Data_Engineering
1.데이터 엔지니어란?

데이터 엔지니어는백엔드부터 시작하는 게 좋은 시작이다.비즈니스적 의사결정 내릴 때, 데이터의 중요성이 대두 되었다. 데이터 드리븐 의사결정과학적 비즈니스 의사결정을 내리는 것이 좋은 결과를 낸다는 믿음이 있기 떄문에데이터 분석가나 사이언티스트에 대한 수요가 생겨났다.이
2.[데이터 엔지니어링] 개발환경 세팅
2\. Java 개발환경 세팅
3.[Linux] 리눅스 기본 활용 - 리눅스 명령어 정리1
manual의 약자.텍스트로 된 명령어 설명이나옴!j : 스크롤 아래로k : 스크롤 위로h : helpq : quitmanual과 비슷한 기능을 하는 옵션경로를 어떻게 표시하는지 알아보자.EC2우분투에 아무 설정변경 않고 접속하면ubuntu@ip-172-31-33-10
4.[Linux] 리눅스 기본 활용 - 리눅스 명령어 정리2
1.1. 시스템 활용을 위한 명령어 명령어 모음
5.[Linux] 리눅스 기본 활용 - 리눅스 명령어 정리3
1.7. vi 명령어 명령어 모음
6.[Linux] 리눅스 기본 활용 - 환경변수의 이해
8. 환경변수의 이해
7.[Linux] 리눅스 기본 활용 - shell script 활용하기
Shell script는 unix shell의 command line interpreter가 실행할 수 있는 명령어(리스트)를 의미한다.unix shell, unix라는 커널의 형태가 있다. 운영체제 형태. 가장 기본적인 형태인데 unix 계열의 운영체제가 여러가지가
8.[Linux] 리눅스 기본 활용 - shell script 실습
shell script 실습 1. 변수 영문, 숫자, _만 사용가능 Unix shell 의 변수 명은 대문자로 작성하는 것이 convention 이다 변수명=변수값 으로 변수 선언 가능 (사이 띄어쓰기 없이 붙여줘야 선언됨) $변수명 : 변수 사용 readonly 변
9.[Java] 자바 학습 계획
데이터 엔지니어로 일하면서 보게될 자바 코드를 이해할 수준까지 끌어올리는 것이 목적이다. 예전에 Android Studio에서 Java로 앱을 개발한 경험이 있다.자바에서 중요한 부분이나 기억나지 않았던 부분들을 위주로 학습하며 빠르게 학습하는 것이 목표.JAVA8(1
10.[Java] Java 기초 - 언어 소개
Java는 객체 지향 프로그래밍이 가능한 언어로 고안되었다.Write Once, Run Anywhere한 번 작성하면 어디에서나 실행된다. 자바로 개발된 프로그램은 자바 실행 환경(JRE)가 설치된 모든 환경에서 실행이 가능하다는 것이다.JRE : Java Runtim
11.[Java] Java 기초 - 자바 코드가 실행되는 원리
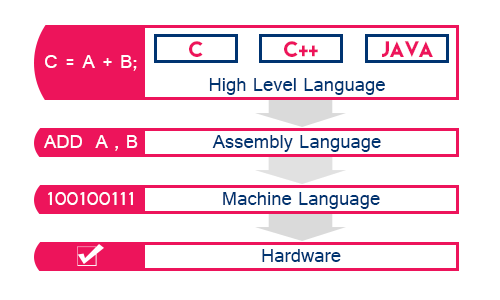
2. 자바 코드가 실행되는 원리 우선 자바 코드 실행하는 원리 배우기 전에 일반적으로 프로그래밍 언어가 어떤 과정으로 실행되는지 배워보자. 2.1. 프로그래밍 언어의 실행 원리 (bottom-up 방식의 설명을 할 것.)왜냐? top-down으로 하는 건 우리가 익
12.[Java] Java 기초 - 자바 코드 구조
3\. 자바의 구조
13.[Java] Java 기초 - 변수와 상수
본격적으로 Java에 대해서 배우겠습니다. 가장 먼저 배울 것은 변수와 상수입니다. 변수와 상수를 선언 하는 방법 및 어떤 의미를 가지는지 알아보겠습니다!(하이레벨 랭귀지의 대표적인 특징이 이름을 붙일 수 있다는 얘기가 이거다.)변수와 상수가 무엇일까?변수 : 어떠한
14.[Java] Java 기초 - 자료형

자바는 정적타입의 언어다 보니 자료형의 사이즈가 정해져 있어야 되고 그렇기 때문에 프리미티브 타입 같은 경우 기본타입이기 때문에 사이즈가 다 정해져 있다.그래서 이 부동소수점에 의해서 모든 숫자가 다 소수점 아래로 표현되지 않는 한계가 있다는 것을 알아둬야지 정말 소수
15.[Java] 연산자 & 연산 순서
연산자는 쉬우니까 바로 넘어가자.연산자란?연산자는 여러 변수들간의 계산 및 비교를 위하여 사용됨.종류로는 산술연산자, 대입연산자, 논리연산자, 관계연산자 등이 있다.나누기를 할 때 0으로 나누면 java.lang.ArithmeticException이 발생한다. 나누기의
16.[Java] Java 기초 - 조건문
조건문조건문과 반복문은 정말 유용하게 쓰이는 제어문입니다. 조건문과 반복문에 대하여 충분히 이해하고 활용할 수 있어야 합니다.특정 조건에 따라 프로그램의 수행을 다르게 하고 싶을때 조건문을 사용합니다.조건문에는 대표적으로 if , switch , 삼항연산자 조건문이 있
17.[Java] Java 기초 - 반복문
반복문이란현재 100명의 학생들 점수의 평균을 구해야 할 때, 100명의 학생의 점수를 일일히 더해서 평균을 낼 경우 더하는 연산과정을 하나하나 하기에는 너무 오래걸린다. 그렇다면 이렇게 단순, 반복의 과정을 간단하게 하는 방법이 반복문!반복문에는 대표적으로 for 문
18.[Java] Java 기초 - 객체지향 프로그래밍
9. 객체 지향 프로그래밍(Object-Oriented Programming) 이번 장에서는 Java 에서 객체지향 프로그래밍을 위해서 지원하는 문법과 이를 이용한 프로그래밍 방법을 알아보자. 객체 지향 프로그래밍은 일상생활에서 실제로 사람과 사물이 관계맺는 방식을 표
19.[Java] Java 기초 - static 심화
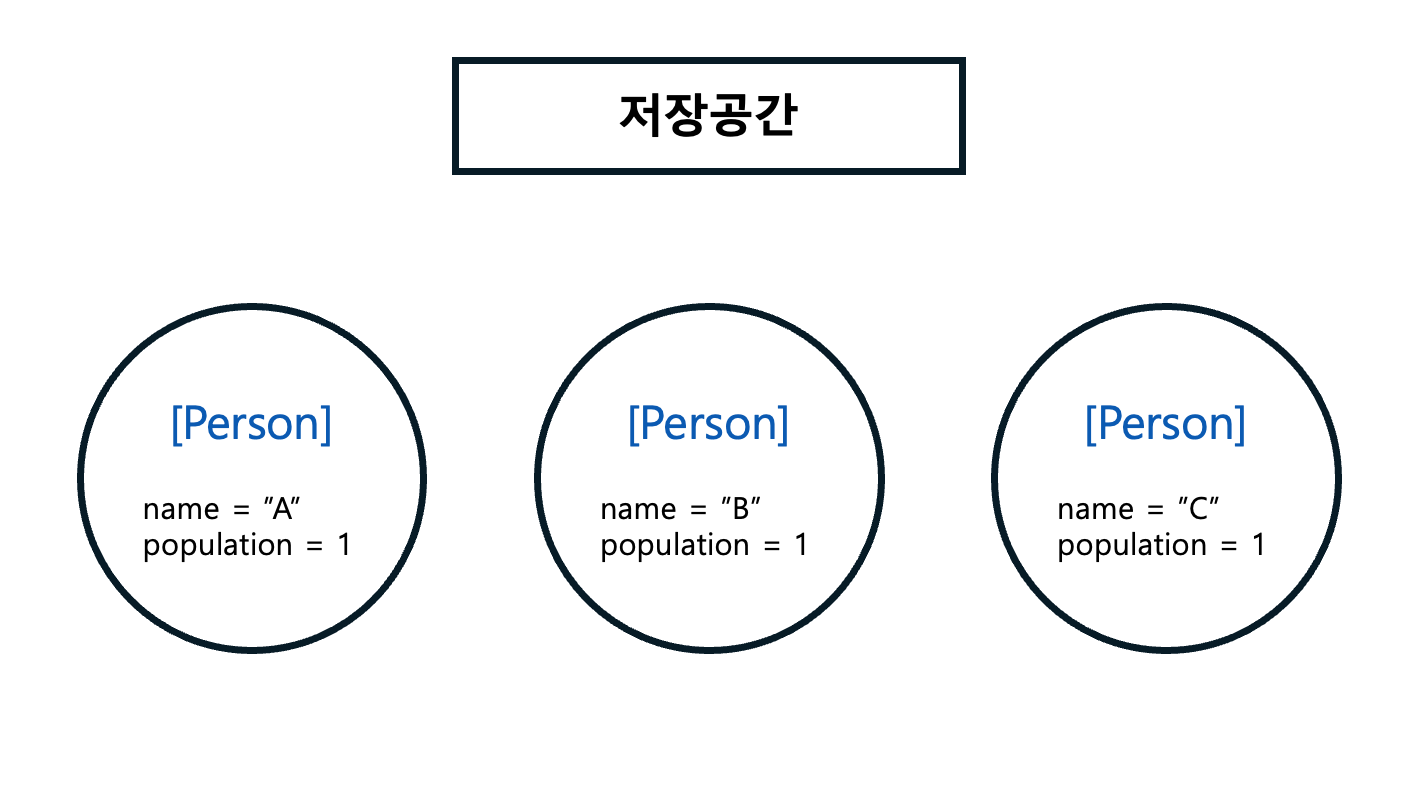
모모코딩 \[자바] 변수 앞에 static 있을 때와 없을 때의 차이Persion class에는 name과 population이라는 객체변수가 있다.생성자에 의해 파라미터로 들어온 name은 객체변수에 세팅하고총 인구수는 new 할 때 마다 하나씩 증가했으면 좋겠다 하
20.[Java] Java 기초 - 추상 클래스 심화
홍팍 - [자바 기초 34] 추상 클래스 추상 클래스란? 객체를 직접 생성할 수 없는 클래스다. 객체 생성은 불가능하지만, 자식 클래스를 통해 간접적으로 객체를 만들 수 있다. 추상 클래스 형식 abstract 키워드를 사용해 선언한다. 일반 클래스와의 차이는 ab
21.[Java] Java 기초 - 상위 클래스에서 새로운 변경자가 추가될 때 발생하는 보안 취약점
문제 상황상위 클래스(User)의 password 필드를 변경할 때 보안 로직을 적용하는 하위 클래스(SecureUser)를 만들었다.하지만 다음 릴리즈에서 상위 클래스에 새로운 변경자(setter)가 추가되면,자식 클래스의 보안 로직을 거치지 않고 필드가 변경되는 취
22.[Java] Java 기초 - 예외, 에러 처리
프로그램을 만들다 보면 다양한 예외상황 또는 에러가 발생하곤 한다. 에러를 처리하는 방법에 대해 알아보자코드를 완벽하게 짰다고 해서 항상 프로그램이 성공적으로 도는 것은 아니다. 다양한 예외 상황이 발생할 수 있고, 이것에 대응하기 위해서 예외 처리 코드가 필요하다.예
23.[Java] Java 기초 - 날짜 & 시간
Java에서 전통적으로 시간을 표현하는 기본 클래스는 Date 클래스다. Date 클래스는 unix epoch time의 milliseconds 단위로 시간을 다룬다.Epoch Time 이란?1970년 1월 1일(UTC/GMT 자정기준) 부터 얼마나 지났는지 초, 밀리
24.[Java] Java 기초 - Collection
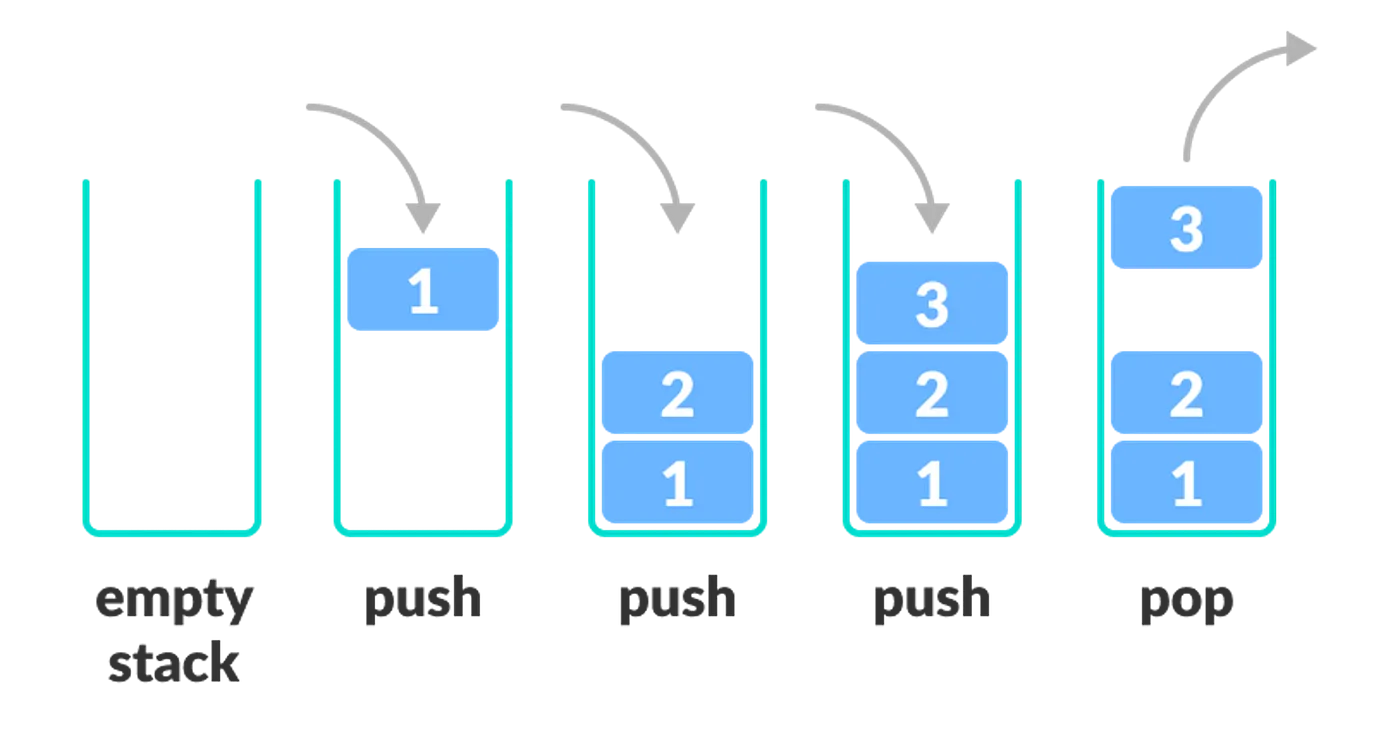
다수의 데이터를 다루기 위한 자료구조를 표현하고 사용하는 클래스의 집합 이다.데이터를 다루는데 필요한 풍부하고 다양한 클래스와 기본함수를 제공하기 때문에 유용하다. 실제 자바 어플리케이션을 개발 할 때 가장 많이 사용하는 클래스.콜렉션 프레임워크의 모든 클래스는 Col
25.[Java] Java 기초 - Generics, Lambda
13. 제네릭스(Generics) 제네릭스는 타입시스템을 유연하게 사용할 수 있는 기능이다. 13.1 제네릭스(Generics)란 클래스나 메소드 레벨에서 명세(동작)는 같지만 사용되는 타입만 다른 경우, 객체를 생성할 때 타입을 지정할 수 있도록 하는 기능이다. 객
26.[Java] Java 기초 - Stream
자바에서 스트림(Stream)은 함수형 프로그래밍(Functional Programming)을 가능하게 해주는 도구이다.스트림을 사용하면 코드의 흐름을 함수처럼 연결해서 처리할 수 있으며, 간결하고 오류가 적은 코드를 작성할 수 있다.기존에는 조건문이나 반복문처럼 명령
27.[Java] Java 기초 - Networking

네트워크의 기초 개념, Retrofit 라이브러리를 이용한 Open API 조회, TCP 소켓 프로그래밍의 기초를 학습한다.네트워킹(Networking)두 대이상의 컴퓨터를 케이블 또는 인터넷으로 연결하여 네트워크를 구성하는 것을 말한다.클라이언트(Client) / 서
28.[Python] Python 학습 계획
Airflow에서 Python Task를 작성할 때는 주로 간단한 스크립트를 실행시키는 수준의 문법만 필요하다. 데이터 엔지니어링 관점에서 보면, 대규모 데이터 프로세싱은 대부분 Java 기반의 프로그램이나 시스템에서 수행되고, 서버 역시 Java로 운영되는 경우가 많
29.[Python] Python 기초 복습
파이썬에서 리터럴은, 변수나 상수에 할당되는 원본 데이터(raw data)를 말한다. 이 데이터 자체는 변경되지 않는다.정수 리터럴, 실수 리터럴, 복소수 리터럴 3가지가 있다.정수 리터럴 : 0b로 시작하면 2진수, 0o로 시작하면 8진수 ,0~9로 시작하면 10진수
30.[Scala] Scala 기초 - 소개
소개1.1 Scala 소개Scala 는 2003년에 스위스 로잔공대의 Martin Odersky 가 개발한 강력한 타입(stronglytyped) 방식의 확장 가능한 (Scalable) 프로그래밍 언어(Language)입니다. 자바 언어의 한계를 극복할 수 있게 설계되
31.[Scala] Scala 기초 - Scala 설치하기
Scala 개발환경 세팅 강의(자료)의 안내대로 설치하자.
32.[Scala] Scala 기초 - 변수, 상수, 데이터 타입
변수, 상수, 데이터 타입우선 프로그래밍 언어에서 가장 기초가 되는 변수와 상수의 선언과 데이터 타입을 알아봅시다.2.1 변수 (variable)Scala 에서 변수는 var 로 선언합니다. 변수는 다른 값으로 변경할 수 있습니다. 아래 예시첫번째 줄은 name 이라는
33.[Scala] Scala 기초 - 연산자
연산자Scala 의 연산자는 다른 언어들과 유사하게 작동합니다. Python 보다는 Java 와 비슷한 점이 더 많습니다.3.1 산술 연산자 (Arithmetic Operators)val a: Int = 3val b: Int = 5println(a + b); // 더하
34.[Scala] Scala 기초 - Pattern Matching
Pattern Matching4.1 소개Pattern Matching 은 스칼라에서 가장 많이 쓰이는 기능 중 하나입니다. 자바의 switch 기능보다 더 강력한 기능이라고 생각하시면 됩니다. 여러 번의 if/else 보다 patternmatching 을 사용하시면 더
35.[Scala] Scala 기초 - 조건식
조건식5.1 종류Control flow 라고도 불리는 조건문은 현실에서 특정 조건이 맞을 때만 행동하는것과 비슷하게 작동합니다.if , if-else , nested if-else , if-else if ladder 종류가 있습니다. 단순한 if 부터 살펴봅니다.5.2
36.[Scala] Scala 기초 - 반복문/식 ( for )
반복문/식 ( for )코드를 반복해서 실행시키고 싶을 때 for 키워드를 사용할 수 있습니다.for 도 반복문(statement)로 사용할 수 있고 반복식(expression)으로 사용할 수 있습니다!반복식으로 사용할 수 있다면 for 을 사용하면 리턴값이 있을 수
37.[Scala] Scala 기초 - 객체지향 프로그래밍 Object Oriented Programming
객체지향 프로그래밍 Object OrientedProgramming7.1 클래스 ClassScala는 객체지향 프로그래밍을 지원하기 위해 클래스를 제공합니다. 타 언어와 비교했을때 더 간소한 문법을 가지고 있습니다.기본적으로 Java와 같은 keyword를 사용하는 특
38.[Scala] Scala 기초 - 함수형 프로그래밍 (Functional Programming)
함수형 프로그래밍 (FunctionalProgramming)8.1 소개함수형 프로그래밍은 순수 함수(pure functions) 와 불변값(immutable values) 를 위주로사용해서 어플리케이션을 만드는 프로그래밍 스타일입니다. 수학을 하는 것처럼 코딩을 하는
39.[Scala] Scala 기초 - 예외처리 (Exception Handling)
예외처리 (Exception Handling)9.1 try-catch-finally blockScala 예외 처리의 기본적인 구조는 Python 이나 Java 와 비슷하지만 사용하는 키워드가약간 다르고 케이스 클래스와 패턴매칭을 사용합니다.var text = ""try
40.토스 채용공고로 알아보는 데이터 엔지니어 역량
Data Analytics Engineer토스인컴 소속정규직초기 멤버토스인컴을 소개해 드려요토스인컴은 토스커뮤니티의 새로운 계열사로 소득 및 세무와 관련된 서비스를 제공하기 위해 2024년 6월에 출범했어요.세무는 고객이 매일 써야 하는 금융 서비스는 아니지만 금융 생
41.[JVM] JVM이란, JVM이 사용되는 이유
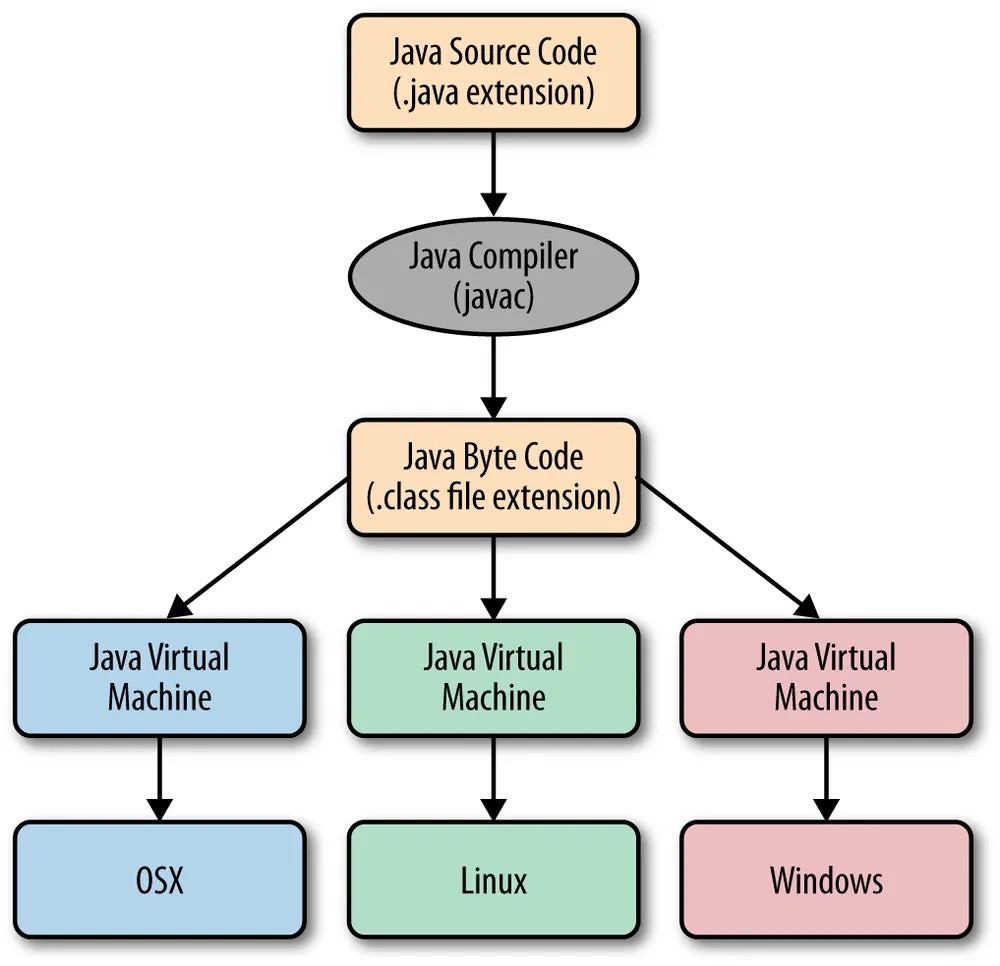
Java Virtual Machine 의 약자. Java 언어로 작성된 프로그램이 돌아갈 수 있는 가상 머신을 의미한다. 그 자체로 하나의 컴퓨터 처럼 동작한다. 내부적으로 thread 자원을 관리하고, 메모리도 주어진 메모리 안에서 알아서 관리한다.JVM이 이해할 수
42.[JVM] JVM의 메모리
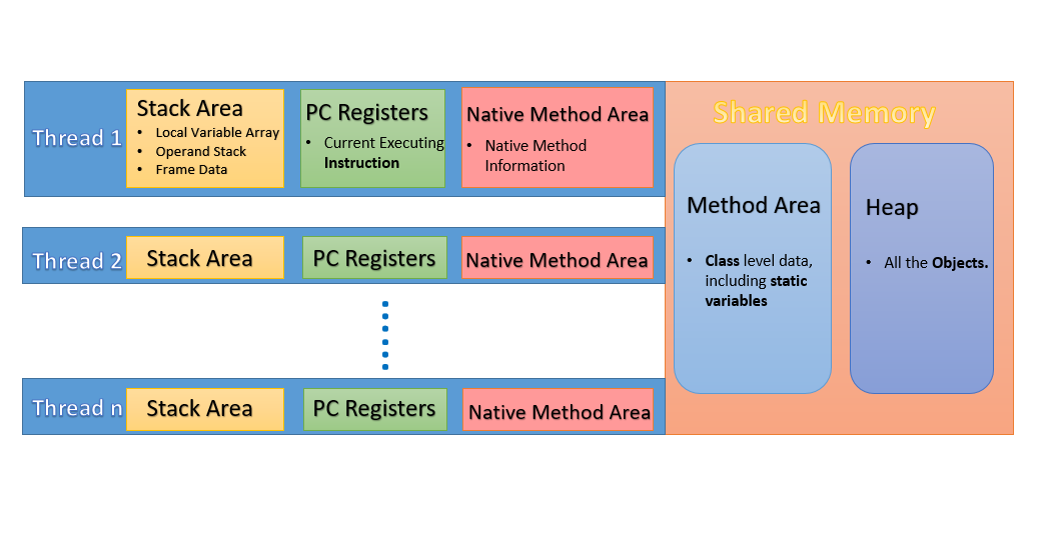
JVM에서 스레드를 생성하면 stack 영역이 기본적으로 생성된다. 해당 스레드 안에서만 사용할 수 있는 stack 자료구조이다.Local Variable Array: 해당 스레드가 실행하면서 필요한 지역변수를 array로 저장한다.Operand Stack: 계산의 중
43.[JVM] JVM의 GC
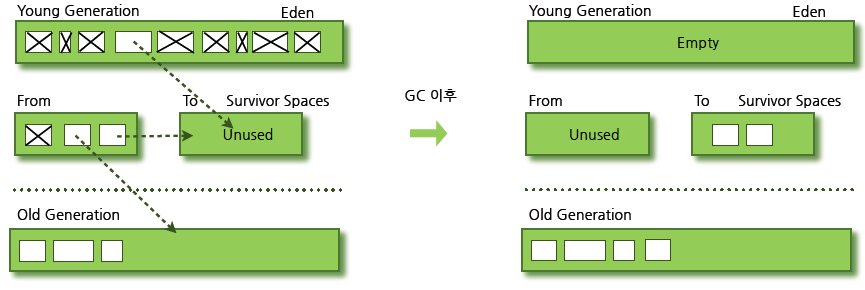
New object는 Young Generations의 Eden에서 생성된다.Eden 이 가득차면 minor GC가 발생한다.이때 Eden 에서 살아남은 객체는 Suvivor 영역 중 비어있는 영역으로 이동한다.이때 Survivor(from) 에서 살아남은 객체중 오래
44.[JVM] JMX란
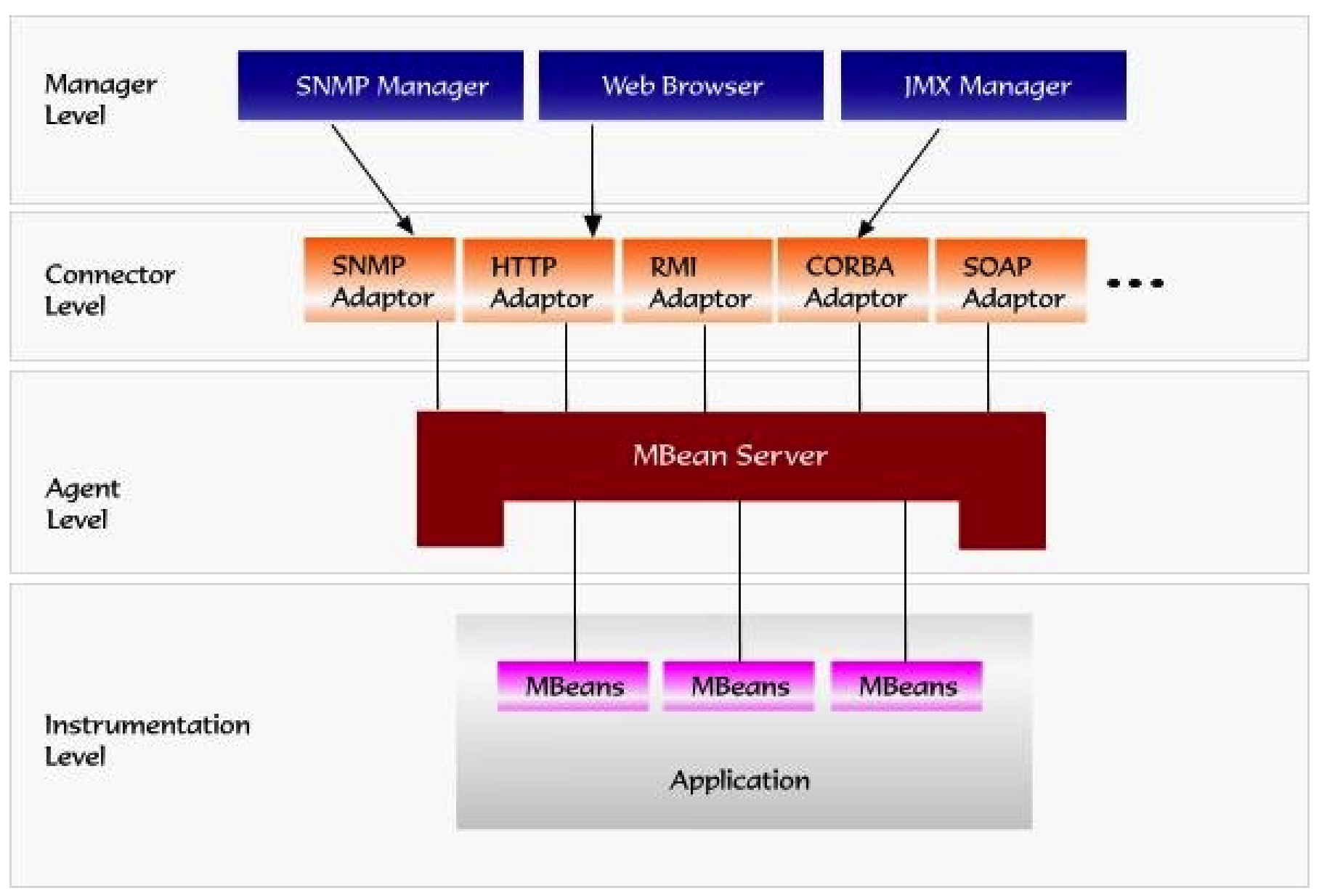
Java Management Extensions 의 약자. JMX는 JVM에서 구동하는 어플리케이션의 상태, JVM의 시스템 상태를 모니터링하기 위한 도구를 제공하는 Java API이다.JMX를 이용해서 JVM내부의 상태를 모니터링 할 수 있고, 다른 메트릭 시스템과
45.[JVM] JVM 모니터링

JVM의 현재의 thread 상태를 파일로 기록하는 것이다. 어떤 스레드 그룹이 있는지, 각 스레드의 상태(running, wait), 각 스레드가 실행하고 있는 클래스 파일 등을 볼 수 있다.갑자기 CPU 사용율이 치솟거나, 스레드 자원을 할당하지 못해서 프로그램이
46.[웹 서비스와 데이터의 이해] 인터넷과 웹
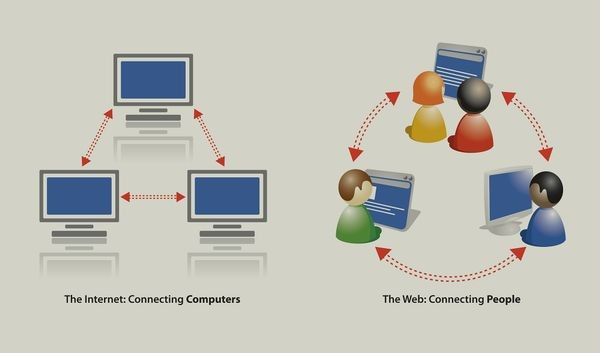
Inter-network 의 줄임말. 컴퓨터와 컴퓨터 사이의 연결을 의미.통상적으로는 국경의 구분 없이 컴퓨터 사이에 연결이 가능한 것을 인터넷이라고 칭함.보이지 않는 인터넷 상(서로 컴퓨터들과 연결된 네트워크 상)에서 접근할 수 있는 콘텐츠의 모음World Wide
47.[웹 서비스와 데이터의 이해] Server-Client 모델
Server-Client 모델2.1 웹사이트에 접속할 때 일어나는 과정2.2 Server - Client 의 의미2.2.1 Server - Client 의 의미둘다 서로간의 역할(Role)로서의 정의이다.Client: 요청을 하는 쪽Server: 요청에 응답하는 쪽2.
48.[웹 서비스와 데이터의 이해] API
상황: 고객이 식당(서버)에 들어가 메뉴판(API 문서)을 보고 정확하게 주문(요청)을 한다.고객: “김치찌개 하나 주세요.”점원: “네, 알겠습니다.”(조리 후 음식 제공)점원: “김치찌개 나왔습니다.”→ 요청 형식도 정확했고, 식당도 해당 요청을 이해하고 정확한 응
49.[웹 서비스와 데이터의 이해] 웹사이트에 접속할 때 일어나는 과정 - 컴퓨터공학적 설명
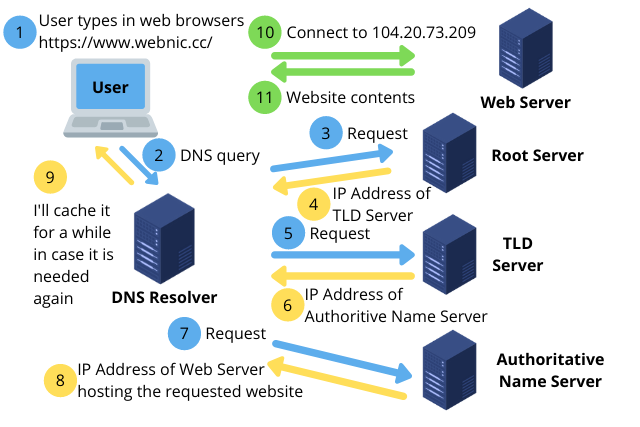
웹사이트에 접속할 때 일어나는 과정 - 컴퓨터공학적 설명4.1 배경지식 OSI 7 Layer4.2 과정1\. 입력한 주소(예: naver.com)를 운영체제가 알고 있는 DNS에 조회한다. 주소에 맞는 IP주소를 얻어온다.2\. 네트워크 통신할 메세지를 만든다. App
50.[웹 서비스와 데이터의 이해] 웹서비스에서 발생하는 데이터의 종류와 특징
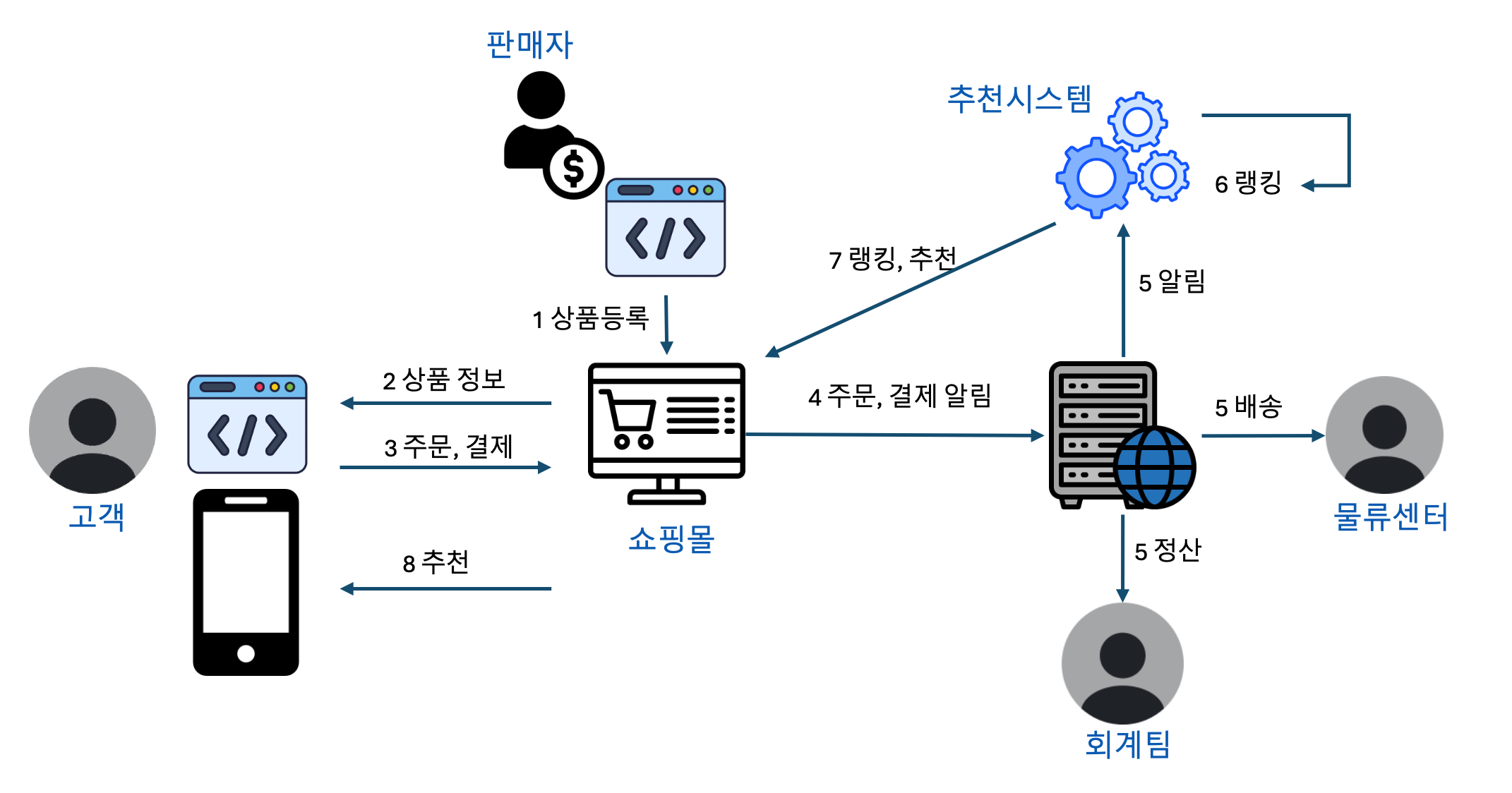
5 웹서비스에서 발생하는 데이터의 종류와 특징5.1 Use Cases5.2 서버 엔지니어가 다루는 데이터데이터 엔지니어링의 특수성이 어디서 나오는지 구분하기 위해서 데이터의 성격을 구분한 것이다.꼭 서버 엔지니어는 이런 데이터만 다루고, 데이터 엔지니어는 어떤 데이터만
51.[RDBMS / JDBC를 이용해 데이터 처리하기] RDBMS란
1 RDBMS란1.1 RDBMS의 정의Relational Database는 Relational Model(관계형 모델)을 기반으로한 데이터베이스를 의미한다. RDBMS는 Relational DatabaseManagement System이다. RDB를 이용할 수 있는 총
52.[RDBMS / JDBC를 이용해 데이터 처리하기] SQL 기초
SQL은 RDBMS 종류의 데이터베이스 뿐만 아니라, NoSQL, 빅데이터용 도구들에서도 지원하기 때문에 기본적인 사용법은 알고 있어야한다.💡 SQL 문법의 표준ANSI SQL을 표준 SQL이라고 한다. DB의 종류마다 ANSI의 규칙의 일부를 지키지 않는 것도 있지
53.[RDBMS / JDBC를 이용해 데이터 처리하기] JDBC
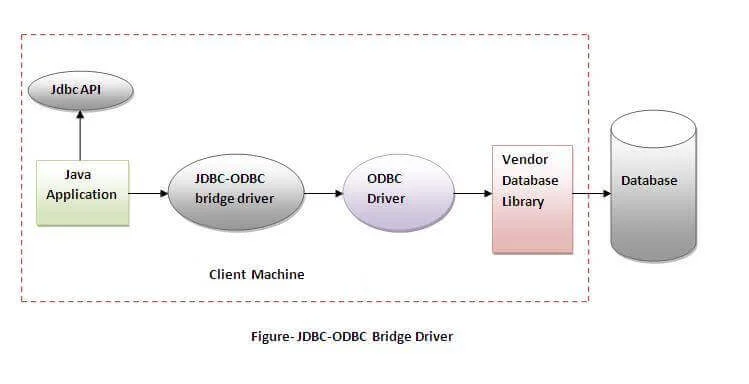
JDBC: Java Database Connectivity데이터 베이스 종류별로 써야하는 클라이언트 라이브러리, 클래스, 함수가 모두 다르다면 어떻게 될까?요구사항은 같은데 (데이터 조회, 업데이트, 삭제) 매번 써야하는 함수가 다르다면 데이터베이스를 바꿀 때마다 모든
54.[RDBMS / JDBC를 이용해 데이터 처리하기] JDBC 실습
4 JDBC 실습 4.1 실습 세팅 4.1.1 실습 세팅 - 실습용 scheam, Table 만들기 Workbench 또는 MySQL CLI 에서 다음 명령어로 실습에 필요한 schema, table, data 를 만든다. 4.1.2 실습 세팅 - MySQL, JDB
55.[RDBMS / JDBC를 이용해 데이터 처리하기] Transaction
Transaction은 데이터베이스에서 하나의 작업 단위를 말한다.Transaction 작업 단위는 ACID 라는 특징을 반드시 가져야 한다.Atomicity 모두 성공하거나, 모두 실패예: 하나의 작업의 단위에서 4개의 update가 이루어져야 하는데, 마지막 upd
56.[RDBMS / JDBC를 이용해 데이터 처리하기] ORM
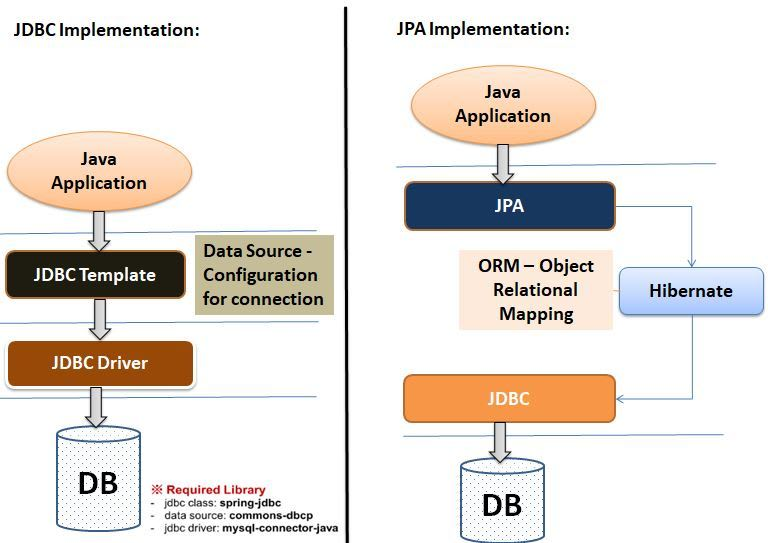
ORM(Object-Relational Mapping)이란, 앞서 살펴본 JDBC에서 ResultSet과 POJO 클래스(Plain Old Java Object)를 수동으로 매핑하는 코드를 매번 작성하는 것이 번거롭기 때문에 만들어진 기술(라이브러리)이다.즉, ORM은
57.[SpringBoot] Java 8버전 스프링부트 프로젝트 만들기(2.x버전 프로젝트)
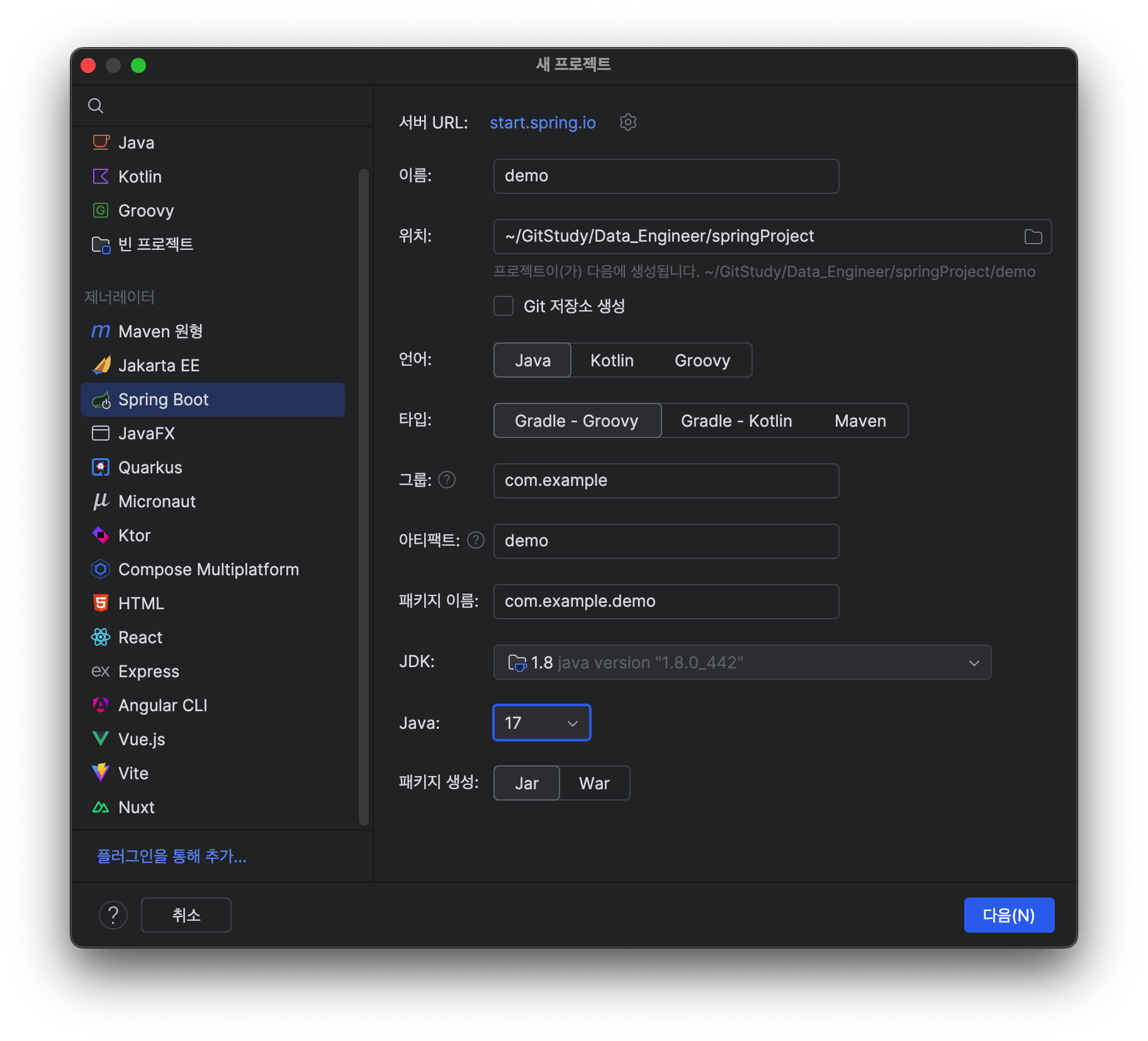
Spring Data JPA를 활용한 실습을 하려고 했는데 오류가 발생했다.내가 설치한 JDK 버전은 1.8이기 때문에 이대로 다음을 누른다면 이렇게 오류 메세지가 나온다.선택한 버전은 SDK1.8에서 지원되지 않고 상위 버전의 SDK를 선택하라는 메세지가 나온다.혹은
58.[NoSQL(MongoDB) 이용해 데이터 관리하기] NoSQL의 개념과 사례
1 NoSQL의 개념과 사례1.1 NoSQL 개념원래는 non-SQL 또는 non-Relational 데이터베이스 종류를 지칭하기 위해서 생긴 용어이다. 하지만 IT 산업 전반에 걸쳐서 SQL의 활용도가 높기 때문에 NoSQL 데이터베이스인데도 오히려 SQL을 지원하는
59.[NoSQL(MongoDB) 이용해 데이터 관리하기] MongoDB의 기본 개념과 기능
2 MongoDB의 기본 개념과 기능들2.1 Document2.1.1 Document란MongoDB에서 데이터를 저장하는 단위는 Document이다. 각 Document의 형식은 미리 지정되어있지 않고, 생성 시점에 어떤 형식의 내용이 와도 된다. 같은 Collecti
60.[NoSQL(MongoDB) 이용해 데이터 관리하기] MongoDB Operations
3 MongoDB Operations3.1 실습 세팅3.1.1 의존성 추가프로젝트를 새로 만들고, build.gradle 에 다음 의존성을 추가해준다.dependencies {implementation 'org.mongodb:mongodb-driver-sync:4.7.
61.[CacheDB로 응답시간 빠르게 만들기] CacheDB 이해하기
Cache 란, 미래의 사용 될 데이터를 빠르게 조회할 수 있는 곳(물리적 장소 또는 소프트웨어로 구현된 위치)에 두고서 사용하는 것을 말한다. 보통 원본 데이터는 다른 곳에 있고 그것으로부터 copy된 데이터가 Cache에 존재한다.Cache hit : 조회하는 데이
62.[CacheDB로 응답시간 빠르게 만들기] Redis 의 대표적인 자료 형식과 기능
2 Redis 의 대표적인 자료 형식과 기능 >Redis 자료구조 실습은 cli를 통해서 진행한다. 자료구조 실습을 위한 설치는 다음 문서를 참고한다. >실습에서 다루는 commands는 해당 자료구조의 모든 commands를 포함하지않는다. 대표 commands를
63.[CacheDB로 응답시간 빠르게 만들기] Redis 사용과 운영
Redis는 In-Memory Database이다. Memory는 가격이 비싸고, 한 Node당 가질 수 있는 용량이 Disk에 비해서 한계가 있으므로 용량의 관리가 중요하다. Memory에 저장된 데이터는 컴퓨터가 종료되면 사라지므로(volatile), 정상/비정상
64.[DNS로 서비스 노출하기] DNS의 원리
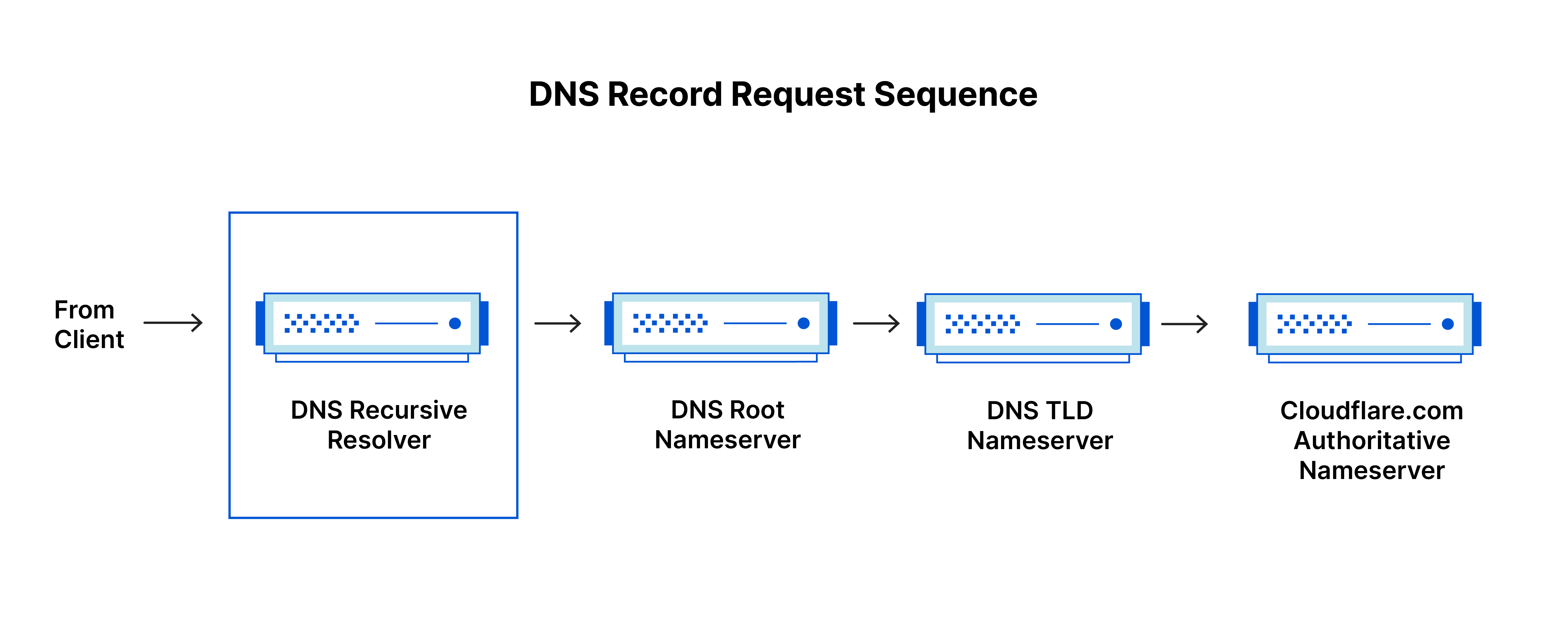
DNS는 사람이 기억하기 쉬운 도메인 이름(hostname)을 컴퓨터가 인식할 수 있는 주소(IPaddress)로 변환해주는 서비스/시스템 이다. google.com, naver.com 의 주소를 브라우저에 입력하면, 각각 google의 서버, naver의 서버로 연결
65.[DNS로 서비스 노출하기] AWS에서 DNS 사용하기
공식문서1\. Route53 Dashboard(https://us-east-1.console.aws.amazon.com/route53/v2/home?region=us-east-12. Register Domain 에서 원하는 도메인 이름을 입력하고 Check3\
66.[DNS로 서비스 노출하기] GSLB - 안정적인 서비스를 위한 DNS 설정
대표적으로 다음과 같은 브랜드/제품들이 GSLB를 제공하고 있다.1\. AWS, GCP, Azure2\. Akamai3\. Cloudflare4\. Citrix5\. NGINX6\. (국내)NCloud7\. (국내)NHNCloudGSLB는 Gloabl Server Lo
67.[DNS로 서비스 노출하기] AWS Route53에서 Routing 설정하기
AWS에서는 GSLB라고 따로 정의한 상품이 있지는 않지만, Route53의 라우팅 정책을 통해서 GSLB의 기능적인 목표를 달성할 수 있다.공식 문서연결 대상인 서비스(DNS/IP/Server)로 연결이 되지 않을 때, 설정한 대체 서비스로 연결하도록 한다.장점예상치
68.[LoadBalancer로 트래픽 분산하기] - LoadBalancer의 개념과 필요성
컴퓨터관련 분야에서 로드밸런싱이란, 어떤 작업을 컴퓨팅 리소스 단위로 분산해서 처리하는 것을 로드밸런싱이라고 한다. 부하가 한 곳에서 처리할 수 있는 용량을 넘으면 처리를 하지 못하거나, 처리가 기대보다 늦어지기 때문에 이것을 방지하기 위해서 부하를 분산하는 방법을 찾
69.[LoadBalancer로 트래픽 분산하기] - LoadBalancing 방법
부하를 분산해주려면 미리 어떻게 분산할 것인지 규칙이 필요하다. 웹서비스 트래픽에서 사용할 수 있는 대표적인 로드밸런싱 방법을 알아보자.라운드로빈은 말 그대로 순서대로 하나씩 돌아가면서 나눠주는 것이다. 사전 지식이 없더라도 누구나 가장 먼저 생각해볼만한 개념이다. 가
70.[LoadBalancer로 트래픽 분산하기] - LoadBalancer 동작원리와 설계
현대 LoadBalancer는 그 자체가 하나의 시스템이다. 외부적으로는 하나의 IP만 존재하기 때문에 하나의 서버같지만, 하나의 IP만으로도 수년동안 안정적인 운영이 가능하도록 한다.DNS형태로 서비스를 제공하는 LB도 있다.LoadBalancer가 연결을 전달하기
71.[LoadBalancer로 트래픽 분산하기] - AWS Elastic LoadBalancer 사용하기
공식 문서AWS에는 3가지 타입의 LoadBalancer가 있다.Classic Loadbalancer 는 retired 되었다.L4 레이어의 정보로 트래픽을 분산해주는 LoadBalancer.L4 레이어의 정보로 트래픽을 분산하는 것으로 충분한 경우에 사용한다. 분산규
72.[웹서버로 콘텐츠 구분해서 서빙하기] 웹서버가 필요한 이유
https://www.nginx.com/blog/inside-nginx-how-we-designed-for-performance-scale/https://www.nginx.com/blog/deploying-nginx-plus-as-an-api-gate
73.[웹서버로 콘텐츠 구분해서 서빙하기] NGINX 시작하기
EC2 서버에 접속해서 다음 명령어로 nginx를 설치한다.upgrade 도중 kernel 업그레이드가 필요하다고 나온다면, yes 를 선택하고, restart 대상 package 를 선택해야한다는 창이 나오면 모두 선택한 뒤 OK를 누른다.방향키, 스페이스, 탭, 엔
74.[웹서버로 콘텐츠 구분해서 서빙하기] NGINX의 대표적인 기능들
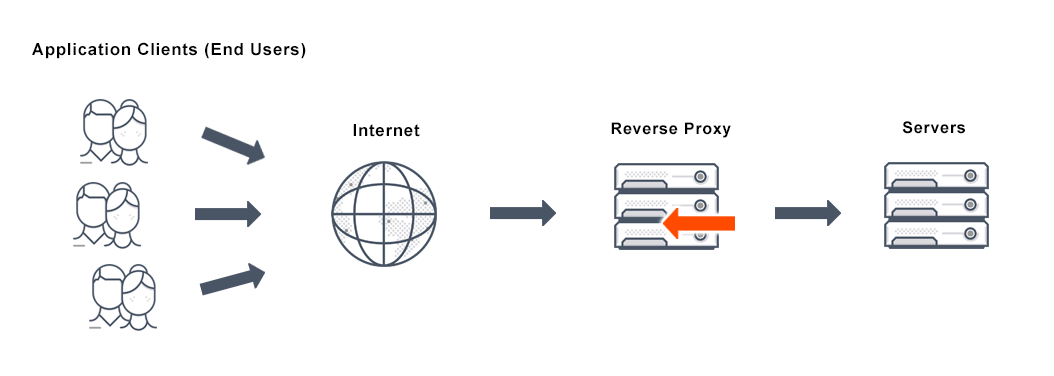
image source : https://zoidsec.medium.com/breaking-parse-logic-gain-access-to-nginx-api-read-write-upstreams-1cb062aa44caReverse proxy는 네트워크의 inb
75.[웹서버로 콘텐츠 구분해서 서빙하기] NGINX 로그의 이해와 활용
WEB 요청에 대한 로그이다. 어플리케이션의 주요 내용과는 관련 없이 프로토콜 정보, client 정보, upstream 서버 정보, 응답시간, 콘텐츠 사이즈 등의 정보를 나열하여 간략하게 볼 수 있다.access log 에 대한 형식만 맞춘다면, 어플리케이션이나 구현
76.[웹서버로 콘텐츠 구분해서 서빙하기] NGINX 동작 원리
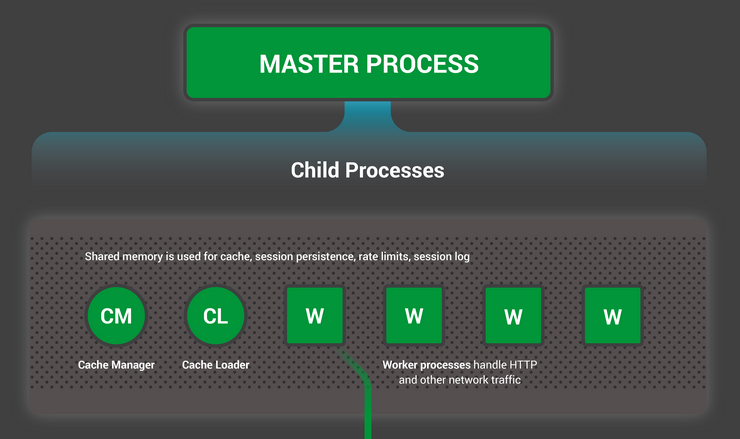
5 NGINX 동작 원리참고자료5.1 NGINX process model 과 기본 기능5.1.1 Master ProcessNGINX를 실행시키면 가장 먼저 실행되는 프로세스이다. 이하에 나오는 다른 역할의 프로세스들을 시작시키는 역할 또한 한다.Master Proces
77.[웹서버로 콘텐츠 구분해서 서빙하기] NGINX를 활용한 System Architecture
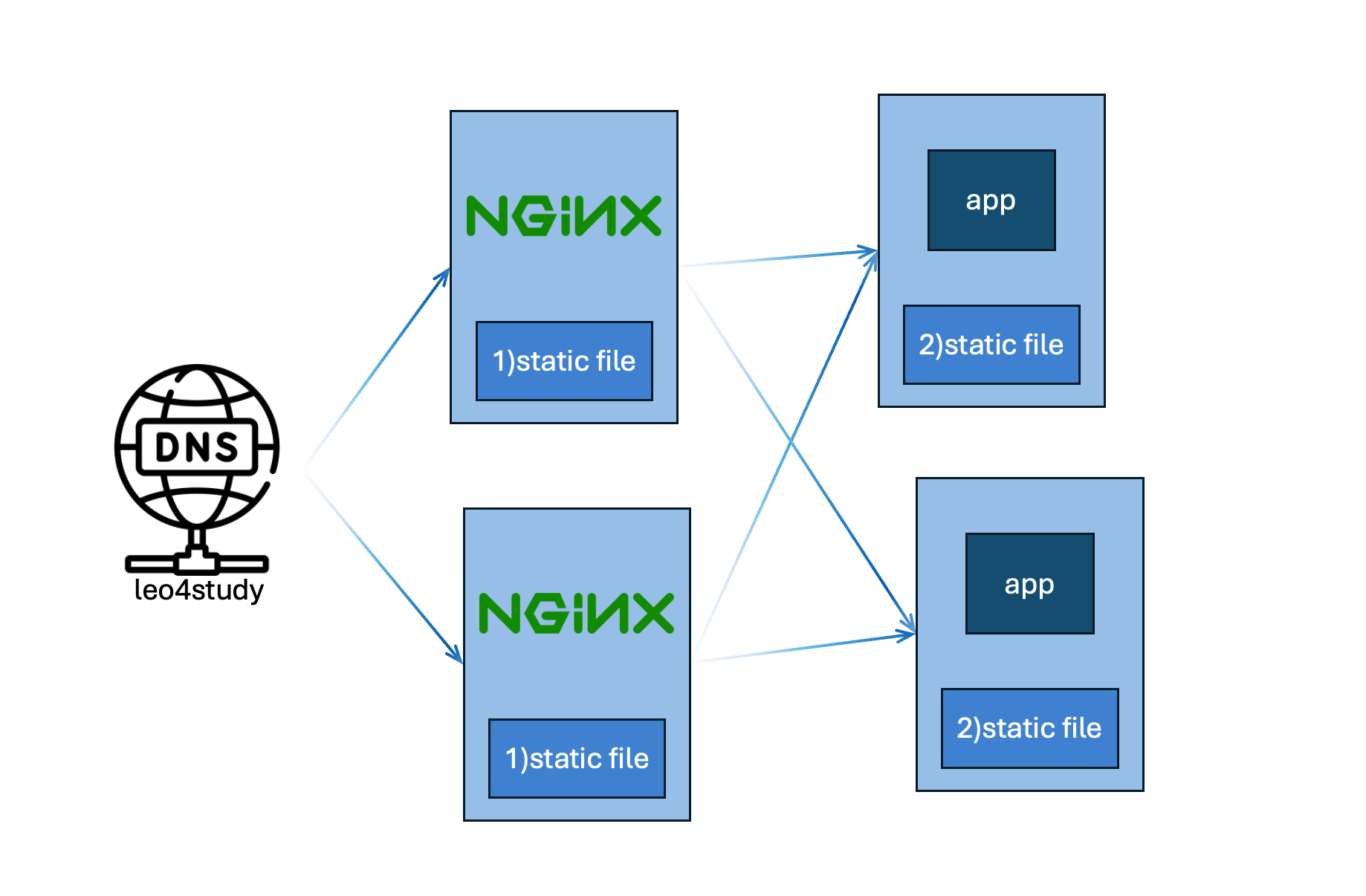
요구사항을 던져보고, 요구사항별로 Web Server(NGINX)를 활용한 시스템 아키텍처를 어떻게 구성하는 것이 문제를 풀 수 있는지 살펴본다.인프라의 특성상, AWS에서 본 것처럼 Loadbalancer 제품을 이용 못하고, 오직 PM으로만 구성해야하는 환경의 제약
78.[웹서버로 콘텐츠 구분해서 서빙하기] systemd,systemctl 로 nginx process 관리하기
7 systemd,systemctl 로 nginx process 관리하기 위에서 NGINX는 systemd 로 관리되는 프로그램이라고 했다. 그렇다면 systemd는 무엇이지, systemd 로 관리되는 process의 관리방법을 배워본다. 7.1 systemd와 s
79.[API Gateway] API Gateway 기초
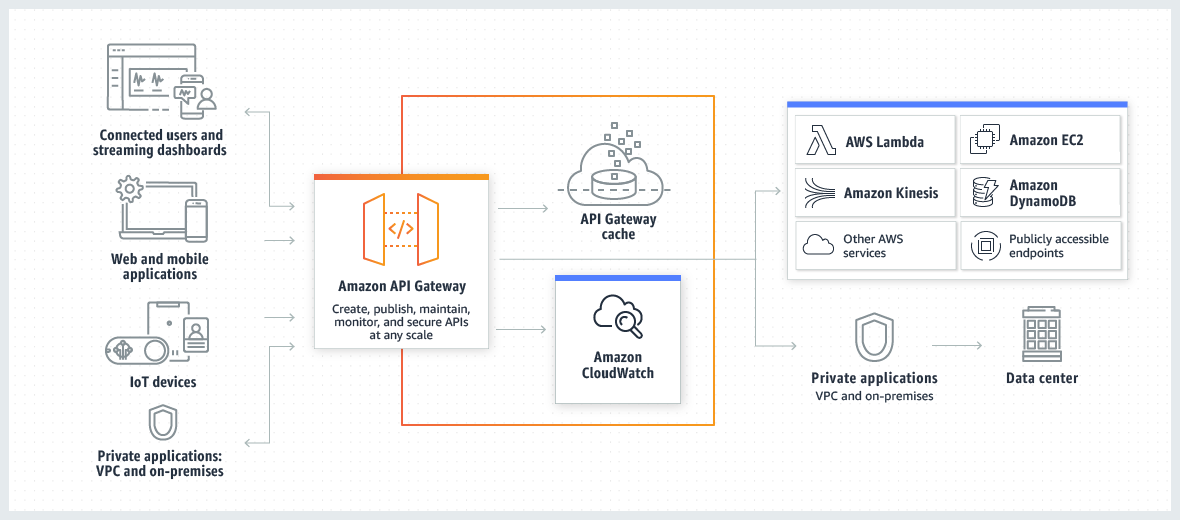
image source : https://docs.aws.amazon.com/apigateway/latest/developerguide/welcome.html하나의 입구에서 다양한 API(Application Programming Interface)의 요청을
80.[API Gateway] AWS API Gateway
강의자료 P04-C07 웹서버로 콘텐츠 구분해서 서빙하기 > 2.3 실습 세팅 과 같이 두대의 EC2 서버에/user, /customer 를 서빙하는 application을 띄운다. 포트번호는 기본(9000).https://console.aws.amazon.c
81.[EFK로 서버 로그 수집하기] 로그를 수집하는 이유
1 로그를 수집하는 이유 1.1 로그란? 1.1.1 로그의 의미 Log 란, 컴퓨터가 수행하는 도중 유의미한 내용을 남기는 기록을 말한다. 통상 파일로 남기는 기록을 말한다. 1.1.2 로그의 내용 로그에는 통상 다음 내용이 들어가야 한다. 로그를 남긴 시간 로그 레
82.[EFK로 서버 로그 수집하기] 로그 수집 아키텍처

어플리케이션에서는 로그를 파일로만 남긴다. 어플리케이션과는 별도로 파일로부터 수집해서 전송하는 프로세스를 만들어서 전송하는 방식.어플리케이션과 로그 수집기가 관심사의 분리(SoC)가 된다. 아키텍처 상으로 역할과 동작이 구분되므로 유연성이 높아진다.컨테이너 환경을 이용
83.[EFK로 서버 로그 수집하기] Fluentd로 로그 파싱하고 보내기
https://docs.fluentd.org/installation/before-install 해당 매뉴얼을 따라서 system 설정을 바꿔야한다. 자신의 값에 따라서 reboot 이 필요할 수도 있다.Gem이외에 다른 방법도 있다. 설치 매뉴얼Ruby gem
84.[EFK로 서버 로그 수집하기] Opensearch(Elasticsearch)로 로그 저장하기
강의에서는 Opensearch, Open Dashboard - 2.4.0 버전을 사용한다.이 강의에서는 기본적인 설치만 다룬다. 더 자세한 설치와 설정 방법은 매뉴얼을 참고.기본설치는 다음 특징을 갖는다.single mode권한이 없다tls 사용안함설정을 Open Da
85.[EFK로 서버 로그 수집하기] Open Dashboard로 로그 시각화하기
5. Open Dashboard(Kibana)로 로그 시각화하기 5.1 Open Dashboard 설치하기 5.1.1 다운로드 및 설치 다운로드 링크 에서 자신의 환경에 맞는 바이너리 다운로드 압축 해제 (자신의 architecture 별로, 일반 EC2라면 x64
86.[RDBMS 구조와 동작 방식] RDBMS Architecture
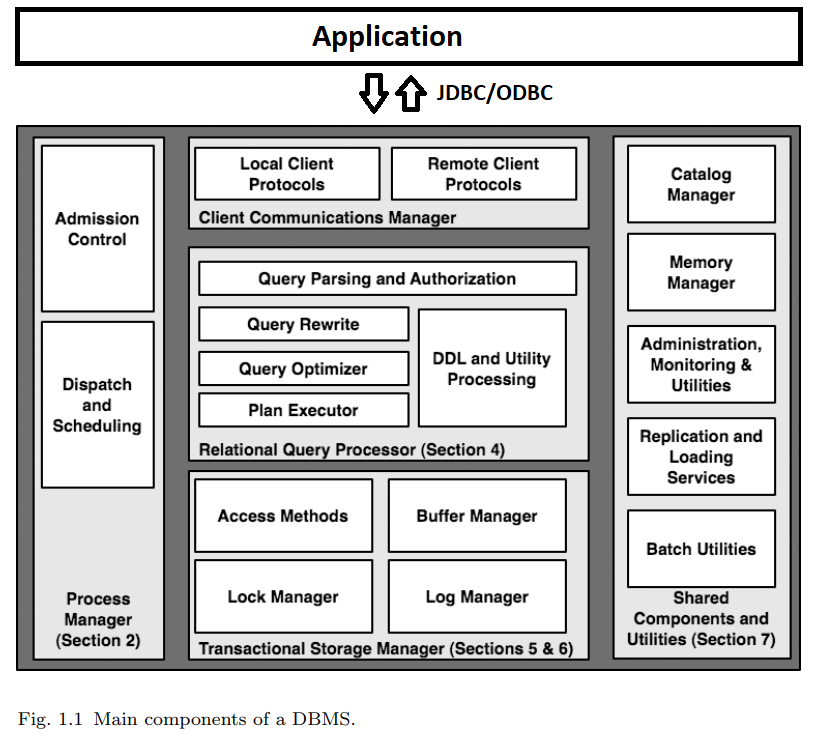
image source : https://payasr.github.io/redbase-spatial/post/architect-dbms/외부의 Client 에서 접속하고, 명령을 전달할 수 있는 통로. 그리고 그 자원의 관리.Client 로부터의 연결을 받는다
87.[RDBMS 구조와 동작 방식] MySQL Architecture
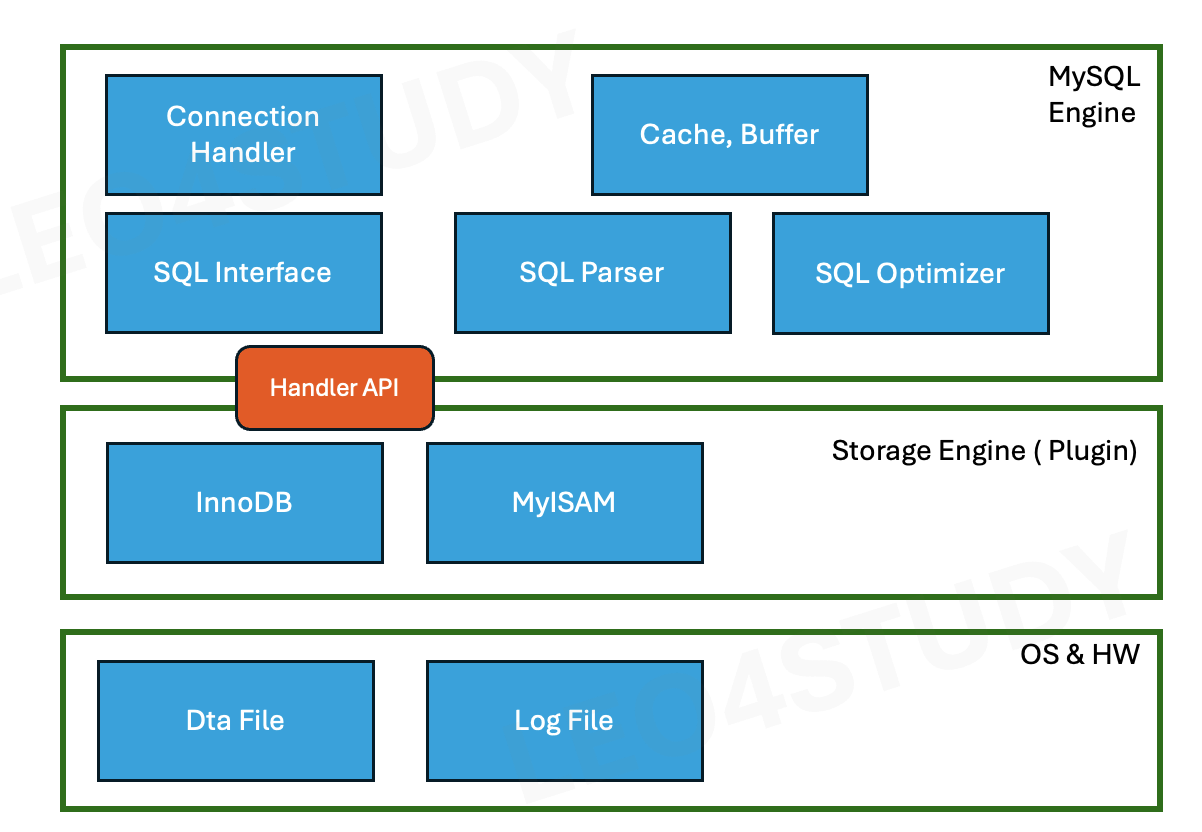
MySQL 서버의 내부 구조MySQL Engine은 클라언트로부터의 요청을 받고, SQL을 분석하고 최적화하는 역할을 수행한다.클라이언트로부터의 접속, 쿼리요청 처리SQL을 받아준다.SQL을 파싱하고, 전처리를 한다.쿼리 최적화와 실행계획을 짠다.MySQL Storag
88.[Application Monitoring] Application Metric 대시보드 만들기
2 Application Metric 대시보드 만들기 2.1 Memory 지표 2.1.1 JVM heap usage 2.1.2 App memory usage (amount) 사용량(heap + offheap) 2.1.3 App memory usage (%) 사용량
89.[Application Monitoring] Custom Metric 구현하기
한 번 선언된 메트릭은 static으로 JVM 내에서 global 영역에 존재해야 한다.builder pattern 으로 설정한다.label 이 있다면 string varags 로 세팅한다.label 은 사용할때 순서대로 맞춰넣어야 하므로 순서가 중요하다.registe
90.[data architecture] Star-Schema vs Snowflake Schema
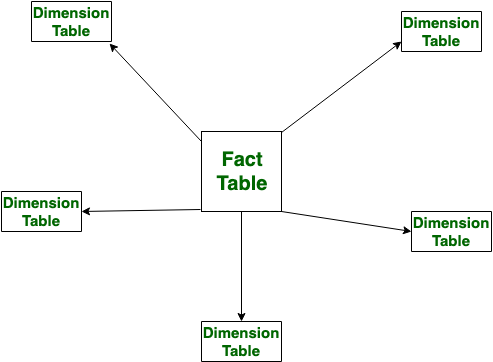
Star Schema(스타 스키마)는 데이터 웨어하우스 설계 방식 중 하나로, 주로 OLAP(Online Analytical Processing) 환경에서 다차원 분석을 위한 데이터 모델링 구조로 사용된다.중심에 사실 테이블(Fact Table)이 있고, 이를 둘러싼
91.[data quality] 데이터 정합성 검증, DQ(Data Quality) 모니터링
동일한 데이터가 여러 위치(테이블, 시스템, DB 등)에 존재할 경우, 해당 값들이 논리적으로 일치하고 모순되지 않음을 보장하는 상태.예를 들어, 주문 시스템과 배송 시스템 모두에서 고객의 주소가 동일하게 유지되어야 함.예시 정합성 있음정합성 없음금융권에서는 매일 정산
92.[data architecture] Data Mesh vs Data Fabric
데이터 웨어하우스(DWH)의 한계Data Lake의 도입과 특징분산형 아키텍처의 필요성 대두Mesh, Fabric의 등장 배경중앙 집중형 레이크/웨어하우스의 문제점Domain-Oriented Architecture의 부상Domain OwnershipData as a P
93.[data architecture] Medallion Architecture
Bronze: 원시 로그 저장Silver: 정제 및 조인, 품질 보정Gold: KPI, 피처 테이블, 보고용 테이블Delta Format + Spark 구조Time Travel, Schema Enforcement, Merge계좌 거래 로그 → Bronze 테이블 저장거
94.[분산 시스템의 이해] 전통적인 서버 아키텍처의 역사

(1930년대) 컴퓨터가 최초에 등장했을 때는 기계가 사람이 수기로 해야할 일을 자동으로 대신해주기만 하면 되었다. 하나의 컴퓨터 머신에 수동으로 작업을 등록하고 실행시키는 방식이었다.이후 컴퓨터 장비의 크기가 작아지고, 명령어를 입력하는 방식이 고도화 되는 방식으로
95.[분산 시스템의 이해] 분산 시스템의 특징

자원은 공유하면서, 리소스내에서 동시에 여러가지 작업을 수행한다. 동시 실행 자원을 늘려서 처리량을 늘릴 수 있다.시스템의 각 부분이 비동기식으로 동작한다.어떤 한 부분의 상태 때문에 다른 곳에 Lock, Bottleneck 이 걸리면 안된다.시스템의 한 부분의 실패가
96.[분산 시스템의 이해] 분산시스템의 대표 use case
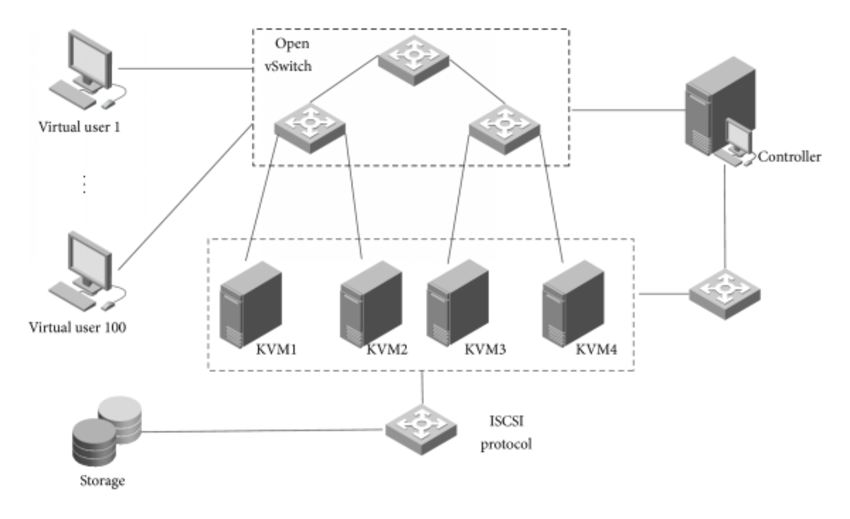
과거 Loadbalancer 는 하나 또는 두개의 고 스펙의 하드웨어 장비/스위치가 로드밸런싱을 했다.현대 LoadBalancer 에는 인스턴스가 많게는 수백~수천대 까지 연결되므로 하나의 고스펙 하드웨어로 모든 LB를 처리할 수 없다. 또한 설정이나 규칙의 변경이 잦
97.[Zookeeper] Zookeeper의 이해
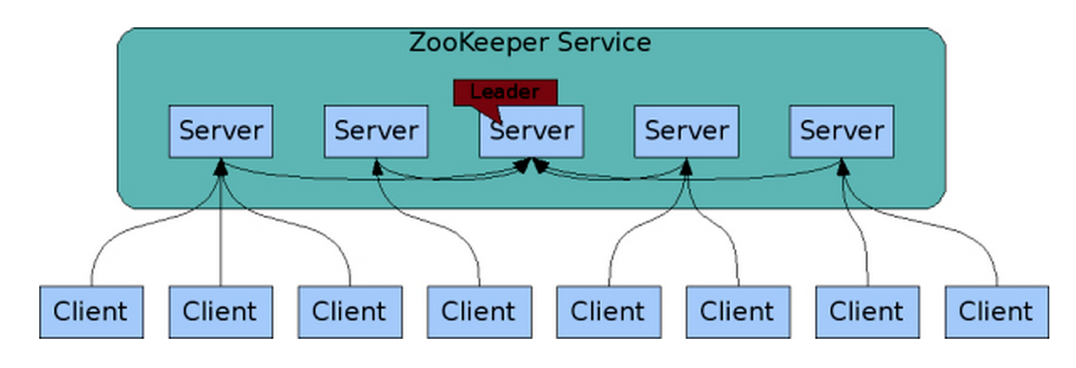
주키퍼는 분산 어플리케이션을 위한 분산 코디네이션 서비스다. 분산 어플리케이션을 만들기 위해 필요한 동기화, 설정, group, naming 에 대한 추상화된 수준의 서비스를 제공한다. 이 기능들을 API로 제공해서 사용하기 쉽고, 데이터 모델도 디렉토리구조를 하고 있
98.[Zookeeper] Zookeeper 상세 기능
ZooKeeper가 제공하는 네임스페이스는 표준 파일 시스템의 형식과 비슷하다. 이름은 슬래시(/)로 구분된 경로로 표현한다. ZooKeeper 네임스페이스의 모든 znode(데이터)는 경로로 식별된다.ZooKeeper's Hierarchical NamespaceZoo
99.[Zookeeper] Zookeeper 실습
3 Zookeeper 실습 실습에서는 Zookeeper 3.7.1 버전을 사용한다. 3.1 설치하기 3.1.1 Prerequisites System requirement: https://zookeeper.apache.org/doc/r3.3.5/zookeeperA
100.[OpenSearch] OpenSearch 구성 요소와 동작 방식
터미널에서 다음 명령어를 실행한다.설치에 성공한 경우 을 실행하면 다음과 같이 버전 정보를 확인할 수 있다.이 챕터에서의 실습은 single-node만으로 충분하다. 세부 설정은 <EFK로 서버 로그 수집하기>의 4.1.3~4.1.7을 참고하자.<EFK로 서
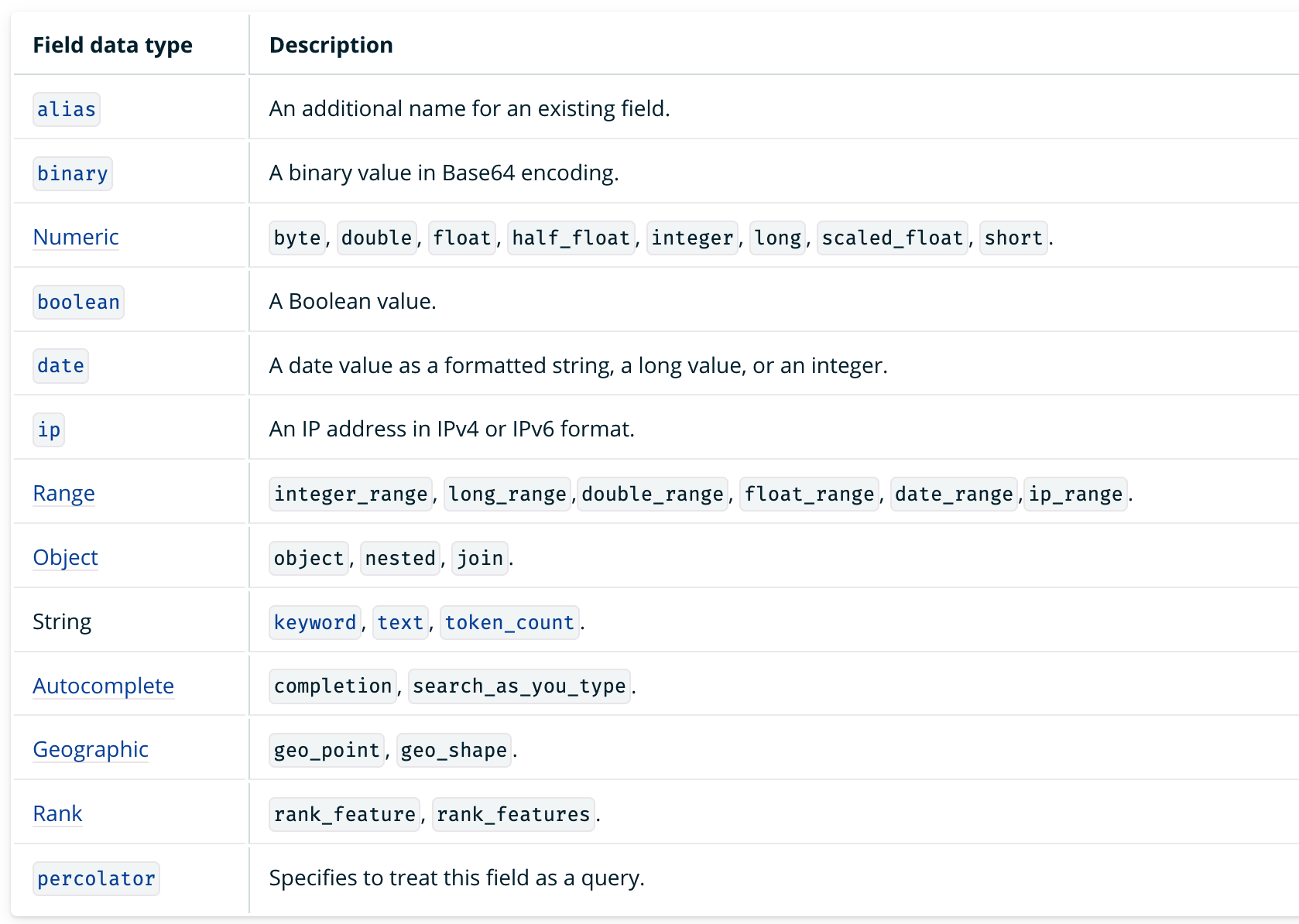
101.[OpenSearch] OpenSearch의 텍스트 인덱싱과 전문 검색
챕터 1에서 OpenSearch의 기본적인 구성 요소와 CRUD에 대해 알아봤다. 챕터 2에서는 OpenSearch의 핵심이라고 볼 수 있는 인덱싱과 전문 검색에 대해 알아보려고 한다.앞서 OpenSearch는 필드의 매핑 타입에 따라 인덱싱하는 방법이 다르다고 설명했
102.[OpenSearch] OpenSearch 클러스터 운영
챕터 1~2에서는 인덱스와 도큐먼트 CRUD, 인덱싱, 도큐먼트 검색 등 인덱스와 도큐먼트 수준에서 OpenSearch에 대해 살펴봤다. 챕터 3에서는 아키텍처 수준에서 OpenSearch의 분산 시스템 구성을 알아보고, OpenSearch가 어떻게 대량의 인덱스와 도
103.[OpenSearch] OpenSearch의 인덱스와 샤드 관리
3 OpenSearch 클러스터 운영 챕터 1~2에서는 인덱스와 도큐먼트 CRUD, 인덱싱, 도큐먼트 검색 등 인덱스와 도큐먼트 수준에서 OpenSearch에 대해 살펴봤다. 챕터 3에서는 아키텍처 수준에서 OpenSearch의 분산 시스템 구성을 알아보고, Open
104.[Data Engineering] 캐시 최적화와 캐시 무효화 전략
서버의 응답 속도는 사용자 경험에 직결되는 중요한 요소이다. 성능을 개선하기 위한 방법 중 하나로 캐시(Caching) 가 널리 사용된다. 캐시는 동일한 요청에 대해 반복적인 연산이나 I/O를 줄여줌으로써 처리 속도를 향상시킨다. 그러나 캐시가 항상 최신 데이터를 제공
105.[OpenSearch 클러스터 운영] OpenSearch의 분산 아키텍처 구성 요소
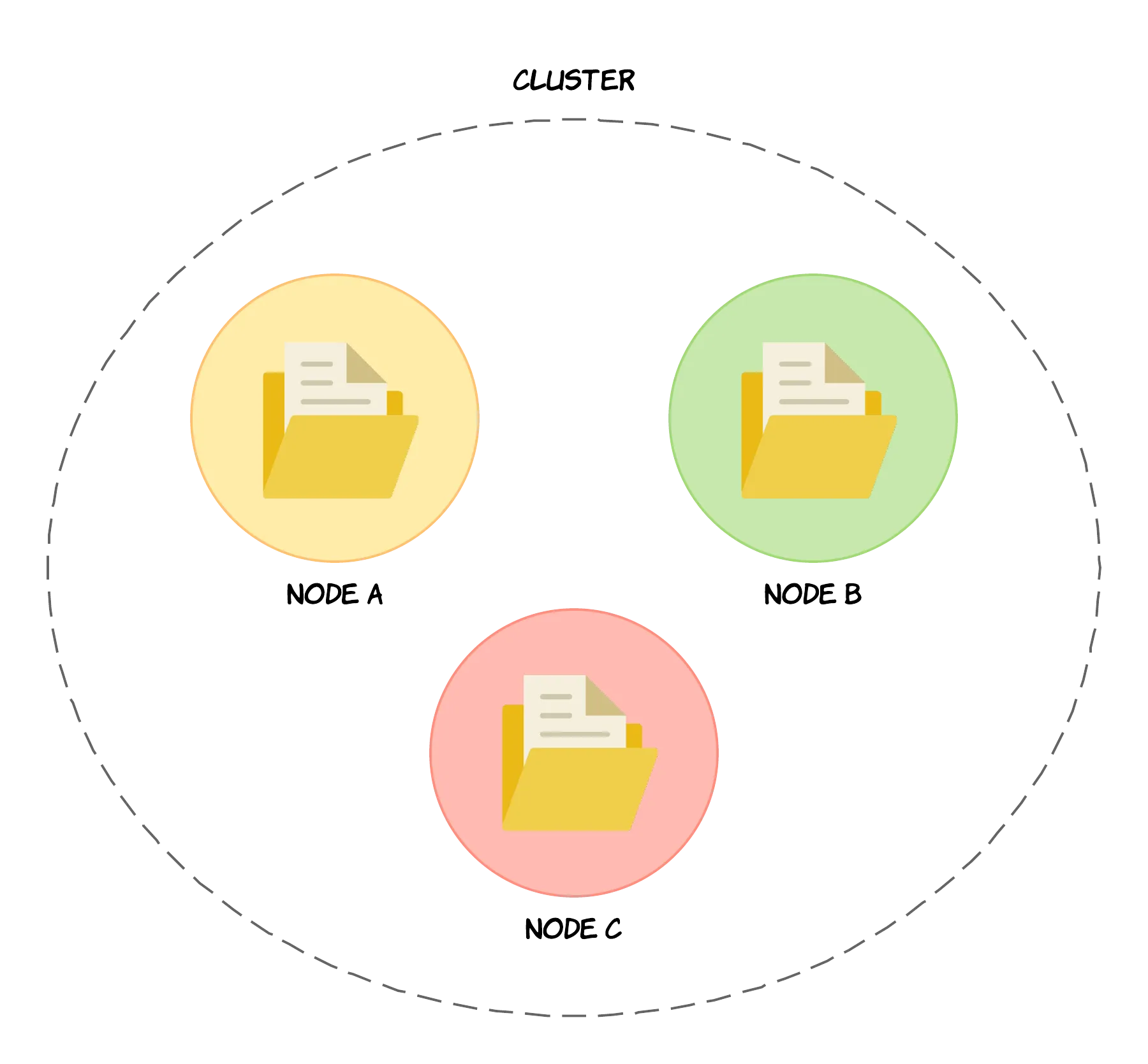
OpenSearch가 데이터를 분산 처리하기 위해 사용하는 분산 아키텍처의 핵심 구성 요소는 다음과 같다.클러스터(Cluster)노드(Node)샤드(Shard)세그먼트(Segment)출처: https://codingexplained.com/coding/elas
106.[OpenSearch 클러스터 운영] OpenSearch의 노드 타입과 역할
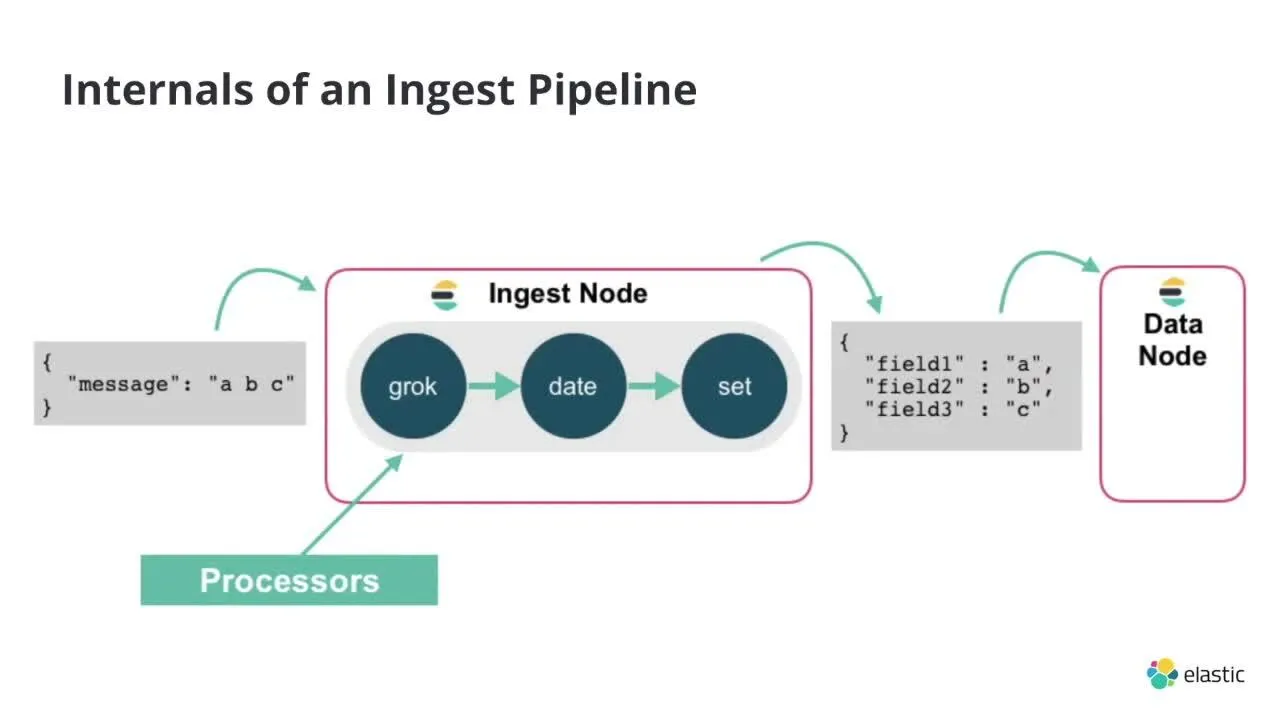
앞서 노드는 타입에 따라 수행하는 역할이 다르다고 했다. OpenSearch에서 제공하는 노드 타입에 대해 알아보자.기본적으로 모든 노드는 어떤 타입도 될 수 있으며, 다양한 역할을 수행할 수 있다. 노드에 OpenSearch를 설치하고 설정 파일을 수정하지 않으면,
107.[OpenSearch 클러스터 운영] OpenSearch의 레플리카 샤드
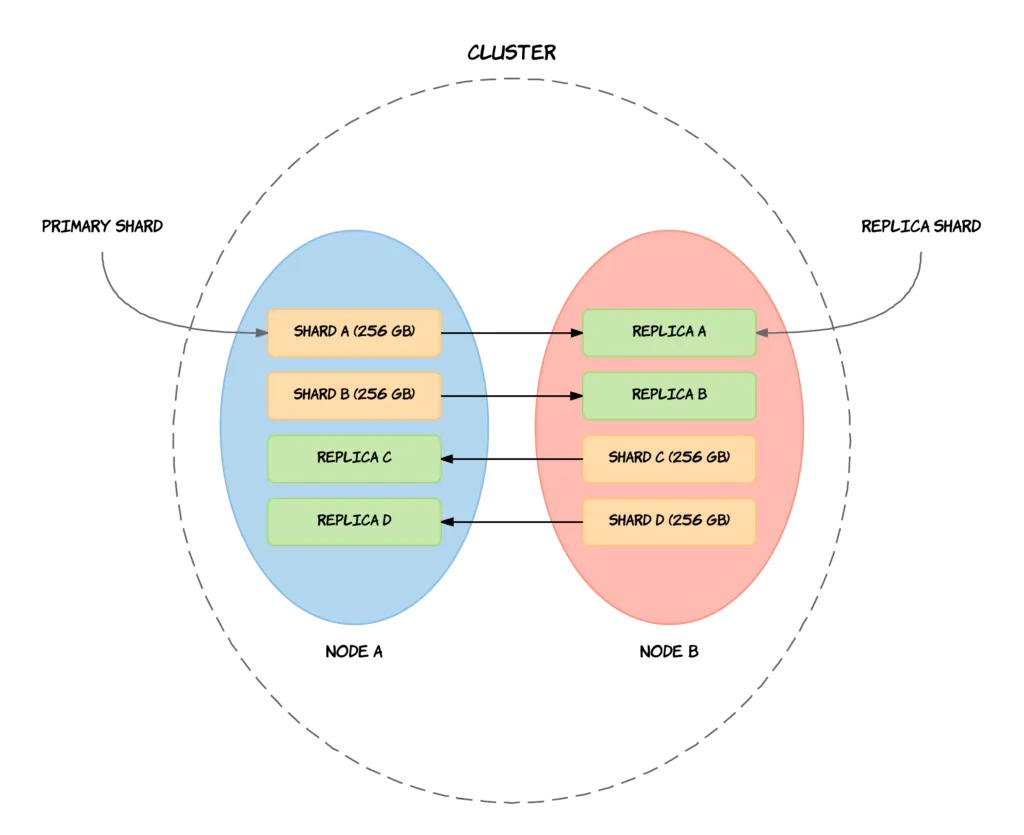
3.1.2에서 설명한 레플리카 샤드에 대해 자세히 알아보자.출처: https://codingexplained.com/coding/elasticsearch/understanding-replication-in-elasticsearch레플리카 샤드의 주된 목적은 노
108.[OpenSearch 클러스터 운영] OpenSearch 클러스터 구성 실습

Elasticvue는 다음과 같은 기능을 제공하는 OpenSearch 클라이언트다.클러스터, 노드, 샤드 상태 확인인덱스 관리REST API 인터페이스스냅샵 관리크롬 확장 프로그램으로 쉽게 설치할 수 있고, 복잡한 환경 설정이 필요 없다는 장점이 있다. 다음 링크를 클
109.분산 시스템에서 Sticky Session과 세션 관리 이해
데이터 엔지니어링을 공부한다면, 대규모 데이터 파이프라인이나 높은 가용성과 확장성을 요구하는 서비스에서 웹 애플리케이션이 사용자 세션을 어떻게 관리하는지 이해하는 것이 중요하다. 세션(Session), 로드 밸런싱(Load Balancing), 스티키 세션(Sticky
110.[OpenSearch의 인덱스와 샤드 관리] Shard allocation과 Rerouting
노드에 샤드를 할당하는 과정을 샤드 할당이라고 한다. 클러스터 매니저는 어떤 샤드를 어떤 노드에 할당하고, 언제 노드 간에 샤드 이동이 필요한지 결정한다. 샤드 할당은 다음과 같은 상황에서 발생한다.처음 인덱스를 생성했을 때인덱스의 레플리카 수를 변경했을 때클러스터에
111.[OpenSearch의 인덱스와 샤드 관리] 인덱스 라이프사이클 관리
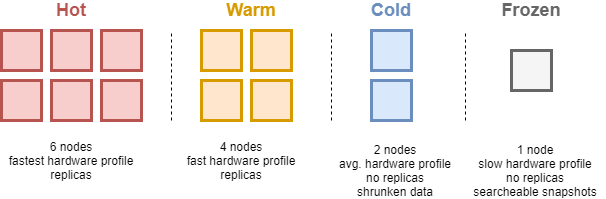
인덱스에 도큐먼트를 제한 없이 저장한다면, 인덱스의 크기는 무한히 커질 수 밖에 없다. 인덱스의 크기가 너무 커질 경우 성능 문제가 발생할 수 있으므로, 주기적으로 인덱스를 나눠주는 작업이 필요하다. OpenSearch에서는 ISM(Index State Manageme
112.[엔지니어링 설계 & 의사결정] - 중견 기업 규모의 데이터 인프라 환경 구성하기
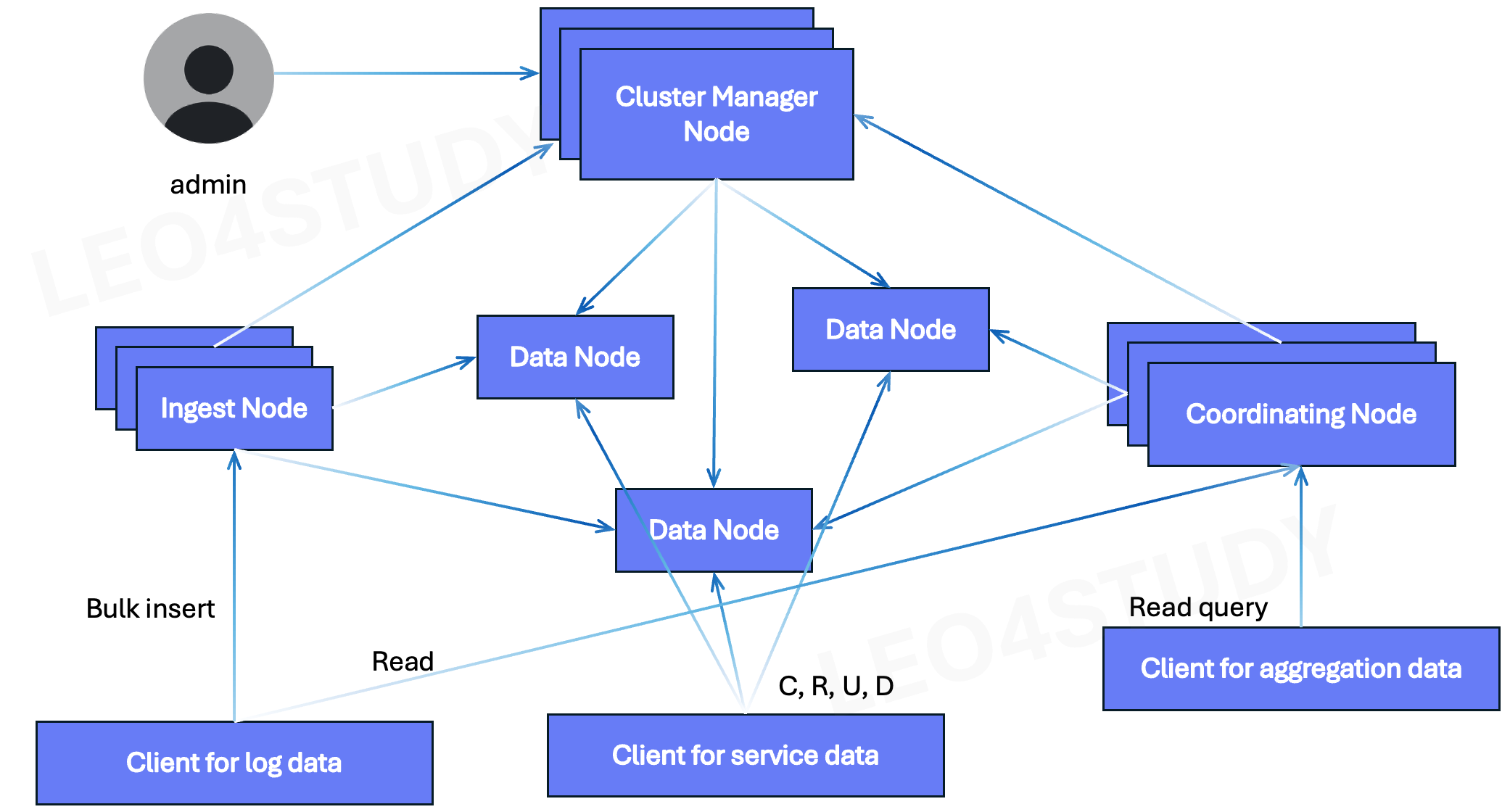
UntitledOpensearch 클러스터 하나로 모든 요구사항을 다 담는 구성이다. 데이터가 많지 않고, client가 많지 않을 때 선택할 수 있다.Service ClusterUntitledLog ClusterUntitledAggregation ClusterUnti
113.[OpenSearch] Ingest Node에서 Data Node와 Manager Node로의 흐름 정리
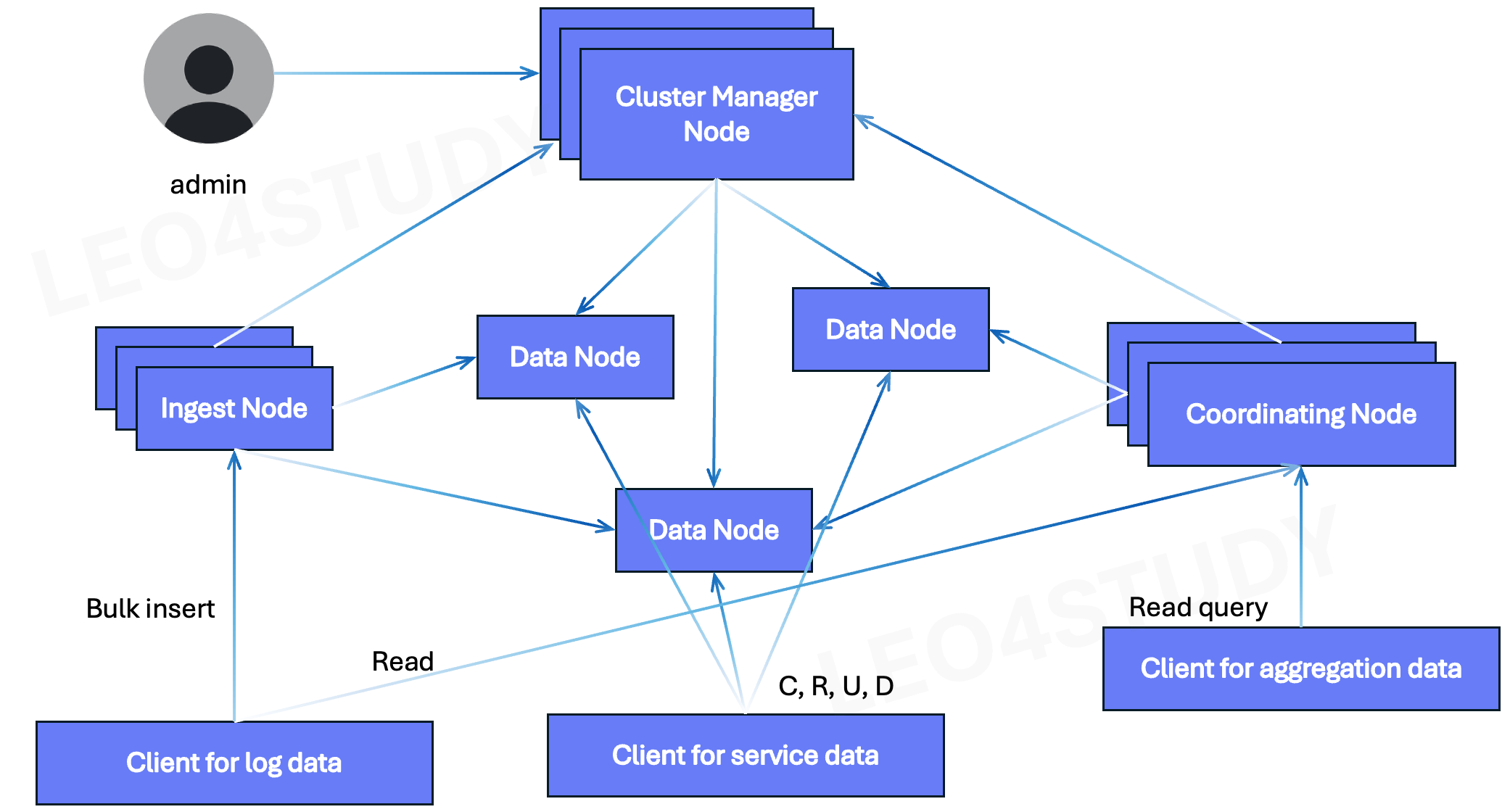
Ingest Node는 데이터를 전처리(grok, remove, mutate 등)한 후, 실제 데이터를 저장하기 위해 Data Node로 전송한다.Client → Ingest Node (pipeline 처리)Ingest Node → Data Node (primary s
114.[OpenSearch] Aggregation & Log Data의 Read 경로: Coordinator Node를 통하는 이유
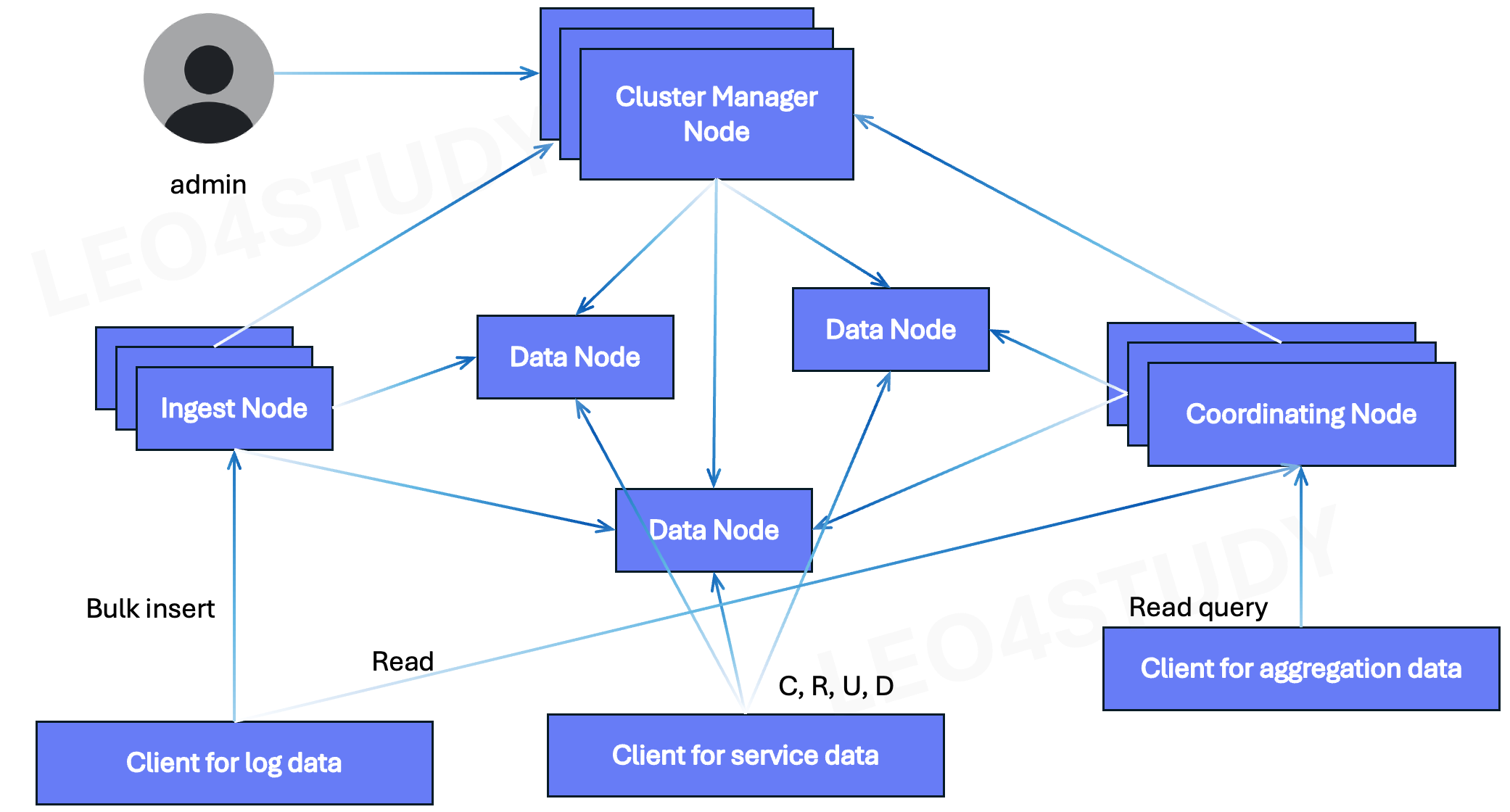
Aggregation 데이터와 Log 데이터가 왜 Coordinator Node를 통해 읽기(Read) 작업을 수행하는지 알아보자.Coordinating Node는 읽기(Read) 요청을 분산 실행하고, 결과를 병합하여 응답하는 노드다.데이터를 직접 저장하지 않음쿼리
115.[오픈소스와 기업관계] Opensource 의 딜레마
Elastic 회사에서 공개한 Elastic stack 제품과 Elastic 회사의 성장 스토리Our StoryElasticsearch는 2000년에 개발되었다.ELK stack 으로 갖춰지기 까지는 10년 이상이 걸렸다.모든 유저가 쉽게 설치하고 관리할 수 있는 성능
116.[오픈소스와 기업관계] Elasticsearch vs Opensearch
Elasticsearch를 온프레미스 기준으로 설치해서 사용한다면, 데이터노드 인스턴스 한대당 2천만원 ~ 3천만원 가량 필요하다. 대신 다른 Elastic stack 이용에 대한 추가 과금은 없다.클라우드형으로 이용한다면 인스턴스와 단계별 과금이 일어난다.수 페타 단
117.[Database] 대용량 쿼리 성능 최적화를 위한 고려 요소
데이터 양과 인덱스 구조 파악필터링 → 조인 → 집계 → 정렬 순으로 쿼리 구조 설계함수/서브쿼리는 반복 실행 여부 중심으로 리팩터링실행계획으로 비용 확인 후 병목 구간 추적물리적 저장 포맷과 Partition 전략 연동Spark/Presto/Hive 등의 분산환경이라
118.[Hadoop의 이해] Hadoop을 사용하는 이유
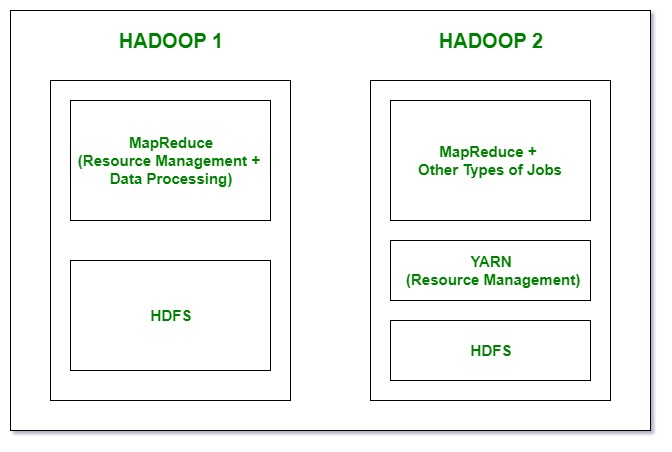
온라인 서비스와 온라인 데이터 처리 기술이 발전하면서, 데이터의 양과 종류가 다양해졌다. 정형 데이터의 경우 기존에 있던 RDBMS에 저장할 수 있지만, 웹 로그 등의 비정형 데이터를 RDBMS에 저장하기에는 데이터의 크기가 너무 크고, RDBMS의 복잡하고 상세한 기
119.[Hadoop의 이해] HDFS
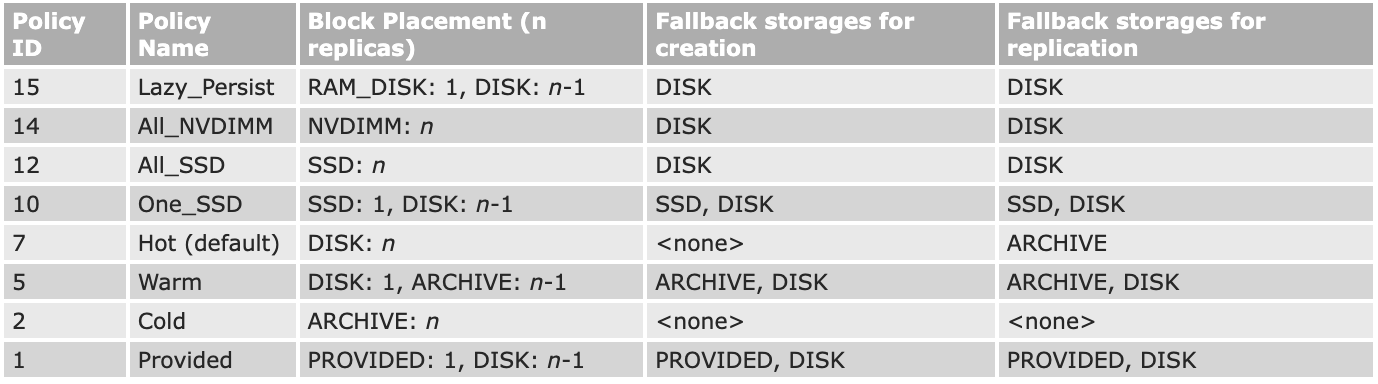
2 HDFS 2.1 HDFS 의 Design Goal 2.1.1 Hardware Failure HDFS를 구성하는 분산 서버에는 다양한 장애가 발생할 수 있다. 예를 들면 하드디스크에 오류가 생겨서 데이터 저장에 실패하는 경우, 디스크 복구가 불가능해 데이터가 유
120.[Hadoop의 이해] Hadoop Name Node HA
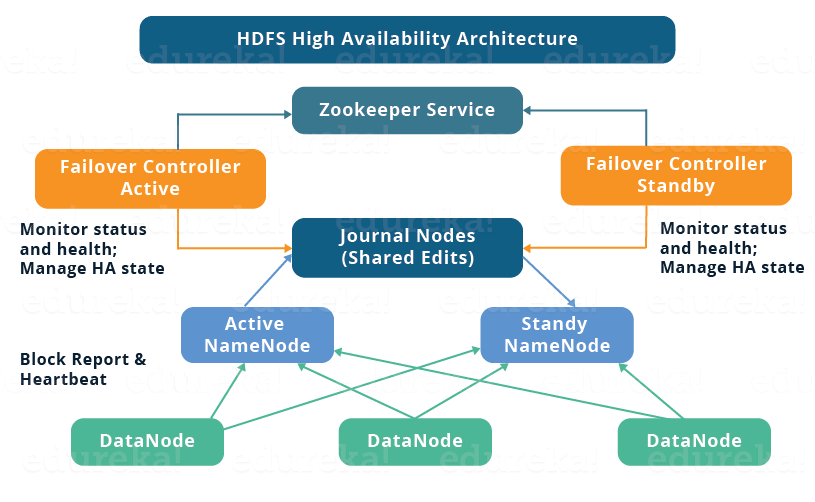
Hadoop v1.x 버전 까지는 namenode 는 SPOF(single point of failure)였다. Hadoop 의 기본 아키텍처는 namenode를 master, datanode 들을 slave 로 하는 master-slave 구조이다. 이 중 namen
121.[Hadoop의 이해] Hadoop 3 Eraser Coding
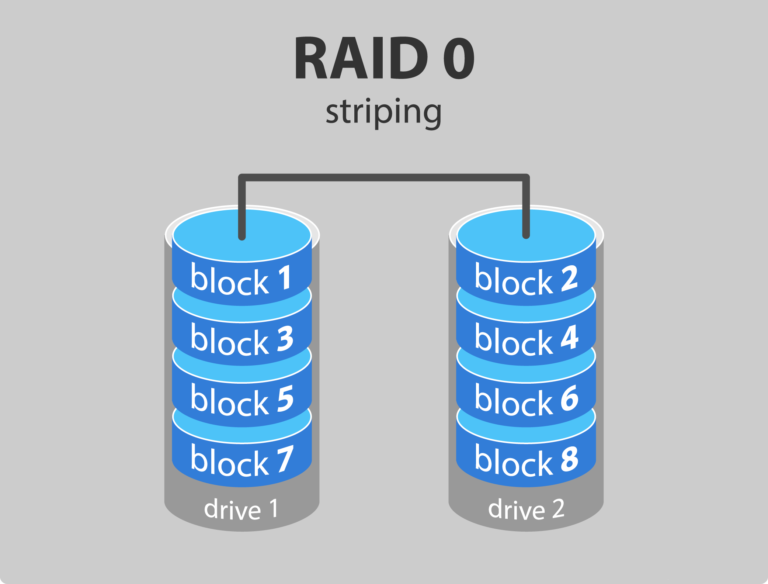
Hadoop 은 기본적으로 같은 data block 에 대해서 3개의 복제본을 유지한다. 이 data block 은 fault tolerance 를 위해 물리적으로 다른 위치에 위치시킨다. 다른 머신, 다른 rack, 다른 data center 단위로 분산해서 위치시켜
122.[Hadoop의 이해] Fair Call Queue
5 Fair Call Queue Fair Call Queue 는 Client의 요청을 담아놓는 Queue 이다. 특정 클라이언트의 요청때문에 전체 요청의 처리가 늦어지지 않도록 하기 위해 만들어졌다. 5.1 FIFO queue 의 단점 Fair Call Queu
123.[EMR 클러스터 구성을 위한 개념] 노드 유형 (Node Type)
ℹ️ 이 강의 자료는 AWS 매뉴얼 을 한글 번역으로 그대로 불러온 강의자료이다. EMR 클러스터 설정시 필요한 개념이나 용어를 설명하기위해서 복사해온 것으로, 강의 시점의 snapshot 유지의 목적이 있다. 정확한 정보는 언제나 공식 매뉴얼에서 확인하는 것이 가장
124.[EMR 클러스터 구성을 위한 개념] 고가용성 클러스터에 대한 제약사항
ℹ️ 이 강의 자료는 AWS 매뉴얼 을 한글 번역으로 그대로 불러온 강의자료이다. EMR 클러스터 설정시 필요한 개념이나 용어를 설명하기위해서 복사해온 것으로, 강의 시점의 snapshot 유지의 목적이 있다. 정확한 정보는 언제나 공식 매뉴얼에서 확인하는 것이 가장
125.[EMR 클러스터 구성을 위한 개념] 클러스터 인스턴스 구성 지침
ℹ️ 이 강의 자료는 AWS 매뉴얼 을 한글 번역으로 그대로 불러온 강의자료이다. EMR 클러스터 설정시 필요한 개념이나 용어를 설명하기위해서 복사해온 것으로, 강의 시점의 snapshot 유지의 목적이 있다. 정확한 정보는 언제나 공식 매뉴얼에서 확인하는 것이 가장
126.[AWS EMR Hadoop 실습] 설치하기
이번 실습의 목적은 Hadoop 실습을 위한 클러스터 세팅이다. 클러스터 운영을 위한 과정은 아니므로 실습의 편의에 맞추어저 있다.EMR의 Multi Primary 또는 hue를 사용하지 않을거면 별도의 MySQL을 생성하지 않아도 된다. 하지만 HA Hadoop ec
127.[AWS EMR Hadoop 실습] 실습용 데이터 다운로드
본 실습은 AWS EMR의 Primary(master) node 에서 진행한다.실습용 데이터는 1987~2008년의 미국 항공편 운항 통계 데이터이다. 링크예제 데이터의 컬럼에 대한 설명은 링크 에서 확인할 수 있다.다음 디렉토리에 데이터를 저장한다.다음 bash sc
128.[AWS EMR Hadoop 실습] HDFS 명령어 실습
본 실습은 AWS EMR의 Primary(master) node 에서 진행한다.HDFS 명령어의 공식 매뉴얼HDFS DFS (distributed file system)의 공식 매뉴얼디렉토리의 파일을 출력For a file ls returns stat on the fi
129.[AWS EMR Hadoop 실습] EMR 클러스터 웹 인터페이스
Hadoop 의 다양한 도구를 패키지로 설치했다. 각 컴포넌트별로 접근하는 인터페이스가 다르다. EMR로 구성한 경우 다음 매뉴얼로 확인한다.매뉴얼EMR 대시보드에서 Applications 를 누르면 접근할 수 있는 url 주소와 포트가 나열되어있다.EMR의 prima
130.[AWS EMR Hadoop 실습] HDFS이용하는 Java Application 구현하기
Primary 노드에 접속해서 경로 생성로컬의 jar 를 scp 로 primary 노드로 이동$key: primary node EC2 에 접속할 수 있는 key 파일$project_path: 5.1 을 수행한 java project 의 path$primary_node:
131.[Yarn] What is Yarn?
YARN (Yet Another Resource Negotiator)Hadoop 에코시스템의 클러스터 리소스 관리 프레임워크이다.Java로 작성되어 있다.CPU, 메모리 등 클러스터 자원(Resource)을 여러 애플리케이션에 효율적으로 분배한다.Job 스케줄링과 모니
132.[Yarn] YARN Architecture
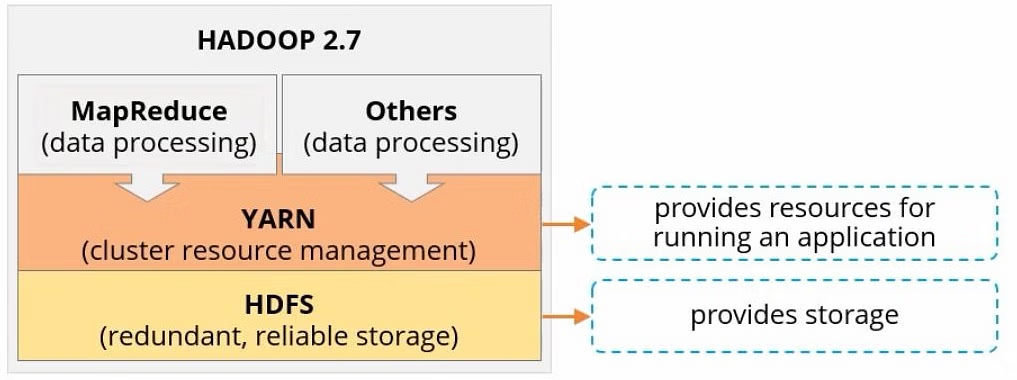
Yarn 은 cpu, memory 와 같은 computing resource 를 할당해주고 리소스의 사용을 관리하는 소프트웨어이다.Yarn 과 HDFS 자체는 완전히 독립적이다. HDFS는 Storage 기능을 제공하고, Yarn 은 application 을 구동하는
133.[Yarn] Yarn 작업 흐름
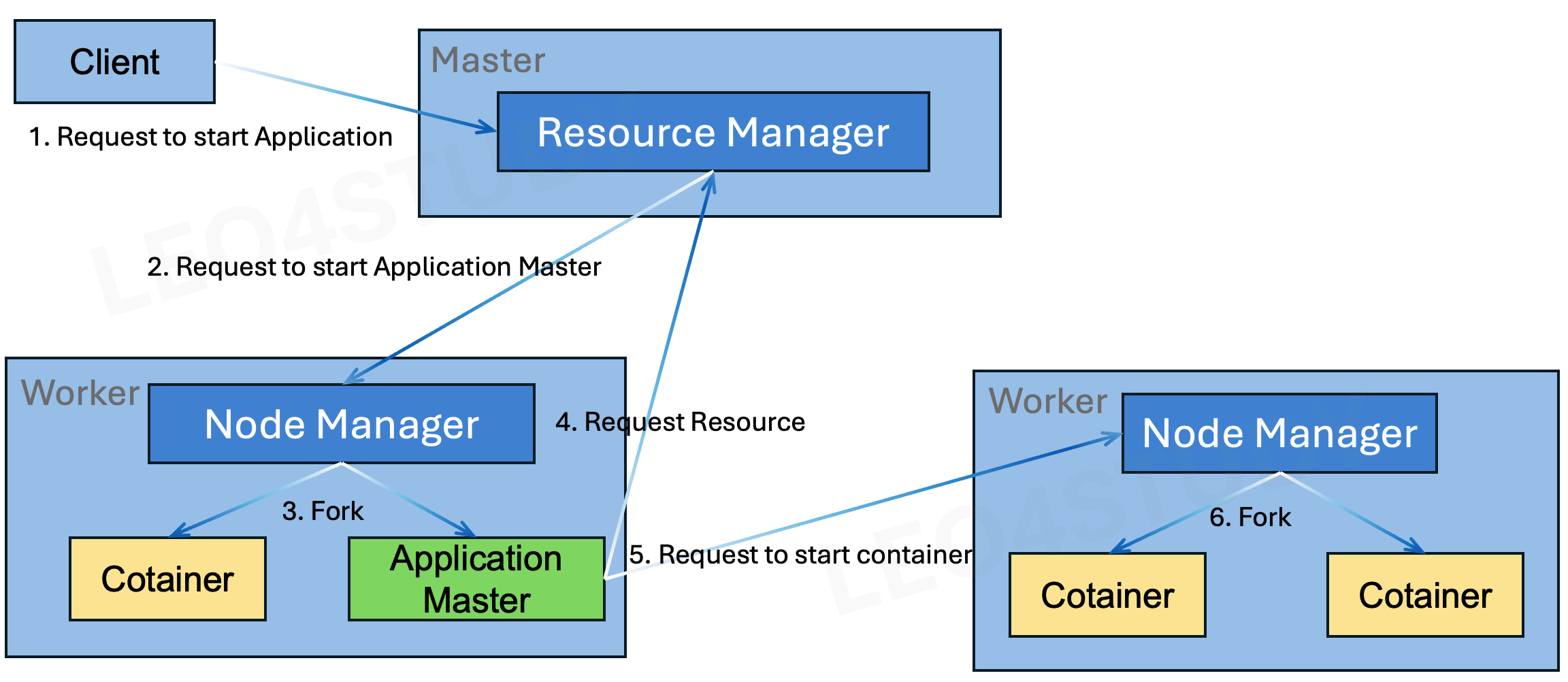
클라이이언트는 어플리케이션 실행을 요청한다. 어플리케이션은 Yarn API를 구현한 프로그램이면 된다.이때, ResourceManager는 실행 요청이 유효할 경우 클라리언트에 새로운 Application ID를 할당한다.ResourceManager는 NodeManag
134.[Yarn] Yarn Application 실습
ℹ️ 실습은 P08-C02 AWS EMR Hadoop 실습에서 세팅한 클러스터에서 진행한다. 클러스터가 없거나 비용이 문제가 되는 경우 hadoop의 single node cluster를 추천. 단, 강의와 내용이 조금 다를 수 있음.build 를 수행한 뒤, jar
135.[Yarn] Yarn Architecture 심화
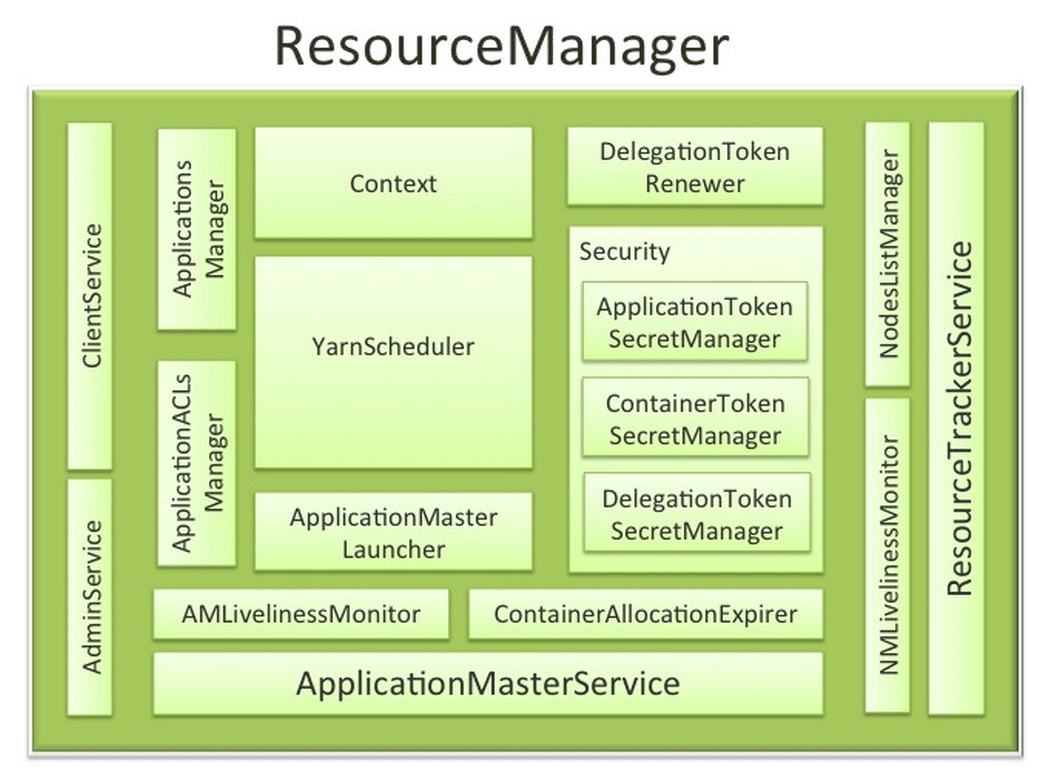
Resource Manager는 전체 클러스터의 가용한 리소스를 스케줄링하고, 클러스터에서 실행되는 애플리케이션들에게 리소스를 분배하고 관리한다.Resource Manager는 NodeManager와 ApplicationMaster를 제어하면서 어플리케이션들이 정상적으
136.[MapReduce] MapReduce Overview
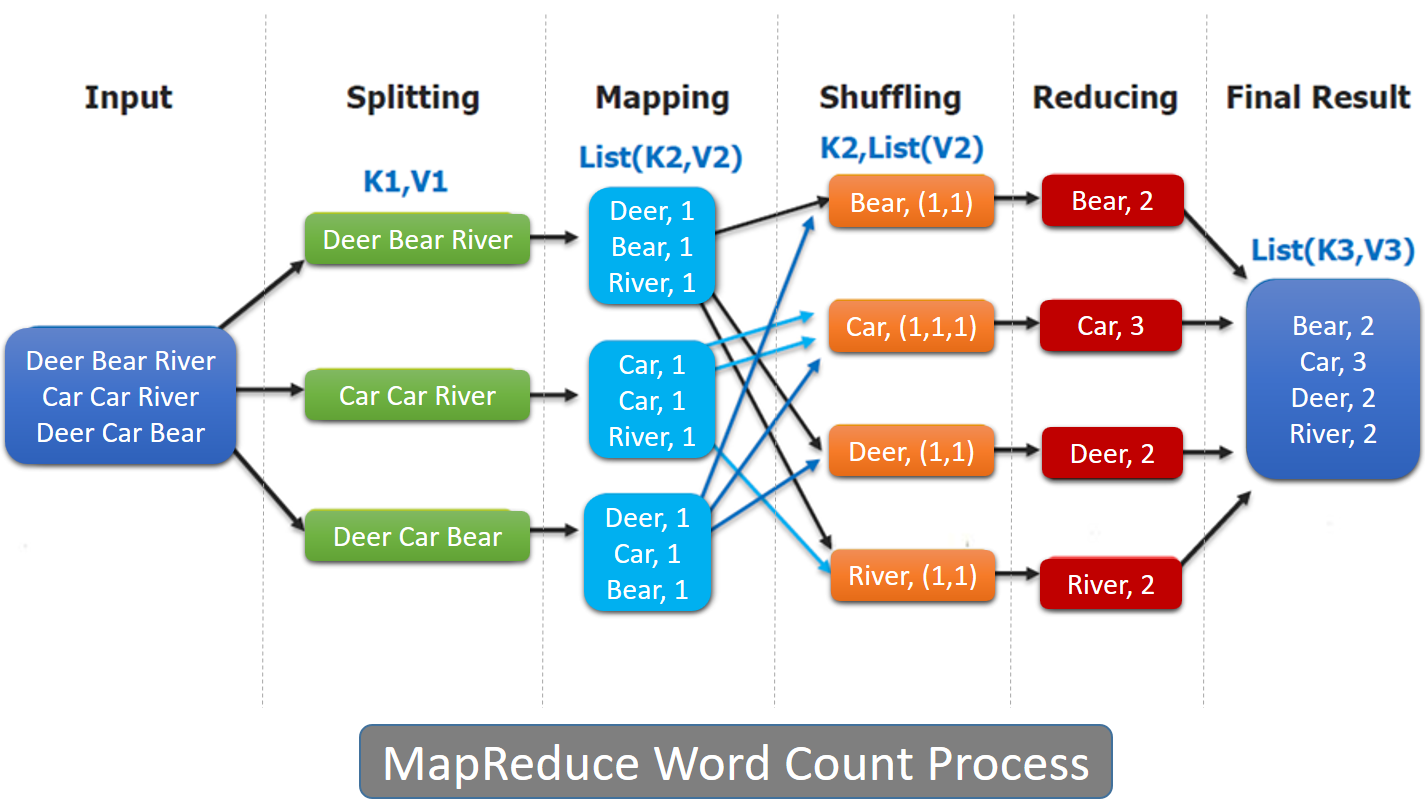
Hadoop MapReduce 는 많은 양의 데이터 처리하는 어플리케이션을 쉽게 작성하는 것을 돕는 소프트웨어 프레임워크이다.동시에 여러 머신들 또는 큰 클러스터에서 동작한다.신뢰성(reliability)을 보장한다.고장 감내성(fault tolerance)을 보장한다
137.[MapReduce] MapReduce 프로그래밍
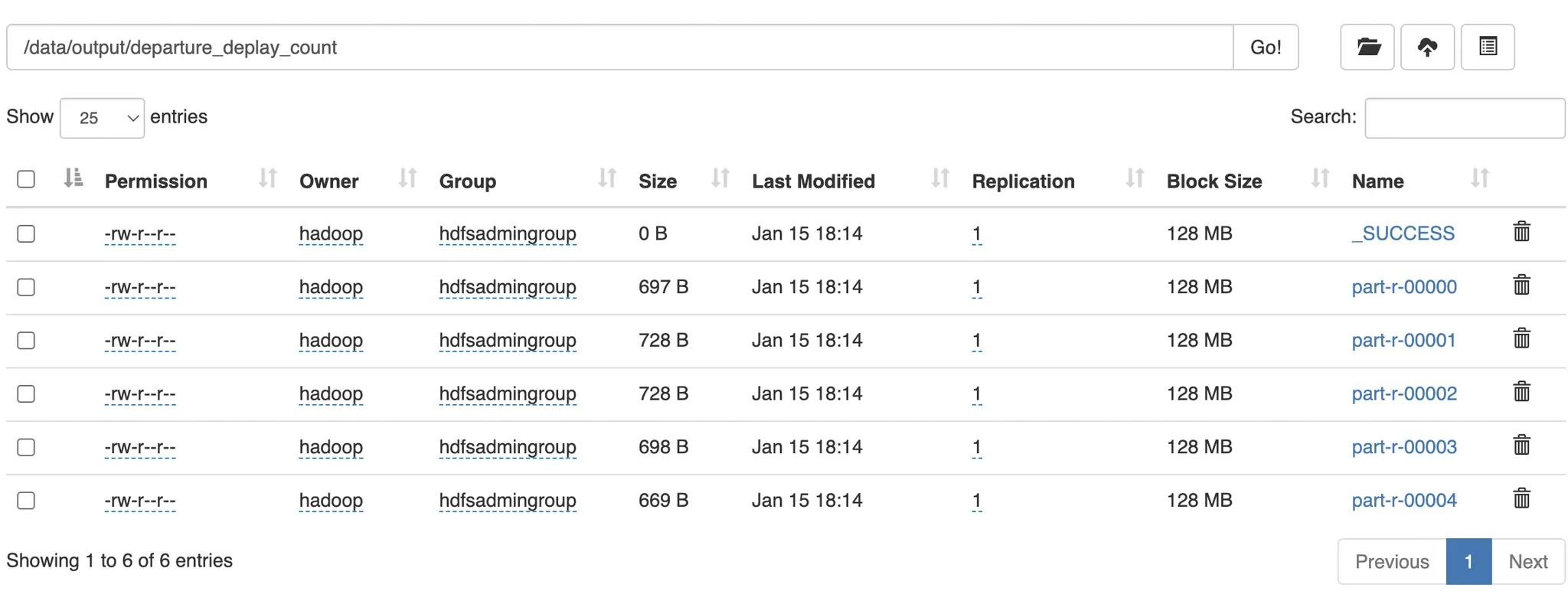
ℹ️ 실습에 사용하는 데이터는, P08-C02 AWS EMR Hadoop 실습 > 2 실습용 데이터 다운로드 에서 세팅한 데이터를 사용한다.csv 파일을 파싱하는 코드이다.드라이버 역할을 하는 클래스이다.빌드이동실행다음과 같은 결과가 나왔다.map task 가 얼마나
138.[MapReduce] 맵리듀스 정렬
3 맵리듀스 정렬 3.1 Secondary Sort(보조정렬) 앞선 예제에서 결과 데이터는 파일에 행으로 나누어져 있는데, 정렬이 되어있지 않다. 정렬되지 않은 이유는 맵리듀스에서 사용한 키를 연월을 단순히 붙인 텍스트로 인식했기 때문이다. 이것을 보조 정렬을 이
139.[MapReduce] MapReduce 프로그래밍의 한계
Java 프로그래밍으로 MapReduce 프레임워크와 인터페이스에 맞추어서 대용량 분산 데이터처리를 할 수 있는 것은 대단한 발전이었다.하지만, Java 로 데이터 파싱부터, 데이터 처리, 정렬, 조인 등의 모든 데이터처리를 매번 짜는 것은 번거로운 일이다.SQL, D
140.[Hive] Hive Overview
P08-C05 HiveHive 는 HDFS(또는 다른 분산 스토리지)의 대량의 데이터를 SQL로 다룰 수 있도록 하는 도구(소프트웨어 패키지)이다.오픈소스이고 무료로 사용할 수 있다.HDFS 를 대상으로 SQL을 사용할 수 있다.다양한 client 프로토콜을 지원한다.
141.[Hive] Hive Architecture
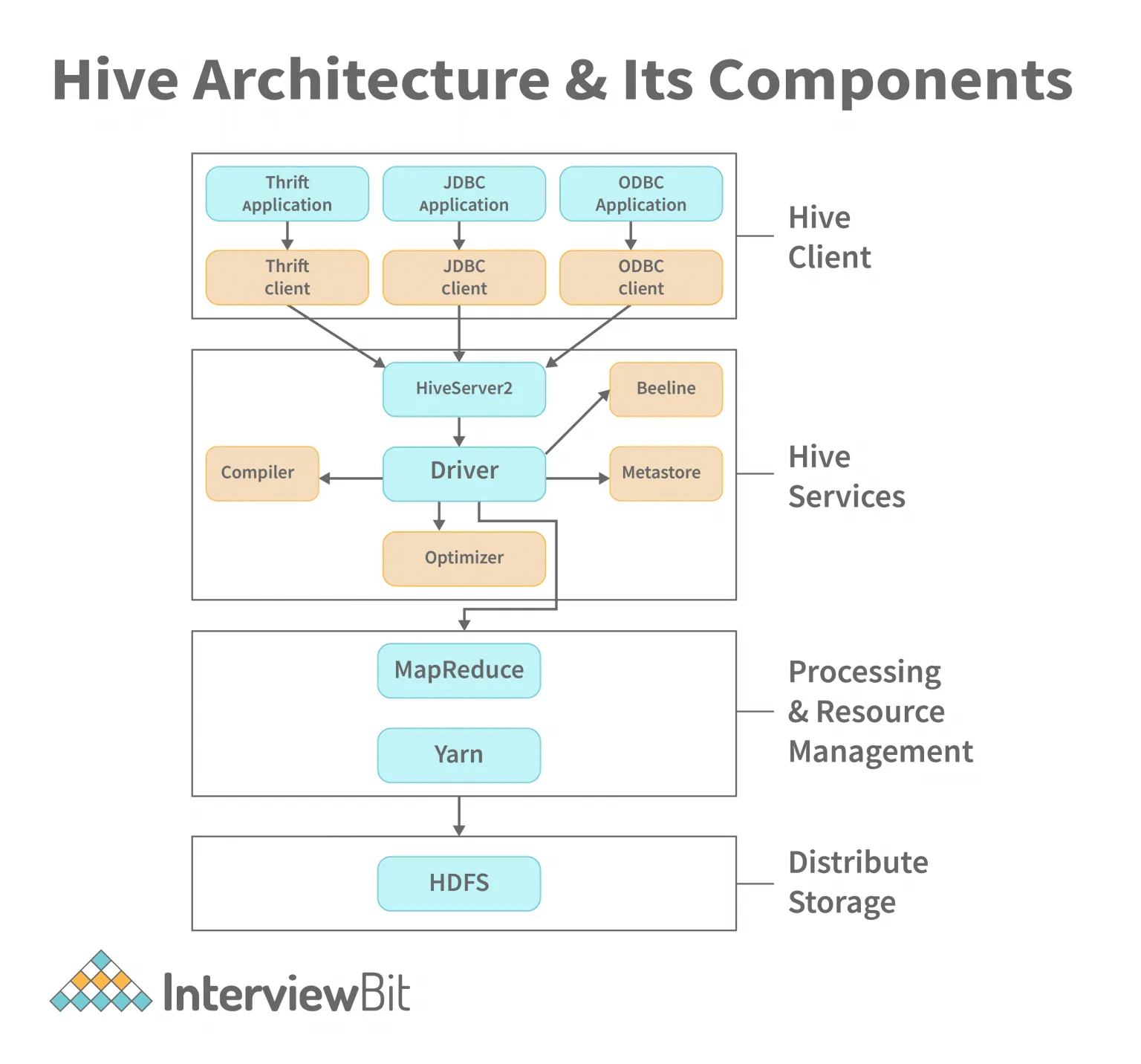
https://www.interviewbit.com/blog/wp-content/uploads/2022/06/Hive-Architecture-1536x1432.pngPython, Java, C++, Ruby 등 다양한 언어로 만들어진 Hive client dr
142.[Hive] Hive Client (실습 필요)
Hive를 이용할 수 있는 방법은 많다. 기본 hive shell 에 들어가도 되고, JDBC driver 를 이용해서 SQL Client 도구들을 이용할 수도 있다. (Workbench, Datagrip 등)실습에서 사용하는 hive server 버전은 Hive 3.
143.[Hive] Hive Table 의 특징
Hive 가 자신의 데이터를 소유하는 형태를 말한다.hive 에대해서 external table 이라는 선언으로 create table 을 하지 않는다면, 기본으로 적용된다.hive 의 전용 경로 하위에 자동으로 생성된다. location 옵션으로 따로 지정할 수도 있
144.[Hive] HiveQL (실습 필요)
HiveQL은 ANSI SQL 과 호환되는 부분이 많기는 하지만, RDBMS와는 차이가 많다. 따라서 SQL을 작성하는 과정에서 꼭 공식문서를 참고하는 것이 좋다.https://cwiki.apache.org/confluence/display/Hive/Langu
145.[Hive] Tez 엔진으로 성능 높이기
전통적인 MapReduce 작업의 단점을 보완해서 Hadoop 에서 mapreduce 작업을 더 빠르게 수행할 수 있도록 돕는 엔진이다.기존의 MapReduce의 단점을 해결하고, 고속화를 실현했다.불필요한 단계가 감소하여 처리가 짧아지고 스테이지 사이의 대기 시간이
146.[HBase] HBase의 탄생 배경
P08-C06 HBase데이터가 많아질수록 데이터 탐색 속도는 느려진다.cache를 도입할 수 있다.다만, view 격차가 생기는 것을 최소화 하기는 해야한다.Scale up → 계속 해서 비용이 증가.슬레이브도 비슷한 성능으로 맞춰줘야함.쿼리 성능이 떨어진다.기능을
147.[HBase] HBase 구성요소

2003년, 구글의 GFS - https://research.google/pubs/pub51/MapReduce - https://research.google/pubs/pub62/GFS + MapReduce로 구글이 보유하고 있는 전체 검색 색인을 포함
148.[HBase] HBase 아키텍처
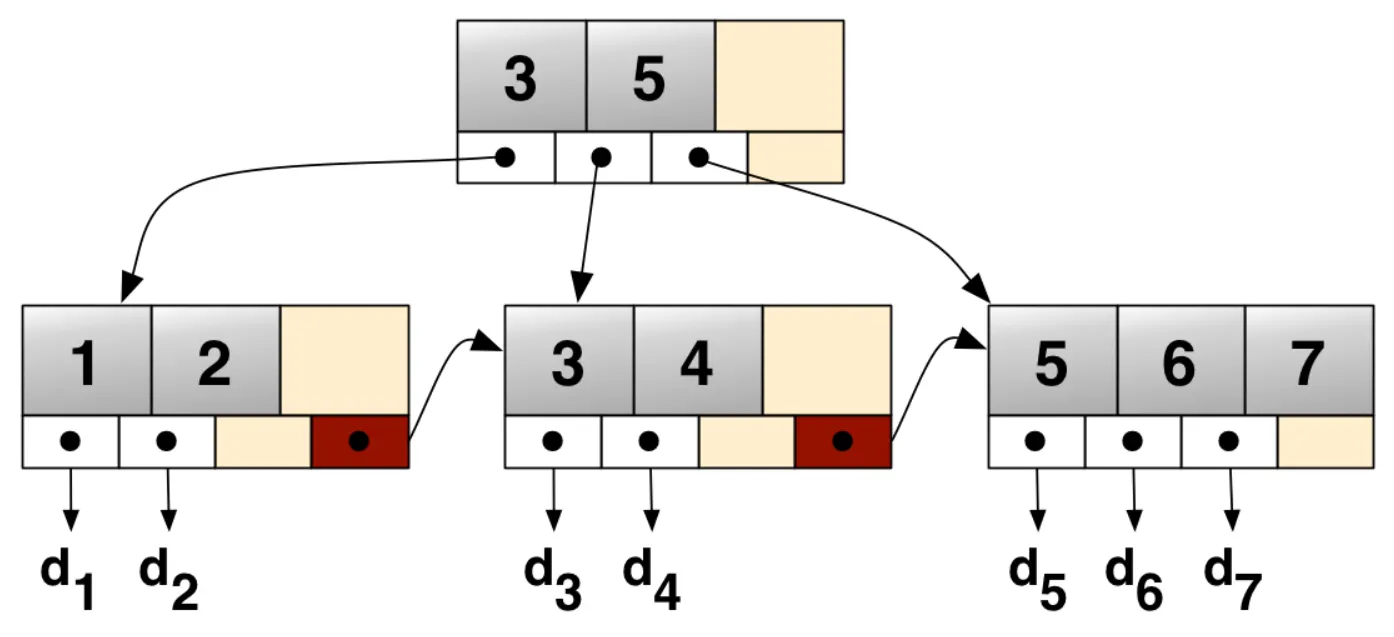
그림에는 next만 있지만, 보통은 prev, next 포인터 다 있음.이는 동적이며, 각각의 인덱스 세그먼트 (보통 블록 또는 노드라고 불리는) 내에 최대와 최소범위의 키의 개수를 가지는 다계층 인덱스(multilevel index)로 구성된다.B트리와 대조적으로 B
149.[HBase] HBase Row Key Design
HBase는 Row Key라는 단일 인덱스로 데이터를 검색한다.데이터의 위치와 분산은 Row Key에 의해 결정되므로, Row Key는 검색 성능뿐만 아니라 클러스터의 전체 상태에도 직접적인 영향을 미친다.따라서 Row Key는 활용 목적에 맞게 신중하게 정의해야 하며
150.[HBase 실습] HBase 설치
P08-C07 HBase 실습HBase standalone 버전으로 설치한다.EC2 인스턴스를 준비한다.사전 프로그램들 set JAVA_HOMEwhich java 로 확인해본다.$host:16010 으로 hbase web UI 에 접속할 수 있다.test table 을
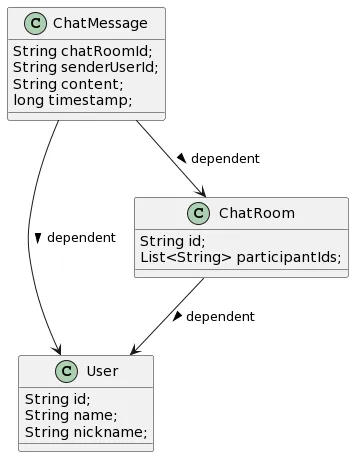
151.[HBase 실습] KakaoTalk
kakao talk 같은 메신저 서비스의 주 저장소를 HBase 로 한다고 했을 때 어떤 데이터 모델과 key 설계를 해야할지 고민해보자.User 는 무한히 많아질 수 있다.ChatRoom 은 무한히 많아질 수 있다.하나의 ChatRoom 에 속할 수 있는 참여자의 수
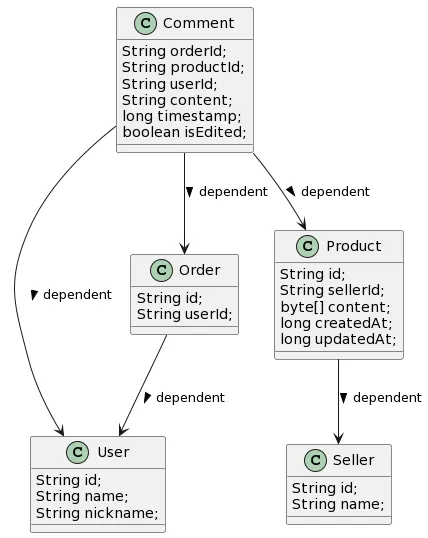
152.[HBase 실습] Coupang
쿠팡과 같은 쇼핑몰의 주 데이터 저장소를 HBase 로 한다고 했을 때, 어떤 데이터 모델과 key 설계를 해야할지 고민해보자.쿠팡의 댓글 기능을 설계해본다.User 는 무한히 많아질 수 있다.Product 는 무한히 많아질 수 있다.Comment 는 Product 별
153.[NoSQL] ORM, ODM이란?
ORM은 객체와 관계형 데이터베이스(RDBMS)의 테이블을 매핑하는 기술이다. 개발자는 SQL을 직접 작성하지 않고 객체 지향적으로 데이터를 조작할 수 있다. 예를 들어, Python 클래스 User와 데이터베이스 테이블 users를 매핑하여 객체 생성, 조회, 수정,
154.Hadoop MapFile Reader를 이용한 분산 데이터 Key 조회 과정
MapFile이 분산된 HDFS 환경에서 어떻게 key 기반으로 데이터를 빠르게 찾는가, 즉 "물리적으로 분산된 데이터 → 논리적으로 정렬된 MapFile"로 변환하는 과정먼저 전제부터 잡고 가보자.MapFile은 Hadoop의 HDFS 파일 포맷 중 하나로, 실제로는
155.Consistent Hashing (일관성 해싱) 정리
분산 캐시는 여러 서버(노드)에 데이터를 나누어 저장하여 성능과 가용성을 높이는 구조이다. 현실 환경에서는 다음 이유로 노드가 자주 추가되거나 삭제됨:수평 확장(Scale-out): 트래픽 증가 → 서버 추가 장애 처리(Failover): 서버 다운 → 노드 제거
156.[DE] RPO와 RTO를 중심으로 본 고가용성(High Availability) 시스템 설계 원리
고가용성(High Availability, HA)은 시스템이 장애 상황에서도 지속적으로 운영될 수 있도록 설계하는 개념이다. 특히 분산 환경이나 클라우드 기반 데이터 인프라에서는 서비스 중단과 데이터 유실을 최소화하는 것이 핵심 목표가 된다. 이때 시스템 복구 전략을