코딩테스트 대비
1.[알고리즘] 시간 복잡도 in 코테

시간복잡도는 알고리즘을 선택하는 기준을 세울 수 있다!ex) 데이터 셋 크기 n=1,000,000 일때 이를 오름차순으로 정렬해라(2초) 문제 시간 2초 => 1초에 1억번 정도의 연산이 가능함으로, 2억번이하의 연산을 통해 해결해야함버블 정렬의 시간 복잡도 => n\
2.[알고리즘] 버블 정렬
정의: 인접한 두 개를 비교하여 정렬하는 방식 시간 복잡도가 n\*n으로 크지만 로직이 단순하다.정렬 과정1\. 비교 연산이 필요한 루프 범위를 설정한다.2\. 인접한 데이터 값을 비교한다3\. swap 조건에 부합하면 swap 연산 수행4\. 루프 범위가 끝날 때까지
3.[자료구조] 배열과 리스트
메모리의 연속 공간에 값이 채워져 있는 형태의 자료구조인덱스를 통해 참조할 수 있고, 선언한 자료형의 값만 저장 가능새로운 값을 "중간"에 삽입하거나, 특정 인덱스 값 없앤 후 땡기기 어려움 (나머지 모든 값을 하나씩 밀거나 땡겨야함)크기를 선언할 때 지정하기에 이후에
4.[알고리즘] 그리디 알고리즘
현재 상태에서 보이는 선택지 중 최선의 선택지 고르는 과정을 반복하다보면 전체 선택지 중 최선의 선택지라고 "가정"하는 알고리즘이다.실제 문제에서 적용할 때 잘 따져보지 않으면 "반례"가 생길 수 있음.=> 그리디 알고리즘 적용 가능한지 꼭 체크해봐야함(조건 등)꼭 각
5.[자료구조] 스택과 큐

삽입과 삭제 연산이 Last-in First-out로 이뤄지는 구조삽입과 삭제가 "한 쪽"에서만 일어남Top: 삽입과 삭제가 일어나는 위치Push: top 위치에 새로운 데이터 삽입Pop: top 위치에 현재 있는 데이터 꺼냄Peek: top 위치에 현재 있는 데이터
6.[알고리즘] 그리디 문제 풀이
얻어갈 점:처음 문제 풀이할 때 가능한 적은 봉지를 들고가려면, 3kg와 5kg 봉지중 5kg를 최대한 많이 써야하기 때문에 입력값을 5로 나누고 나머지를 3kg로 채우려고 했다. 그러나 이러한 풀이는 9kg같이 3kg를 3개 이용하는 것이 불가능했다.idea는 최대한
7.[알고리즘] 선택 정렬
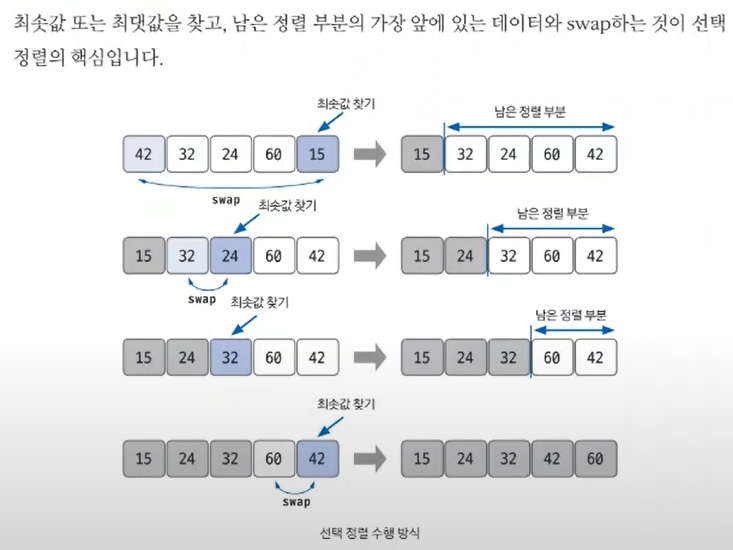
대상 데이터에서 최대나 최소 데이터를 데이터가 나열된 순으로 찾아가며 선택하는 방법구현이 복잡한 편이고 시간 복잡도도 n^2로 좋지 않은 편이다.얻어갈 점:처음에 주어진 입력값 n이 1,000,000,000이기에 정렬 알고리즘의 시간 복잡도를 생각했을때 선택정렬을 적용
8.[자료구조] 우선순위 큐
기본적으로 큐 구조이기에 First-in First-out그러나 일반적인 큐와는 다르게 입력되는 데이터 순서대로가 아닌, 우선순위가 높은 것을 먼저 꺼내기 위해 만들어진 자료구조큰 것에 우선순위를 주는 것을 최대힙(Max Heap)이라 한다작은 것에 우선순위를 주는 것
9.[알고리즘] 구간 합
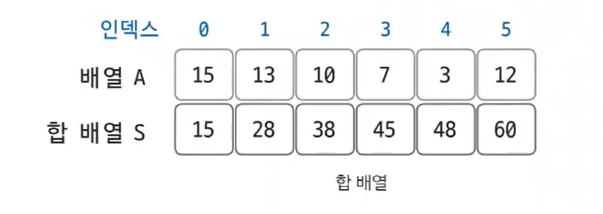
합 배열을 이용하여 시간 복잡도를 더 줄일 수 있는 특수한 목적의 알고리즘합 배열이란? 기존의 배열을 전처리한 배열로 Si = A0 + A1 + A2 --- + Ai-1 + Ai로 나타낼 수 있으며, Si는 합 배열 / Ai는 기존의 배열이다.합 배열 만드는 공식: S
10.[알고리즘] 투 포인터 문제 풀이
얻어갈 점:투 포인터는 시간 복잡도가 O(n)으로 굉장히 작은 편에 속하기에 제한 시간이 적은 문제에 활용 가능!1부터 입력받는 n까지 꼭 배열을 만들 필요 없이 start_index, end_index 두 개를 ++ 연산하면서 배열처럼 쓸 수 있음.
11.[알고리즘] 스택 문제 풀이
얻어갈 점:여태 스택을 활용한 문제는 하나의 스택만 활용했는데 스택 배열을 생성하여 각각의 줄마다 할당해주는 idea + 해당 줄로 찾아가기 위한 현재의 줄 번호와 프렛 번호 저장해줄 변수 선언원래 풀이는 .split() 함수를 사용해 공백을 기준으로 나눠줬는데 Str
12.[알고리즘] 그리디 문제 풀이 2
백준 2012 얻어갈 점: 일단 해당 문제에서 그리디 알고리즘을 사용해야한다는 것 자체를 인지를 못했다. 그리디 문제 안 푼지 좀 돼서 그런 것 같으니 이 글 정리 후 그리디 알고리즘 복습하기. long sum => 자료형을 처음에 int로 썼는데 예시를 잘 보면 주
13.[알고리즘] BFS, DFS
내가 정리하려고 했던 느낌으로 정리한 분이 계셔서 링크 첨부https://codingnojam.tistory.com/44 (DFS)https://codingnojam.tistory.com/41 (BFS)얻어갈 점:main함수와 메서드에서 같이 사용하고
14.[자료구조] Stack 문제 풀이
얻어갈 점:처음에는 배열에 탑들의 정보를 미리 넣고, 맨 끝 인덱스부터 앞과 비교하여 신호를 받을 수 있는 탑을 찾으려 했으나 그렇게 하면 시간 초과가 날 수 밖에 없음(시간복잡도에 의해)Stack을 사용할 수 있었던 이유? 입력된 변수가 가장 가까운 탑과 비교를 통해
15.[알고리즘] 투 포인터
얻어갈 점투 포인터를 이용한 문제 풀이 => why? 특정 구간의 합을 구하는 것! => start, end 인덱스를 사용하여 길이를 조절하여 풀면 되겠다!int\[] arr = new intn+1 => 처음엔 배열의 개수를 n개로 지정했다 그러나 아래의 핵심 로직 쪽
16.[알고리즘] 백 트래킹 문제
백준 9663 얻어갈 점: dfs vs 백 트래킹 => dfs: 완전 탐색을 기본으로 그래프를 모두 순회하기 때문에 불필요한 경로를 사전에 차단 불가 / 백 트래킹: 경로를 찾아가는 도중에 해가 되지 않을 것 같은 경로라면 되돌아옴 백 트래킹으로 풀어야겠다 catch
17.[알고리즘] 유니온 파인드
얻어갈 점:유니온 파인드를 쓸 수 있는 point => 진실을 알고 있는 사람과 한 번이라도 같은 파티라면 거짓말 불가능 => 그룹핑을 통해 한 번이라도 같은 파티였는지, 아닌지 묶는 알고리즘? => 유니온 파인드유니온 파인드를 묶기 위해서는 union(x,y)와 같이
18.[알고리즘] 정규 표현식
백준 2671 얻어갈 점: 정규 표현식을 사용하는 문제를 처음 접해서 노가다해서 풀려고 했는데 실패했다. 특정 규칙을 가지는 문자열을 체크할 수 있는 정규표현식의 존재를 구글링해서 찾아서 잘 정리된 글을 아래에 첨부함 정규 표현식에서 () 와 []의 차이가 궁금했는데
19.[알고리즘] 투 포인터 / 이진 탐색(binary search)
백준 2467 투 포인터 풀이 얻어갈 점: 투 포인터로 풀이할 수 있는 이유? 두 개의 용액이 -부터 +까지 정렬된 상태에서 두 개를 골라 0에 최대한 근접한 값을 찾는다(구간 합과 유사) => 양 쪽 끝에서 두 개를 고른 다음 0보다 크면 start를 하나 땡기고
20.[알고리즘] DFS 문제 풀이
얻어갈 점: 이전의 DFS 구현할 때 인접 행렬을 이용했으나, 이번엔 인접 리스트를 통해 구현했음(성능 상의 이점)DFS 사용 이유? 그래프를 다 뒤져서 가장 거리가 먼 두 수를 찾아서 더해주는 문제라서 사용했음노드의 값은 인덱스와 가중치 두 개의 속성이 있으니 Cla
21.[알고리즘] 백 트래킹 문제 풀이
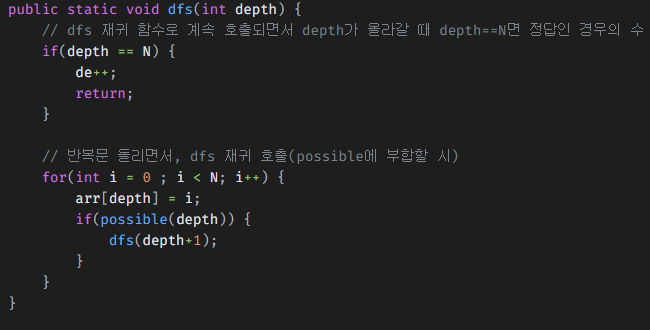
얻어갈 점:이전에 풀었던 NxN queen 문제와 비슷한 느낌이 들어 백 트래킹 알고리즘 채용스도쿠를 풀어가며(dfs이용) 잘못 입력될 시 돌아오는 로직이기 때문그러나 그때 NxN 문제에서는 초기화하고 돌아가는 로직이 없는데 같은 백트래킹이지만 구현이 다른 건가? 의문
22.[알고리즘] 위상 정렬

위상 정렬이란? > 깔끔하게 정리해주신 블로그를 첨부(보고 이해가 안 될 수가 없을듯..) https://bcp0109.tistory.com/21 실전 문제 풀이(백준 1005) 얻어갈 점: