📜문제
👍풀이
import sys
s1 = '0' + sys.stdin.readline().rstrip()
s2 = '0' + sys.stdin.readline().rstrip()
LCS = [[0 for _ in range(len(s1)+1)] for _ in range(len(s2)+1)]
result = 0
for i in range(1, len(s2)):
for j in range(1, len(s1)):
if s2[i] == s1[j]:
LCS[i][j] = LCS[i-1][j-1] + 1
else:
LCS[i][j] = max(LCS[i-1][j], LCS[i][j-1])
result = max(result, LCS[i][j])
print(result)어제 풀었던 LIS(Longest Increasing Subsequence) 문제와 유사한 문제로, 이 알고리즘은 LIS(Longest Common substring)라고 불린다.
❤️ 알고리즘의 원리
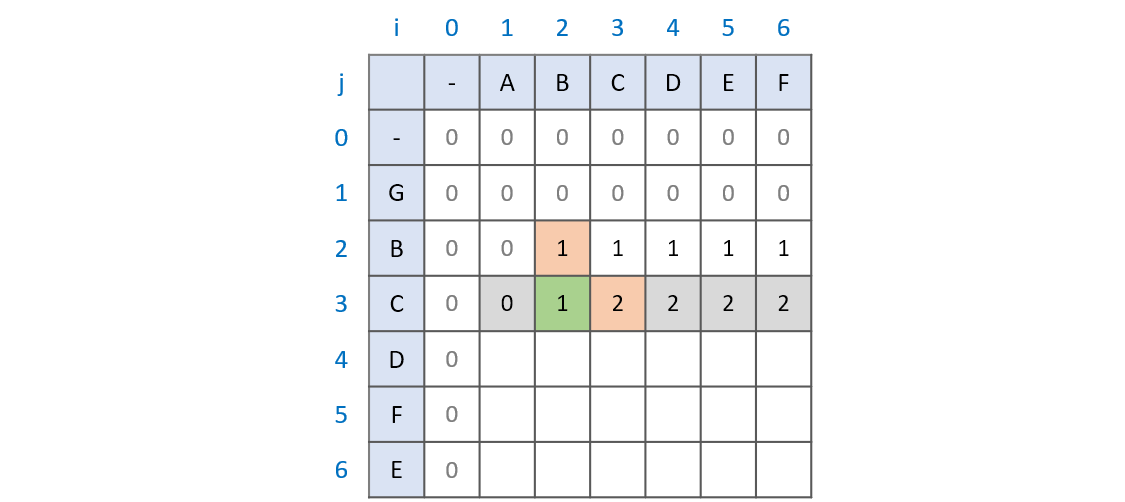
LCS는 두 문자열의 문자를 하나하나씩 대조해가면서 비교한다.
여기서, 초록색 부분은 문자열 S2의 'AB' 와 S1의 'GBC' 에서의 LCS를 찾는 과정이라고 할 수 있다.
초록색 박스를 기준으로,
1. 만일 대조하는 두 문자가 다르다면,
LCS[i-1][j]와LCS[i][j-1]은 각각 GB-AB, A-GBC 를 비교한 구간으로, 현재의 문자열을 비교하기 바로 전 단계에 해당한다.- GB-AB, A-GBC를 서로 비교했을 때 GB-AB 의 경우에는 B가 공통 문자열인데 반해, A-GBC에선 공통문자열이 없다.
- 서로 다른 문자가 하나만 추가되었으므로 'AB'와 'GBC' LCS 또한 B이다. 따라서
max(LCS[i-1][j], LCS[i][j-1])값을 구하는 것이다.
2. 만일 대조하는 두 문자가 같다면,
LCS[i-1][j-1]은 GB-AB를 비교한 구간으로, 현재의 문자열을 비교하기 바로 전 단계에 해당한다.- GB-AB, 서로 비교했을 때 B가 공통 문자열이다.
- 이때 대조하는 두 문자가 같다는 것은 GB-AB의 상황에서 같은 문자(여기선 C)를 두 문자열에 넣어주었다는 뜻이므로,
LCS[i-1][j-1]의 값에1을 더하는 것이다.

꿈이 많은 개발자 지망생