13. 정형 데이터 마이닝 - 분류분석
13.1 로지스틱 회귀분석
분류분석
분류분석이란
반응변수(또는 종속변수)가 알려진 다변량 자료를 이용하여 모형을 구축하고, 이를 통해 새로운 자료에 대한 예측 및 분류를 수행하는 것이 목적입니다. 즉, 주어진 데이터를 미리 정의된 여러 클래스 중 하나로 분류하는 작업을 의미합니다.
- 반응변수가 범주형인 경우의 예측모형은 새로운 자료에 대한 분류가 주목적이며, 반응변수가 연속형인 경우에는 그 값을 예측하는 것이 주목적이라고 할 수 있습니다. 따라서 예측과 분류는 유사한 의미로 사용됩니다.
분류분석, 예측분석 공통점
코드의 특정 속성의 값을 미리 알아맞히는 점
분류분석, 예측분석 차이점
분류 : 레코드의 범주형 속성의 값을 알아맞히는 것
- 예시) 이메일의 내용, 제목으로 스팸여부 알아맞히는 것
예측 : 레코드의 연속형 속성의 값을 알아맞히는 것
- 예시) 지역 특성, 인구 통계, 인프라 등을 통해 미래의 부동산 가격을 알아맞히는 것
많이 사용되는 분류 분석 모형
로지스틱회귀, 의사결정나무, 인공신경망, 앙상블, k최근접 이웃, 나이브 베이즈 등이 있습니다.
로지스틱 회귀분석
로지스틱 회귀분석 개념(중)
로지스틱 회귀분석은 종속 변수가 범주형 데이터인 경우에 사용되는 통계 분석 기법 중 하나이다.
- 새로운 독립변수의 값이 주어질 때 종속변수 각 범주에 속할 확률이 얼마인지를 추정하여, 추정 확률을 기준치에 따라 분류하는 목적으로 사용될 수도 있다. 이때, 모형의 적합을 통해 추정된 확률을 사후확률이라 부르기도 한다.
- 주로 이진 분류가 기본이며, 세 개 이상의 집단을 분류하는 경우 이를 다중 로지스틱 회귀분석이라고 한다.
- 로지스틱 회귀분석은 독립변수가 연속형, 종속변수가 범주형일 때 가능하다. 만약 독립변수가 범주형일 경우에는 그 범주형 독립변수를 더미변수로 변환하면 가능하다.
더미변수란?
범주형 자료를 표현하는 데 사용되는 이진 변수(0 또는 1의 값)이다. 예를 들어 남성은 1, 여성은 0으로 표현할 수 있다.
다중 로지스틱 회귀모형의 일반적인 형태
- 로지스틱 회귀분석의 종속변수는 항상 0과 1사이의 값을 가지는데, 이를 위해 오즈, 로짓 변환, 시그모이드 함수 같은 개념이 등장하게 된다.
선형회귀분석과 로지스틱 회귀분석의 비교
| 목적 | 선형회귀 분석 | 로지스틱 회귀분석 |
|---|---|---|
| 종속변수 | 연속형 변수 | (0,1) |
| 계수 추정법 | 최소제곱법 | 최대우도추정법 |
| 모형 검정 | F-검정, t-검정 | 카이제곱 검정(-test) |
참고하면 좋을 내용 👀
최대우도추정법 (MLE : Maximum Likelihood Estimation)
- 우도란, 주어진 데이터가 어떤 확률 분포에서 나왔을 때, 해당 모수가 얼마나 '그럴듯한'지를 나타내는 것이다.
- 최대우도추정법은 확률 분포의 모수를 추정하는 통계적 방법 중 하나이다. 최대 우도는 주어진 데이터가 주어진 모수 아래에서 가장 가능성(우도)이 높은 값을 찾는 것을 목표로 한다.
- 우도 L(θ|x)는 θ가 전제되었을 때 표본 x가 등장할 확률인 p(x|θ)에 비례한다.
로지스틱 회귀분석의 알고리즘(중)
오즈(Odds)
로지스틱 회귀분석을 사용하기 위해서는 ‘오즈’라는 값을 사용한다.
오즈란, 성공할 확률이 실패할 확률의 몇 배인지를 나타내는 값이다. 따라서 오즈를 사용하여 각 범주(집단)에 분류될 확률 값을 추정한다.
- 예를 들어, 4번의 성공과 1번의 실패를 경험했다면 오즈는 이다.
- 독립변수(x)가 주어졌을 때 성공확률을 P라고 하면 실패 확률은 1-P이고 이때 오즈 값은 이다.
- 로지스틱 회귀분석의 추정식으로부터 오즈값을 도출하면 아래의 식을 얻을 수 있다.
- 이는 독립변수 가 1만큼 증가할 때 의 제곱만큼 오즈 값(성공 확률)이 증가함을 의미한다.
로짓변환
- 오즈의 한계
- 음수를 가질 수 없다
- 확률값과 오즈의 그래프는 비대칭성을 띤다
- 위 한계를 극복하기 위해 오즈에 로그를 취한 것이 로짓(logit)이며, 이를 로짓 변환이라고 한다.
- 로짓 변환은 다음과 같이 정의된다.
- 오즈의 범위가 무한대에서 확장되며 확률과 로짓값의 그래프는 성공확률 0.5를 기준으로 대칭 형태를 띠게 된다.
- 로짓변환을 이용한 회귀분석식은 다음과 같이 정의된다.
시그모이드 함수
시그모이드 함수는 로지스틱 회귀분석과 인공신경망 분석에서 활성화 함수로 활용되는 함수 중 하나다. 로짓 함수와 역함수 관계이기 때문에 로짓함수를 통해 시그모이드 함수가 도출된다.
- 시그모이드 함수식은 다음과 같이 정의된다.
로지스틱 회귀분석 예제
예제 1
R에서 로지스틱회귀모형은 glm()함수를 이용하여 수행한다.
반응변수의 범주가 2개인 로지스틱회귀를 적용하기 위해 iris 자료의 일부분만 이용하기로 한다. Species가 setosa와 versicolor인 100개의 자료만을 이용한다.
> data("iris")
> a<-subset(iris,Species=='setosa'|Species=='versicolor')
> a$Species<-factor(a$Species)
> str(a)
'data.frame': 100 obs. of 5 variables:
$ Sepal.Length: num 5.1 4.9 4.7 4.6 5 5.4 4.6 5 4.4 4.9 ...
$ Sepal.Width : num 3.5 3 3.2 3.1 3.6 3.9 3.4 3.4 2.9 3.1 ...
$ Petal.Length: num 1.4 1.4 1.3 1.5 1.4 1.7 1.4 1.5 1.4 1.5 ...
$ Petal.Width : num 0.2 0.2 0.2 0.2 0.2 0.4 0.3 0.2 0.2 0.1 ...
$ Species : Factor w/ 2 levels "setosa","versicolor":
1 1 1 1 1 1 1 1 1 1 ...Species는 Factor형 변수(범주형 변수를 의미)로 setosa는 Y=1, versicolor는 Y=2로 인식하고 있음을 나타낸다. 이 자료에 대해 로지스틱회귀가 적용될 때, 보다 큰 숫자인 versicolor일 때 오즈를 모형화하므로 해석에 유의할 필요가 있다.
glm() 함수를 이용하여 로지스틱 회귀모형을 수행한다. 이때 family= binomial 옵션을 사용한다. summary() 함수를 통해 그 결과를 확인할 수 있다.
# glm(종속변수 ~ 독립변수1+...+독립변수k, family=binomial, data=데이터셋명)
> b<-glm(Species~Sepal.Length,data=a,family=binomial)
> summary(b)Call:glm(formula = Species ~ Sepal.Length, family = binomial, data = a)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -27.831 5.434 -5.122 3.02e-07 ***
Sepal.Length 5.140 1.007 5.107 3.28e-07 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 138.629 on 99 degrees of freedom
Residual deviance: 64.211 on 98 degrees of freedom
AIC: 68.211
Number of Fisher Scoring iterations: 6
# Null deviance : 절편만 포함한 모형의 완전 모형으로부터의 이탈도
# 값이 작을수록 완전 모형에 가깝다.
# Residual deviance : 독립변수들이 추가된 모형의 완전 모형으로부터의 이탈도
# 값이 작을수록 완전 모형에 가깝다.회귀계수의 검정에서 p-값이 거의 0이므로 Sepal.Length가 매우 유의한 변수이며, Sepal.Length가 한 단위 증가함에 따라 Versicolor(Y=2)일 오즈가 exp(5.140) ≈ 170배 증가함을 알 수 있다. 위 결과의 마지막 부분에 제시된 Null deviance는 절편만 포함하는 모형( : = 0 하의 모형)의 완전모형으로부터의 이탈도(deviance)를 나타내며 p-값= P( (99) > 138.629) ≈ 0.005 으로 통계적으로 유의하므로 적합결여를 나타낸다. Residual deviance는 예측변수 Sepal.Length가 추가된 적합 모형의 이탈도를 나타낸다. Null deviance에 비해 자유도 1 기준에 이탈도의 감소가 74.4 정도의 큰 감소를 보이며, p-값=P( (98) > 64.211) ≈ 0.997 이므로 귀무가설을 기각하지 못한다. 따라서 적합값이 관측된 자료를 잘 적합하고 있다고 말할 수 있다
> coef(b)
(Intercept) Sepal.Length
-27.831451 5.140336
> exp(coef(b)['Sepal.Length'])
Sepal.Length
170.7732회귀계수 β와 오즈의 증가량 exp(β)에 대한 신뢰구간은 다음과 같다.
> confint(b,parm = 'Sepal.Length')
Waiting for profiling to be done...
2.5 % 97.5 %
3.421613 7.415508
> exp(confint(b,parm = 'Sepal.Length'))
Waiting for profiling to be done...
2.5 % 97.5 %
30.61878 1661.55385fitted() 함수를 통해 적합 결과를 확인할 수 있다.
> fitted(b)[c(1:5,96:100)]
1 2 3 4 5
0.16579367 0.06637193 0.02479825 0.01498061 0.10623680
96 97 98 99 100
0.81282396 0.81282396 0.98268360 0.16579367 0.81282396 predict() 함수를 이용하여 새로운 자료에 대한 예측을 수행한다. 여기서는 편의성 모형구축에 사용된 자료를 다시 사용한다.
> predict(b,newdata = a[c(1,50,51,100),],type='response')
1 50 51 100
0.1657937 0.1062368 0.9997116 0.8128240cdplot() 함수는 Sepal.Length(연속형 변수)의 변화에 따른 범주형 변수의 조건부 분포를 보여준다. 아래의 그림은 Sepal.Length가 커짐에 따라 versicolor의 확률이 증가함을 보여준다. 이 함수는 로지스틱회귀의 탐색적 분석에 유용하다.
> cdplot(Species~Sepal.Length,data=a)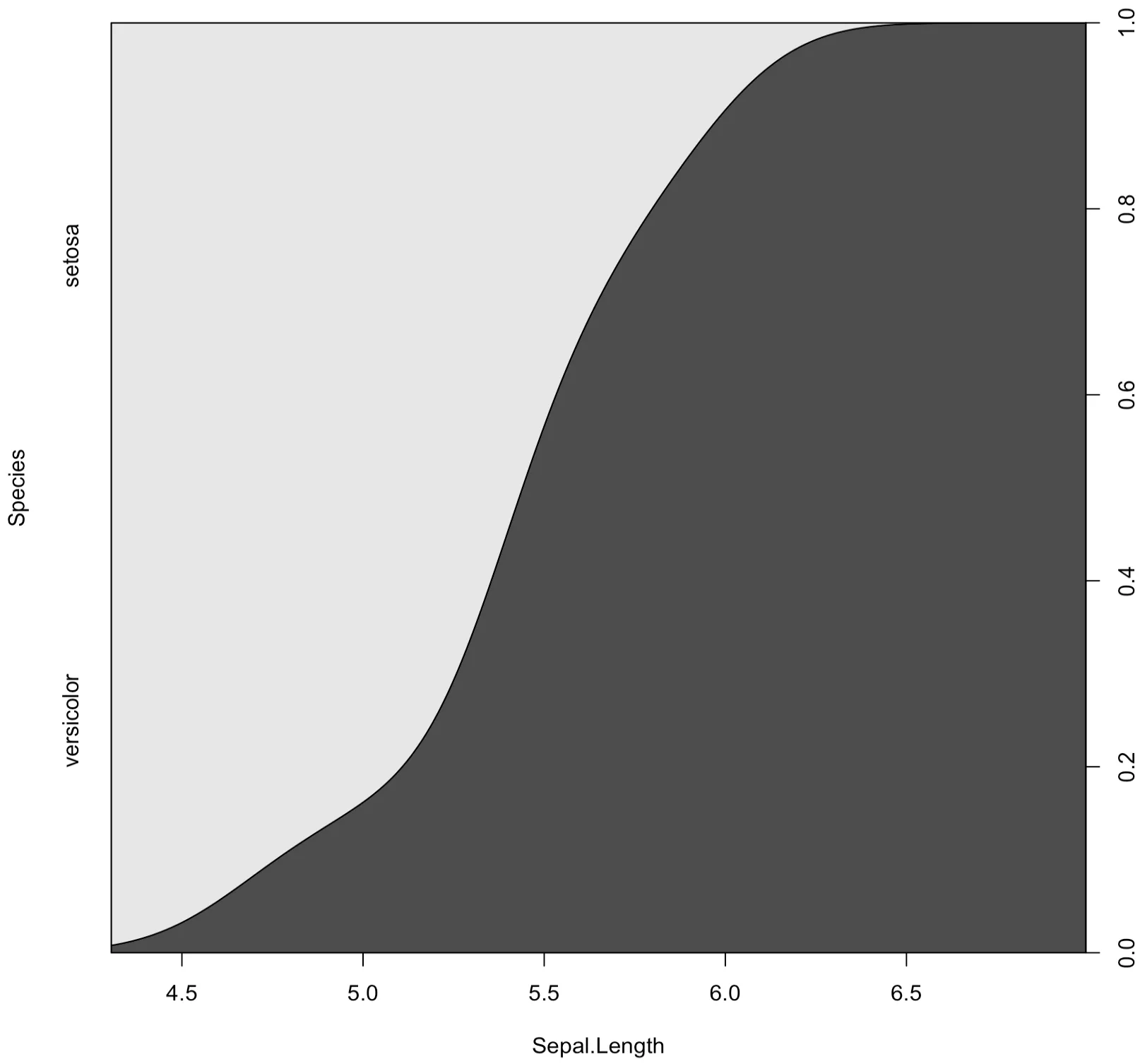
적합된 로지스틱회귀모형의 그래프를 아래와 같다.
> plot(a$Sepal.Length,a$Species,xlab = 'Sepal.Length')
> x=seq(min(a$Sepal.Length),max(a$Sepal.Length),0.1)
> lines(x,1+(1/(1+(1/exp(-27.831+5.140*x)))),type = 'o',col='red')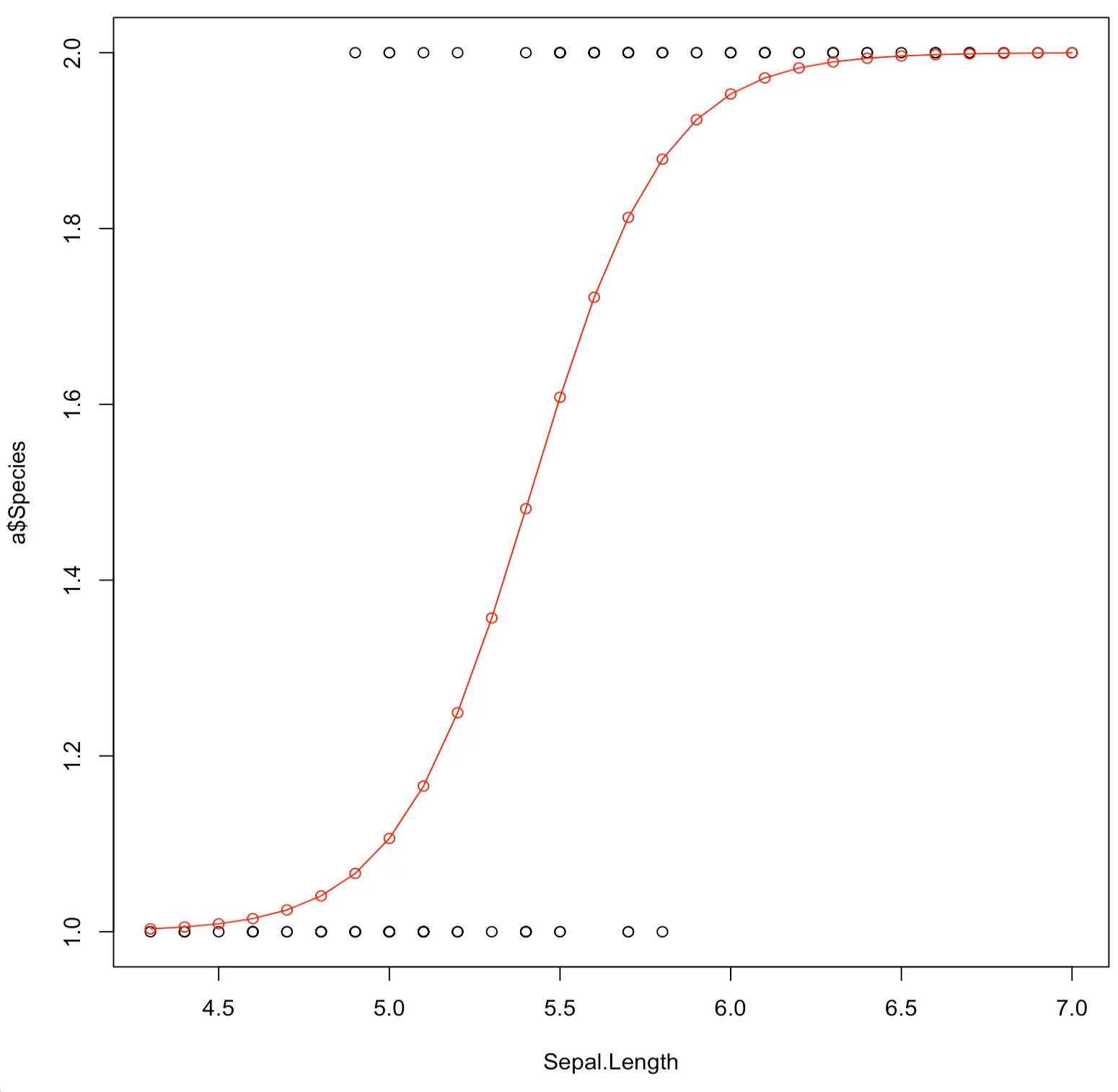
예제2
예제 2는 예측변수가 여러 개인 다중 로지스틱회귀모형을 사용하여 분석한 결과이다.
분석에 사용되는 자료는 1973~1974 년도에 생산된 32종류의 자동차에 대해 11개 변수값을 측정한 자료이다.
> attach(mtcars)
> str(mtcars)'data.frame': 32 obs. of 11 variables:
$ mpg : num 21 21 22.8 21.4 18.7 18.1 14.3 24.4 22.8 19.2 ...
$ cyl : num 6 6 4 6 8 6 8 4 4 6 ...
$ disp: num 160 160 108 258 360 ...
$ hp : num 110 110 93 110 175 105 245 62 95 123 ...
$ drat: num 3.9 3.9 3.85 3.08 3.15 2.76 3.21 3.69 3.92 3.92 ...
$ wt : num 2.62 2.88 2.32 3.21 3.44 ...
$ qsec: num 16.5 17 18.6 19.4 17 ...
$ vs : num 0 0 1 1 0 1 0 1 1 1 ...
$ am : num 1 1 1 0 0 0 0 0 0 0 ...
$ gear: num 4 4 4 3 3 3 3 4 4 4 ...
$ carb: num 4 4 1 1 2 1 4 2 2 4 ...이항 변수 vs(0:flat engine, 1:straight engine)를 반응변수로, mpg(miles/gallon)와 am(Transmission:0=automatic, 1:manual)을 예측변수로 하는 로지스틱회귀모형을 이용하면 다음과 같다. 아래 glm() 함수의 적용 시 family=binomial은 family=binomial(logit)과 동일하다.
> glm.vs <- glm(vs~mpg+am, data=mtcars, family = binomial)
> summary(glm.vs)
Call:glm(formula = vs ~ mpg + am, family = binomial, data = mtcars)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -12.7051 4.6252 -2.747 0.00602 **
mpg 0.6809 0.2524 2.698 0.00697 **
am -3.0073 1.5995 -1.880 0.06009 .
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 43.860 on 31 degrees of freedom
Residual deviance: 20.646 on 29 degrees of freedom
AIC: 26.646
Number of Fisher Scoring iterations: 6다중로지스틱에서 추정된 회귀계수 에 대한 해석은 다음과 같다. 다른 모든 변수들(여기서는 am)이 주어질 때, mpg 값이 한 단위 증가함에 따라 vs가 1일 오즈가 exp(0.6809) ≈ 1.98배(즉, 98%) 증가한다. 마찬가지로, mpg가 주어질 때, 오즈에 대한 am의 효과는 exp(-3.0073) ≈ 0.05배 즉, 변속기가 수동인 경우 자동에 비해 vs=1의 오즈가 95%나 감소한다.
예측변수가 여러 개인 모형의 적합 시 변수선택법을 적용하기 위해서는 direction= 옵션을 사용한다. direction= 옵션에는 ‘both’, ‘backward’, ‘forward’가 있으며, 디폴트는 ‘backward’가 적용된다.
> step.vs<-step(glm.vs,direction='backward')
Start: AIC=26.65
vs ~ mpg + am
Df Deviance AIC
<none> 20.646 26.646
- am 1 25.533 29.533
- mpg 1 42.953 46.953아래의 summary() 함수를 수행한 결과는 위의 summary(glm.vs)의 결과와 동일하므로 생략하기로 한다.
> summary(step.vs)gIm() 함수의 수행결과는 많은 유용한 결과를 제공한다. 예를 들어 glm.vsfitted, glm.vseffects 등이 있으며 ls(), str()함수를 통해 확인할 수 있다.
> ls(glm.vs)
> str(glm.vs)아래의 anova() 함수는 모형의 적합(변수가 추가되는) 단계별로 이탈도의 감소량과 유의성 검정 결과를 제시해 준다.
> anova(glm.vs, test='Chisq')
Analysis of Deviance Table
Model: binomial, link: logit
Response: vs
Terms added sequentially (first to last)
Df Deviance Resid. Df Resid. Dev Pr(>Chi)
NULL 31 43.860
mpg 1 18.327 30 25.533 1.861e-05 ***
am 1 4.887 29 20.646 0.02706 *
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1위의 결과는 절편항만 포함하는 영(nul) 모형에서 mpg와 am 변수가 차례로 모형에 추가됨에 따라 발생하는 이탈도의 감소량을 제시하며, p-값은 각각 을 계산한 값이다. 그 결과 두 변수가 차례로 추가되면서 생겨나는 이탈도의 감소량이 모두 통계적으로 유의함을 나타낸다.
> 1-pchisq(18.327, 1)
[1] 1.860515e-05
> 1-pchisq(4.887, 1)
[1] 0.02705967로지스틱회귀모형은 일반화선형모형의 특별한 경우로 로짓 모형으로도 불린다. 반응변수의 범주가 3개 이상인 경우에는, 범주의 유형(명목형 또는 순서형)에 따라, 다양한 다범주(multi-category) 로짓모형을 적합할 수 있다.
연습문제
1번
로지스틱 분석에 대한 설명으로 옳지 않은 것은?
1. 종속 변수가 범주형 데이터인 경우에 사용되는 통계 분석 기법 중 하나이다.
2. 두 개 이상의 집단을 분류하는 경우 이를 다중 로지스틱 회귀분석이라고 한다.
3. 로지스틱 회귀분석의 종속변수는 범주형이다.
4. 성공횟수가 10이고 실패 횟수가 1이면 오즈값은 10이다.
정답
세 개 이상의 집단을 분류하는 경우 이를 다중 로지스틱 회귀분석이라고 한다.
2번
로지스틱 회귀분석의 알고리즘에 대한 설명으로 옳지 않은 것은?
1. 오즈값이란 실패 확률을 성공 확률로 나눈 값이다.
2. 독립변수(x)가 주어졌을 때 성공확률을 P라고 하면 실패 확률은 1-P이다.
3. 시그모이드 함수는 로지스틱 회귀분석과 인공신경망 분석에서 활성화 함수로 활용되는 함수 중 하나다.
4. 종속변수(y)는 0과 1사이의 확률값을 반환하므로 이진 분류에 적합하다.
정답
오즈값이란 성공 확률을 실패 확률로 나눈 값이다.
3번
회사 재무상태에 관련한 여러 변수를 활용하여 기업의 파산 여부를 판단하려고 할 때, 모형 구축에 적절한 기법은 무엇인가?
1. 시계열 분석
2. 로지스틱 회귀분석
3. 회귀분석
4. 군집분석
정답
파산여부 YES/NO의 이진분류를 위해서는 로지스틱 회귀분석이 가장 적절하다.
13.2 의사결정나무
의사결정나무 개요
의사결정나무
나무(tree) 구조로 나타내어 전체 자료를 몇 개의 소집단으로 분류하거나 예측을 수행하는 분석방법으로 의사결정이 진행되는 방식을 한눈에 볼 수 있다.
- 상위 노드로부터 하위노드로 나무 구조를 형성하는 매 단계마다 분류변수와 분류기준값의 선택이 중요하다.
- 하위노드에서 노드(집단) 내에서는 동질성이, 노드(집단) 간에는 이질성이 가장 커지도록 선택된다. 나무 모형의 크기는 과대적합(또는 과소적합) 되지 않도록 합리적 기준에 의해 적당히 조절되어야 한다.
- 계산 결과가 의사결정나무에 직접 나타나기 때문에 해석이 간편하다.
- 주어진 입력값에 대하여 출력값을 예측하는 모형으로 분류나무와 회귀나무 모형이 있다.
- 의사결정나무는 종속변수가 연속형인 회귀나무와 종속변수가 이산형인 분류나무로 구분된다.
의사결정나무의 구성요소
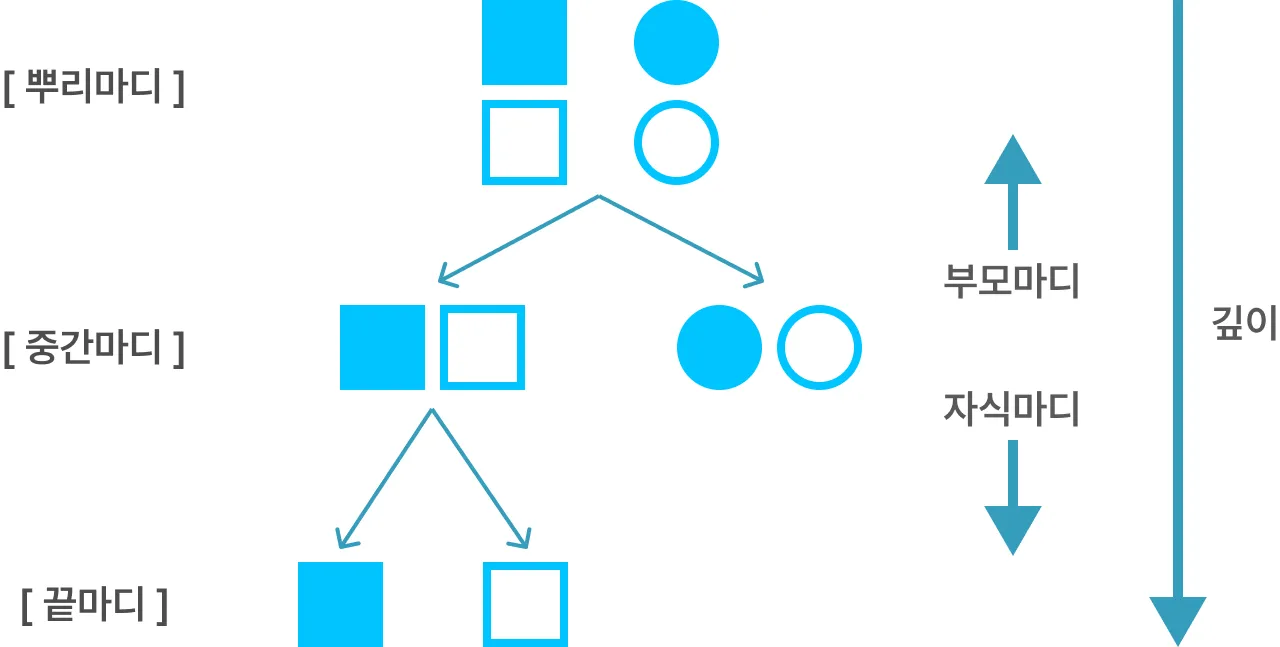
- 뿌리마디 : 시작되는 마디로 전체 자료를 포함
- 자식마디 : 하나의 마디로부터 나온 2개 이상의 하위 마디들
- 부모마디 : 모든 자식마디의 바로 상위 마디
- 끝마디 : 자식마디가 없는 최하위 마디
- 중간마디 : 부모마디와 자식마디가 모두 있는 마디
- 가지 : 뿌리마디부터 끝마디까지 연결된 마디들
- 깊이 : 뿌리마디부터 끝마디까지의 중간마디들의 수
의사결정나무의 활용(중)
- 세분화
- 비슷한 특성을 갖는 몇 개의 그룹으로 분할하여 그룹별 특성을 발견하는 것
- 분류
- 여러 독립변수들에 근거해 종속변수의 범주를 몇 개의 등급으로 분류
- 예측
- 자료(데이터)에서 규칙을 찾고 이를 미래 사건 예측에 활용
- 차원 축소 및 변수 선택
- 여러 독립변수들 중에서 종속변수에 큰 영향을 미치는 변수를 골라내는 경우 사용하는 기법
- 교호작용
- 여러 개의 독립변수들을 결합하여 종속변수에 작용하는 규칙을 파악
- 범주의 병합 또는 연속형 변수의 이산화 : 범주형 종속변수의 범주를 소수의 몇 개로 병합하거나 연속형 종속변수를 몇 개의 등급으로 이산화하고자 하는 경우
의사결정나무의 특징 (중)

- 데이터의 선형성, 정규성 등의 가정이 불필요하다.
- 대용량 데이터에서도 빠르게 만들 수 있다.
- 독립변수들 사이의 중요도를 판단하기 쉽지 않다.
- 새로운 자료에 대한 과적합 발생 가능성이 높다.
- 분류 경계선 근처의 자료값에 대해 오차가 크다.
의사결정나무 분석과정 (중)
의사결정나무의 형성과정은 크게 성장, 가지치기, 타당성 평가, 해석 및 예측으로 이루어진다.
1. 성장 단계
각 마디에서 적절한 최적의 분리규칙을 찾아서 나무를 성장시키는 과정으로 적절한 정지규칙을 만족하면 중단한다.
분리규칙
- 분리 변수가 연속형인 경우 :
- 분리 변수가 범주형 {1,2,3,4}인 경우 와 으로 나눌 수 있다.
- 최적의 분할은 불순도 감소량을 가장 크게 하는 분할이다.
불순도란?
자료들의 범주가 한 그룹 안에 얼마나 섞여 있는지를 나타내는 측도로
분류가 잘 되어 하나의 범주로만 구성되어 있으면 불순도 값은 작고, 다양한 범주의 데이터로 구성되어 있으면 불순도 값은 크다.
분리기준
-
종속변수가 이산형일 경우
분류트리를 사용하며 분리 기준으로 카이제곱 검정, 지니 지수, 엔트로피 지수 등을 사용한다.
-
종속변수가 연속형일 경우
회귀트리를 사용하며, 분리 기준으로 분산분석에서의 F통계량, 분산의 감소량 등을 사용한다. -
이산형 목표변수

카이제곱통계량 p값, 지니지수, 엔트로피 지수
- 연속형 목표변수
ANOVA F-통계량, 분산의 감소량
2. 가지치기 단계
오차를 크게 할 위험이 높거나 부적절한 추론규칙을 가지고 있는 가지 또는 불필요한 가지를 제거하는 단계이다.
- 쉽게 말해, 의사결정나무의 성장이 끝났지만 모형이 너무 복잡한 경우 과적합이 발생할 수 있어 일부 가지를 적당히 제거하여 적당한 크기의 완성된 의사결정나무 모형으로 만들어준다.
- 모형이 복잡한 경우 과적합이, 너무 단순한 경우 과소적합이 발생할 수 있다.
- 자료가 일정 수(가령 5) 이하일 때 분할을 정지하고 비용-복잡도 가지치기를 이용하여 성장시킨 나무를 가지치기하게 된다
3. 타당성 평가 단계
타당성 평가 단계에서는 형성된 의사결정나무를 평가하는 단계다. 이익도표(Gain Chart), 위험도표(Risk Chart), 혹은 시험자료를 이용하여 의사결정나무를 평가하는 단계다.
4. 해석 및 예측 단계
구축된 의사결정나무의 모형을 해석하고 예측에 적용하는 단계다.
불순도의 여러 가지 측도
대표적인 불순도로 카이제곱 통계량, 지니지수, 엔트로피 지수 등이 있다.
카이제곱 통계량
- 기대도수 = 열의 합계 X 합의 합계 / 전체 합계
(ex. 동전의 앞면과 뒷면이 나올 확률 = 확률)$$ (X^2)=\sum^k_{i=1} \frac{(O_i-E_i)^2}{E_i}\\ (k : 범주의 수, O_i : 실제도수, E_i : 기대도수) $$ - 카이제곱 통계량 예제
동전 4개 중에 앞면이 나온 동전 3개, 뒷면이 나온 동전 1개가 있는 경우 카이제곱 통계량은?
지니지수
노드의 불순도를 나타내는 값이다.
- 지니지수의 값이 클수록 이질적이며 순수도가 낮다고 볼 수 있다.
- 지니지수 예제
남자가 20명, 여자가 30명 있는 경우의 지니지수를 구하면?
1 - { (20/50)^2 + (30/50)^2 }
엔트로피 지수
- 열역학에서 사용하는 개념으로 무질서 정도에 대한 측도이다.
- 값이 클수록 순수도가 낮다고 볼 수 있다.
- 엔트로피 지수가 가장 작은 예측 변수와 이때의 최적분리 규칙에 의해 자식마디를 형성한다.
- 엔트로피 지수 예제
동전 4개 중에 앞면이 나온 동전 3개, 뒷면이 나온 동전 1개가 있는 경우 엔트로피 지수는?
의사결정나무 예시
예제1은 R 패키지 [rpart]의 rpart() 함수를 이용하여 의사결정나무 분석을 수행한다.
예제1
iris 자료를 이용하여 의사결정나무 분석을 수행
> library(rpart)
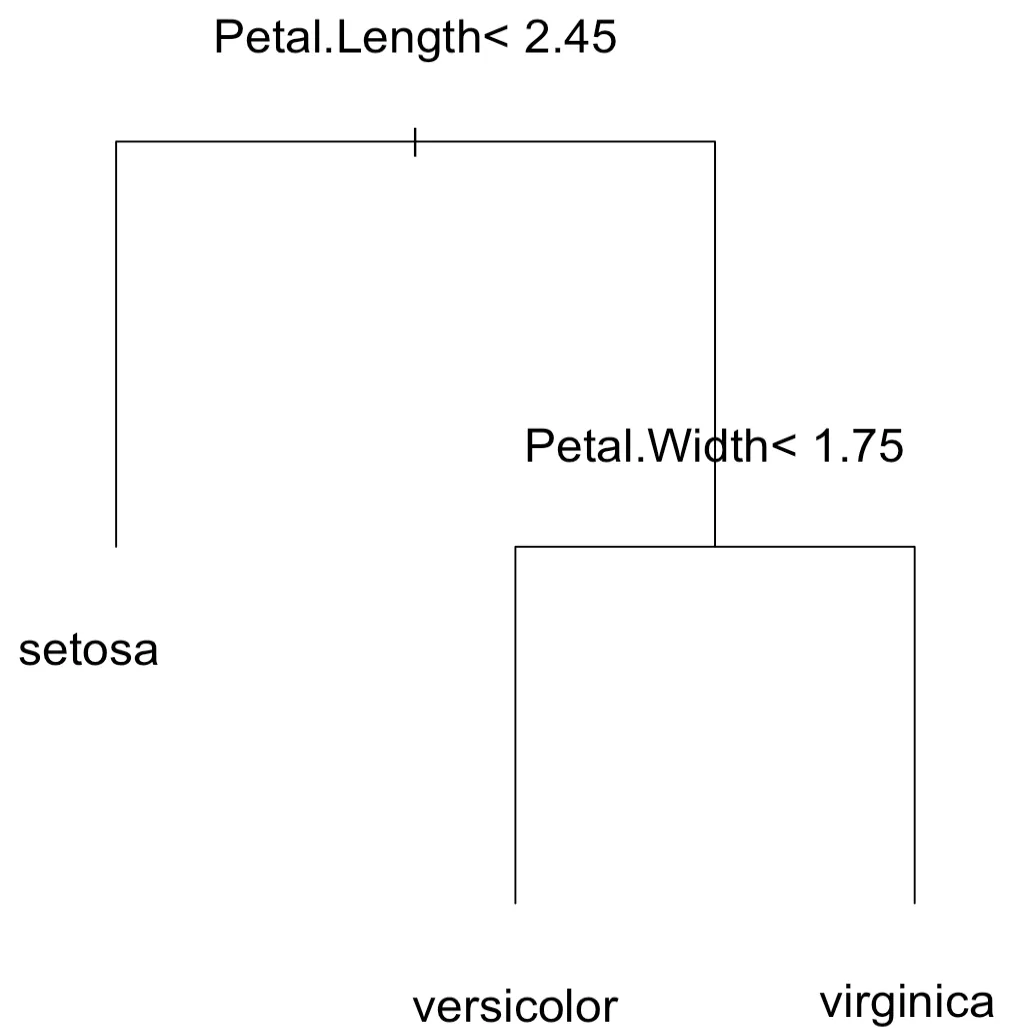
> c<-rpart(Species~.,data=iris)
> c
n= 150
node), split, n, loss, yval, (yprob)
* denotes terminal node
1) root 150 100 setosa (0.33333333 0.33333333 0.33333333)
2) Petal.Length< 2.45 50 0 setosa (1.00000000 0.00000000 0.00000000) *
3) Petal.Length>=2.45 100 50 versicolor (0.00000000 0.50000000 0.50000000)
6) Petal.Width< 1.75 54 5 versicolor (0.00000000 0.90740741 0.09259259) *
7) Petal.Width>=1.75 46 1 virginica (0.00000000 0.02173913 0.97826087) *
> plot(c,compress=T,margin=0.3)
> text (c, cex=1.5)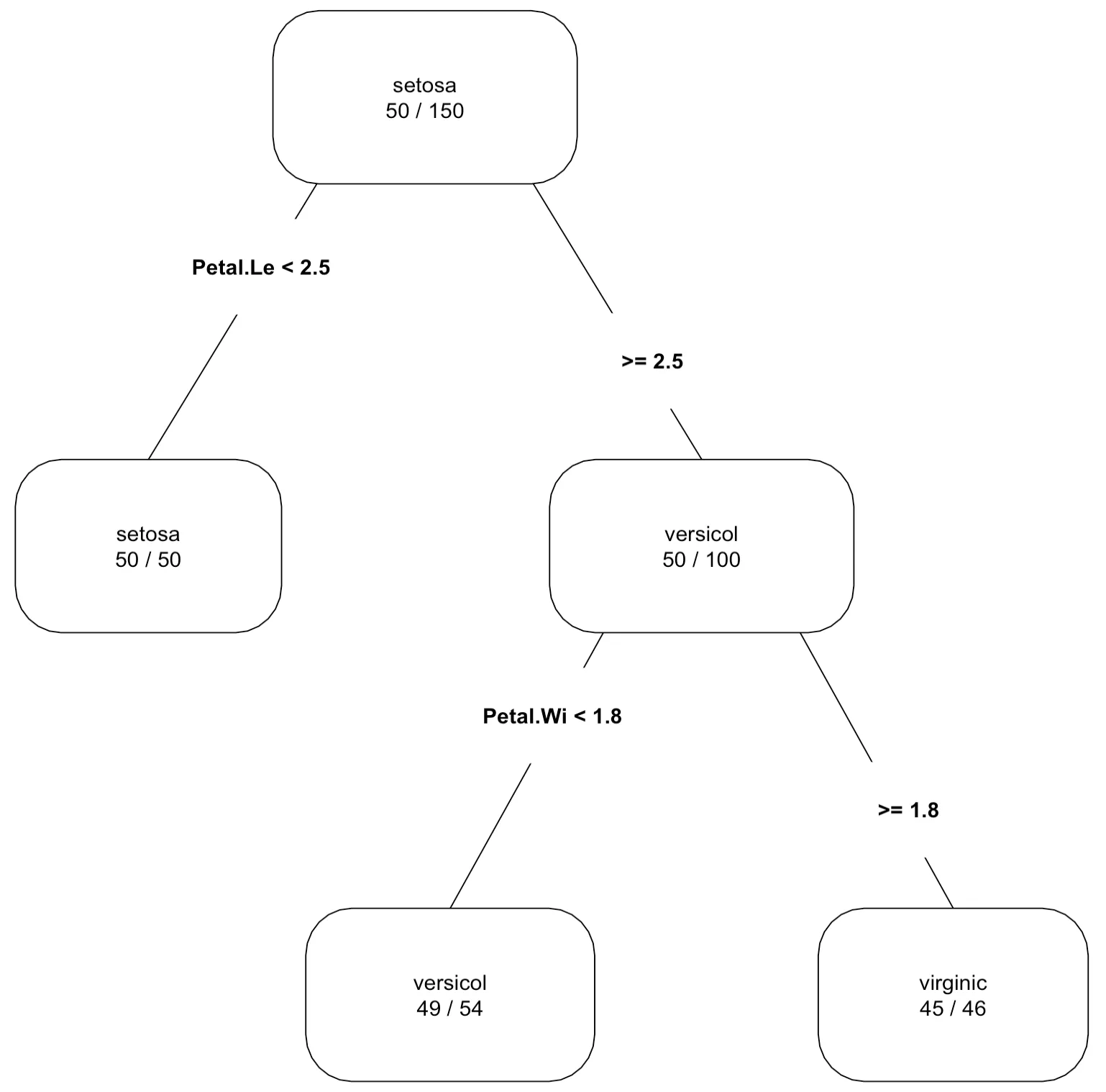
predict() 함수를 이용하여 새로운 자료에 대해 예측을 수행한다. 여기서는 편의상 모형구축에 사용된 자료를 재대입한 결과를 제시한다.
> head(predict (c, newdata=iris, type="class"))
1 2 3 4 5 6
setosa setosa setosa setosa setosa setosa
Levels: setosa versicolor virginica
> tail(predict (c, newdata=iris, type="class"))
145 146 147 148 149 150
virginica virginica virginica virginica virginica virginica
Levels: setosa versicolor virginicaR 패키지 (rpart.plot)을 이용하여 적합된 의사결정나무 모형을 여러 방식으로 시각화할 수 있다.
> install.packages("rpart.plot")
> library(rpart.plot)
> prp(c,type=4,extra=2)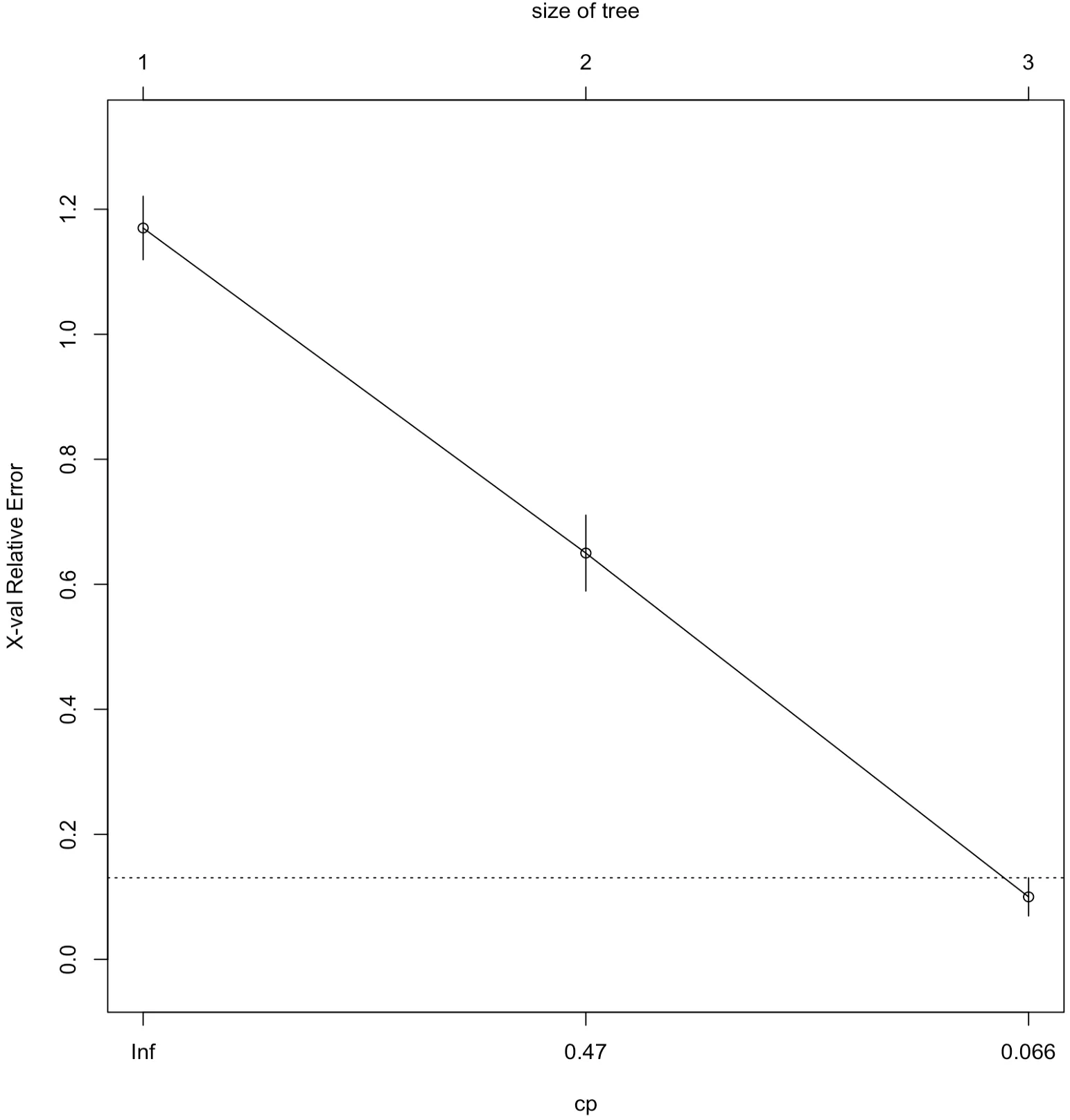
최종 노드에 대한 해석은 다음과 같다. 예를 들어, 두 조건(Petal.Length>=2.5 와 Petal.Width<1.8)을 만족하는 노드에서 49/54는 이 노드에 속하는 해당 개체가 54개이며 이 가운데 versicolor가 49임을 나타낸다. 따라서 이 노드에 해당되는 새로운 자료는 versicolor로 분류된다.
R 패키지 (rpart의 plotepo 함수를 이용하면 cp값을 그림으로 나타낼 수 있다.
> plotcp(c)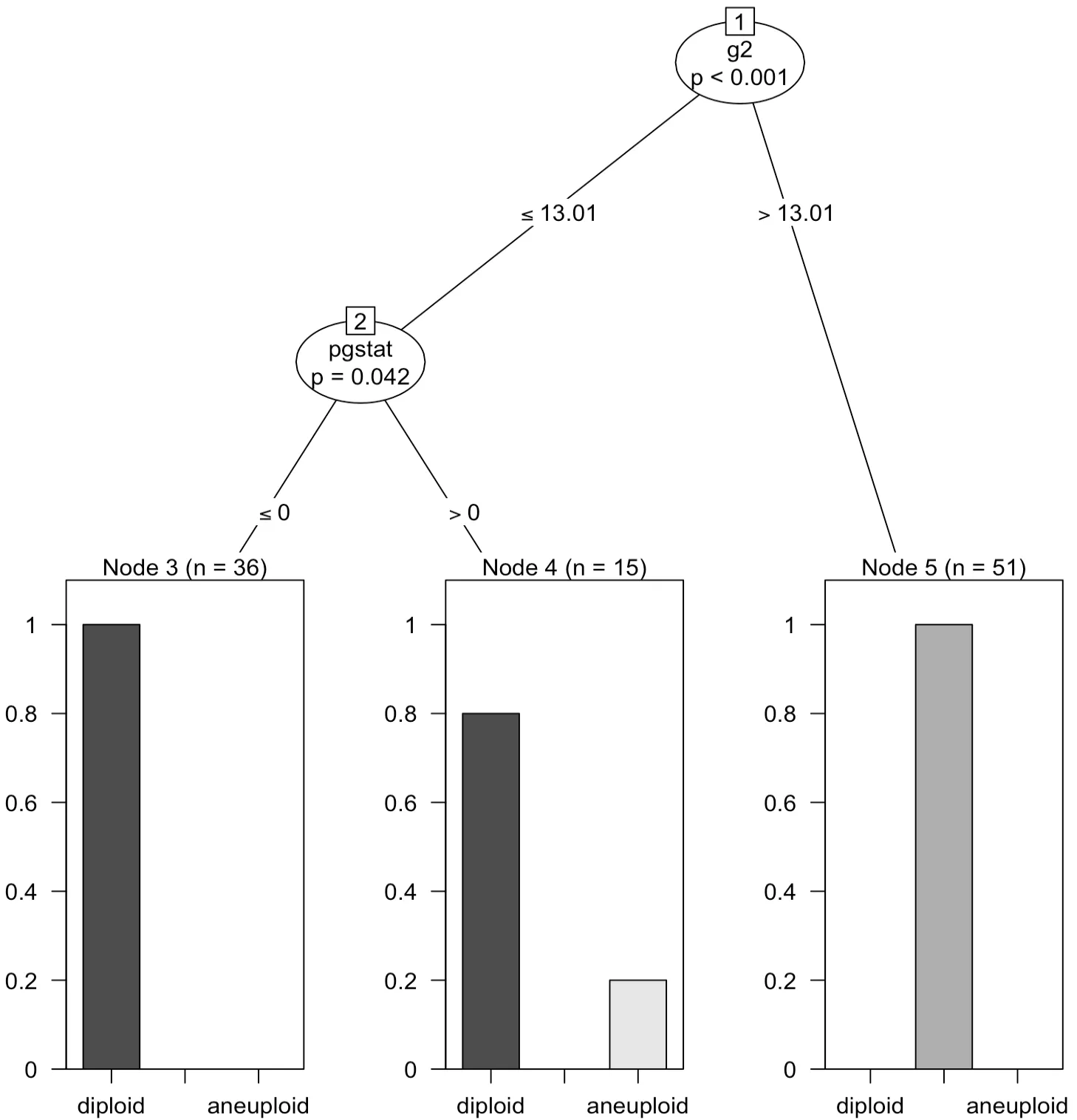
예제2
패키지 {party}의 ctree() 함수를 이용하여 의사결정나무모형을 적용한 예제이다.
분석에 사용된 자료는 146명의 전립선 암 환자의 자료이다. 7개의 예측변수를 이용하여
범주형의 반응변수(ploidy)를 예측(또는 분류)한다.
> install.packages("party")
> library(party)
> data(stagec)
> str(stagec)
'data.frame': 146 obs. of 8 variables:
$ pgtime : num 6.1 9.4 5.2 3.2 1.9 4.8 5.8 7.3 3.7 15.9 ...
$ pgstat : int 0 0 1 1 1 0 0 0 1 0 ...
$ age : int 64 62 59 62 64 69 75 71 73 64 ...
$ eet : int 2 1 2 2 2 1 2 2 2 2 ...
$ g2 : num 10.26 NA 9.99 3.57 22.56 ...
$ grade : int 2 3 3 2 4 3 2 3 3 3 ...
$ gleason: int 4 8 7 4 8 7 NA 7 6 7 ...
$ ploidy : Factor w/ 3 levels "diploid","tetraploid",..: 1 3 1 1 2 1 2 3 1 2 ...다음은 결측값을 제거하는 과정이다.
> stagec1<- subset(stagec, !is.na(g2))
> stagec2<- subset(stagec1, !is.na(gleason))
> stagec3<- subset(stagec2, !is.na(eet))
> str(stagec3)결측값이 제거된 134개의 자료를 이용하여 모형에 적용한다. 모형구축을 위한 훈련용 자료와 모형의 성능을 검증하기 위한 검증용 자료를 70%와 30%로 구성한다.
> set.seed(1234)
> ind <- sample(2,nrow(stagec3),replace=TRUE,prob=c(0.7,0.3))모형을 만들기 전에 stagec 자료를 복원 추출 방법을 이용하여 두 개의 부분집합 training(70%)과
test(30%)로 만들고, 결과의 재현성을 위해 random seed를 고정하였다.
> ind
> trainData <- stagec3[ind==1,]
> testData <- stagec3[ind==2,]훈련용 자료( = 102)에 대해 ctree()를 적용한 결과는 다음과 같다.
> tree<-ctree(ploidy~.,data=trainData)
> tree
> plot(tree)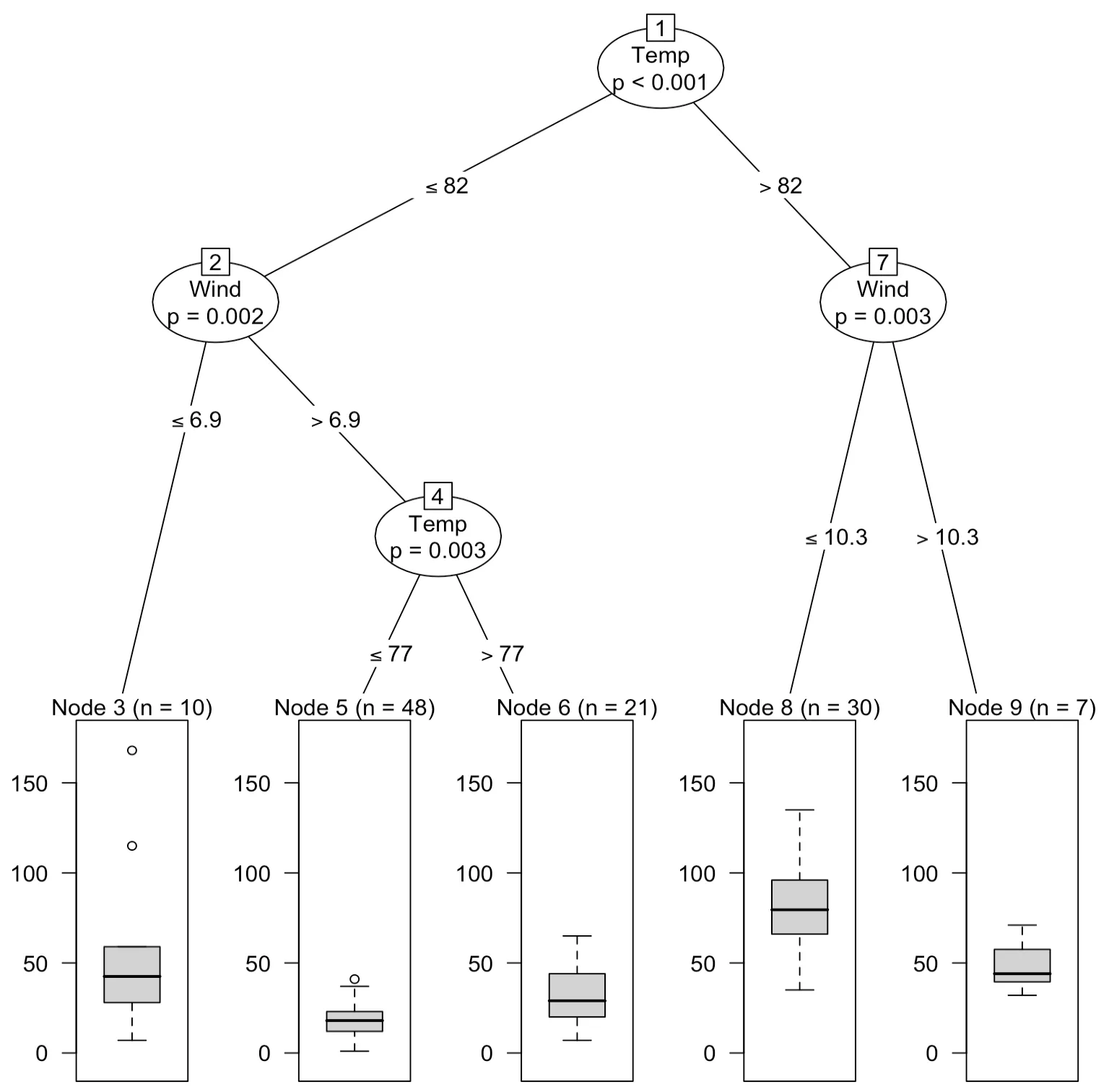
최종노드의 막대그래프는 반응변수의 각 범주별 비율을 나타낸다.
predict() 함수를 통해 검증용 자료에 대해 적합모형을 적용하면 다음과 같다.
> testPred = predict(tree, newdata=testData)
> table (testPred, testData$ploidy)
testPred diploid tetraploid aneuploid
diploid 17 0 1
tetraploid 0 13 1
aneuploid 0 0 0예제3
예제3은 ctree() 함수를 이용하여 반응변수가 연속형인 경우 의사결정나무(회귀나무)를 통한 예측을 수행한다.
airquality 자료에 대해 의사결정나무모형을 적합한다. 먼저 반응변수 Ozone이 결측인 자료를 제외한 후 ctree() 함수를 적용한다.
> airq <- subset(airquality, !is.na(Ozone))
> head(airq)
Ozone Solar.R Wind Temp Month Day
1 41 190 7.4 67 5 1
2 36 118 8.0 72 5 2
3 12 149 12.6 74 5 3
4 18 313 11.5 62 5 4
6 28 NA 14.9 66 5 6
7 23 299 8.6 65 5 7
> airct <- ctree(Ozone~.,data=airq)
> airct
Conditional inference tree with 5 terminal nodes
Response: Ozone
Inputs: Solar.R, Wind, Temp, Month, Day
Number of observations: 116
1) Temp <= 82; criterion = 1, statistic = 56.086
2) Wind <= 6.9; criterion = 0.998, statistic = 12.969
3)* weights = 10
2) Wind > 6.9
4) Temp <= 77; criterion = 0.997, statistic = 11.599
5)* weights = 48 4) Temp > 77
6)* weights = 21
1) Temp > 82
7) Wind <= 10.3; criterion = 0.997, statistic = 11.712
8)* weights = 30
7) Wind > 10.3
9)* weights = 7최종마디(*로 표시된 마디)가 5개인 트리모형을 나타낸다. 이를 시각화하면 다음과 같다.
> plot(airct)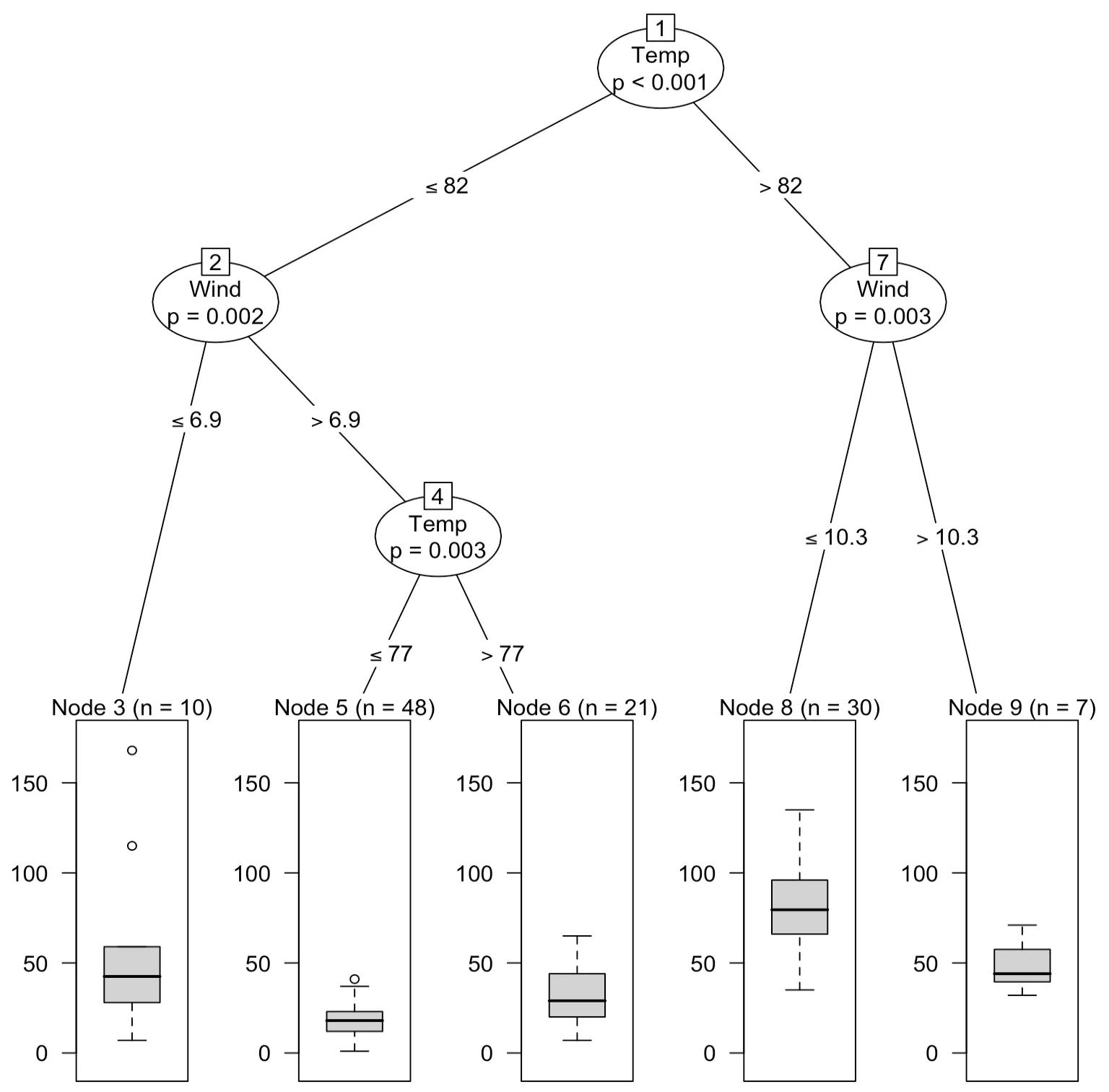
위 모형으로부터 새로운 자료에 대한 예측은 predict() 함수를 이용한다. 연속형 반응변수에 대한 예측값은 최종 마디에 속한 자료들의 평균값이 제공된다. 분석에 사용된 자료를 재대입한 결과는 다음과 같다.
> head(predict(airct, data=airq))
Ozone
[1,] 18.47917
[2,] 18.47917
[3,] 18.47917
[4,] 18.47917
[5,] 18.47917
[6,] 18.47917자료가 속하는 해당 최종마디의 번호를 출력하고 싶을 때는 type="node” 옵션을 사용한다.
> predict(airct, data=airq, type="node")
[1] 5 5 5 5 5 5 5 5 3 5 5 5 5 5 5 5 5 5 5 5 5 5 5 6 3 5 6 9 9 6
(이하생략)예측값을 이용하여 평균제곱오차를 구하면 다음과 같다.
> mean((airq$Ozone-predict(airct))^2)
[1] 403.6668연습문제
1번
의사결정나무의 특정으로 옳지 않은 것은?
1. 모형 분류의 정확도가 높다.
2. 분류 경계선 근처의 자료값에 대해 오차가 작다.
3. 새로운 자료에 대한 과적합 발생 가능성이 높다.
4. 데이터 정규화 및 단위 변환이 필요하지 않다.
정답
의사결정나무는 분류 경계선 근처의 자료값에 대해 오차가 크다는 단점이 있다.
2번
의사결정나무의 활용법으로 옳지 않은 것은?
1. 비슷한 특성의 그룹으로 분할하여 그룹별 특성을 발견
2. 데이터에서 규칙을 찾고 이를 미래 사건 예측에 활용
3. 연속형의 병합 또는 범주형 변수의 이산화
4. 종속변수의 범주를 몇 개의 등급으로 분류
정답
의사결정나무의 활용법으로 ‘범주의 병합 또는 연속형 변수의 이산화’가 있다.
3번
불순도의 여러 가지 측도에 대한 설명으로 옳지 않은 것은?
1. 지니지수는 노드의 불순도를 나타내는 값이다.
2. 지니지수의 값이 작을수록 이질적이며 순수도가 낮다고 볼 수 있다.
3. 엔트로피 지수는 값이 클수록 순수도가 낮다고 볼 수 있다.
4. 카이제곱 통계량의 기대도수 수식은 ‘열의 합계 X 합의 합계 / 전체 합계’이다.
정답
지니지수의 값이 클수록 이질적이며 순수도가 낮다고 볼 수 있다.
13.3 앙상블분석
앙상블 분석 개요
앙상블 기법
프랑스어로 앙상블(Ensemble)은 ‘함께, 동시에’라는 의미를 가지고 있다. 데이터 마이닝에서는 여러 개별 모델을 결합하여 하나의 강력한 모델을 만드는 기법을 의미한다. 이러한 기법은 단일 모델보다 높은 정확성과 일반화 능력을 제공할 수 있다.
- 대표적인 앙상블 기법에는 배깅(bagging), 부스팅(boosting), 랜덤 포레스트(random forest)가 있다.
- 결과가 수치형 데이터인 경우에는 값들의 평균을 통해 최종 결과를 예측하고, 결과가 범주형 데이터인 경우에는 다수결 방식으로 최종 결과를 예측한다.
### 앙상블 분석 종류
배깅
배깅(bagging)은 bootstrap aggregating의 준말로 원 데이터 집합으로부터 크기가 같은 표본을 여러 번 단순 임의 복원추출하여 각 표본(이를 붓스트랩 표본이라 함)에 대해 분류기를 생성한 후 그 결과를 앙상블 하는 방법이다.
- 반복추출 방법을 사용하기 때문에 같은 데이터가 한 표본에 여러 번 추출될 수도 있고, 그렇지 않을 수도 있다.
- 보팅(Voting)은 여러 개의 모형으로부터 산출된 결과를 다수결에 의해서 최종 결과를 선정하는 과정이다.
- 최적의 의사결정나무를 구축할 때 가장 어려운 부분이 가지치기이지만 배깅에서는 가지치기를 하지 않고 최대로 성장한 의사결정나무들을 활용한다.
- 분석을 위한 데이터 모집단의 분포를 알 수 없기 때문에 실제 문제에서는 평균예측 모형을 구할 수 없다. 하지만 하나의 붓스트랩을 구성할 때 원본 데이터로부터 복원추출을 진행하기 때문에 붓스트랩은 알 수 없던 모집단의 특성을 더 잘 반영할 수 있다. 배깅은 모집단의 특성이 잘 반영되는 분산이 작고 좋은 예측력을 보여준다.
배깅예제
iris 자료에 대해 R 패키지 {adabag}의 bagging() 함수를 통해 분석을 수행한다.
> install.packages("adabag")
> library(adabag)
> data(iris)
> iris.bagging<-bagging(Species~.,data=iris,mfinal=10)
> iris.bagging$importance
Petal.Length Petal.Width Sepal.Length Sepal.Width
76.01566 23.98434 0.00000 0.00000- macOS에서 위 adabag 패키지가 실행되지 않을 경우 이곳을 확인해 주세요! macOS에서는 XQuartz 또는 X11이 필요할 수 있습니다. XQuartz 설치 : XQuartz 공식 웹사이트에서 XQuartz를 다운로드하고 설치하세요. 설치 후에는 R을 다시 시작하고 패키지를 설치하고 로드해 보세요.
R 패키지 {adabag}의 bagging() 함수는 배깅을 이용하여 분류를 수행한다. plot() 함수를 통해 분류 결과를 트리 형태로 나타낼 수 있다.
> plot(iris.bagging$trees[[10]])
> text(iris.bagging$trees[[10]])
predict() 함수를 통해 새로운 자료에 대한 분류(예측)를 수행할 수 있다. 여기서는 모형 구축에 사용된 자료를 재사용하여 분류를 수행하였다. 그 결과 setosa는 50개 모두, versicolor는 50개 중 48개, virginica 는 50개 중 45개가 제대로 분류되었다.
> pred<-predict(iris.bagging,newdata=iris)
> table(pred$class,iris[,5])
setosa versicolor virginica
setosa 50 0 0
versicolor 0 48 5
virginica 0 2 45부스팅
부스팅(boosting)은 배깅의 과정과 유사하나 붓스트랩 표본을 구성하는 재표본(re-sampling) 과정에서 각 자료에 동일한 확률을 부여하는 것이 아니라, 분류가 잘못된 데이터에 더 큰 가중을 주어 표본을 추출한다.
- 약한 모델들을 결합하여 나감으로써 점차적으로 강한 분류기를 만들어 나가는 과정이다.
- 부스팅에서는 붓스트랩 표본을 추출하여 분류기를 만든 후, 그 분류결과를 이용하여 각 데이터가 추출될 확률을 조정한 후, 다음 붓스트랩 표본을 추출하는 과정을 반복한다.
- 에이다부스팅(AdaBoosting)은 가장 많이 사용되는 부스팅 알고리즘이며, 그 밖에 Gradient Boost, XGBoost, Light GBM 등이 있다.
- 붓스트립을 재구성하는 과정에서 잘못 분류된 데이터에 더 큰 가중치를 주어 표본을 추출하기 때문에 훈련오차를 빠르게 줄일 수 있다.
- 예측 성능이 배깅보다 뛰어난 경우가 많다.
- 배깅은 각각의 모델이 독립적이지만 부스팅은 독립적이지 않다.
부스팅 예제1
iris 자료에 대해 R 패키지 {adabag}의 boosting() 함수를 통해 분석을 수행한다.
> library(adabag)
> boo.adabag<-boosting(Species~., data=iris, boos=TRUE, mfinal=10)
> boo.adabag$importance
Petal.Length Petal.Width Sepal.Length Sepal.Width
67.229188 18.780665 4.964470 9.025677R 패키지 {adabag}의 boosting() 함수는 부스팅을 이용하여 분류를 수행한다. plot() 함수를 통해 분류 결과를 트리 형태로 나타낼 수 있다.
> plot(boo.adabag$trees[[10]])
> text(boo.adabag$trees[[10]])
predic() 함수를 통해 새로운 자료에 대한 분류(예측)을 수행할 수 있다. 여기서는 모형 구축에 사용된 자료를 재사용하여 분류를 수행하였다. 그 결과 setosa, versicolor, virginica 모두 정확히 분류되었음을 알 수 있다.
> pred <- predict (boo.adabag, newdata=iris)
> tb <- table (pred$class, iris [,5])
> tb
setosa versicolor virginica
setosa 50 0 0
versicolor 0 50 0
virginica 0 0 50위의 결과로부터 오분류율을 계산하면 다음과 같이 그 값이 0임을 알 수 있다.
> error.rpart <- 1-(sum(diag(tb))/sum(tb))
> error.rpart
[1] 0부스팅 예제2
예제 2는 R 패키지 {ada}의 ada() 함수를 이용하여 에이다부스팅을 이용한 분류를 수행한 예제이다.
iris 자료 중 setosa를 제외한 versicolor와 virginica 자료만으로 분석을 수행한다.
> install.packages("ada")
> library(ada)
> data(iris)
> iris[iris$Species!='setosa', ]->iris #setosa 50개 자료 제외
> n<-dim(iris)[1]총 100개의 자료를 60개의 훈련용 자료와 검증용 자료로 나누었다.
> trind<-sample(1:n,floor(.6*n),FALSE)
> teind<-setdiff(1:n,trind)
> iris[,5]<-as.factor((levels(iris[,5])[2:3])[as.numeric(iris[,5])-1])훈련용 데이터를 이용하여 부스팅 방법으로 모형을 구축하고, 검증용 자료에 대해 분류(예측)를 실시하였다. 그 결과 검증용 자료에 대한 정분류율이 100%로 나타났다.
> gdis<-ada(Species~.,data=iris[trind,],iter=20, nu=1, type="discrete")
> gdis<-addtest(gdis,iris[teind,-5],iris[teind,5])
> gdis
Call:
ada(Species ~ ., data = iris[trind, ], iter = 20, nu = 1, type = "discrete")
Loss: exponential Method: discrete Iteration: 20
Final Confusion Matrix for Data:
Final Prediction
True value versicolor virginica
versicolor 27 0
virginica 0 33
Train Error: 0
Out-Of-Bag Error: 0.017 iteration= 6
Additional Estimates of number of iterations:
train.err1 train.kap1 test.errs2 test.kaps2
12 12 1 1plot(), varplot(), pairs() 함수를 이용하여 부스팅 결과를 시각화 한 결과는 다음과 같다.
아래의 plot() 함수는 오차와 일치도를 나타내는 카파(kappa) 계수를 그려준다. 두 개의 TRUE 옵션은 훈련용, 검증용 자료 모두에 대해 그림을 그려준다.
> plot(gdis,TRUE,TRUE)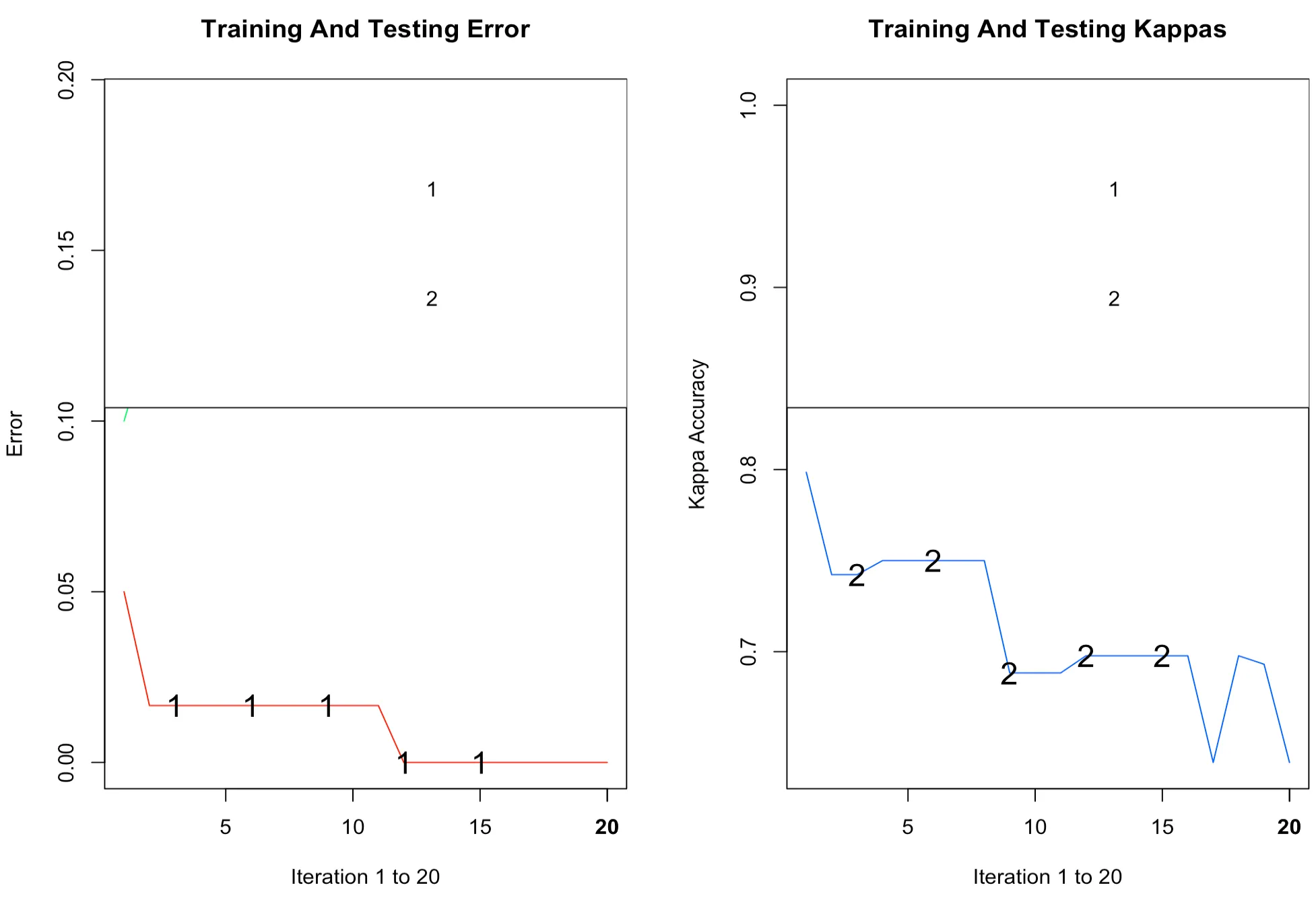
varplot() 함수는 변수의 중요도를 나타내는 그림을 제공한다. Sepal.Length 변수가 분류에 가장 중요한 변수로 사용되었음을 보여준다.
> varplot(gdis)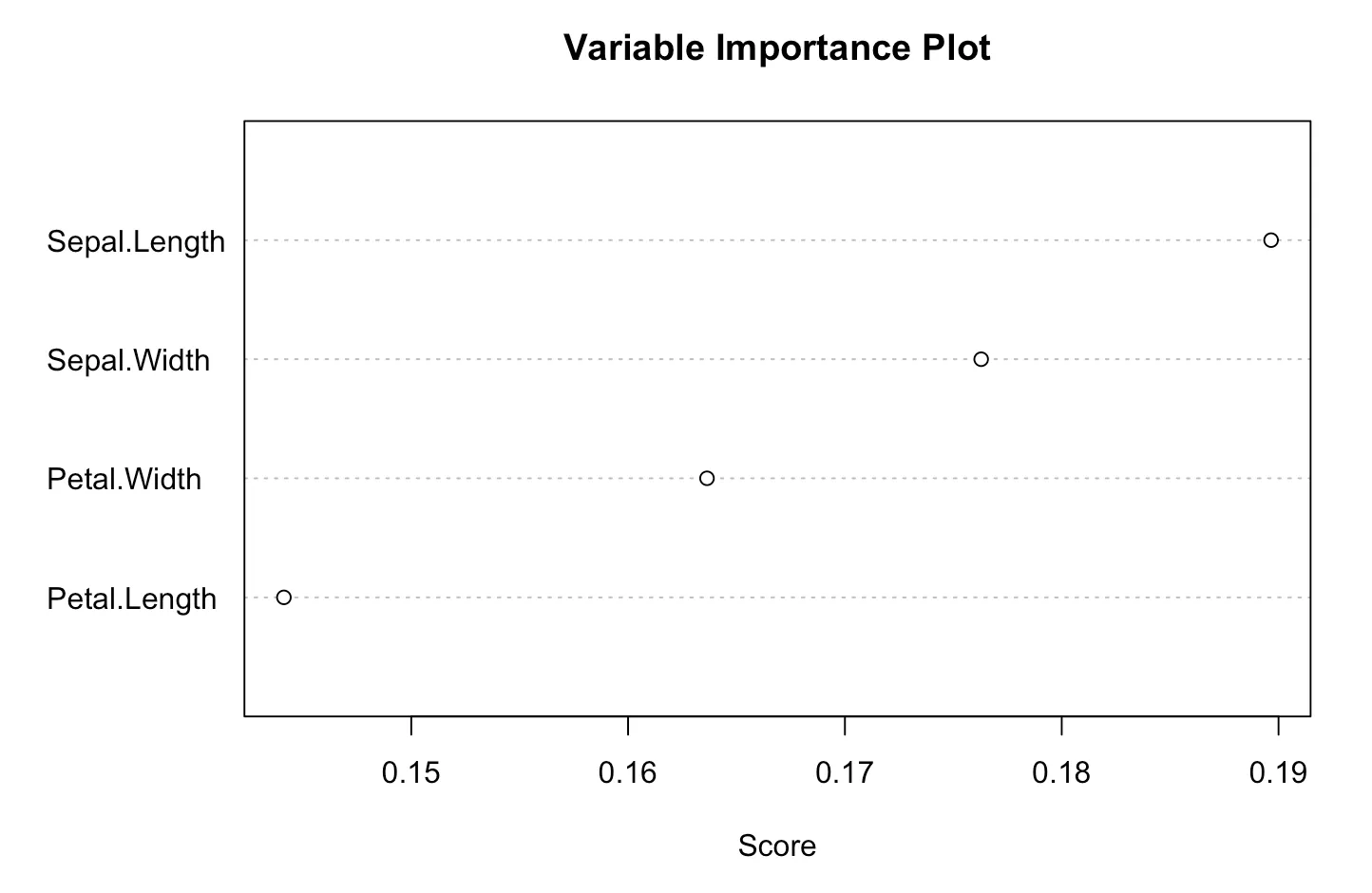
pairs() 함수는 두 예측변수의 조합별로 분류된 결과를 그려준다. maxvar= 옵션을 통해 변수의 수(중요도가 높은 상위 변수의 수)를 지정할 수 있다.
> pairs(gdis, iris[trind,-5],maxvar=4)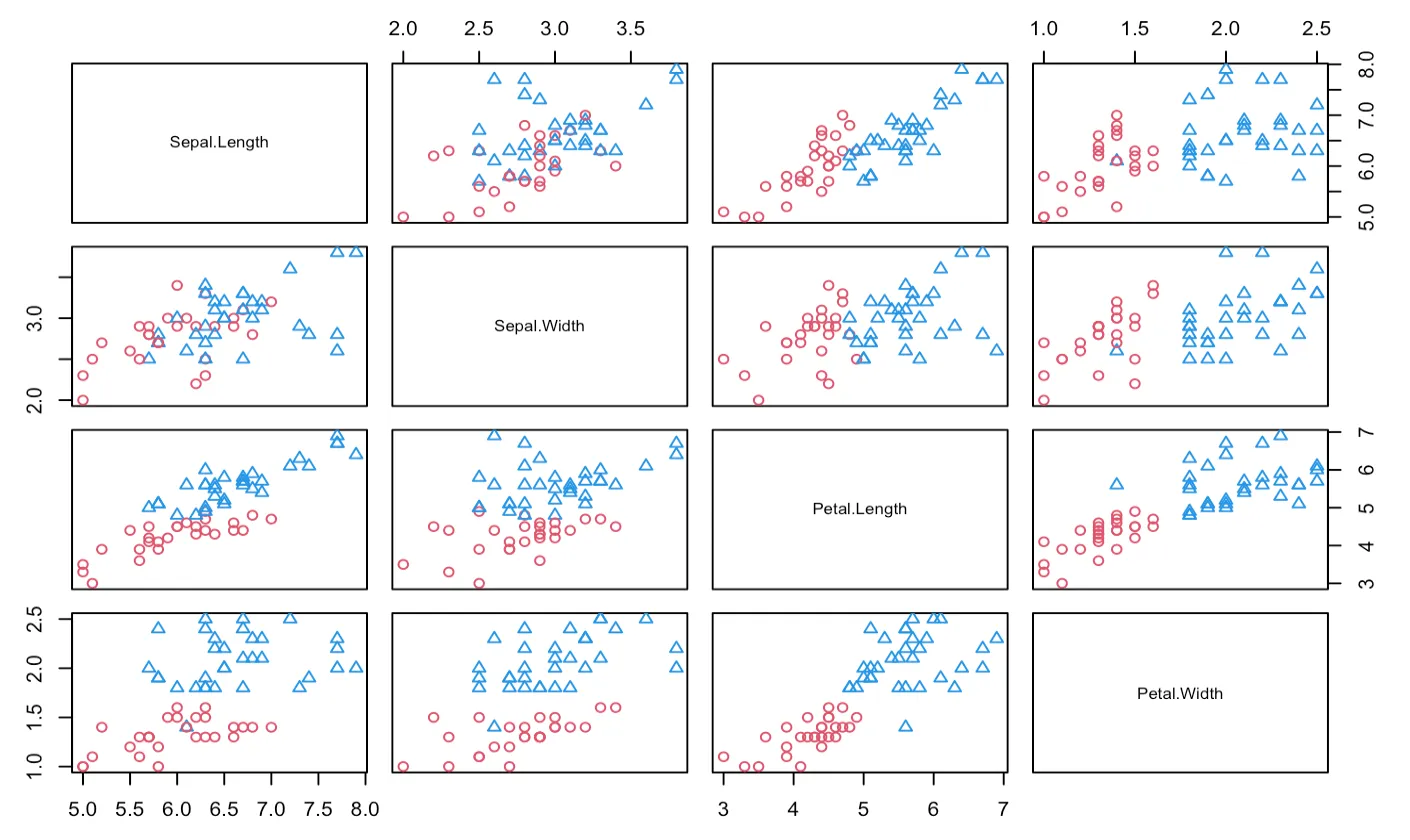
랜덤 포레스트
랜덤포레스트(random forest)는 서로 상관성이 없는 나무들로 이루어진 숲을 의미하며 배깅에 랜덤 과정을 추가한 방법이다.
- 의사결정나무의 특징인 분산이 크다는 점을 고려하여 배깅과 부스팅보다 더 많은 무작위성을 주어 약한 학습기들을 생성한 후 이를 선형 결합하여 최종 학습기를 만드는 방법이다. 또한 의사결정나무의 특징을 물려받아 이상값에 민감하지 않다는 장점이 있다.
- 랜덤한 Forest에는 많은 트리들이 생성된다.
- 분류의 경우에는 다수결로 최종 결과를 구하지만 회귀의 경우에는 평균 또는 중앙값을 구하는 방법을 사용한다.
- 수천 개의 변수를 통해 변수제거 없이 실행되므로 정확도 측면에서 좋은 성과를 보인다.
- 이론적 설명이나 최종 결과에 대한 해석이 어렵다는 단점이 있지만 예측력이 매우 높은 것으로 알려져 있다. 특히 입력변수가 많은 경우, 배깅과 부스팅과 비슷하거나 좋은 예측력을 보인다.
랜덤포레스트 예제
의사결정나무분석에 사용되었던 ploidy자료에 대해 randomforest() 함수를 이용하여 분석을 수행한다.
> install.packages("randomForest")
> library(randomForest)
> library(rpart)
> data(stagec)
> stagec3 <- stagec[complete.cases(stagec),]
> set.seed(1234)
> ind<-sample(2,nrow(stagec3),replace=TRUE, prob=c(0.7,0.3))
> trainData<-stagec3[ind==1,]
> testData<-stagec3[ind==2,]
> rf<-randomForest(ploidy~.,data=trainData,ntree=100,proximity=TRUE)
> table(predict(rf),trainData$ploidy)
diploid tetraploid aneuploid
diploid 45 0 3
tetraploid 1 51 0
aneuploid 2 0 0
> print(rf)
Call:
randomForest(formula = ploidy ~ ., data = trainData, ntree = 100, proximity = TRUE)
Type of random forest: classification
Number of trees: 100
No. of variables tried at each split: 2
OOB estimate of error rate: 5.88%
Confusion matrix:
diploid tetraploid aneuploid class.error
diploid 45 1 2 0.0625
tetraploid 0 51 0 0.0000
aneuploid 3 0 0 1.0000위 결과는 정오분류표와 함께, 오류율에 대한 OOB(out-of-bag) 추정치를 제공한다.
랜덤 포레스트에서는 별도의 검증용 데이터를 사용하지 않더라도 붓스트랩 샘플과정에서 제외된(out-of-bag) 자료를 사용하여 검증을 실시할 수 있다.
Out of Bag(OOB)
- Out of Bag(OOB)은 하나의 트리를 구성하기 위한 붓스트랩을 생성할 때 선택되지 않은 데이터를 의미한다.
- Out of Bag Score는 붓스트랩에 의해 구성된 트리를 Out of Bag 데이터로 몇 개가 올바르게 분류되었는지 파악하고 랜덤 포레스트 작업이 종료된 이후 올바르게 분류한 비율을 나타낸 값이다. 즉, 평가용 데이터로부터 모델을 평가하는 것과는 유사하지만 활용 데이터가 다르다는 것이 특징이다.
아래의 plot() 함수는 트리 수에 따른 종속변수의 범주별 오분류율 나타낸다. 검은색은 전체 오분류율을 나타낸다. 오분류율이 1로 나타난 범주는 aneuploid 범주로 개체수가 매우 작은() 범주에서 발생된 결과이다.
> plot(rf)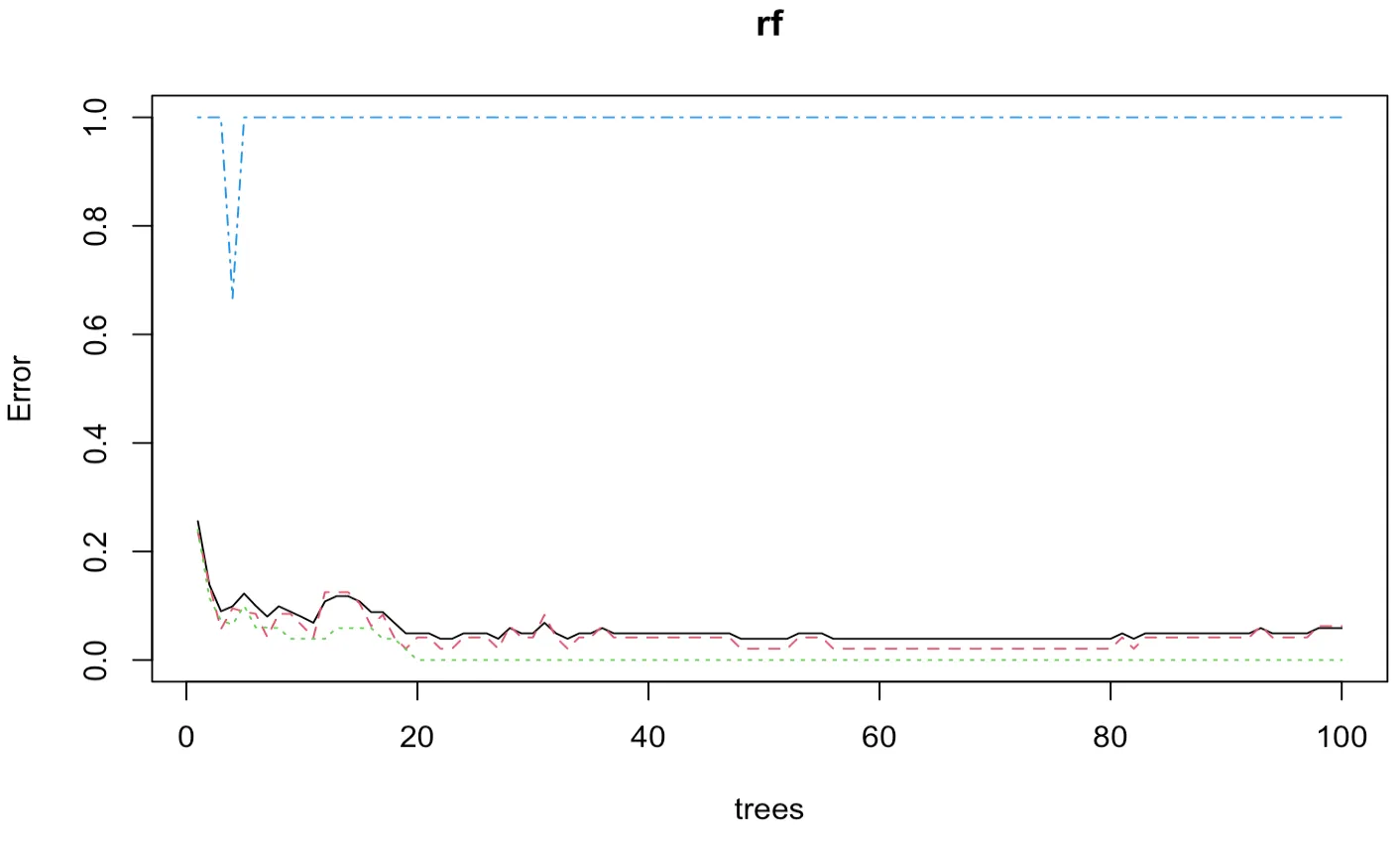
importance()와 varImpPlot()로 변수의 중요성을 알 수 있다.
> importance(rf)
MeanDecreaseGini
pgtime 4.6800225
pgstat 2.0635061
age 3.5726107
eet 0.7875501
g2 37.5032896
grade 1.2084410
gleason 2.0820408
> varImpPlot(rf)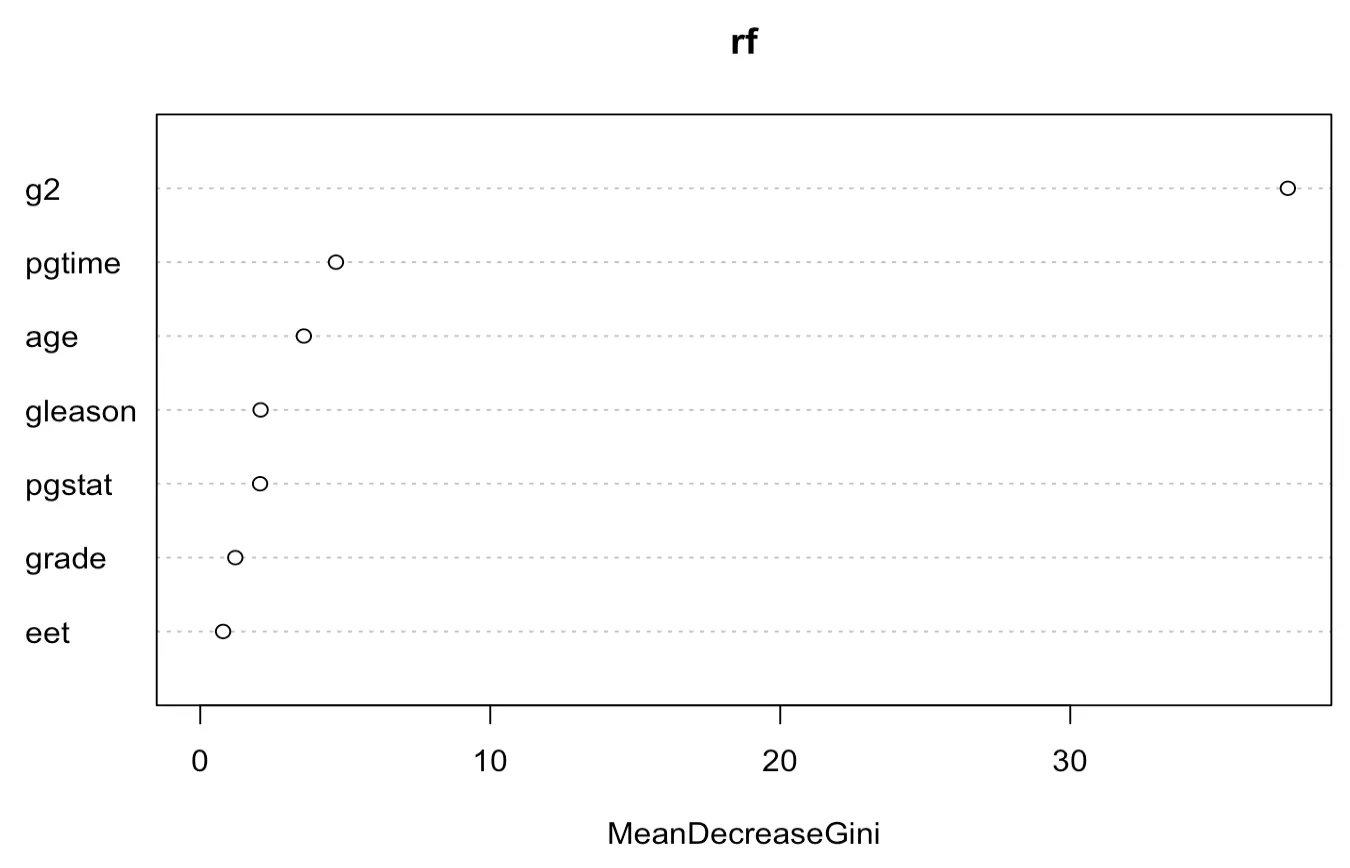
위 그림은 각 변수의 중요도를 나타내는 그림으로, 해당 변수로부터 분할이 일어날 때 불순도의 감소가 얼마나 일어나는지를 나타내는 값이다(불순도의 감소가 클수록 순수도가 증가함). 지니 지수는 노드의 불순도를 나타내는 값이다. 회귀의 경우에는 잔차제곱합을 통해 측정된다.
다음은 테스트 자료에 대해 예측을 수행한 결과이다.
> rf.pred<-predict(rf,newdata=testData)
> table(rf.pred,testData$ploidy)
rf.pred diploid tetraploid aneuploid
diploid 17 0 1
tetraploid 0 13 1
aneuploid 0 0 0아래의 그림은 훈련용 자료값(총 102개)의 마진을 나타낸다. 마진은 랜덤 포레스트의 분류기 가운데 정분류를 수행한 비율에서 다른 클래스로 분류한 비율의 최대치를 뺀 값을 나타낸다. 즉, 양의 마진은 정확한 분류를 의미하며, 음은 그 반대이다.
> plot(margin(rf))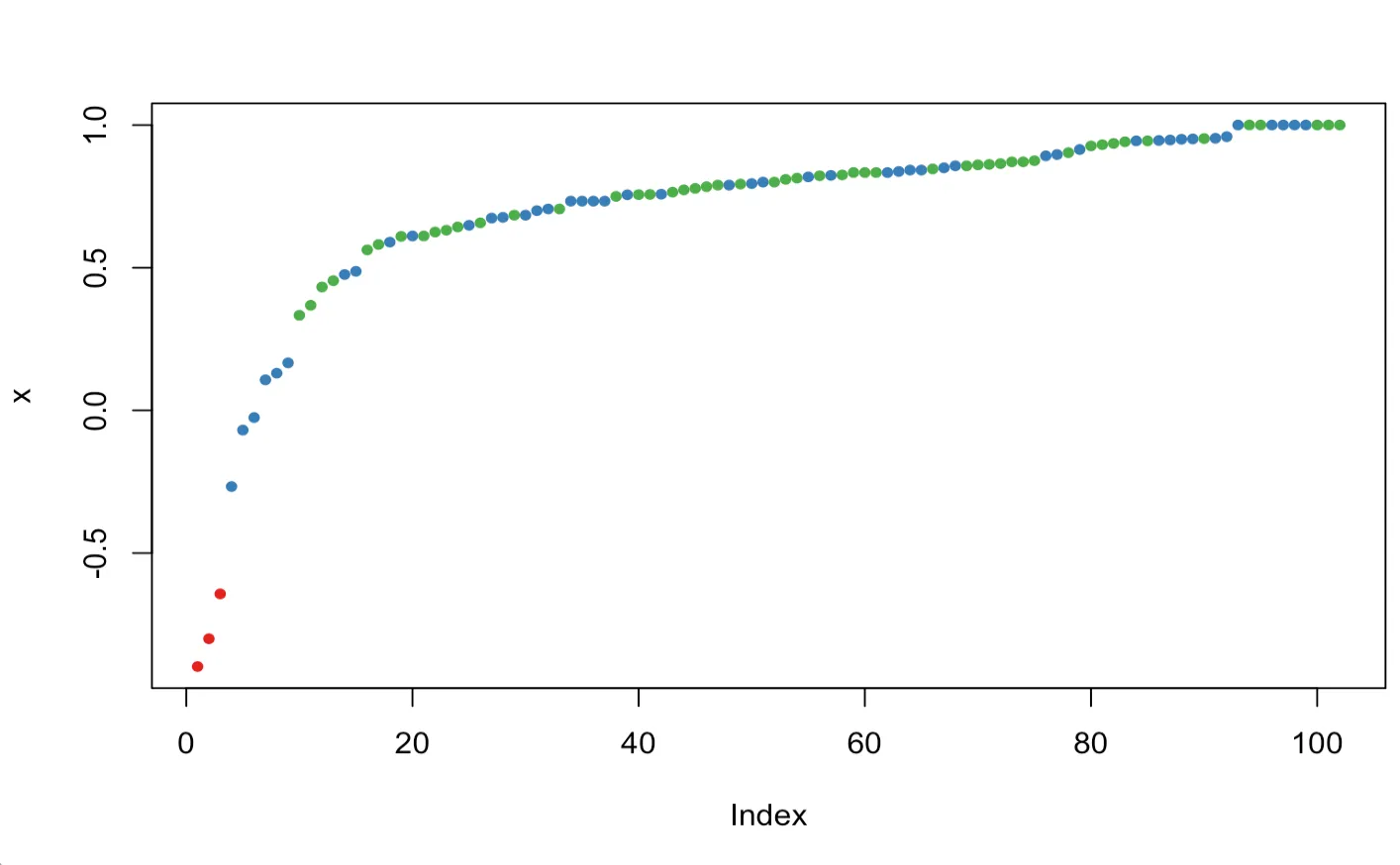
랜덤포레스트는 다음과 같이 R 패키지 {party}의 cforest() 함수를 이용할 수도 있다.
> install.packages("party")
> library(party)
> set.seed(1234)
> cf<-cforest(ploidy~.,data=trainData)
> cf.pred<-predict(cf,newdata-testData,OOB=TRUE,type='response')연습문제
1번
앙상블 기법에 대한 설명으로 옳지 않은 것은?
1. 여러 개별 모델을 결합하여 하나의 강력한 모델을 만드는 기법이다.
2. 단일 모델보다 높은 정확성과 일반화 능력을 제공한다.
3. 결과가 범주형 데이터인 경우에는 값들의 평균을 통해 최종 결과를 예측한다.
4. 배깅은 반복추출 방법을 사용하기 때문에 같은 데이터가 한 표본에 여러 번 추출될 수도 있다.
정답
결과가 수치형 데이터인 경우에는 값들의 평균을 통해 최종 결과를 예측하고, 결과가 범주형 데이터인 경우에는 다수결 방식으로 최종 결과를 예측한다.
2번
앙상블 분석 종류 중에서 배깅에 해당하는 내용이 아닌 것은?
1. bagging() 함수를 통해 분석을 수행한다
2. 보팅은 여러 개의 모형으로부터 산출된 결과를 다수결에 의해서 최종 결과를 선정하는 과정이다.
3. 모집단의 특성이 잘 반영되는 분산이 작고 좋은 예측력을 보여준다.
4. 배깅에서 의사결정나무를 구축할 때 가장 어려운 부분이 가지치기다.
정답
최적의 의사결정나무를 구축할 때 가장 어려운 부분이 가지치기이지만 배깅에서는 가지치기를 하지 않고 최대로 성장한 의사결정나무들을 활용한다.
3번
랜덤 포레스트에 대한 설명으로 옳지 않은 것은?
1. 랜덤 포레스트는 예측력이 매우 높은 것으로 알려져 있다.
2. 최종 결과에 대한 해석이 어렵다는 단점이 있다.
3. 정확도 측면에서 좋은 성과를 보인다.
4. 의사결정나무의 특징으로 이상값에 민감하다는 단점이 있다.
정답
의사결정나무의 특징을 물려받아 이상값에 민감하지 않다는 장점이 있다.
13.4 인공신경망 분석
인공신경망 개요
인공신경망
인공신경망은 인간의 뇌를 기반으로한 학습 및 추론 모형이다.
- 인간의 뇌는 여러 시냅스의 결합으로 신호를 받아 뉴런이 활성화되고 출력 신호를 내보낸다. 뉴런과 뉴런 사이는 시냅스로 연결되어 있는데, 입력신호가 다른 뉴런으로 전달되기 위해서는 신호의 강도가 일정 기준치를 초과해야 한다. 이러한 뇌의 구조를 수학적으로 단순화하여 모델링 한 것이 인공신경망 분석이다.
- 인공신경망에서 입력은 시냅스에 해당하며 개별신호의 강도에 따라 가중되며, 활성 함수는 인공신경망의 출력을 계산한다. 많은 데이터에 대해 학습을 거쳐, 원하는 결과가 나오도록(오차가 작아지는 방향으로) 가중치가 조정된다. 안정화된 모형에서 가중치는 회귀모형에서처럼 입력변수의 영향으로 해석될 수 있다.
인공신경망 분석의 장단점(중)

잡음 민감하게 반응하지 않는다. 비선형적 문제 분석하는데 유용. 초기 가중치에 따라 전역해가 아닌 지역해로 수렴가능. 결과 해석 쉽지 않다. 추정 가중치 신뢰도 낮다. 은닉층,은닉노드 수 결정 어렵다.
용어설명
- 전역해
- 손실 함수를 최소화하는 가중치와 편향 값의 조합 중에서 가장 작은 값을 갖는 해
- 지역해
- 함수가 최솟값을 갖는 지점 중에서 특정 영역 안에 있는 해를 의미
- 은닉층
- 인공신경망의 구성 요소 중 하나로, 입력층과 출력층 사이에 위치한 보이지 않는 여러개의 은닉층
- 주어진 입력에서 학습된 가중치와 활성화 함수를 통해 출력을 생성하며, 이를 통해 모델이 비선형 관계를 학습할 수 있다.
- 노드
- 인공신경망의 기본 구성 요소 중 하나
- 각 노드는 입력을 받아 가중치와 함께 가중합을 계산하고, 그 결과를 활성화 함수를 통과시켜 출력을 생성한다. 이때, 노드는 입력층, 은닉층, 출력층에 위치할 수 있다.
인공신경망의 알고리즘
활성함수란?
뉴런은 전이함수, 즉 활성화 함수(Activation Function)를 사용한다.
- 인공신경망은 노드에 입력되는 값을 바로 다음 노드로 전달하지 않고 비선형 함수에 통과시킨 후 전달한다. 이때 사용되는 비선형 함수를 활성함수라고 한다.
- 쉽게 말해 활성함수는 입력값에 따라 출력 신호를 내보낼지 여부를 결정하는 요소다.
- 어떤 활성함수를 사용하느냐에 따라 그 출력값이 달라지므로 적절한 활성함수를 사용하는 것이 중요하다. 대표적인 활성함수로는 시그모이드, 소프트맥스, ReLU(렐루) 등이 있다.
많이 사용되는 활성함수 (중)
- 계단(Step) 함수 기본적인 활성함수로 0 또는 1을 반환하는 이진형 함수다.
- 부호(Sign) 함수 기본적인 활성함수로 -1 또는 1을 반환하는 이진형 함수다.
- 시그모이드(sigmoid) 함수 로지스틱 회귀분석의 확률값을 구하기 위한 계산 식과 유사하며 0과 1 사이의 값을 반환한다.
- 소프트맥스(Softmax) 함수
표준화지수(또는 일반화로지스틱) 함수로도 불리며, 출력값이 다범주인 경우에 사용된다. 로지스틱 회귀분석과 마찬가지로 각 범주에 속할 확률값을 반환한다. - tanh 함수 확장된 형태의 시그모이드 함수로 중심값은 0이며, -1과 1 사이의 값을 출력한다.
- 가우스(Gauss) 함수 결과는 연속형이며, 0과 1사이의 값을 반환한다.
- ReLU 함수 최근 딥러닝에서 많이 사용되는 함수로 입력값과 0 중에서 큰 값을 반환한다.
입력값이 0 이하는 0, 0 이상은 x값을 가지는 함수다.
신경망 모형 구축 시 고려사항
인공신경망의 계층 구조(중)
인공신경망은 단층신경망과 다층신경망으로 구분된다.
- 입력층은 데이터를 입력받아 시스템으로 전송하는 역할을 한다.
- 은닉층은 신경망 외부에서는 은닉층의 노드에 직접 접근할 수 없도록 숨겨진 은닉한 층이다.
- 은닉층은 입력층으로부터 값을 전달받아 가중치를 계산한 후에 활성함수에 적용하여 결과를 산출하고 이를 출력층으로 보낸다.
- 출력층은 학습된 데이터가 포함된 층으로, 활성함수의 결과를 담고 있는 노드로 구성된다. 출력층의 노드수는 출력 범주의 수로 결정된다.
- 은닉층과 은닉노드가 많으면 가중치가 많아져서 과대 적합 문제가 발생할 수 있다. 반대로 은닉층과 은닉노드가 적으면 과소적합 문제가 발생한다.
- 은닉노드의 수는 적절히 큰 값을 놓고 가중치를 감소시키며 적용하는 것이 좋다.
입력 변수
신경망 모형은 그 복잡성으로 인해 입력 자료의 선택에 매우 민감하다. 입력변수가 범주형 또는 연속형 변수일 때 아래의 조건이 신경망 모형에 적합하다.
- 범주형 변수 : 모든 범주에서 일정 빈도 이상의 값을 갖고 각 범주의 빈도가 일정할 때
- 연속형 변수 : 입력변수 값들의 범위가 변수 간의 큰 차이가 없을 때
인공신경망 학습(역전파 알고리즘) (중)
인공신경망은 지도학습의 한 종류로 입력층과 출력층의 데이터에 따른 이상적인 가중치 값을 결정해야 한다. 가중치 값의 결정은 입력층에서 출력층으로 찾아 나가는 순전파 알고리즘을 먼저 활용한다. 이때 발생한 오차들을 줄이고자 출력층에서 입력층 방향으로 거꾸로 찾아 나가는 역전파 알고리즘을 활용하여 조정한다.
- 훈련용 데이터의 자료들이 순차적으로 입력될 때마다 가중치가 새롭게 조정되는 것을 인공신경망이 학습한다고 표현한다.
- 가중치가 0이면 시그모이드 함수는 선형이 되고 신경망 모형은 근사적으로 선형모형이 된다
과대 적합 문제
신경망에서는 많은 가중치를 추정해야 하므로 과대적합 문제가 빈번하다. 알고리즘의 조기종료와 가중치 감소(Weight Decay) 기법으로 해결할 수 있다.
- 모형이 적합하는 과정에서 검증오차가 증가하기 시작하면 반복을 중지하는 조기종료를 시행한다.
- 선형모형의 능형회귀와 유사한 가중치 감쇠라는 벌점화 기법을 활용한다.
인공신경망의 종류 (중)
하나의 퍼셉트론은 데이터를 입력하는 입력층, 데이터를 출력하는 출력층을 갖고 있는 단층 퍼셉트론과 입력층과 출력층 사이에 보이지 않는 다수의 은닉층을 가지고 있을 수 있는 다층 퍼셉트론으로 구분할 수 있다.
단층 퍼셉트론 (단층 신경망)
하나의 인공신경망은 데이터를 입력하는 입력층, 데이터를 출력하는 출력층을 갖고 있다. 단층 신경망이라고도 하며 입력층이 은닉층을 거치지 않고 바로 출력층과 연결된다.
- 퍼셉트론은 여러 개의 개별 입력 데이터를 받아 하나의 입력 데이터로 가공하여 활성함수에 의하여 출력값을 결정한다. 퍼셉트론의 출력값은 또 다른 퍼셉트론의 입력 데이터가 된다.
- 단층 퍼셉트론은 다수의 입력값을 받아 하나의 출력값을 출력하는데, 이 출력값이 정해진 임곗값을 넘었을 경우 1을 출력하고 넘지 못했을 경우에는 0을 출력한다.
다층 퍼셉트론 (다층 신경망)
다층 퍼셉트론은 단층 퍼셉트론보다 학습하기가 어려우며 은닉층의 노드의 수가 너무 적으면 복잡한 의사결정 경계를 구축할 수 없다.
- 입력층과 출력층 사이에 보이지 않는 다수의 은닉층을 가지고 있을 수 있다. 은닉층이 존재하지 않는 단층신경망은 한계점이 있기에 일반적인 인공신경망은 다층신경망을 의미한다.
인공신경망 예시
R 패키지를 활용하여 실습하기
> install.packages('neuralnet')
> library(neuralnet)
> index<-sample(c(1,2),nrow(iris),replace=T,prob=c(0.7,0.3))
> train<-iris[index==1, ]
> test<-iris[index==2, ]
> result<-neuralnet(data=train,Species~.,hidden=c(4,4),stepmax = 1e7)
> pred<-predict(result,newdata = test)
> head(pred,5)
[,1] [,2] [,3]
1 1.0003129 -6.842363e-04 -3.324936e-04
7 0.9997121 6.486066e-04 1.936844e-04
10 1.0003006 -6.295548e-04 -3.305435e-04
12 1.0000023 6.580618e-05 -5.014236e-05
18 1.0000681 -6.494720e-05 -1.152810e-04
# 출력변수로 'setosa', 'versicolor', 'virginica' 3개 변수 보유
# 종속변수는 가장 큰 값을 갖고 활성화되는 노드 하나
# 2번 데이터의 경우 1번 노드가 가장 큰 값으로 활성화되어 'setosa'로 분류된다.
# train 데이터로 구축된 모형을 test 데이터로 검정
# 가장 큰 값을 갖는 노드를 명목형으로 변환하기
> predicted_class<-c( )
> for(i in 1:nrow(test))
for(i in 1:nrow(test)){
loc<-which.max(pred[i,])
if(loc==1){
predicted_class <- c(predicted_class, 'setosa')
}else if(loc==2){
predicted_class<-c(predicted_class, 'versicolor')
}else{
predicted_class<-c(predicted_class, 'virginica')
}
}
# 명목형 변수로 바뀐 것 확인 가능
> head(predicted_class,5)
[1] "setosa" "setosa" "setosa" "setosa" "setosa"
> pred<-predict(result,newdata=test)
> predicted_class <- predicted_class[1:length(test$Species)] #예측 결과 변수 길이 조정
# test 데이터의 실제값(condition)과 예측값(pred)의 표 확인
> table(condition=test$Species,predicted_class)
predicted_class
condition setosa versicolor virginica
setosa 13 0 0
versicolor 0 11 0
virginica 0 3 11
# test 데이터 모두를 정확하게 분류함을 확인할 수 있다.
# 위 결과는 조금씩 다를 수 있다.
#plot을 활용하여 인공신경망 시각화
> plot(result)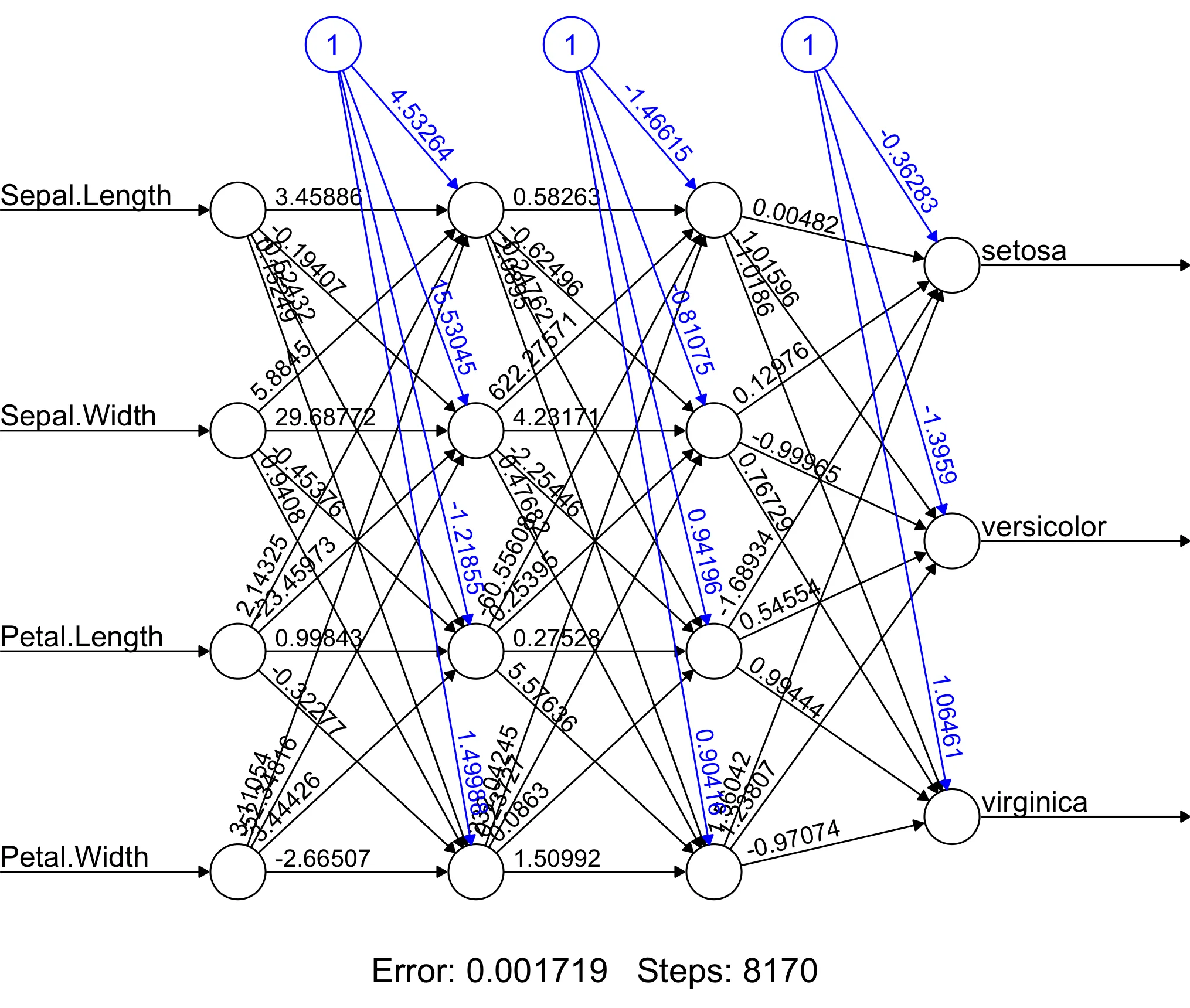
연습문제
1번
인공신경망에 대한 설명으로 옳지 않은 것은?
1. 인공신경망에서 입력은 시냅스에 해당하며 개별신호의 강도에 따라 가중된다.
2. 비선형적인 문제를 분석하는 데 유용하다.
3. 초기 가중치에 따라 전역해가 아닌 지역해로 수렴할 수 있다.
4. 다층신경망에서 은닉층의 수와 은닉노드의 수는 많을수록 좋다.
정답
은닉층의 수와 은닉노드의 수가 너무 많으면 과적합이 발생할 수 있다.
2번
인공신경망 계층 구조에 대한 설명으로 옳지 않은 것은?
1. 출력층의 노드수는 출력 범주의 수로 결정된다
2. 은닉노드의 수는 적절한 최소 값을 놓고 가중치를 증가시키며 적용하는 것이 좋다.
3. 단층신경망은 한계점이 있기에 일반적인 인공신경망은 다층신경망을 의미한다.
4. 다층신경망은 입력층과 출력층 사이에 보이지 않는 다수의 은닉층을 가지고 있는 것이다.
정답
은닉노드의 수는 적절히 큰 값을 놓고 가중치를 감소시키며 적용하는 것이 좋다.
3번
아래 보기에서 설명하는 활성함수로 적절한 것은?
<보기>
표준화지수 함수로도 불리며, 출력값이 다범주인 경우에 사용된다. 로지스틱 회귀분석과 마찬가지로 각 범주에 속할 확률값을 반환한다.
1. 소프트맥스 함수
2. 계단 함수
3. ReLU 함수
4. 시그모이드 함수
정답
보기의 내용은 소프트맥스(Softmax) 함수에 대한 설명이다.
13.5 그 외 다양한 분류분석
나이브 베이즈 분류(중)
베이즈 이론
베이즈 이론은 확률을 해석하는 이론이다. 통계학에서 확률은 크게 빈도 확률과 베이지안 확률로 구분할 수 있다.
빈도 확률
사건이 발생한 횟수의 장기적인 비율을 의미하며 객관적으로 확률을 해석한다.
- 근본적으로 반복되는 어떤 사건의 빈도를 다루는 것으로, 모집단으로부터 반복적으로 표본을 추출했을 때 추출된 표본이 사건 A에 포함되는 경향을 사건 A의 확률이라고 한다.
베이지안 확률
베이지안 확률을 주관적으로 확률을 해석한다.
-
사전확률과 우도확률을 통해 사후확률을 추정하는 정리로 데이터를 통해 확률을 추정할 때 현재 관측된 데이터의 빈도만으로 분석하는 것이 아니라 분석자의 사전지식까지 포함해 분석하는 방법이다.
-
베이즈 정리에서 확률은 ‘주장 혹은 믿음의 신뢰도’로 나타난다.
나이브 베이즈 분류
‘나이브(naive)’라는 용어는 모든 특성(또는 변수)이 서로 독립적이라고 가정한다는 것을 나타낸다. 확률적인 분류 알고리즘 중 하나로, 베이즈 정리를 기반으로 한다.
- 주로 텍스트 분류에서 사용되며, 스팸 메일 필터링, 문서 분류, 감성 분석 등 다양한 자연어 처리 작업에서 효과적으로 활용된다.
- 주로 다중 클래스 분류에 사용되며, 클래스 간의 확률을 계산하여 최종적으로 가장 높은 확률을 갖는 클래스를 선택한다.
- 나이브 베이즈 알고리즘은 이진 분류 데이터가 주어졌을 때 베이즈 이론을 통해 범주 a, b가 될 확률을 구하고, 더 큰 확률값이 나오는 범주에 데이터를 할당하는 알고리즘이다. 범주 a, b에 속할 확률은 아래와 같다.
- 범주 a에 속할 확률
- 범주 b에 속할 확률
-P(a)와 P(b)는 사전확률로 범주 a와 b에 해당하는 레코드를 전체 레코드로 나눈 비율을 의미한다.
k-NN 알고리즘
k-NN (최근접 이웃법)(중)
k-Nearest Neighborhood
지도 학습 알고리즘 중 하나로, 데이터 포인트의 근접 이웃을 활용하여 분류 또는 회귀 문제를 해결하는 데 사용된다.
- 새로운 데이터의 클래스(범주)를 해당 데이터와 가장 가까이 있는 k개 데이터들의 클래스(범주)로 결정한다.
- k는 이웃의 개수를 나타내며, 적절한 k를 선택하는 것이 모델의 성능에 영향을 미친다.
k의 선택은 학습의 난이도와 데이터의 개수에 따라 결정될 수 있다. - 일반적으로는 최적의 k 값을 찾기 위해 총 데이터들의 제곱근 값을 사용한다.
- k-NN은 함수가 오직 지역적으로 근사하고 모든 계산이 분류될 때까지 연기되는 인스턴스 기반 학습이다.
- 작은 k는 모델이 데이터의 노이즈에 민감하게 반응하게 하고, 큰 k는 모델의 결정 경계를 더 부드럽게 만든다.
고객의 구매 이력을 기반으로하는 간단한 k-NN의 예시.
- 온라인 쇼핑몰에서 사용자의 과거 구매 이력을 바탕으로, 새로운 사용자의 선호 제품을 예측하고자 한다.
- 과정
1. 데이터 수집 : 기존 사용자들의 과거 구매 이력을 수집
2. 학습 단계 : 각 사용자의 구매 이력을 이용하여 k-NN 모델 학습
3. 예측 단계 : 새로운 사용자가 특정 제품 카테고리를 구매하려고 할 때, 해당 사용자와 가장 근접한 k명의 이웃을 찾아서 이들의 마지막 구매 제품을 확인
4. 분류 : 다수결을 통해 새로운 사용자의 선호 제품 카테고리를 예측한다.
SVM, 서포트벡터머신
Support Vector Machine, SVM
분류 및 회귀 분석을 위한 지도 학습 모델로 사용되는 강력한 알고리즘이다. 특히 분류 성능이 뛰어나 분류 분석에 자주 사용된다.
- SVM 분류 모델은 데이터가 표현된 공간에서 분류를 위한 경계를 정의한다. 즉, 분류되지 않은 새로운 값이 입력되면 경계의 어느 쪽에 속하는지를 확인하여 분류 과제를 수행한다.
- 초평면을 이용하여 카테고리를 나누어 비확률적 이진 선형모델을 만든다.
- SVM은 분류할 때 가장 높은 마진을 가져가는 방향으로 분류한다. 마진이 크면 클수록 학습에 사용하지 않는 새로운 데이터가 들어오더라도 분류를 잘 할 가능성이 높기 때문이다.
- 일반적으로 SVM은 분류 또는 회귀분석에 사용 가능한 초평면 또는 초평면들의 집합으로 구성되어 있다. 초평면이 가장 가까운 데이터와 큰 차이를 가진다면 오차가 작아지기 때문에 좋은 분류를 위해서는 어떤 분류된 점에 대해서 가장 가까운 학습 데이터와 가장 먼 거리를 가지는 초평면을 찾아야 한다.
- 초평면 f(x)는 wTx+b=0 으로 나타낼 수 있다.
- SVM은 높은 차원의 데이터셋에서도 잘 작동하며, 다양한 응용 분야에서 사용된다. 주로 이미지 분류, 텍스트 분류, 손글씨 인식 등 다양한 분야에서 효과적으로 활용되고 있다.
연습문제
1번
베이즈에 대한 설명으로 옳지 않은 것은?
1. 베이지안 확률은 객관적으로 확률을 해석한다.
2. 베이지안 확률은 분석자의 사전지식까지 포함해 분석하는 방법이다.
3. 빈도 확률은 사건이 발생한 횟수의 장기적인 비율을 의미한다.
4. 베이즈 정리에서 확률은 ‘주장 혹은 믿음의 신뢰도’로 나타난다.
정답
빈도 확률은 객관적으로 확률을 해석하며 베이지안 확률은 주관적으로 확률을 해석한다
2번
k-NN 알고리즘에 대한 설명으로 옳지 않은 것은?
1. 큰 k는 모델이 데이터의 노이즈에 민감하게 반응한다.
2. k-NN은 함수가 오직 지역적으로 근사하고 모든 계산이 분류될 때까지 연기되는 인스턴스 기반 학습이다.
3. 적절한 k를 선택하는 것이 모델의 성능에 영향을 미친다
4. 데이터 포인트의 근접 이웃을 활용하여 분류 또는 회귀 문제를 해결하는 데 사용된다.
정답
작은 k는 모델이 데이터의 노이즈에 민감하게 반응하게 하고, 큰 k는 모델의 결정 경계를 더 부드럽게 만든다.
3번
서포트 벡터 머신에 대한 설명으로 옳지 않은 것은?
1. 주로 이미지 분류, 텍스트 분류, 손글씨 인식 등에서 효과적으로 활용된다.
2. 분류 및 회귀 분석을 위한 지도 학습 모델로 사용된다.
3. 초평면을 이용하여 카테고리를 나누어 확률적 이진 선형모델을 만든다.
4. 분류할 때 가장 높은 마진을 가져가는 방향으로 분류한다
정답
초평면을 이용하여 카테고리를 나누어 ‘비확률적’ 이진 선형모델을 만든다.
13.6
성과평가
좋은 모델을 선정하기 위해서는 평가 기준이 필요합니다
모델 평가 기준
모형 평가의 기준으로는 다른 데이터에서도 안정적으로 적용이 가능한지 판단하는 일반화, 모형의 계산 양에 비한 모형의 성능을 고려하는 효율성, 구축된 모형의 분류 정확성 등의 기준이 있습니다
이번에 컴퓨전매트릭스(혼동행렬, Confusion Matrix)라고도 불리는 오분류표, ROC 커브, 이익도표, 향상도곡선에 대해 알아보겠습니다.
오분류표와 평가 지표
대부분의 분류 분석 모형의 예측 결과는 분류 범주로 나타남에 따라 분류 분석 모형의 평가에는 오분류표가 일반적으로 사용된다.
-
분류 분석 성과 평가는 분류 분석 모형이 내놓은 답과 실제 정답이 어느 정도 일치하는지를 판단하는 것이기 때문에 일반적으로 정답과 예측값은 True/False, 0/1, Yes/No 등의 이진 분류 클래스 레이블을 갖는다.
-
분류 분석 후 예측한 값과 실제 값의 차이를 교차표 형태로 정리한 것을 오분류표 또는 컨퓨전매트릭스라고 부른다.
-
오분류표는 분류오차의 정확한 추정치를 얻기 위해서 평가용(test) 데이터로부터 계산되어 얻은 표다. 훈련용(train) 데이터를 활용한 오분류표는 과적합의 위험성이 존재하기 때문이다.
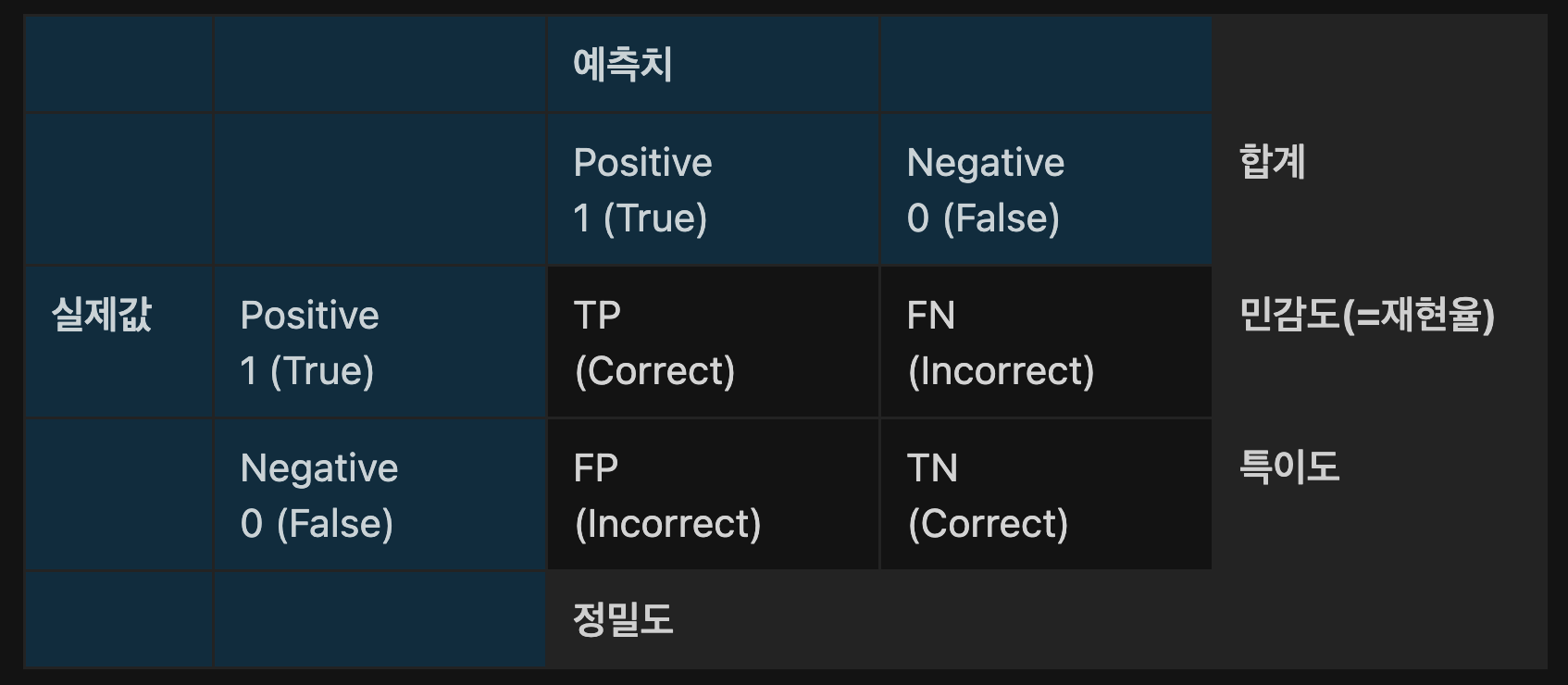
TP(True Positive) : 예측한 값이 Positive이고 실제 값도 Positive인 경우
FP(False Positive) : 예측한 값이 Positive 이고 실제 값은 Negative인 경우
TN(True Negative) : 예측한 값이 Negative이고 실제 값도 Negative인 경우
FN(False Negative) : 예측한 값이 Negative 이고 실제 값은 Positive인 경우 -
오분류율 (Error Rate) : 전체 관측치 중 잘못 예측한 비율
-
정분류율(=정확도)(Accuracy) : 전체 관측치 중 올바르게 예측한 비율
-
정밀도 (Precision) : 예측 True 중 올바르게 True를 찾아낸 비율
-
민감도(=재현율)(Sensitivity) : 실제 True 중 올바르게 True를 찾아낸 비율
-
특이도 (Specificity) : 실제 False 중 올바르게 False를 찾아낸 비율
- F1 Score : 정밀도와 재현율의 조화평균 값으로, 정밀도의 재현율은 높은 확률로 음의 상관관계를 가질 수 있는 효과를 보정하기 위한 지표로 값이 높을수록 좋다.
- 거짓 긍정률 (FPR : False Positive Rate) : 실제 Negative인 값 중 Positive로 잘못 분류한 비율
평가 지표 계산 예제
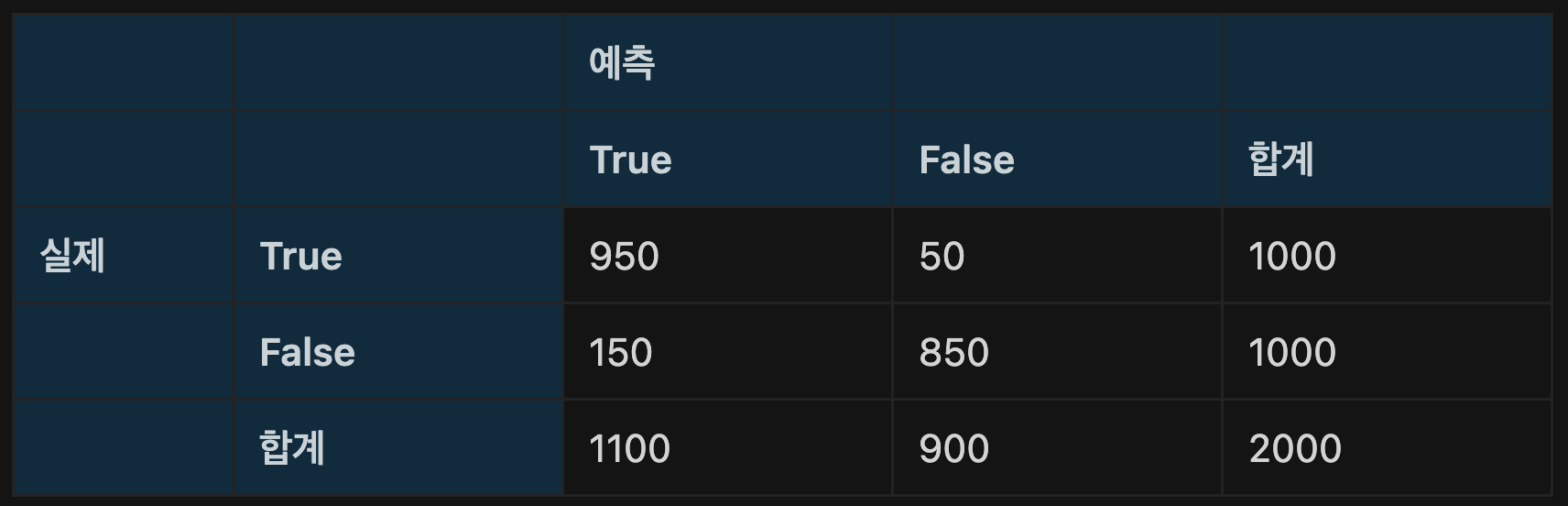
정분류율(정확도) : 950+850 / 950+50+150+850 >> 1800/2000 >> 0.9
오분류율 : 150+50 / 950+50+150+850 >> 200/2000 >> 0.1
정밀도 : 950 / 950+150 >> 950/1100 >> 0.864
민감도 : 950 / 950+50 >> 950/1000 >> 0.95
특이도 : 850 / 150+850 >> 850/1000 >> 0.85
F1스코어 : 2 0.8640.95/(0.864+0.95) >> 0.905
### ROC 커브(중)
ROC 커브란
Receiver Operating Characteristic Curve의 약자로 분류 분석 모형의 평가를 쉽게 비교할 수 있도록 시각화한 그래프.
- x축은 FPR(1-특이도) 값을, y축은 TPR(민감도) 값을 갖는 그래프
- 이진 분류 (0 또는 1) 모형의 성능을 평가하기 위해 사용
- ROC 곡선 아래의 면적을 의미하는 ‘AUROC(Area Under ROC)’값이 크면 클수록 (=1에 가까울수록) 모형의 성능이 좋다고 평가한다.
TPR (True Positive Rate) : 1인 케이스에 대한 1로 예측한 비율
FPR (False Positive Rate) : 0인 케이스에 대한 1로 잘못 예측한 비율
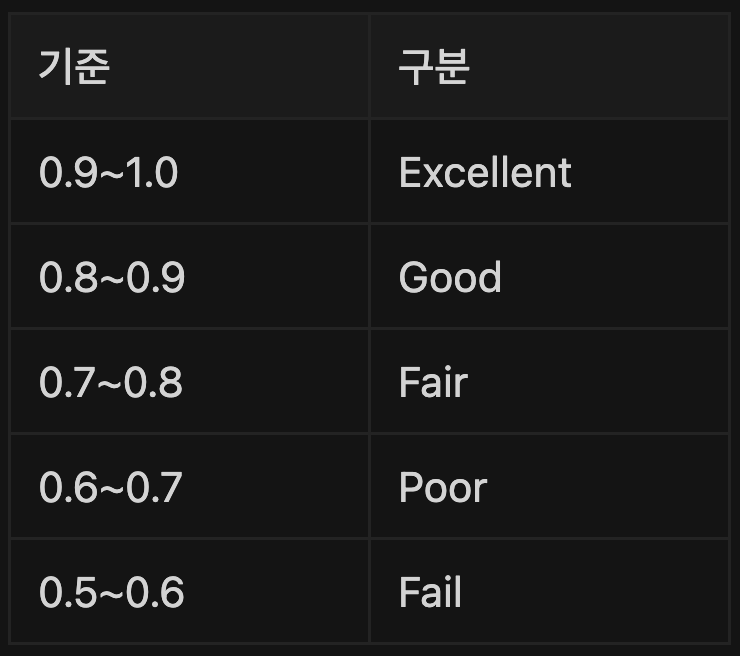
AUROC를 이용한 정확도의 판단 기준
ROC 커브 예제
infert자료에 대한 분류 분석 모형 평가 비교를 위하여 의사결정나무 모형은 R패키지 {C50}의
C5.0() 함수를 사용하고 신경망 모형은 {neuralnet}의 neuralnet() 함수를 사용한다. 모형 학습 및 검증을 위하여 70%의 훈련용 자료와 30%의 검증용 자료로 구분한다.
> set.seed(1234)
> infert<-infert[sample(nrow(infert)),]
> infert<-infert[,c('age','parity','induced','spontaneous','case')]
> trainData<-infert[1:(nrow(infert)*0.7),]
> testData<-infert[((nrow(infert)*0.7)+1):nrow(infert),]각 모형을 학습하고, 학습된 모형을 검증용 자료에 적용시켜 예측값을 도출시킨 뒤 ROC 그래프 작성을 위해 각 예측 결과를 검증용 자료에 함께 저장한다.
> library(neuralnet)
> net.infert<-neuralnet(case~age+parity+induced+spontaneous,data=trainData,hidden=3,err.fct='ce',linear.output = FALSE,likelihood=TRUE)
> n_test<-subset(testData,select=-case)
> nn_pred<-compute(net.infert,n_test)
> testData$net_pred<-nn_pred$net.result
> head(testData)
age parity induced spontaneous case net_pred
191 40 2 0 0 0 0.08925963
129 37 1 0 0 0 0.08910922
170 35 3 0 0 0 0.08925963
12 37 4 2 1 1 0.50665901
37 36 1 0 1 1 0.63951267
218 27 3 2 0 0 0.50665901
> install.packages('C50')
> library(C50)
> trainData$case<-factor(trainData$case)
> dt.infert<-C5.0(case~age+parity+induced+spontaneous,data=trainData)
> testData$dt_pred<-predict(dt.infert,testData,type='prob')[,2]
> head(testData)
age parity induced spontaneous case net_pred dt_pred
191 40 2 0 0 0 0.08925963 0.1792474
129 37 1 0 0 0 0.08910922 0.1792474
170 35 3 0 0 0 0.08925963 0.1792474
12 37 4 2 1 1 0.50665901 0.1931316
37 36 1 0 1 1 0.63951267 0.5775320
218 27 3 2 0 0 0.50665901 0.1792474각 모형의 예측 결과값을 기반으로 ROC 그래프를 작성하기 위해서는 R패키지 {Epi}의 ROC() 함수를 사용한다.
> install.packages('Epi')
> library (Epi)
> neural_ROC <- ROC(form=case~net_pred, data=testData, plot='ROC')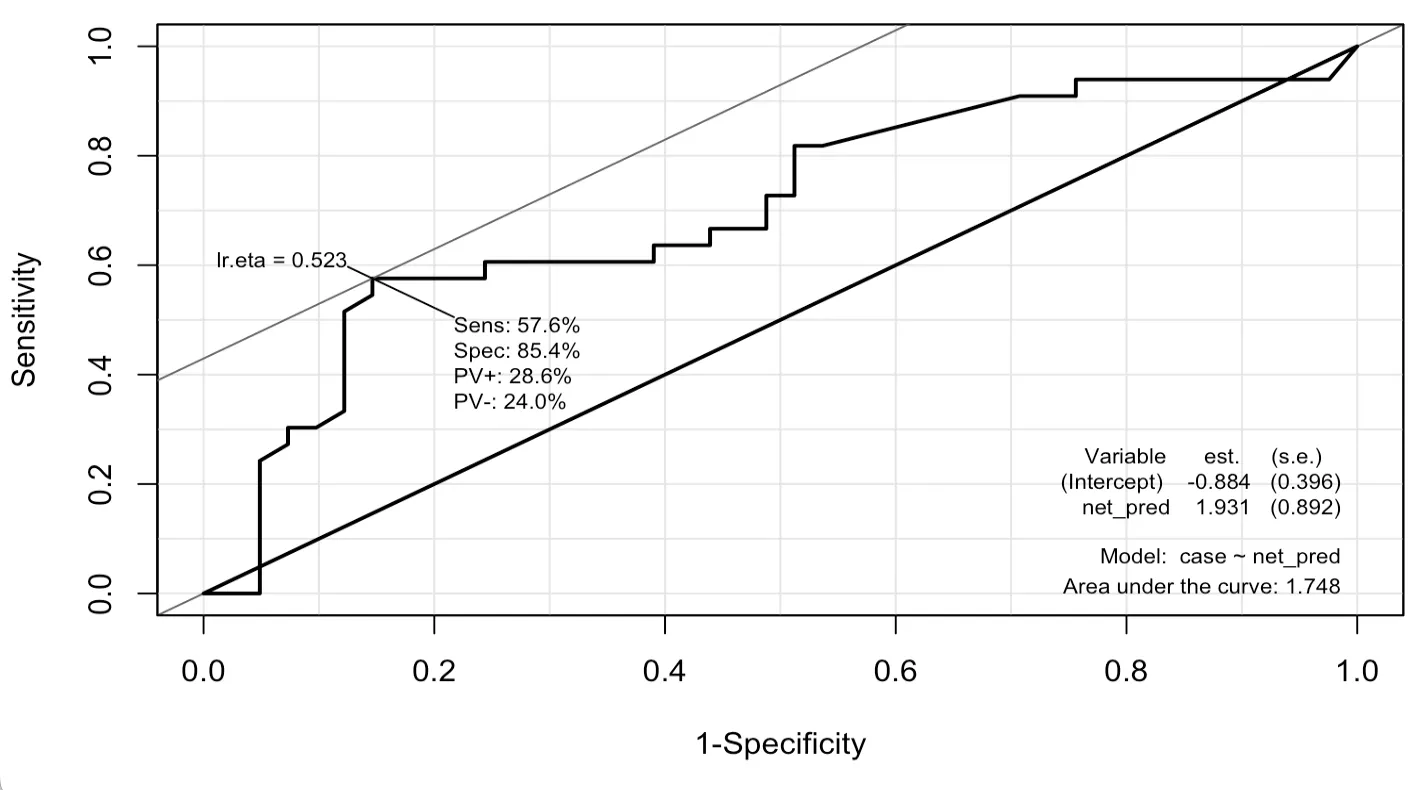
> dtree_ROD <- ROC (form=case~dt_pred, data=testData, plot='ROC')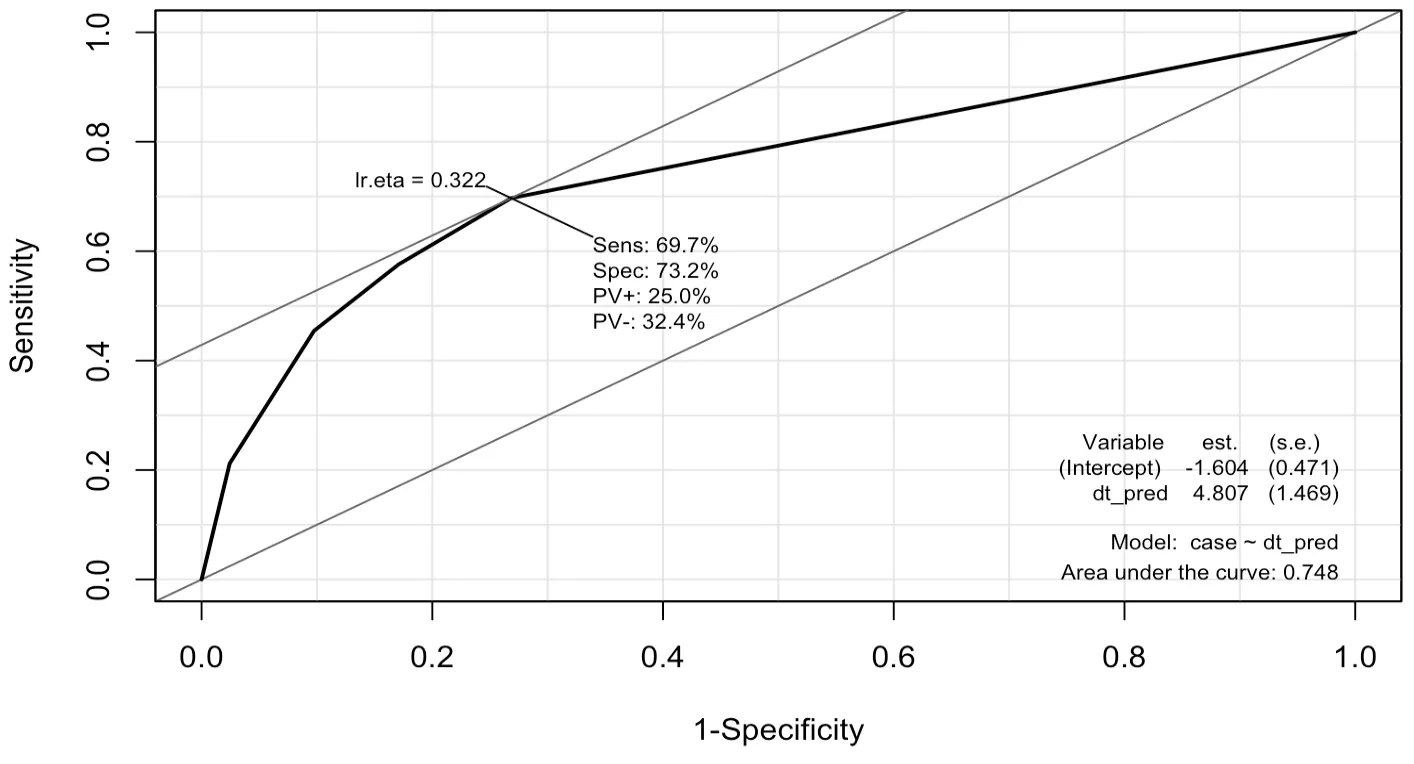
두 분류 분석 모형 간의 평가 결과 신경망 모형의 AUC(1.748)가 의사결정나무의 AUC(0.748)보다 크게
나와 신경망 모형의 분류 분석 모형이 더 높은 성과를 보인다고 할 수 있다.
이익도표와 향상도 곡선
이익도표 (중)
이익도표(Lift Chart) 는 모델의 성능을 판단하기 위해 작성한 표이며, 이득곡선, 이득도표라고도 부른다. 얼마나 예측이 잘 이루어졌는지를 나타내기 위해 임의로 나눈 각 등급별로 반응검출율, 반응률, 리프트 등의 정보를 산출하여 나타내는 도표이다.
- 데이터셋의 목표범주에 속할 확률을 내림차순으로 정렬하여 데이터를 몇 개의 구간으로 나누어 각 구간에서의 성능을 판단하고, 기본 향상도에 비해 반응률이 몇 배나 높은지를 계산하는데 이것을 향상도(Lift)라고 한다.
- 이익도표의 각 등급은 예측 확률에 따라 매겨진 순위이기 때문에, 상위 등급에서는 더 높은 반응률을 보이는 것이 좋은 모형이라고 평가할 수 있다.
- 예측력 = (목표범주 그룹1에 속한 데이터 개수)/(전체 데이터 개수)
- 향상도 = (반응률)/(예측력)
- 등급별로 향상도가 급격하게 변동할수록 좋은 모형이라고 할 수 있다. (모델의 상위 등급, 하위 등급간의 예측 성과 차이가 커야함.)
- 각 등급별로 향상도가 들쭉날쭉하면 좋은 모형이라고 볼 수 없다. (각 등급 내에서의 향상도의 일관성을 지켜야 함)
향상도 곡선
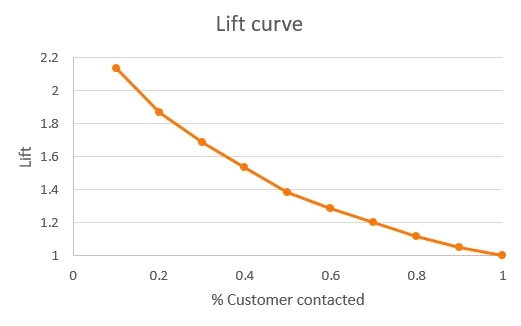
향상도 곡선(Lift Curve) 은 누적 반응률이 전체 데이터 대비 얼마나 향상되었는지를 보여준다
- 모델의 성과가 얼마나 향상되었는지 구간별로 파악할 수 있다.
- 곡선이 기울어질수록(큰 값에서 시작 후 급격히 감소) 모델 또는 전략의 효과가 더 크다고 해석할 수 있다.
연습문제
1번
오분류표 평가지표에 대한 설명으로 옳지 않은 것은?
1. 정확도 (Accuracy) : 예측 True 중 올바르게 True를 찾아낸 비율
2. 오분류율 (Error Rate) : 전체 관측치 중 잘못 예측한 비율
3. 거짓 긍정률 (FPR : False Positive Rate) : 실제 Negative인 값 중 Positive로 잘못 분류한 비율
4. 특이도 (Specificity) : 실제 False 중 올바르게 False를 찾아낸 비율
정답
예측 True 중 올바르게 True를 찾아낸 비율 정확도가 아니라 정밀도 (Precision)이다.
2번
ROC 커브에 대한 설명으로 옳지 않은 것은?
1. 분류 분석 모형의 평가를 쉽게 비교할 수 있도록 시각화한 그래프
2. 이진 분류 모형의 성능을 평가하기 위해 사용
3. AUROC 값이 크면 클수록 모형의 성능이 좋다고 평가
4. TPR : 0인 케이스에 대해 1로 예측한 비율
정답
TPR (True Positive Rate) : 1인 케이스에 대한 1로 예측한 비율
FPR (False Positive Rate) : 0인 케이스에 대한 1로 잘못 예측한 비율
3번
분류모형성과에 대한 설명으로 옳지 않은 것은?
1. 이익도표는 등급별로 향상도가 급격하게 변동할수록 좋은 모형이라고 할 수 있다.
2. 향상도 곡선은 곡선이 기울어질수록 효과가 크다고 볼 수 있다.
3. 이득곡선은 모델의 성능을 판단하기 위해 작성한 표다.
4. 향상도 곡선이 갈수록 급격히 감소할 경우 안정적이지 않다고 볼 수 있다.
정답
향상도 곡선은 큰 값에서 시작 후 급격히 감소할 경우 모델 또는 전략의 효과가 더 크다고 해석할 수 있다.
