8. 통계분석 - 기초통계
8.1. 기술통계
기술통계
기술통계(Descriptive Statistics)란?
자료의 특성을 표, 그림, 통계량 등을 사용하여 쉽게 파악할 수 있도록 정리/요약하는 것
- 데이터 분석에 앞서 데이터의 대략적인 통계적 수치를 계산해 보며 분석에 대한 통찰력을 얻을 수 있다.
그래프를 이용한 자료 정리
- 히스토그램
주어진 데이터를 구간으로 나누고 각 구간에 속하는 데이터의 빈도를 막대로 표현한 그래프
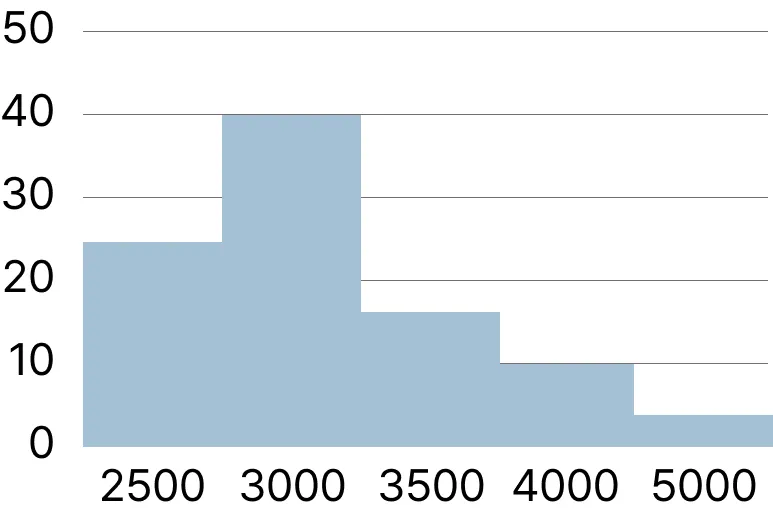
- 주로 데이터의 분포를 살펴보거나, 데이터의 모양이나 특성을 파악하는 데에 사용
- 연속(Continuous)형으로 표시된 데이터를 표현하며 임의로 순서 변경할 수 없고 막대 사이 간격이 없다
- 연속형 데이터 예시 : 키, 몸무게, 성적, 소득 등
히스토그램 생성
- 데이터의 수를 활용하여 계급 수와 계급 간격을 계산하여 도수분포표를 만들고 히스토그램을 생성한다.
- 계급의 수와 간격이 변하면 히스토그램의 모양도 변한다.
- 계급의 수 : 을 만족하는 최소의 정수 에서 최소의 정수
(k=계급수 / n = 데이터 수) - 계급의 간격 : (최댓값 - 최솟값) / 계급 수로 파악 가능
- 막대그래프
범주(Category)형으로 구분된 데이터를 표현하며 범주의 순서를 의도에 따라 바꿀 수 있다.
- 범주형 데이터 예시 : 직업, 종교, 음식 등
- 줄기-잎 그림 (Stem-and Leaf Plot)
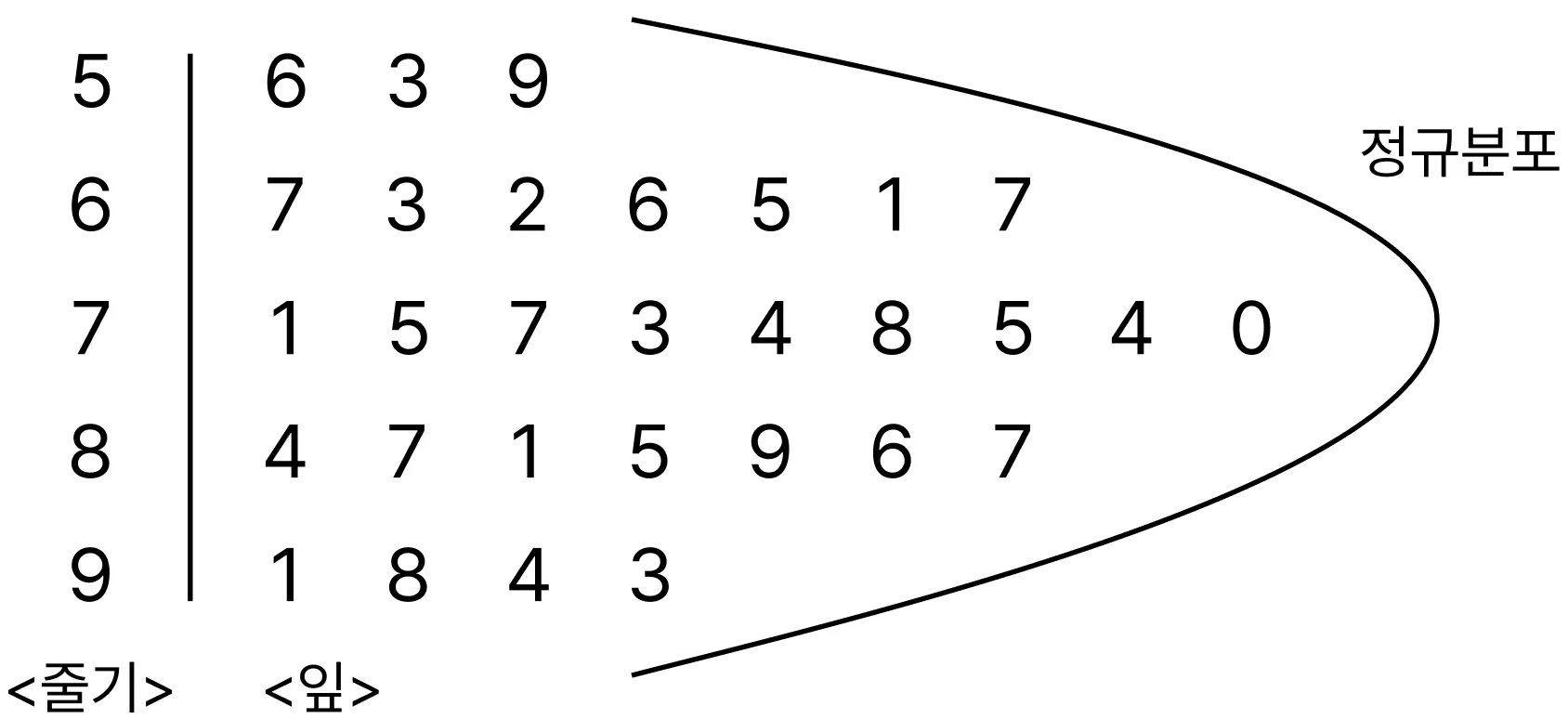
데이터를 줄기와 잎의 모양으로 그린 그림
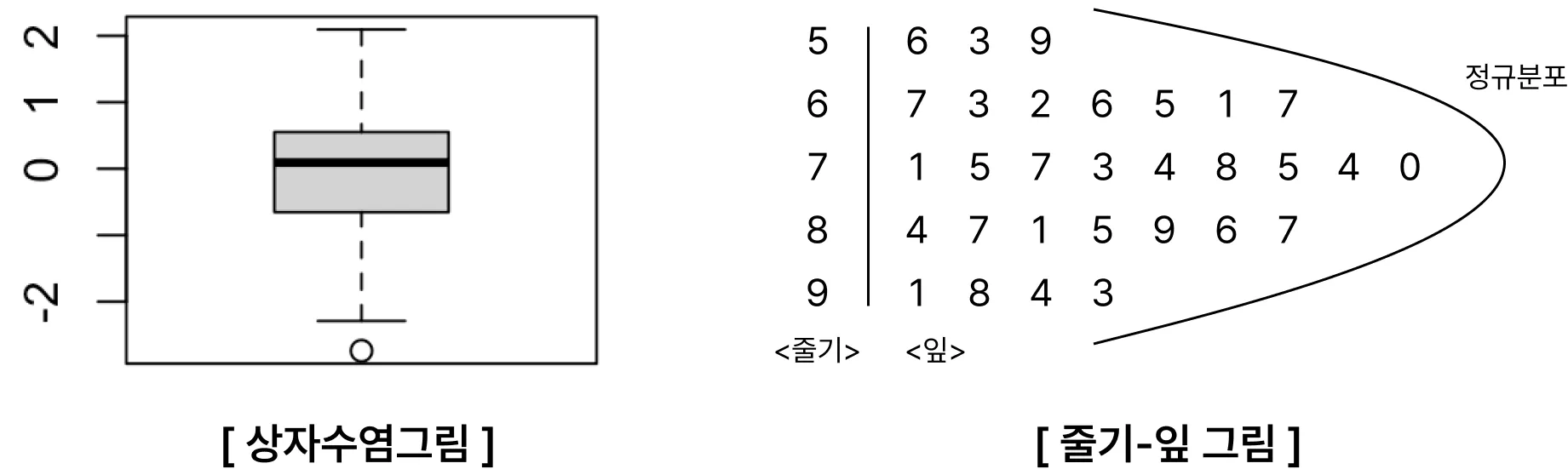
- 상자그림 (상자수염그림, Box Plot)
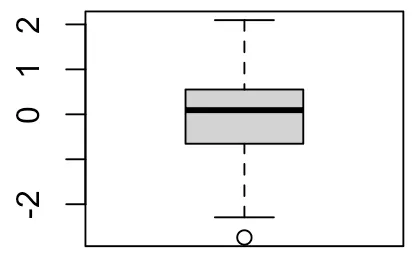
- 다섯 숫자 요약을 통해 그림으로 표현한 것 (최솟값, Q1, Q2, Q3, 최댓값)
- 보통이상점 (Mild Outlier) : 안쪽 울타리와 바깥 울타리 사이에 있는 자료
- 극단이상점(Extreme Outlier) : 바깥울타리 밖의 자료
인과관계의 이해
종속변수 (반응변수, y)
다른 변수의 영향을 받는 변수
- 어떤 실험이나 조사에서 변화의 결과로 나타나는 변수이며, 이러한 변화는 독립변수들에 의해 영향을 받는다.
예시 : 학업 성적을 예측하고자 할 때,
종속변수 - 학업 성적
독립변수 - 공부시간, 수면시간, 출석률 등
독립변수 (설명변수, x)
- 다른 변수에 영향을 주는 변수
- 독립변수는 종속변수의 값을 설명하거나 예측하는 데 사용되며, 종속변수의 원인이 되는 변수라고 볼 수 있다.
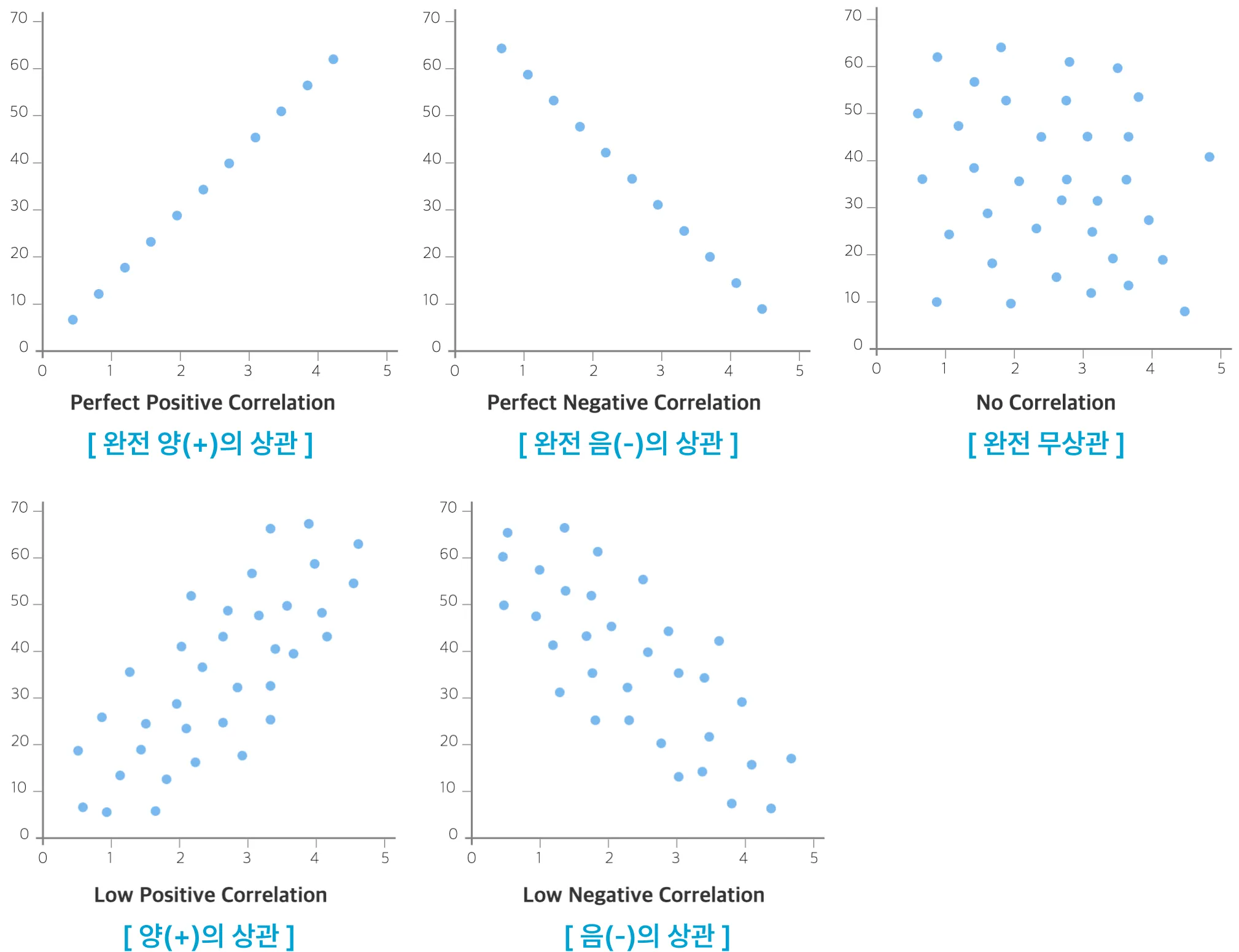
산점도
- 두 변수 간의 관계를 시각적으로 나타내는 그래픽 표현 방법 중 하나
- 각 점은 두 변수의 값을 나타내며, 점들의 분포를 통해 두 변수 간의 관계를 시각적으로 확인할 수 있다.
산점도에서 확인할 사항
- 두 변수 사이의 선형관계(직선관계)가 성립하는가?
- 두 변수 사이의 함수관계(직선관계 또는 곡선관계)가 성립하는가?
- 이상값이 존재하는가?
- 몇 개의 집단으로 구분(층별) 되는가?
이미지 출처 : diagrammm (https://diagrammm.com/scatter_plot)
연습문제
01. 히스토그램에 대한 설명으로 옳지 않은 것?
- 범주형으로 구분된 데이터를 표현한다
- 데이터의 모양이나 특성을 파악하는 데에 사용
- 데이터 예시 : 키, 몸무게, 성적 등
- 임의로 순서 변경할 수 없다
정답
히스토그램은 연속(Continuous)형으로 표시된 데이터를 표현한다.
02. 산점도에서 확인할 사항으로 옳지 않은 것은?
- 두 변수 사이의 선형관계(곡선관계)가 성립하는가?
- 이상값이 존재하는가?
- 두 변수 사이의 함수관계(직선관계 또는 곡선관계)가 성립하는가?
- 몇 개의 집단으로 구분(층별) 되는가?
정답
두 변수 사이의 선형관계(직선관계)가 성립하는지 확인해야 한다.
8.2. t-검정
일 표본 t-검정
일 표본 t-검정 (one sample t-test) 이란?
한 집단의 평균이 어떤 특정한 값과 차이가 있는지를 검정하는 통계적 방법
- 주로 특정 가설을 확인하거나 평균이 기대값과 일치하는지 여부를 평가할 때 사용
일 표본 단측 t-검정
특정 방향으로 평균의 차이를 검정하는 통계적 방법
- 대립가설이 어느 한 방향으로 특정되어 있을 때 사용
- 대립가설이 '크다' 또는 '작다'와 같이 어떤 특정 방향을 가리킬 때 유용
# 어떤 훈련 프로그램이 평균적으로 시험 성적을 향상시킬 것이라고 가정했을 경우
# 귀무가설 (H0): 훈련 전후의 평균 시험 성적에 유의미한 차이가 없다.
# 대립가설 (H1): 훈련 후의 평균 시험 성적이 훈련 전보다 더 높다.
# 가상의 데이터 생성
> set.seed(123)
> before_training <- c(75, 78, 80, 72, 76)
> after_training <- c(80, 82, 85, 78, 81)
# 일 표본 단측 t-검정 수행
> result <- t.test(after_training, mu = mean(before_training), alternative = "greater")
# 결과 출력
> result
One Sample t-test
data: after_training
t = 4.3193, df = 4, p-value = 0.006227
alternative hypothesis: true mean is greater than 76.2
95 percent confidence interval:
78.73221 Inf
sample estimates:
mean of x
81.2
# 검정통계량 t = 4.3193 , 자유도 df = 4 , p-value = 0.006227
# 결과에서 나온 p-value를 통해 귀무가설을 기각할지 여부를 판단할 수 있다.일 표본 양측 t-검정
모수값이 ‘~이다’ 혹은 ‘~이 아니다’와 같이 방향성이 없는 경우에 수행되는 검정 방법
- 양측 t-검정은 주로 두 집단의 평균이 서로 다르다는 것을 확인하고자 할 때 사용
# 어떤 과자의 평균 무게가 200g인지 확인하고자 한다고 가정했을 경우
# 귀무가설 (H0): 과자의 평균 무게는 200g이다.
# 대립가설 (H1): 과자의 평균 무게는 200g과 다르다.
# 가상의 데이터 생성
> set.seed(123)
> cookie_weights <- c(198, 201, 199, 202, 200, 198, 201, 199, 200, 201)
# 일 표본 양측 t-검정 수행
> result <- t.test(cookie_weights, mu = 200, alternative = "two.sided")
# 결과 출력
> result
One Sample t-test
data: cookie_weights
t = -0.23077, df = 9, p-value = 0.8227
alternative hypothesis: true mean is not equal to 200
95 percent confidence interval:
198.9197 200.8803
sample estimates:
mean of x
199.9
# 값이 유의수준(보통 0.05)보다 작다면 귀무가설을 기각하게 된다.
# 값이 유의수준(보통 0.05)보다 크다면 귀무가설을 기각할 수 없다.이(독립) 표본 t-검정
이 표본 t-검정(independent sample t-test) 이란?
독립된 그룹 간에 평균 차이가 있는지를 검정하는 통계적 방법 중 하나로 두 그룹이 서로 독립되어 있고, 각각의 그룹에서의 관측치들이 서로 영향을 미치지 않는 경우에 사용
- 두 그룹의 분산이 같음을 의미하는 등분산성을 만족해야 하므로 이 표본 t-검정을 수행하기 전에 등분산 검정(F 검정)을 먼저 수행해야 한다.
이 표본 단측 t-검정
두 그룹에 대하여 모수 비교를 할 때 ‘~이 ~보다 크다’ 혹은 ‘~이 ~보다 작다’와 같이 두 그룹 사이에 대소가 있는 경우 수행되는 검정 방법
# A 집단의 성적이 B 집단의 성적보다 같거나 더 높다는 귀무가설을 수립했다고 가정
# 가상의 데이터 생성
> set.seed(123)
> group_A <- c(75, 78, 82, 85, 80)
> group_B <- c(80, 85, 88, 90, 87)
# 표본 단측 t-검정 (예상 방향: A 집단의 평균이 같거나 높다)
> result <- t.test(group_A, group_B, alternative = "less")
# 결과 출력
> result
Welch Two Sample
t-testdata: group_A and group_B
t = -2.4914, df = 8, p-value = 0.01872
alternative hypothesis: true difference in means is less than 0
95 percent confidence interval:
-Inf -1.521615
sample estimates:
mean of x mean of y
80 86
# 값이 유의수준(보통 0.05)보다 작다면 귀무가설을 기각하게 된다.
# 값이 유의수준(보통 0.05)보다 크다면 귀무가설을 기각할 수 없다.이 표본 양측 t-검정
두 그룹의 모수를 비교할 때 ‘두 그룹이 같다’ 또는 ‘두 그룹이 다르다’와 같이 두 그룹 사이에 대소가 없는 경우 수행되는 검정 방법
# A 집단과 B 집단의 평균 성적이 서로 다르다는 가설 테스트
# 가상의 데이터 생성
> set.seed(123)
> group_A <- runif(30, min = 60, max = 90) # A 그룹의 수학 성적
> group_B <- runif(30, min = 65, max = 95) # B 그룹의 수학 성적
# 표본 양측 t-검정
> result <- t.test(group_A, group_B, alternative = "two.sided")
# 결과 출력
> result
Welch Two Sample t-test
data: group_A and group_B
t = -0.43848, df = 57.999, p-value = 0.6627
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-5.494026 3.519583
sample estimates:
mean of x mean of y
77.17200 78.15923
# 값이 유의수준(보통 0.05)보다 작다면 귀무가설을 기각하게 된다.
# 값이 유의수준(보통 0.05)보다 크다면 귀무가설을 기각할 수 없다.대응 표본 t-검정
동일한 대상에 대해 두 가지 관측지가 있는 경우 이를 비교하여 차이가 있는지 검정할 때 사용
- 실험 전후의 효과를 비교할 때 주로 사용
- 결과적으로, 두 변수 간의 변화가 우연에 의한 것인지, 아니면 특정한 처리나 조건에 의해 유발된 것인지를 알 수 있다.
# before와 after라는 두 가지 조건에서 얻은 가상의 데이터를 생성 후
# 그 차이를 나타내는 after 데이터를 만들기
# 가상의 데이터 생성
> set.seed(123)
> before <- runif(20, min = 25, max = 35)
> after <- before + runif(20, min = -2, max = 2)
# 대응 표본 t-검정
> result <- t.test(before, after, paired = TRUE)
# 결과 출력
> result
Paired t-test
data: before and after
t = -1.1969, df = 19, p-value = 0.2461
alternative hypothesis: true mean difference is not equal to 0
95 percent confidence interval:
-0.8435527 0.2297860
sample estimates:
mean difference
-0.3068834
# 값이 유의수준(보통 0.05)보다 작다면 귀무가설을 기각하게 된다.
# 값이 유의수준(보통 0.05)보다 크다면 귀무가설을 기각할 수 없다.연습문제
1번
모수값이 ‘~보다 크다’ 또는 ‘~보다 작다’와 같이 한쪽으로의 방향성을 갖는 경우 수행되는 검정 방법으로 옳은 것은?
1. 일 표본 단측 t-검정
2. 이 표본 단측 t-검정
3. 이 표본 양측 t-검정
4. 대응 표본 t-검정
정답
일 표본 단측 t-검정은 모수값이 ‘~보다 크다’ 또는 ‘~보다 작다’와 같이 한쪽으로의 방향성을 갖는 경우 수행되는 검정 방법이다.
2번
아래 보기에서 설명하는 t-검정 방법에 대한 설명으로 옳지 않은 것은?
그룹의 분산이 같음을 의미하는 등분산성을 만족해야 하므로 이 표본 t-검정을 수행하기 전에 등분산 검정(F 검정)을 먼저 수행해야 한다.
1. 독립된 그룹 간에 평균 차이가 있는지를 검정하는 통계적 방법 중 하나
2. 두 그룹이 서로 독립되어 있고, 각각의 그룹에서의 관측치들이 서로 영향을 미치지 않는 경우에 사용
3. 독립 표본 t-검정이라고도 부른다
4. 모수값이 ‘~이다’ 혹은 ‘~이 아니다’와 같이 방향성이 없는 경우에 수행되는 검정 방법
정답
보기의 내용은 이 표본 t-검정에 대한 설명이며, 4번의 내용은 일 표본 양측 t-검정에 대한 설명이다.
3번
아래 보기에서 설명하는 t-검정 방법으로 옳은 것은?
<보기>
두 그룹의 모수를 비교할 때 ‘두 그룹이 같다’ 또는 ‘두 그룹이 다르다’와 같이 두 그룹 사이에 대소가 없는 경우 수행되는 검정 방법
1. 상관관계 검정
2. 일 표본 단측 t-검정
3. 이 표본 양측 t-검정
4. 대응 표본 t-검정
정답
이 표본 양측 t-검정이란, 두 그룹의 모수를 비교할 때 ‘두 그룹이 같다’ 또는 ‘두 그룹이 다르다’와 같이 두 그룹 사이에 대소가 없는 경우 수행되는 검정 방법이다.
8.3. 분산분석
분산분석 개요
분산분석(Analysis of Variance, ANOVA)이란?
여러 그룹 간의 평균 차이를 비교하는 통계적인 기법 중 하나
- 일반적으로 세 개 이상의 그룹 간의 평균 차이를 비교하는 데에 쓰인다.
- 그룹 간의 차이가 우연에 의한 것인지를 판단하는 데에 사용한다.
- 분산분석에는 ‘(집단 간 분산)÷(집단 내 분산)’으로 계산되는 F-value가 사용된다.
분산분석의 단점
귀무가설을 기각할 경우 어느 집단 간 평균이 같은지, 혹은 어느 집단 간의 평균이 얼마나 다른지 알 수없다는 점
- 그래서 분산분석의 귀무가설을 기각했을 경우 사후검정방법으로 Scheffe, Tukey, Duncan, Fisher’s LSD, Dunnett, Bonferroni 등의 방법을 사용한다.
분산분석을 수행하기 위한 3가지 가정
- 등분산성 : 모든 그룹에서의 오차(잔차)의 분산이 동일해야 한다.
이는 각 그룹 내의 데이터가 대체로 비슷한 정도의 퍼짐을 가지고 있어야 함을 의미한다. - 독립성 : 각 그룹 내의 관측치들은 서로 독립적이어야 한다.
즉, 각 집단은 서로에게 영향을 주지 않아야 한다. - 정규성 : 각 그룹 내의 오차(잔차)가 정규분포를 따라야 한다.
일원분산분석
일원분산분석 (one-way Anova) 이란?
하나의 집단에 속하는 독립변수와 종속변수 모두 한 개일 때 사용한다.
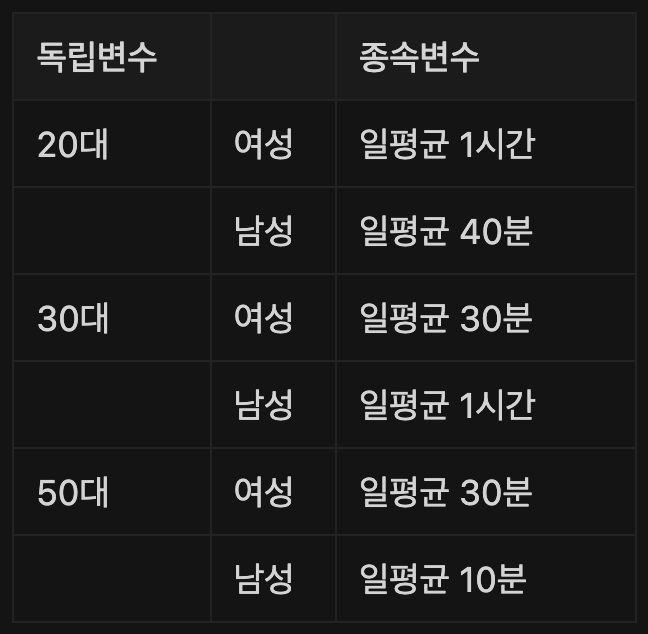
예를 들어 연령대별(20대, 30대, 50대) OTT 시청 시간의 차이가 있는지 알아보고 싶다고 가정할 경우
- 독립변수는 연령대별 집단(20대, 30대, 50대), 종속변수는 OTT 시청 시간
- 셋 이상의 집단이지만 독립변수는 ‘연령대별 집단’ 하나의 종류로 봐야 한다. 하나의 독립변수가 각각 종속변수에 영향을 끼치기 때문이다.
분산분석표
- SSE : 잔차들이 자신의 표본평균으로부터 벗어난 편차의 제곱
- SSR : 표본평균과 종속변수값 중 독립변수에 의해 설명된 부분과의 차이를 제곱하여 합한 값
- SST : 종속변수의 관측값과 표본의 평균의 차이(편차)를 제곱하여 합한 값
일원분산분석 R 실습
# 컴퓨터 A,B,C의 속도 차이가 있는지 여부 확인
# 귀무가설 : A,B,C 라는 세 대의 신형 핸드폰 간의 속도 차이는 없다.
# 대립가설 : 그룹 간 평균의 차이가 존재한다.
> ComputerSpeed <- runif (45, min=75, max=100)
> Computer <- rep(c('A','B','C'),15)
> ComputerData <- data.frame(ComputerSpeed, Computer)
#분산분석 수행
> result <- aov ( data = ComputerData, ComputerSpeed~Computer)
> summary (result)
Df Sum Sq Mean Sq F value Pr(>F)
Computer 2 68 33.98 0.685 0.51
Residuals 42 2085 49.64
#p-value 값이 0.51로 0.05 보다 작지 않으므로 귀무가설을```r
# 컴퓨터 A,B,C의 속도 차이가 있는지 여부 확인
# 귀무가설 : A,B,C 라는 세 대의 신형 핸드폰 간의 속도 차이는 없다.
# 대립가설 : 그룹 간 평균의 차이가 존재한다.
> ComputerSpeed <- runif (45, min=75, max=100)
> Computer <- rep(c('A','B','C'),15)
> ComputerData <- data.frame(ComputerSpeed, Computer)
#분산분석 수행
> result <- aov ( data = ComputerData, ComputerSpeed~Computer)
> summary (result)
Df Sum Sq Mean Sq F value Pr(>F)
Computer 2 68 33.98 0.685 0.51
Residuals 42 2085 49.64
#p-value 값이 0.51로 0.05 보다 작지 않으므로 귀무가설을 기각할 수 없다.이원분산분석
이원분산분석 (two-way Anova) 이란?
두 개의 독립 변수(요인)가 종속 변수에 미치는 영향을 동시에 평가하는 통계 분석 기법
- 각 독립 변수는 두 개 이상의 수준(그룹 또는 조건)을 가질 수 있다.
- 예를 들어, 두 가지 요인이 제품의 생산에 미치는 영향을 알고 싶을 때 사용될 수 있다.
- 독립변수 간 교호작용이 있다고 판단될 때 ‘반복이 있는 실험’을 하고, 교호작용이 없다고 판단될 때, 즉 두 독립변수가 독립인 경우에는 ‘반복이 없는 실험’을 한다.
* 교호작용이란, 독립변수끼리 서로 영향을 미치는 경우를 말한다.
교호작용이 있을 때 반복이 있는 이원분산분석표
p, q = 집단의 수, r = 반복횟수

교호작용이 없을 때 반복이 없는 이원분산분석표
p, q = 집단의 수

연습문제
1번
연령대별 혈압의 차이가 있는지 검정하려고 할 때, 아래의 표를 보고 검정을 수행하기 위해 적절한 R코드는?
| 변수명 | 데이터 유형 | 데이터 예시 |
|---|---|---|
| age | 범주형 | 10대, 20대, 30대, … |
| pressure | 연속형 | 87.1mmHg, 110mmHg, … |
- anova(pressure~age)
- anova(age~pressure)
- aov(age~pressure)
- aov(pressure~age)
정답
분산분석을 수행하기 위해서는 aov 함수를 사용하며, aov(연속형~범주형)으로 입력한다.
anova 함수는 회귀분석 및 로지스틱스 회귀분석과 같이 모델에 대한 분산분석 결과를 반환하기에 위 예시에 사용하기 적합하지 않다.
2번
분산분석을 수행하기 위한 가정으로 옳지 않은 것은?
1. 등분산성
2. 적합성
3. 독립성
4. 정규성
정답
분산분석을 수행하기 위한 3가지 가정
1. 등분산성 : 모든 그룹에서의 오차(잔차)의 분산이 동일해야 한다.
2. 독립성 : 각 그룹 내의 관측치들은 서로 독립적이어야 한다.
3. 정규성 : 각 그룹 내의 오차(잔차)가 정규분포를 따라야 한다.
3번
분산분석에 대한 설명으로 옳지 않은 것은?
1. 여러 그룹 간의 평균 차이를 비교하는 통계적인 기법 중 하나이다.
2. 일반적으로 세 개 이상의 그룹 간의 평균 차이를 비교하는 데에 쓰인다.
3. 그룹 간의 차이가 우연에 의한 것인지를 판단하는 데에 사용한다.
4. 귀무가설을 기각할 경우 어느 집단 간 평균이 같은지 확인할 수 있다는 장점이 있다.
정답
분산분석은 귀무가설을 기각할 경우 어느 집단 간 평균이 같은지, 혹은 어느 집단 간의 평균이 얼마나 다른지 알 수없다는 단점이 있다.
8.4. 교차분석/상관분석
교차분석
교차분석
교차분석이란
주로 범주형 변수 간의 관계를 파악하고자 할 때 사용되는 통계 분석 기법
- 카이제곱 () 검정통계량을 이용한다.
- 적합도 검정, 독립성 검정, 동질성 검정에 사용된다.
교차분석표
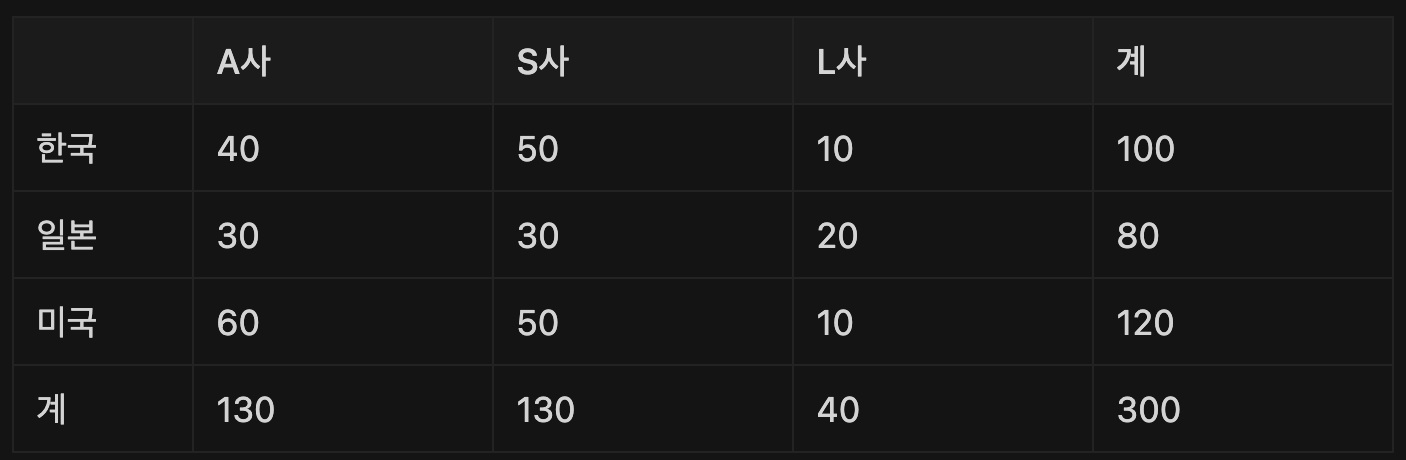
주로 교차분석에서 사용되는 도구로는 교차분석표가 있다. 교차분석표는 두 범주형 변수의 각 수준에 따른 빈도를 나타낸 표이다.
<나라별 핸드폰 브랜드 선호도>
적합도 검정
적합도 검정이란?
실험 결과 얻어진 관측값이 예상값과 일치하는지를 검정하는 방법
- 실험 데이터 : 관측도수 / 예측값 : 기대도수
- 주로 범주형 데이터(카테고리 혹은 그룹으로 나누어진 데이터)에 적용된다.
- 적합도 검정을 하는 유의수준은 보통 로 정한다.
- 적합도 검정의 기각값은 카이제곱 분포표에서 유의수준 일 때 자유도 범주 수-1 에 해당하는 값이다.
적합도 검정 예시
어떤 학급의 학생들이 선호하는 과목이 학교 전체 학생들의 선호하는 과목 분포와 일치하는지 확인
적합도 검정에서의 가설
- 귀무가설 **() :** 실제 분포와 예측 분포가 일치한다.
- 대립가설 **() :** 실제 분포와 예측 분포가 일치하지 않는다.
독립성 검정
독립성 검정이란?
두 변수 간의 관계가 독립적인지 여부를 테스트하는 통계적 방법
- 주로 교차표를 사용하여 두 범주형 변수 간의 독립성을 확인한다.
- 독립성 검정에서 가장 일반적으로 사용되는 통계 검정 중 하나는 카이제곱 검정이다.
- 카이제곱 검정에 의한 독립성 검정 결과는 두 범주형 변수 간에 관계가 있는지 없는지만 나타낼 뿐이며, 두 변수 간 관계의 강도를 말해주지는 않는다.
독립성 검정 예시
- 학생들의 성별과 성적 간의 독립성을 확인하여 성별이 성적에 영향을 미치는지 여부 판단
- 특정 지역의 투표 결과가 선거 참여자의 연령과 관련이 있는지 여부 검정
독립성 검정에서의 가설
- 귀무가설 (): 두 변수는 독립적이다.
- 대립가설 (): 두 변수는 독립적이지 않다.
동질성 검정
동질성 검정이란?
두 개 이상의 모집단이 동일한 분포를 가지고 있는지를 검정하는 통계적 방법이다.
가장 흔하게 사용되는 동질성 검정 중 하나는 카이제곱 동질성 검정이다
- 두 개 이상의 독립적인 표본 집단이 동일한 모집단에서 추출되었는지를 판단하기 위해 사용
동질성 검정 예시
- 서로 다른 지역에서 추출한 세 개의 표본 집단이 동일한 성별 분포를 가지고 있는지 확인
- 서로 다른 세 가지 제품 브랜드에서 추출한 소비자들의 선호도가 동일한지를 검정
동질성 검정에서의 가설
- 귀무가설 () : 각 표본은 동일한 모집단에서 추출되었다 (모든 집단은 동일한 분포를 가짐)
- 대립가설 () : 적어도 하나의 표본은 다른 모집단에서 추출되었다 (적어도 하나의 집단은 다른 분포를 가짐)
상관분석
상관분석 (Correlation Analysis) 이란?
두 변수 간의 관계의 정도를 알아보기 위한 분성방법
- 상관분석에서 사용되는 상관계수(correlation coefficient)는 두 변수 간의 선형적 관계를 나타낸다.
- 일반적으로 -1에서 1 사이의 값을 가지는데, +1에 가까우면 강한 양의 상관관계가, -1에 가까우면 강한 음의 상관관계가 있다고 보며, 0에 가까울수록 상관관계가 존재하지 않는다고 본다.
산점도 귀무가설
- 상관분석의 귀무가설은 ‘ (두 변수는 아무 상관관계가 없다)’이다.
- p-value가 유의수준보다 작아 귀무가설을 기각할 수 있다면 두 변수 간에 유의한 상관관계가 있다고 말할 수 있다.
상관분석의 유형
피어슨 상관분석 (선형적 상관관계)
- 등간척도 이상으로 측정된 두 변수들의 상관관계 측정 방식
- 모수적 방법의 하나로 두 변수가 모두 정규분포를 따른다는 가정이 필요하다.
- 연속형 변수, 정규성 가정
- 상관계수 : 피어슨 (적률상관계수)
스피어만 상관분석 (비선형적 상관관계)
- 서열척도인 두 변수들의 상관관계 측정 방식
- 순서형 변수, 비모수적 방법
- 순위를 기준으로 상관관계 측정
- 상관계수 : 순위상관계수 (,로우)
상관분석을 위한 R 코드

#### 상관분석 예제
# datasets 패키지의 mtcars라는 데이터셋 사용
# 마일(mpg), 총마력(hp)의 상관관계 분석
> data(mtcars)
> a <- mtcars$mpg
> b <- mtcars$hp
> cov(a,b)
[1] -320.7321
> cor(a,b)
[1] -0.7761684
> cor.test(a,b,method="pearson")
Pearson's product-moment correlation
data: a and b
t = -6.7424, df = 30, p-value = 1.788e-07
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
-0.8852686 -0.5860994
sample estimates:
cor
-0.7761684
# 공분산 -320.7321
# 상관계수 -0.7761684
# mpg와 hp는 공분산으로 음의 방향성을 가짐을 알 수 있고,
# 상관계수로 강한 음의 상관관계가 있음을 알 수 있다.
# p-value 가 1.788e-07로 유의수준 0.05보다 작기 때문에 mpg와 hp가 상관관계가 있다고 할 수 있다.연습문제
1번
스피어만 상관계수에 대한 설명으로 옳지 않은 것은?
1. 특징으로 순서형 변수, 비모수적 방법이라는 것이 있다.
2. 비선형적인 상관관계는 나타내지 못한다.
3. 서열척도인 두 변수들의 상관관계 측정 방식이다.
4. -1에서 1 사이의 값을 가진다.
정답
(2) 스피어만 상관계수는 순서형 변수를 사용하며 비모수적 상관관계를 나타낸다.
2번
피어슨 상관분석에 대한 설명으로 옳지 않은 것은?
1. 등간척도 이상으로 측정된 단 하나의 변수의 상관관계 측정 방식이다.
2. 모수적 방법의 하나로 두 변수가 모두 정규분포를 따른다는 가정이 필요하다.
3. 연속형 변수, 정규성 가정
4. 선형적 상관관계를 나타낸다
정답
등간척도 이상으로 측정된 두 변수들의 상관관계 측정 방식이다.
3번
교차분석이 사용되는 검정으로 옳지 않은 것은?
1. 독립성 검정
2. 동질성 검정
3. 정규성 검정
4. 적합도 검정
정답
교차분석은 적합도 검정, 독립성 검정, 동질성 검정에 사용된다
