10. 통계분석-다변량 분석
10.1. 다차원척도법
다차원 척도법 개요
다차원 척도법이란?
다차원척도법(Multidimensional Scaling, MDS)은 여러 대상 간의 거리가 주어져 있을 때, 대상들을 동일한 상대적 거리를 가진 실수공간의 점들로 배치시키는 방법을 말한다.
- 자료들의 상대적 관계를 이해하는 시각화 방법의 근간으로 주로 사용된다.
- 군집분석과 같이 개체들을 대상으로 변수들을 측정한 후에 개체들 사이의 유사성/비유사성을 측정하여 개체들을 2차원 공간상에 점으로 표현하는 분석 방법이다.
- 데이터를 축소하는 목적으로 사용된다. 즉, 데이터에 포함되는 정보를 끄집어내기 위해서 다차원척도법을 탐색수단으로 사용한다.
다차원 척도법 방법
- 개체들의 거리 계산에는 유클리드 거리행렬을 활용한다.
- 개체의 실제 거리와 모형에 의해 추정된 거리 사이의 적합도를 측정하기 위해 stress 척도를 사용한다.
- stress값을 통해 적합여부를 판단한다.
- stress 값은 0~1 사이의 값을 가지며 그 값이 낮을수록 적합도가 높다고 평가한다. 보통 0.05 이내이면 적합도가 좋다고 판단하고, 0.15 이상이면 적합도가 매우 나쁘다고 판단한다.
| stress | 적합도 |
| --- | --- |
| 0 | 완벽 |
| 0~0.05 | 매우 우수 |
| 0.05~0.1 | 우수 |
| 0.1~0.15 | 보통 |
| 0.15 이상 | 나쁨 | - 최적모형의 적합은 부적합도를 최소로 하는 방법으로 일정 수준 이하로 될 때까지 반복해서 수행한다.
다차원 척도법 종류
계량적 MDS(metric MDS)
- 데이터가 구간척도나 비율척도 및 양적척도인 경우 활용
- 개체들간의 유클리드 거리행렬을 계산하고 개체들간의 비유사성 S(거리제곱 행렬의 선형함수)를 공간상에 표현한다.
- R에서 ‘cmdscale’ 함수를 사용한다
비계량적 MDS(nonmetric MDS)
- 데이터가 순서척도, 서열척도인 경우 활용
- 개체들 간의 거리가 순서로 주어진 경우에는 순서척도를 거리의 속성과 같도록 변환하여 거리를 생성한 후 적용한다.
- R에서 ‘isoMDS’ 함수를 사용한다.
다차원 척도법 예제
# 도시 사이의 거리를 매핑한 자료인 R의 euridist를 샘플 데이터로 이용
> data(eurodist)
> eurodist
Athens Barcelona Brussels Calais Cherbourg Cologne ...
Barcelona 3313
Brussels 2963 1318
Calais 3175 1326 204
Cherbourg 3339 1294 583 460
Cologne 2762 1498 206 409 785
Copenhagen 3276 2218 966 1136 1545 760
Geneva 2610 803 677 747 853 1662
Gibraltar 4485 1172 2256 2224 2047 2436
Hamburg 2977 2018 597 714 1115 460
Hook of Holland 3030 1490 172 330 731 269
Lisbon 4532 1305 2084 2052 1827 2290
Lyons 2753 645 690 739 789 714
Madrid 3949 636 1558 1550 1347 1764
Marseilles 2865 521 1011 1059 1101 1035
Milan 2282 1014 925 1077 1209 911
Munich 2179 1365 747 977 1160 583
Paris 3000 1033 285 280 340 465
Rome 817 1460 1511 1662 1794 1497
Stockholm 3927 2868 1616 1786 2196 1403
Vienna 1991 1802 1175 1381 1588 937
...
> loc <- cmdscale(eurodist)
> loc
[,1] [,2]
Athens 2290.274680 1798.80293
Barcelona -825.382790 546.81148
Brussels 59.183341 -367.08135
Calais -82.845973 -429.91466
Cherbourg -352.499435 -290.90843
Cologne 293.689633 -405.31194
Copenhagen 681.931545 -1108.64478
...
> x <- loc[,1]
> y <- loc[,2]
> plot (x,y, type="n", main="eurodist")
> text (x, y, rownames (loc) , cex=0.8)
> abline(v=0,h=0)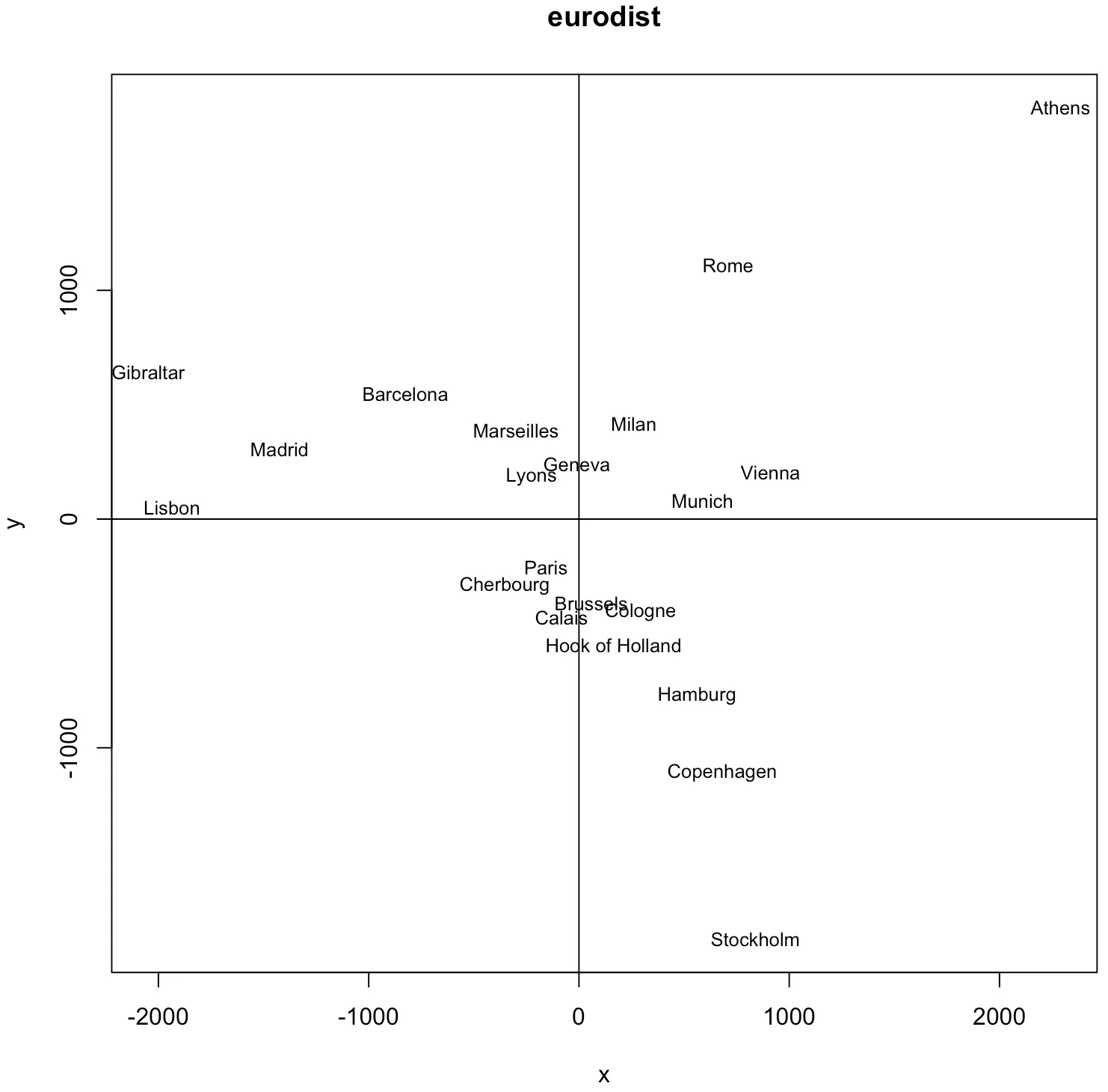
위 이미지 처럼 각 개체에 대한 특정 변수들의 관측치는 없더라도 개체 간의 유사성에 대한 자료를 사용하여 산점도를 그릴 수 있다
연습문제
1번
다차원 척도법에 대한 설명으로 옳지 않은 것은?
1. 자료들의 상대적 관계를 이해하는 시각화 방법의 근간으로 주로 사용된다.
2. 데이터 시각화 결과를 보고 회귀모형을 산출할 수 있다.
3. 데이터를 저차원 공간에 배열하는 시각화 기법 중 하나이다.
4. 데이터를 축소하는 목적으로 사용된다
정답
(2)
다차원 척도법은 시각화 기법으로 데이터 간의 거리를 표현하여 저차원 공간에 표현하는 것이 목적이다.
2번
4개의 보기 중 성격이 다른 다차원 척도법은 무엇인가?
1. 데이터가 구간척도나 비율척도인 경우 활용한다.
2. 유클리드 거리행렬을 계산한다.
3. R에서 isoMDS 함수를 사용한다.
4. 양적척도인 경우 사용한다.
정답
R에서 ‘isoMDS’ 함수를 사용하는 것은 비계량적 MDS이며, 나머지 보기는 계량적 MDS에 해당하는 내용이다.
3번
stress 값이 0~0.05일 때 적합도는 무엇인가?
1. 완벽
2. 매우 우수
3. 우수
4. 나쁨
정답
매우 우수
10.2. 주성분분석
주성분분석 개요
주성분분석이란?
주성분분석(Principal Component)이란 여러 변수 중 서로 상관성이 높은 변수들의 선형 결합으로 새로운 변수(주성분)를 만들어 기존 변수를 요약 및 축소하는 분석 방법이다.
- 새로운 변수로 생성을 위해서는 자료의 분산이 가장 큰 축(가장 손실이 작은 축)을 탐색한다.
- 아래 그림과 같이 희생되는 정보가 가장 적은 방향을 결정한다.
주성분분석 목적
다중공선성이 존재하는 경우, 상관성이 없는(적은) 주성분으로 변수들을 축소하여 모형 개발에 활용된다. 회귀분석 등의 모형 개발 시 입력변수들간의 상관 관계가 높은 다중공선성이 존재할 경우 모형이 잘못 만들어져 문제가 생긴다.
- 연관성이 높은 변수를 주성분분석을 통해 차원을 축소한 후에 군집분석을 수행하면 군집화 결과와 연산속도를 개선할 수 있다.
- 기계에서 나오는 다수의 센서 데이터를 주성분분석으로 차원을 축소한 후에 시계열로 분포나 추세의 변화를 분석하면 기계의 고장 징후를 사전에 파악하는데 활용하기도 한다.
- 모형의 설명력이 높아지고, 다중공산성 문제를 해결할 수 있고, 모형의 성능이 높아질 수 있다.
주성분분석 방법
주어진 데이터를 하나의 변수로 요약한다는 것은 하나의 관점에서 바라보는 것을 의미하며, 그에 따른 데이터 손실이 발생할 수밖에 없다. 손실이 가장 작은 축을 찾는 것, 즉 자료의 분산(퍼진 정도)이 가장 큰 축을 찾아 새로운 변수로 만드는 방법이다.
- 데이터를 가장 잘 표현하는 직교상의 데이터 벡터들을 찾아서 데이터 압축한다. 속성들을 선택하고 조합하여 다른 작은 집합을 생성한다.
- 계산이 간단하며 데이터 부족이나 일률적 데이터 혹은 정렬되지 않은 속성을 가진 데이터도 처리할 수 있다는 장점이 있다.
주성분의 선택법
- 주성분분석의 결과에서 누적기여율(Cumulative Proportion)이 85%이상이면 주성분의 수로 결정할 수 있다.
- Scree Plot을 활용하여 고윳값이 수평을 유지하기 전단계로 주성분의 수를 선택한다.
주성분분석 시각화
scree plot (스크리 플롯)
x축을 성분의 개수, y축을 고윳값으로 하는 그래프로 주성분의 개수를 선택하는 데 도움을 준다. 일반적으로 고윳값이 1 근처의 값을 갖는 주성분분석의 수를 결정할 수 있다. 그러나 또 다른 방법으로는 그래프가 수평을 이루기 전 단계를 주성분의 수로 선택할 수 있다.
biplot
첫 번째 주성분(x)과 두 번째 주성분(y)을 축으로 하는 그래프다. biplot 그래프는 다차원 척도법과 같이 주성분분석의 결과로 데이터가 어떻게 퍼져 있는지 시각화할 수 있다.
주성분분석 사례
USArrests 자료 활용
이 자료는 미국의 50개 주의 인구 10만 명 당 체포된 세 가지 강력범 죄수와 각 주마다 도시에 거주하는 인구의 비율로 구성되어 있다.
> library(datasets)
> data(USArrests)
> summary(USArrests)
Murder Assault UrbanPop Rape
Min. : 0.800 Min. : 45.0 Min. :32.00 Min. : 7.30
1st Qu.: 4.075 1st Qu.:109.0 1st Qu.:54.50 1st Qu.:15.07
Median : 7.250 Median :159.0 Median :66.00 Median :20.10
Mean : 7.788 Mean :170.8 Mean :65.54 Mean :21.23
3rd Qu.:11.250 3rd Qu.:249.0 3rd Qu.:77.75 3rd Qu.:26.18
Max. :17.400 Max. :337.0 Max. :91.00 Max. :46.00
> fit <- princomp(USArrests, cor = TRUE)
> summary(fit)
Importance of components:
Comp.1 Comp.2 Comp.3 Comp.4
Standard deviation 1.5748783 0.9948694 0.5971291 0.41644938
Proportion of Variance 0.6200604 0.2474413 0.0891408 0.04335752
**Cumulative Proportion** 0.6200604 0.8675017 0.9566425 1.00000000
> loadings(fit)
Loadings:
Comp.1 Comp.2 Comp.3 Comp.4
Murder 0.536 0.418 0.341 0.649
Assault 0.583 0.188 0.268 -0.743
UrbanPop 0.278 -0.873 0.378 0.134
Rape 0.543 -0.167 -0.818
Comp.1 Comp.2 Comp.3 Comp.4
SS loadings 1.00 1.00 1.00 1.00
Proportion Var 0.25 0.25 0.25 0.25
Cumulative Var 0.25 0.50 0.75 1.00
> plot(fit,type="lines")주성분분석은 R 함수 princomp를 이용하여 수행되었고, 그 결과는 fit이라는 이름으로 저장되었다. cor=TRUE 옵션은 주성분분석을 공분산행렬이 아닌 상관계수 행렬을 사용하여 수행하도록 한다. summary(fit)의 결과는 4개의 주성분의 표준편차, 분산의 비율 등을 보여준다. 제1주성분과 제2주성분까지의 누적 분산비율은 대략 86.8%로 2개의 주성분 변수를 활용하여 전체 데이터의 86.8%를 설명할 수 있다. loadings(fit) 함수는 주성분들의 로딩 벡터들을 보여준다.
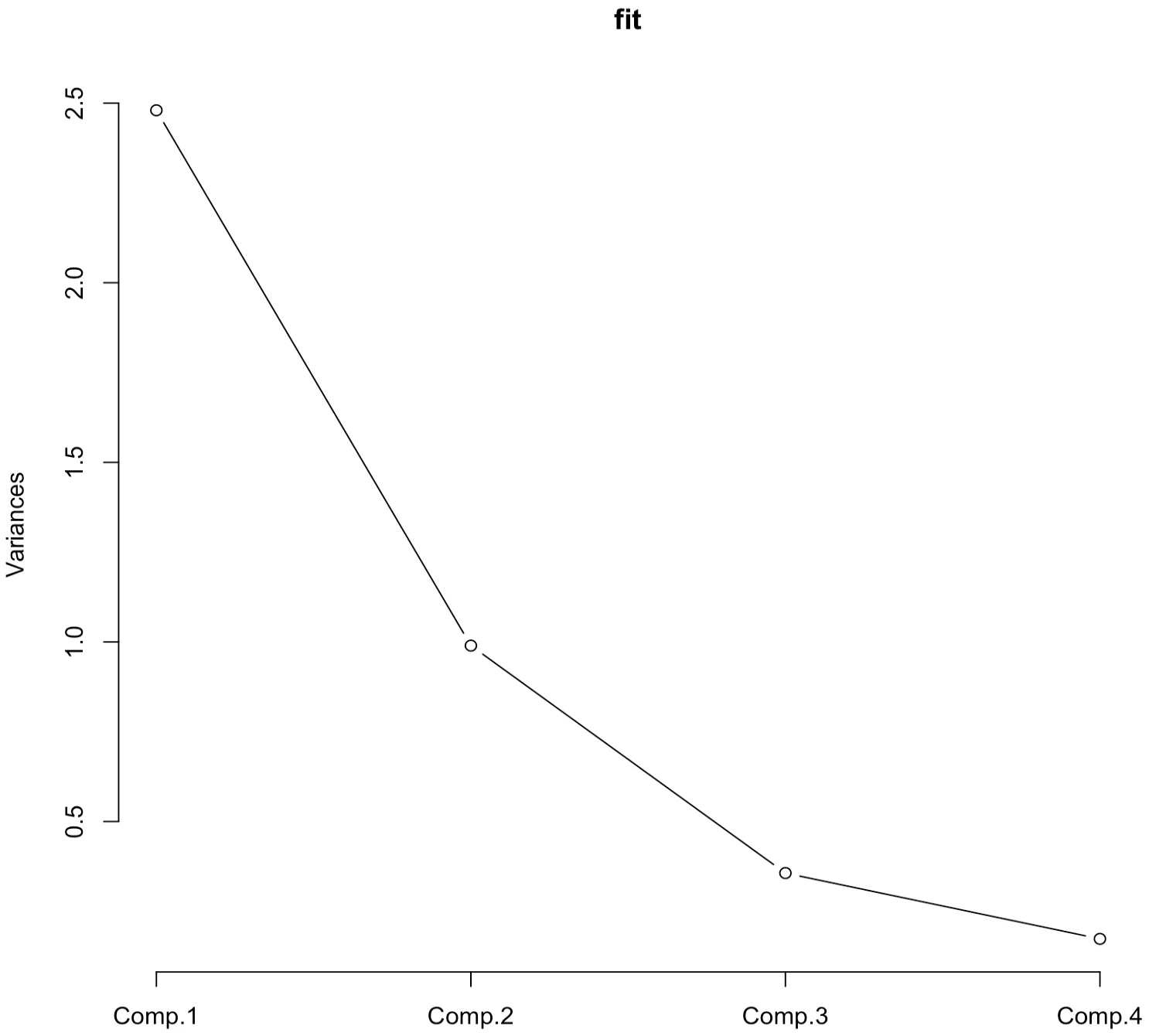
plot(fit) 함수는 각 주성분의 분산의 크기를 그림으로 그려준다. 이 그림을 스크리 그림(Scree plot)이라고 한다. 이를 통해서 주성분의 분산의 감소가 급격하게 줄어들어 주성분의 개수를 늘릴 때 얻게되는 정보의 양이 상대적으로 미미한 지점에서 주성분의 개수를 정하는 것이 하나의 방법이다. 그 외에도 주성분들이 설명하는 총 분산의 비율이 70~90% 사이가 되는 주성분의 개수를 선택하는 방법을 사용하기도 한다.
> fit$scores
Comp.1 Comp.2 Comp.3 Comp.4
Alabama 0.98556588 1.13339238 0.44426879 0.156267145
Alaska 1.95013775 1.07321326 -2.04000333 -0.438583440
Arizona 1.76316354 -0.74595678 -0.05478082 -0.834652924
Arkansas -0.14142029 1.11979678 -0.11457369 -0.182810896
...
> biplot(fit)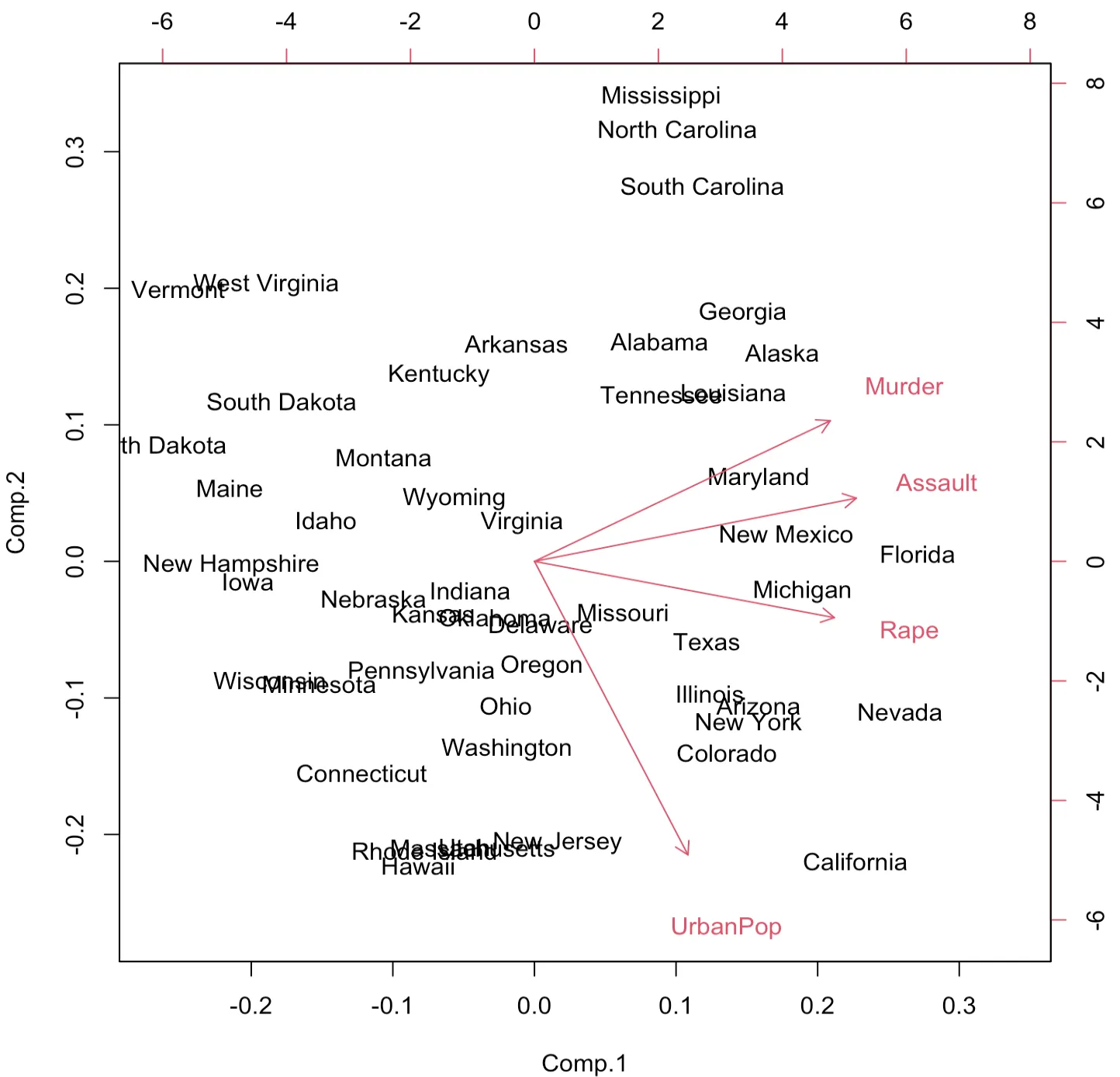
fit$scores는 각 관측치를 주성분들로 표현한 값을 나타낸다. biplot은 관측치들을 첫 번째와 두 번째 주성분의 좌표에 그린 그림이다. 첫 번째 주성분(Comp. 1)이 Assault, Murder, Rape와 비슷한 방향을 가지고 UrbanPop과 방향이 수직에 가까운 것으로 보아 첫 번째 주성분이 주로 Assault, Murder, Rape 변수들에 대해 상대적으로 큰 가중치를 적용하여 계산된 것을 알 수 있다. 두 번째 주성분은 UrbanPop과 상대적으로 평행하기 때문에 다른 변수들에 비해 UrbanPop의 영향을 크게 받아 구성된 것으로 보인다.
연습문제
1번
아래 이미지의 주성분분석 결과에 대한 설명으로 옳지 않은 것은?
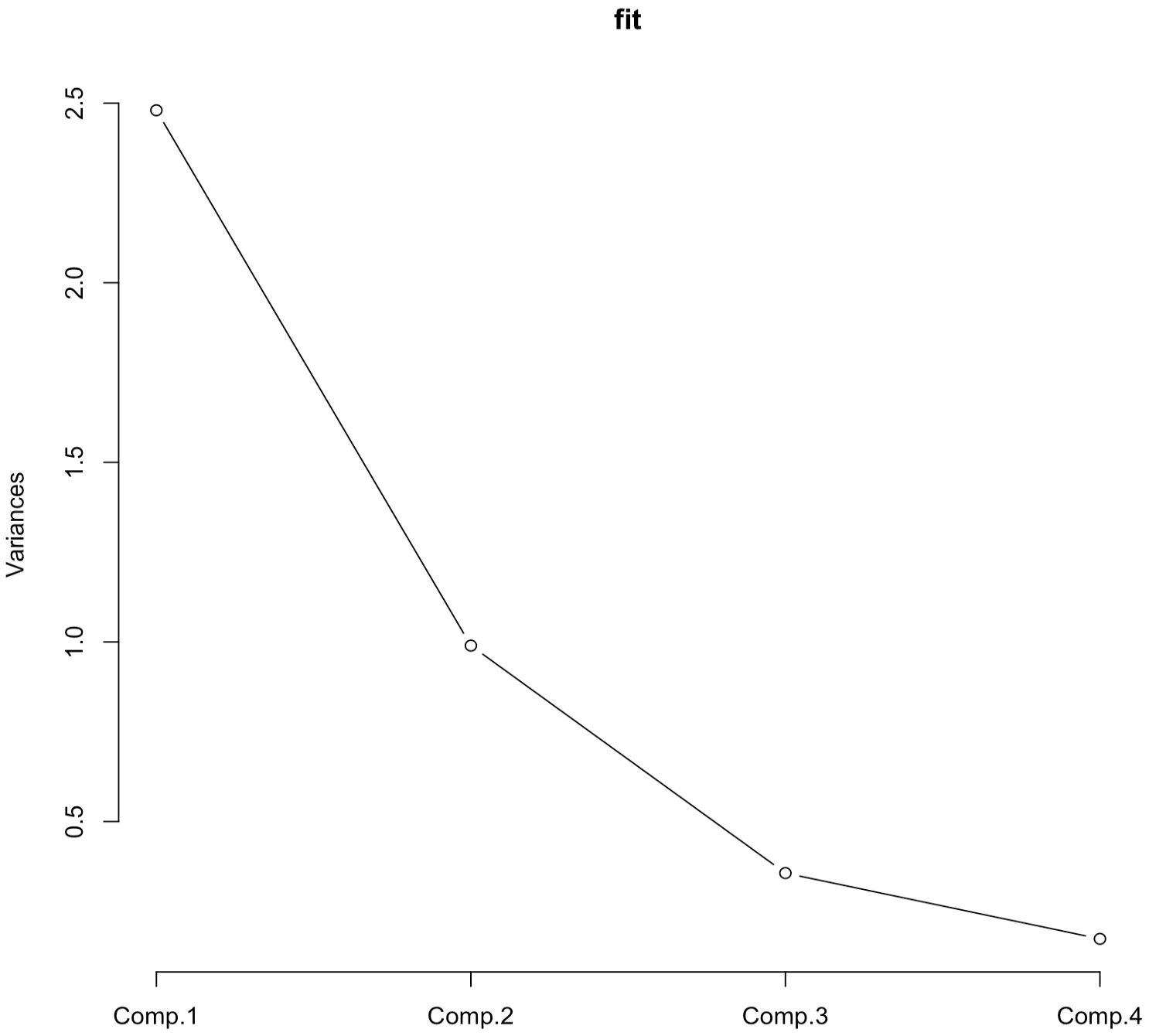
1. 그래프가 수평을 이루기 전 단계를 주성분의 수로 선택할 수 있다.
2. 관측치들을 첫 번째와 두 번째 주성분의 좌표에 그린 그림이다.
3. 주성분의 분산의 감소가 급격하게 줄어들어 주성분의 개수를 늘릴 때 얻게되는 정보의 양이 상대적으로 미미한 지점에서 주성분의 개수를 정하는 것이 하나의 방법이다.
4. 주성분의 분산의 크기를 보여주는 스크리 그림(Scree plot)이다.
정답
관측치들을 첫 번째와 두 번째 주성분의 좌표에 그린 그림은 biplot이다.
2번
주성분 분석의 목적으로 옳지 않은 것은?
1. 다중공선성 문제 해결
2. IoT 센서 데이터를 주성분분석 후 스마트팩토리에 활용
3. 군집분석 시 모형의 성능을 높일 수 있음
4. 변수를 축소하여 모형의 설명력을 낮춤
정답
변수를 축소하여 모형의 설명력을 높인다.
3번
주성분의 개수를 결정하는데 영향을 미치는 요소로 적절한 것은?
1. 주성분 개수는 데이터의 행의 수에만 의존한다
2. 주성분 개수는 사용자의 주관적인 결정에 의해 결정된다.
3. 주성분 개수는 각 주성분의 설명력에 따라 결정된다.
4. 주성분 개수는 변수의 수에만 의존한다.
정답
주성분 분석에서는 각 주성분이 데이터의 분산을 얼마나 설명하는지에 따라 주성분의 개수를 결정한다.
