9. 통계분석 - 회귀분석
9.1. 회귀분석 개요
회귀분석 개념
회귀분석(Regression Analysis)이란(중)
한 변수(종속 변수)와 하나 이상의 다른 변수(독립 변수) 간의 관계를 모델링하고 설명하는 통계적 기법으로 하나 이상의 독립변수(들이 종속변수()에 미치는 영향을 예측하는 통계기법이다.
- 독립변수를 원인변수(혹은 설명 변수), 종속변수를 결과변수(혹은 반응변수)라고도 부른다.
- 독립변수와 종속변수는 모두 연속형 변수일 때 사용 가능하며, 종속변수가 범주형 변수인 경우에 대해서는 로지스틱 회귀분석을 사용한다.
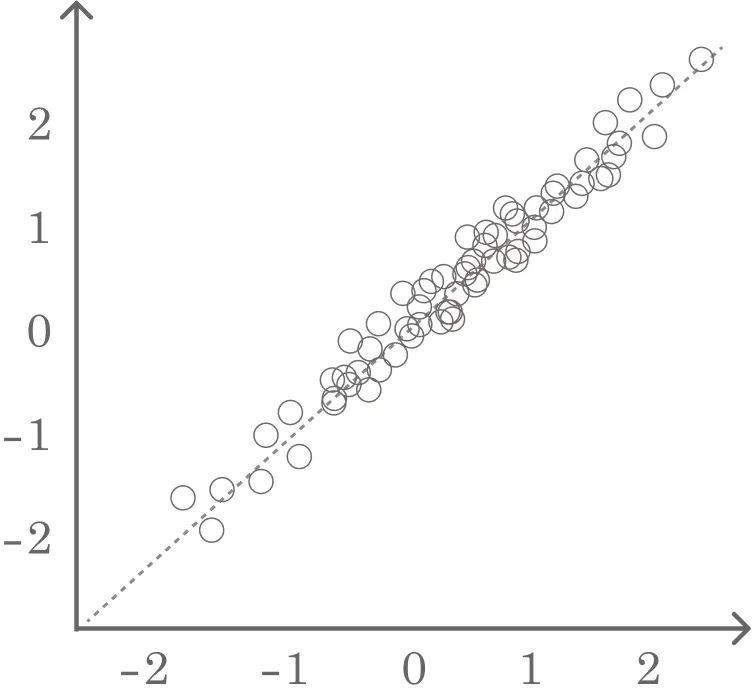
- 변수들이 일정한 경향성을 띤다는 것은 그 변수들이 일정한 인과관계를 갖고 있다고 추측할 수 있다. 산점도를 봤을 때 일정한 추세선이 나타난다면, 경향성을 가지거나 혹은 변수들 간에 인과관계가 존재한다고 생각할 수 있다.
회귀분석의 종류
단순회귀, 다중회귀, 다항회귀, 로지스틱 회귀, 비선형 회귀가 있다.

회귀분석의 가정
회귀분석은 4가지 가정 사항을 전제로 분석을 수행할 수 있습니다.
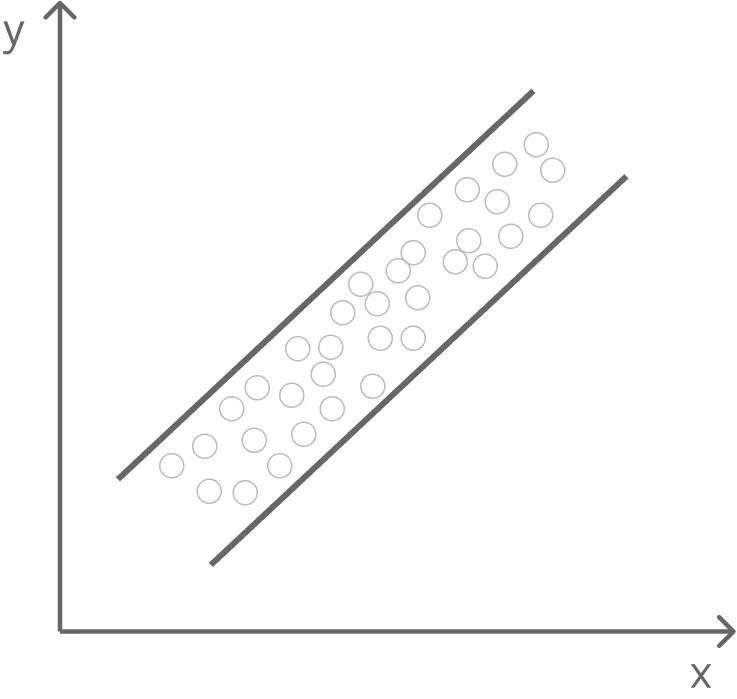
1. 선형성
입력변수와 출력변수의 관계가 선형이다.
- 예외적으로 2차 함수 회귀선을 갖는 다항회귀분석의 경우, 선형성을 갖지 않아도 된다.
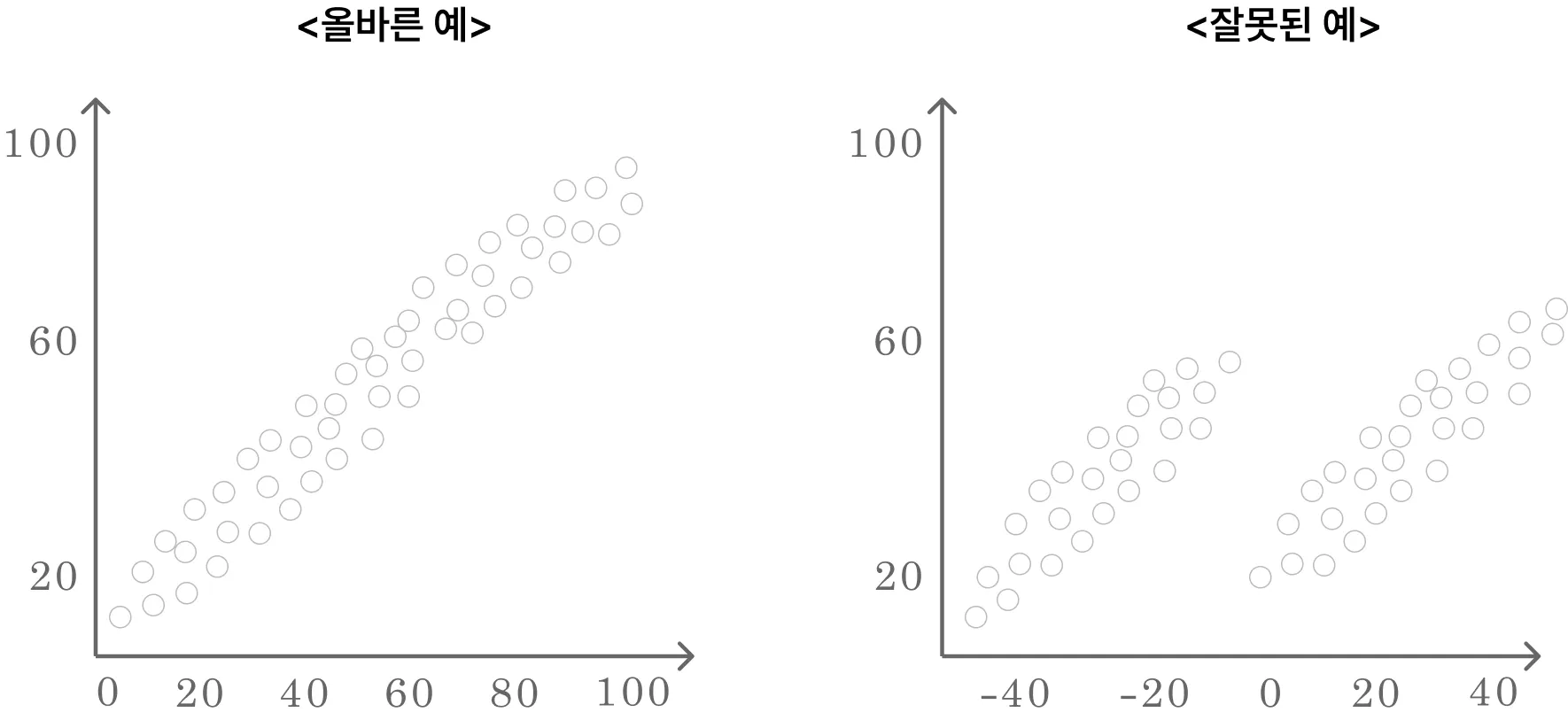
2. 독립성
잔차와 독립변수의 값이 서로 독립이어야 한다.
- 독립변수가 여러 개인 다중회귀분석의 경우에는 독립변수들 간에 상관성이 없이 독립이어야 한다.
- 상관성이 존재하는 경우 다중공선성이라고 하며, 이를 제거하고 회귀분석을 수행해야 한다.
- 독립성을 알아보기 위해 Durbin-Waston 통계량을 사용하며 주로 시계열 데이터에서 많이 활용한다.
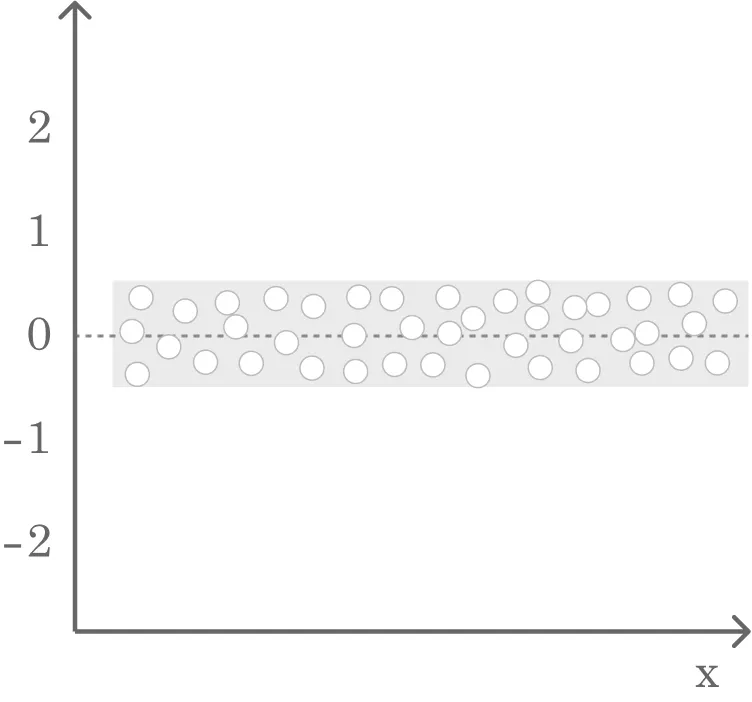
3. 등분산성
모든 독립 변수 값에 대한 오차 항의 분산이 일정하다는 가정
- 잔차플롯(산점도)을 활용하여 잔차와 입력변수간에 아무런 관련성이 없게 무작위적으로 고루 분포되어야 등분산성 가정을 만족하게 된다.
등분산성을 만족하는 경우
등분산성을 만족하지 못하는 경우
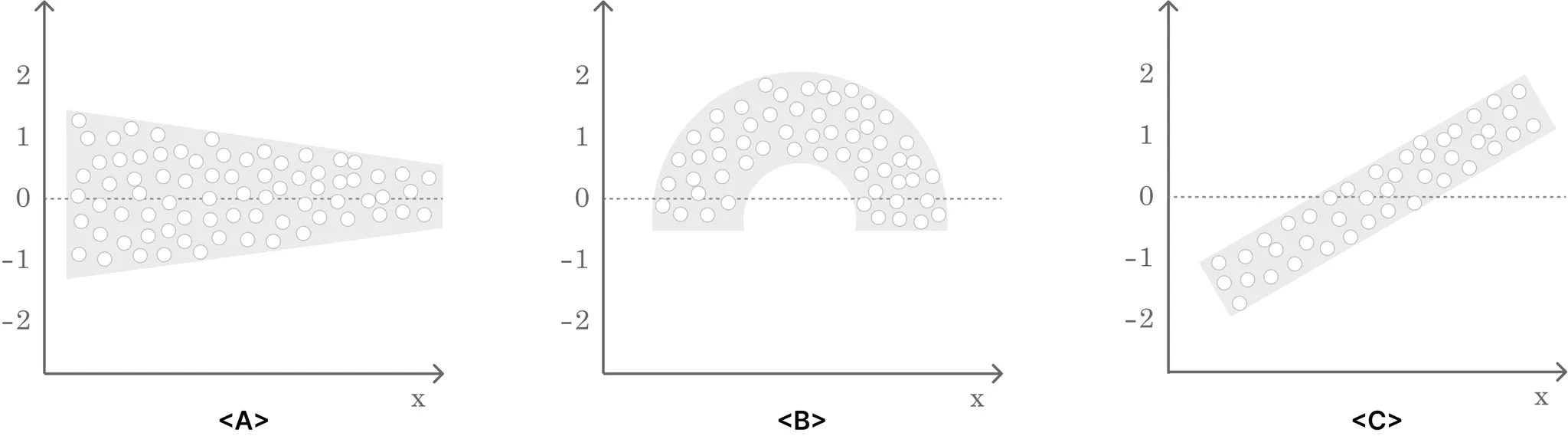
- A : 설명변수(x)가 커질수록 잔차의 분산이 줄어드는 이분산의 형태
- B : 2차항 설명변수 필요
- C : 새로운 설명변수 필요
4. 정규성
Q-Q Plot을 출력했을 때, 잔차가 대각방향의 직선의 형태를 지니고 있으면 정규분포를 따른다고 할 수 있다.
5. 비상관성 (추가사항)
관측치들의 잔차들끼리 상관이 없어야 한다
연습문제
1번
회귀분석에 대한 설명으로 옳지 않은 것은?
1. 하나 이상의 독립변수들이 종속변수에 얼마나 영향을 미치는지 추정하는 통계기법
2. 하나 이상의 설명변수들이 결과변수에 얼마나 영향을 미치는지 추정하는 통계기법
3. 독립변수가 범주형 변수인 경우 로지스틱 회귀분석을 사용한다
4. 변수들이 일정한 경향성을 띤다는 것은 그 변수들이 일정한 인과관계를 갖고 있다고 추측할 수 있다
정답
독립변수와 종속변수는 모두 연속형 변수일 때 사용 가능하며, 종속변수가 범주형 변수인 경우에 대해서는 로지스틱 회귀분석을 사용한다.
2번
데이터의 정규성을 확인하기 위해 사용하는 방법으로 옳지 않은 것은?
1. Q-Q plot
2. Durbin-Waston
3. 히스토그램
4. Shaprio-Wilk
정답
Durbin-Waston 통계량은 독립성을 알아보기 위해 사용한다.
3번
회귀분석의 4가지 가정 사항으로 옳지 않은 것은?
1. 비선형성
2. 등분산성
3. 독립성
4. 정규성
정답
회귀분석 4가지 가정 사항으로는 선형성, 등분산성, 독립성, 정규성이 있다.
9.2. 단순 / 다중선형회귀분석
단순선형회귀분석
단순선형회귀분석
하나의 독립 변수와 하나의 종속 변수 간의 선형 관계를 분석하는 통계기법
- : 번째 종속변수 값
- : 번째 독립변수 값
- : 선형 회귀식의 절편
- : 선형 회귀식의 기울기
- : 오차항
회귀분석에서의 검토사항
- 모형이 통계적으로 유의미한가?
F통계량을 확인한다. 유의수준 5% 하에서 F통계량의 p-값이 0.05보다 작으면 추정된 회귀식은 통계적으로 유의하다고 볼 수 있다.
- 회귀계수들이 유의미한가?
해당 계수의 t-통계량의 p-값 또는 이들의 신뢰구간을 확인한다.
- 모형이 얼마나 설명력을 갖는가?
- 결정계수를 확인한다. 결정계수는 0에서 1값을 가지며, 높은 값을 가질수록 추정된 회귀식의 설명력이 높다.
- 회귀모형의 설명력이 좋다는 의미는 데이터들의 분포가 회귀선에 밀접하게 분포하고 있다는 의미이다.
- 결정계수 를 구하는 공식
결정계수는 회귀 모델이 주어진 데이터를 얼마나 잘 설명하는지를 나타내는 통계적 측도이다.
- 모형이 데이터를 잘 적합하고 있는가?
잔차를 그래프로 그리고 회귀진단을 한다
최소제곱법으로 회귀계수의 추정
최소제곱법은 회귀 분석에서 사용되는 통계적 방법으로, 모델의 파라미터를 추정하는데 사용된다. 주로 단순선형회귀나 다중선형회귀에서 모델 파라미터를 추정하는 데에 적용된다.
- 최소제곱법을 사용하면 모델이 실제 데이터와 얼마나 잘 맞는지를 나타내는 적합도를 최대화하는 회귀 계수를 찾을 수 있다.
- 측정값을 기초로 하여 적당한 제곱합을 만들고 그것을 최소로 하는 값을 구하여 측정결과를 처리하는 방법으로 잔차제곱이 가장 작은 선을 구하는 것을 의미한다.
결정계수
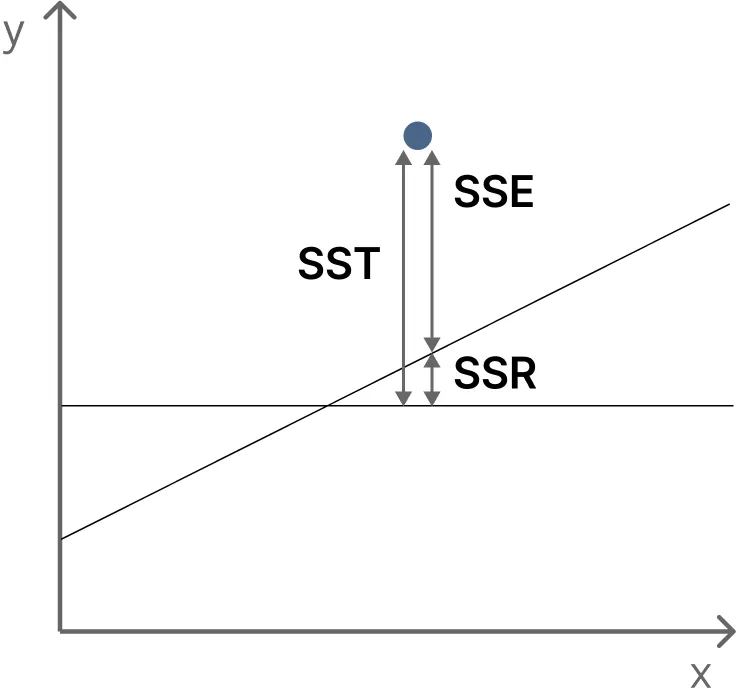
- 전체제곱합 (SST) :
- 회귀제곱합 (SSR) :
- 오차제곱합
- 결정계수()는 전체 제곱합에서 회귀제곱합의 비율(SSR/SST), (여기서 SST=SSR=SSE)
- 결정계수()는 전체 데이터를 회귀모형이 설명할 수 있는 설명력을 의미한다.
회귀직선의 적합도 검토
결정계수()를 통해 추정된 회귀식이 얼마나 타당한지 검토한다. 독립변수가 종속변수 변동의 몇 %를 설명하는지 나타내는 지표이다.
- 다변량 회귀분석에서는 독립변수의 수가 많아지면 결정계수()가 높아지므로 독립변수가 유의하든, 유의하지 않든 독립변수의 수가 많아지면 결정계수가 높아지는 단점이 있다.
- 결정계수의 단점을 보완하기 위해 수정된 결정계수( : adjusted ) 를 활용한다. 수정된 결정계수는 결정계수보다 작은 값으로 산출되는 특징이 있다.
- k : 독립변수 개수, n : 데이터의 개수단순선형회귀분석 예제
쌍으로 묶인 관찰들 인 두 벡터 x와 y를 생성하고, x와 y사이에 선형관계가 있다고 가정하고 lm()함수를 이용해 단순선형회귀분석 해보기
> set.seed(2)
> x=runif (10,0,11)
> y=2 + 3*x + rnorm(10,0,0.2)
> dfrm=data.frame (x, y )
> dfrm
x y
1 2.033705 8.127599
2 7.726114 25.319934
3 6.306590 20.871829
4 1.848571 7.942608
5 10.382233 33.118941
6 10.378225 33.218204
7 1.420749 6.458597
8 9.167937 29.425272
9 5.148204 17.236677
10 6.049821 20.505909
> lm(y~x, data=dfrm)
Call:
lm(formula = y ~ x, data = dfrm)
Coefficients:
(Intercept) x
2.213 2.979
# 이 경우 회귀방정식은 y=2.213 + 2.979x로 추정된다.식이요법 방법을 적용한 닭에 대한 데이터로 두번째 예제 실습해보기
> library(MASS)
> head(ChickWeight)
weight Time Chick Diet
1 42 0 1 1
2 51 2 1 1
3 59 4 1 1
4 64 6 1 1
5 76 8 1 1
6 93 10 1 1
# 1번 닭에게 식이요법 방법 1을 적용한 데이터만 조회하여 chick 변수에 할당한다.
> Chick <- ChickWeight[ChickWeight$Diet==1,]
> Chick
weight Time Chick Diet
1 42 0 1 1
2 51 2 1 1
3 59 4 1 1
... (중략)
217 98 16 20 1
218 107 18 20 1
219 115 20 20 1
220 117 21 20 1
# chick 데이터세트에서 1번 닭만 조회한다.
> Chick <-ChickWeight[ChickWeight$Chick==1,]
> Chick
weight Time Chick Diet
1 42 0 1 1
2 51 2 1 1
3 59 4 1 1
4 64 6 1 1
5 76 8 1 1
6 93 10 1 1
7 106 12 1 1
8 125 14 1 1
9 149 16 1 1
10 171 18 1 1
11 199 20 1 1
12 205 21 1 1
# 시간의 경과에 따른 닭들의 몸무게를 단순회귀분석을 해본다.
> lm(weight~Time, data=Chick)
Call:
lm(formula = weight ~ Time, data = Chick)
Coefficients:
(Intercept) Time
24.465 7.988
# 여기서 회기식은 weight=7.988Time+24.465로 추정된다.
> summary(lm(weight~Time, data=Chick))
Call:
lm(formula = weight ~ Time, data = Chick)
Residuals:
Min 1Q Median 3Q Max
-14.3202 -11.3081 -0.3444 11.1162 17.5346
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 24.4654 6.7279 3.636 0.00456 **
Time 7.9879 0.5236 15.255 2.97e-08 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 12.29 on 10 degrees of freedom
Multiple R-squared: 0.9588, Adjusted R-squared: 0.9547
F-statistic: 232.7 on 1 and 10 DF, p-value: 2.974e-08F통계량 = 232.7이며 p-값이 2.974e-08로 유의수준 5% 이하에서 추정된 회귀 모형이 통계적으로 매우 유의함을 볼 수 있다. 결정계수 또한 0.9588로 매우 높은 값을 보이므로 이 회귀식이 데이터를 96% 정도로 설명하고 있음을 알 수 있다. 또한 회귀계수들의 p-값들도 0.05보다 매우 작으므로 회귀계수의 추정치들이 통계적으로 매우 유의하다. Time에 대한 회귀계수가 7.99 이므로 Time이 1 증가할 때 weight 가 7.99 만큼 증가한다고 해석할 수 있다.
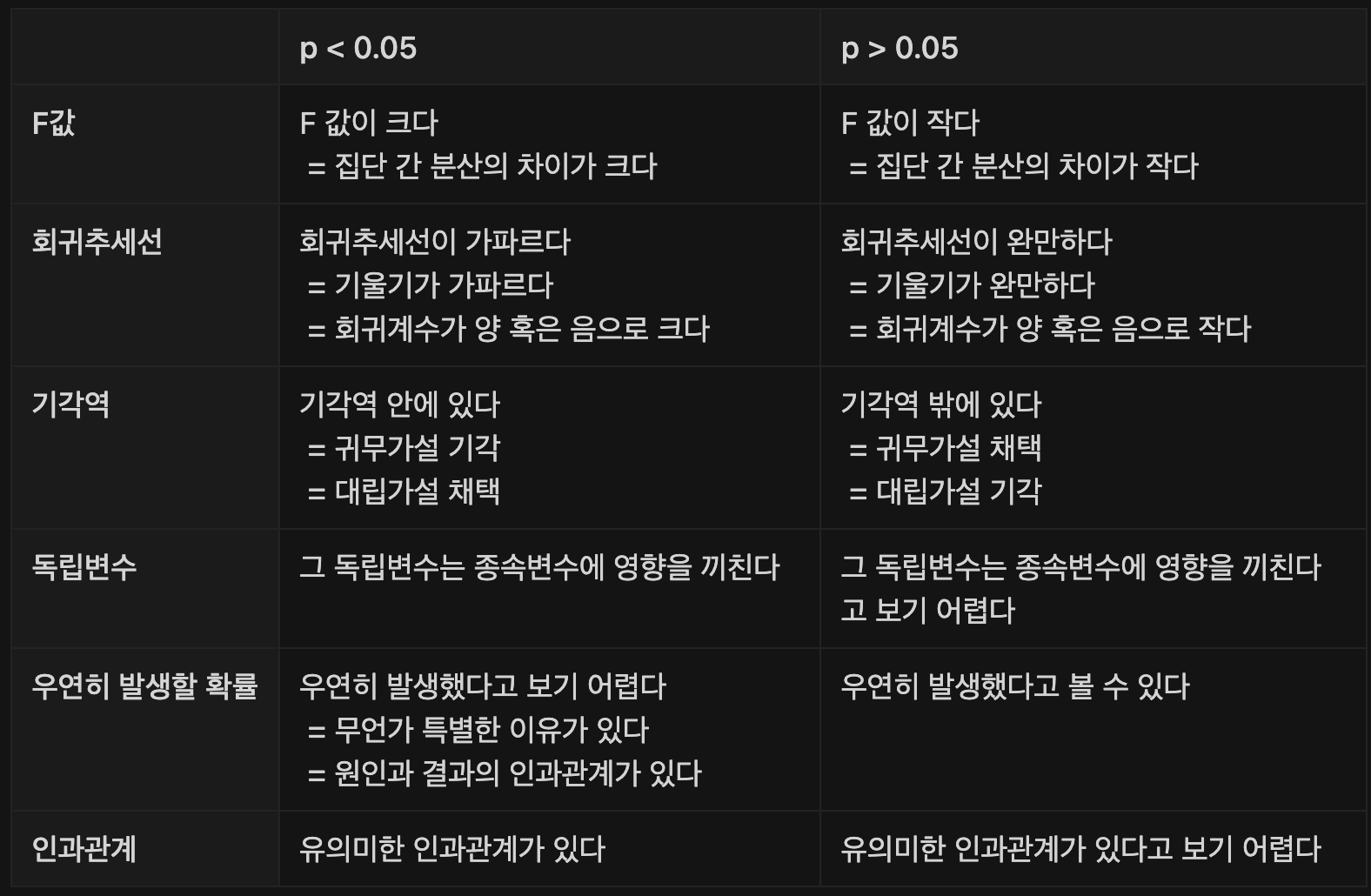
참고하면 좋을 P값 정리표 👀
다중선형회귀분석
다중선형회귀분석이란
2개 이상의 독립변수에 대하여 종속변수의 관계를 수치적으로 파악하기 위한 기법
- 실제 데이터와 오차가 가장 작아지는 회귀 방정식을 찾기 위해 최소 제곱법을 활용
다중공선성
다중선형회귀분석에서 사용된 독립 변수들 간에 강한 상관관계가 나타나는 현상
- 다중공선성은 일반적으로 독립 변수들 간의 높은 상관관계로 인해 회귀 모델의 안정성이나 해석이 어려워지는 문제를 일으킬 수 있다.
- 독립변수가 1개인 단순선형회귀분석에서는 문제가 안 되지만 독립변수가 2개 이상인 다중선형회귀분석에서는 다중공선성에 유의해야 한다.
다중공선성 진단
결정계수 값이 커서 회귀식의 설명력은 높지만 각 독립변수의 p-value 값이 커서 개별 인자가 유의하지 않은 경우 다중공선성을 의심할 수 있다.
- 독립 변수들 간의 상관계수를 나타내는 공분산 행렬을 확인한다.
- 분산팽창요인 (VIF, Variance Inflation Factor)을 구해 이 값이 10을 넘는다면 보통 다중공선성이 있다고 판단하며, 30보다 크면 심각한 문제가 있다고 해석할 수 있다.- VIF는 각 독립 변수가 다른 독립 변수들과 얼마나 강하게 상관되어 있는지를 측정하는 지표이다.
다중공선성 문제 해결법
- 다중공선성 진단 후에는 필요한 경우 변수를 삭제하거나 변환하여 다중공선성을 완화할 필요가 있다. (주성분회귀, 능형회귀 모형을 적용하여 문제를 해결한다)
- 주성분분석(PCA)을 통해 변수의 차원을 축소한다.
(=원래 데이터가 가진 내재적 속성을 보존하면서 데이터를 축소하는 방법) - R에서 ‘스크리 산점도(Scree plot)’를 사용해 주성분 개수를 선택한다.
- 선형판별분석(LDA)으로 차원을 축소한다.
LDA는 지도학습으로 데이터의 분포를 학습하여 결정경계를 만들어 데이터를 분류한다. - t-분포 확률적 임베딩(t-SNE)으로 차원을 축소한다.
- 특잇값 분해(SVD)로 차원을 축소한다. PCA와 유사한 행렬 분해 기법을 사용하지만, PCA와 달리 행과 열의 크기를 다른 어떤 행렬에도 적용할 수 있다는 이점이 있다.
다중선형회귀분석의 예제연습문제
여러 개의 독립변수(u,v,w)와 하나의 반응변수(y)를 생성하고 ,이들 간에 선형관계가 있다고 생각하며, 데이터에 다중선형회귀 실시해보기!
> set.seed(2)
> u=runif(10,0, 11)
> v=runif (10, 11,20)
> w=runif(10,1,30)
> y=3 + 0.1*u + 2*v -3*w + rnorm(10,0,0.1)
> dfrm=data.frame (y,u,v,w)
> dfrm
y u v w
1 -25.6647952 2.033705 15.97407 20.195064
2 -6.5562326 7.726114 13.15005 12.238937
3 -36.4858791 6.306590 17.84462 25.269786
4 12.4472764 1.848571 12.62738 5.364542
5 0.1638434 10.382233 14.64754 11.070895
6 -3.9124946 10.378225 18.68194 15.174424
7 26.6127780 1.420749 19.78759 5.328159
8 -3.9238295 9.167937 13.03243 11.354815
9 -53.0331805 5.148204 15.00328 28.916677
10 12.4387413 6.049821 11.67481 4.838788
> m<-lm(y~u+v+w)
> m
Call:
lm(formula = y ~ u + v + w)
Coefficients:
(Intercept) u v w
3.0417 0.1232 1.9890 -2.9978
# 이 경우 회귀식은 y=3.0417+0.1232u+1.9890v-2.9978w로 추정된다.
> summary(m)
Call:
lm(formula = y ~ u + v + w)
Residuals:
Min 1Q Median 3Q Max
-0.188562 -0.058632 -0.002013 0.080024 0.143757
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 3.041653 0.264808 11.486 2.62e-05 ***
u 0.123173 0.012841 9.592 7.34e-05 ***
v 1.989017 0.016586 119.923 2.27e-11 ***
w -2.997816 0.005421 -552.981 2.36e-15 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.1303 on 6 degrees of freedom
Multiple R-squared: 1, Adjusted R-squared: 1
F-statistic: 1.038e+05 on 3 and 6 DF, p-value: 1.564e-14F통계량 = 1.038e+05이며 p-값이 1.564e-14로 유의수준 5% 하에서 추정된 회귀 모형이 통계적으로 매우 유의함을 볼 수 있다. 결정계수와 수정된 결정계수 모두 1로 이 회귀식이 데이터를 매우 잘 설명하고 있음을 알 수 있다. 또한 회귀계수 u, v, w들의 p-값들도 0.01보다 작으므로 회귀계수의 추정치들이 통계적으로 유의하다.
연습문제
1번
아래 보기에서 설명하는 것으로 옳은 것은?
<보기>
- 회귀 분석에서 사용되는 통계적 방법으로, 모델의 파라미터를 추정하는데 사용된다.
- 측정값을 기초로 하여 적당한 제곱합을 만들고 그것을 최소로 하는 값을 구하여 측정결과를 처리하는 방법으로 잔차제곱이 가장 작은 선을 구하는 것을 의미한다
- 최소제곱법
- 결정계수
- 독립변수
- 다중공선성
정답
위 설명은 최소제곱법에 대한 설명이다
2번
다중공선성 문제 해결법으로 옳지 않은 것은?
1. 결정계수()를 통해 추정된 회귀식이 얼마나 타당한지 검토한다.
2. 선형판별분석(LDA)으로 차원을 축소한다.
3. 주성분분석(PCA)을 통해 변수의 차원을 축소한다.
4. t-분포 확률적 임베딩(t-SNE)으로 차원을 축소한다.
정답
1번의 내용은 회귀직선의 적합도 검토에 대한 내용이다.
3번
회귀분석에서의 검토사항으로 옳지 않은 것은?
1. 모형이 통계적으로 유의미한가?
2. 회귀계수들이 유의미한가?
3. 모형의 데이터가 얼마나 밀집되어 있는가?
4. 모형이 얼마나 설명력을 갖는가?
정답
3번은 회귀분석에서의 검토사항에 해당되지 않는 내용이다.
9.3. 최적 회귀방식과 고급 회귀분석
최적 회귀방정식
최적 회귀방정식 개념
여러개의 독립변수가 있을 때 종속변수를 설명하기 가장 좋은 독립변수를 선택하고 최적의 회귀방정식을 찾는 것이 목표이다. 보통 모델 성능을 향상시키기 위해 사용한다.
최적회귀방정식의 선택
설명변수 선택
필요한 변수만 상황에 따라 타협을 통해 선택한다.
- y에 영향을 미칠 수 있는 모든 설명변수 x들을 y의 값을 예측하는데 참여시킨다.
- 데이터에 설명변수 x들의 수가 많아지면 관리하는데 많은 노력이 필요하므로, 가능한 범위 내에서 적은 수의 설명변수를 포함한다.
모형선택
분석 데이터에 가장 잘 맞는 모형을 찾아내는 방법이다.
- 모든 가능한 조합의 회귀분석(All Possible Regresstion) : 모든 가능한 독립변수들의 조합에 대한 회귀모형을 생성한 뒤 가장 적합한 회귀모형을 선택한다.
단계적 변수선택
일정한 단계를 거치면서 변수를 추가하거나 제거하는 방식으로 최적의 회귀방정식을 도출하는 방식으로 전진선택법, 후진제거법, 단계선택법이 있다.
단계적 변수선택법(중)
전진선택법 (Forward Selection)
- 절편만 있는 상수모형으로부터 시작해 중요하다고 생각되는 설명변수부터 차례로 모형에 추가한다.
- 전진선택법은 이해하기 쉽고 변수의 개수가 많은 경우에도 사용 가능하다. 하지만 변수값의 작은 변동에도 그 결과가 크게 달라져 안정성이 부족한 단점이 있다.
- 상관계수의 절댓값이 가장 큰 변수에 대해 부분 F 검정으로 유의성 검정을 하고 더는 유의하지 않은 경우 해당 변수부터는 더 이상 변수를 추가하지 않는다.
후진제거법 (Backward Elimination)
- 독립변수 후보 모두를 포함한 모형에서 출발해 가장 적은 영향을 주는 변수부터 하나씩 제거하면서 더 이상 제거할 변수가 없을 때의 모형을 선택한다.
- 전진 선택법과 반대로 상관계수의 절댓값이 가장 작은 변수에 대해 부분 F 검정을 실시한다. 검정 결과가 가장 적은 영향을 주는 변수(=유의하지 않는 변수=p-value가 큰 변수)부터 하나씩 제거한다.
- 후진제거법은 전체 변수들의 정보를 이용하는 장점이 있는 반면 변수의 개수가 많은 경우 사용하기 어렵다.
단계선택법 (Stepwise Method)
전진선택법과 후진 제거법을 보완한 방법이다.
- 전진선택법에 의해 변수를 추가하면서 새롭게 추가된 변수에 기인해 기존 변수의 중요도가 약화되면 해당 변수를 제거하는 등 단계별로 추가 또는 제거되는 변수의 여부를 검토해 더 이상 없을 때 중단한다.
변수 선택에 사용되는 성능지표(중)
벌점화 방식
모형의 복잡도에 벌점을 주는 방법으로 AIC 방법과 BIC 방법이 주로 사용되며, 두 벌점 모두 편향과 분산이 최적이 되는 균형점을 제안해준다.
- 패널티가 적은 회귀모형이 좋은 회귀모형이라고 할 수 있다.
AIC (Akaike Information Criteria : 아카이케 정보 기준)
모델의 상대적인 품질을 측정하는 통계적 평가 지표 중 하나이다.
- 일반적으로 회귀분석에서 Model Selection할 때 많이 쓰이는 지표다.
- L(θ)는 가능도 함수, 는 모수의 최대 가능도 추정량, k는 모형의 모수 개수
BIC (Bayes Information Criteria : 베이즈 정보 기준)
AIC의 단점인 표본(n)이 커질 때 부정확하다는 단점을 보완한 지표이다.
- BIC는 복잡한 모델에 더 많은 페널티를 부여하므로, 더 간단하면서도 데이터를 잘 설명하는 모델을 선호한다. 또한 BIC는 샘플 크기에 따라 페널티를 조절하여 모델 선택에 더 안정성을 부여한다.
- L(θ)는 가능도 함수, 는 모수의 최대 가능도 추정량, k는 모형의 모수 개수, n은 자료의 개수
최적회귀방정식 실습
후진제거법 이용
Y를 반응변수로 하고, X1, X2, X3, X4를 설명변수로 하는 선형회귀모형을 고려하여 진행하기
> X1 <- c(7,1,11,11,7,11,3,1,2,21,1,11,10)
> X2 <- c(26,29,56,31,52,55,71,31,54,47,40,66,68)
> X3 <- c(6,15,8,8,6,9,17,22,18,4,23,9,8)
> X4 <- c(60,52,20,47,33,22,6,44,22,26,34,12,12)
> Y <- c(78.5,74.3,104.3,87.6,95.9,109.2,102.7,72.5,93.1,115.9,83.8,113.3,109.4)
> df <- data.frame(X1,X2,X3,X4,Y)
> head(df)
X1 X2 X3 X4 Y
1 7 26 6 60 78.5
2 1 29 15 52 74.3
3 11 56 8 20 104.3
4 11 31 8 47 87.6
5 7 52 6 33 95.9
6 11 55 9 22 109.2
> a <- lm(Y~X1+X2+X3+X4, data=df)
> a
Call:
lm(formula = Y ~ X1 + X2 + X3 + X4, data = df)
Coefficients:
(Intercept) X1 X2 X3 X4
62.4054 1.5511 0.5102 0.1019 -0.1441
> summary(a)
Call:
lm(formula = Y ~ X1 + X2 + X3 + X4, data = df)
Residuals:
Min 1Q Median 3Q Max
-3.1750 -1.6709 0.2508 1.3783 3.9254
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 62.4054 70.0710 0.891 0.3991
X1 1.5511 0.7448 2.083 0.0708
X2 0.5102 0.7238 0.705 0.5009
X3 0.1019 0.7547 0.135 0.8959
X4 -0.1441 0.7091 -0.203 0.8441
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 2.446 on 8 degrees of freedom
Multiple R-squared: 0.9824, Adjusted R-squared: 0.9736
F-statistic: 111.5 on 4 and 8 DF, p-value: 4.756e-07회귀식은 Y= 62.4054+ 1.5511X1 + 0.5102X2 + 0.1019X3 - 0.1441X4로 추정된다. 여기서 F통계량= 111.5이며 p-값이 0.00000047564로 유의수준 5% 하에서 추정된 회귀 모형이 통계적으로 매우 유의함을 볼 수 있다. 수정된 결정계수 또한 0.9736으로 매우 높은 값을 보이므로 추정된 회귀식이 데이터를 97%로 적절하게 설명하고 있음을 알 수 있다. 설명변수 X1, X2, X3, X4의 p-value를 보면 X3의 유의 확률이 가장 높아 이들 중 가장 유의하지 않음을 볼 수 있다. 설명변수 X3을 제거하고 다시 회귀분석을 한다.
참고
부동소수점 : 컴퓨터에서 실수를 표시하는 방법으로 (가수)(밑수)^(지수)와 같은 형태로 표현(가수는 유효숫자, 지수는 소수점 위치를 나타냄)
| 부동소수점 | 가수 | (밑수)^(지수) | 값 |
|---|---|---|---|
| 1e+02 | 1 | 10^(2) | 100 |
| 1e+01 | 1 | 10^(1) | 10 |
| 1e+00 | 1 | 10^(0) | 1 |
| 1e-01 | 1 | 10^(-1) | 0.1 |
| 1e-02 | 1 | 10^(-2) | 0.01 |
- 예를 들어, 0.312e+02는 0.312 x 10^(2)=0.312 x 100=31.2를 의미하고,
4.756e-07은 4.756 x 10^(-7)=4.756 x 0.0000001=0.00004756을 의미한다.
전진선택법 이용
step 함수를 사용하여 전진선택법을 적용해보기
step 함수
step(lm(종속변수~설명변수,데이터세트),scope=list(lower=~1,upper=~설명변수),drection=”변수선택방법”)
- lm : 우리가 사용할 분석방법은 회귀분석인 것을 인지시켜준다.
- scope : 분석할 때 고려할 변수의 범위를 정한다. 가장 낮은 단계는 lower에서 1을 입력하면 상수항을 의미하고, 1가장 높은 단계를 설정하기 위해서는 설명변수들을 모두 써주면 된다.
- direction : 변수 선택방법으로, 선택 가능한 옵션은 forward, backward, both가 있다.
> step(lm(Y~1,data=df), scope=list(lower=~1, upper=~X1+X2+X3+X4), direction="forward")
Start: AIC=71.44
Y ~ 1
Df Sum of Sq RSS AIC
+ X4 1 1831.90 883.87 58.852
+ X2 1 1809.43 906.34 59.178
+ X1 1 1450.08 1265.69 63.519
+ X3 1 776.36 1939.40 69.067
<none> 2715.76 71.444
Step: AIC=58.85
Y ~ X4
Df Sum of Sq RSS AIC
+ X1 1 809.10 74.76 28.742
+ X3 1 708.13 175.74 39.853
<none> 883.87 58.852
+ X2 1 14.99 868.88 60.629
Step: AIC=28.74
Y ~ X4 + X1
Df Sum of Sq RSS AIC
+ X2 1 26.789 47.973 24.974
+ X3 1 23.926 50.836 25.728
<none> 74.762 28.742
Step: AIC=24.97
Y ~ X4 + X1 + X2
Df Sum of Sq RSS AIC
<none> 47.973 24.974
+ X3 1 0.10909 47.864 26.944
Call:
lm(formula = Y ~ X4 + X1 + X2, data = df)
Coefficients:
(Intercept) X4 X1 X2
71.6483 -0.2365 1.4519 0.4161최종회귀식은 Y= 71.6483 - 0.2365X4 + 1.4519X1 + 0.4161X2로 추정된다. 앞의 후진선택법의 결과와 다른 모형이 선택되었다. 보통 변수선택의 기준에 따라 선택된 모형은 차이를 보일 수 있다.
단계적 방법
위의 자료와 모형에 대해 단계적 방법을 적용하여 모형 선택해보기
> df
X1 X2 X3 X4 Y
1 7 26 6 60 78.5
2 1 29 15 52 74.3
3 11 56 8 20 104.3
4 11 31 8 47 87.6
5 7 52 6 33 95.9
6 11 55 9 22 109.2
7 3 71 17 6 102.7
8 1 31 22 44 72.5
9 2 54 18 22 93.1
10 21 47 4 26 115.9
11 1 40 23 34 83.8
12 11 66 9 12 113.3
13 10 68 8 12 109.4
> step(lm(Y~1,data=df), scope=list (lower=~1, upper=~X1+X2+X3+X4), direction="both")
Start: AIC=71.44
Y ~ 1
Df Sum of Sq RSS AIC
+ X4 1 1831.90 883.87 58.852
+ X2 1 1809.43 906.34 59.178
+ X1 1 1450.08 1265.69 63.519
+ X3 1 776.36 1939.40 69.067
<none> 2715.76 71.444
Step: AIC=58.85
Y ~ X4
Df Sum of Sq RSS AIC
+ X1 1 809.10 74.76 28.742
+ X3 1 708.13 175.74 39.853
<none> 883.87 58.852
+ X2 1 14.99 868.88 60.629
- X4 1 1831.90 2715.76 71.444
Step: AIC=28.74
Y ~ X4 + X1
Df Sum of Sq RSS AIC
+ X2 1 26.79 47.97 24.974
+ X3 1 23.93 50.84 25.728
<none> 74.76 28.742
- X1 1 809.10 883.87 58.852
- X4 1 1190.92 1265.69 63.519
Step: AIC=24.97
Y ~ X4 + X1 + X2
Df Sum of Sq RSS AIC
<none> 47.97 24.974
- X4 1 9.93 57.90 25.420
+ X3 1 0.11 47.86 26.944
- X2 1 26.79 74.76 28.742
- X1 1 820.91 868.88 60.629
Call:
lm(formula = Y ~ X4 + X1 + X2, data = df)
Coefficients:
(Intercept) X4 X1 X2
71.6483 -0.2365 1.4519 0.4161최종 회귀모형은 Y = 71.6483 - 0.2365X4+1.4519X1 + 0.4161X2로 추정된다.
고급 회귀분석
정규화 선형회귀
정규화 선형회귀
모델이 과도하게 최적화되는 현상(과적합,Overfitting)을 막는 방법
- 모형이 과적합되면 계수의 크기도 과도하게 증가하는 경향이 있다. 따라서 정규화 선형회귀에서는 계수의 크기를 제한하는 방법으로 제약조건을 추가한다.
- 정규화 선형회귀에는 제약 조건의 종류에 따라 릿지, 라쏘, 엘라스틱넷 회귀모형이 사용된다.
과적합과 과소적합
과적합은 모델이 학습 데이터를 과하게 학습하는 것을 의미한다.
- 일반적으로 학습 데이터에 과적합되면 일반화 성능이 낮아져 이미 학습한 훈련용 데이터에 대한 성능은 높게 나오지만, 아직 학습하지 않은 테스트 데이터에 대한 성능은 낮게 나온다. 그 이유는 모델이 학습 데이터에 너무 과하게 맞춰져서 새로운 데이터에 일반화하기 어렵기 때문이다.
- 반대로 모델이 너무 단순해서 학습 데이터조차 제대로 예측하지 못하는 경우를 과소적합(underfitting)이라고 한다.
정규화 선형회귀의 종류
라쏘 (Lasso Regression)
- 가중치들의 절댓값의 합을 최소화하는 것을 제약조건으로 추가하는 기법
- 라쏘회귀에선 일정한 상숫값이 페널티로 부여되어 일부 불필요한 가중치 파라미터를 0으로 만들어 분석에서 아예 제외시킨다. 몇 개의 의미 있는 변수만 분석에 포함시키고 싶을 때 효과적인 방법이다.
- 라쏘회귀에서 사용하는 규제 방식을 L1 규제라고 한다.
릿지 (Ridge Regression)
- 가중치들의 제곱합을 최소화하는 것을 제약 조건으로 추가하는 기법
- 능형 회귀모형이라고도 부른다.
- 일부 가중치 파라미터를 제한하지만, 완전히 0으로 만들지는 않고 0에 가깝게 만든다.
- 릿지 회귀는 매우 크거나 작은 이상치의 가중치를 0에 가깝게 유도함으로써 선형 모델의 일반화 성능을 개선하는 데 사용할 수 있다.
- 릿지회귀에서 사용하는 규제 방식을 L2 규제라고도 한다.
엘라스틱넷 (Elastic Net)
라쏘와 릿지를 결합한 모델이다.
- 가중치 절댓값의 합과 제곱합을 동시에 제약조건으로 가지는 모형이다.
일반화 선형회귀
일반화 선형회귀
선형 회귀 분석을 일반화하여 다양한 종속 변수 분포와 관련된 모델링을 수행하는 통계적 방법
- 종속변수가 범주형 자료이거나 정규성을 만족하지 못하는 경우 그 종속변수를 적절한 함수 f(x)로 정의한 다음, 이 함수 f(x)와 독립변수를 선형 결합하여 회귀분석을 수행할 수 있다.
일반화 선형회귀의 구성요소
- 확률 요소 : 종속변수의 확률분포를 규정하는 성분
- 선형 예측자 : 종속변수의 기댓값을 정의하는 독립변수들 간의 선형 결합
- 연결 함수 : 확률 요소와 선형예측자를 연결하는 함수
일반화 선형회귀의 종류
- 로지스틱 회귀
- 종속변수가 범주형 변수(0 또는 1, 합격/불합격 등)인 경우로 의학연구에 많이 사용된다.
- 독립변수에 의해 종속변수의 범주로 분류화 한다는 것이 선형 회귀 분석과의 차이점이며 따라서 분류 분석 방법으로 설명한다.
- 포아송 회귀
- 종속변수가 특정 시간 동안 발생한 사건의 건수에 대한 도수 자료(음수가 아닌 정수)인 경우이면서, 종속변수가 정규분포를 따르지 않거나 등분산성을 만족하지 못하는 경우에 포아송 회귀분석이 사용된다.
- 선형회귀모형이 최소제곱법으로 모수를 추정한다면 포아송 회귀모형은 최대 가능도 추정을 통해 모수를 추정한다.
더빈 왓슨 검정
회귀 분석의 주요한 가정 중 오차항이 독립성을 만족하는지를 검정하기 위해서는 더빈 왓슨(Durbin-Watson) 검정을 수행한다
- 더빈 왓슨 통계량의 값이 0에 가까울수록 양의 상관관계가 있음을 의미하고, 4에 가까울수록 음의 상관관계가 있음을 의미한다. 따라서 더빈 왓슨 통계량이 0 혹은 4에 가까울 경우 잔차들 간의 상관관계가 있어서 회귀식이 부적합함을 의미한다.
연습문제
1번
최적회귀방정식을 선택법 중, 단계적 변수 선택법으로 적절하지 않은 것은?
1. 단계선택법
2. 모형선택법
3. 후진제거법
4. 전진선택법
정답
단계적 변수선택으로는 전진선택법, 후진제거법, 단계선택법이 있다
2번
아래 보기에서 설명하는 정규화 선형회귀의 종류로 옳은 것은?
<보기>
가중치들의 절댓값의 합을 최소화하는 것을 제약조건으로 추가하는 기법으로 몇 개의 의미 있는 변수만 분석에 포함시키고 싶을 때 효과적인 방법이다.
정답
보기의 설명은 라쏘회귀에 대한 설명이다.
3번
고급 회귀분석에 대한 설명으로 옳지 않은 것은?
1. 정규화 선형회귀는 과적합을 막는 방법이다.
2. 로지스틱 회귀는 종속변수가 범주형 변수인 경우로 의학연구에 많이 사용된다.
3. 포아송 회귀는 오차항이 독립성을 만족하는지를 검정하기 위해서 사용된다.
4. 일반화 선형회귀의 구성요소로 확률 요소, 선형 예측자, 연결 함수가 있다.
정답
오차항이 독립성을 만족하는지를 검정하기 위해서 사용되는 것은 더빈 왓슨 검정이다.
