👍 Proportional Scheduling
- Turnaround time, Response time을 스케쥴링 기준으로 고려했던 FCFS, SJF, STCF, RR, MLFQ와는 달리 Fairness(형평성)을 기준으로 삼아 스케쥴링 하는 방법이다.
📢 Lottery Scheduling
프로세스에게 CPU를 점유할 수 있는 티켓을 부여한다. (티켓이 많을수록 CPU를 더 많이 점유할 수 있다.)
- 예를 들어, 전체 100개 티켓 중 A에는 75개의 티켓을, B에는 25개의 티켓을 주고 랜덤으로 CPU를 할당한다면, A와 B의 실행 비율이 75% : 25%로 수렴하는 것을 확인 할 수 있다.

📜 Ticketing Mechanisms - Currency, Transfer, Inflation
1. Ticket Currency
- 만일 User A와 User B가 가지고 있는 그대로 티켓을 환산하여 CPU를 할당한다면, 500 : 500 : 10으로 스케쥴링 되므로 이는 불공평함.
- 대신, CPU에선 User A와 User B에게 global ticket을 할당, User A가 가지고 있는 500개의 티켓들은 global ticket 50개로 환산됨.
- 따라서 50 : 50 : 100으로 공평하게 스케쥴링 되게 됨.

2. Ticket Transfer
- 한 프로세스에서 다른 프로세스로 가지고 있는 티켓을 잠시 빌려준다.
- e.g) Client - Server Process : 클라이언트가 보낸 요청을 서버 프로세스가 처리하고 있는 동안 클라이언트가 가지고 있는 티켓을 서버 프로세스로 이동시킨다.
3. Ticket Inflation
- 한 프로세스가 가지고 있는 티켓 수를 일시적으로 증가 또는 감소
- 서로 다른 프로세스끼리 협력적인 상황일 때 적용가능한 메커니즘
📜 Fairness Metric
- A 프로세스가 실행을 완료한 시각을 C1, B 프로세스가 실행을 완료한 시각을 C2라고 둘 때, C1/C2를 형평성 기준, F로 둘 수 있다.
- 형평성은 1일 때 최상이며, 작업시간이 길수록 Fairness는 1에 근접한 양상을 띈다. (이는 곧, Lottery Scheduling은 전적으로 운에 의존하기 때문에 작업시간이 짧은 프로세스에 대한 형평성을 보장하지 못한다)
📢 Stride Scheduling
- Lottery Scheduling은 짧은 시간동안의 프로세스의 형평성을 보장하지 못하므로, 이를 보완하기 위해 고안된 스케쥴링 기법이다.
예시) A에 100개의 티켓, B에 50개의 티켓, C에 250개의 티켓이 배정되었다고 가정한다면,
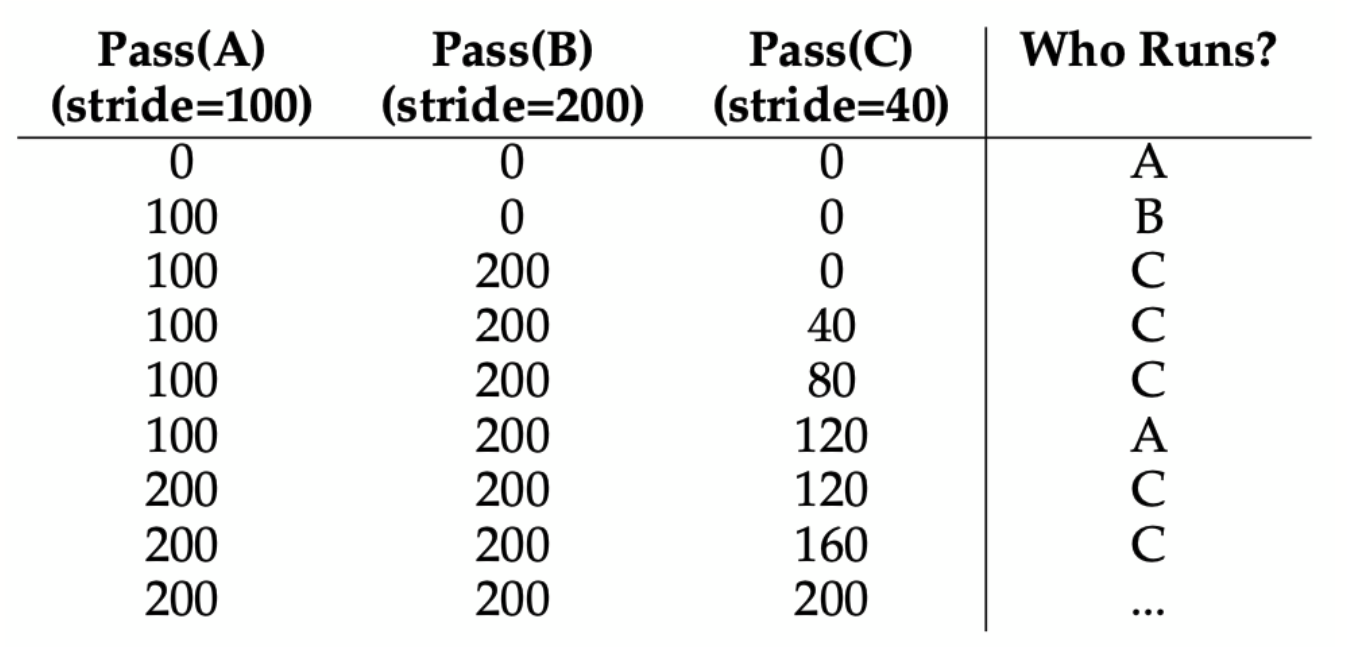
- Pass: 프로세스마다 할당된 값이며, 얼마만큼 실행되었는지를 표시하는 수이기도 하다. 프로세스가 실행될 때마다 pass값에 stride값을 더한다.
- Stride: 특정 수에서 티켓 수로 나눈 값(여기선 10000), 티켓을 많이 할당 받을 수록 stride 값은 작게 되고, 그 결과 더 많이 CPU를 배정받을 수 있다.
- Pass 값이 가장 작은 프로세스를 수행한다!
그러나, stride scheduling도 프로세스가 실행되는 도중 다른 프로세스가 들어온다면, pass 값을 0으로 초기화 하기 때문에 한동안은 CPU를 독점하는 문제가 발생할 수 있다.
👍 Linux Schedulers
📢** Linux Schedulers - O(1) Scheduler
- O(1)은 추후 공부, 지금은 CFS부터(xv6...)
📢 Linux CFS(Completely Fair Scheduler)
- CFS에서의 프로세스는 실행되면 virtual runtime이 누적되며, virtual runtime이 가장 작은 프로세스를 실행한다.
- virtual runtime은 프로세스의 실행 빈도와, 우선순위(가중치)가 적용된 가상 CPU 사용 시간이다.
📜 프로세스를 얼만큼 실행할 것인가?
- CFS는 virtual runtime이 가장 작은 프로세스를 선택하여 그 프로세스를 실행하는데, 얼마만큼 실행할지는 time slice처럼 정해지지 않는다.
- 대신 CFS는 다양한 매개 변수를 활용하여 이를 결정한다.
👍 1. sched_latency (예정된 지연시간)
- 어떤 프로세스를 실행하기 전 계산을 실행.
- 기준은 대체로 48ms이고, 만일 실행되는 프로세스가 10개라면 각 프로세스에 할당된 time slice는 48/10 = 4.8ms
-> But, 실행되는 프로세스가 엄청 많다면, time_slice가 과도하게 짧아지는 문제가 발생
👍 2. min_granularity
-> sched_latency의 문제점을 보완하기 위해, time_slice가 min_granularity가 정한 시간보다는 절대 짧으면 안되게 설정
-> 기준은 대체로 6ms, 따라서 실행되는 프로세스가 10개일때의 time slice는 48/10 = 4.8ms가 아닌 6ms이다.
👍 3. weight(niceness)
-> time_slice는 최종적으로 프로세스가 가지고 있는 가중치와 sched_latency를 연산하여 결정됨.
-> e.g) Process A(Nice=-5), Process B(Nice=0), Sched_latency = 48ms이라 할때
A = 48 (3121(3121+1024)) = 36ms / B = 48 * (1024(3121+1024)) = 12ms!


👍 Stride of virtual runtime
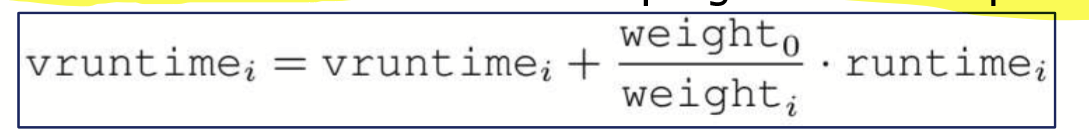
- virtual runtime은 실행한 시간 그대로 더해지지 않는다. 가중치가 적용되어 더해지며, 가중치가 높은 프로세스들은 실제로 실행한 시간보다 덜 더해지게 된다.
- 따라서, 가중치가 높은 프로세스들은 virtual runtime이 증가되는 정도가 작으므로, 더 많이 실행될 수 있다.
📜 CFS에서의 프로세스 내역 관리
- 스케쥴러는 다음에 실행할 프로세스를 빠르게 찾아야 하며, 단순한 자료구조로는 이 목표를 달성하기 어렵다.
- CFS는 virtual runtime으로 표기된 RB-tree(Red-black tree)로 가장 작은 vruntime을 갖는 프로세스를 자동으로 찾아낼 수 있다. (트리 가장 왼쪽에 위치)
- run, ready state에 놓인 프로세스들만 RB Tree에 포함되며, sleep하면 자동 제거된다.
📢 Sleep시의 CPU 독점 현상?
- 작업 A, B가 실행되던 도중, B가 10초간 Sleep 상태로 변경 -> B는 RB tree에서 제거
- 작업 A가 10초동안 실행된 후, B가 Sleep 상태에서 돌아오면 B의 vruntime은 0에서부터 시작하기 때문에 CPU를 독점할 수 있음
- 대신 B의 vruntime을 RB tree에서 가장 작은 값으로 조정 => starvation 현상 방지
📢 Multiple Processor Scheduling
👍 Classification - CPU의 역할을 중심으로
1.Asymmetric Multiprocessing : Master server라고 지칭되는 Master cpu가 scheduling, I/O processing 등을 전부 수행, 나머지 CPU들은 User Code만을 수행함.
2.Symmetric Multiprocessing : CPU의 역할을 나누지 않고 각자 scheduling.
-> Single-Queue Scheduling: 공통적인 Ready queue가 한개 존재
-> Multi-Queue Scheduling: 각 프로세서마다 개별적인 ready queue가 존재
📢 Single-queue scheduling(SQMS)
👍 Single-queue scheduling의 쟁점 - synchronization
-
만일 CPU1가 CPU2가 같은 메모리 A를 동시에 참조해서, CPU1은 A를 B로 변경하고, CPU2는 A를 C로 변경했을 때, CPU1이 기존 메모리 A를 참조한다면? => 만일 CPU2에 의해 바뀐 C를 CPU1이 참조한다면 문제 발생
-
따라서, CPU는 lock을 획득해야만 queue에 접근가능하도록 해야 동시성 문제를 해결 할 수 있음.
👍 Single-queue scheduling의 쟁점 2 - Cache Affinity
- CPU에서 메모리에 바로 접근하는 것은 overhead가 크기 때문에, CPU는 접근이 빠른 캐시를 두어 메모리에 접근함.
- 캐시는 빠르지만 공간은 한정적이기 때문에, locality(최근에 사용한 메모리는 사용가능성이 높음, 한 메모리의 주변 메모리 공간을 사용할 가능성이 높음)을 활용하여 캐시에 메모리를 저장함.
- 이때, 특정 CPU에 상관없이 프로세스를 분배한다면, Context-Switch를 할때마다 캐시에 새로운 데이터를 저장해야할 확률이 높게됨(cache miss 증가)
- 따라서 CPU에 대한 프로세스의 affinity를 설정한다면 특정 프로세스는 특정 CPU에만 실행되어 cache miss가 줄게 됨.
📢 Multiple-queue scheduling(MQMS)
- 각 CPU마다 고유한 ready queue가 존재하고, 프로세스가 ready queue에 들어가야 할 때 특정 CPU를 정해두고 ready queue에 push 됨.
- 따라서 각 CPU는 고유한 프로세스만을 수행하기 때문에 동시성의 문제는 존재하지 않음.
👍 Multiple-queue scheduling의 쟁점 - Load imbalance

- 만일 오른쪽 상황처럼 CPU 0에는 A만이 ready queue에 들어오고 CPU B에는 B와 D가 ready queue에 들어옴 -> load imbalance(부하 불균형) 문제 발생
- Solve 1) Push migration: 부하 불균형 발생 시 작업이 많은 CPU의 작업을 작업이 적은 CPU로 분배시켜줌
- Solve 2) Pull migration(work stealing) : 작업이 적은 ready queue가 작업이 많은 ready queue의 작업을 steal
