6. 데이터 전처리
6.1. 데이터 마트
데이터 마트의 이해
데이터 마이닝에서 다양한 분석기법을 적용해 모델을 개발하는 과정을 모델링이라고 합니다. 모델링 분석에 앞서 데이터를 수집, 변형하는 과정이 필요한데, 잘 정리된 데이터 마트를 개발해 놓으면 보다 효율적이고 신속한 모델링이 될 수 있습니다.
데이터 마트
데이터 마트란, 데이터 웨어하우스로부터 특정 사용자가 관심을 갖는 데이터들을 주제별, 부서별로 추출하여 모은 비교적 작은 규모의 데이터 웨어하우스입니다. 효율적인 데이터 마트 개발을 위해서는 R에서 제공하는 reshape, sqldf, plyr 등의 다양한 패키지를 활용할 수 있습니다.
- 데이터 마트로 분리시 시간/공간적인 효율성을 기대할 수 있음
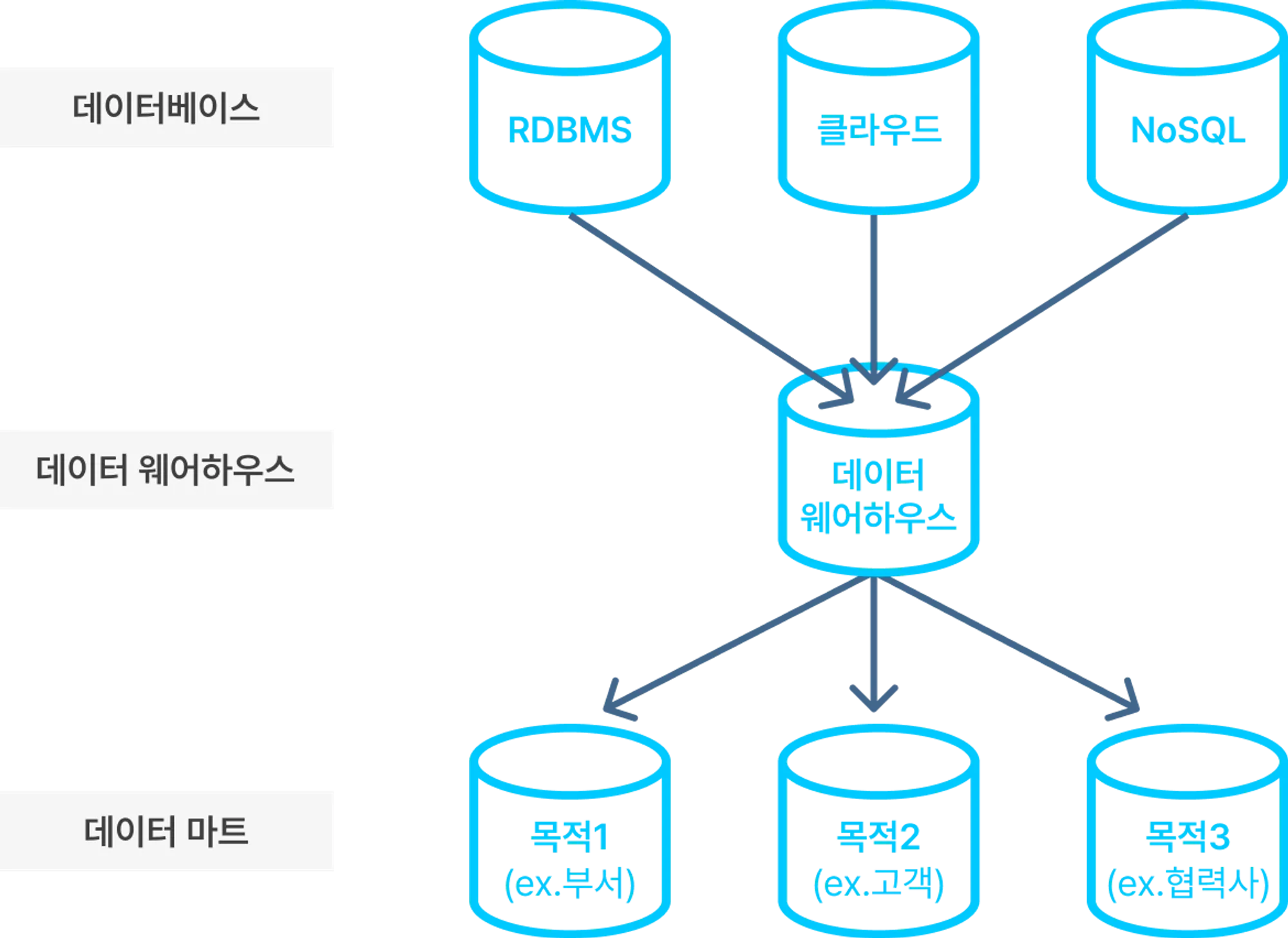
데이터 전처리 (data preprocessing)
데이터 마트에서 데이터를 수집하고 변형하여 적재했다면 전처리 단계를 거쳐야 할 차례입니다. 전처리에는 데이터를 정제하는 과정과 분석 변수를 처리하는 과정이 포함됩니다. 데이터 정제 과정은 크게 결측값과 이상값을 처리하는 내용으로 이루어지며, 분석 변수 처리 과정은 변수 선택, 파생변수 생성 등으로 이루어집니다.
요약변수
- 원래 데이터로부터 기본적인 통계 자료를 추출한 데이터 마트에서 가장 기본적인 변수 (총 합계, 평균, 횟수, 구매여부 등)
- 많은 모델을 공통으로 사용될 수 있어 재활용성이 높다
- 기초적인 통계 자료들이 여기에 속한다
- 예시) 상품별 구매 금액, 상품별 구매 순서, 기간별 구매 금액
파생변수
- 범용으로 활용되는 기본적인 통계자료가 아닌 특정 조건을 만족하거나 특정 함수에 의해 값을 만들어 의미(목적)를 부여한 변수
- 주관적일 수 있으므로 논리적 타당성을 갖추는 것이 중요
- 예시) 최적 통화 시간, 선호하는 가격대 변수, 주 활동 지역 변수, 특정한 목적의 변수들
6.2. 데이터 탐색
탐색적 데이터 분석(EDA)
데이터를 다루다 보면 결측값이나 이상값이 존재할 수 있습니다. 이런 경우 효율적인 방법으로 처리하여 데이터의 정보가 손실되거나 왜곡되는 것을 피해야 합니다.
- 결측값(Missing Data) : 데이터셋에서 특정한 값이 없는 상태
- 이상값(Outlier) : 일반적인 데이터 분포에서 벗어나 있는 값으로, 다른 데이터와 비교했을 때 통계적으로 불규칙한 값을 의미
탐색적 데이터 분석(EDA:Exploratory Data Analysis)이란, 데이터를 본격 분석하기 전에 데이터의 대략적인 특성을 파악하고 의미 있는 관계를 찾아내기 위해 다각도로 접근하는 것을 의미합니다.
데이터 분석 시 자주 사용하는 함수
head / tail
- 시작 또는 마지막 6개 record만 조회
- head(,) 숫자를 넣어주면 원하는 개수만큼 확인 가능
summary
- 수치형 변수 : 최댓값, 최솟값, 평균, 1사분위수, 2사분위수(중앙값), 3사분위수
- 명목형 변수 : 명목값, 데이터 개수
명목형 변수란?
그 자체로는 순서나 크기에 의미가 없는 범주. 예를 들어, 성별(남성, 여성), 혈액형(A, B, AB, O) 등이 명목형 변수의 예시
결측값
결측값(Missing data)은 존재하지 않는 데이터를 의미합니다. 결측값 처리를 위해 시간을 많이 쓰는 것은 비효율적이기 때문에 가능하면 결측값은 제외하고 처리하는 게 적합합니다. 다만 결측값 자체가 의미있는 예외의 경우도 있기 때문에 무조건 제외해버리는 것도 주의해야 합니다.
- 결측값 표현법 : NA(Not Available), 공백, null, 99999999, -1 등
- 결측값 처리를 위한 패키지 : Amelia, DMwR2 등
- 결측값 여부 확인 : is.na
- 결측값 제외 : na.rm → 해당 값만 제외 여부 결정
- na.omit → NA가 있는 행 전체 삭제
결측값 대치 방법
단순 대치법 (Single Imputation)
평균 대치법에서 추정량 표준 오차의 과소 추정 문제를 보완하고자 고안된 방법
- 대표적인 방법 : K-Nearest Neighbor
평균 대치법 (Mean Imputation)
여러 번의 대치를 통해 n개의 가상적 완전 자료를 만드는 방법
- 1단계 : 대치 (Imputation Step)
- 2단계 : 분석 (Analysis Step)
- 3단계 : 결합 (Combination Step)
단순 확률 대치법
평균 대치법에서 추정량 표준 오차의 과소 추정 문제를 보완하고자 고안된 방법
- 대표적인 방법 : K-Nearest Neighbor
다중 대치법
여러 번의 대치를 통해 n개의 가상적 완전 자료를 만드는 방법
- 1단계 : 대치 (Imputation Step)
- 2단계 : 분석 (Analysis Step)
- 3단계 : 결합 (Combination Step)
이상값
이상값(Outlier)은 데이터를 입력하는 과정에서 의도하지 않게 잘못 입력한 경우(Bad Data) 혹은 의도하지 않게 입력됐으나 분석 목적에 부합되지 않아 제거해야 하는 경우(Bad Data) 그리고 의도되지 않은 현상이지만 분석에 포함해야 하는 경우가 있습니다. 따라서 이상값을 꼭 제거해야 하는 것은 아니기 때문에 분석의 목적이나 종류에 따라 적절한 판단이 필요합니다.
이상치 사용 분야
사기 탐지, 의료(특정 환자에게 보이는 예외적인 증세), 네트워크 침입탐지 등 부정사용방지
이상값 판단 방법
ESD (Extreme Studentized Deviation)
- 평균으로부터 3 표준편차 만큼 떨어진 값을 이상값으로 인식하는 방법
- 정규분포에서 99.7%의 자료들은 3 표준편차 안에 위치하므로 전체 데이터의 0.3 퍼센트를 이상값으로 구분
사분위수
- 사분위수는 측정값을 최솟값에서 최댓값까지 오름차순으로 정렬한 자료를 4등분했을 때 각 위치에 해당하는 값을 의미
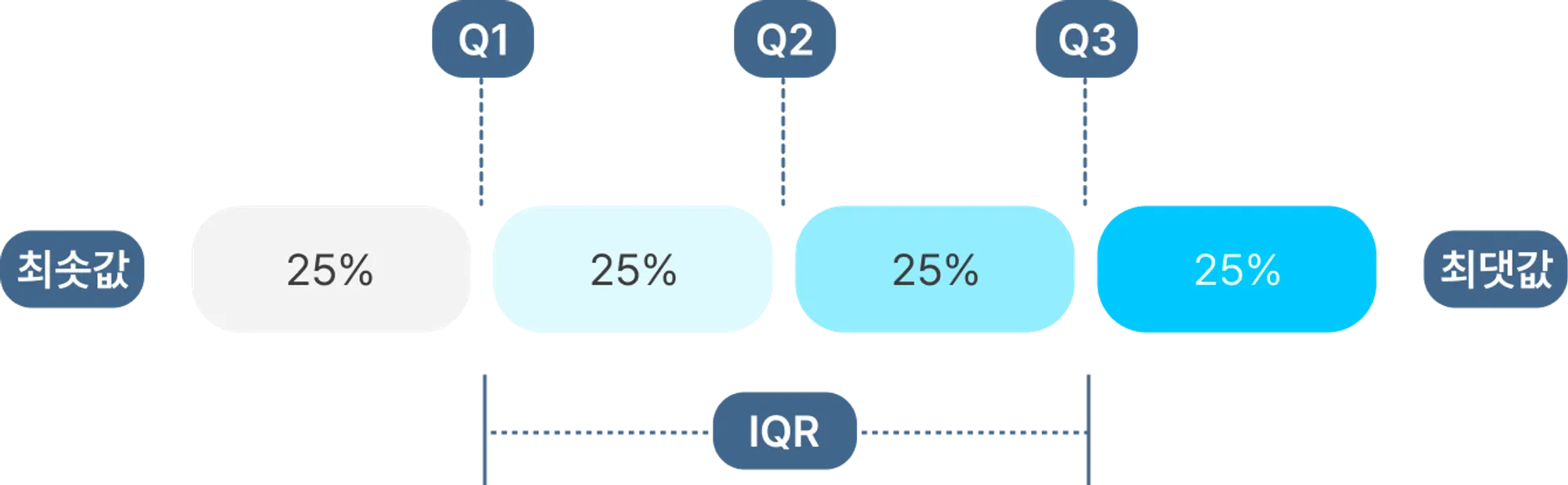
- QR (Interquartile Range) : 분범위라고 부르며, 1분위 수(Q1)부터 3분위 수(Q3)까지의 범위를 의미
- 중앙값 (median) : 2분위 수(Q2)
- 일반적으로 사분범위에서 1.5분위수를 벗어나는 경우 이상치로 판단
- Q1 - 1.5 X IQR (하한 최솟값) 보다 작거나 Q3 + 1.5 X IQR (상한 최댓값)보다 큰 값을 이상값으로 간주
- 이상값은 상자그림(boxplot)으로 식별 가능
