Index란?
데이터를 빠르게 탐색하기 위해 사용한다. 특정 컬럼에 대해 값을 정렬하고 이를 통해 빠르게 데이터를 찾을 수 있도록 도와준다.
- 단점
- 인덱스도 데이터기 때문에 저장하기 위해 별도의 저장 공간 필요
- CUD가 빈번한 테이블에 인덱스를 걸게 되면 데이터 변경 시 인덱스도 함께 수정되야 하기 때문에 성능 저하가 발생한다. => 수정이 아닌 삭제 및 재등록
DB Btree Index가 범위 검색이 빠른 이유는?
- 정렬된 순서를 유지하기 때문에 한번 찾은 값 다음 값이 동일한 경로 혹은 인접한 노드에 존재하므로 범위 검색에 효율적
- B+Tree에서는 모든 데이터가 리프 노드에 저장 되어 있고 리프 노드는 연결 리스트 형태로 연결 되어 있기 때문에 링크 통해 이동하며 빠르게 범위 검색을 할 수 있다.
동작방식
- 인덱스는 Btree 자료 구조로 저장되며
- Btree에서 데이터를 저장하는 곳을 노드 라고 합니다.
- 노드는 최상단에 있는 루트노드, (브랜치 노드), 리프 노드로 구성 되며 MySQL 에서는 이 노드를 페이지라고 합니다.
- 인덱스는 페이지 단위(8kbyte)로 저장되며 인덱스 키를 기준으로 정렬 됩니다.
- 따라서 인덱스 탐색 시 루트노드부터 시작하여 찾으려는 값과 키를 비교하여 작다면 왼쪽으로, 크다면 오른쪽으로 이동합니다.
- 이 과정을 거쳐 브랜치 노드에서 리프 노드에 도달하고
- 리프노드에 있는 인덱스 키와 pk 쌍을 사용하여 데이터 영역에서 실제 레코드에 접근하게 됩니다.
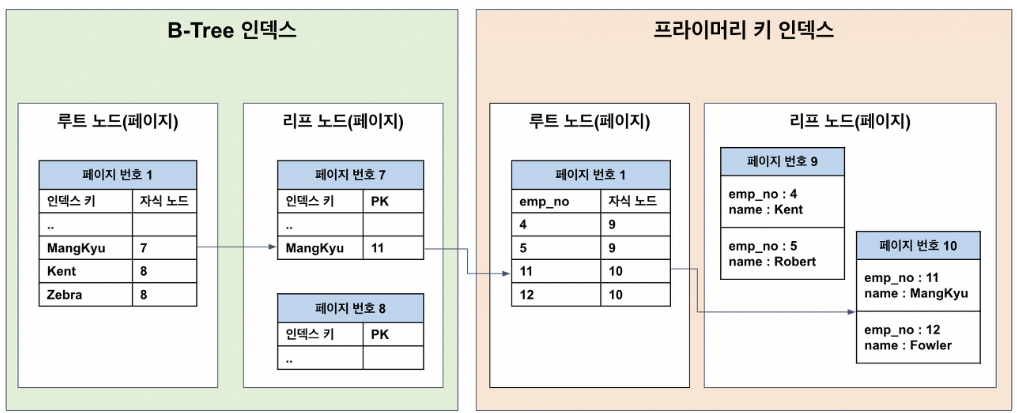
Cluster Index
- 테이블 당 하나의 클러스터 인덱스만 존재
- 보통 PK가 클러스터 인덱스가 된다 ( PK가 없다면 not null Unique index 중 첫번째→ Unique index 없다면 임의로 유니크한 값을 생성하여 사용)
- 클러스터 인덱스 순서로 실제 데이터가 정렬된다
- 인덱스의 리프 페이지가 곧 데이터 이기 때문에 논 클러스터 인덱스 보다 용량을 적게 사용함
어떤 값을 PK로 만들어야 할까요?
- 인덱스 영역에 PK를 저장하고 있으므로 PK의 크기가 너무 크지 않은 것이 좋다
- PK를 기준으로 실제 데이터가 정렬 되기 때문에 계속 증가하는 값으로 생성하는 것이 좋다
- 그렇지 않으면 중간에 PK가 추가되면 데이터를 다시 정렬되어야 하기 때문에 성능 오버헤드가 발생한다.
- 변하지 않는 값으로 설정하는 것이 중요하다.
- PK는 레코드의 물리적인 저장 위치를 결정한다.
- 따라서 PK가 변경되면 단순 값을 변경하는 것이 아니라 레코드가 저장된 위치도 변경 되어야 하기 때문에 레코드를 삭제하고 다시 저장해야한다.
- 따라서 두번의 디스크 I/O가 발생하기 때문에 비용이 상당히 크다.
- 따라서 PK는 변하지 않는 값으로 설정하는 것이 중요하다.
- PK를 만들지 않아도 알아서 내부 PK를 생성해주는데 굳이 PK를 생성하는 이유는?(⭐️)
=> 내부 PK는 사용자에게 노출 되지 않기 때문에 쿼리에 사용할 수 없다. 클러스터 인덱스는 테이블당 하나만 가질 수 있고 빠르게 데이터에 접근할 수있기 때문에 활용할 수 있도록 PK를 생성하는 것이 좋다.
- 참고할만한 ref:

.