2 로그 수집 아키텍처
2.1 로그 수집 방식
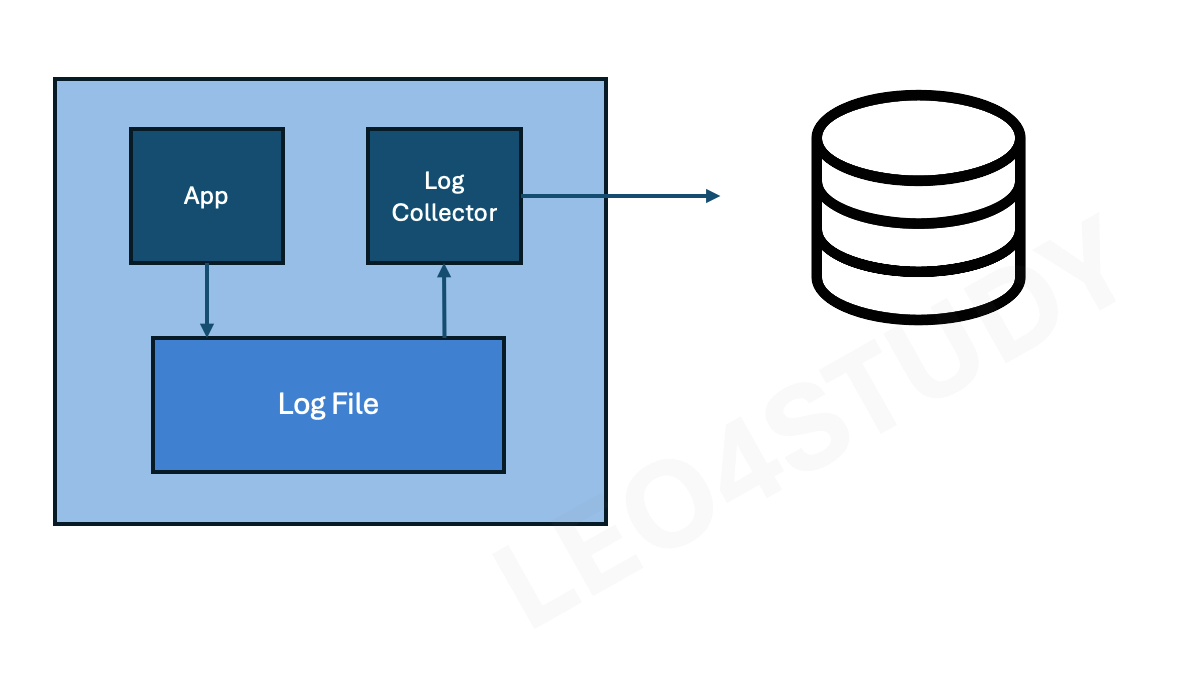
2.1.1 파일을 이용한 수집
어플리케이션에서는 로그를 파일로만 남긴다. 어플리케이션과는 별도로 파일로부터 수집해서 전송하는 프로세스를 만들어서 전송하는 방식. (기록 남기는 친구, 기록 수집해서 보내는 친구의 역할을 분리)
장점
- 어플리케이션과 로그 수집기가 관심사의 분리(SoC, seperate of concern)가 된다. 아키텍처 상으로 역할과 동작이 구분되므로 유연성이 높아진다.
- 어플리케이션 개발자 : 내가 어떤 저장소 쓸 건데 어떤 프로토콜로 보내야하는지, 리소스 사용이 얼마나 되니까 로그가 얼만큼 쌓일 거고 그 양을 보내려면 어느 정도 스레드 할당해야되는지 등 고민할 필요 없어짐
- 컨테이너 환경을 이용해서 어플리케이션과 수집기의 리소스를 분리하면, 수집기 때문에 어플리케이션에 부하를 주지 않는다.
- 컨테이너 별로 코어수의 차이를 두어서 할당하면서 리소스를 구분한다.
단점
- 어플리케이션, 로그 수집기를 별도로 관리해야 한다.
- 어플리케이션은 정상인데, 로그 수집기의 이상으로 어플리케이션의 이상으로 판단될 수도 있다.
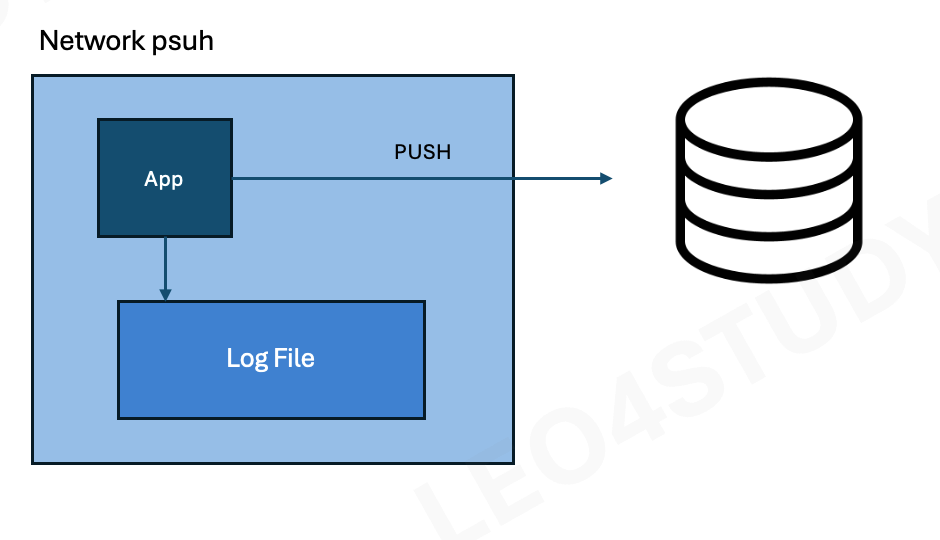
2.1.2 Network를 이용한 Push
어플리케이션에서 직접 로그 수집기로 TCP, HTTP 등의 프로토콜을 이용해서 전송하는 방법.
장점
- 로그 전송의 성공, 실패 여부를 어플리케이션에서 판단할 수 있다.
단점
- 어플리케이션의 로직과 로그 전송을 같은 process 에서 수행하므로 서로 영향을 미칠 수 있다.
- 로그 전송 때문에 어플리케이션의 부하나 bottleneck 이 있을 수 있다.
- 문제를 디버깅하기 복잡해진다.
- 개발자 입장에서 어플리케이션 두 개 관리해야함.
2.1.3 Network를 이용한 Polling
어플리케이션은 시스템의 정보, 로그 정보 등에대해서 scrap 할 수 있는 채널(network port, path)만 열어두고, 수집기에서 주기적으로 Polling으로 scrap 하는 방식.
어떤 순간의 스냅샷 정보다보니 사실 이벤트가 발생한 건 아니다.
Log 보다는 Metic(통계 정보, 상태정보에 대한 snapshot)수집에 더 적합하다.
그래서 로그는 여전히 로그 파일을 남기던가 아니면 따로 보내던가 할 필요가 있다.
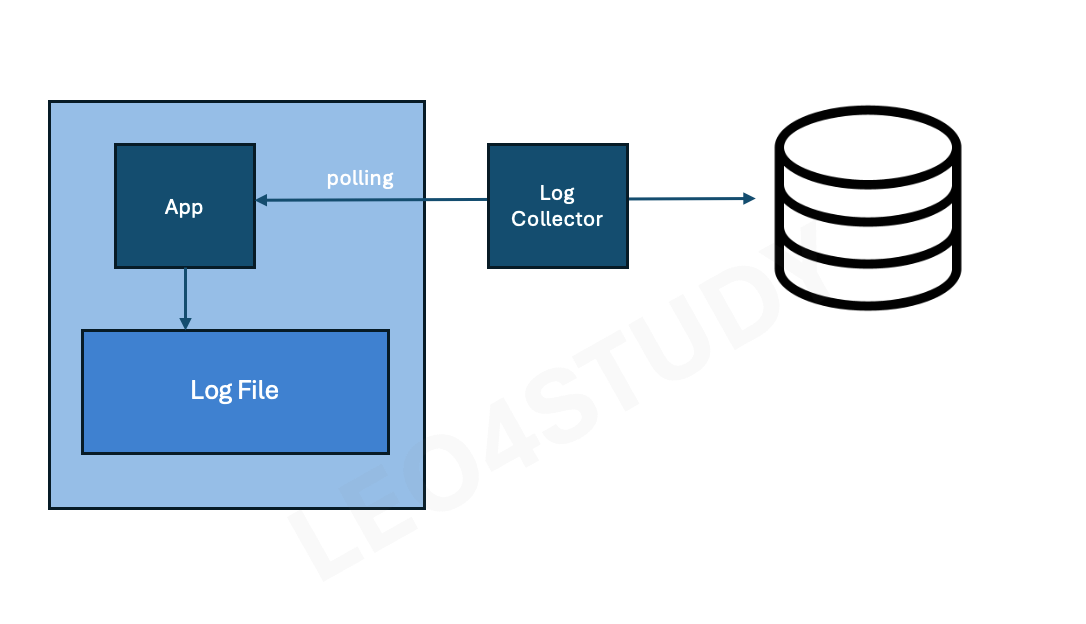
어플리케이션은 자신의 상태를 (status) 들고 있다. 이게 보내졌는지는 상관은 안 한다. 근데 밖에 있는 콜렉터가 App을 주기적으로 찔러보면서 (polling) 가져가고 스크랩 하는 방식.
장점
- 어플리케이션과 메트릭에 수집에 대한 관심사의 분리(SoC)가 이루어진다.
- 어플리케이션에서 개발자가 수집에 대한 관리를 할 필요가 없다.
- 분산 환경, 컨테이너 환경, 자동화된 인프라 환경에서 사용성이 편하고, 확장성이 높다.
- 그 이유는 리소스 매니저가 어떤 서버에 어떤 애플리케이션을 배포할지 결정하기 때문이다. 예를 들어 App1이 1번 서버에 올라갔다고 해도, 그 정보를 애플리케이션 개발자가 직접 알 필요는 없다. 리소스 매니저가 이 배포 정보를 알고 있으므로, 로그를 수집할 때 해당 애플리케이션의 메타정보(App ID 등)를 함께 붙여서 수집하면 된다. 이처럼 구성 요소 간의 상태나 위치를 몰라도 로그 수집이나 모니터링이 원활하게 이뤄질 수 있어, 인프라 관리가 훨씬 유연하고 무중단 운영이 가능해진다.
단점
- 결국 Polling 하는 거니까 인터벌이 생긴다는 것.
- Polling 주기나 scrap 시점에 따라 값이 바뀌므로 특정 순간의 정확한 정보를 보는데는 적합하지 않다.
Network를 이용한 Polling은 이벤트의 정확한 내용을 보기보다는 매트릭 정보를 보는 데 쓴다.
2.1.4 어떤 방식을 쓰는 것이 좋을까?
Q : 어차피 파일로 남기는 Warning, Error log 를 수집하고 싶다 나중에 로그 내용(text)를 찾아서 보고 싶다
- polling이 낫지 않을까?
파일에 남아 있다면 그 중에 어떤 게 warning인지, error인지 수집기에서 충분히 판단할 수 있다. 구래서 별도의 log 수집기가 파일을 읽어서 보내는 게 적합하다.
내용은 Metric이 아닌 것이고 따라서 Polling도 아니다.
파일로 남기는 거니까 파일을 이용한 수집 Push방식이다.
Q : 즉시 알람이 와야하는 중요한 이벤트(로그)를 보내야 해요, 그리고 어차피 파일로 남고는 있어요
- Network를 이용한 Push가 낫겠다. 빠르잖아.
중요한 건 네트워크를 이용한 푸시가 적합하다. 그 결과가 잘 보내졌는지, 안 보내졌는지 판단이 필요할 수도 있으니까.
사실상 로그라고 말하지만 로그가 아닐 수도 있다. (로직일 수도 있음)
Q : 얼마나 요청이 많이 왔는지 통계 정보를 보고 싶어요.
- Network를 이용한 Polling이 통계 정보에 좋댔어.
통계정보 : Metric
특정 기간 동안의 통계 정보를 얻으려면, 로그를 충분히 남겨두고 이를 기반으로 통계를 계산할 수 있어야 한다.
하지만 통계 수치가 이미 서버에서 계산되어 노출되고 있다면, 그것을 주기적으로 가져오기만 하면 되므로, 예를 들어 1분마다 수치를 수집한 후 60초로 나누면 초당 평균 요청 수를 구할 수 있다.
이처럼 이미 계산된 데이터를 일정 주기로 가져오는 경우에는 로그 수집 방식보다는 네트워크를 이용한 Polling 방식이 더 적합하다.
Q : 현재 메모리 사용율, 스레드의 수, 어플리케이션의 상태를 보고 싶어요.
- 현재 상태? 네트워크를 이용한 push를 해야하지 않을까?
네트워크를 이용해 푸시하거나 파일로 로그를 남기고 모두 수집하는 방식은 오버엔지니어링이 되는 경우가 많다.
메모리 사용률이나 스레드 수, 애플리케이션 상태와 같은 정보는 일반적으로 짧은 순간에 급격하게 변화하기보다는 점진적으로 변화하거나, 이상이 발생하더라도 일정 구간 안에서 추세를 통해 파악할 수 있다.
이러한 경우에는 로그를 직접 푸시하기보다는 네트워크를 이용한 Polling 방식으로 주기적으로 상태 정보를 수집하는 것이 더 적절한 방식이다.
실제 시스템에서는 로그 수집 아키텍처를 어떻게 구성하는 것이 효과적일지, 이에 대한 Best Practice를 살펴보자
2.2 EFK 로그 수집 Architecture
ElasticSearch, Fluentd, Kibana 의 앞자를 따서 EFK 라고 한다.
- Elastic stack으로 구성된 ELK( L은 Logstash) 라는 용어로 더 잘 알려져 있다.
- Elastic stack 의 유료화 때문에,
ElasticSearch대신Opensearch를,Kibana대신Opendashboard를 사용한다.
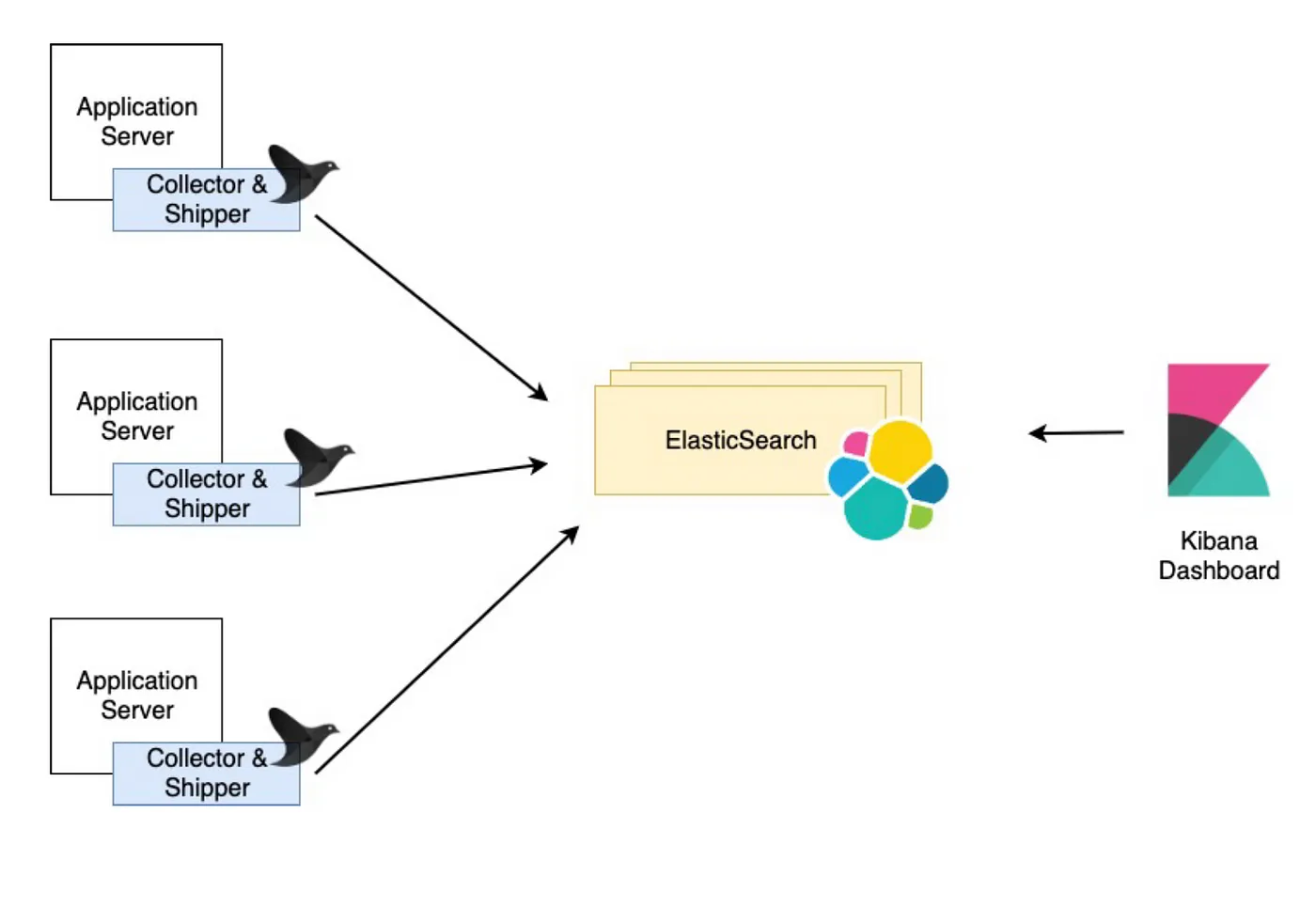
image source : https://faun.pub/logging-architectures-efk-stack-and-kubernetes-6c3f4d940775
2.2.1 Fluentd
로그의 수집, 파싱, 전송은 Fluentd 가 맡는다.
Fluentd 는 어플리케이션의 파일을 읽기 위해 어플리케이션과 같은 호스트에 뜬다.
Fluentd 는 적은 리소스를 사용하면서 로그를 파싱하고 전송하는데 특화되어 있다. 규칙을 태그방식으로 정하기 때문에 사용성이 직관적이다. CRuby로 만들어져 있다.
- Fluentbit 이라는 C기반의 경량화된 버전도 있다. 이것은 forwarder 로서 사용하기에 적합하다.
forwarder : 로그 수집 시스템에서 로그를 다른 서버나 중앙 저장소로 전달하는 역할을 하는 구성요소
- 애플리케이션이나 서버에서 발생하는 로그를 읽고, 로그를 중앙 수집 서버나 처리 시스템(예: Elasticsearch, Kafka, Fluentd 등)으로 보내는 역할을 담당
- 즉, **로그를 "수집하고 전달만 하는 경량 에이전트"
2.2.2 Opensearch(Elasticsearch)


로그를 저장하는 저장소다. Opensearch는 텍스트 데이터의 검색에 특화된 인덱싱 방법을 가지고 있기 때문에, 로그의 저장소 겸 검색 시스템으로 사용하기 좋다.
미리 스키마를 선언하지 않더라도 저장된 데이터 형식에 맞게 자동으로 인덱싱할 수 있는 것 또한 장점이다.
로그는 다양한 시스템에서 다양한 목적으로 남기기 때문에 로그 저장소는 데이터 타입과 형식에 대한 유연성을 제공하는 것을 선택해야한다.
Java 로 만들어졌고, JVM 위에서 돌아간다.
2.2.3 Open Dashboard(Kibana)

Opensearch와 연동되고, 사용하기 쉬운 시각화 도구이다.
기본으로 timeline 방식의 로그 시각화를 제공하고, SQL을 모르더라도 UI를 통해서 원하는 로그를 쉽게 찾고 추이를 볼 수 있다. 검색 결과에 대한 link를 생성해서 빠르게 공유할 수 있다.
이미 데이터가 Opensearch에 쌓여있다면, 다양한 그래프를 작성하고 통합된 Dashboard도 구성할 수 있다.
Javascript로 만들어졌고, Nodejs 서버로 동작한다.
2.3 Filebeat+Logstash vs Fluentd
2.3.1 구성 언어
-
Filebeat: Go 언어로 작성되어 경량
-
Logstash: JRuby 기반 → 메모리 사용량 높음
-
Fluentd: CRuby 기반 → 비교적 경량
Filebeat는 단독 사용 시 간편하지만, 종종 Logstash 등과 함께 사용됨 → 복잡도 증가
Filebeat도 좋은 로그 수집기이지만, 복잡도 면에서 두 개의 시스템을 다루는 것보다는 하나의 시스템을 다루는 것이 편한 장점이 있다.
JRuby와 CRuby의 차이 때문에 Logstash 가 조금 더 많은 메모리를 사용한다.
2.3.2 아키텍처와 성능
가장 성능에서 큰 차이를 보이는 것은 메모리의 buffer queue 다.
Logstash는 메모리 상의 큐에 고정된 크기인 20개의 이벤트를 갖고 있다.
재시작 시 지속성, throughput 대비 높은 유입량에 대비하기 위해 Redis 또는 Kafka와 같은 외부 큐에 의존해야 한다.
Fluentd는 메모리상에 또는 디스크에 끝없는 배열로 구성되어있는 버퍼를 가진다.
따라서 유입량에 대한 관리를 할 수 있고, 재시작시 디스크에서 읽어서 재처리 할 수 있다.
다만, OpenStack Summit 2015에서 둘 다 대부분의 사용 사례에서 잘 수행되고 10,000 개 이상의 이벤트를 잘 처리할 수 있다. (파싱이 복잡하지 않은 경우)
throughput(처리량)은 시스템이나 네트워크가 단위 시간 내에 처리할 수 있는 작업이나 데이터의 양을 의미한다. 예를 들어, 서버가 1초에 1000개의 요청을 처리할 수 있다면, 그 서버의 throughput은 초당 1000 요청이 되는 것이다
Logstash
- 메모리 큐에 20개 이벤트 제한
- 높은 유입량 시 Redis/Kafka 등 외부 큐 필요
- 재시작 시 데이터 복구 불가
Fluentd
- 메모리 또는 디스크 기반 무제한 큐
- 유입량 관리 용이
- 디스크 기반 버퍼로 재시작 시 복구 가능
일반적인 경우(복잡하지 않은 파싱)에는 두 수집기 모두 1만 건 이상 처리 가능
2.3.3 문법
Logstash는 if-else 조건에 기반에 이벤트를 라우팅 한다.
output { if [loglevel] == "ERROR" and [development] == "production" { { ... } }
Fluentd는 태그에 기반해 이벤트를 라우팅 한다.
<match logtype.error> type ... </match>
Fluentd의 이벤트에 태그를 지정하고 각 이벤트 유형에 대해 if-else를 사용하는 것이 더 직관적이다. 만약 로그에 다른 종류의 타입이 많아진다면 Logstash는 관리하기가 어렵다.
- 물론 Fluentd도 많아진다면 설정이 복잡하고 성능이 떨어질 수 있다. 이 경우 rsyslog 가 하나의 대안이 된다.(초당 1million 로그의 전송이 가능하다고 한다.) rsyslog → fluentd 로 파싱결과를 보내는 아키텍처도 선택가능하다.
2.3.4 플러그인
Fluentd는 다양한 플러그인을 제공하기 때문에 지원 범위가 넓지만, 실제 현업에서 자주 사용하는 기능(예: 특정 로그 수집, 필터링, 전송 등)은 Fluentd나 Filebeat+Logstash 모두 이미 지원한다.
따라서 실무에서 필요한 기능 측면에서는 큰 차이가 없다.
2.4 요구사항에 따른 구성 방법
2.4.1 기본 아키텍처
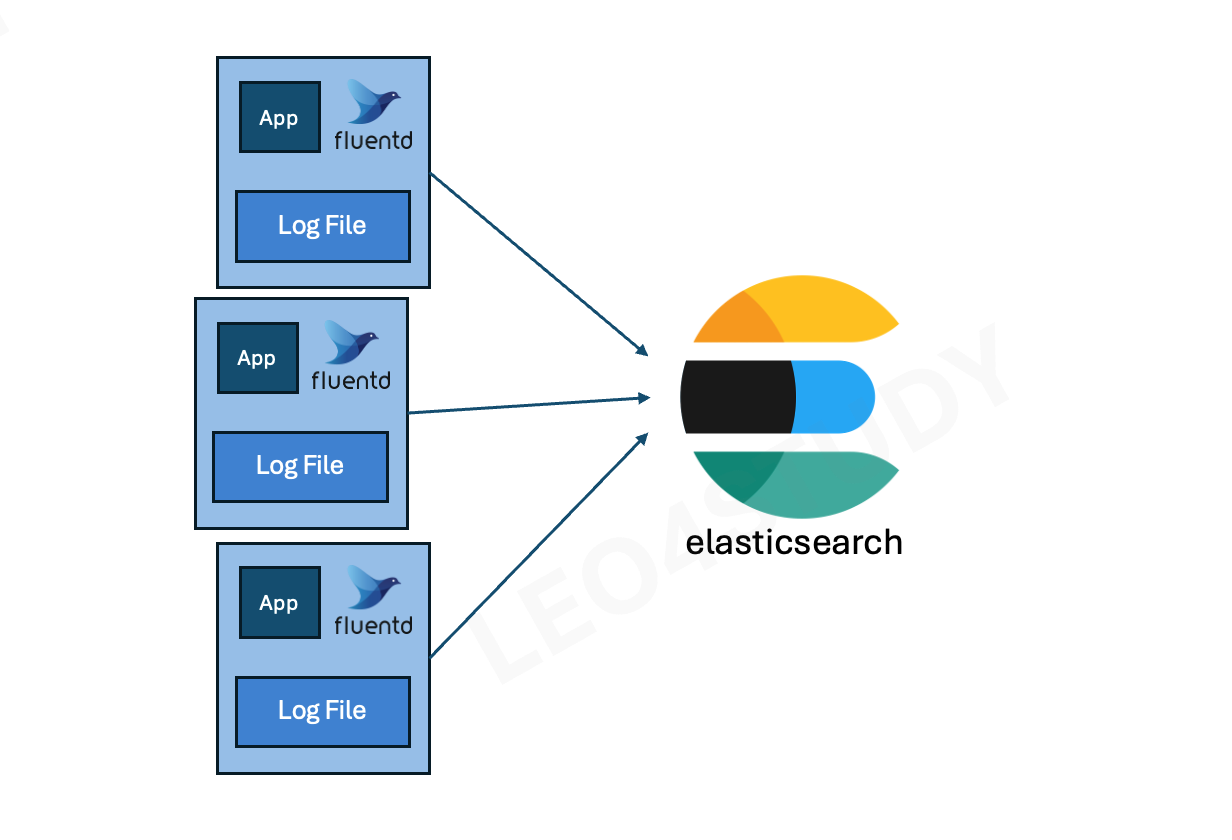
2.4.2 작은 규모의 서비스
작은 규모의 서비스에서는 수집기(fluentd)에서 바로 storage(Opensearch)로 전송하는 것이 구성이 간단하고, 비용도 적게 나가는 이점이 있다.
기본 아키텍처와 동일하다.
2.4.3 로그 수집기에 부하가 있을 때
다음의 경우 로그 수집이 지연되거나 로그가 유실될 수 있으므로 대책이 필요하다.
- 실시간으로 쌓이는 로그의 양이 수집기가 처리할 수 있는 양보다 많다.
- 수집기에서 처리하는 파싱 로직이 복잡할 때
- 로그 수집기의 리소스가 처리하는 작업에 비해서 부족할 때
로그 수집기에 부하가 있다면, 역할을 나눠주는 것이 좋다.
Fluentd를 forwarder 와 collector 로 나눈다.
Forwarder
- 각 노드(또는 인스턴스)에서 fluend 는 최소한의 Parsing 과 전송만 한다.
Collector
- Forwarder 에 의해 전달된 로그를 파싱하고, 적절한 스토리지로 전송한다.
- 인스턴스 수를 늘리거나 줄이면서 로그의 유입량의 변화와 부하에 대응할 수 있다.
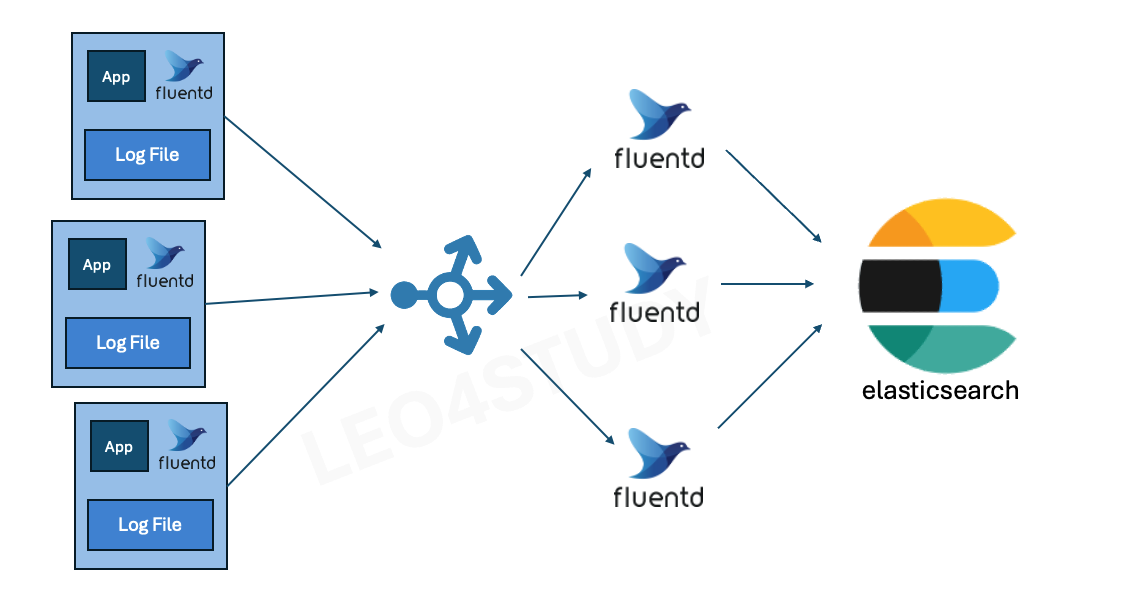
Fluentd forwarder는 애플리케이션이 생성한 로그 파일을 읽어서 로그 데이터를 수집하는 역할을 담당한다. 이때 forwarder는 여러 개의 로그 수집 서버(collector)가 있을 경우, 직접 collector들을 관리하지 않고, 먼저 로드밸런서에 로그 데이터를 전송한다.
로드밸런서는 들어오는 로그 요청을 여러 collector 인스턴스에 라운드로빈 방식으로 분배한다. collector들은 전달받은 로그를 파싱하고, 필요한 형태로 가공한 후 적절한 저장소에 저장한다. 또한, collector 인스턴스 수는 로그 유입량과 시스템 부하에 맞춰 동적으로 늘리거나 줄일 수 있다.
이 구조 덕분에, forwarder는 단지 로그 파일 경로만 알고 있으면 되고, 복잡한 처리 로직은 collector에서 수행한다. 따라서 애플리케이션과 로그 수집기는 서로 독립적으로 운영될 수 있다. 예를 들어, forwarder에 별도의 복잡한 로직이 추가되어 애플리케이션 환경 전체를 재배포해야 하는 부담이 없어진다.
특히 쿠버네티스 환경에서는 forwarder와 collector가 각각 별도의 컨테이너로 분리되어 배포되기 때문에, 관심사를 명확히 분리하고 유연하게 시스템을 확장하거나 유지관리할 수 있다.
결과적으로, 애플리케이션이 로그를 생성하고, forwarder가 이를 읽어 로드밸런서에 보내면, 로드밸런서는 collector에게 트래픽을 효율적으로 분배하고, collector가 로그를 처리해 저장하는 형태로 전체 로그 수집 시스템이 원활하게 작동하게 된다.
하루에 트래픽이 천 개 정도 들어오고, 유저가 만 명도 되지 않은 경우엔 굳이 이렇게 쓸 필요 없고 기본 아키텍쳐 만으로도 충분하다
앞서 Fluentd(FrontD)가 자체 메모리 버퍼와 디스크를 활용해 일종의 Queue처럼 작동할 수 있다고 설명했다. 이 구조는 일반적인 상황에서는 충분히 안정적으로 로그를 수집하고 전송할 수 있다.
하지만 로그 트래픽이 매우 많아지면, 이 Queue도 한계에 도달하여 문제가 발생할 수 있다.
예를 들어, Fluentd 인스턴스가 처리하지 못할 만큼 로그가 몰리면, 저장소로의 전송이 지연되거나, Forwarder에서 로그를 보내려 해도 수신 측(Fluentd)이 받지 못해 전달 실패 또는 로그 유실이 발생할 수 있다.
이러한 문제는 Logstash보다 나은 편이긴 하지만, 여전히 하이트래픽 상황에서는 문제가 될 수 있다.
이러한 상황을 대비하기 위해 Kafka 같은 분산 메시지 큐를 중간에 두는 구조를 사용할 수 있다.
Kafka는 대용량 로그를 저장할 수 있을 뿐만 아니라, 안정적인 Queue 역할도 수행한다.
이때 로그를 수집하는 Forwarder들은 Kafka의 특정 토픽(topic)으로 로그를 전송하게 된다.
Kafka는 받은 로그를 일단 내부에 쌓아두고, 이후 Fluentd 인스턴스들이 Kafka로부터 데이터를 가져와 파싱한 뒤, Elasticsearch나 다른 로그 저장소로 전송한다.
Kafka의 장점은 큐가 길어져도 메시지를 안정적으로 저장할 수 있다는 것이다.
Fluentd 인스턴스 수를 일시적으로 확장해 Kafka에 쌓인 로그를 병렬로 빠르게 소진하고, 이후 다시 인스턴스 수를 줄이는 식으로 유연하게 대응할 수 있다.
이렇게 구성하면 대량의 트래픽과 다양한 유형의 로그에 안정적으로 대응할 수 있다.
또한, 로그의 성격이 완전히 다르거나 인프라를 분리해서 운영하고 싶은 경우, Kafka에서 토픽을 구분해 서로 다른 Fluentd 그룹이 각 토픽을 구독하도록 구성할 수 있다. 이로써 특정 유형의 로그는 특정 Fluentd 인스턴스 그룹이 처리하고, 별도의 저장소로 분리해서 저장하는 유연한 아키텍처 구성이 가능해진다.
Fluentd를 클러스터 구성해서 운영하는 것이 어렵다면, Kafka와 같은 메세지 큐를 이용해서 구성하면 다양한 트래픽과 로그를 대응할 수 있다.
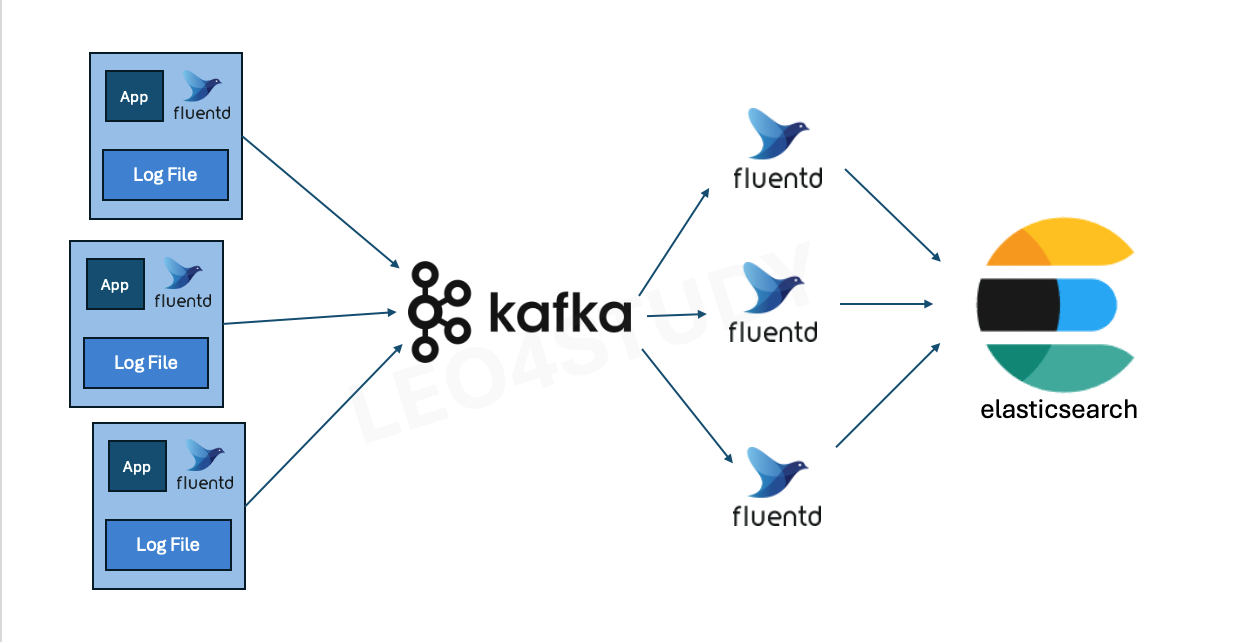
2.4.4 저장소에서 트래픽을 받아주지 못할 때
2.4.3 처럼 대응해서 대량의 트래픽에 대해서도 로그를 수집할 수 있게 되었다. 그래도 문제가 끝나지 않는다.
로그 수집기들은 모두 정상 작동하지만, 저장소에서 실시간으로 저장요청이 너무 많으면 저장하고 인덱싱하는데 걸리는 시간이 많이 걸려서 Storage가 bottleneck 이 될 수도 있다. 이런 경우에 Storage API에서 Error를 받게 되면, 로그 수집기에서 무한 재시도 또는 쌓여있는 로그때문에 buffer full 로 인해서 부하가 커지거나 로그가 유실될 수 있다.
이때 스토리지에서 저장의 효율을 높여주는 시스템이 있다면 대응할 수 있다. Opensearch 에서는 ingest node 라는 서버로 그 역할을 할 수 있다. ingest node의 수를 늘려서 대량의 저장요청에 대응할 수 있다.
2.4.5 최종 아키텍처
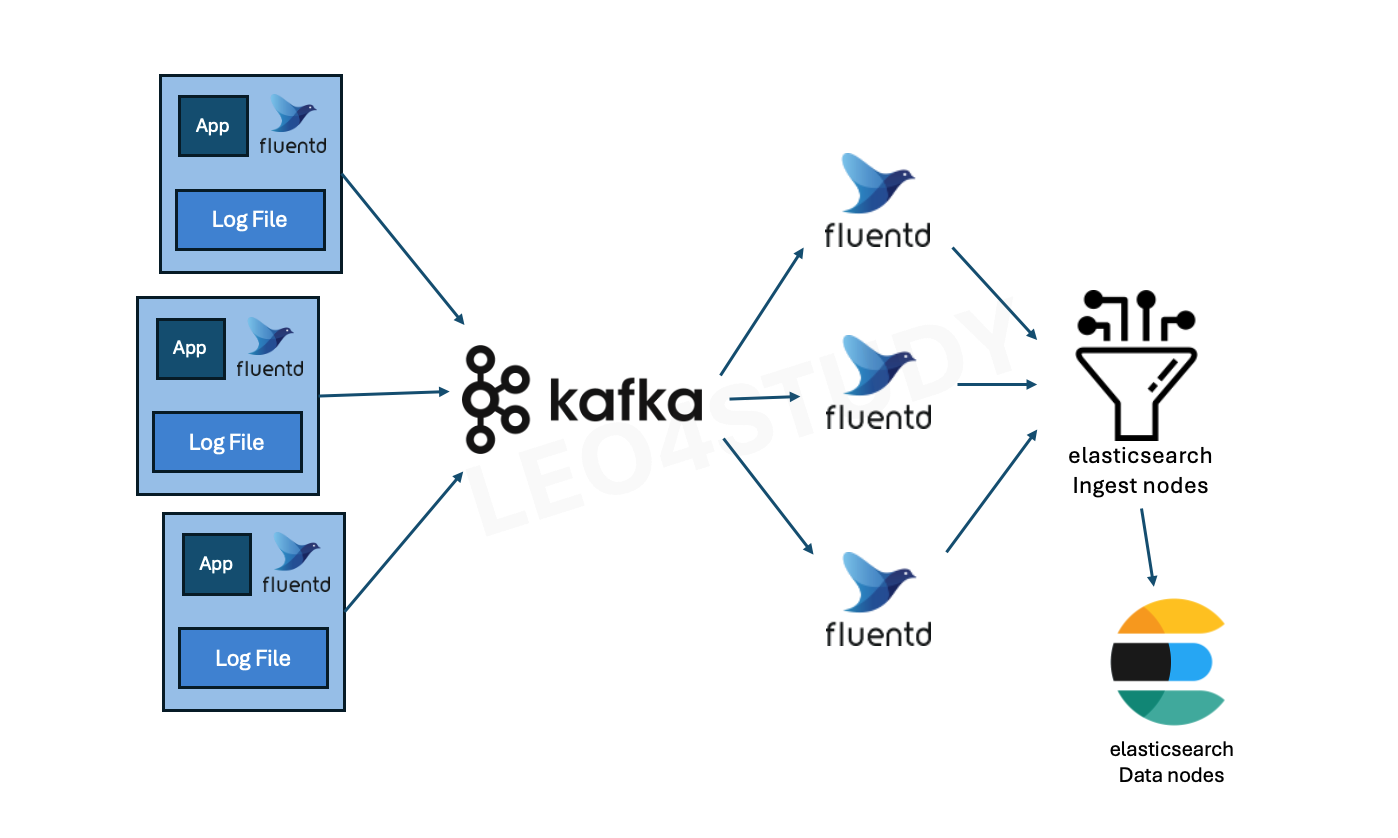
대규모 트래픽을 처리하고 로그 파싱 로직이 복잡한 경우에는, 각 애플리케이션 혹은 노드마다 Fluentd Forwarder를 배치하여 로그를 수집하고, 이를 Kafka로 전달하는 아키텍처를 구성할 수 있다. Kafka는 로그 데이터를 안정적으로 버퍼링한 뒤, 별도의 Fluentd Consumer 그룹이 Kafka 토픽을 구독하여 로그를 수신한다. 이 Consumer들은 필요한 로직을 적용하거나 로그를 파싱한 뒤, 최종적으로 Elasticsearch로 데이터를 전송한다.
이때 저장 대상은 Elasticsearch의 Ingest Node들이다. Ingest Node는 수신한 데이터를 분석하여, 어떤 Data Node에 저장하는 것이 가장 효율적인지를 판단한다. 이 과정에서는 데이터의 인덱싱 부담, 분산 정도, 노드 간 부하 균형 등이 고려된다. Ingest Node는 이러한 판단을 바탕으로 데이터를 적절한 Data Node에 분산 저장하여, 전체 저장소의 성능과 안정성을 높인다.
2.4.6 실습 아키텍처
실습은 1번 기본 아키텍처로 진행한다.
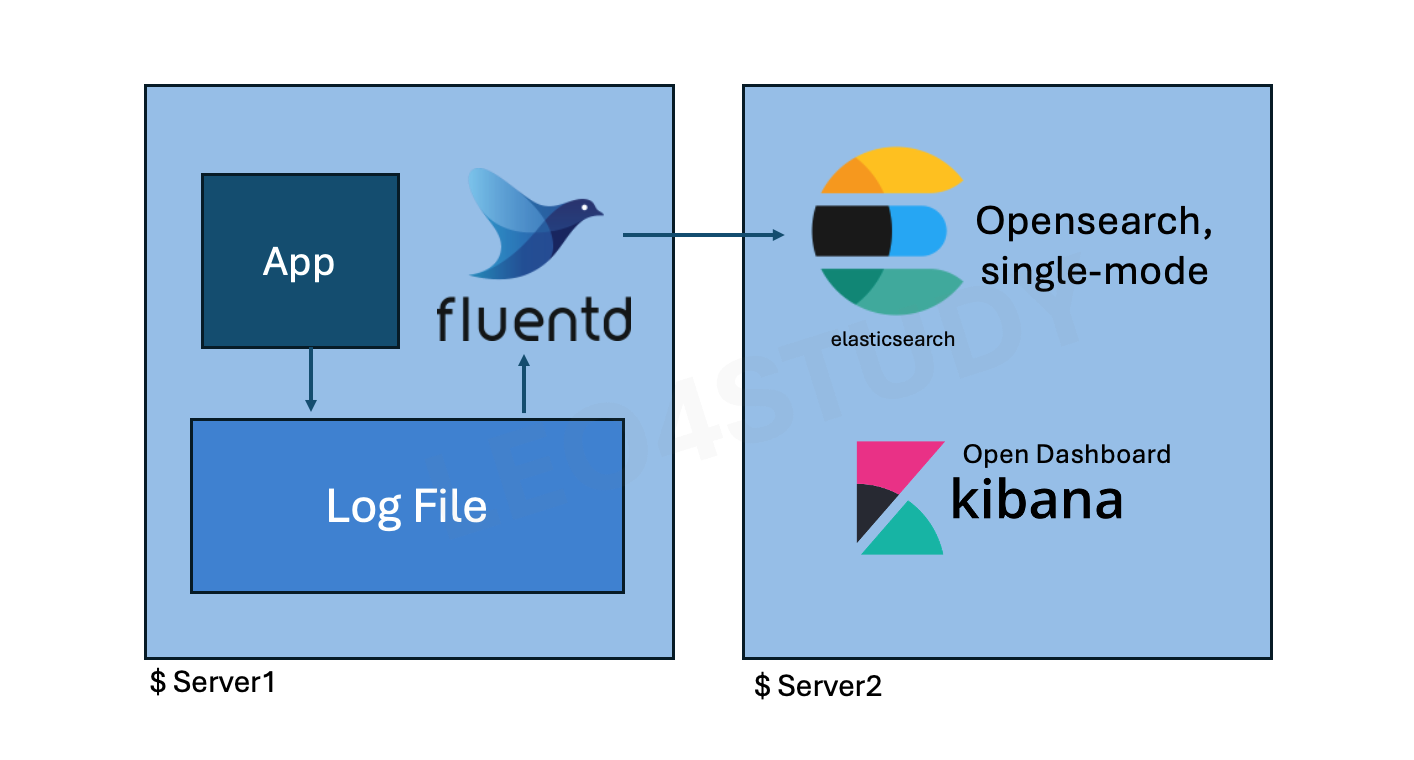
실습에서는 1번 아키텍처를 기반으로 환경을 구성한다. 총 서버 두 대를 사용하며, 이는 ELK 스택이 어떻게 동작하는지를 확인하는 데 목적이 있기 때문이다.
-
서버 1에는 로그를 남기는 애플리케이션이 존재하며, 해당 로그 파일을 FluentD가 수집한다.
-
서버 2에는 OpenSearch와 OpenDashboard를 설치하며, 서버 1의 FluentD가 서버 2의 OpenSearch로 로그를 전송한다.
로그가 저장되면, 브라우저를 통해 서버 2에 띄워둔 OpenDashboard에 접속하여 OpenSearch에 저장된 데이터를 시각적으로 확인할 수 있다.
따라서 실습은 적은 리소스를 사용하여 두 대의 서버로 구성하며, 기능적인 동작을 검증하는 데 중점을 두고 진행한다.
그러면 아키텍처에 대한 설명은 여기서 마친다.
