5. R을 활용한 분석 실습
5.1. R 이란
R 소개
데이터 분석을 위하여 사용하는 다양한 종류의 소프트웨어가 있다. 그중에서 R은 통계 분석 과정에서 수행되는 복잡한 계산이나 시각화 기법을 쉽게 사용할 수 있도록 설계된 무료 소프트웨어이다. R은 뉴질랜드 통계학자인 로스 이하카와 캐나다 통계학자인 로버트 젠틀맨에 의하여 제작된 통계 분석을 위한 언어로, 빠른 속도로 확산되어 다양한 분야에서 사용하고 있다.
R Studio란?
R Studio는 사용자가 원하는 대로 R 명령문을 활용하여 구현하게 해주는 통합 개발 환경(IDE)이다. R언어를 활용하여 작성된 함수에 따라 데이터를 분석하고, 결과 및 시각화된 결과를 사용자에게 개발 환경에서 즉시 보여준다. 즉 R 언어를 더 쉽고 효과적으로 사용할 수 있게 해주는 프로그램이다.
5.2. R 데이터 구조
벡터
다양한 형태의 데이터 구조가 존재하지만 그 중에서도 R에서 가장 많이 사용되는 벡터, 행렬, 배열, 리스트, 데이터 프레임에 대해 살펴보자.
벡터
벡터는 타입이 같은 여러 데이터를 하나의 행으로 저장하는 1차원 데이터 구조다. 이때 벡터 데이터 내에 들어갈 수 있는 데이터는 숫자, 문자, 논리 연산자 등이 될 수 있고, 이렇게 하나의 값은 스칼라(scalar)라고 부른다. 숫자로 이루어진 벡터는 숫자 벡터가 되고 문자로 이루어진 벡터는 문자 벡터가 된다. R에서 다루는 데이터 구조 중 가장 단순한 형태이며 명령어 C를 이용해 선언할 수 있다. 이때, 'c'는 concentration(연결)을 의미한다.

코드 예시
x = c(1, 10, 20, 30) y = c("사과", "복숭아", "바나나") z = c(TRUE, FALSE, TRUE) * 등호 '='의 경우 우측의 값을 좌측의 변수에 할당한다는 의미로, '<-'화살표를 사용할 수도 있다.
벡터를 생성할 때 c안에 콤마를 넣어 구분자로 쓸 수 있지만 콜론(:)을 활용하여 시작값과 끝값을 지정하여 벡터를 생성할 수 있다
class1 = c(1:10) class1 [1] 1 2 3 4 5 6 7 8 9 10 * '>'는 R에서 자동적으로 출력되는 기호이므로 실제 R 명령어를 작성할 때는 적지 않는다
벡터와 벡터를 결합하여 새로운 벡터를 형성할 수도 있다. 다만, 벡터의 형식이 서로 다른 경우에는 어떨까? 문자형 벡터가 포함되면 합쳐지는 벡터는 문자형 백터가 된다. 아래 코드 예시를 살펴보면, 숫자형 벡터인 x와 문자형 벡터인 y를 xy라는 벡터로 합쳤다. 합쳐진 xy벡터는 x벡터가 가지고 있던 1, 10. 20, 30의 값을 그대로 가지고는 있지만 문자형 벡터로 전환되었기 때문에 이 값들을 숫자가 아닌 문자 데이터로 인식하게 된다.
x <- c(1, 10, 20, 30) y <- c("사과", "복숭아", "바나나") xy <- c(x,y) xy [1] "1" "10" "20" "30" "사과" "복숭아" "바나나"
벡터(Vector) 요약
- 벡터들은 동질적이다.
- 벡터는 위치로 인덱스 된다
A[3] 는 A벡터의 3번째 원소이다
행렬
행렬은 2차원 구조를 가진 벡터이고, 행렬에 저장된 모든 데이터는 같은 타입이어야 한다. 그렇지 못할 경우 자동으로 타입 변환을 수행한다.
행렬의 선언을 위해서는 명령어 matrix를 사용한다. ncol을 사용하여 열(column)의 수를 정하거나 nrow를 사용하여 행(row)의 수를 정할 수 있다.
코드 예시
> mx = matrix(c(1:6), ncol=2)
> mx
[,1] [,2]
[1,] 1 4
[2,] 2 5
[3,] 3 6matrix를 사용하여 행렬을 만들 경우 행렬의 값들이 열로 저장되는 것을 확인할 수 있다. 만약 byrow옵션에 T(TRUE)를 지정하면 값들이 열이 아닌 행으로 저장된다
mx2 = matrix(c(1:6), nrow=2, byrow=T) mx2 [,1] [,2] [,3] [1,] 1 2 3 [2,] 4 5 6
행렬을 만드는 다른 방법은 벡터에 차원을 주는 방법이다. dim 함수를 사용하면 행의 개수와 열의 개수를 지정하여 행렬로 변환할 수 있다.
a1 = c(1:6) a1 [1] 1 2 3 4 5 6 dim(a1) = c(2,3) a1 [,1] [,2] [,3] [1,] 1 3 5 [2,] 2 4 6
명령어 rbind와 cbind를 사용하여 이미 만들어진 벡터를 합쳐 행렬을 만들 수도 있다. rbind의 ‘r’은 ‘row’를 의미하는데, 기존의 행렬에 행을 추가하는 형태로 데이터를 결합시킨다. cbind의 ‘c’는 ‘column’을 의미하며 기존 행렬에 열을 추가하는 형태로 데이터를 결합시킨다.
a2 = matrix(c(1:6), ncol=2) a2 [,1] [,2] [1,] 1 4 [2,] 2 5 [3,] 3 6 r1 = c(10, 10) c1 = c(20, 20, 20) rbind(a2, r1) [,1] [,2] 1 4 2 5 3 6 r1 10 10 cbind(a2, c1) c1 [1,] 1 4 20 [2,] 2 5 20 [3,] 3 6 20
배열과 리스트
배열
3차원 이상의 구조를 갖는 벡터를 배열이라고 한다. 배열 또한 벡터의 성질을 가지고 있으므로 하나의 배열에 포함된 데이터는 모두 같은 타입이어야 한다. array를 사용하여 배열을 만들 수는 있지만 몇 차원의 구조를 갖는지 dim 옵션에 명시해 줘야 한다. 명시하지 않을 경우 1차원 벡터가 생성되기 때문이다.
코드 예시
b1 = array( c(1:12) , dim = c(2, 3, 2) ) b1 , , 1 [,1] [,2] [,3] [1,] 1 3 5 [2,] 2 4 6 , , 2 [,1] [,2] [,3] [1,] 7 9 11 [2,] 8 10 12
리스트
리스트는 데이터 타입, 데이터 구조에 상관없이 사용자가 원하는 모든 것을 저장할 수 있는 자료구조이며, 여러 자료형의 원소들이 포함될 수 있는 이질적인 특징을 가지고 있다.
리스트 (List)
- 리스트는 각각의 원소가 인덱스를 가진다.
L[[3]] 는 L 리스트의 3번째 원소이다. - 리스트의 원소들은 이름을 가질 수 있다.
L[[”red”]]과 L$red는 둘 다 ‘red’라는 이름의 원소를 지칭한다
아래 코드 예시는 list()를 사용해서 list를 담을 변수를 선언하고 첫 번째 성분으로 숫자형 데이터를, 두 번째 성분으로 벡터를, 세 번째 성분으로 행렬을, 네 번째 성분으로 배열을 담은 뒤 리스트를 출력한 결과이다.
> L = list()
> L[[1]]=5
> L[[2]]=c(1:6)
> L[[3]]=matrix(c(1:6),nrow=2)
> L[[4]]=array(c(1:12),dim=c(2,3,2))
> L
[[1]]
[1] 5
[[2]]
[1] 1 2 3 4 5 6
[[3]]
[,1] [,2] [,3]
[1,] 1 3 5
[2,] 2 4 6
[[4]]
, , 1
[,1] [,2] [,3]
[1,] 1 3 5
[2,] 2 4 6
, , 2
[,1] [,2] [,3]
[1,] 7 9 11
[2,] 8 10 12데이터 프레임
데이터 프레임은 행렬과 유사한 2차원 목록 데이터 구조이다. 다루기 쉽고 한 번에 많은 정보를 담을 수 있어서 R에서 가장 많이 활용되는 데이터 구조이다. 행렬과는 다르게 각 열이 서로 다른 데이터 타입을 가질 수 있기 때문에 데이터의 크기가 커져도 다루기 수월하다. 명령어 data.frame을 이용하면 여러 개의 벡터를 하나의 데이터 프레임으로 합쳐 입력할 수 있다.
코드 예시
d1 = c(1:5) d2 = c('red','yellow','blue','purple','pink') df = data.frame(d1,d2) df d1 d2 1 1 red 2 2 yellow 3 3 blue 4 4 purple 5 5 pink
5.3. R 기본 문법
연산자
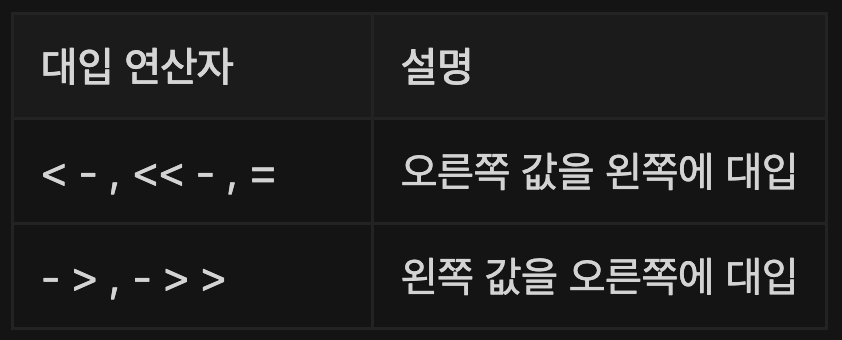
대입 연산자
비교 연산자

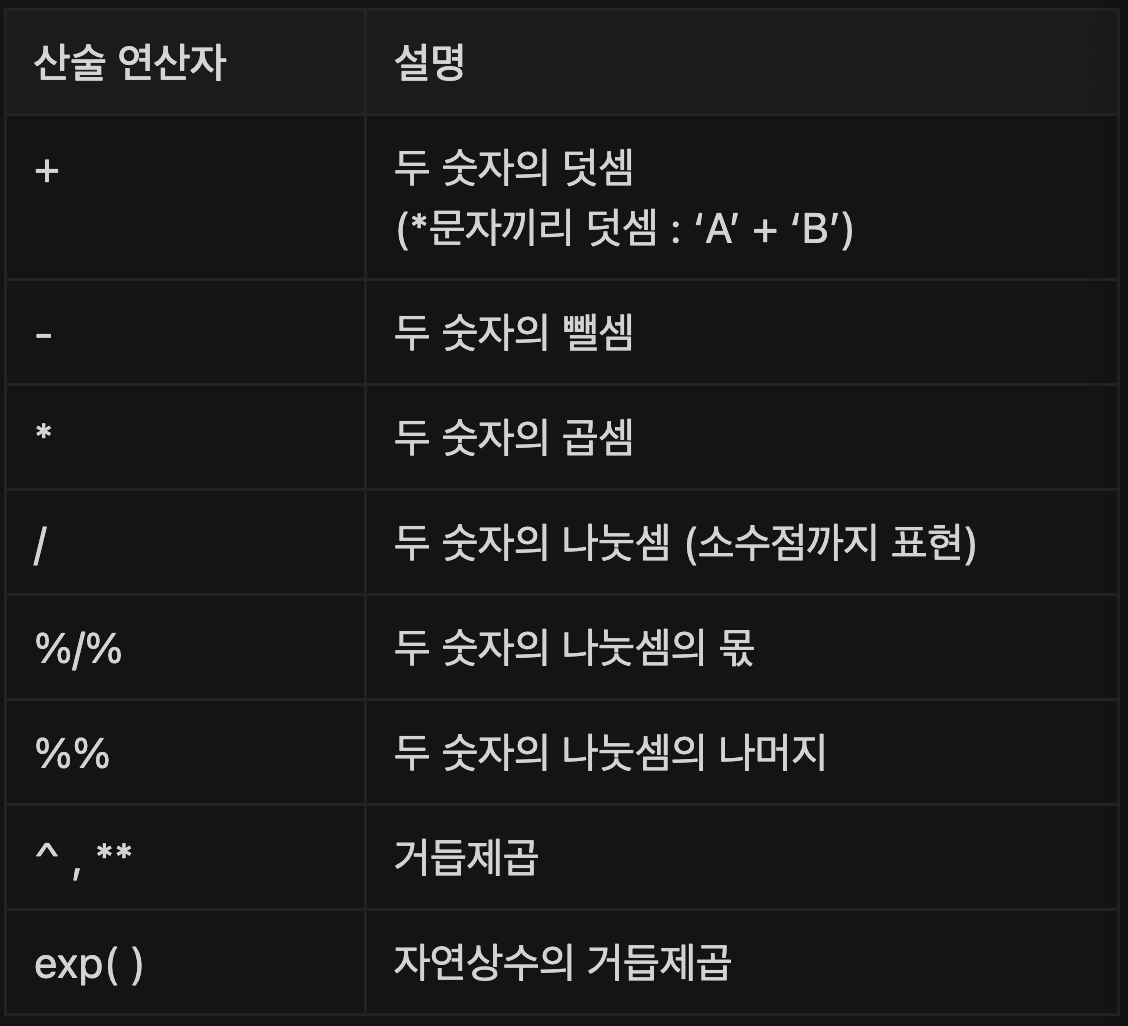
산술 연산자
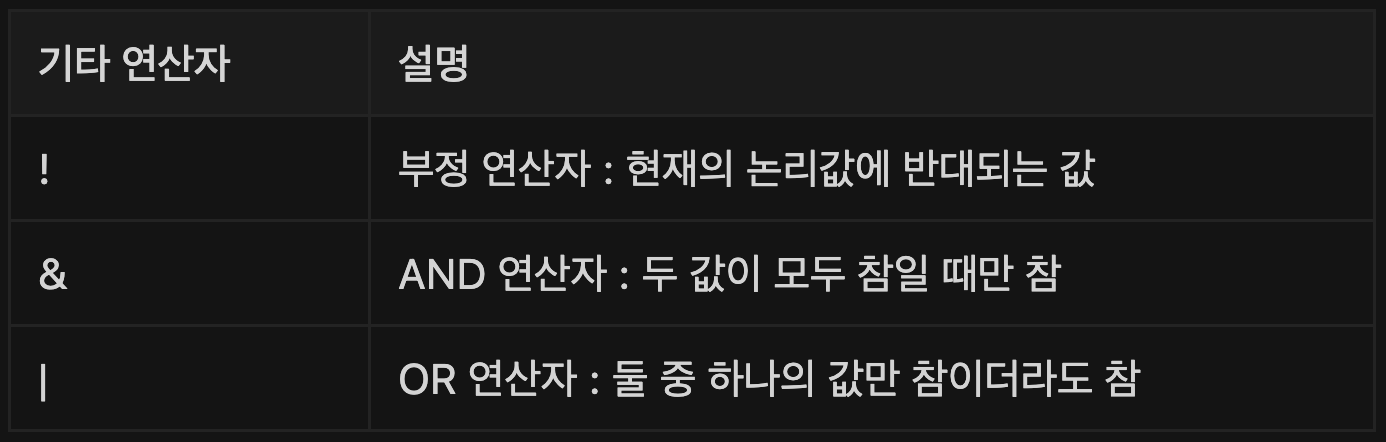
기타 연산자
R 내장 함수
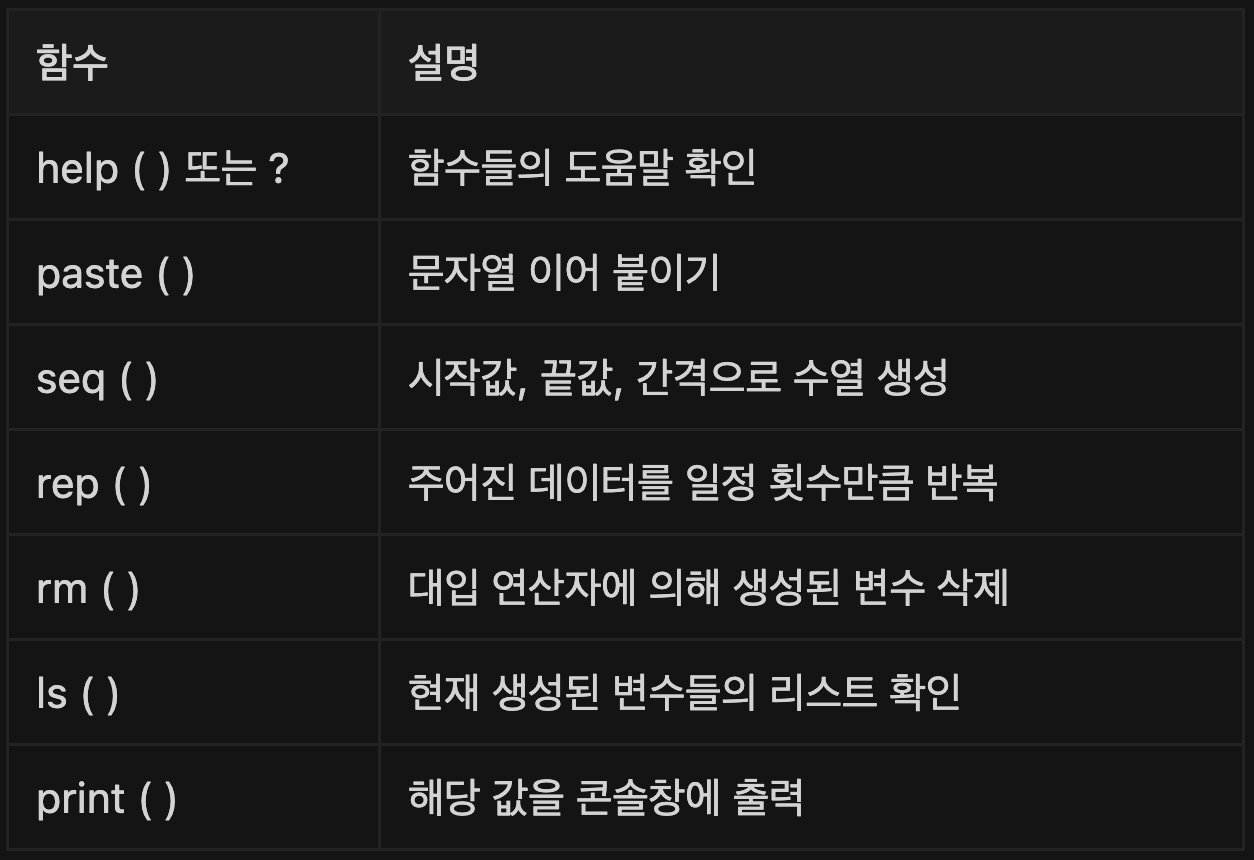
기본 함수
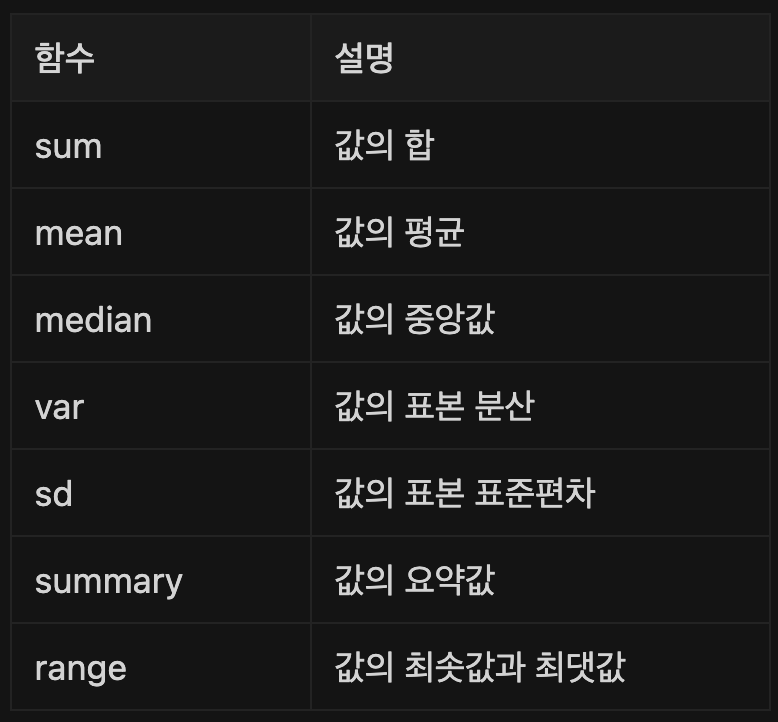
통계 함수
R 데이터 핸들링
벡터형 변수
데이터 이름 변경
데이터 추출/결합 응용
[ , ] 기호를 사용하여 원하는 위치의 데이터를 구할 수 있고 행과 열의 이름으로도 데이터를 얻을 수 있다.
v2 <- matrix(c(1:6),nrow=3) v2[3,2] [1] 6 colnames(v2) <- c('c1','c2') v2[,'c1'] [1] 1 2 3 rownames(v2) <- c('r1','r2','r3') v2['r3','c2'] [1] 6
행렬과 행렬, 데이터프레임과 데이터프레임의 경우 행의 수 혹은 열의 수가 같을 경우 결합이 가능하다. 하지만 벡터와 벡터의 결합에서는 재사용 규칙으로 인하여 부족한 데이터를 재활용하여 사용하며 결과를 반환한다. > ```r > r1 <- c(1,2,3) > r2 <- c(4,5,6,7,8) > rbind(r1,r2) [,1] [,2] [,3] [,4] [,5] r1 1 2 3 **1 2** r2 4 5 6 7 8 Warning message: In rbind(r1, r2) : number of columns of result is not a multiple of vector length (arg 1) ```
제어문
반복문
- for 반복문
- for 반복 구문은 괄호 안의 조건 하에서 1값을 하나씩 증가시켜가며 중괄호 { } 안의 구문을 반복실행 하도록 한다.
- 괄호의 조건 (1 in 1:9)는 11 구문 안의 1 변수가 1:9, 즉 (1, 2, 3, 4, 5, 6, 7, 8, 9)의 값을 순서대로 하나씩 가지며 반복된다는 것을 의미한다.
> e = c() #아무런 값도 포함되지 않는 벡터 선언
> for (i in 1:9) {
+ e[i] = i * i
+ }
> e
[1] 1 4 9 16 25 36 49 64 81- while 반복문
- while 반복 구문 역시 괄호 안의 조건 하에서 중괄호 { } 안의 구문을 반복하도록 한다.
- for 구문과 다르게 While 구문은 괄호 안의 조건이 만족되어 있는 동안 중괄호 안의 구문을 반복한다.
- 따라서 for 구문은 선언과 동시에 몇 회 반복될지 처음부터 정해지는 반면 while 구문은 중괄호 안의 구문이 괄호 안의 조건을 만족하지 않을 때까지 반복되므로 몇 회 반복될지 미리 정해지지 않는다.
f = 1 while(f<5){ + f=f+1 + print(f) + } [1] 2 [1] 3 [1] 4 [1] 5
조건문
if ~ else 구문을 이용하면 if의 조건이 만족되지 않는 경우 else 이하의 조건을 이용해 또 다른 조건을 부여할 수 있다.
아래 코드 예시는 score 벡터에서 성분값이 70 이상인 경우만을 남겨 70이상인 값들만의 개수를 구하는 코드이다.
score = c(88, 90, 78, 84, 76, 68, 50, 48, 33, 70, 48, 66, 88, 96, 79, 65, 27, 88, 96, 33, 64, 48, 77, 18, 26, 44, 48, 68, 77, 64, 88, 95, 79, 88, 49, 30, 29, 10, 49, 88) over70 = rep (0, 40) for (i in 1:40) { + if (score[i] >= 70) { + over70[i] <- 1 + } else { + over70[i] <- 0 + } + } over70 [1] 1 1 1 1 1 0 0 0 0 1 0 0 1 1 1 0 0 1 1 0 0 0 1 0 0 0 0 0 [29] 1 0 1 1 1 1 0 0 0 0 0 1 sum(over70) [1] 18
사용자 정의 함수
'함수 이름 = function (x, y, z)’의 형식으로 선언하며 이 때 괄호 안의 x, y, z는 함수 구문에서 인수(argument)로 사용된다.
아래 코드 예시는 입력한 인수 a까지의 합을 계산해주는 함수 addto를 선언한다.
addto = function (a) { + isum=0 + for (i in 1:a) { + isum=isum + i + } + print (isum) + } addto ( 100 ) [1] 5050 addto ( 50 ) [1] 1275
그 외 유용한 기능들
substr
paste와는 반대로 주어진 문자열에서 일부분을 추출하는 기능
substr("dataanylysis",2,8) [1] "ataanyl"
cov 두 수치 벡터의 공분산을 구하는 기능
공분산이란?
두 변수 간의 관계를 나타내는 통계적 개념으로 두 변수가 함께 어떻게 변하는지를 측정해준다.
height <- c(150, 160, 170, 180, 190) weight <- c(50, 60, 70, 80, 90) covariance <- cov(height, weight) cat("키와 몸무게 간의 공분산:", covariance, "\n") 키와 몸무게 간의 공분산: 250 * cat : "concatenate"의 약어로, R에서는 하나 이상의 인자를 연결하여 출력하는 함수이다. cat 함수는 화면에 문자열이나 값을 출력할 때 주로 사용된다.cor
두 수치 벡터의 상관계수를 구하는 기능x <- c(1, 2, 3, 4, 5) y <- c(2, 3, 5, 4, 6) correlation <- cor(x, y) cat("두 변수의 상관계수:", correlation, "\n") 두 변수의 상관계수: 0.9
날짜
- Sys.Date () : 연, 월, 일 출력
- Sys.time () : 연, 월, 일, 시간 출력
- as.Date () : 주어진 데이터를 날짜 형식으로 변환
Sys.Date( ) #현재 날짜를 출력한다 [1] "2023-11-10" Sys.time() [1] "2023-11-10 00:17:05 KST" as.Date ("2024-01-01") [1] "2024-01-01" # %Y는 연도 네 자리, %y는 연도 두 자리, %m은 월, %d는 일, %A는 요일 format(Sys.Date(),'%Y/%m/%d') [1] "2023/11/10"
자료형 데이터 구조 변환
- as.data.frame () : 데이터 프레임 형식으로 변환
- as.list () : 리스트 형식으로 변환
- as.matrix () : 행렬 형식으로 변환
- as.vector () : 벡터 형식으로 변환
- as.factor () : 팩터 형식으로 변환
- as.numeric () : 문자열이나 다른 데이터 타입을 숫자로 변환
- as.character () : 숫자, 날짜, 논리값 등 다양한 데이터 타입을 문자열로 변환
그래픽 기능
- 산점도 그래프
산점도는 x변수와 y변수의 값을 한눈에 살펴볼 수 있도록 평면에 점을 찍어 표현한 것이다. plot (x, y) 함수는 x에 대한 y의 그래프를 그려주는 함수이다.
키와 몸무게 데이터를 활용하여 산점도 그래프 명령문 결과값을 살펴보자.
height = c(170,168,174,175,188,165,165,190,173,168,159,170,184,155)
weight = c(68,65,74,77,92,63,67,95,72,69,60,69,73,56)
plot(height, weight)
