조회): 내가 만든 데이터만 보기 create policy "Users can view their own data" on public.todos for select using (user_id = auth.uid()); -- ✅ todos INSERT (생성): user_id가 내 아이디일 때만 추가 create policy "Users can insert their own data" on public.todos for insert with check (user_id = auth.uid()); -- ✅ todos UPDATE (수정): 내 데이터만 수정 가능 create policy "Users can update their own data" on public.todos for update using (user_id = auth.uid()) with check (user_id = auth.uid()); -- ✅ todos DELETE (삭제): 내 데이터만 삭제 가능 create policy "Users can delete their own data" on public.todos for delete using (user_id = auth.uid());💡
auth.uid()는 로그인 토큰의 UID를 DB 세션에 주입해 읽는 값이라,
“현재 로그인한 사용자 소유 행만 허용”을 간단히 표현할 수 있다.
⚙️ 적용 대상:
todos나머지 테이블(
events_*,notes,habits등)도
같은 정책을 복사해서 적용하면 된다.
Run실행 후 "Success. No rows returned"이 출력되면 성공!✅
4. profiles 테이블은 예외 처리 (id 기반 정책)
profiles는user_id컬럼이 따로 없고,
id가 곧 로그인한 사용자의 고유 식별자이므로 정책을 따로 만든다.
+버튼을 눌러 새로운 쿼리 파일(New query tab)을 만든 뒤,
아래 코드를 붙여넣고 실행한다.
🔎 왜 예외인가
- 대부분 테이블은 소유자 키가
user_id이지만,profiles는 PKid자체가 사용자 UID다.- 또 프로필 생성은 6단계 트리거가 자동으로 처리하므로, 보통
INSERT정책은 불필요하다.- 운영 상
DELETE도 보통 막아두고, SELECT/UPDATE만 허용하는 구성이 안전하다.-- drop (재실행 안전) drop policy if exists "Users can view their own profile" on public.profiles; drop policy if exists "Users can update their own profile" on public.profiles; -- 프로필 조회/수정은 자신의 것만 가능 -- ✅ profiles SELECT (조회): 내 프로필만 보기 create policy "Users can view their own profile" on public.profiles for select using (id = auth.uid()); -- ✅ profiles UPDATE (수정): 내 프로필만 수정 create policy "Users can update their own profile" on public.profiles for update using (id = auth.uid()) with check (id = auth.uid());⚠️
insert정책은 필요하지 않다.
프로필은 이미 6단계의 트리거 함수로 자동 생성되기 때문이다.
Run실행 후 "Success. No rows returned"이 출력되면 성공!✅
5. 다른 테이블에도 일괄 적용 (공통 RLS 정책 복사)
여러 테이블에 같은 규칙을 반복 적용하려면 아래 SQL을 실행한다.
권장: SQL Editor+→ 새 쿼리 파일을 따로 만들어 실행한다.
💡 이게 뭔가?
3번(
todos), 4번(profiles)에서 정책의 모양(패턴)을 확정했다.
이제 이 동일한 패턴을 나머지 테이블에 한 번에 뿌려 주는 “동기화 스크립트”다.
즉, 테이블을 여러 개 운영할 때 발생하는 불일치/누락/오타를 막고, 언제든 같은 상태로 되돌릴 수 있게 만든다.
🔧 왜 하는가
- 테이블이 늘어나거나(예:
events_*추가), 정책을 손댄 뒤 전체 일관성을 맞춰야 할 때가 잦다.- 사람이 테이블마다 수동으로 복사·붙여넣기 하면 한 글자 차이로 정책이 달라지는 사고가 난다.
- 아래 스크립트는 각 테이블의 정책을 한 번에 “드롭 → 동일 이름으로 재생성”하여
“여러 번 실행해도 항상 같은 결과(재실행 안전)”가 되도록 한다.profiles는 키가id라 패턴이 달라서 별도(4번)로 유지한다.-- 공통 정책 (내 데이터만 보기/쓰기) do $$ declare tbl text; begin -- 필요한 테이블 목록: user_id 컬럼 기준 for tbl in select unnest(array[ 'events_daily', 'events_weekly', 'events_monthly', 'habits', 'notes', 'dashboard_layouts' ]) loop -- 1) 기존 정책 드롭 (있으면 제거) execute format('drop policy if exists "Users can view their own data" on public.%I;', tbl); execute format('drop policy if exists "Users can insert their own data" on public.%I;', tbl); execute format('drop policy if exists "Users can update their own data" on public.%I;', tbl); execute format('drop policy if exists "Users can delete their own data" on public.%I;', tbl); -- 2) 정책 재생성 (내 데이터만 허용) execute format($SQL$ -- SELECT: 내가 만든 데이터만 보기 create policy "Users can view their own data" on public.%1$I for select using (user_id = auth.uid()); -- INSERT: 내 uid인 행만 추가 허용 create policy "Users can insert their own data" on public.%1$I for insert with check (user_id = auth.uid()); -- UPDATE: 내 행만 수정 가능 + 수정 후에도 내 행이어야 함 create policy "Users can update their own data" on public.%1$I for update using (user_id = auth.uid()) with check (user_id = auth.uid()); -- DELETE: 내 행만 삭제 가능 create policy "Users can delete their own data" on public.%1$I for delete using (user_id = auth.uid()); $SQL$, tbl); end loop; end $$;이렇게 하면
events_*,habits,notes,dashboard_layouts
모두 한 번에 동일한 정책이 생성된다.
💬메모
- 이 스크립트는 운영 중 정책을 손댄 뒤 전체 맞춤, 새 테이블 추가, 로컬/스테이징 초기화 같은 상황에서 특히 유용하다.
profiles는 4번 파일을 계속 별도로 관리한다(id = auth.uid()기준).
Run실행 후 "Success. No rows returned"이 출력되면 성공!✅
6. 테스트 (Supabase 환경에서 직접 검증하기)
프론트엔드가 아직 없는 상태라도,
Supabase대시보드 안에서 로그인과 쿼리 실행을 통해
RLS 정책이 실제로 작동하는지 직접 테스트할 수 있다.🧩 ① 테스트 계정 생성
Supabase → Authentication → Users 탭에서
테스트용 계정을 2개 만든다.
예:test_a@example.com,test_b@example.com
🧩 ② SQL Editor에서 쿼리 실행
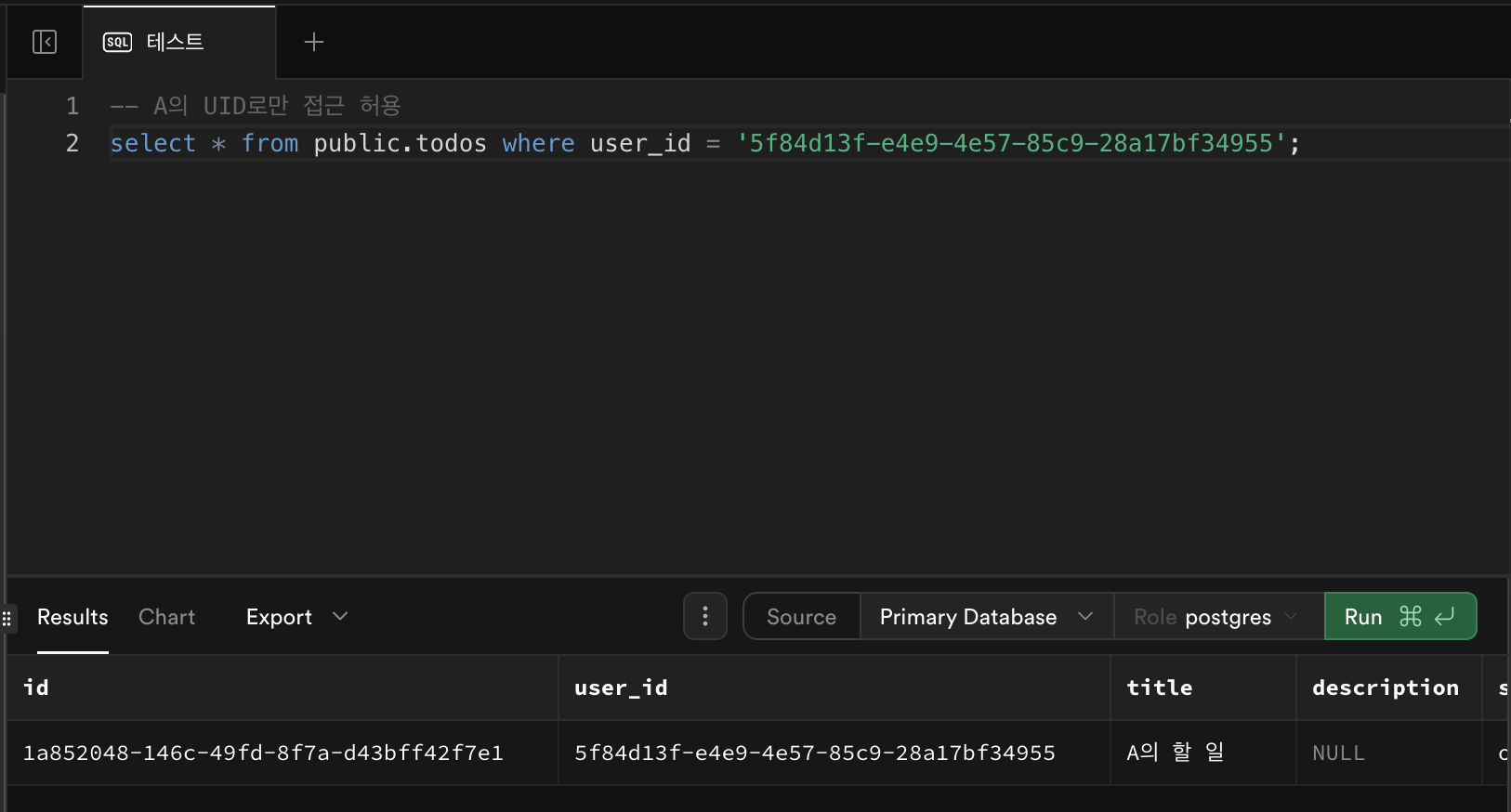
테스트용 UUID를 각각 복사한 뒤, 아래 쿼리 실행
-- A 계정 데이터 삽입 insert into public.todos (user_id, title) values ('<A의 UUID>', 'A의 할 일'); -- B 계정 데이터 삽입 insert into public.todos (user_id, title) values ('<B의 UUID>', 'B의 할 일');🧩 ③ 접근 제한 확인
⚠️ 아래 코드를 넣기 전 위에서 데이터 삽입한
insert코드를 지우고 확인해야한다. (안지우고 하면 데이터가 중복 됨 이 문제에 대해서는 아래에 적어놨음!)-- A의 UID로만 접근 허용 select * from public.todos where user_id = '<A의 UUID>';→ 결과: A의 데이터만 보이고, B의 데이터는 보이지 않으면 ✅ 정상 작동.
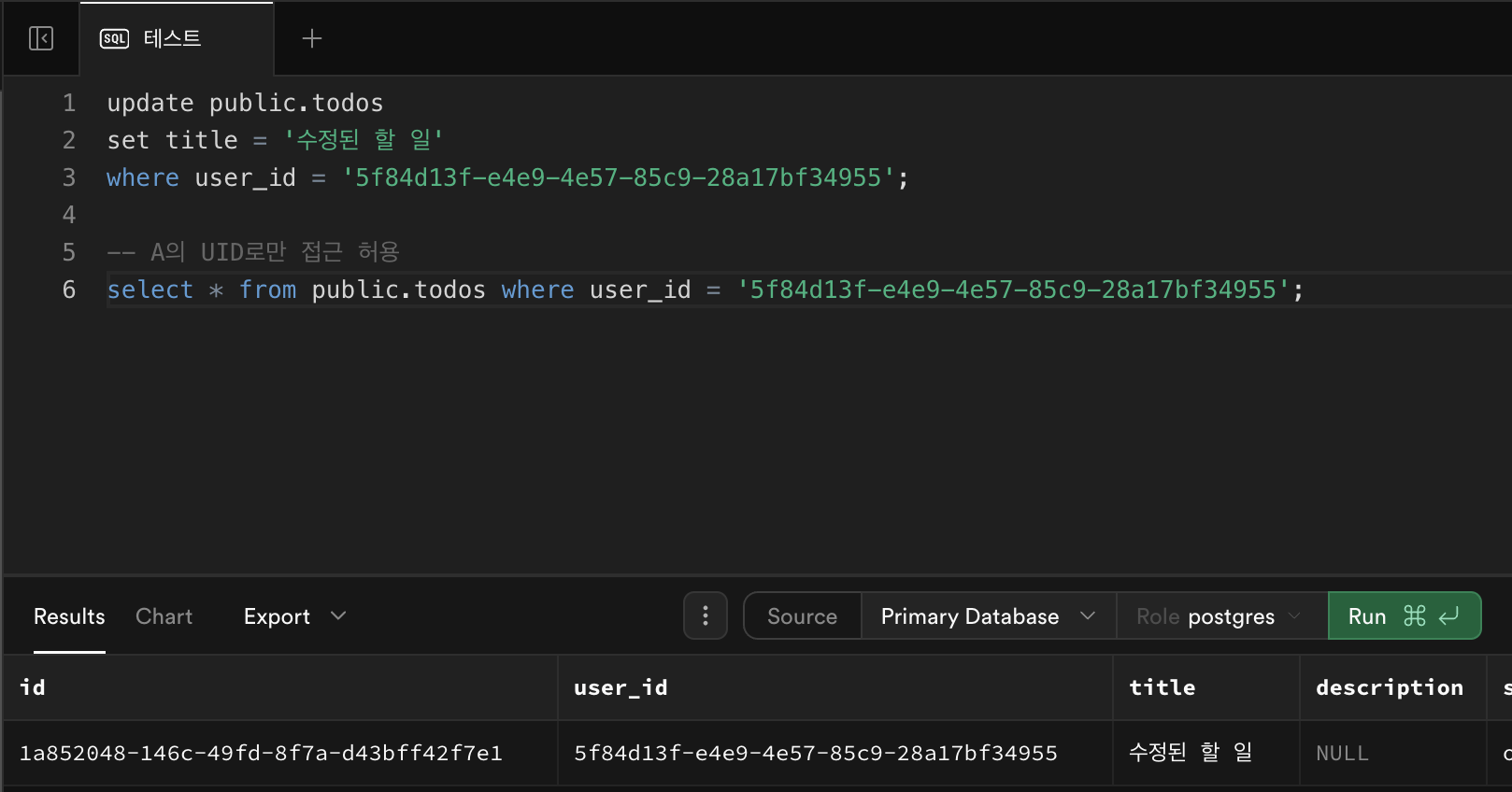
🧩 ④ 수정 테스트
update public.todos set title = '수정된 할 일' where user_id = '<A의 UUID>';→ 에러 없이 정상 수행되면,
RLS 정책이 제대로 적용된 상태다.
💡 Tip
SQL Editor 하단의 Role을
postgres로 두면 모든 데이터가 보이고,
authenticated로 바꾸면 실제 로그인 사용자 권한처럼 테스트할 수 있다.
⚠️ 트러블슈팅 | 같은 쿼리를 두 번 실행했을 때 중복 데이터가 생기는 이유
todos에 “A의 할 일”, “B의 할 일”을 추가했는데
데이터가 두 배로 쌓였다.
RLS 문제도 아닌데, 왜 이런 일이 생겼을까?
1️⃣ 원인: 두 번째 실행에서
INSERT가 한 번 더 실행됨처음에는 이렇게 실행했다.
-- A 계정 데이터 삽입 insert into public.todos (user_id, title) values ('<A_UUID>', 'A의 할 일'); -- B 계정 데이터 삽입 insert into public.todos (user_id, title) values ('<B_UUID>', 'B의 할 일');그런데 다음 실행 때 아래처럼 SELECT를 추가한 뒤, Run을 다시 눌렀다.
-- A 계정 데이터 삽입 insert into public.todos (user_id, title) values ('<A_UUID>', 'A의 할 일'); -- B 계정 데이터 삽입 insert into public.todos (user_id, title) values ('<B_UUID>', 'B의 할 일'); -- A의 UID로만 접근 허용 select * from public.todos where user_id = '<A_UUID>';💡 Supabase SQL Editor에서
Run ▶을 누르면
스크립트 전체가 위에서부터 다시 실행된다.
즉,SELECT만 보이지만 실제로는INSERT두 개가 또 실행된 것이다.
결과적으로todos에 같은 데이터가 한 번 더 쌓였다.
2️⃣ 해결 및 재발 방지: 중복 자체를 막는 인덱스 + 안전 삽입 패턴
이번 문제는
todos에서 발견됐지만, 다른 테이블(notes,habits,events_*,dashboard_layouts등)에서도 동일하게 발생할 수 있다.
각 테이블마다 컬럼 구조(자연스러운 고유키) 가 다르므로, 유니크 인덱스와ON CONFLICT타겟을 해당 컬럼에 맞춰 작성해야 한다.
✅ ① 유니크 인덱스 추가 (DB 차원에서 중복 자체 차단)
새 쿼리파일에서 작성:
7. 중복방지_인덱스.sql-- todos: 같은 user_id + title 조합은 한 번만 허용 create unique index if not exists todos_unique_user_title on public.todos(user_id, title); -- notes: 사용자별 제목 중복 금지 create unique index if not exists notes_unique_user_title on public.notes(user_id, title); -- habits: 사용자별 습관 이름 중복 금지 (name 컬럼 가정) create unique index if not exists habits_unique_user_name on public.habits(user_id, name); -- dashboard_layouts: 사용자별 레이아웃 키 중복 금지 create unique index if not exists dashboard_layouts_unique_user_key on public.dashboard_layouts(user_id, layout_key); -- events_daily: 같은 (날짜, 제목) 중복 금지 (event_date 컬럼 버전) create unique index if not exists events_daily_unique_user_date_title on public.events_daily(user_id, event_date, title); -- events_weekly: 같은 (주, 제목) 중복 금지 (week_start 컬럼 버전) create unique index if not exists events_weekly_unique_user_week_title on public.events_weekly(user_id, week_start, title); -- events_monthly: 같은 (월, 제목) 중복 금지 (month_start 컬럼 버전) create unique index if not exists events_monthly_unique_user_month_title on public.events_monthly(user_id, month_start, title);
Run실행 후 "Success. No rows returned"이 출력되면 성공!✅표현식으로 정규화하고 싶다면(대소문자/공백 무시), 예:
create unique index ... on public.todos(user_id, lower(trim(title)));처럼 표현식 인덱스를 사용하면 된다.
✅ 정리 & 테스트
구분 역할 설명 🔒 유니크 인덱스 DB 차원에서 중복 자체 차단 테이블별 자연키(고유 컬럼 조합) 기준으로 INSERT 거부 💡 한 줄 요약
todos뿐 아니라 전 테이블에 자연키 기반 유니크 인덱스를 걸고,
같은 쿼리를 실수로 다시 실행해도 중복 데이터가 생기지 않는다.
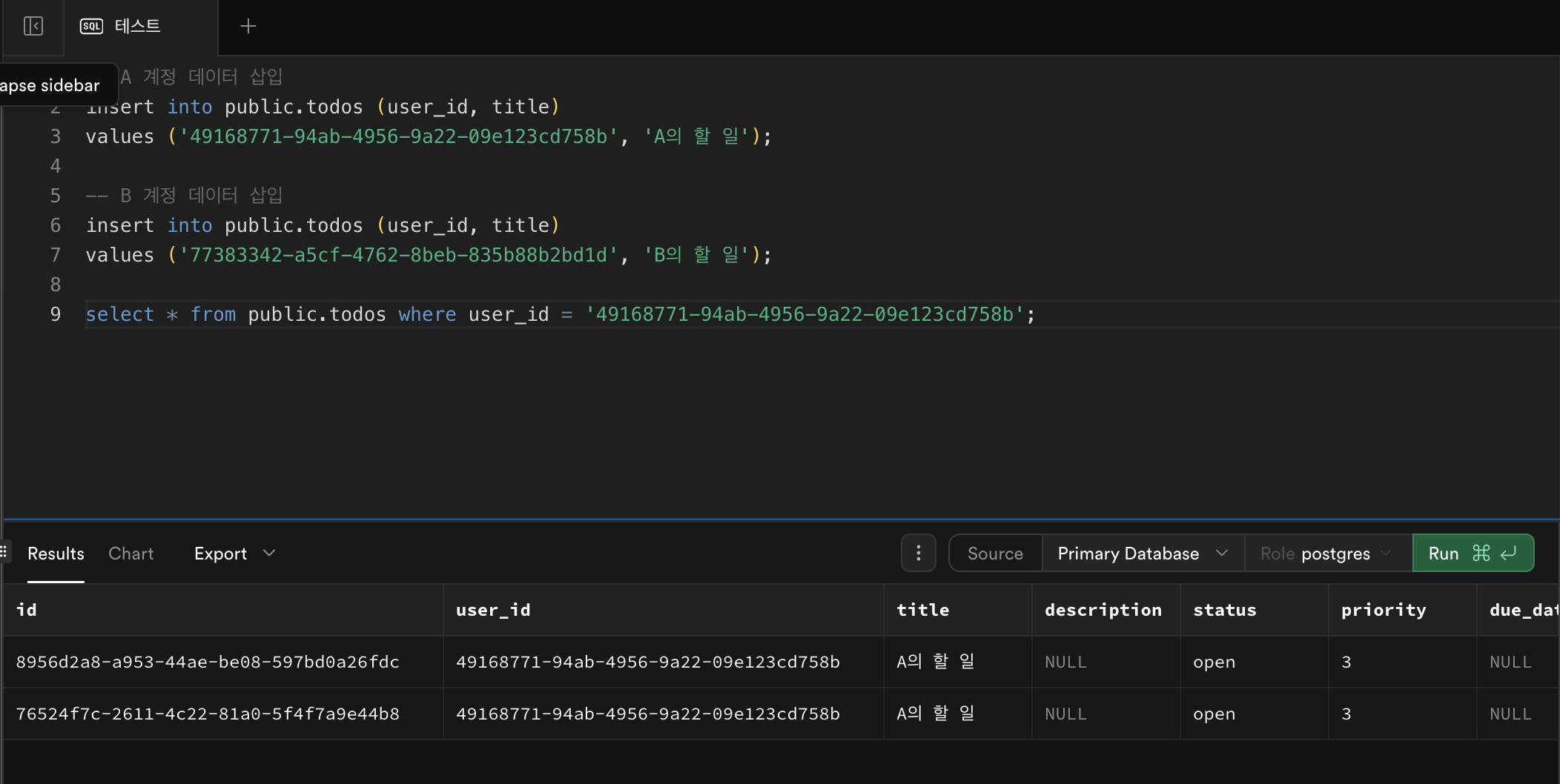
다시 테스트 해보면
현재 테이블을 보면 데이터가 들어가 있는 상태에서 다시insert를 통해 데이터를 집어넣어보았다.
위 사진을 보면 데이터가 중복되었다고 에러를 띄우고 있는 것을 볼 수 있다.
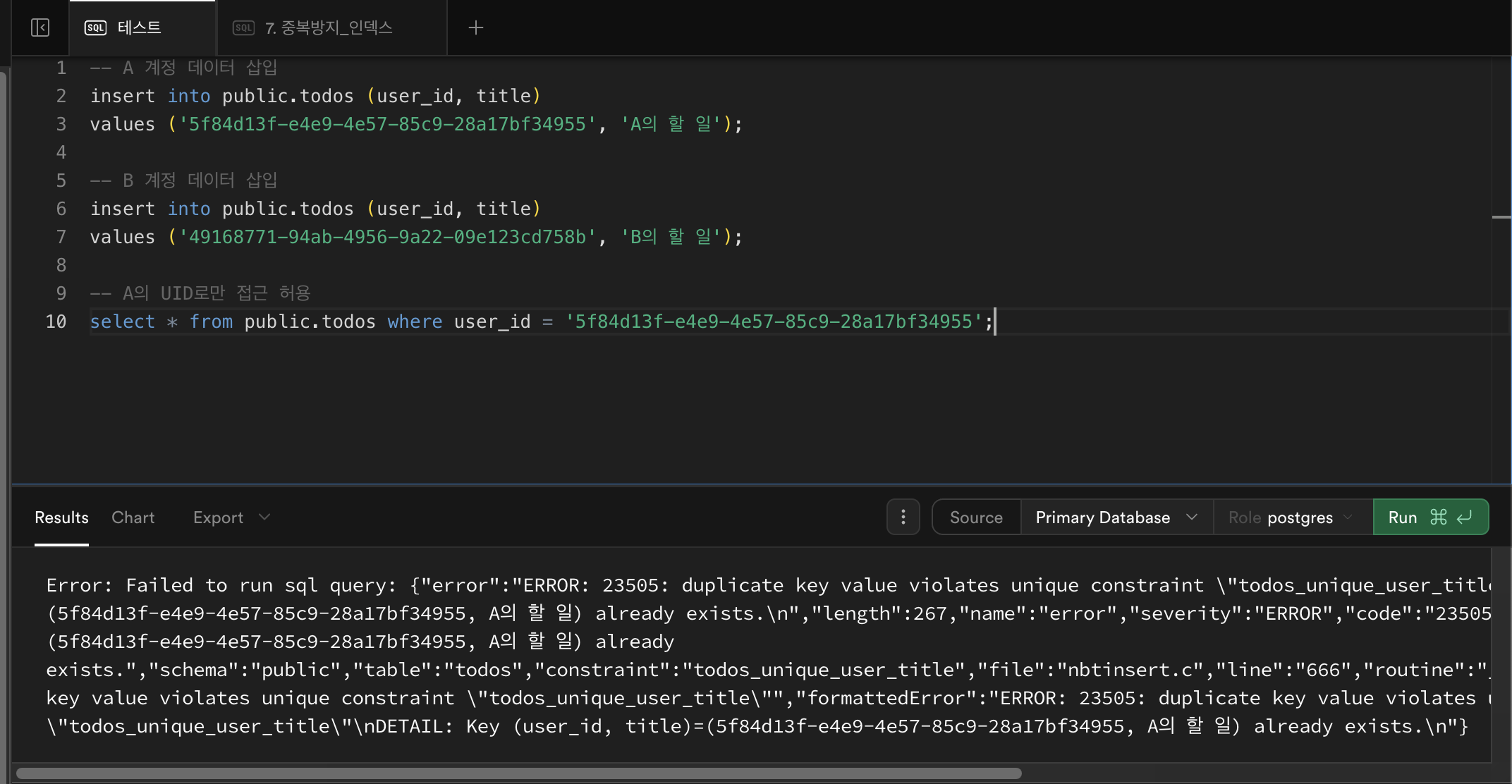
7. RLS 활성화 확인 (SQL로 직접 검증하기)
✅ 1️⃣ 새 쿼리 파일 열기
Supabase 대시보드 → Database → SQL Editor →
+New Query 클릭
아래 쿼리를 붙여넣고 실행한다 👇-- 모든 public 테이블의 RLS 활성화 여부 확인 select tablename, rowsecurity from pg_tables where schemaname = 'public';📊 결과 예시
tablename rowsecurity profiles t todos t habits t notes t events_daily t events_weekly t events_monthly t dashboard_layouts t
🔍
rowsecurity = t면 해당 테이블에 RLS가 “Enabled ✅”로 설정된 상태다.
만약f로 표시되면 아래 명령으로 다시 활성화해야 한다:alter table public.<테이블명> enable row level security;.
💡 참고
- 이 쿼리는 모든 public 테이블의 RLS 설정 상태를 한 번에 점검한다.
- 정책이 존재하더라도
rowsecurity=false이면 실제로는 적용되지 않으므로 반드시t를 확인해야 한다.- 추가로 현재 등록된 정책을 보고 싶다면 아래 쿼리도 함께 실행한다 👇
-- 등록된 정책 목록 확인 select schemaname, tablename, policyname from pg_policies where schemaname = 'public';정책(
policyname)이 표시되고rowsecurity = t인 경우,
RLS 정책이 정상적으로 적용된 상태다 ✅
8. 정리 메모
💬 RLS는 Supabase 보안의 핵심이다.
프런트엔드에서 로그인 검증을 아무리 철저히 해도,
RLS가 없으면 누군가 API 요청으로 다른 사람 데이터를 볼 수도 있다.
RLS 정책은 데이터베이스 내부에서 작동하는 최종 방어막이다.
SQL을 수정하지 않는 한, 그 누구도 이 규칙을 우회할 수 없다. 🔐
✅ 이 단계 완료 기준
- 모든 테이블에
enable row level security실행 완료todos및profiles정책 생성- 다른 테이블에도 일괄 적용 (
do $$블록 실행)- A/B 계정 테스트로 접근 차단 확인
- Table Editor에서 “Enabled ✅” 확인
🧱 중복 데이터 차단하기 (유니크 인덱스)
RLS로 “누가 접근할 수 있는가”를 잠갔다면,
이번 단계는 “같은 데이터가 여러 번 들어가는 사고”를 DB 레벨에서 막는 작업이다.특히
SQL Editor에서 쿼리를 다시 실행하거나, 같은 요청이 여러 번 날아가는 상황이 생기면
의도치 않게 중복 레코드가 계속 쌓일 수 있다.
이걸 애플리케이션 코드에서만 막으려 하면 빈틈이 생기기 때문에,
최종 방어선은 유니크 인덱스(Unique Index) 로 깔아두는 게 안전하다.
1. 유니크 인덱스가 뭐예요?
유니크 인덱스는 특정 컬럼(또는 컬럼 조합)에 대해
- ✅ 동일한 값이 두 번 이상 저장되는 것을 금지하는 제약
을 DB가 강제로 걸어주는 장치다.
즉,
- 실수로 같은
INSERT를 다시 실행하든- 네트워크 재시도 때문에 요청이 중복되든
- 클라이언트에서 중복 방지를 빼먹든
DB는 중복을 허용하지 않고 에러로 차단한다.
2. 실행 위치
Supabase 대시보드 → Database → SQL Editor →
+ New Query
아래 SQL을 그대로 붙여넣고 실행한다.-- profile: email 중복 체크 create unique index if not exists profiles_unique_email_lower on public.profiles (lower(email)); -- todos: 같은 user_id + title 조합은 한 번만 허용 create unique index if not exists todos_unique_user_title on public.todos(user_id, title); -- notes: 사용자별 제목 중복 금지 create unique index if not exists notes_unique_user_title on public.notes(user_id, title); -- habits: 사용자별 습관 이름 중복 금지 (name 컬럼 가정) create unique index if not exists habits_unique_user_name on public.habits(user_id, name); -- dashboard_layouts: 사용자별 레이아웃 키 중복 금지 create unique index if not exists dashboard_layouts_unique_user_key on public.dashboard_layouts(user_id, layout); -- events_daily: 같은 (날짜, 제목) 중복 금지 (event_date 컬럼 버전) create unique index if not exists events_daily_unique_user_date_title on public.events_daily(user_id, title); -- events_weekly: 같은 (주, 제목) 중복 금지 (week_start 컬럼 버전) create unique index if not exists events_weekly_unique_user_week_title on public.events_weekly(user_id, title); -- events_monthly: 같은 (월, 제목) 중복 금지 (month_start 컬럼 버전) create unique index if not exists events_monthly_unique_user_month_title on public.events_monthly(user_id, title);
3. 각 인덱스가 막는 “중복”의 기준
유니크 인덱스는 “이 조합은 유일해야 한다”를 정의한다.
여기서는 테이블별로 아래 기준을 잡았다.✅
profiles_unique_email_lower
- 대상:
public.profiles(lower(email))- 의미: 이메일은 대소문자 차이를 무시하고 유일해야 한다
- 예:
Test@Example.com과test@example.com은 같은 이메일로 취급
✅
todos_unique_user_title
- 대상:
(user_id, title)- 의미: 같은 사용자가 같은 제목의 할 일을 2개 만들 수 없다
✅
notes_unique_user_title
- 대상:
(user_id, title)- 의미: 같은 사용자가 같은 제목의 메모를 2개 만들 수 없다
✅
habits_unique_user_name
- 대상:
(user_id, name)- 의미: 같은 사용자가 같은 이름의 습관을 2개 만들 수 없다
✅
dashboard_layouts_unique_user_key
- 대상:
(user_id, layout)- 의미: 같은 사용자가 같은 레이아웃 키(layout)를 2개 만들 수 없다
✅
events_daily / weekly / monthly의 유니크
- 대상:
(user_id, title)- 의미: 같은 사용자가 같은 제목의 일정을 중복 생성할 수 없다
여기서는 날짜 컬럼까지 묶지 않고title기준으로만 막는 버전이다.
즉, “같은 제목은 한 번만”이라는 정책을 선택한 셈이다.
4. 정상 동작 확인 방법
1) 인덱스 생성 여부 확인
select tablename, indexname, indexdef from pg_indexes where schemaname = 'public' order by tablename, indexname;.
2) 중복 삽입 시도해서 에러 확인
예를 들어
todos에서 같은(user_id, title)로 두 번 넣으면
두 번째INSERT는 에러로 막혀야 한다.insert into public.todos (user_id, title) values ('<USER_UUID>', '중복 테스트'); insert into public.todos (user_id, title) values ('<USER_UUID>', '중복 테스트'); -- 여기서 에러가 나야 정상
5. 주의 사항
- 이미 테이블 안에 중복 데이터가 존재하면,
유니크 인덱스 생성 자체가 실패할 수 있다.layout,name,title같은 컬럼명은 테이블 정의와 정확히 일치해야 한다.
(컬럼명이 다르면 인덱스 생성이 바로 실패한다)
⚡️ 빨라지게 하기 (기본 인덱스 설정)
RLS 정책으로 보안 잠금은 끝났다.
이제는 속도를 올릴 차례다.
데이터가 많아질수록 조회 속도가 느려지기 시작하므로,
자주 조회되는 컬럼에 인덱스를 걸어 검색을 빠르게 만든다.
1. 인덱스(Index)란?
인덱스는 데이터베이스가 테이블을 빠르게 탐색하기 위해 만들어 두는 색인표(index table) 다.
쉽게 말해, 도서관의 책 찾기 카드나 책의 ‘찾아보기’ 와 같은 개념이다.
🔍 왜 필요한가
데이터베이스는 기본적으로 테이블을 위에서부터 한 줄씩 훑어가며(Sequential Scan) 조건에 맞는 값을 찾는다.
데이터가 수십·수백만 건이 되면, 이 방식은 너무 느리다.
그래서 자주 검색하는 컬럼(user_id,created_at,title등)에 색인을 따로 저장해두고,
그 색인을 통해 “필요한 데이터가 어느 위치에 있는지”를 직접 점프(Seek) 하게 만든다.
예를 들어,
todos테이블에서user_id = 'abcd-1234'인 데이터를 찾으려면
원래는 모든 행을 검사해야 하지만,
user_id컬럼에 인덱스가 있으면 색인표를 통해
“이 UID는 1032번째 블록에 있다”를 바로 찾아간다.그 결과, 조회 속도는 수십~수백 배 빨라지고,
정렬(ORDER BY)이나 필터링(WHERE)도 훨씬 효율적으로 처리된다.
2. 실행 위치
Supabase 대시보드 → Database → SQL Editor →
+ New Query
아래 각 블록(3(todos인덱스) ~ 10(FK왜래키))을 붙여넣고Run ▶실행한다.
모두 끝나면8. 기본 인덱스등의 이름으로 저장해 둔다.
Run실행 후 "Success. No rows returned"이 출력되면 성공!✅
3. todos 인덱스 만들기 (내 할 일 목록 빠르게)
-- 내 데이터 필터용 create index if not exists idx_todos_user_id on public.todos(user_id); -- 마감일 정렬/필터용 create index if not exists idx_todos_due_date on public.todos(due_date);💡 효과
- 내 할 일 목록 로딩이 훨씬 빨라진다.
예를 들어SELECT * FROM todos WHERE user_id = '...'같은 쿼리가
인덱스를 통해 필요한 데이터 위치로 바로 접근한다.- 마감일순 정렬도 빠르게 작동한다.
ORDER BY due_date ASC조건으로 리스트를 불러올 때
이미 인덱스가 정렬된 상태라 별도 정렬 연산이 거의 필요 없다.- 현재는 기본 필터(
user_id,due_date) 중심으로 최소 구성만 추가했다.
이후 “완료된 할 일만 보기”나 “중요도별 정렬” 같은 기능이 생기면
쿼리 패턴에 맞게 새로운 인덱스(예:is_done,priority)를 추가할 수 있다.
4. events_daily 인덱스 만들기 (일간 일정 빠르게)
-- 내 일정 + 시작시각 기준 조회 create index if not exists idx_events_daily_user_start on public.events_daily(user_id, start_ts);💡 효과
- ‘오늘 일정’이나 ‘특정 기간 일정 보기’ 속도가 개선된다.
예:이런 쿼리는SELECT * FROM events_daily WHERE user_id = '...' AND start_ts BETWEEN '2025-10-10' AND '2025-10-12';user_id + start_ts인덱스로 바로 범위 스캔이 가능하다.- 즉, 매일·주간 뷰에서 특정 날짜 범위를 불러올 때
필요한 행만 빠르게 읽어오며 전체 테이블을 훑지 않는다.
- 현재는
start_ts기준으로 설계했지만,
나중에 화면에서 “종료 시각(end_ts)”으로 필터하거나
“태그·카테고리별 일정 보기” 같은 기능이 추가되면
해당 쿼리 패턴에 맞춰 인덱스를 보강할 수 있다.
5. events_weekly 인덱스 만들기 (주간 일정 빠르게)
-- 내 일정 + 주 시작일 + 요일 create index if not exists idx_events_weekly_user_week_day on public.events_weekly(user_id, week_start, day_of_week);💡 효과
- 캘린더 주간 화면에서 렌더링이 훨씬 가벼워진다.
예를 들어이번 주(week_start=2025-10-06)일정을 불러올 때,
인덱스가 주차별로 정렬되어 있어 빠르게 해당 주간만 스캔한다.- 요일별 탭(월~일)을 전환할 때도 인덱스 덕분에
각 요일 데이터만 바로 찾아서 보여준다.
- 현재는 주/요일 기준으로 최소 구성만 포함했다.
향후 “카테고리별 주간 일정”, “참여자 기반 필터” 같은 기능이 추가되면
실제 쿼리 사용 패턴에 따라 인덱스 구조를 변경할 수 있다.
6. events_monthly 인덱스 만들기 (월간 일정 빠르게)
-- 내 일정 + 년/월/일 create index if not exists idx_events_monthly_user_ymd on public.events_monthly(user_id, year, month, day);💡 효과
- 달력 형태로 월간 일정을 조회할 때 매우 유용하다.
예:이런 쿼리에서 인덱스가SELECT * FROM events_monthly WHERE user_id = '...' AND year = 2025 AND month = 10;(user_id, year, month)순으로 정렬되어 있으므로
특정 월만 빠르게 필터링할 수 있다.- 월간 캘린더를 렌더링할 때, 전체 데이터를 불러오지 않고
필요한 월 범위만 읽기 때문에 렌더링 지연이 줄어든다.
- 이후 일정 필터(예: “공휴일 제외”, “프로젝트별 일정”) 등이 생기면
필요한 컬럼을 조합한 복합 인덱스로 수정할 수 있다.
7. habits 인덱스 만들기 (습관 목록 빠르게)
-- 내 습관 목록 조회 속도 향상 create index if not exists idx_habits_user_id on public.habits(user_id); -- (선택) 빈도별 조회 빠르게 하고 싶을 때 create index if not exists idx_habits_user_frequency on public.habits(user_id, frequency);💡 효과
- ‘내 습관 리스트’ 불러오기가 빠르게 작동한다.
예:인덱스가 없으면 모든 사용자 데이터를 스캔하지만,SELECT * FROM habits WHERE user_id = '...';
인덱스가 있으면 내 습관 행만 바로 찾는다.- ‘빈도별 보기(매일/매주)’ 기능이 생길 경우
(user_id, frequency)인덱스가 그 필터에 맞춰 빠르게 작동한다.
- 현재는 사용자·빈도 중심으로 기본 인덱스만 적용했다.
이후 “성공률 순 정렬”이나 “기간별 필터” 기능이 추가되면
새로운 쿼리 패턴에 맞게 인덱스를 확장하면 된다.
8. notes 인덱스 만들기 (메모/태그 검색 빠르게)
-- 내 메모 필터 create index if not exists idx_notes_user_id on public.notes(user_id); -- 태그 배열 검색 빠르게 (태그를 쓰는 경우에만 권장) create index if not exists idx_notes_tags_gin on public.notes using gin (tags);💡 효과
- 내 메모 목록 로딩이 즉시 이뤄진다.
WHERE user_id = '...'조건으로 불러올 때 인덱스 덕분에 전체 스캔이 사라진다.- 태그 검색 속도 향상 — GIN 인덱스는 배열 검색(
@>,&&)에 최적화되어 있다.
예:이때 인덱스를 사용하면 수천 건 중에서도 ‘work’ 태그만 바로 조회 가능하다.SELECT * FROM notes WHERE tags @> ARRAY['work'];
- 현재는
user_id와tags중심으로 최소 구성을 유지하고 있다.
추후 “제목 검색”, “내용 검색” 기능이 생기면
title또는content컬럼 기반의 GIN/Full Text 인덱스로 확장할 수 있다.
9. dashboard_layouts 인덱스 + 부분 유니크 (유저당 활성 1개)
-- 소유자/활성 여부로 빠르게 찾기 create index if not exists idx_dashboard_user_active on public.dashboard_layouts(user_id, is_active); -- 유저당 is_active=true는 1개만 허용 (부분 유니크) create unique index if not exists uniq_dashboard_active_per_user on public.dashboard_layouts(user_id) where is_active = true;💡 효과
- 현재 로그인한 사용자의 활성 레이아웃을 빠르게 찾을 수 있다.
예:이런 쿼리가 바로 인덱스로 연결돼 즉시 결과를 반환한다.SELECT * FROM dashboard_layouts WHERE user_id = '...' AND is_active = true;- 또한 유저당 활성 레이아웃은 1개만 허용되므로,
is_active=true상태로 두 번째 레이아웃을 만들면 자동으로 에러로 막힌다.
→ UX와 데이터 무결성을 동시에 보장.
- 현재는
user_id+is_active기준으로 최소 구성했지만,
이후 “레이아웃 이름 검색”이나 “생성일 정렬” 기능이 추가되면
해당 컬럼 조합으로 복합 인덱스를 새로 설계할 수 있다.
10. FK(외래키) 확인 및 보강 (무결성 유지)
FK(외래키)란?
한 테이블의 컬럼이 다른 테이블의 기본키(PK) 를 참조하도록 만드는 무결성 규칙이다.
우리 프로젝트에선 각 데이터(todos,notes, …)의user_id가auth.users(id)에 실제로 존재하는 사용자여야 한다는 것을 DB 차원에서 강제한다.
왜 필요한가
- ❌ 잘못된
user_id(없는 사용자)로 데이터가 들어가는 것을 사전에 차단- 👤 사용자가 삭제되면(
auth.users), 해당 사용자의 레코드를 자동으로 정리(ON DELETE CASCADE)- 🧹 “고아 레코드(주인 없는 데이터)” 방지 → 데이터 일관성 유지
-- 전체 테이블에 FK(user_id -> auth.users.id) + user_id 인덱스 일괄 적용 do $$ declare tbl text; con_name text; begin for tbl in select unnest(array[ 'todos', 'habits', 'notes', 'dashboard_layouts', 'events_daily', 'events_weekly', 'events_monthly' ]) loop con_name := format('fk_%s_user', tbl); -- 기존 FK 있으면 제거(재실행 안전) execute format( 'alter table public.%I drop constraint if exists %I;', tbl, con_name ); -- FK 추가 execute format( 'alter table public.%I add constraint %I foreign key (user_id) references auth.users(id) on delete cascade;', tbl, con_name ); -- 외래키 컬럼 인덱스(자동 생성 안 됨) execute format( 'create index if not exists %I on public.%I(user_id);', format('idx_%s_user_id', tbl), tbl ); end loop; end $$;같은 패턴으로
events_*,habits,notes,dashboard_layouts도 적용 가능하다.
💡 효과
유저 삭제 시 관련 데이터 자동 정리.
예:auth.users에서 사용자가 삭제되면 해당 사용자의todos/habits/notes/...가 함께 삭제된다.데이터 무결성을 유지하면서 수동 정리 작업이 필요 없어 운영이 단순해진다.
주의배열에 포함된 테이블에는
user_id uuid not null컬럼이 있어야 한다.운영 대용량 DB는 비피크 시간에 실행 권장. (필요시
NOT VALID→VALIDATE전략으로 잠금 영향 완화 가능)
11. 점검하기 (효과 확인)
Supabase 대시보드 → Database → SQL Editor →
+ New Query
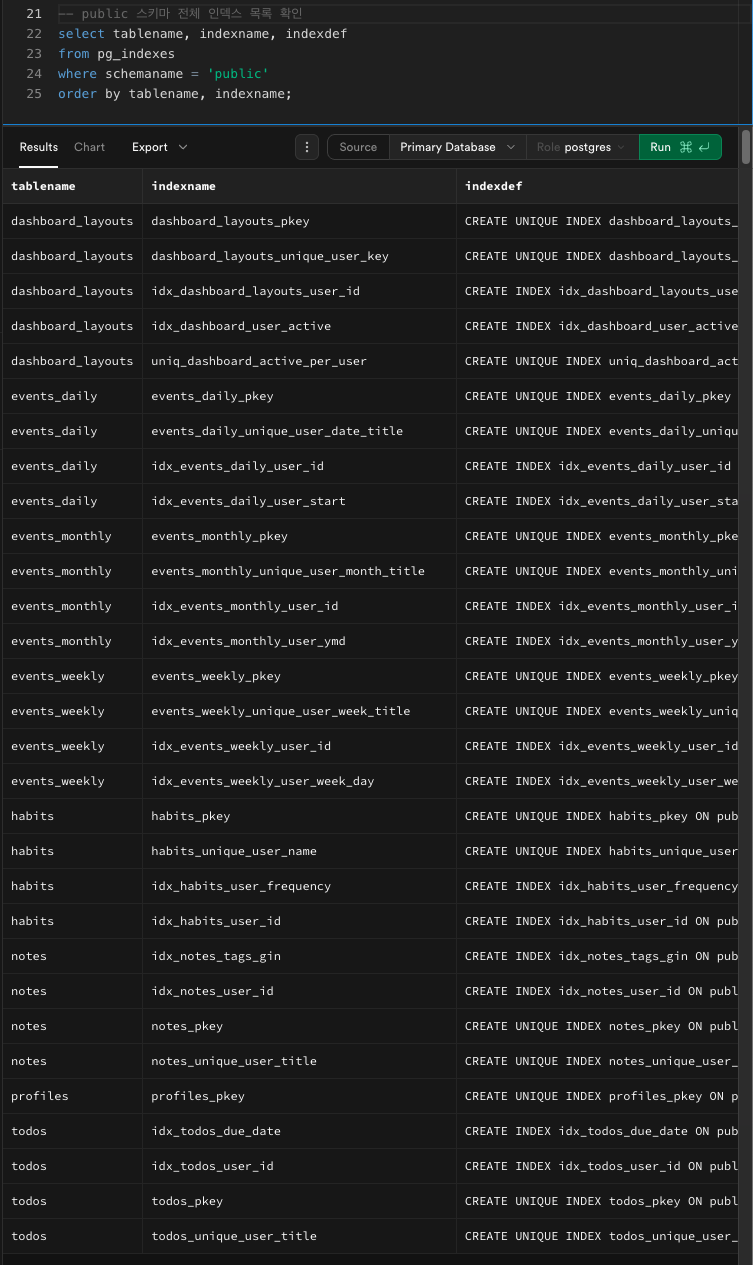
아래 쿼리를 실행해 인덱스가 정상 생성됐는지 확인한다. ✅-- public 스키마 전체 인덱스 목록 확인 select tablename, indexname, indexdef from pg_indexes where schemaname = 'public' order by tablename, indexname;인덱스 이름(
idx_...)과 정의(CREATE INDEX ...)가 표시되면 정상 적용된 상태다.
각 테이블별로 확인하려면where tablename = 'todos';처럼 조건을 추가하면 된다.
💡 테스트 방법
- 같은 조건으로 리스트를 여러 번 불러본다 — 첫 로딩보다 이후가 확실히 빨라지면 성공.
dashboard_layouts에서is_active = true인 행을 2개 이상 추가해 본다 →
에러 발생 시 정상 동작! (부분 유니크 제약이 작동 중)
모든 테이블에
idx_<테이블명>_user_id인덱스와
기능별 인덱스(due_date,start_ts,frequency,tags등)가 함께 표시된다면 성공이다.
dashboard_layouts의uniq_dashboard_active_per_user(부분 유니크)도 보이면 완벽히 적용된 상태다. ✅
12. 성능 팁 (필요할 때만 추가)
지금 만든 인덱스는 필수 최소 세트다.
나중에 특정 화면이 느려지면,
그 화면에서 실제로 사용하는WHERE/ORDER BY컬럼에만 추가 인덱스를 1개씩 더 만든다.
⚠️ 인덱스가 많아질수록
INSERT/UPDATE시점에는 오히려 느려질 수 있다.
균형이 중요하다.
“자주 읽는 컬럼에만 만든다.” 이것만 기억하면된다!
✅ 이 단계 완료 기준
- 주요 테이블별 인덱스 생성 완료
dashboard_layouts의 부분 유니크 제약 동작 확인- FK 누락 컬럼 점검 완료
- Table Editor에서 인덱스 목록 확인
⚙️ 빠른 점검 (내가 제대로 했는지)
RLS, 트리거, 인덱스, FK를 모두 설정했다면
이제 실제로 데이터가 잘 움직이는지 직접 점검할 차례다.
특히CRUD(추가·조회·수정·삭제)와 FK(외래키)연결은
기능이 모두 정상 작동하는지 확인하는 가장 기본적인 단계다.
2. CRUD 테스트 (데이터 추가/조회/수정/삭제 확인)
“데이터가 실제로 추가·조회·수정·삭제되는가?”
그리고 “로그인한 사용자 본인의 데이터만 보이는가?”
이 두 가지를 동시에 검증한다.
🧩
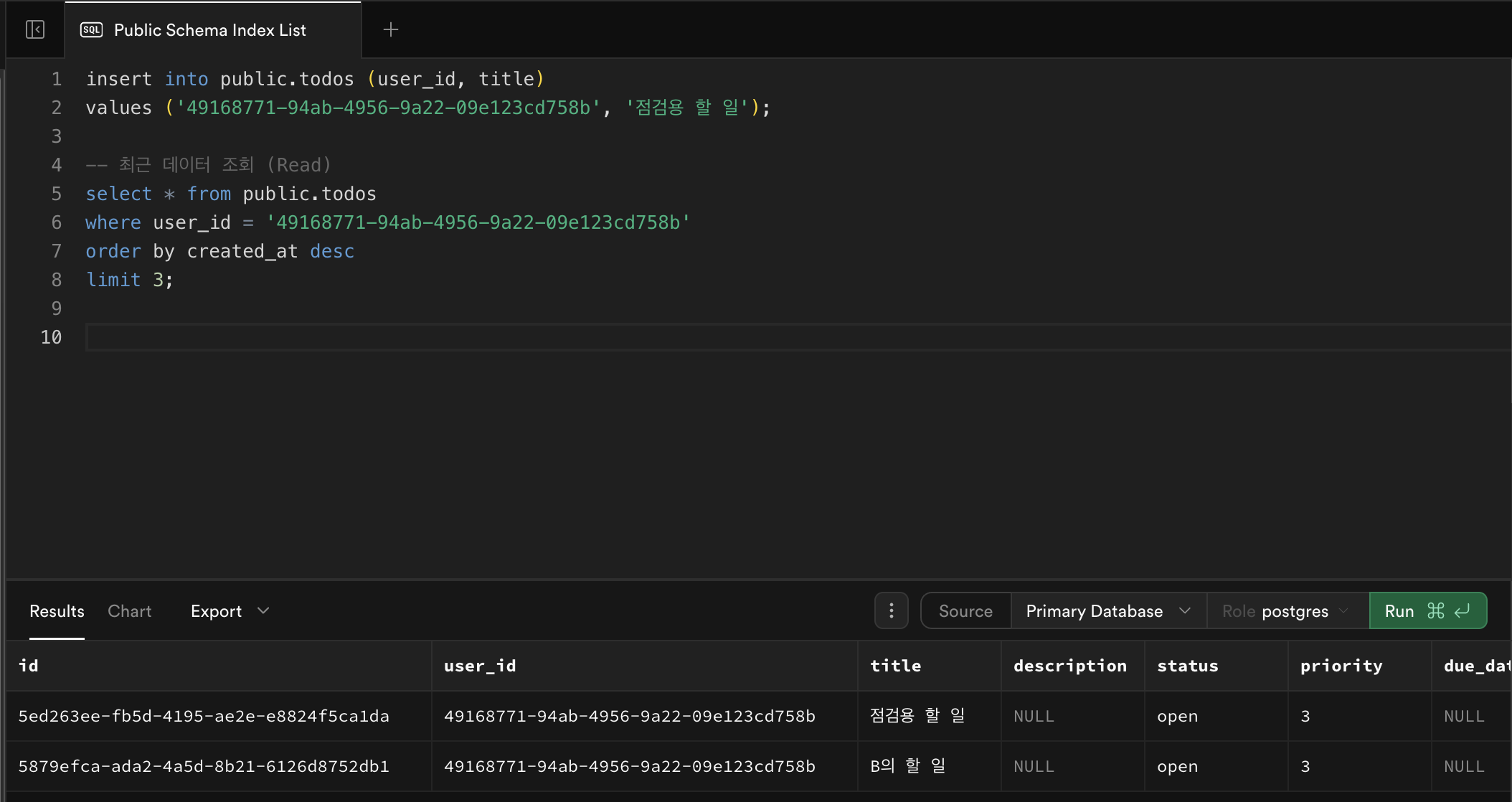
todos테스트-- 이메일로 UUID 조회 select id from auth.users where email = 'new@example.com';👉 결과의
id값을 복사:<TEST_USER_UUID>
-- 할 일 추가 (Create) insert into public.todos (user_id, title) values ('<TEST_USER_UUID>', '점검용 할 일'); -- 최근 데이터 조회 (Read) select * from public.todos where user_id = '<TEST_USER_UUID>' order by created_at desc limit 3;🔍 결과: 새로 추가한
'점검용 할 일'이 보이면 정상.
다른 계정으로 로그인했을 때는 이 데이터가 보이지 않아야 한다.
즉, RLS 정책이 잘 작동 중인 상태다 ✅
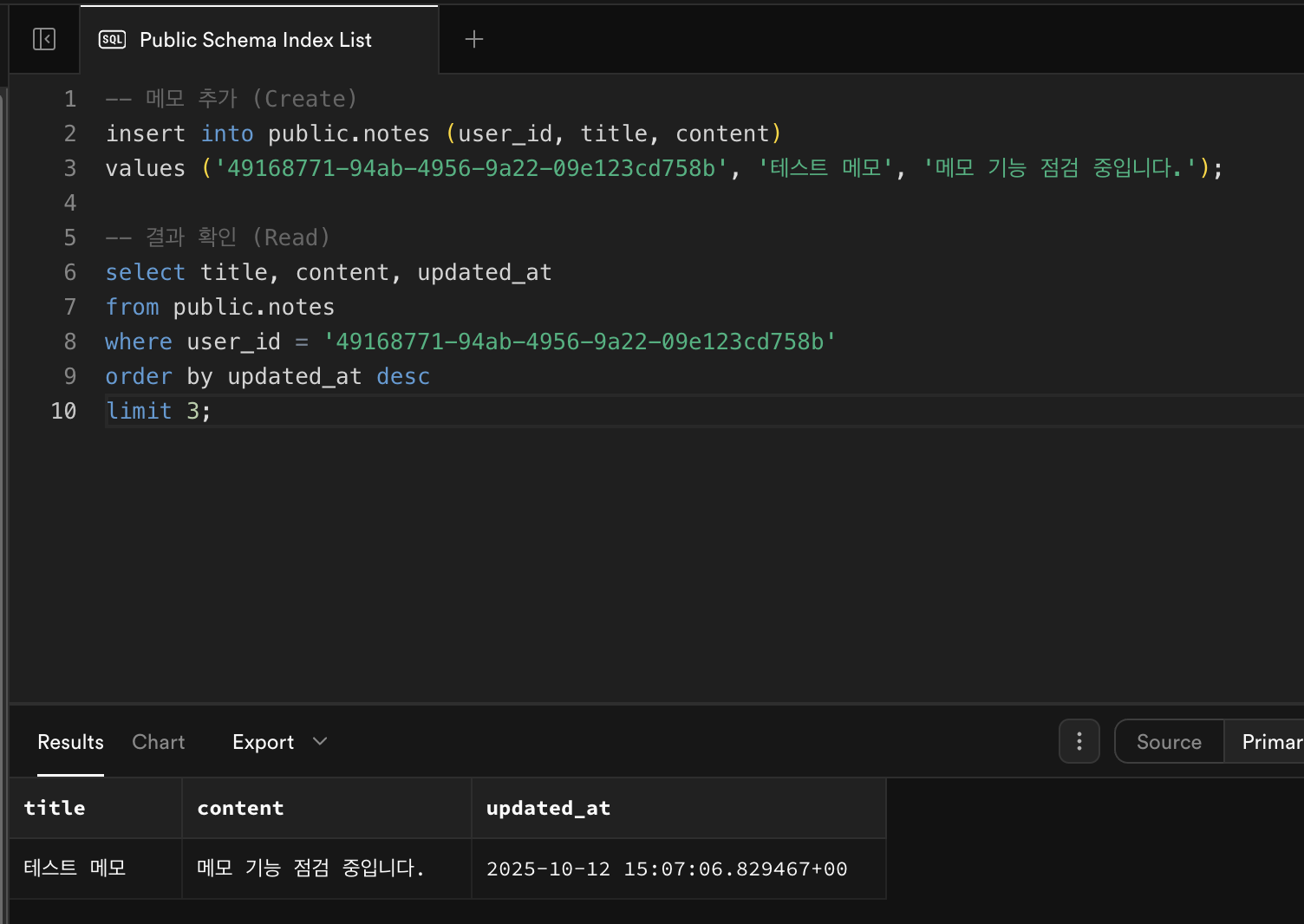
🧩
notes테스트-- 메모 추가 (Create) insert into public.notes (user_id, title, content) values ('<TEST_USER_UUID>', '테스트 메모', '메모 기능 점검 중입니다.'); -- 결과 확인 (Read) select title, content, updated_at from public.notes where user_id = '<TEST_USER_UUID>' order by updated_at desc limit 3;🔍 결과
content값이‘메모 기능 점검 중입니다,’라고 나와야함
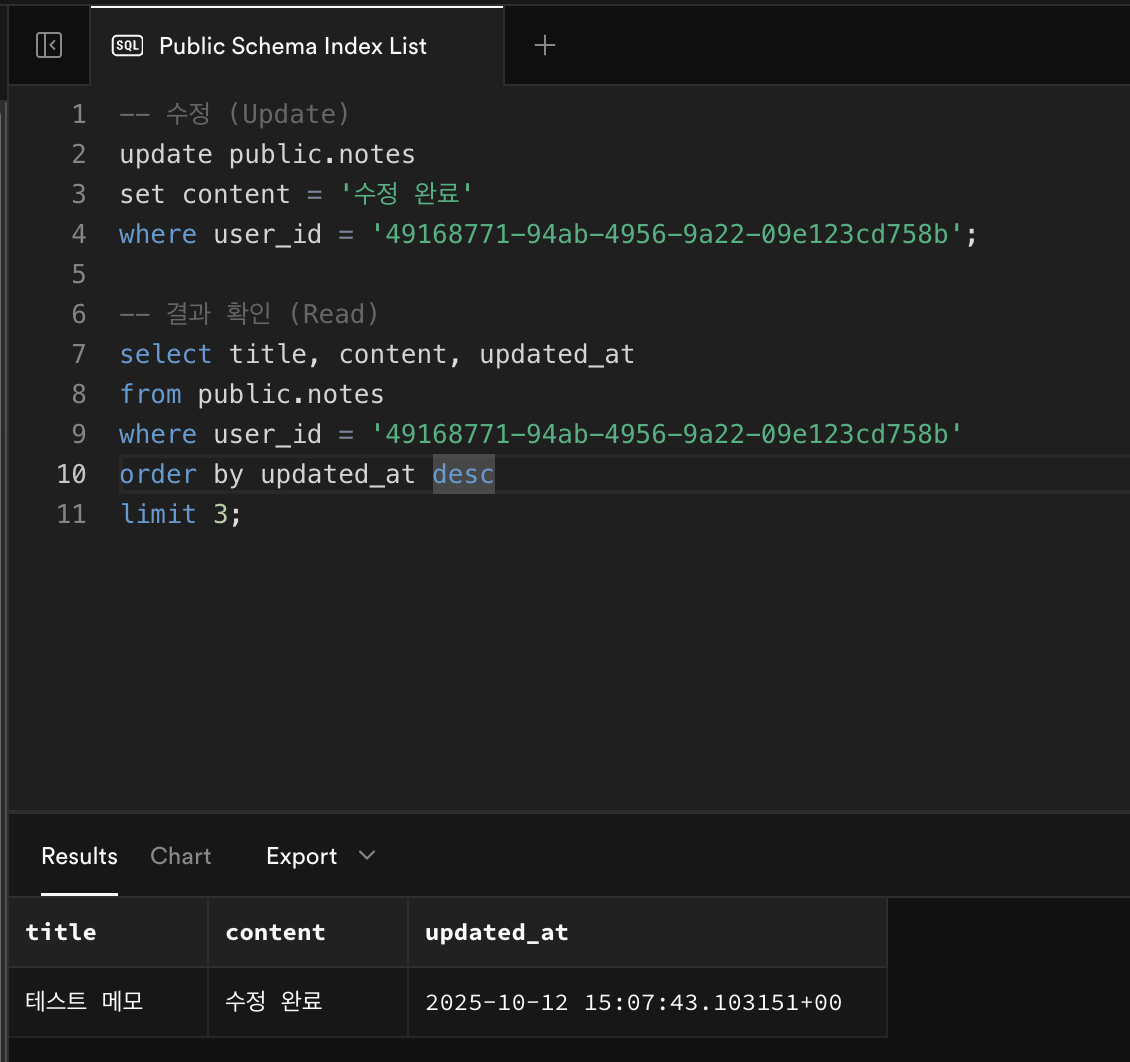
-- 수정 (Update) update public.notes set content = '수정 완료' where user_id = '<TEST_USER_UUID>'; -- 결과 확인 (Read) select title, content, updated_at from public.notes where user_id = '<TEST_USER_UUID>' order by updated_at desc limit 3;🔍 결과
content값이‘수정 완료’로 바뀌어야 함updated_at이 현재 시간으로 자동 변경되면 정상 ✅
(앞서 만든set_updated_at()트리거가 잘 작동 중이라는 뜻)
💡 삭제(Delete) 테스트
원하면 아래 쿼리로 데이터 삭제까지 점검할 수 있다.
delete from public.todos where user_id = '<TEST_USER_UUID>';실행 후 다시 조회했을 때 데이터가 사라지면 CRUD 전체가 정상 작동이다. ✅
9-6. FK(외래키) 동작 확인 (유저 삭제 시 연동)
FK(외래키)는 한 테이블의 컬럼이
다른 테이블의 기본키(PK)를 참조하도록 강제하는 제약 조건이다.
우리 프로젝트에선 각 데이터(todos,notes,habits등)의
user_id가 실제auth.users(id)를 참조하도록 연결되어 있다.
🔎 왜 필요한가
- 잘못된
user_id(존재하지 않는 사용자)의 데이터가 들어가는 것을 DB 차원에서 차단auth.users에서 사용자를 삭제하면
연결된 데이터가 자동으로 함께 삭제(on delete cascade)- “고아 데이터(주인 없는 레코드)”가 남지 않도록 데이터 일관성 유지
🧩 테스트 방법
- Supabase → Authentication → Users
테스트용 계정을 선택하고 Delete user 실행- SQL Editor에서 아래 쿼리 실행:
select * from public.todos where user_id = '<삭제한 유저의 UUID>';- 결과가 비어 있으면 정상 ✅
💡 결과 해석
auth.users의 유저가 삭제되면,
해당 사용자의todos,notes,habits,events_*,dashboard_layouts데이터가
자동으로 함께 삭제된다.
즉, FK의on delete cascade옵션이 정상 동작 중이다. 🔄