14. 정형 데이터 마이닝 - 군집분석, 연관분석
14.1. 군집분석 (1)
군집분석
군집분석 개념
군집분석은 각 개체에 대해 관측된 여러 개의 변수 () 값들로부터 개의 개체를 유사한 성격을 가지는 몇 개의 군집으로 집단화하고, 형성된 군집들의 특성을 파악하여 군집들 사이의 관계를 분석하는 다변량분석 기법이다.
- 군집 분석에 이용되는 다변량 자료는 별도의 반응변수가 요구되지 않으며, 오로지 개체들 간의 유사성에만 기초하여 군집을 형성한다. 군집 분석은 이상값 탐지에도 사용되며, 심리학, 사회학, 경영학, 생물학 등 다양한 분야에 이용되고 있다.
- 생물학에서는 종의 분류, 마케팅에서는 고객 특성 파악, 금융에서는 산업 분석 등에 활용되며 추천 서비스가 등장하는 기반을 제공하였다.
- 군집의 개수나 구조에 대한 가정 없이 데이터들 사이의 거리를 기준으로 군집화를 유도한다.
- 군집분석의 평가 지표로는 계수가 사용되는데, 응집도와 분리도를 계산하며 그 값이 1에 가까울수록 완벽하게 분리되었다고 판단한다.
- 군집분석에서는 관측 데이터 간 유사성이나 근접성을 측정해 어느 군집으로 묶을 수 있는지 판단해야 하는데, 거리측도로는 유클리디안 거리, 맨하튼 거리 등이 있고 유사성 측도로는 코사인 거리와 상관계수가 있다. 거리가 가까울수록 유사성이 크다.
단위설명
- 계수(유사도) : 값이 높을수록 두 데이터의 거리가 가까움을 의미한다.
- 거리 : 1에서 유사도를 뺀 값으로, 유사도가 클수록 거리 값은 작아진다(=두 데이터가 가깝다)
거리 측도 - 연속형 변수인 경우
거리 측도 - 범주형 변수인 경우
유클리디안 거리(Euclidean)
- 두 점 사이의 거리를 계산할 때 가장 많이 사용하는 계산 방법이다.
- 두 점 사이의 가장 짧은 거리를 계산한다.
- 통계적 개념이 포함되어 있지 않아 변수들의 산포 정도를 감안하지 않는다.
맨하튼 거리(Manhattan)
- 유클리디안 거리와 함께 가장 많이 사용되는 거리로 맨하튼 도시에서 건물에서 건물을 가기 위한 최단 거리를 구하기 위해 고안된 거리다.
- 두 점 사이를 가로지르지 않고 길을 따라 갔을 때의 거리
- 사거리라고도 표현하며, 도시에서 최단거리를 움직이듯 변수들의 차이의 단순합으로 계산한 거리다.
체비셰프 거리(Chebychev)
변수 간 거리 차이 중 최댓값을 데이터 간의 거리로 정의한다.
표준화 거리(Standardized)
- 해당변수의 표준편차로 척도 변환한 후 유클리디안 거리를 계산하는 방법이다.
- 표준화하게 되면 척도의 차이, 분산의 차이로 인한 왜곡을 피할 수 있다.
마할라노비스 거리(Mahalanobis)
- 표준화 거리가 고려하지 못한 변수 간 상관성까지 고려한 거리다.
- 두 벡터 사이의 거리를 산포를 의미하는 표본공분산으로 나눠주어야 하며, 그룹에 대한 사전 지식 없이는 표본공분산S를 계산할 수 없으므로 사용하기 곤란하다.
민코프스키 거리(Minkowski)
- 맨하튼 거리와 유클리디안 거리를 한번에 표현한 공식이다.
- 일 때는 맨하튼 거리이며 일 때는 유클리디안 거리가 된다
캔버라 거리(Canberra)
주로 희소한 데이터에서 사용되며, 변수 간의 상대적인 크기에 민감한 특성이
예제를 통해 계수 구하기
x와 y의 값이 아래와 같이 있다고 할 때, 각 계수의 값을 구하시오.

거리 측도 - 범주형 변수인 경우
단순 일치 계수(SMC)
- 두 객체 i와 j간의 상이성을 불일치 비율로 계산한다.
- P는 변수의 총 개수이며, m은 객체 i와 j가 같은 상태인 변수의 수를 의미한다.
- 쉽게 말해, 전체 변수의 수들 중, 동일한 변수의 수가 몇 개인지 세는 것이다.
자카드 지수
- 두 집합 사이의 유사도를 측정하는 지표이다.
- 두 집합이 같으면 1, 완전히 다르면 0의 값을 갖는다.
자카드 거리
- 자카드 지수를 거리화하기 위한 값이다.
- 완전히 다르면 먼 거리를 갖는 1, 완전히 동일하면 거리를 0으로 변환하기 위해 1에서 자카드 지수를 뺀 값이다.
코사인 유사도
- 텍스트의 유사도를 측정하기 위한 지표이다.
- 크기가 아닌 방향성을 측정한다.
- 완전히 일치하면 1의 값, 완전히 다른 방향이면 -1의 값을 갖는다.( : 두 벡터의 내적 값, : 벡터의 크기)
코사인 거리
- 코사인 유사도를 거리화하기 위한 것으로, 1에서 코사인 유도를 뺀 값이다.
순위 상관 계수
- 순서척도인 두 데이터 사이의 거리를 측정하기 위한 지표로서 스피어만 상관계수를 사용할 수 있다.
예제를 통해 계수 구하기!
x와 y의 값이 아래와 같이 있다고 할 때, 각각 값을 구하시오.
- 단순 일치 계수 :
- 자카드 지수 :
풀이
: 와 에서 둘 다 1인 원소의 개수
: 와 에서 적어도 하나가 1인 원소의 개수
계산과정
x와 y를 비교해 보면, 둘 다 1인 위치가 하나 있다. (두 번째 위치) 따라서
또는 가 1인 위치는 총 4개 있다 (첫 번째, 두 번째, 세 번째, 네 번째 위치). 따라서
- 코사인 거리 :
아래의 표를 확인 후, 2개 문서의 유사도를 측정하기 위한 코사인 거리의 값을 구하시오.
| review | diary | essay | |
|---|---|---|---|
| 문서 A | 1 | 0 | 5 |
| 문서 B | 4 | 7 | 3 |
계층적 군집분석
계층적 군집분석 개념
- 가장 유사한 개체를 묶어 나가는 과정을 반복하여 원하는 개수의 군집을 형성하는 방법이다.
-
계층적군집을 형성하는 방법
- 작은 군집으로부터 출발하여 군집을 병합해 나가는 병합적 방법>한 개의 항목으로 시작하여 군집을 형성해 나가는 매 단계마다 모든 그룹 쌍 간의 거리를 계산하여 가까운 순으로 병합을 수행한다. 이 과정을 한 개 그룹만 남을 때까지 혹은 종료의 조건이 될 때까지 반복한다. 여기에서 그룹 혹은 항목 간의 상대적 거리가 가까울수록 유사성이 높다고 말할 수 있다. 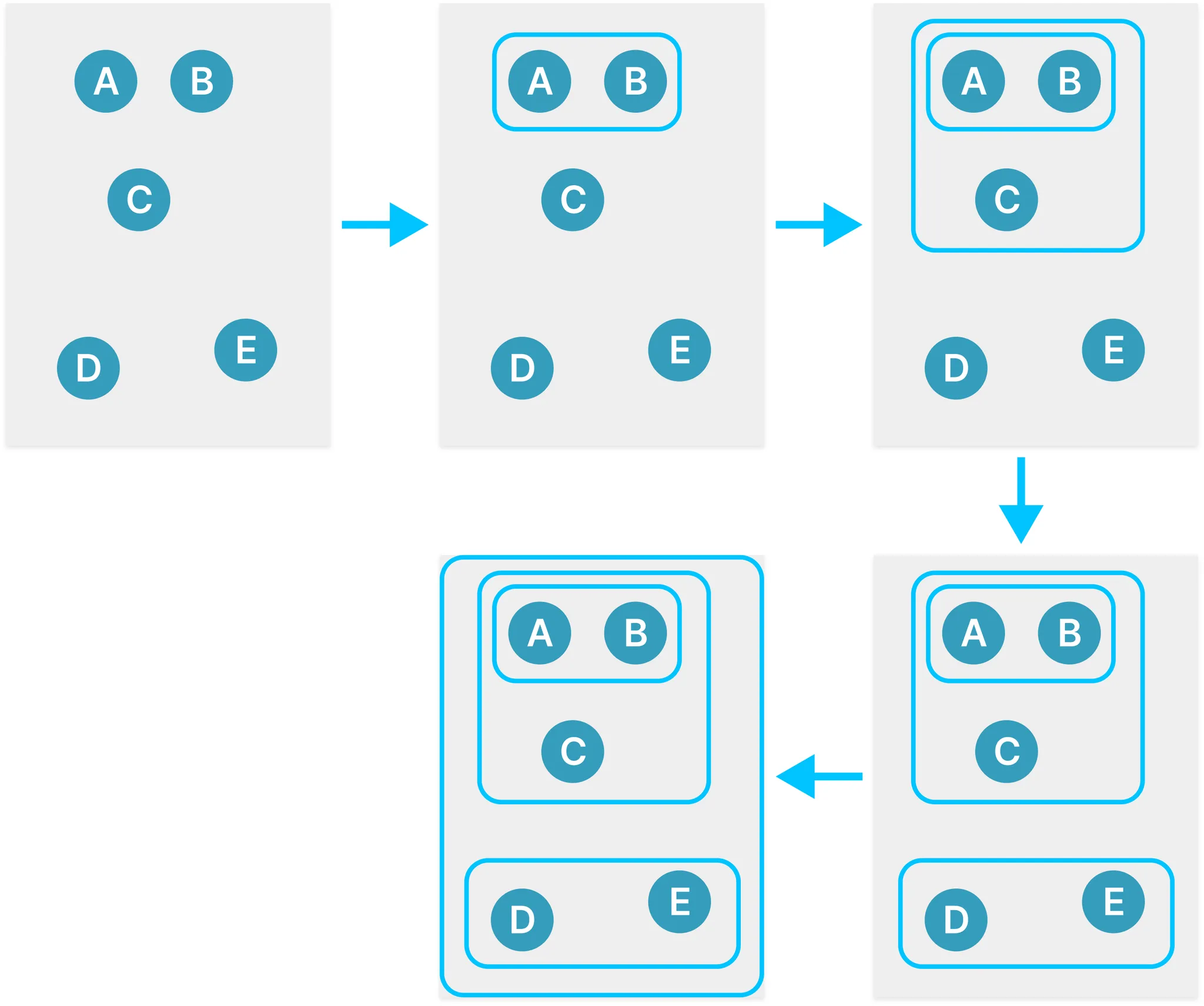 - 큰 군집으로부터 출발하여 군집을 분리해 나가는 분할적 방법
-
여러 데이터 중 가장 유사한 두 데이터를 하나의 군집으로 묶었다면 새로운 군집과 기존의 데이터 사이의 거리를 새로 측정해야 한다. 이때 새로운 거리를 어떻게 계산하느냐에 따라 여러 방법으로 나뉠 수 있다.
-
계층적 군집의 결과는 아래 이미지와 같이 덴드로그램의 형태로 표현된다. 이 구조를 통해서 항목 간의 거리, 군집 간의 거리를 알 수 있고 군집 내의 항목 간 유사정도를 파악함으로써 군집의 견고성을 해석할 수 있다.
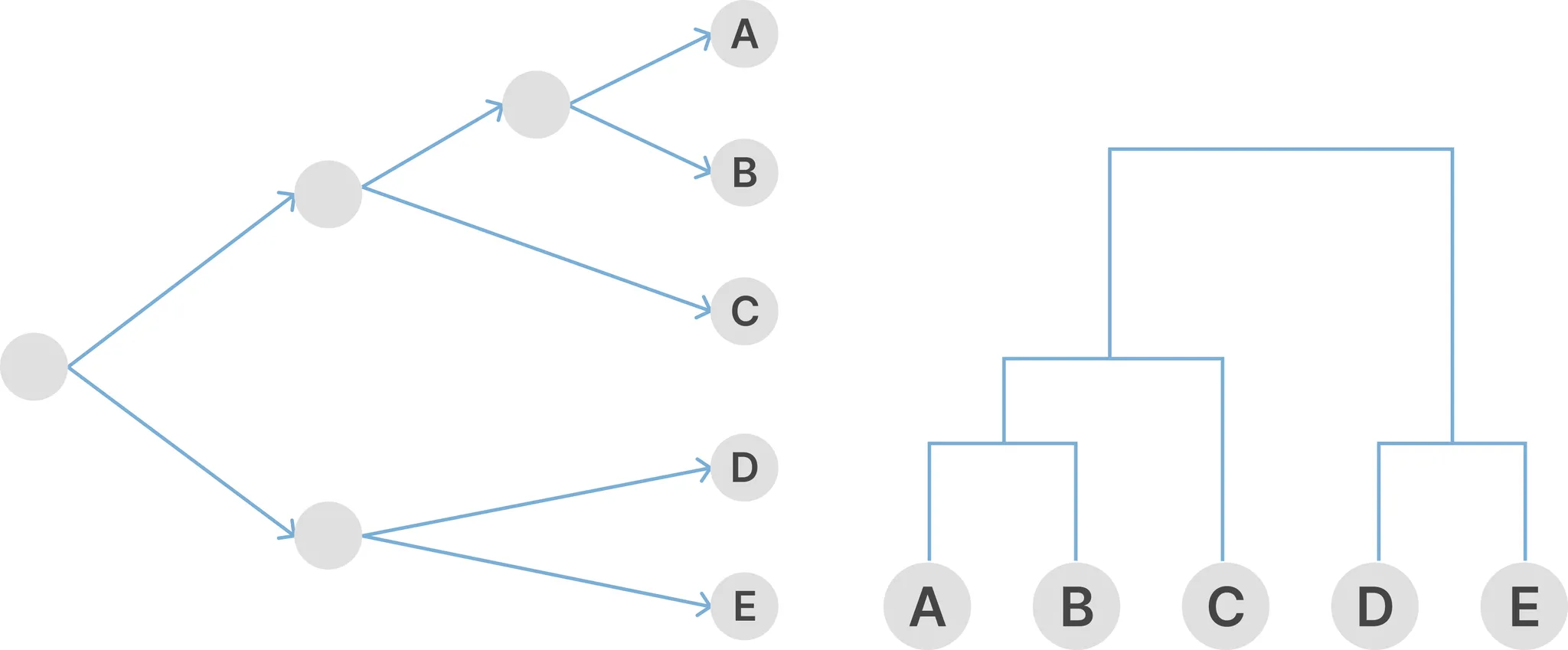
군집 간의 거리
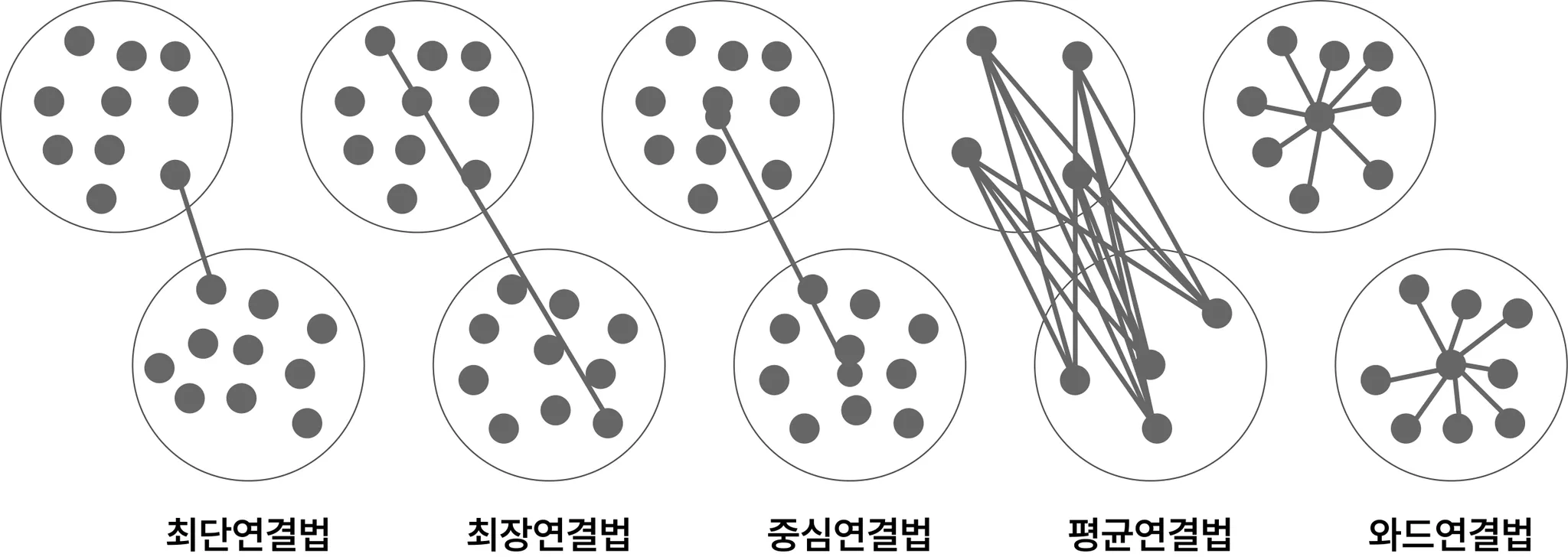
최단연결법
두 군집 사이의 거리를 각 군집에서 하나씩 관측 값을 뽑았을 때 나타날 수 있는 거리의 최소값으로 측정한다. 최단거리를 사용할 때 사슬 모양으로 생길 수 있으며, 고립된 군집을 찾는데 중점을 둔 방법이다. 대부분 관측치가 멀리 떨어져 있어도 하나의 관측치만 다른 군집과 가까이 있으면 병합이 가능하다.
최장연결법
완전연결법이라고도 하며 두 군집 사이의 거리를 각 군집에서 하나씩 관측 값을 뽑았을 때 나타날 수 있는 거리의 최대값으로 측정한다. 같은 군집에 속하는 관측치는 알려진 최대 거리보다 짧으며, 군집들의 내부 응집성에 중점을 둔 방법이다.
중심연결법
두 군집의 중심 간의 거리를 측정한다. 두 군집이 결합될 때 새로운 군집의 평균은 가중평균을 통해 구해진다.
평균연결법
모든 항목에 대한 거리 평균을 구하면서 군집화를 하기 때문에 계산량이
불필요하게 많아질 수 있다. 단일연결법과 최장연결법보다 이상치에 덜 민감하다.
와드연결법
군집 간의 거리에 기반하는 다른 연결 법과는 달리 군집 내의 오차 제곱합에 기초하여 군집을 수행한다. 보통 두 군집이 합해지면 병합된 군집의 오차 제곱합은 병합 이전 각 군집의 오차 제곱합의 합보다 커지게 되는데, 그 증가량이 가장 작아지는 방향으로 군집을 형성해 나가는 방법이다. 와드연결법은 크기가 비슷한 군집끼리 병합하는 경향이 있다.
최단 연결법 - 유클리디안 거리 예시
| 데이터 | X | Y |
|---|---|---|
| A | 2 | 4 |
| B | 1 | 2 |
| C | 6 | 4 |
| D | 3 | 3 |
| E | 3 | 1 |
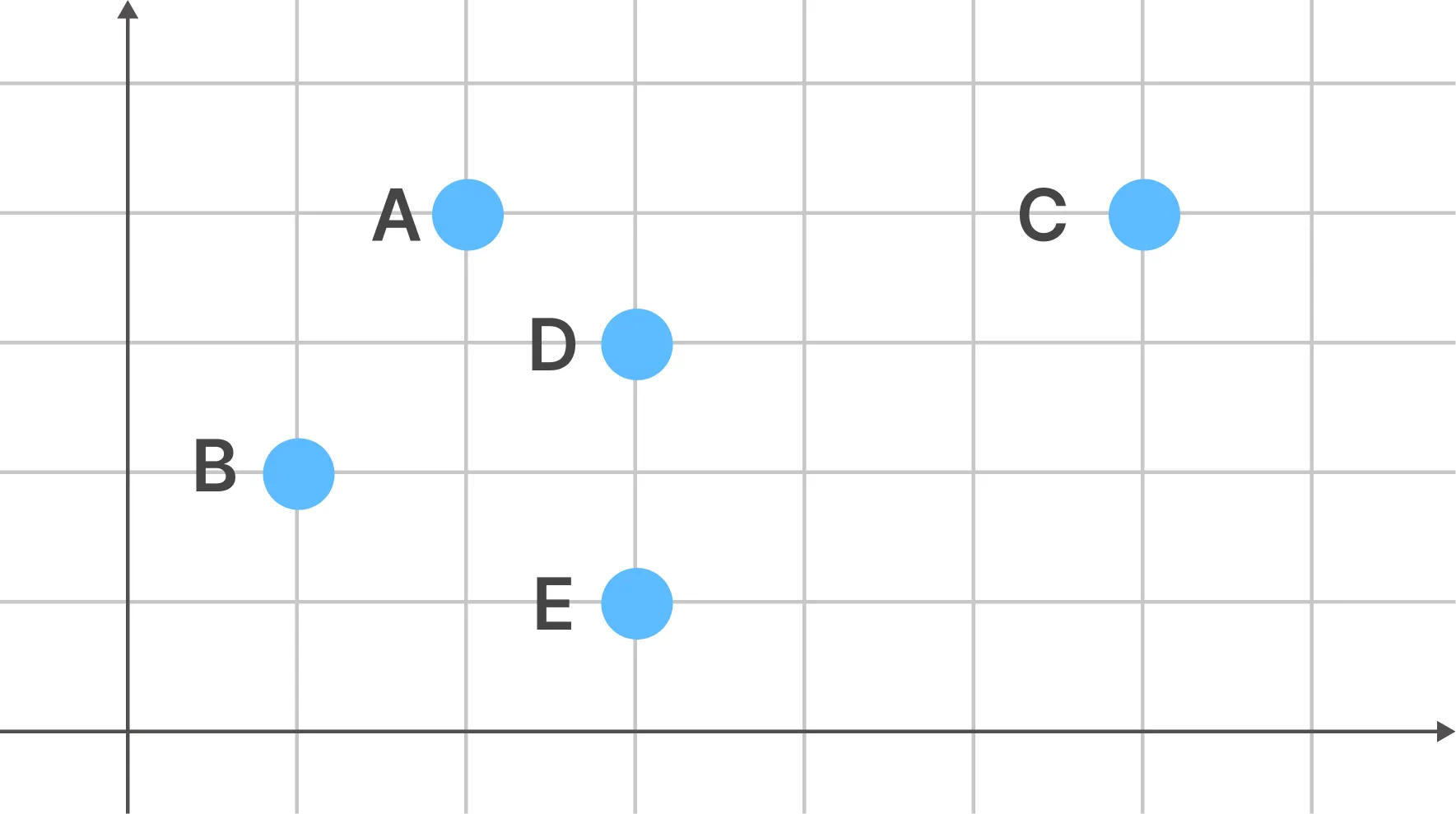
[1차 거리행렬]
| A | B | C | D | E | |
|---|---|---|---|---|---|
| A | 0 | ||||
| B | 0 | ||||
| C | 0 | ||||
| D | 0 | ||||
| E | 0 |
[2차 거리행렬]
| AD | B | C | E | |
|---|---|---|---|---|
| AD | 0 | |||
| B | 0 | |||
| C | 0 | |||
| E | 0 |
[3차 거리행렬]
| ADE | B | C | |
|---|---|---|---|
| ADE | 0 | ||
| B | 0 | ||
| C | 0 |
[4차 거리행렬]
| ABDE | C | |
|---|---|---|
| ABDE | 0 | |
| C | 0 |
마지막으로, ABDE와 C가 가장 가까우므로 ABCDE 군집을 형성한다. 모든 개체가 한 군집으로 묶이고 분석을 종료한다.
hclust() 함수를 이용한 계층적 군집 분석 예제
USArrests 자료는 미국 50개 주에서 1973년에 발생한 폭행, 살인, 강간 범죄를 주민 100,000명 당 체포된 사람의 통계 자료다. 주별 전체 인구에 대한 도시의 인구 비율을 함께 제공한다.
- dist()는 거리(또는 비유사성) 행렬을 제공하는 함수로 method= 옵션을 통해 다양한 방식으로 거리를 정의할 수 있다. dist() 함수의 method= 옵션에는 "euclidean", "maximum", "manhattan", "binary”, "minkowski" 등이 있다. hclust() 함수는 계층적 군집 분석을 수행하는 함수로 method= 옵션을 통해 병합 방법을 지정할 수 있다. hclust() 함수의 method= 옵션에는 “ward", "single", "complete", "average", "centroid" 등이 있다.
> data("USArrests")
> str(USArrests)
'data.frame': 50 obs. of 4 variables:
$ Murder : num 13.2 10 8.1 8.8 9 7.9 3.3 5.9 15.4 17.4 ...
$ Assault : int 236 263 294 190 276 204 110 238 335 211 ...
$ UrbanPop: int 58 48 80 50 91 78 77 72 80 60 ...
$ Rape : num 21.2 44.5 31 19.5 40.6 38.7 11.1 15.8 31.9 25.8 ...
> d<-dist(USArrests,method="euclidean")
> fit<-hclust(d,method="ave")
# 계층적군집 분석의 결과는 plot()함수를 통해 덴드로그램으로 시각화할 수 있다.
> par(mfrow=c(1,2))
> plot(fit)
> plot(fit,hang=-1)
> par(mfrow=c(1,1))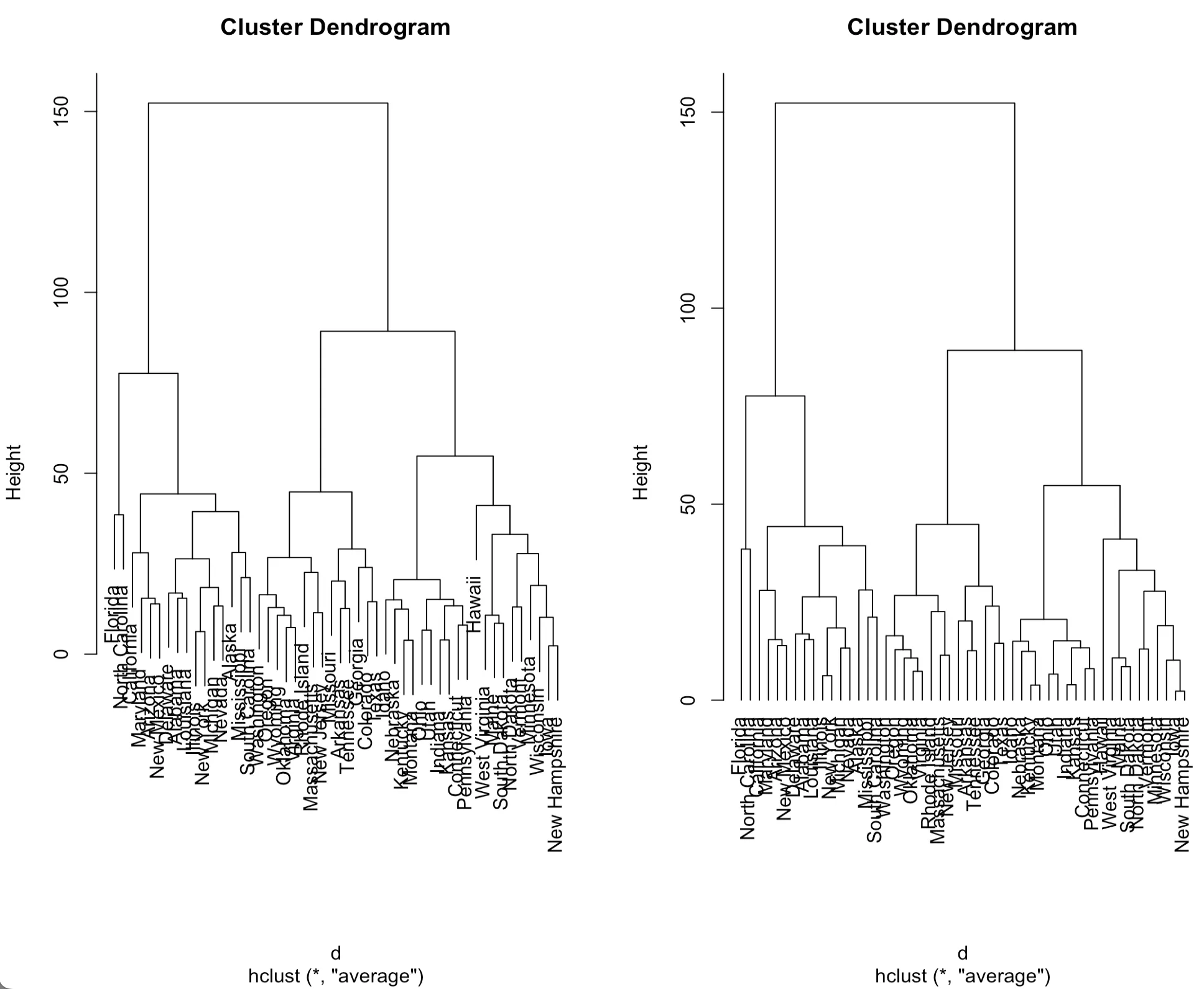
> groups<-cutree(fit,k=6)
> groups
Alabama Alaska Arizona
1 1 1
Arkansas California Colorado
2 1 2
Connecticut Delaware Florida
3 1 4
Georgia Hawaii Idaho
2 5 3
Illinois Indiana Iowa
1 3 5
Kansas Kentucky Louisiana
3 3 1
Maine Maryland Massachusetts
5 1 6
Michigan Minnesota Mississippi
1 5 1
Missouri Montana Nebraska
2 3 3
Nevada New Hampshire New Jersey
1 5 6
New Mexico New York North Carolina
1 1 4
North Dakota Ohio Oklahoma
5 3 6
Oregon Pennsylvania Rhode Island
6 3 6
South Carolina South Dakota Tennessee
1 5 2
Texas Utah Vermont
2 3 5
Virginia Washington West Virginia
6 6 5
Wisconsin Wyoming
5 6덴드로그램은 plot() 함수와 rect.hclust() 함수를 이용하여 각각의 그룹을 사각형으로 구분 지어 나타낼 수 있다. 위에서 cutree() 함수로 나누어진 그룹과 동일하게 표시되었음을 확인할 수 있다.
> plot(fit)
> rect.hclust(fit,k=6,border = "red")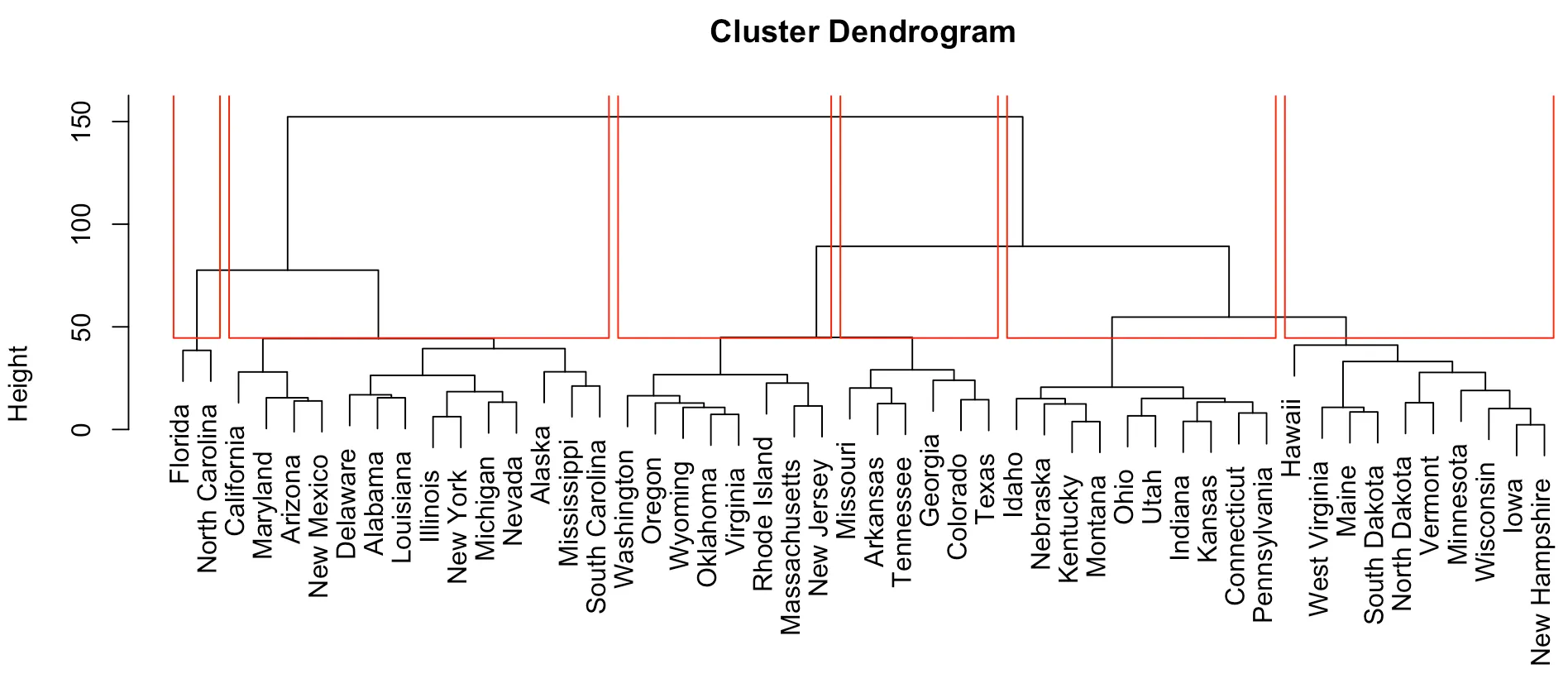
rect.hclust() 함수는 그룹수(k)를 이용하여 그룹을 시각화 할 뿐 아니라, tree의 높이(h)와 위치 (which) 이용하여 그룹의 전체 또는 일부를 나타낼 수 있다.
> hca<-hclust(dist(USArrests))
> plot(hca)
> rect.hclust(hca,k=3,border="red")
> rect.hclust(hca,h=50,which=c(2,7),border = 3:4)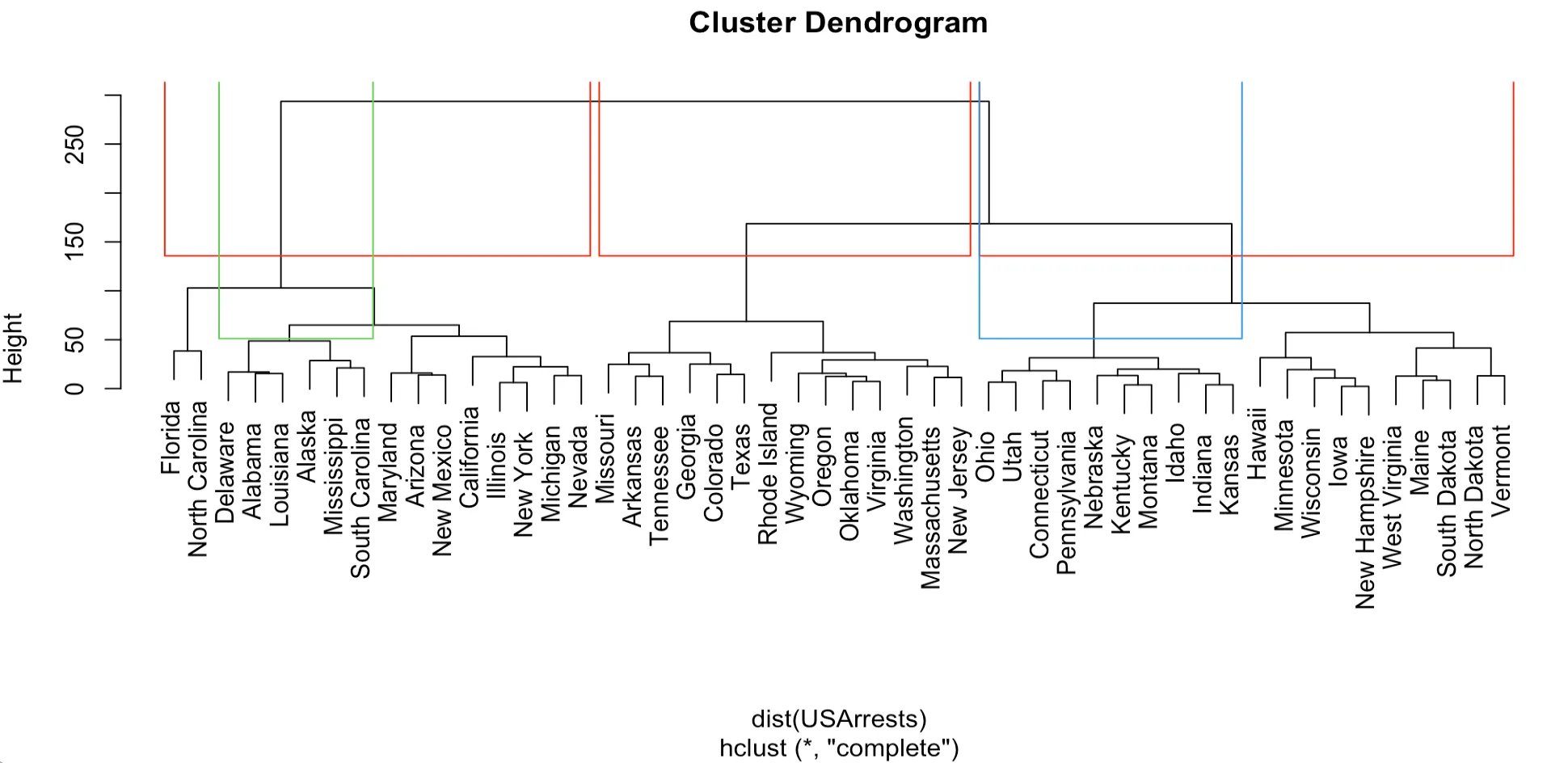
비계층적 군집분석
비계층적 군집분석이란?
계층적으로 군집을 형성하지 않고 구하고자 하는 군집의 수를 사전에 정의해 정해진 군집의 수만큼 형성하는 방법이다.
- 데이터 간 거리행렬을 사용하여 분석을 수행하지 않으며 원하는 군집의 수(k)의 초깃값을 설정하고 분석을 수행한다.
k-means 군집 (k-평균군집)
주어진 데이터를 k개의 클러스터로 묶는 알고리즘으로, 각 클러스터와 거리 차이의 분산을 최소화하는 방식으로 동작한다.
- 군집의 수(k)를 먼저 정한 뒤 집단 내 동질성과 집단 간 이질성이 모두 높게 전체 데이터를 k개의 군집으로 분할한다
k-means 군집 방법
- 원하는 군집의 개수와 초기값(seed)들을 정해 seed 중심으로 군집을 형성한다.
- 각 데이터를 거리가 가장 가까운 seed가 있는 군집으로 할당한다.
- 각 군집의 데이터들 사이의 평균값 혹은 중앙값을 계산하여 새로운 seed를 설정한다.
- 새로운 seed를 중심으로 군집을 재할당한다.
- 모든 개체가 군집으로 할당될 때까지 위 과정들을 반복한다. (3, 4번 과정 반복)
k-means 군집의 특징
- K개의 초기 중심값은 임의로 선택이 가능하며 가급적이면 멀리 떨어지는 것이 바람직하다.
- 초기 중심값의 선정에 따라 결과가 달라질 수 있다.
- 초기 중심으로부터의 오차 제곱합을 최소화하는 방향으로 군집이 형성되는 탐욕적 알고리즘이다.
k-means 군집의 장단점

알고리즘 단순, 빠르게 수행. 다양한 형태데이터에서 사용 가능. 계층적 군집분석 비해 많은 양의 데이터 다룰 수 있음. 초깃값 k개의 설정 어렵다. 목적없이 수행>결과 해석 어렵다. 데이터의 변수들이 연속형 변수여야 함. 안정된 군집 보장, 최적의 보장 없다.
DBSCAN
Density Based Spatial Clustering of Applications with Noise
- 대부분의 군집분석 알고리즘은 개체 간의 거리를 기반으로 군집을 형성하기 때문에 데이터의 분포가 볼록하지 않은 경우 효과적으로 군집을 형성하지 못하는 경우가 많았다.
- DBSCAN 알고리즘은 밀도 기반 군집분석의 한 방법으로 개체 간의 거리에 기반을 둔 다른 군집 방법 알고리즘과 다르게 개체들이 밀접한 정도에 기초해 군집을 형성한다.
- DBSCAN 알고리즘은 k-means 알고리즘과 달리 군집의 형태에 구애받지 않아 데이터의 분포가 기하학적이고 노이즈가 포함된 데이터셋에 대해서도 효과적으로 군집을 형성할 수 있고, 초기 군집의 수를 설정할 필요가 없다.
연습문제
1번
군집분석에 대한 설명으로 옳지 않은 것은?
1. 군집 분석에 이용되는 다변량 자료는 별도의 반응변수가 요구되지 않는다.
2. 마케팅에서는 고객 특성 파악, 금융에서는 산업 분석 등에 활용된다.
3. 유사도가 클수록 두 데이터의 거리가 멀어진다.
4. 오로지 개체들 간의 유사성에만 기초하여 군집을 형성한다.
정답
거리라는 단위는 1에서 유사도를 뺀 값으로, 유사도가 클수록 거리 값은 작아진다(=두 데이터가 가깝다)
2번
거리측도에 대한 설명 중 잘못된 것은?
1. 마할라노비스 거리는 표준화 거리가 고려하지 못한 변수 간 상관성까지 고려한 거리다.
2. 민코프스키 거리는 일 때는 맨하튼 거리이며 일 때는 유클리디안 거리가 된다.
3. 맨하튼 거리는 변수 간 거리 차이 중 최댓값을 데이터 간의 거리로 정의한다.
4. 두 점 사이의 가장 짧은 거리를 계산하는 것은 유클리디안 거리다.
정답
변수 간 거리 차이 중 최댓값을 데이터 간의 거리로 정의하는 것은 체비셰프 거리이다
- 맨하튼 거리 (Manhattan Distance) : 두 점 사이의 거리를 계산할 때, 각 축에서의 차이의 절대값을 더하여 구합니다.
- 체비셰프 거리 (Chebyshev Distance): 두 점 사이의 거리를 계산할 때, 각 축에서의 차이 중 가장 큰 값을 사용하여 구합니다.
3번 (중)
k-means 군집에 대한 설명으로 옳지 않은 것은?
1. 원하는 군집의 수(k)의 초깃값을 사전 설정하고 분석을 수행한다.
2. 이상값의 영향을 많이 받는다는 단점이 있다.
3. 계층적 군집분석에 비해 많은 양의 데이터를 다룰 수 있다.
4. 데이터의 변수들이 범주형 변수여야 한다
정답
거리를 측정해야하므로 데이터의 변수들이 연속형 변수여야 한다.
14.2. 군집분석 (2)
혼합분포군집
혼합분포군집의 개념
모형 기반의 군집 방법으로 데이터가 k개의 모수적 모형(흔히 정규분포 또는 다변량 정규분포를 가정함)의 가중합으로 표현되는 모집단 모형으로부터 나왔다는 가정하에서 모수와 함께 가중치를 자료로부터 추정하는 방법을 사용한다.
- k개의 각 모형은 군집을 의미하며, 각 데이터는 추정된 k개의 모형 중 어느 모형으로부터 나왔을 확률이 높은지에 따라 군집의 분류가 이루어진다.
- 흔히 혼합모형에서의 모수와 가중치의 추정(최대가능도추정)에는 EM 알고리즘이 사용된다.
EM 알고리즘
Expectation-Maximization, 기댓값 최대화
- EM 알고리즘은 확률모델의 최대가능도(Likelihood)를 갖는 모수와 함께 그 확률모델의 가중치를 추정하고자 한다.
- 각 데이터가 어느 분포에서 추출된 데이터인지 각 집단(잠재변수,Z)으로부터 기댓값을 구할 수 있다. 이때 추정된 기댓값을 활용하여 로그-가능도 함수가 최대로 되게 하는 모수를 찾을 수 있다.
- 알고리즘으로 두 가지 단계(E-step, M-step)로 구성되어 있다.
EM 알고리즘 진행 과정
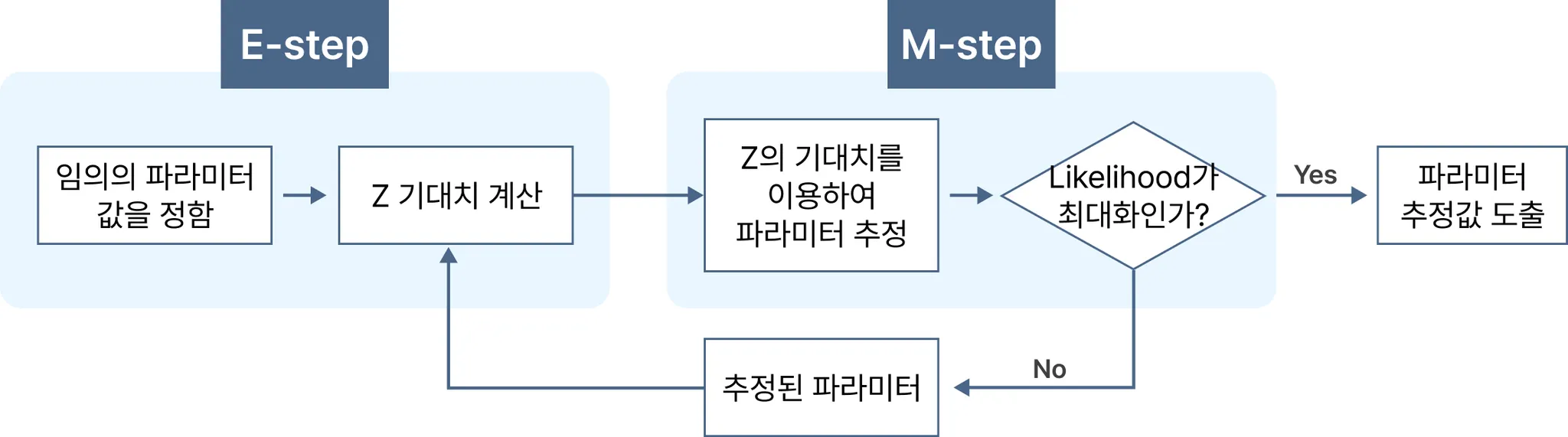
1. 파라미터(모수) 설정 : 두 개의 정규분포로 혼합된다고 가정할 경우 초기 파라미터(각 정규분포의 평균과 표준편차, 가중치) 값을 임의로 설정한다.
2. Z의 기댓값 계산 : 설정된 파라미터 값을 가진 분포로부터 실제 데이터가 얼마나 나올지를 알아보기 위해 로그 가능도 함수의 기댓값을 계산한다.
3. 새로운 파라미터 추정 : 위 과정에서 얻은 기댓값을 사용하여 새로운 파라미터 값을 추정한다.
4. 알고리즘 반복 및 종료 : 이전 가능도에 비해 가능도 증가량이 특정 기준값보다 낮으면 가능도가 최대가 되었다고 판단하고 알고리즘을 종료한다. 그렇지 않으면 2번과 3번 단계를 반복한다.
혼합 분포 군집모형의 특징
- k-평균 군집의 절차와 유사하지만 확률분포를 도입하여 군집을 수행한다.
- 군집을 몇 개의 모수로 표현할 수 있으며, 서로 다른 크기나 모양의 군집을 찾을 수 있다.
- EM 알고리즘을 이용한 모수 추정에서 데이터가 커지면 수렴에 시간이 걸릴 수 있다.
- 군집의 크기가 너무 작으면 추정의 정도가 떨어지거나 어려울 수 있다.
- k-평균 군집과 같이 이상치 자료에 민감하므로 사전에 조치가 필요하다.
혼합 분포 수행 예제
미국의 올드페이스풀 간헐천의 분출 간의 시간 자료(faithful)에 대해 정규혼합분포모형을 적합한다.
> install.packages("mixtools")
> library(mixtools)
> data("faithful")
> attach(faithful)
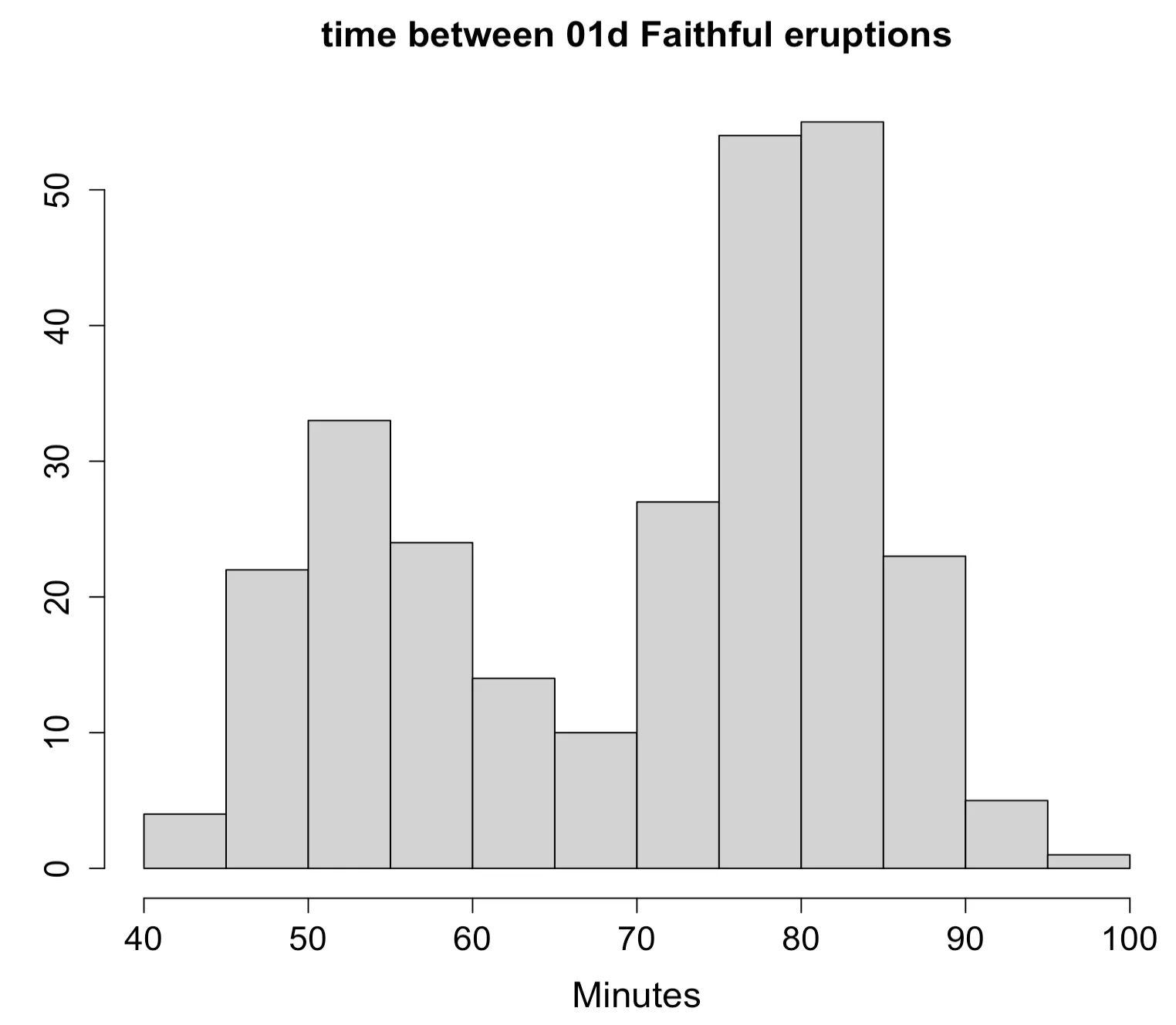
> hist(waiting,main = "time between 01d Faithful eruptions",
xlab="Minutes",ylab = "",cex.main=1.5, cex.lab=1.5, cex.axis=1.4)faithful 자료에 대한 히스토그램은 다음과 같다.
EM 알고리즘을 이용한 정규혼합분포의 추정결과는 다음과 같다.
> wait1 <- normalmixEM(waiting, lambda = .5, mu = c(55, 80) ,
sigma = 5)number of iterations= 9
> summary(wait1)
summary of normalmixEM object:
comp 1 comp 2
lambda 0.36085 0.63915
mu 54.61364 80.09031
sigma 5.86909 5.86909
loglik at estimate: -1034.002추정된 정규혼합분포를 시각화하면 다음과 같다.
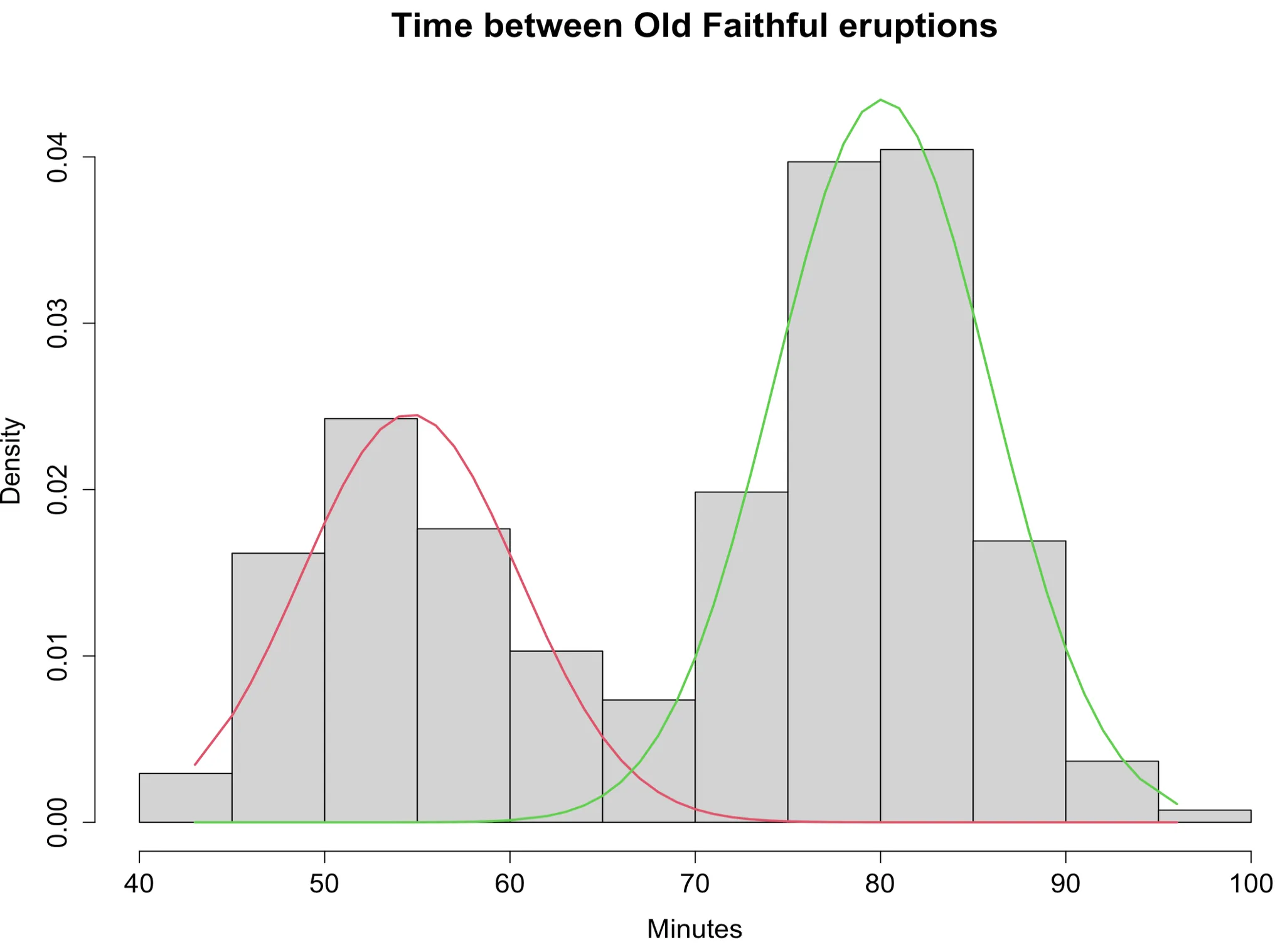
> plot(wait1, density=TRUE, cex.axis=1.4, cex.lab=1.4, cex.main=1.8,
main2="Time between Old Faithful eruptions", xlab2="Minutes")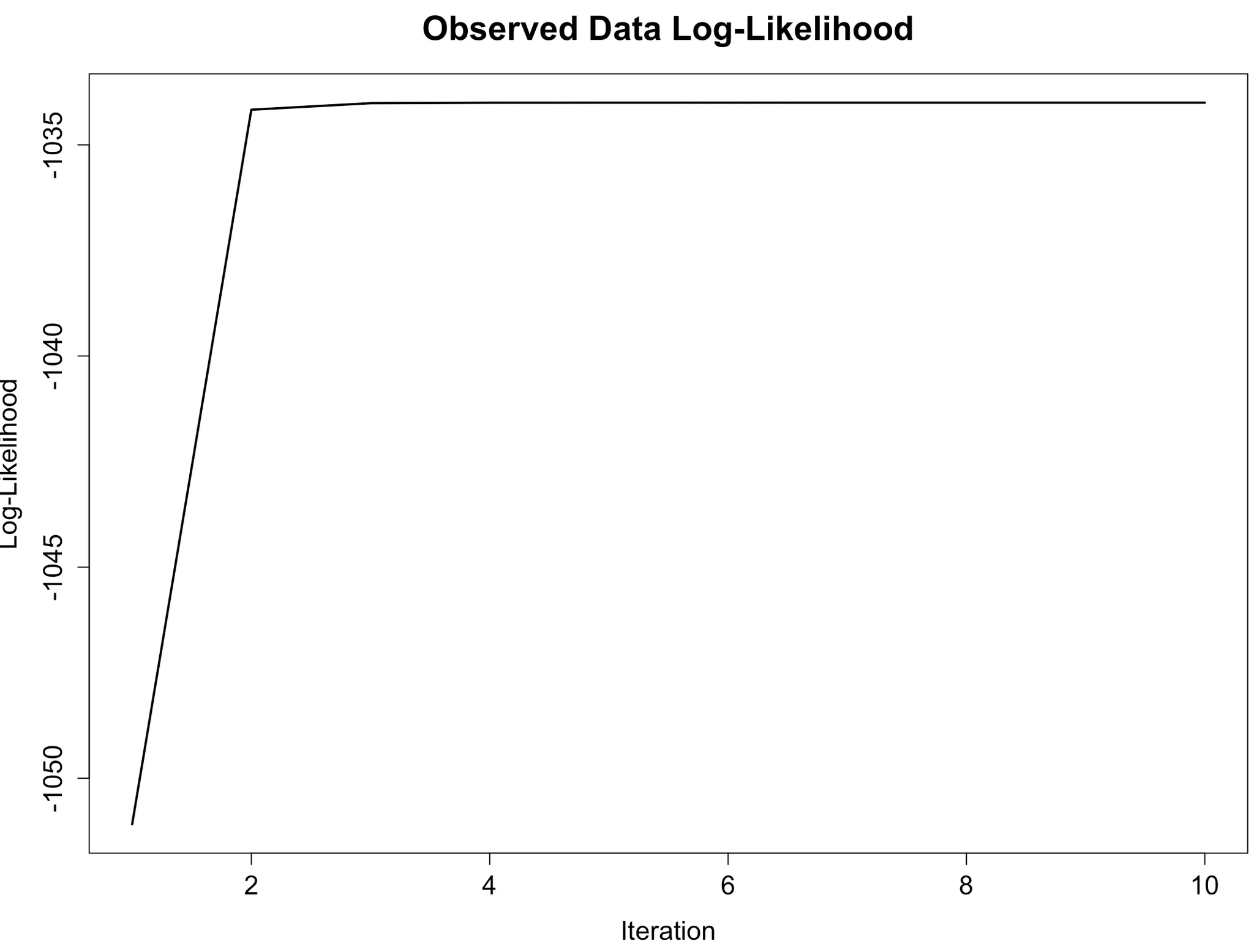
EM 알고리즘을 통해 모수를 추정하는 과정에서 반복 횟수 2회 만에 로그-가능도 함수가 최대가 됨을 알 수 있다.
자기조직화지도
자기조직화지도 개념
- SOM(Self-Organizing Maps, 자기조직화지도) 알고리즘은 코호넨에 의해 개발되었으며 코호넨 맵이라고도 불린다.
- 비지도 신경망으로 고차원의 데이터를 이해하기 쉬운 저차원의 뉴런으로 정렬하여 지도의 형태로 형상화한다. 이러한 형상화는 입력 변수의 위치 관계를 그대로 보존한다는 특징이 있다.
- 다시 말해 실제 공간의 입력 변수가 가까이 있으면, 지도상에서도 가까운 위치에 있게 된다. 이러한 SOM의 특징으로 인해 입력 변수의 정보와 그들의 관계가 지도상에 그대로 나타난다.
- SOM 알고리즘은 복잡한 데이터의 차원 축소와 유사한 데이터의 군집화를 동시에 수행할 수 있는 알고리즘이다.
- SOM 모델은 두 개의 인공신경망 층으로 구성되어 있으며 하나는 입력벡터를 받는 입력층, 다른 하나는 2차원 격차로 구성된 경쟁층이다.
경쟁층 : 입력 벡터의 특성에 따라 벡터가 한 점으로 클러스터링 되는 층
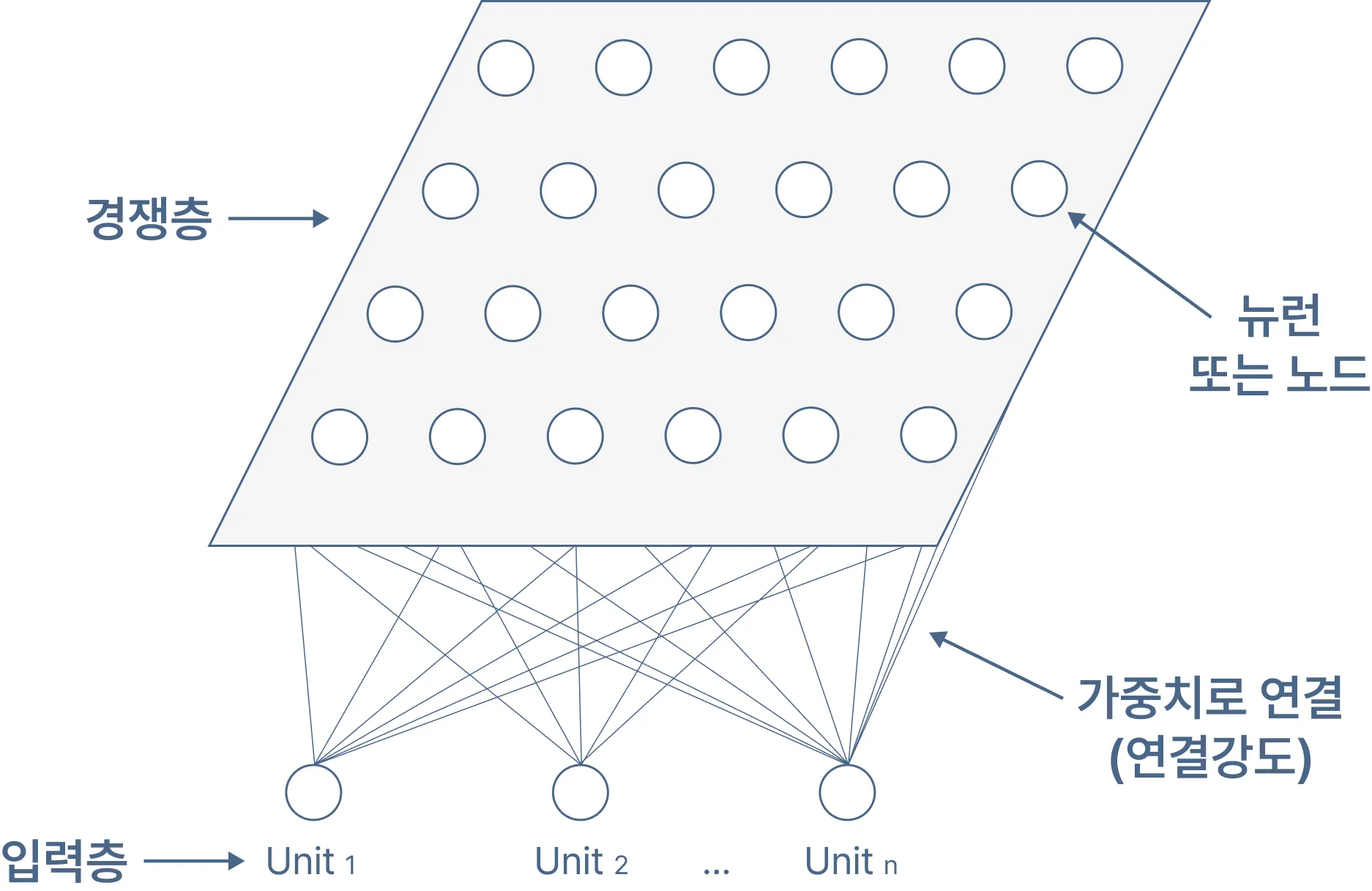
자기조직화지도 구성
- 입력층은 은닉층을 보유한 다층신경망과 달리 은닉층이 없으며, 입력 변수의 개수와 동일하게 뉴런 수가 존재한다
- 경쟁층은 사용자가 미리 정해놓은 군집의 수만큼 뉴런 수가 존재한다. 입력층의 자료는 학습을 통하여 경쟁층에 정렬되는데, 이를 지도(map)라 부른다.
- 입력 층에 있는 각각의 뉴런은 경쟁층에 있는 각각의 뉴런들과 연결되어 있으며, 이 때 완전 연결되어 있다.
- 각 학습 단계마다 입력층의 데이터 집합으로부터 하나의 표본 벡터 x 가 임의로 선택되었을 때, 프로토타입 벡터(경쟁층의 각각의 뉴런을 의미)와의 거리를 유클리드 거리에 의해 계산하고 비교한다. 입력층의 표본 벡터에 가장 가까운 프로토타입 벡터를 선택하여 BMU(Best-Matching Unit)라 명명한다.
- 그리고 코호넨의 승자 독점의 학습 규칙에 따라 BMU 뿐만 아니라 위상학적 이웃에 대한 연결 강도를 조정한다. 이처럼 SOM은 경쟁 학습으로 각각의 뉴런이 입력 벡터와 얼마나 가까운가를 계산하여 연결 강도를 반복적으로 재조정하여 학습한다.
- 이와 같은 과정을 거치면서 연결강도는 입력 패턴과 가장 유사한 경쟁층 뉴런이 승자가 된다. 결국 승자 독식 구조로 인해 경쟁층에는 승자 뉴런만이 나타나며, 승자와 유사한 연결 강도를 갖는 입력 패턴이 동일한 경쟁 뉴런으로 배열된다.
- 따라서 SOM을 이용한 군집 분석은 역전파 알고리즘 등을 이용하는 인공신경망과 달리 단 하나의 전방 패스를 사용함으로써 수행 속도가 매우 빠르다. 잠재적으로 실시간 학습 처리를 할 수 있는 모델이다.
자기조직화지도 과정
- 초기 학습률과 임의의 값의 가중치 행렬, 경쟁층의 노드 개수를 지정한다.
- 입력 벡터(첫 번째 데이터)를 제시하고 가중치 행렬에 의하여 가장 가까운 노드에 나타낸다.
- 입력 벡터에 대한 승자노드가 입력 벡터를 더 잘 나타내도록 학습률을 사용하여 해당 가중치를 재조정한다.
- 2단계로 돌아가서 반복하여 모든 입력 벡터를 승자노드에 나타낸다. 모든 입력 벡터가 승자노드에 표시되는 과정을 1회 이터레이션(iteration,반복)이라 한다.
- 일정 이터레이션 수에 도달할 때까지 2번으로 돌아가 위 작업을 반복한다.
자기조직화지도 특징

| 장점 | - 순전파 방식을 사용하여 속도가 매우 빠르다. - 저차원의 지도로 형상화되어 시각적 이해가 쉽다. - 패턴 발견 및 이미지 분석에서 성능이 우수하다. - 입력 데이터에 대한 속성을 그대로 보존한다. |
|---|---|
| 단점 | - 초기 학습률 및 초기 가중치에 많은 영향을 받는다. - 경쟁층의 이상적인 노드의 개수를 결정하기 어렵다. |
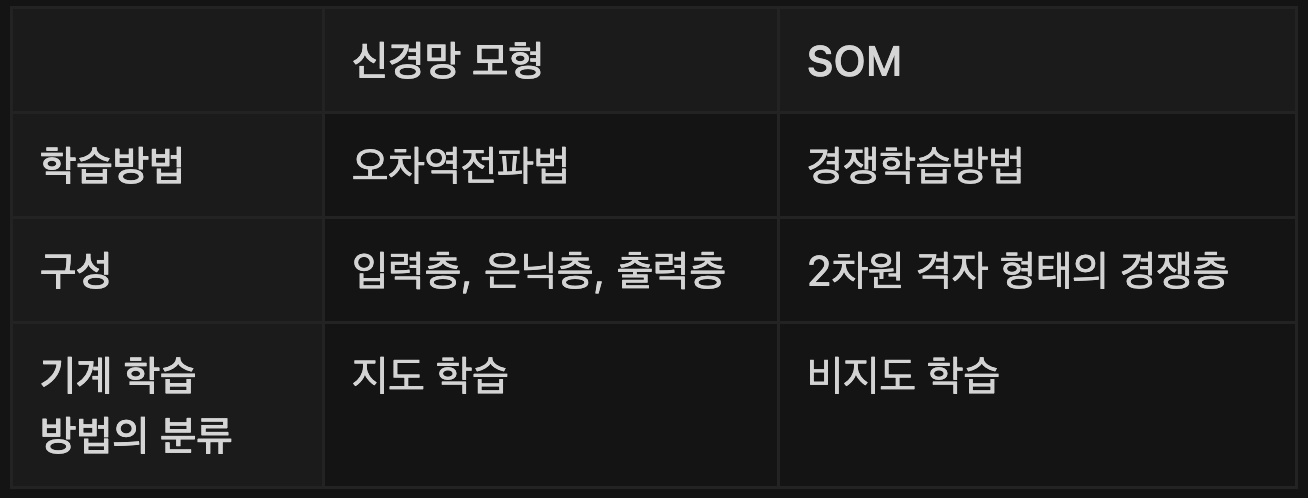
자기조직화지도와 신경망 모형의 차이점
SOM 군집분석 예제
과일 데이터를 사용하여 자기조직화지도를 활용하는 SOM 군집 분석 예제이다.
> install.packages("kohonen")
> library(kohonen)
> cal<-c(52,160,89,57,34,32,30,69)
> car<-c(112.4,8.5,22.8,14.5,8.2,7.7,7.6,18.1)
> fat<-c(0.2,14.7,1.3,0.7,0.2,0.3,0.2,0.2)
> pro<-c(0.3,2.0,1.1,0.3,0.8,0.7,0.6,0.7)
> fib<-c(2.4,6.7,2.6,2.4,0.9,2.0,0.4,0.9)
> sug<-c(10.4,0.7,12.2,9.9,7.9,4.7,6.2,15.5)
> fruits<-data.frame(cal,car,fat,pro,fib,sug)
> names<-c('apple','avocado','banana','blueberry','melon','watermelon','strawberry','grape')
> rownames(fruits)<-names
> fruits_scaled<-scale(fruits,center=T,scale=T)
# SOM 수행 (경쟁층의 노드 수는 1x3으로 3개)
> result<-som(fruits_scaled,grid=somgrid(3,1))
> par(mfrow=c(1,2))
> plot(result)
> plot(result, type='mapping',labels=names)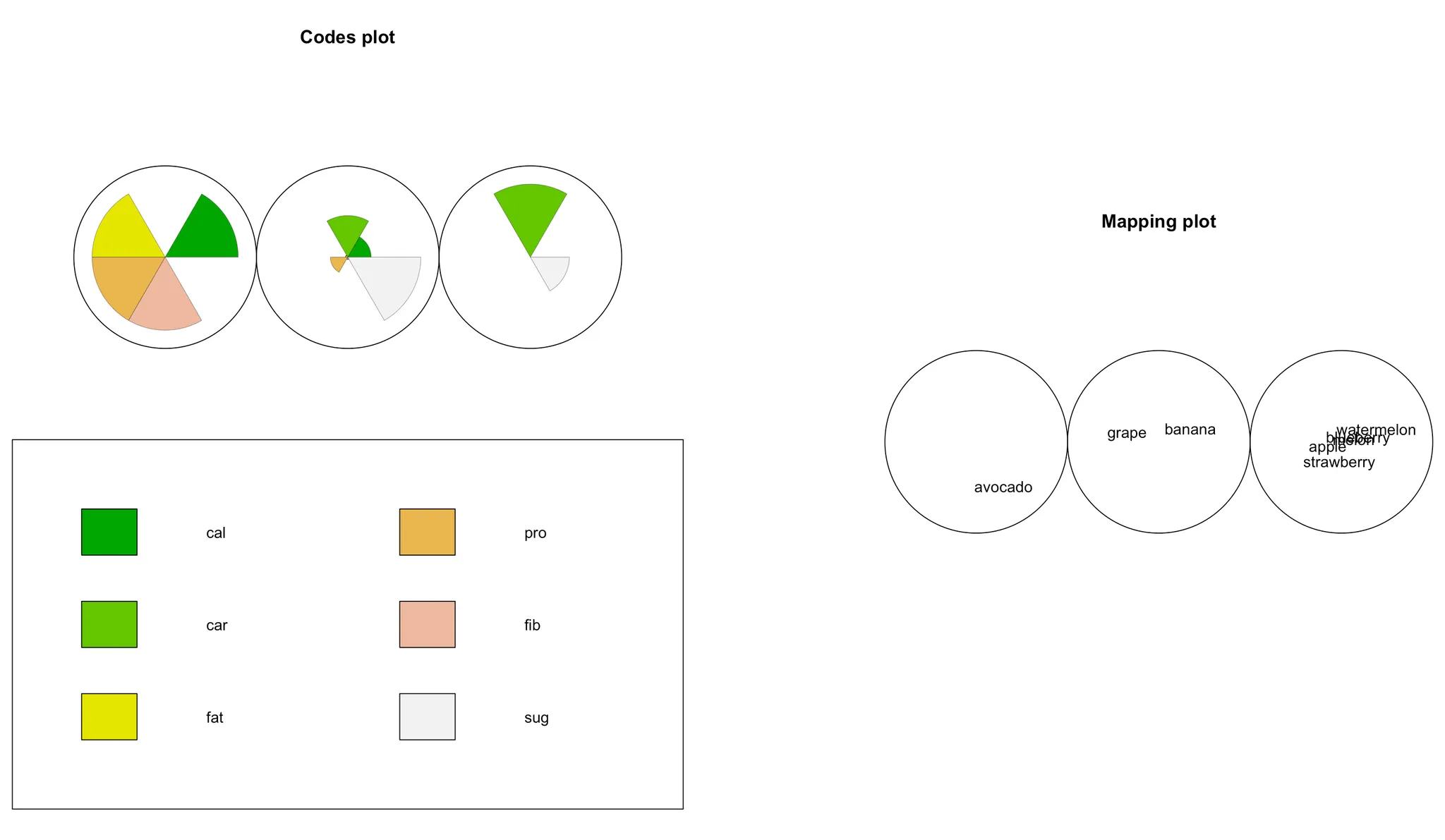
연습문제
1번
혼합분포군집에 대한 설명으로 옳지 않은 것은?
1. k-평균 군집의 절차와 유사하지만 확률분포를 도입하여 군집을 수행한다.
2. 군집의 크기가 너무 작으면 추정의 정도가 떨어지거나 어려울 수 있다.
3. 알고리즘으로 두 가지 단계(E-step, M-step)로 구성되어 있다.
4. k-평균 군집과 달리 이상치 자료에 민감하지 않아서 사전 조치가 필요없다.
정답
혼합 분포 군집모형은 k-평균 군집과 같이 이상치 자료에 민감하므로 사전에 조치가 필요하다.
2번
EM 알고리즘 진행 과정으로 옳지 않은 것은?
1. 파라미터(모수) 설정 - 초기 파라미터 값을 임의로 설정한다.
2. Z의 중심값 계산 - 설정된 파라미터 값을 가진 분포로부터 실제 데이터가 얼마나 나올지 알아본다.
3. 새로운 파라미터 값을 추정한다.
4. 알고리즘 반복 및 종료 : 가능도가 최대가 되었다고 판단되면 알고리즘을 종료한다.
정답
Z의 ‘중심값’ 계산이 아닌 ‘기댓값’ 계산이다.
3번
SOM에 대한 설명으로 옳지 않은 것은?
1. 은닉층이 없으며 순전파 방식만 사용하기 때문에 매우 빠르게 수행된다.
2. 완전 연결의 형태로 입력층의 각 데이터는 경쟁층의 각각의 뉴런에 연결된다.
3. 경쟁층의 이상적인 노드의 개수를 결정하기 매우 쉽다.
4. 초기 학습률 및 초기 가중치에 많은 영향을 받는다.
정답
경쟁층의 이상적인 노드의 개수를 결정하기 어렵다는 단점이 있다.
14.3. 연관분석
연관분석
연관분석의 개요
흔히 장바구니분석으로도 불리는 연관분석은 서로 연관된 의미있는 규칙을 찾아내는 분석이다.
- 장바구니 하나에 해당하는 정보를 트랜잭션이라고 하며, 장바구니 데이터에서는 주로 트랜잭션 사이의 연관성을 살펴보는 것으로, 빈번히 나타나는 규칙을 찾아낸다.
예를 들어, 미국의 마트에서 기저귀를 사는 고객은 맥주를 동시에 구매한다는 연관규칙을 알아냈다고 한다. 이를 통해 기저귀와 맥주를 인접한 진열대에 놓으면 매출 증대를 꾀할 수 있다.
- 구매 내역이 쌓이다 보면 ‘어느 고객이 어떤 제품을 같이 구매할까?’에 대한 궁금증이 자연스럽게 생겨난다. 이러한 궁금증을 해결하기 위해 연관성 분석을 실시한다. 분석을 통해 제품 간의 연관성을 파악하면 세트 메뉴를 구성하거나 쿠폰을 발행하는 등의 교차판매를 할 때 훨씬 효과적이다.
- 연관성 규칙의 일반적인 형태 : 조건과 반응 If - A then B (만약 A가 일어나면 B가 일어난다.)
- 연관분석은 탐색적 기법의 일종으로 조건 반응에 의해 표현되어 결과를 쉽게 이해할 수 있다. 또한 특별한 분석 의도가 없는 비지도 학습 유형으로 다양하게 활용될 수 있다. 사용이 편리하고 계산이 간단하다.
- 연관분석은 품목의 수가 증가하면 분석 계산이 기하급수적으로 증가할 수 있다. 이를 개선하기 위해 유사한 품목을 하나의 범주로 일반화하는 작업을 수행하기도 한다. 너무 세분화된 품목으로 연관규칙을 찾으면 의미 없는 분석이 될 수 있다.
연관분석의 측도
연관분석을 하면 많은 연관규칙이 생성되는데, 모든 연관규칙이 유용하지는 않으니 측도를 통해 이 규칙들이 유의미한지 확인해야 한다. 도출된 연관규칙이 얼마나 유의미한지 평가하기 위한 측정지표로는 지지도, 신뢰도, 향상도가 있다.
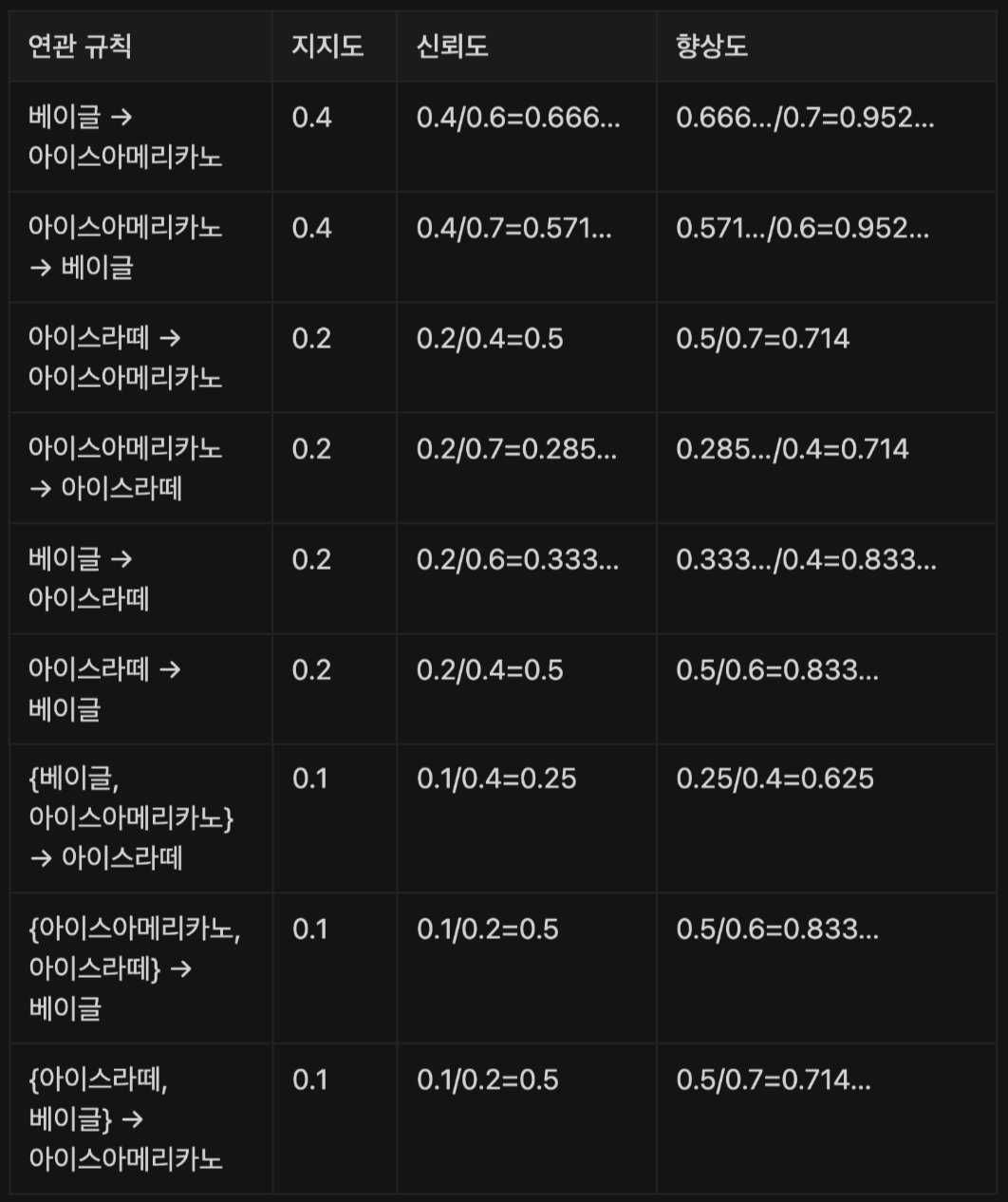
지지도 (Support)
- 전체 거래 중에서 A와 B 항목을 동시에 포함하는 거래의 비율이다.
- 지지도가 높다는 것은 두 항목이 같이 잘 팔린다는 것을 의미한다.
신뢰도 (Confidence)
- 어떤 하나의 품목이 구매되었을 때 다른 품목 하나가 구매될 확률
- A가 구매되었을 때 B가 구매될 확률인 신뢰도(A→B)와, B가 구매되었을 때 A가 구매될 확률인 신뢰도(B→A)는 다르다.
- 신뢰도 (A→B)
- 신뢰도 (B→A)
향상도 (Lift)
-
품목 A가 주어지지 않았을 때 품목 B가 구매될 확률 대비, 품목 A가 구매될 때 품목 B가 구매될 확률
-
신뢰도와 달리 향상도(A→B)와 향상도(B→A)는 같다.
$$향상도(A→B)=\frac{신뢰도 (A→B)}{P(B)}=\frac{P(A \cap B)}{P(A)P(B)}$$ $$향상도(B→A)=\frac{신뢰도 (B→A)}{P(B)}=\frac{P(A \cap B)}{P(A)P(B)}$$
연관분석 측도 계산 예제
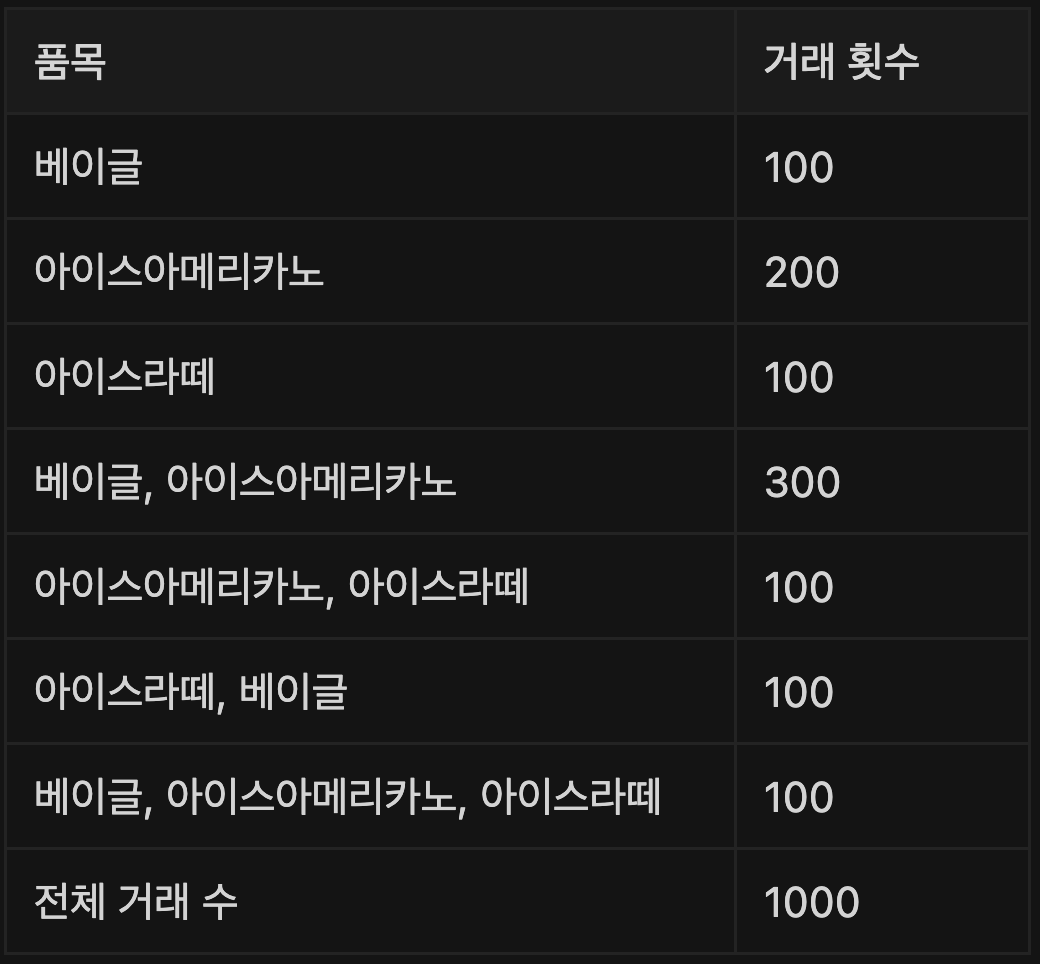
위 표와 같은 거래 데이터가 있다고 할 경우 각 연관분석 측도를 계산하시오.
-
거래 횟수별 구매율(지지도)
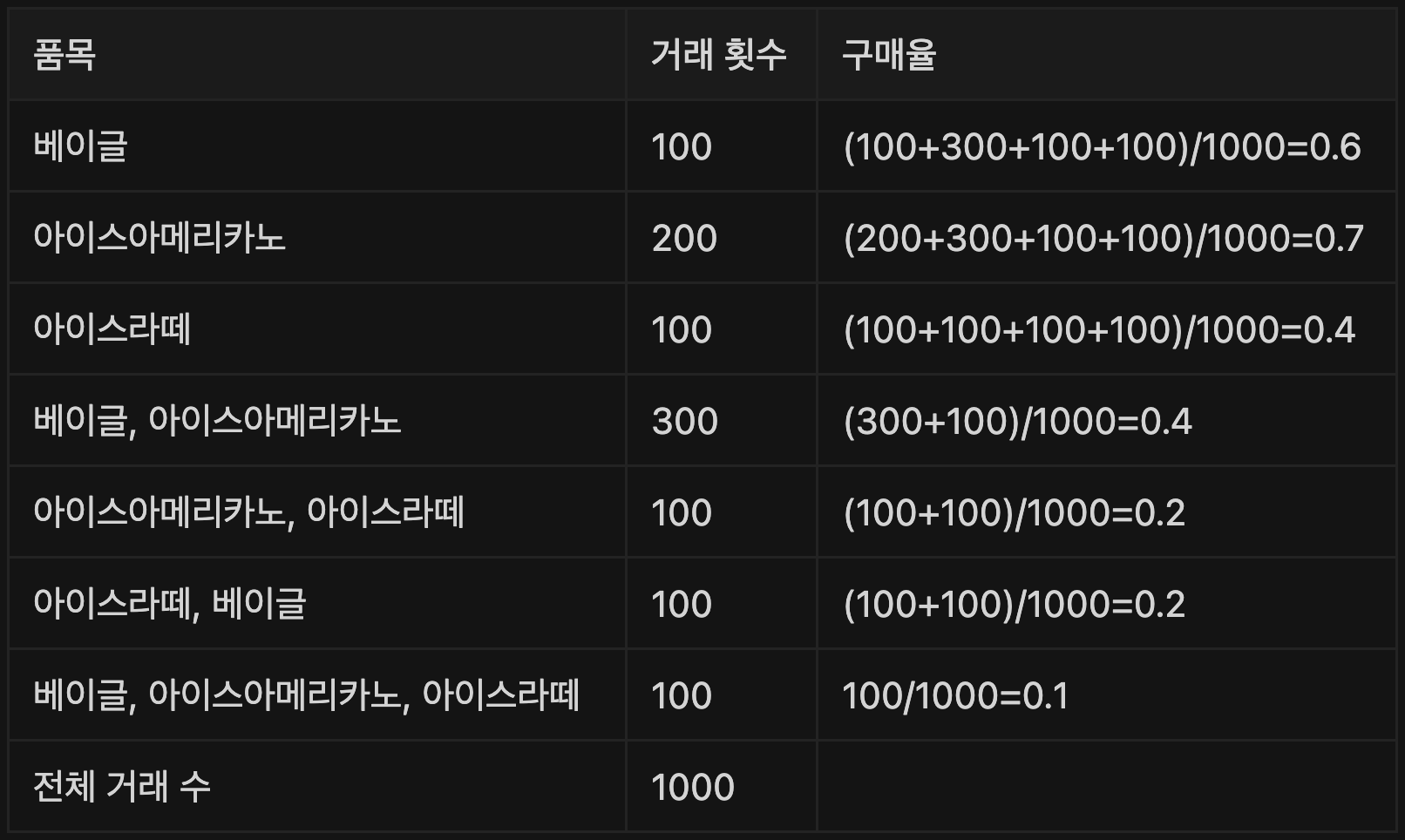
-
단일 품목에 대한 확률값 :
- 베이글 : 600/1000 = 0.6
- 아이스아메리카노 : 700/1000 = 0.7
- 아이스라떼 : 400/1000 = 0.4
- 신뢰도와 향상도
연관분석 특징 및 알고리즘
연관분석 특징
장점
- 목적변수가 없으므로 데이터로부터 의미있는 규칙이 있는지(데이터 탐색) 파악하기 위해 사용 가능하다.
- 결과가 단순하고 분명하다 (IF ~ THEN ~)
- 분석을 위한 계산이 간단하다
- 사용이 편리한 분석 데이터의 형태로 거래 내용에 대한 데이터를 변환 없이 그 자체로 이용할 수 있는 간단한 자료 구조를 갖는다.
단점
- 지나치게 품목 세분화하면 의미없는 결과를 도출할 가능성이 있으므로 품목 세분화에 어려움이 있다.
- 품목 수의 증가는 기하급수적인 계산량의 증가를 초래한다. 이를 개선하기 위해 유사한 품목을 한 범주로 일반화한다. (ex. 대형마트에 있는 모든 품목들에 대해 연관분석을 진행하지 않고 유사한 품목끼리 하나로 묶어서 계산한다.)
- 거래가 발생하지 않거나 거래량이 적은 품목에 대해서는 분석이 불가능하다.
참고하면 좋을 용어
- 순차패턴
연관분석에 시간 개념이 추가되어 ‘프린터를 구매한 고객은 추후 종이를 구매한다’와 같은 규칙을 찾는 분석 기법이다. 연관분석은 장바구니를 언제 누가 들고 있었는지에 대한 정보는 필요 없지만 순차패턴은 장바구니를 누가 언제 들고 있었는지에 대한 고객과 시간의 정보가 함께 필요하다.
연관분석 알고리즘
apriori 알고리즘
- 연관분석을 위한 대표적인 알고리즘이다.
- Apriori 알고리즘은 데이터에서 자주 발생하는 항목 집합을 찾아내고, 이를 기반으로 연관 규칙(association rules)을 발견하는 알고리즘이다.
- apriori 알고리즘은 지지도를 사용해 빈발 아이템 집합을 판별하고 이를 통해 계산의 복잡도를 감소시키는 알고리즘이다. (최소 지지도 이상의 빈발항목집합)
- 가능한 모든 경우의 수를 탐색하여 측정지표가 높게 나타나는 연관규칙을 찾는 aprioi 알고리즘은 아이템의 수가 증가할수록 계산에 소요되는 시간과 복잡도가 기하급수적으로 증가하게 된다.
- apriori 알고리즘은 지지도가 낮은 후보 집합 생성 시 아이템의 개수가 많아지면 계산의 복잡도가 증가한다는 문제점을 가지고 있다.
apriori 알고리즘 절차
1. 최소 지지도를 설정한다.
2. 최소 지지도보다 큰 지지도를 갖는 단일 품목을 선별한다.
3. 위 과정에서 찾은 단일 품목으로 2가지 품목으로 생성되는 연관규칙(A→B) 중 최소 지지도 이상의 연관규칙을 찾는다.
4. 위 과정을 반복적으로 수행하면서 3가지 이상의 품목에 대한 연관규칙을 생성하면서 의미 있는 결과를 찾는다.
FP-Growth 알고리즘
- FP-Growth 알고리즘은 apriori 알고리즘의 약점을 보완하기 위해 고안된 것으로 데이터베이스를 스캔하는 횟수가 작고 빠른 속도로 분석이 가능하다.
- 후보 빈발항목집합을 생성하지 않고, FP-Tree를 만든 후 분할정복 방식을 통해 apriori 알고리즘보다 더 빠르게 빈발항목집합을 추출할 수 있는 방법이다.
- FP-Growth 알고리즘은 지지도가 낮은 품목부터 지지도가 높은 품목 순으로 차츰 올라가면서 빈도수가 높은 아이템 집합을 생성하는 상향식 알고리즘이다.
연관분석 예제
연관 분석을 실습하기 위해 사용할 데이터는 arules 패키지 내에 있는 Adult 데이터다. Adult 데이터는 여러 변수들을 통해서 연소득이 large(>5만 달러)인지 small인지 예측하기 위한 트랜잭션 형태의 미국 센서스 데이터다
> install.packages('arules')
> library(arules)
> data(Adult)
> Adulttransactions in sparse format with
48842 transactions (rows) and
115 items (columns)더불어 as 함수를 사용하면 트랜잭션 데이터를 원하는 형태의 데이터 형식으로 강제 변환할 수 있다. 예를 들어, as(Adult, ‘data.frame’)이라고 하면 트랜잭션의 형태를 데이터 프레임 형식으로 변환하여 살펴볼 수 있다.
> rules<-apriori(Adult)
Apriori
Parameter specification:
confidence minval smax arem aval originalSupport
0.8 0.1 1 none FALSE TRUE
maxtime support minlen maxlen target ext
5 0.1 1 10 rules TRUE
Algorithmic control:
filter tree heap memopt load sort verbose
0.1 TRUE TRUE FALSE TRUE 2 TRUE
Absolute minimum support count: 4884
set item appearances ...[0 item(s)] done [0.00s].
set transactions ...[115 item(s), 48842 transaction(s)] done [0.03s].
sorting and recoding items ... [31 item(s)] done [0.00s].
creating transaction tree ... done [0.01s].
checking subsets of size 1 2 3 4 5 6 7 8 9 done [0.05s].
writing ... [6137 rule(s)] done [0.00s].
creating S4 object ... done [0.01s].연관 분석을 위해서는 arules 패키지를 사용한다. arules 패키지의 apriori 함수를 사용하면 연관규칙을 발굴해낼 수 있다.
inspect 함수를 사용하면 apriori 함수를 통해 발굴된 규칙을 보여준다. 아래 결과는 발굴된 규칙 중에 일부만 본 것이다. 결과를 보면 lhs(left hand side)에 해당하는 항목이 없는 경우 rhs(right hand side) 결과가 나타나는 무의미한 결과가 나타난다. 이를 방지하기 위해 지지도, 신뢰도를 조정하여 규칙을 발굴해야 한다.
> inspect(head(rules))
lhs rhs
support confidence coverage lift count
[1] {} => {race=White}
0.8550428 0.8550428 1.0000000 1.000000 41762
[2] {} => {native-country=United-States}
0.8974243 0.8974243 1.0000000 1.000000 43832
[3] {} => {capital-gain=None}
0.9173867 0.9173867 1.0000000 1.000000 44807
[4] {} => {capital-loss=None}
0.9532779 0.9532779 1.0000000 1.000000 46560
[5] {relationship=Unmarried} => {capital-loss=None}
0.1019819 0.9719024 0.1049302 1.019537 4981
[6] {occupation=Sales} => {race=White}
0.1005282 0.8920785 0.1126899 1.043314 4910지지도와 신뢰도의 값을 지정하여 좀 더 유의미한 결과가 나올 수 있도록 한다. 그리고 rhs를 income 변수에 대해서 small인지 large인지에 대한 규칙만 나올 수 있도록 하여 income 변수에 대한 연관 규칙만 출력한다.
> adult.rules <- apriori(Adult, parameter=list(support=0.1, confidence=0.6),
+ appearance = list(rhs=c('income=small', 'income=large'),
+ default='lhs'),
+ control=list(verbose=F))
> adult.rules.sorted<-sort(adult.rules, by='lift')
> inspect(head(adult.rules.sorted))
lhs rhs support confidence coverage lift count
[1] {age=Young,
workclass=Private,
capital-loss=None} => {income=small} 0.1005282 0.6633342 0.1515499 1.310622 4910
[2] {age=Young,
workclass=Private} => {income=small} 0.1025961 0.6630938 0.1547234 1.310147 5011
[3] {age=Young,
marital-status=Never-married,
capital-gain=None,
capital-loss=None} => {income=small} 0.1060563 0.6616426 0.1602924 1.307279 5180
[4] {age=Young,
marital-status=Never-married,
capital-gain=None} => {income=small} 0.1084517 0.6609683 0.1640801 1.305947 5297
[5] {relationship=Own-child,
capital-loss=None} => {income=small} 0.1000983 0.6604972 0.1515499 1.305016 4889
[6] {relationship=Own-child} => {income=small} 0.1023914 0.6596755 0.1552148 1.303393 5001결과를 보면 규칙이 rhs는 income 변수에 관한 규칙만 발굴된 것을 볼 수 있다. 예를 들어, 첫 번째 규칙을 보면 연령대가 젊고 자영업이면서 자본 손실이 없는 사람은 연 소득이 5000만 달러 이하인 것으로 나타났다.
발굴한 연관규칙은 시각화하는 패키지로 arulesViz가 있는데, 이 패키지를 사용하여 도출된 규칙을 그림으로 나타낼 수 있다.
> install.packages('arulesViz')
> library (arulesViz)
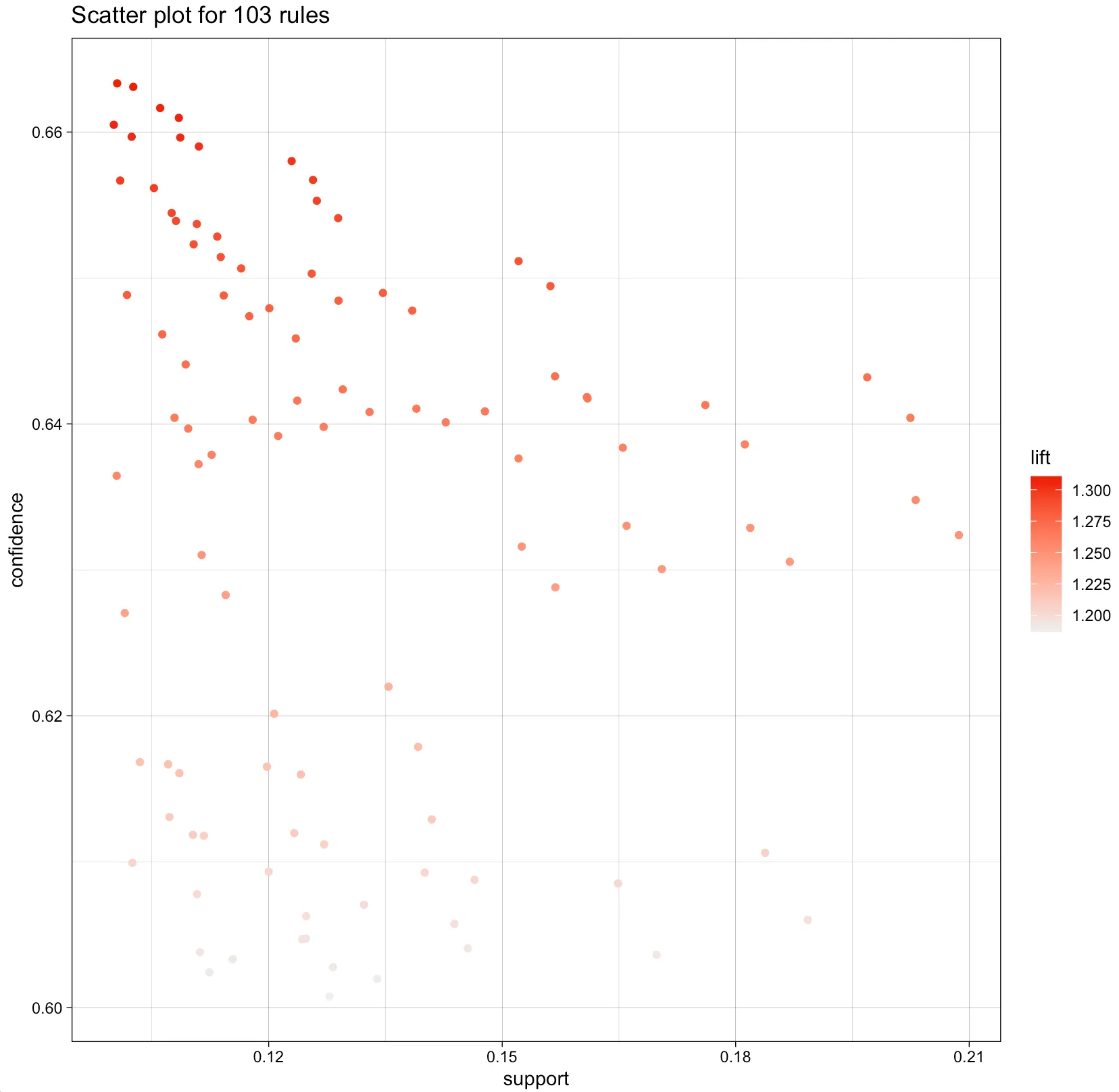
> plot (adult.rules.sorted, method='scatterplot')아래의 그림은 도출된 연관 규칙의 지지도, 신뢰도, 향상도를 산점도로 나타내고 있다.
> plot(adult.rules.sorted, method='graph', control=list(type='items', alpha=0.5))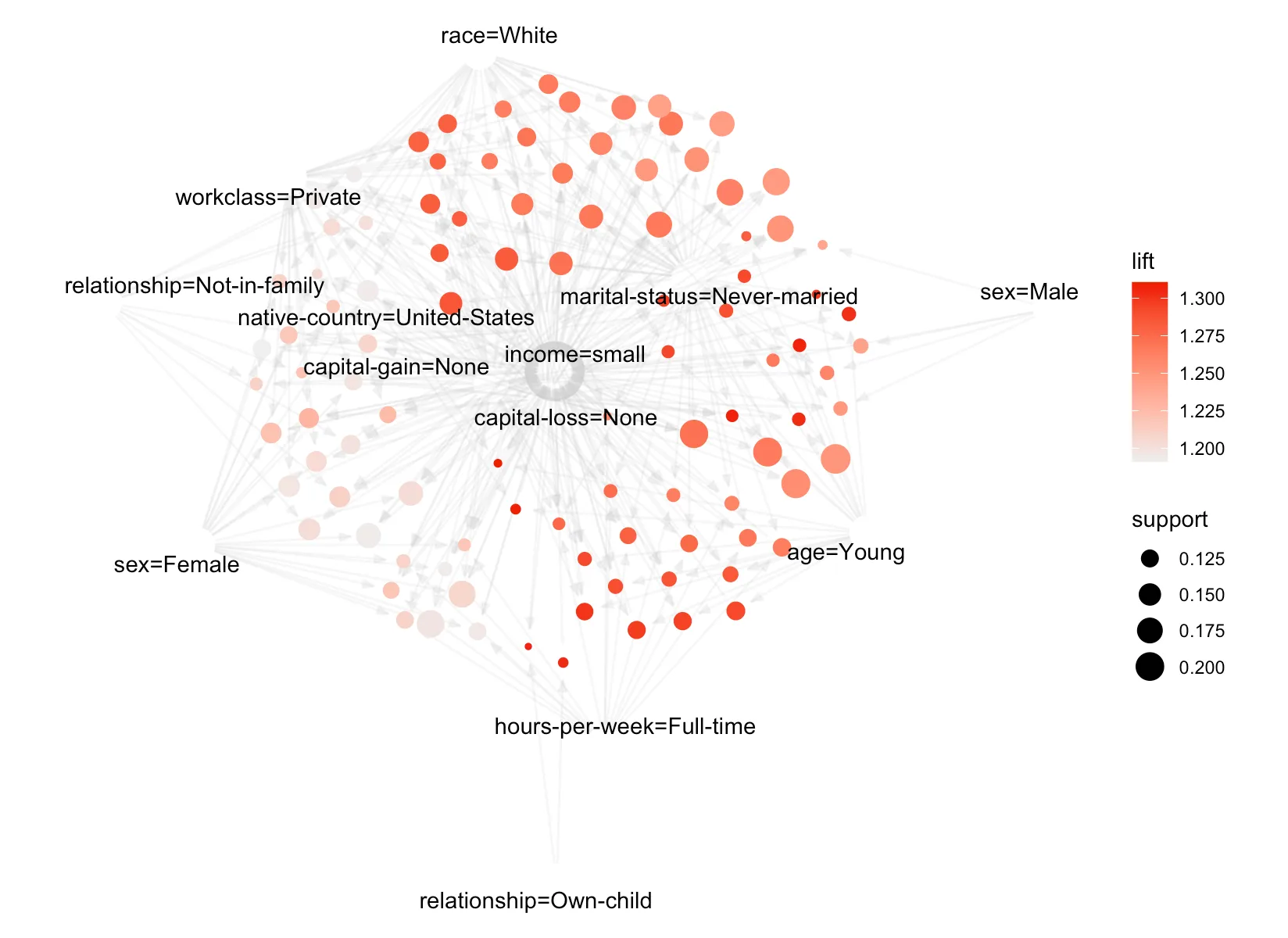
연관분석 예제
연습문제
1번
품목 A가 주어지지 않았을 때 품목 B가 구매될 확률 대비, 품목 A가 구매될 때 품목 B가 구매될 확률
1. 지지도
2. 신뢰도
3. 향상도
4. 정확도
정답
2번
연관분석의 장점으로 옳지 않은 것은?
1. 연관성 분석의 결과를 쉽게 이해할 수 있다.
2. 강력한 비목적성 분석기법으로 분석 방향이나 목적이 없는 경우 목적변수가 없으므로 유용하게 활용 된다.
3. 유사한 품목을 한 범주로 일반화할 경우 기하급수적인 거래량 증가를 초래한다.
4. 분석을 위한 계산이 간단하다
정답
품목 수의 증가는 기하급수적인 계산량의 증가를 초래한다. 이를 개선하기 위해 유사한 품목을 한 범주로 일반화한다3번
apriori 알고리즘에 대한 설명으로 옳지 않은 것은?
1. 데이터베이스를 스캔하는 횟수가 작고 빠른 속도로 분석이 가능하다.
2. 지지도를 사용해 계산의 복잡도를 감소시킨다.
3. 최소 지지도 이상의 빈발항목집합을 찾은 후 그것들에 대해서만 연관규칙을 계산한다.
4. apriori 알고리즘은 구현과 이해하기가 쉽다는 장점이 있다.
정답
1번의 내용은 FP-Growth 알고리즘에 대한 설명이다.
