Graph Local Query
이번에는 생성된 그래프에 질의를 하는 방법을 알아본다. 앞선 장에서 소개한 MATCH 키워드는 일치하는 패턴에 대해 설정된 변수에 매칭시켜주는 기능을 수행한다. 예를 들어 로마에 사는 사람을 찾는 쿼리를 작성한다고 해보자.
MATCH (p:Person)-[:LIVES_IN]->
(:Place {city : 'Rome', country : "Italy"})
RETURN p위 쿼리 문은 단순히 로마에 사는 사람에 관한 노드를 찾아 변수 p에 매칭시켜준다.
그렇다면, 친구의 친구(Friends of Friends)와 같이, 여러 홉(hop)을 거쳐야 하는 복잡한 매칭은 어떻게 수행할까?
MATCH (:Person {name:"Kimi"})
-[:FRIEND*2..2]->
(fof:Person) RETURN (fof)-[:FRIEND*2..2]->는 2에서 2까지의 길이를 갖는 FRIEND레이블 경로 패턴을 의미한다. *n..m 은 n부터 m까지의 가변길이를 의미한다. 위 예시에서는 2부터 2까지이므로, 정확히 길이가 2인 경우에 대해서만 매칭된다.
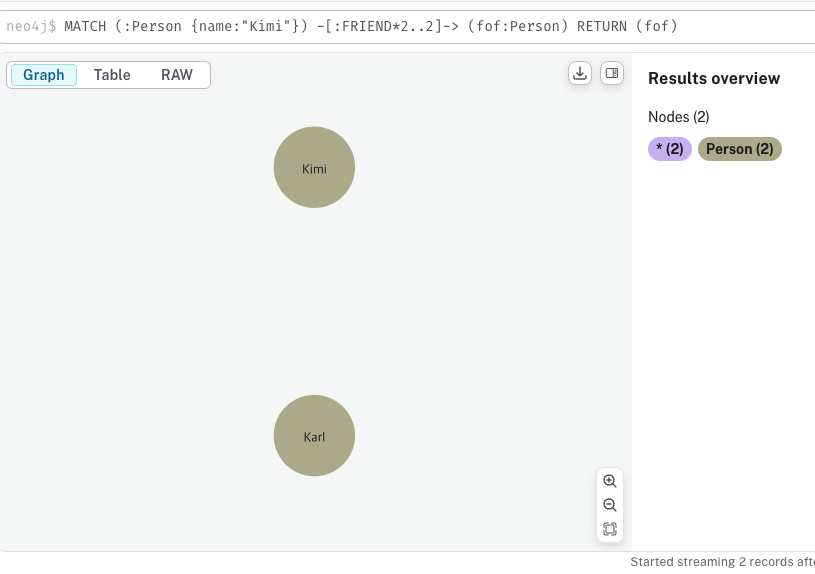
쿼리를 실행시키면 위 사진과 같이 단 두개의 노드만 나타난다.
그러나, 이렇게 하면 Kimi로부터 Karl까지 매칭이 되었다가, 반대로 Karl부터 Kimi까지 다시 매칭이 되어, 자기 자신(Kimi) 마저 친구로 나타나는 문제가 발생한다. 따라서, 자기 자신은 매치되지 않도록 조건을 추가해주어야 한다.
MATCH (kimi:Person {name:"Kimi"})
-[:FRIEND*2..2]->
(fof:Person)
WHERE kimi <> fof RETURN fof패턴과 RETURN 키워드 사이에 WHERE 키워드를 사용해 조건문을 적용하면, 자기자신을 제외한 친구의 친구 노드를 확인할 수 있다.
이 밖에 STARTS WITH, ENDS WITH, CONTAINS, IN과 같은 조건들이 존재한다.
여러개의 패턴을 갖는 경우에는 어떻게 쿼리를 작성할까? 예를 들어, '런던에 사는 사람'의 친구, 또는 친구의 친구를 찾는다고 생각해보자.
이 경우 생각해 볼 수 있는 패턴은 두 개다.
- 런던에 사는 사람
MATCH (:Place {city : "London"})<-[:LIVES_IN]-(p:Person) RETURN p- 사람의 친구, 또는 친구의 친구
MATCH (p:Person)<-[:FRIEND*1..2]-(f:Person)
WHERE f <> p
RETURN f두 패턴에서 공통적으로 p가 나타난다. p 변수를 기준으로 두 쿼리를 이어주면 된다.
MATCH (:Place {city:'London'})<-[:LIVES_IN]-(p:Person)<-[:FRIEND*1..2]-(f:Person)
WHERE f <> p
RETURN f만약, 친구, 친구의 친구도 반드시 런던에 살아야 한다면, WHERE문에서 조건을 걸어 필터링할 수 있다.
MATCH (:Place {city:'London'})
<-[:LIVES_IN]-(p:Person)
<-[:FRIEND*1..2]-(f:Person)
WHERE f <> p AND
(f)-[:LIVES_IN]->(:Place {city:"London"})
RETURN fGraph Global Query
지금까지의 쿼리는 "Kimi의 친구의 친구", "런던에 사는 사람의 친구"와 같이 특정 노드에 쿼리를 고정시켜 질문하였다. 이러한 방식을 local query라고 지칭한다. global query는 그래프 전체에 대해 질의하는 방식으로, 특정 노드에 국한되지 않고 모든 노드에 대해 고려하는 방식이다. 예를 들면, "가장 인기있는 도시는 어디인가?" 와 같은 질문에 대해 답하기 위해서는, 각 Place 레이블 노드와 연결된 Person 노드의 개수를 파악해야 한다.
MATCH (p:Place)<-[l:LIVES_IN]-(:Person)
RETURN p AS place,
count(l) AS rels ORDER BY rels DESC위의 쿼리문은 LIVES_IN 엣지로 연결된 Person 노드, Place 노드 패턴을 찾고, 이중 엣지는 변수 l에, 장소는 p에 매칭시킨다. 의미를 명확히 하고자, 변수 p의 별칭으로 'place'를 정의한가. 한편 변수 l은 count메서드를 사용해 각 place별 연결 링크 개수를 세고, 이를 별칭 rels 정의한다. 마지막으로 ORDER_BY 메서드를 사용해 rels를 내림차순으로 정렬한다.
쿼리 실행 후, 테이블을 확인하면 아래와 같은 결과를 볼 수 있다.
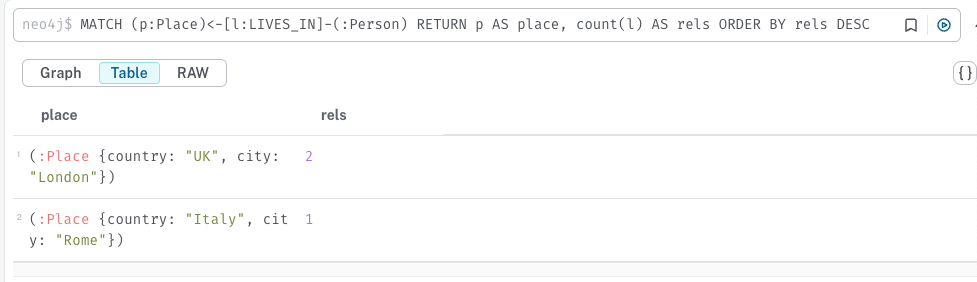
예제에 사용된 데이터가 적어 결과가 3개 밖에 안 나왔지만, 실제 데이터로 진행했을 때는 너무 많은 결과가 반환될 수 있다. Cypher는 avg, mac, sum 같은 집계함수와 limit, skip과 같이 결과를 조절할 수 있는 절을 제공한다.
Calling Function and Procedure
함수(Function), 프로시저(Procedure)
본문에서는 함수, 프로시저를 딱히 구분하지 않고 이들을 호출하는 방식에 대해서만 설명한다. 그러나 함수와 프로시저는 엄연히 구분되는 단위로, 프로시저는 각 업무를 수행하기 위한 절차를 의미하며, 함수는 프로시저에서 정의된 각 프로세스를 수행하기 위해 필요한 기능을 의미한다.
- 함수(Function) : 특정 계산을 수행하며, 리턴값을 오직 하나만 가질 수 있고, 반드시 리턴값을 가져야만 함. 클라이언트 단에서 기술할 수 있으며, 수식 내에서만 사용이 가능함. 단독으로 문장을 구성하는 것이 불가능함.
- 프로시저 (Procedure): 특정 작업을 수행. 리턴값을 0~N개 가질 수 있고, 서버 단에서 기술됨. 수식 내에서 사용이 불가능 하나, 단독으로 문장을 구성하는 것이 가능함.
neo4j에서는 특정 작업을 구현하는 함수와 프로시저를 제공하며, 이를 Cypher 구문에서 호출할 수 있다. 대표적으로 자주 사용되는 함수는 스키마 시각화 함수이다. 함수, 프로시저의 호출은 CALL 키워드를 사용한다.
CALL db.schema.visualization()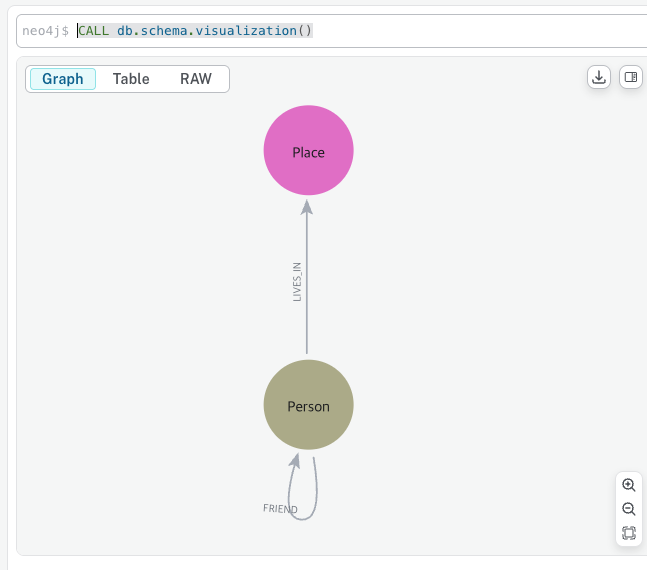
통상적으로 많이 사용되는 라이브러리는 APOC Library로, 지식그래프 작업을 위한 유용한 기능과 단축키들이 포함되어 있다.
만일 아래 소개된 쿼리를 실행시켰는데 42N08: Syntax error or access rule violation - no such procedure 에러가 뜨면 APOC이 설치되지 않은 것이다.
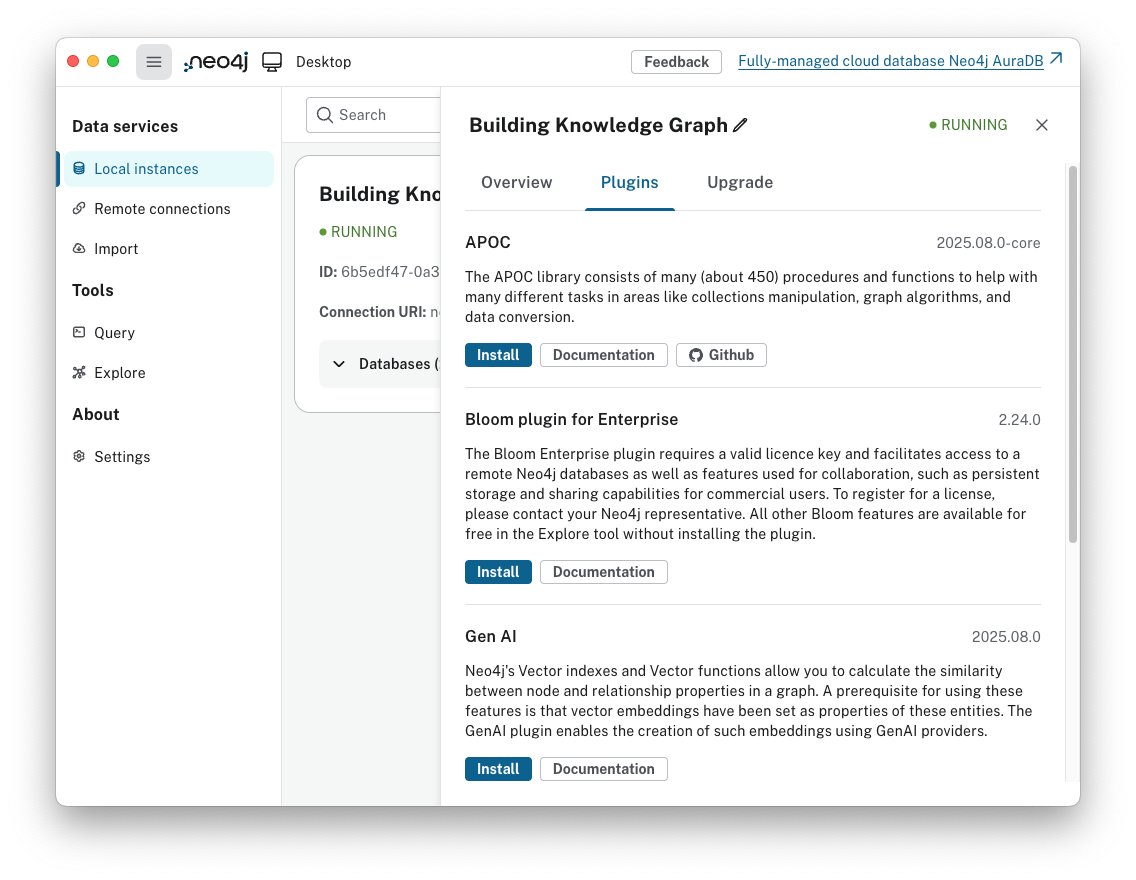
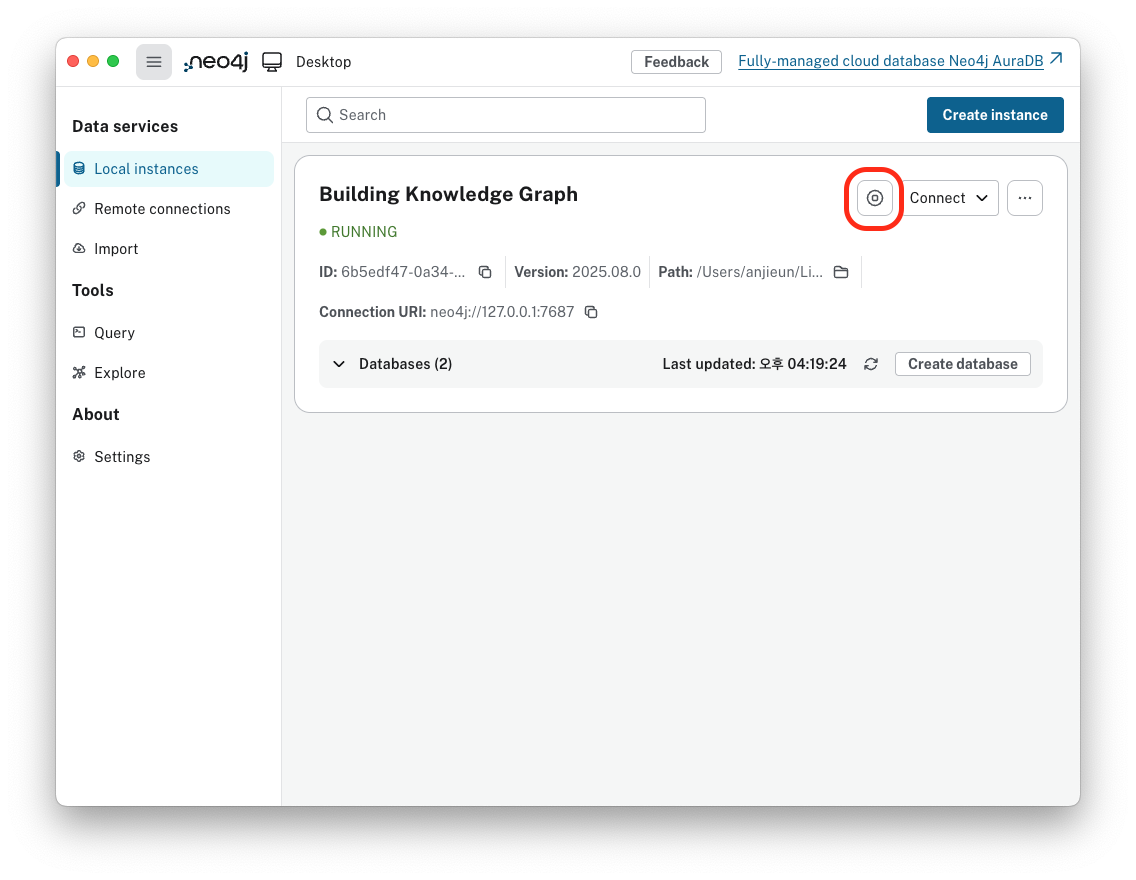
APOC 플러그인 설치하기 (neo4j desktop 기준)
1. Local Instance 탭으로 들어가서 현재 자신이 사용하고 있는 인스턴스의 우측 설정 버튼(점 세개)을 눌러준다. 여기서 Plugin을 클릭한다.
2. 플러그인을 클릭하면 APOC이 최상단에 뜰 것이다. Install 버튼을 클릭해준다.
3. 인스턴스를 정지시켰다가 다시 시작한다.
apoc.atomic.concat은 속성값 문자열에 다른 문자열을 추가할 수 있도록 한다. 아래 쿼리는 "Karl"에 "os"를 추가하여 "Karlos"로 변경하는 쿼리이다.
MATCH (p:Person {name:'Karl'})
CALL apoc.atomic.concat(p, "name", 'os')
YIELD oldValue, newValue
RETURN oldValue, newValue;실행 시켜보면 아래와 같은 표를 확인할 수 있다.
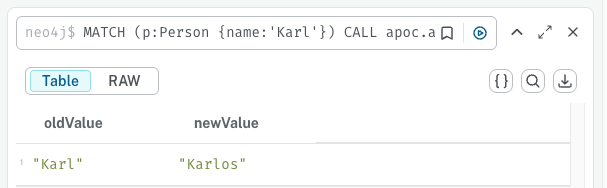
쿼리에서 나타난 YIELD는 프로시저나 함수가 반환하는 결과 중에서 원하는 컬럼을 꺼낼 때 사용하는 키워드이다.
이 밖에도, 이 링크에 들어가면 apoc 라이브러리에서 제공하는 함수와 프로시저에 대해 확인할 수 있다.
EXPLAIN, PROFILE
EXPLAIN, PROFILE 키워드는 개발자가 쿼리 성능을 이해하는데 도움을 주는 키워드이다. 이중 EXPLAIN 키워드는 쿼리 계획을 시각화 하여, 쿼리 과정 중에서서의 데이터 처리량(DB Hits)를 시각화 하여 보여준다.
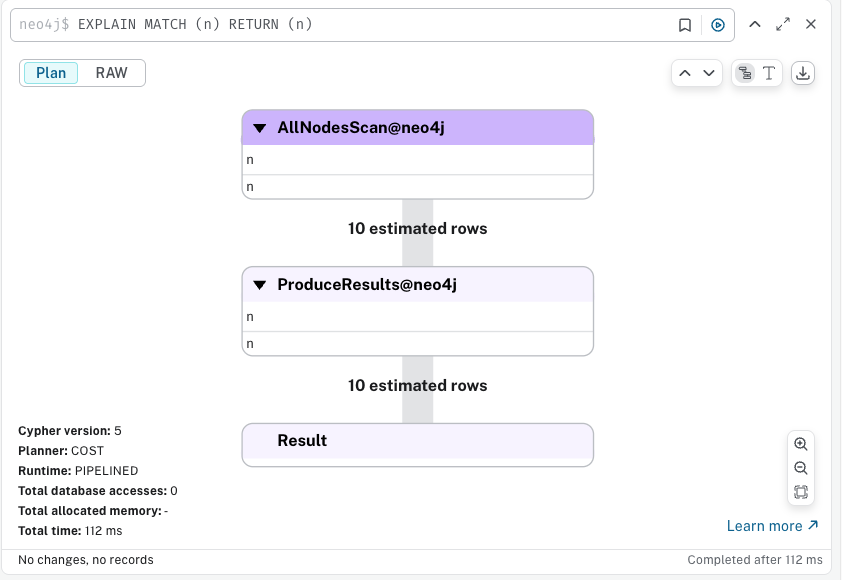
PROFILE은 EXPLAIN에서 더 나아가, 실행 중의 실제 동작을 보여주기 위해 실행 쿼리를 조정한다. PROFILE 을 사용하면 실제 쿼리가 어떻게 작동하는지 확인할 수 있다.
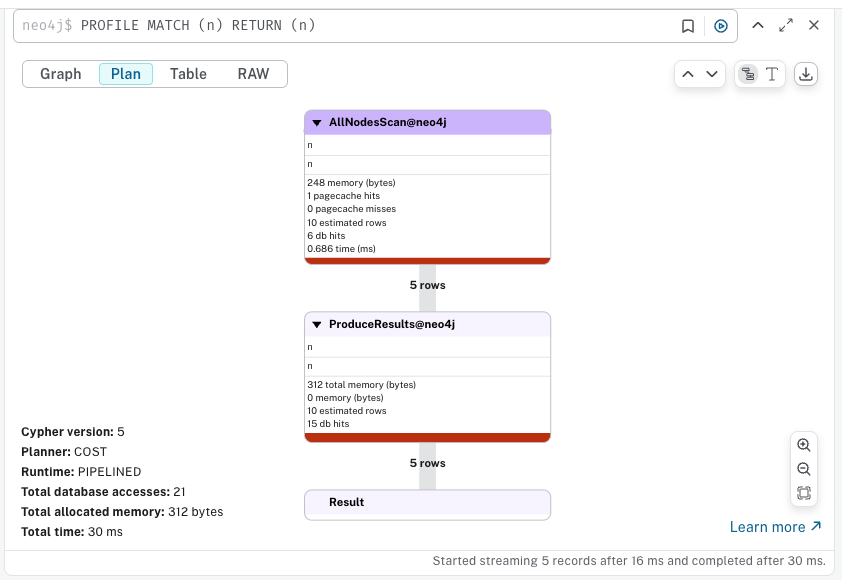
EXPALIN, PROFILE을 사용해 얻은 정보를 토대로 쿼리 성능을 향상시킬 수 있다. 예를 들어 연산자 사이에 너무 큰 규모의 데이터가 이동한다면 리팩토링할 쿼리를 찾아야 하고, 매크로 수준의 시각화가 db scan 과 같이 큰 비용이 드는 경우에는 유용한 인덱스가 누락되어 인덱스가 조회되지 않고 전체를 스캔하고 있을 가능성이 있다.
