11. 통계분석 - 시계열분석
11.1. 시계열 분석
시계열 분석 개요
시계열 분석이란?
시간의 흐름에 따라 관찰된 값들을 시계열 자료라 한다. 일정 시간 간격으로 기록된 자료들에 대하여 특성을 파악하고 미래를 예측하는 분석 방법이다.
주가 데이터, 환율 데이터, 월별 재고량 등이 시계열 자료에 해당한다.
시계열 자료의 자기상관성(중)
- 시계열 자료들은 자기상관성을 가지고 있다. 인접한 자료들과 상호 연관성을 가진다는 의미다.
- 공분산이 시계열 분석에서 중요한 이유는 시계열 자료의 자기상관성 때문이다. 확률변수의 흩어짐 정도를 의미하는 공분산이 어느 정도인지, 어느 정도의 상관성을 갖는지가 중요한 것이다.
시계열 분석의 자료
크게 정상성 시계열 자료와 비정상성 시계열 자료로 구분된다.
- 시계열 분석을 수행할 경우 정상성 자료여야 하는데, 자료의 대부분은 비정상성이므로 이를 정상성 시계열 자료로 변환해야 한다.
- 정상성이란 평균이 일정할 것, 분산이 시점에 의존하지 않을 것 등의 일정한 조건을 요구한다.
- 평균값이 시간에 관계없이 일정하다.
- 분산값이 시간에 관계없이 일정하다.
- 공분산은 시간에 의존하지 않고 시차에만 의존한다
시계열 자료의 정상성 조건(중)
시계열 자료가 분석을 수행함에 있어서 용이한지 확인해야 하는데, 그 조건이 아래 정상성 3가지이다.
일정한 평균
- 모든 시점에 대해 일정한 평균을 가진다.
- 평균이 일정하지 않은 시계열은 차분을 통해 정상화할 수 있다.
차분이란?
현시점 자료에서 전 시점 자료를 빼는 것이며, 차분을 통해 평균을 일정하게 만든다.
일반차분 : 바로 전 시점의 자료를 배는 방법
계절차분 : 여러 시점 전의 자료를 빼는 방법, 주로 계절성을 갖는 자료를 정상화하는데 사용- 예를 들어, ‘1, 2, 3, 4, 5,…’ 이렇게 계속 증가하는 시계열 자료가 있다면
2-1, 3-2, 4-3, 5-4 … = 차분 : 1, 1, 1, 1 … → 일정한 평균의 모형으로 변하게 된다.
- 예를 들어, ‘1, 2, 3, 4, 5,…’ 이렇게 계속 증가하는 시계열 자료가 있다면
일정한 분산
모든 시점에 대하여 분산이 일정해야 한다.
- 분산이 일정하지 않을 경우 변환을 통해 정상화할 수 있다.
- 자료 값에 지수 혹은 로그를 취해 변환하면 시간에 따라 변하는 분산의 크기를 안정시킬 수 있다.
시차에만 의존하는 공분산
- 공분산은 시차에만 의존하고 실제 특정시점 t, s에는 의존하지 않는다.
- t는 시점, s는 시차라고 했을 때, ‘t시점과 t+s시점의 공분산’과 ‘t-s시점의 공분산’은 서로 같다.
정상 시계열의 특징
정상 시계열은 어떤 시점에서 평균과 분산 그리고 특정한 시차의 길이를 갖는 자기공분산을 측정하더라도 동일한 값을 갖는다.
- 정상 시계열은 항상 그 평균값으로 회귀하려는 경향이 있으며, 그 평균값 주변에서의 변동은 대체로 일정한 폭을 갖는다.
- 정상 시계열이 아닌 경우 특정 기간의 시계열 자료로부터 얻은 정보를 다른 시기로 일반화할 수 없다.
시계열 분석 기법
자료 형태에 따른 분석방법
일변량 시계열 분석
- Box-Jenkins(ARMA), 지수 평활법, 시계열 분해법 등
- 시간(t)을 설명변수로 한 회귀모형주가, 소매물가지수 등 하나의 변수에 관심을 갖는 경우의 시계열 분석
다중 시계열분석
- 계량경제 모형, 전이함수 모형, 개입분석, 상태공간 분석, 다변량 ARIMA 등
- 여러 개의 시간(t)에 따른 변수들을 활용하는 시계열 분석
- 계량경제란? 시계열 데이터에 대한 회귀분석
(ex. 이자율, 인플레이션이 환율에 미치는 요인)
- 계량경제란? 시계열 데이터에 대한 회귀분석
이동평균법
과거로부터 현재까지의 시계열 자료를 대상으로 일정 기간별 이동평균을 계산하고, 이들의 추세를 파악하여 다음 기간을 예측하는 방법
- 시간이 지남에 따라 평균 계산에 포함되는 자료가 바뀌기 때문에 이동평균법이라고 한다. 변동이 많은 시계열 데이터의 평균을 구함으로써 여러 요인으로 인한 변동을 없앨 수 있다.
- 시계열 자료에서 계절변동과 불규칙 변동을 제거하여 추세변동과 순환 변동만 가진 시계열로 변환하는 방법으로도 사용된다.
- 이동평균법은 장기적인 추세를 파악하는데 효율적이나 모든 시점에 대해서 동일한 가중치를 주고 있기 때문에 최근의 자료가 더 많은 정보를 간직한다고 볼 수 있는 일반적인 견해에 어긋난다.
- 일반적으로 시계열 자료에 뚜렷한 추세가 있거나 불규칙변동이 심하지 않은 경우에는 짧은 기간의 평균을 사용, 반대로 불규칙 변동이 심한 경우 긴 기간의 평균을 사용한다.
- 간단하고 쉽게 미래를 예측할 수 있으며, 자료의 수가 많고 안정된 패턴을 보이는 경우 예측의 품질이 높다.
지수평활법
일정 기간의 평균을 이용하는 이동평균법과 달리 모든 시계열 자료를 사용하여 평균을 구하며, 시간의 흐름에 따라 최근 시계열에 더 많은 가중치를 부여하여 미래를 예측하는 방법
- 자료의 수가 많고 자료가 안정된 패턴을 보이는 경우 예측 품질이 높으며, 불규칙변동의 영향을 제거할 수 있으므로 중장기 예측에 주로 사용된다.
- 지수평활법은 불규칙변동의 영향을 제거하는 효과가 있으며, 중기 예측 이상에 주로 사용된다.
연습문제
1번
시계열 분석의 정상성에 대한 설명으로 옳지 않은 것은?
1. 분산이 일정하지 않을 경우 변환을 통해 정상화할 수 있다.
2. 모든 시점에 대해 일정한 평균을 가진다.
3. 공분산은 시차가 아닌 특정 시점에 의존한다.
4. 정상 시계열은 모든 시점에 대하여 분산이 일정해야 한다.
정답
공분산은 특정 시점이 아닌 시차에 의존한다.
2번
시계열 분석 기법 중 하나인 이동평균법에 대한 설명으로 옳지 않은 것은?
1. 불규칙변동의 영향을 제거하는 효과가 있으며, 중기 예측 이상에 주로 사용된다.
2. 일정 기간별 이동평균을 계산하고, 이들의 추세를 파악하여 예측하는 방법이다.
3. 불규칙 변동이 심한 경우 긴 기간의 평균을 사용한다.
4. 자료의 수가 많고 안정된 패턴을 보이는 경우 예측의 품질이 높다.
정답
지수평활법은 불규칙변동의 영향을 제거하는 효과가 있으며, 중기 예측 이상에 주로 사용된다.
이동평균법 : 시간이 지남에 따라 평균 계산에 포함되는 자료가 바뀐다. 변동이 많은 시계열 데이터의 평균을 구함으로써 여러 요인으로 인한 변동을 없앨 수 있다
3번
시계열 분석에 대한 설명으로 옳지 않은 것은?
1. 시계열 분석은 시간의 흐름에 따라 관찰된 값이다.
2. 시계열 자료들은 독립성을 가지고 있다.
3. 주가 데이터, 환율 데이터, 월별 재고량 등이 시계열 자료에 해당한다.
4. 시계열 분석 자료로는 크게 정상성, 비정상성 시계열 자료로 구분된다.
정답
시계열 자료들은 인접한 자료들과 상호 연관성을 가진다
11.2. 시계열 모형
자기회귀모형
자기회귀(AR:Autoregressive) 모형
‘자기회귀’라는 용어는 현재 값이 자기 자신에게 회귀되는 형태를 나타낸다. 자기회귀 모형이란 과거 시점의 관측 자료들의 선형 결합으로 표현한 모형으로 시계열 자료를 설명하기 위한 모형 중 하나다. t라는 시점에서의 값 는 이전 시점들 n개에 의해 설명될 수 있음을 의미한다.
- : 현재 시점의 시계열 자료
- : 1~p 시점 이전의 시계열 자료
- : p 시점이 현재 시점에 어느 정도 영향을 주는지 나타내는 모수
- : 백색잡음과정, 시계열 분석에서 오차항을 의미
- AR(1) 모형 : , 직전 시점 데이터로만 분석
- AR(2) 모형 : , 연속된 2시점 정도의 데이터로 분석
- 자기회귀모형인지 판단하기 위한 모형 식별을 위해서 자료에서 자기상관함수(ACF, Auto-Correlation Function)와 부분자기상관함수(PACF, Partial Auto-Correlation Function)를 이용하여 식별한다.
- 자기상관함수(ACF)는 빠르게 감소, 부분자기함수(PACF)는 어느 시점에서 절단점을 가진다.
백색잡음이란?
현재의 시점이 이전 시점과의 상관관계가 존재하지 않는 서로 독립적인 시계열 자료를 백색잡음이라고 한다. 평균이 , 분산이 으로 정규분포를 따를 경우 가우시안 백색잡음이라고 하며, 평균이 0인 경우 시계열 모형에서 오차항이 될 수 있다.
자기상관계수(ACF, Auto-Correlation Function)(중)
시계열 분석에서 자기상관계수는 시간의 흐름에 따른 자기상관관계를 나타낸다.
- 시계열 자료가 시간의 흐름에 따라 일정한 패턴을 보인다면 변수들이 자기상관성을 갖고 있기 때문이다.
- 시계열 분석에서는 자기상관함수를 시계열 자료가 시간에 의존하지 않고 무작위성을 띠는지 확인하는 데 사용한다. 만약 시계열 데이터가 무작위성을 띠지 않는다면 시계열 분석을 통한 미래 시점의 예측도 가능하다.
- 자기상관함수는 시차 에서의 값과 로부터 만큼의 시차를 갖는 시점에서의 값의 상관계수를 나타내는 함수다.
- 시차 =0인 경우, 자신과의 상관계수를 의미하며 항상 1이다. 일반적으로 자기상관계수는 시차가 증가하면서 자기상관계수 값이 감소한다.
부분자기상관계수(PACF, Partial Auto-Correlation Function)(중)
부분자기상관함수는 두 시계열 확률변수 간에 다른 시점의 확률변수 영향력은 통제하고 상관관계만 보여준다.
- 두 시계열 확률변수의 상관관계를 알아보려고 할 때, 그에 영향을 주는 요소들을 제외하고 오로지 둘 사이의 상관관계만을 고려할 때 부분자기상관계수를 이용한다.
- 부분자기상관계수는 시점 와 시차 을 갖는 시점 사이에 존재하는 개의 자료값이 자기상관계수에 미치는 영향을 제거한 상관계수다. 일반적으로 부분자기상관계수는 특정 시점 이후 급격히 감소한다.
이동평균 모형
이동평균(MA:Moving Average) 모형
시계열 자료를 모형화하는데 자기회귀모형 다음으로 많이 쓰이는 모형이다.
- 현 시점의 자료를 유한개의 백색잡음의 선형결합으로 표현되었기 때문에 항상 정상성을 만족한다.
- 1차 이동평균모형, MA(1) 모형은 가장 간단한 이동평균모형으로 같은 시점의 백색잡음과 바로 전 시점의 백색잡음의 결합으로 이루어진 모형이다.
- 2차 이동평균모형, MA(2) 모형은 바로 전 시점의 백색잡음과 시차가 2인 백색잡음의 결합으로 이루어진 모형이다.
- 이동평균모형은 자기회귀모형과 반대로 ACF에서 절단점을 갖고, PACF가 빠르게 감소하는 형태를 띠게 된다.
자기회귀누적이동평균 모형
자기회귀누적이동평균모형(ARIMA : Autoregressive Integrated Moving Average) 모형
ARIMA 모형은 비정상 시계열 모형이기 때문에 차분이나 변환을 통해 AR모형이나 MA모형, ARMA 모형으로 정상화할 수 있다.
- 차수 p는 AR 모형과 관련이 있고, q는 MA 모형과 관련이 있는 차수이다.
- d는 ARIMA에서 ARMA로 정상화할 때 몇 번 차분을 했는지를 의미한다.
- d=0이면 ARMA(p,q) 모형이라 부르고, 이 모형은 정상성을 만족한다.
- p=0이면 IMA(d,q) 모형이라 부르고, 이 모형을 d번 차분하면 MA(q) 모형이 된다.
- q=0이면 ARI(p,d) 모형이며, 이를 d번 차분한 시계열 모형이 AR(p) 모형을 따르게 된다.
분해 시계열
분해 시계열이란?
시계열에 영향을 주는 일반적인 요인을 시계열에서 분리해 분석하는 방법을 말하며, 회귀분석적인 방법을 주로 사용한다.
분해식의 일반적 정의
- : t시점에서의 시계열 자료 값
- : 시계열 자료의 증가 혹은 감소 추세, 경향(추세)요인
- : 시간, 계절과 같은 원인으로 인한 주기를 두고 변동하는 자료, 계절요인
- : 알 수 없는 원인으로 인한 주기를 두고 변동하는 자료, 순환요인
- : 설명할 수 없는 오차, 불규칙요인
시계열의 구성요소
- 추세요인 : 인구의 증가, 기술의 변화 등과 같은 요인에 의해 장기간 일정한 방향으로 오르거나 내리는 추세이며, 이차식이나 지수적 형태를 취할 수도 있다.
- 계절요인 : 요일마다 반복되는 주기, 월별, 분기별, 사계절 각 분기에 의한 변화 등 고정적인 주기에 따라 자료의 변동이 반복되는 경우이다. 예측하기가 상대적으로 쉬우며 순환요인보다 주기가 짧은 것이 특징이다.
- 순환요인 : 경제적이나 자연적인 이유 없이 알려지지 않은 주기를 가지고 변화하는 자료이다.
- 불규칙요인 : 위 3가지 요인으로 설명할 수 없는 회귀분석에서 오차에 해당하는 요인이다.
시계열 분석 실습
예제1.
먼저, R에 기본적으로 내장되어 있는 Nile 데이터를 불러온다. Nile 데이터는 1871년도부터 1970년도까지 아스완 댐에서 측정한 나일강의 연간 유입량에 관한 시계열 데이터다.
> Nile
Time Series:
Start = 1871
End = 1970
Frequency = 1
[1] 1120 1160 963 1210 1160 1160 813 1230 1370 1140 995 935
[13] 1110 994 1020 960 1180 799 958 1140 1100 1210 1150 1250
[25] 1260 1220 1030 1100 774 840 874 694 940 833 701 916
[37] 692 1020 1050 969 831 726 456 824 702 1120 1100 832
[49] 764 821 768 845 864 862 698 845 744 796 1040 759
[61] 781 865 845 944 984 897 822 1010 771 676 649 846
[73] 812 742 801 1040 860 874 848 890 744 749 838 1050
[85] 918 986 797 923 975 815 1020 906 901 1170 912 746
[97] 919 718 714 740예제2.
> ldeaths
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec
1974 3035 2552 2704 2554 2014 1655 1721 1524 1596 2074 2199 2512
1975 2933 2889 2938 2497 1870 1726 1607 1545 1396 1787 2076 2837
1976 2787 3891 3179 2011 1636 1580 1489 1300 1356 1653 2013 2823
1977 3102 2294 2385 2444 1748 1554 1498 1361 1346 1564 1640 2293
1978 2815 3137 2679 1969 1870 1633 1529 1366 1357 1570 1535 2491
1979 3084 2605 2573 2143 1693 1504 1461 1354 1333 1492 1781 1915
예제 1,2에서 불러온 데이터를 plot 함수를 이용하여 그려본 후 살펴본다.
> plot(Nile)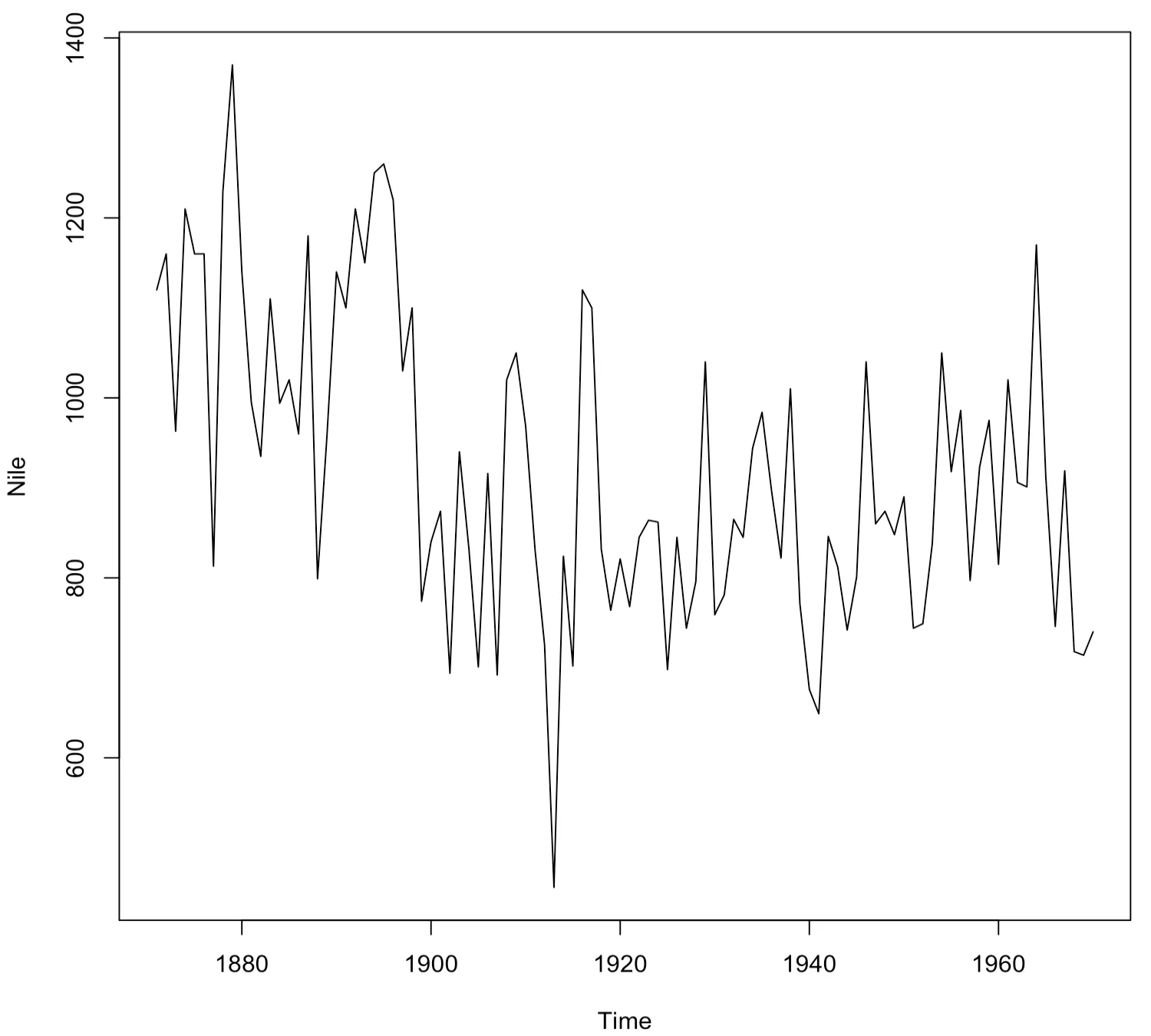
나일강 연간 유입량 데이터는 비계절성을 띠는 데이터다. 그러나 이 시계열 자료는 평균이 변화하는 추세를 보이므로 정상성을 만족하지 못하는 것으로 보인다.
> plot(ldeaths)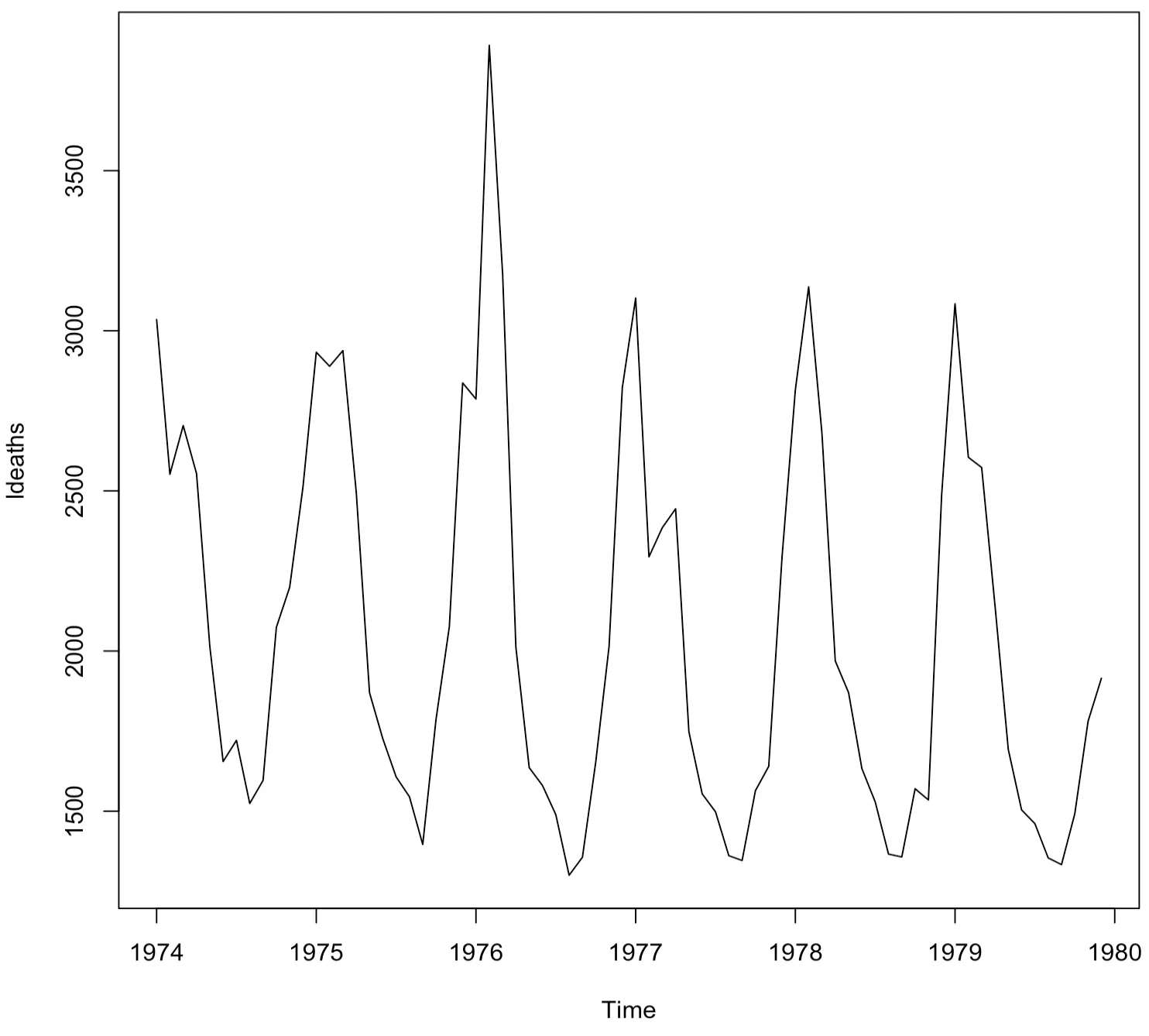
영국 내 폐 질환 사망자 데이터는 연도 별로 계절성을 띠고 있는 것으로 보인다. 매년 일정 주기별로 사망자 수가 늘었다 줄었다 하는 경향을 보인다.
- 분해시계열
R에서 decompose 함수를 사용하면 시계열 자료를 4가지 요인으로 분해할 수 있다
> ldeaths.decompose <- decompose(ldeaths)
> ldeaths.decompose$seasonal
Jan Feb Mar Apr May Jun
1974 873.7514 896.3347 687.5431 156.5847 -284.4819 -440.0236
1975 873.7514 896.3347 687.5431 156.5847 -284.4819 -440.0236
1976 873.7514 896.3347 687.5431 156.5847 -284.4819 -440.0236
1977 873.7514 896.3347 687.5431 156.5847 -284.4819 -440.0236
1978 873.7514 896.3347 687.5431 156.5847 -284.4819 -440.0236
1979 873.7514 896.3347 687.5431 156.5847 -284.4819 -440.0236
Jul Aug Sep Oct Nov Dec
1974 -519.4236 -669.8736 -678.2236 -354.3069 -185.2069 517.3264
1975 -519.4236 -669.8736 -678.2236 -354.3069 -185.2069 517.3264
1976 -519.4236 -669.8736 -678.2236 -354.3069 -185.2069 517.3264
1977 -519.4236 -669.8736 -678.2236 -354.3069 -185.2069 517.3264
1978 -519.4236 -669.8736 -678.2236 -354.3069 -185.2069 517.3264
1979 -519.4236 -669.8736 -678.2236 -354.3069 -185.2069 517.3264
> plot(ldeaths.decompose)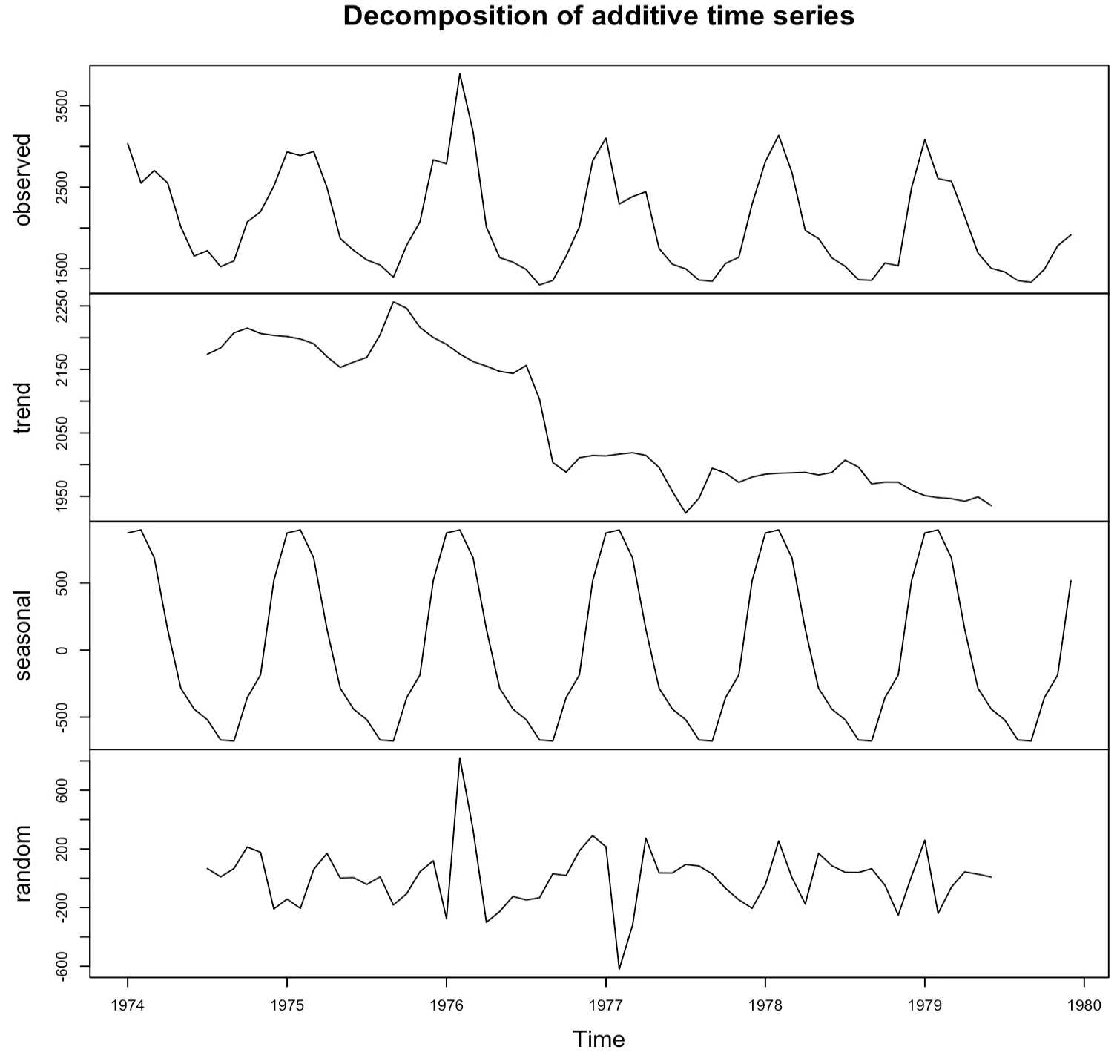
계절성을 띠는 시계열 자료는 계절요인을 추정하여 그 값을 원 시계열자료에서 빼면 적절하게 조정할 수 있다. 즉, 원 시계열 자료에서 계절요인을 제거한 후 그림을 그린다.
> ldeaths.decompose.adj<-ldeaths-ldeaths.decompose$seasonal
> plot(ldeaths.decompose.adj)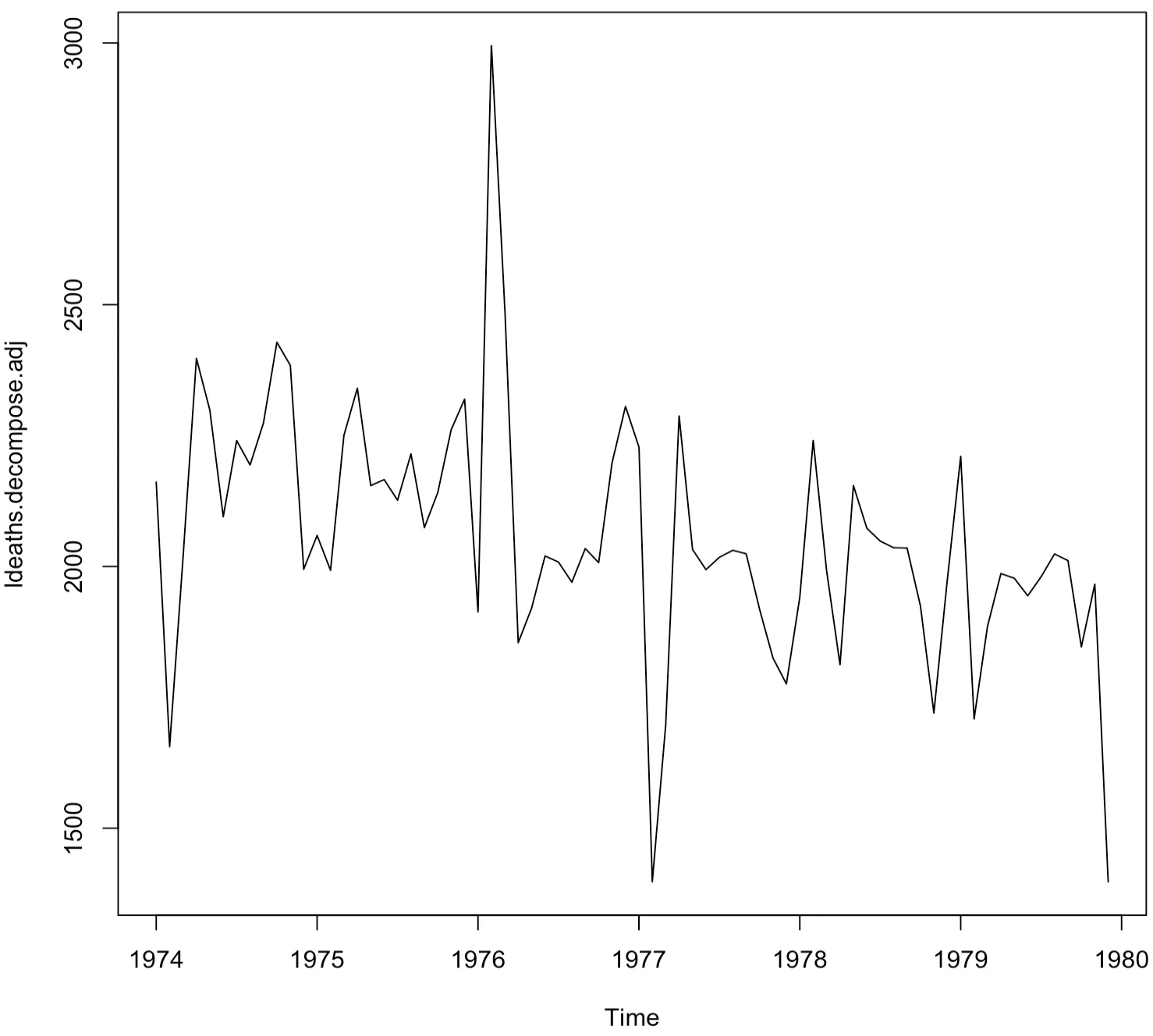
위와 같이 계절요인이 제거되어 조정된 시계열 자료를 얻게 된 것을 확인할 수 있다.
- ARIMA 모형
시간에 따라 평균이 일정하지 않은 비정상 시계열 자료인 나일강 연간 유입량 데이터를 diff 함수를 사용하여 차분을 진행한다.
> Nile.diff1<-diff(Nile,differences=1)
> plot(Nile.diff1)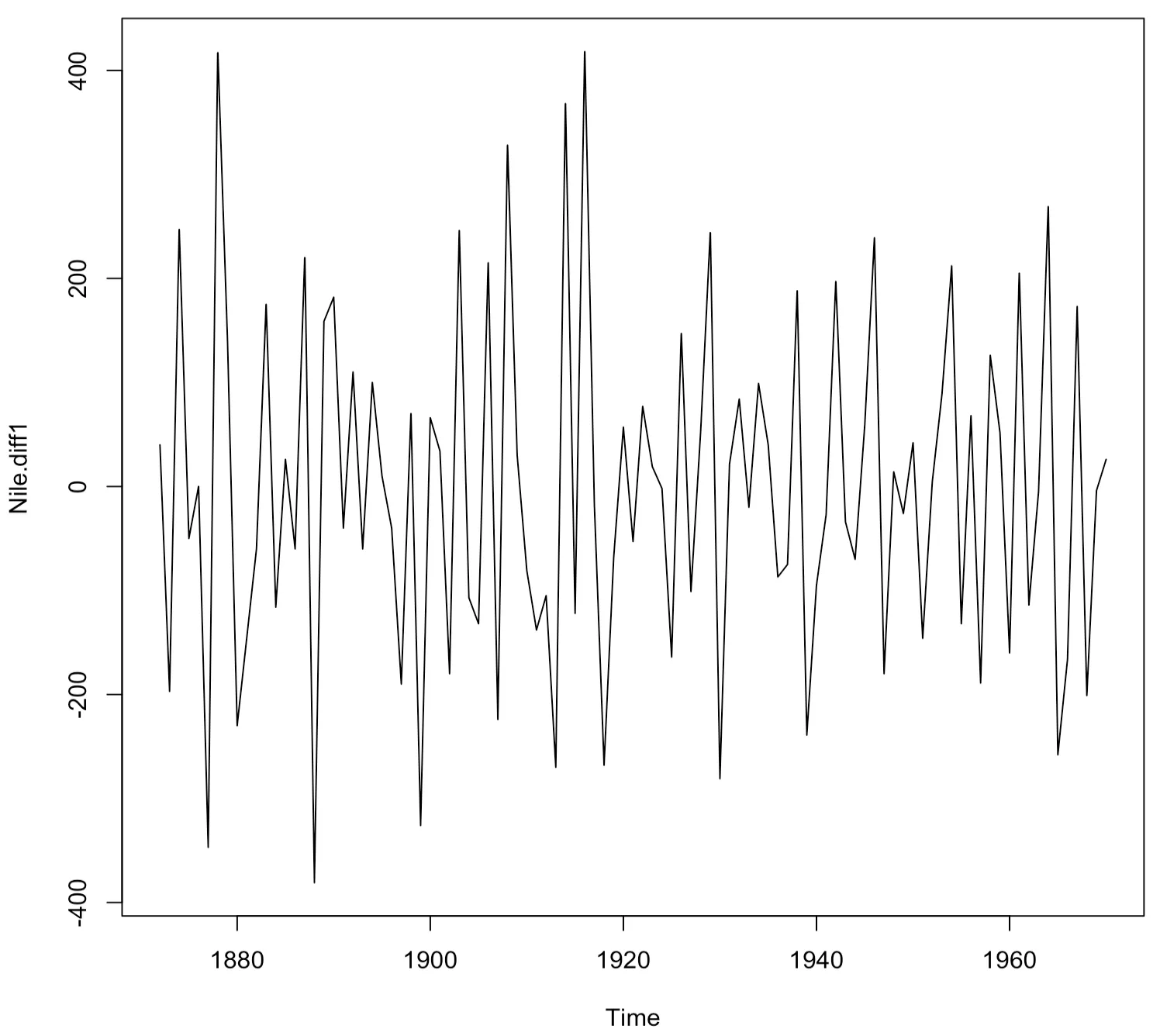
아직 평균이 일정하지 않아 보인다. 차분을 2번 진행한다.
> Nile.diff2<-diff(Nile,differences=2)
> plot(Nile.diff2)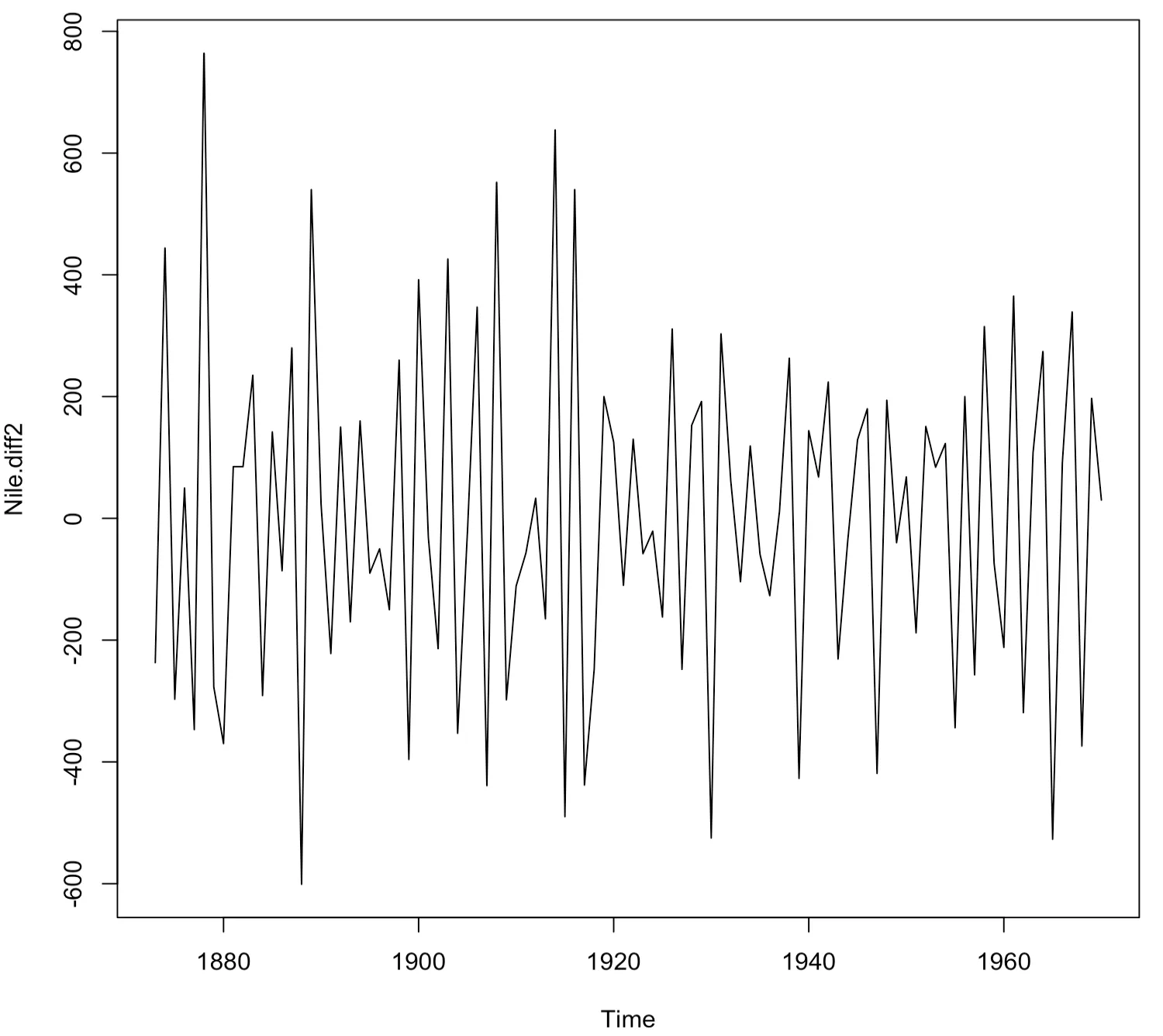
2번 차분한 결과, 시간이 지남에 따라 평균과 분산이 어느 정도 일정한 정상성을 만족하는 것으로 보인다.
- ARIMA 모형 적합 및 결정
자기상관함수를 살펴보기 위해 acf 함수를 사용하여 2차 차분을 한 나일강 연간 유입량 시계열 자료의 자기상관함수 그래프를 그려보면 다음과 같다.
> acf(Nile.diff2, lag.max = 20)
> acf(Nile.diff2, lag.max = 20,plot = FALSE)
Autocorrelations of series ‘Nile.diff2’, by lag
0 1 2 3 4 5 6 7 8
1.000 -0.626 0.100 0.067 -0.072 0.017 0.074 -0.192 0.245
9 10 11 12 13 14 15 16 17
-0.079 -0.153 0.183 -0.106 0.062 0.010 -0.096 0.134 -0.134
18 19 20
0.091 -0.030 0.003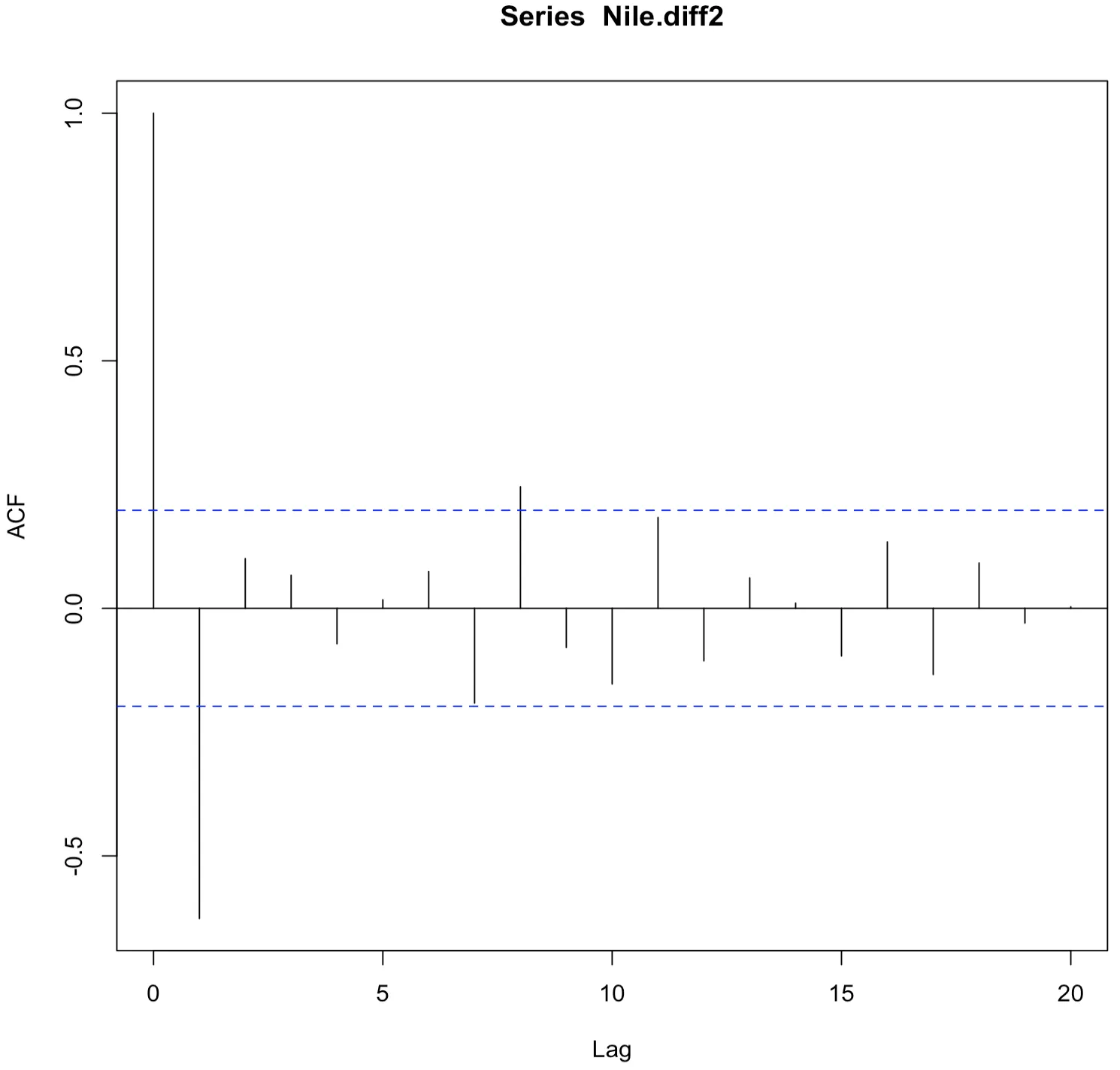
위 결과 자기상관함수가 1ag=1, 8을 제외하고 모두 신뢰구간 안에 있는 것을 확인할 수 있다. 다음으로 부분자기상관함수 그래프를 그려보면 아래와 같다.
> pacf(Nile.diff2, lag.max = 20)
> pacf(Nile.diff2, lag.max = 20,plot = FALSE)
Partial autocorrelations of series ‘Nile.diff2’, by lag
1 2 3 4 5 6 7 8 9
-0.626 -0.481 -0.302 -0.265 -0.273 -0.112 -0.353 -0.213 0.038
10 11 12 13 14 15 16 17 18
-0.120 -0.117 -0.197 -0.132 -0.055 -0.109 0.022 -0.184 -0.067
19 20
-0.037 -0.024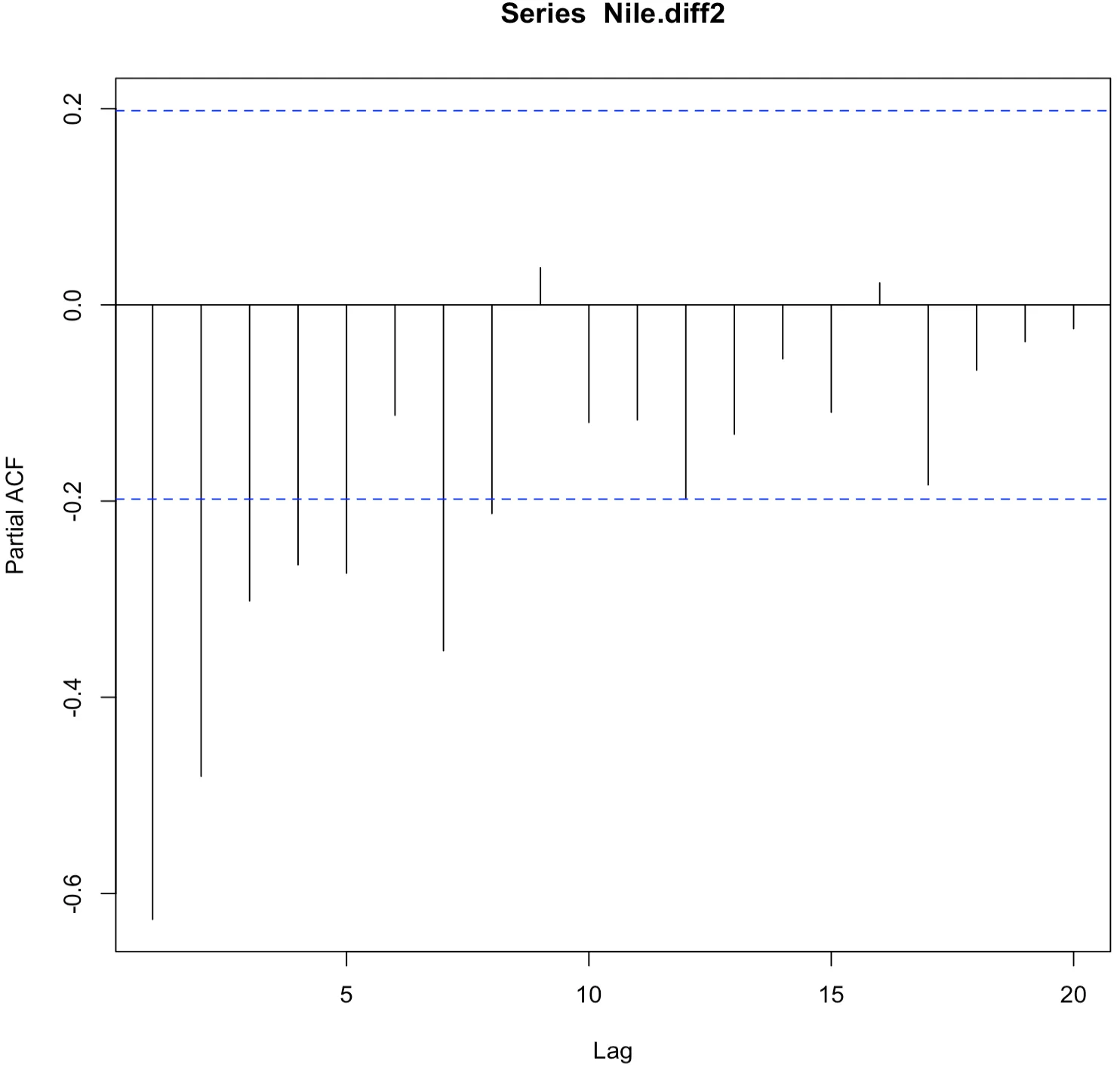
자기상관함수와 부분자기상관함수의 그래프를 종합해보면 다음과 같은 ARMA 모형이 존재 하게 된다.
- ARMA(8,0) : 부분자기상관함수 그래프에서 lag=9에서 절단되었음
- ARMA(0,1) : 자기상관함수 그래프에서 lag=2에서 절단되었음
- ARMA(p,q) : AR 모형과 MA 모형을 혼합하여 모형을 식별하고 결정해야 함
이번 예제에서는 forecast 패키지에 있는 auto.arima 함수를 사용하여 적절한 ARIMA 모형을 결정할 것이다.
> install.packages("forecast")
> library(forecast)
> auto.arima(Nile)
Series: Nile ARIMA(1,1,1)
Coefficients:
ar1 ma1
0.2544 -0.8741
s.e. 0.1194 0.0605
sigma^2 = 20177: log likelihood = -630.63
AIC=1267.25 AICc=1267.51 BIC=1275.04나일강의 연간 유입량 시계열 자료에 적절한 모형은 ARIMA(1,1,1) 모형으로 결정된 것을 알 수 있다.
- ARIMA 모형을 이용한 예측
> Nile.arima <- arima(Nile, order=c(1,1,1))
> Nile.arima
Coefficients:
ar1 ma1
0.2544 -0.8741
s.e. 0.1194 0.0605
sigma^2 estimated as 19769: log likelihood = -630.63
aic = 1267.25
# forecast 패키지의 forecast 함수를 사용하여 미래의 수치 값을 예측한다.
# h=10은 10개 년도만 예측한다는 의미이다.
> Nile.forecasts<-forecast(Nile.arima,h=10)
> Nile.forecasts
Point Forecast Lo 80 Hi 80 Lo 95 Hi 95
1971 816.1813 635.9909 996.3717 540.6039 1091.759
1972 835.5596 642.7830 1028.3363 540.7332 1130.386
1973 840.4889 643.5842 1037.3936 539.3492 1141.629
1974 841.7428 642.1115 1041.3741 536.4331 1147.053
1975 842.0617 640.0311 1044.0923 533.0826 1151.041
1976 842.1429 637.8116 1046.4741 529.6452 1154.641
1977 842.1635 635.5748 1048.7522 526.2134 1158.114
1978 842.1687 633.3514 1050.9861 522.8102 1161.527
1979 842.1701 631.1488 1053.1914 519.4408 1164.899
1980 842.1704 628.9682 1055.3727 516.1057 1168.235
> plot(Nile.forecasts)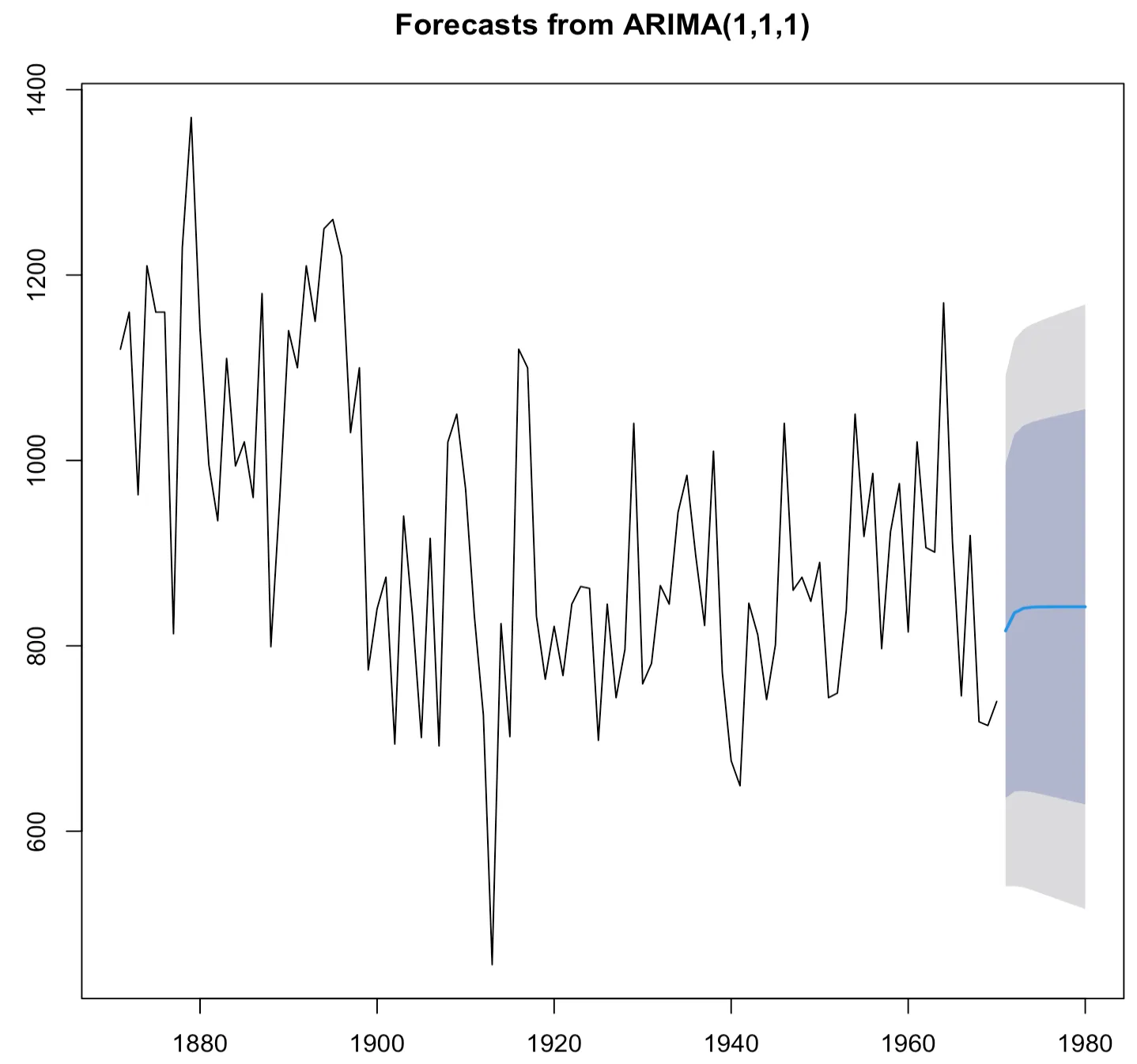
연습문제
1번
아래 보기에서 설명하는 모형으로 옳은 것은?
<보기>
시계열 자료를 모형화하는데 자기회귀모형 다음으로 많이 쓰이는 모형이며, 현 시점의 자료를 유한개의 백색잡음의 선형결합으로 표현되었기 때문에 항상 정상성을 만족한다.
1. 자기회귀 모형
2. 분해 시계열
3. 자기회귀누적이동평균 모형
4. 이동평균 모형
정답
보기의 설명은 이동평균모형에 대한 설명이다.
2번
AR 모형에 대한 설명으로 옳은 것은?
1. ACF에서 절단점을 갖고, PACF가 빠르게 감소하는 형태를 띠게 된다.
2. 시계열에 영향을 주는 일반적인 요인을 시계열에서 분리해 분석하는 방법이다.
3. t라는 시점에서의 값 는 이전 시점들 n개에 의해 설명될 수 있음을 의미한다.
4. 경제적이나 자연적인 이유 없이 알려지지 않은 주기를 가지고 변화하는 자료이다.
자기회귀 모형은 시계열 자료를 설명하기 위한 모형 중 하나로서 t라는 시점에서의 값 는 이전 시점들 n개에 의해 설명될 수 있음을 의미한다.
3번
시계열 데이터를 구성하는 요소로 옳지 않은 것은?
1. 추세요인
2. 순환요인
3. 계절요인
4. 규칙요인
정답
규칙요인이 아닌 불규칙요인이 시계열 구성요소이다
