2 KakaoTalk
kakao talk 같은 메신저 서비스의 주 저장소를 HBase 로 한다고 했을 때 어떤 데이터 모델과 key 설계를 해야할지 고민해보자.
2.1 요구사항
- User 는 무한히 많아질 수 있다.
- ChatRoom 은 무한히 많아질 수 있다.
- 하나의 ChatRoom 에 속할 수 있는 참여자의 수는 1000명이다.
- ChatRoom 의 ChatMessage 들은 언제나 최신데이터부터 조회한다. 최신데이터부터 과거로 스크롤 하며 조회한다.
💡 강의를 멈추고 스스로 HBase 의 테이블과 Row Key 를 어떻게 설계할지 디자인해본다.
2.2 Class-D
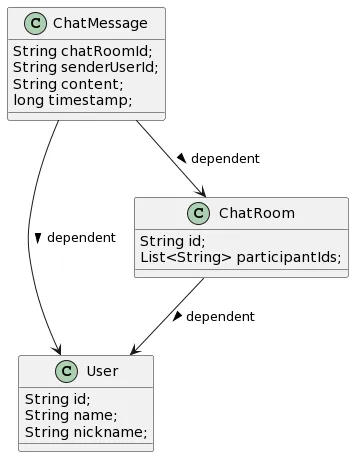
아래 링크에서 Class UML Diagram을 만들 수 있다.
https://www.plantuml.com/plantuml/uml/SyfFKj2rKt3CoKnELR1Io4ZDoSa700002#google_vignette
class ChatMessage {
String chatRoomId;
String senderUserId;
String content;
long timestamp;
}
class ChatRoom {
String id;
List<String> participantIds;
}
class User {
String id;
String name;
String nickname;
}
ChatMessage --> ChatRoom : dependent
ChatMessage --> User : dependent
ChatRoom --> User : dependentChatRoom에서 User의 객체 자체를 담진 않지만 User의 id를 갖기 때문에 dependent라고 표시해 두었음
2.3 Table + Row Key
전제조건: 모든 id 종류는 random string 으로 발급한다.
String의 길이는 10글자로 제한
User
- RowKey:
id - Value: object 를 serialize
- 이거는 따로 CF나 Qualifier가 필요 없다. 그래서 Default CF와 Qualifier 사용. 다른 것들도 마찬가지.
ChatRoom
- RowKey:
id - Value: object 를 serialize
ChatMessage
-
RowKey:
chatRoomId:reverseTimestamp:hashsedValue(senderUserId, content)- chatRoomId : 10bytes
- reverseTimestmap: 8bytes
- reverseTimestamp는 Long으로 된 Timestamp값을 LongMax 값에서 뺀 것이고 그것 또한 long이니까 8byte
- hashedValue: 32bytes (256bit, SHA256으로 해싱)
- SHA256 256bit, 8로 나누면 32byte
- 실제로는 256보다 더 작게 해도 될 것 같기는 한데, 실습용이니까 이렇게 구성.
-
Value: object 를 serialize
chatRoomId 는 랜덤. region에 여러 군데에 분포가 될 것. 그런데 같은 chatRoom에 대해서는 reverseTimestamp로 정렬해서 정렬되어 있는 최신 timeline 순으로 바로바로 묶어서 10개든 20개든 한 번에 빨리 조회할 수 있도록.
하나의 region에 접근해서 벌크로 확정적으로 인메모리 기준 log(n) 시간이고 파일 기준으로는 O(1)과 유사한 속도록 region으로 찾아간 다음 거기서 bulk로 관련된 걸 다 긁어오니까 용량이 대용량에 비해서,
RDMBS로 구축을 하고 RDMBS의 데이터가 이 메세지 100개, 1000개 밖에 없다. 이러면 timestamp조건을 줘도 RDBMS가 더 빠를 테지만 1억개, 10억개 넘어가면 RDBMS가 그걸 다 담지 못 할 뿐더러 담는다 하더라도 조회 속도가 느릴 것. HBase는 1000개일 때랑 1억개 일 때랑 큰 차이 없이 (조금 있긴 함) 안정적으로 응답 속도를 보여줄 수 있다. 그래서 실시간성을 요하는 timeline순으로 데이터를 조회하는 것에 대해 아무리 chatRoom이 늘어나고 Message가 늘어나도 일관되게 응답할 수 있다.
RowKey를 여러 값의 조합으로 설계할 때 주의사항
-
고정된 Byte 길이 유지 필요성
- RowKey의 각 구성 요소는 항상 정해진 바이트 길이를 지켜야 한다.
- 그래야만 HBase의 사전순 정렬에 따라 RangeScan 결과가 올바르게 정렬된다.
-
문제 사례
- 예를 들어 chatRoomId가 어떤 방은 "aa", 다른 방은 "aaa"라고 가정하자.
- 이를 그대로 RowKey에 쓰면 길이가 달라서, 스캔 시 정렬 순서가 예상과 다를 수 있다.
- 특히 특정 timestamp 중간값을 기준으로 데이터를 필터링하거나, 특정 구간을 aggregation하려는 경우 문제가 발생한다.
- 이유는 RowKey 앞부분의 길이가 제각각이면, HBase가 어디서부터 스캔을 시작해야 하는지 일관성 있게 판단하기 어렵기 때문이다.
-
해결 방법
- RowKey 설계 시 각 의미 단위(예: chatRoomId)가 차지하는 Byte 수를 미리 정의하고, 항상 그 길이에 맞추어 저장되도록 한다.
- 문자열(String)은 길이가 가변적이므로, RowKey 생성 함수를 따로 만들어 각 구성 요소를 일정한 길이로 패딩(padding)하거나 해시를 사용해 고정 길이로 변환한다.
- 이렇게 하면 HBase RowKey는 항상 동일한 길이를 가지게 되어, RangeScan 및 정렬 결과의 일관성이 보장된다.
Dynamic에서 Length를 맞추기 힘들다면 Hash를 활용하기도 함.
Creat tables
create 'user', 'cf'
create 'chatroom', 'cf'
create 'chatmessage', 'cf'
list
describe 'user'
describe 'chatroom'
describe 'chatmessage'주로 HBase 테이블 만들 때는 소문자와 대시를 많이 사용한다.
콜론은 NameSpace와 Table을 구분하는 단위다. 콜론을 중간에 쓰진 않는다.
2.4 Codes
위 설계 내용을 구현하는 코드를 작성한다.
API 구현을 해서 armeria 를 사용했다.
실습을 위해 armeria라는 Server builder를 사용했다. Spring보다는 좀 더 가볍고 편하게 쓸 수 있어서 이것을 사용했음.
settings.gradle
rootProject.name = 'de-hbase'build.gradle
plugins {
id 'java'
id 'application'
id 'com.github.johnrengelman.shadow' version '7.1.2'
}
group 'de.hbase'
version '1.0'
repositories {
mavenCentral()
}
application {
mainClassName 'de.hbase.talk.TalkApp'
}
dependencies {
['armeria',
].each {
implementation "com.linecorp.armeria:${it}:1.22.1"
}
runtimeOnly 'ch.qos.logback:logback-classic:1.3.6'
compileOnly 'org.projectlombok:lombok:1.18.26'
annotationProcessor 'org.projectlombok:lombok:1.18.26'
implementation 'org.apache.hbase:hbase-client:2.5.3-hadoop3'
}
test {
useJUnitPlatform()
}de.hbase.common.HBaseData
HBaseData interface를 만들었다. 아까 설계한 데이터 클래스들의 key들의 byte 수를 지켜줘야해서 유지해둘 수 있는 게 필요한데, 그것을 뽑기 위한 공통의 인터페이스를 HBaseData라는 interface에 rowkey를 byte array형태로 뽑는 함수를 만들고 이걸 구현하게 만들 것.
package de.hbase.common;
public interface HBaseData {
byte[] getRowKey();
}de.hbase.talk.data.User
package de.hbase.talk.data;
import org.apache.hadoop.hbase.util.Bytes;
import com.fasterxml.jackson.annotation.JsonIgnore;
import com.fasterxml.jackson.annotation.JsonIgnoreProperties;
import de.hbase.common.HBaseData;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.extern.jackson.Jacksonized;
@Data
@Jacksonized
@NoArgsConstructor
@Builder
@AllArgsConstructor
@JsonIgnoreProperties(ignoreUnknown = true)
public class User implements HBaseData {
private String id;
private String name;
private String nickname;
@Override
@JsonIgnore
public byte[] getRowKey() {
return Bytes.toBytes(id);
}
}getRowKey() return에 있는 Bytes는 org.apache.hadoop.hbase.util.Bytes 인데, java에 있는 프리미티드 타입이나 다른 타입 별로 Byte를 만들 수도 있고 byte로부터 다시 해당하는 타입을
to~ 로 만들 수 있는 util들을 제공함. 이것을 사용함.
- byte를 만들 때, 보통은 신경을 많이 안 쓰지만 인코딩 값들이 들어감. 그런 것들을 일관되게 안 해주면 실제로 HBase 에 적용된 것 자체는 Byte니까 그걸 내가 어떤 형식으로 serialize 했는지 까먹으면 deserialize해서 그걸 해석할 수가 없으니 serialize/deserialize를 일관되게 할 수 있도록 신경을 써줘야 하고, 그걸 코드로 만들어 놓아야 함.
de.hbase.talk.data.ChatRoom
package de.hbase.talk.data;
import java.util.Set;
import org.apache.hadoop.hbase.util.Bytes;
import com.fasterxml.jackson.annotation.JsonIgnore;
import com.fasterxml.jackson.annotation.JsonIgnoreProperties;
import de.hbase.common.HBaseData;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.extern.jackson.Jacksonized;
@Data
@Jacksonized
@NoArgsConstructor
@Builder
@AllArgsConstructor
@JsonIgnoreProperties(ignoreUnknown = true)
public class ChatRoom implements HBaseData {
private String id;
private Set<String> participantIds;
// 참여자들의 Id인데 Id가 unique하다고 헀으니까 user 별로 id가 Unique하다면 이거를 set으로 자료구조를 설정을 했음.
@Override
@JsonIgnore
public byte[] getRowKey() {
return Bytes.toBytes(id);
}
}de.hbase.talk.data.ChatMessage
package de.hbase.talk.data;
import java.nio.charset.StandardCharsets;
import org.apache.hadoop.hbase.util.Bytes;
import com.fasterxml.jackson.annotation.JsonIgnore;
import com.fasterxml.jackson.annotation.JsonIgnoreProperties;
import com.google.common.hash.Hashing;
import de.hbase.common.HBaseData;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.extern.jackson.Jacksonized;
@Data
@Jacksonized
@NoArgsConstructor
@Builder
@AllArgsConstructor
@JsonIgnoreProperties(ignoreUnknown = true)
public class ChatMessage implements HBaseData {
private String chatRoomId;
private String senderUserId;
private String content;
private long timestamp;
@Override
@JsonIgnore
public byte[] getRowKey() {
byte[] sha256hex = Hashing.sha256()
.hashString(senderUserId + content, StandardCharsets.UTF_8)
.asBytes();
long reverseTimestamp = Long.MAX_VALUE - timestamp;
return com.google.common.primitives.Bytes.concat(
Bytes.toBytes(String.format("%10s", chatRoomId)),
Bytes.toBytes(reverseTimestamp),
// 엄밀하게 말하면 : 구분자까지 넣어줘야 프로토콜에 맞는 건데 ,byte를 좀 줄이고 코드 간결하게 하기 위해 그냥 붙였음. 어차피 자릿수가 다 정해져 있기 때문.
//Bytes.toBytes(":")
sha256hex
);
}
}Bytes.toBytes(String.format("%10s", chatRoomId)) : chatRoomId 에 대해 String을 만들 건데, 10글자로 제한하도록 함.
de.hbase.talk.storage.AbstractStorage
위에서 데이터 모델들을 다 만들었다. 이제는 HBase를 억세스 하는 클래스를 만들어야 함. UserStorage 접근하는 거 ChatRoomStorage 접근하는 거, ChatMessageStorage접근하는 거 만들었는데 만들다 보니 기본적으로 get/put 하는 거랑 Scan하는 건 얼추 비슷해서 그것에 대한 공통 Abstract클래스를 만들고 다른 스토리지클래스에서 상속받도록 만듦.
package de.hbase.talk.storage;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.hadoop.hbase.CompareOperator;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.filter.BinaryComparator;
import org.apache.hadoop.hbase.filter.Filter;
import org.apache.hadoop.hbase.filter.PrefixFilter;
import org.apache.hadoop.hbase.filter.RowFilter;
import org.apache.hadoop.hbase.util.Bytes;
import com.fasterxml.jackson.databind.ObjectMapper;
import de.hbase.common.HBaseData;
import lombok.Getter;
// 제네릭으로 HBaseData get row key가 있는 타입을 받도록 함.
// user, chatroom, chatmessage 중 하나를 쓸 수 있음.
public abstract class AbstractStorage<T extends HBaseData> {
@Getter
protected String tableName;
protected Table table;
// CF와 Qualifier는 테이블이랑 같이 정의해야되는데, 우리가 따로 컬럼을 쓰지 않고, key-value로만 쓸 것이기 때문에 기본 값으로 우선 세팅을 해 두었다.
@Getter
protected byte[] cf = Bytes.toBytes("cf");
@Getter
protected byte[] qualifier = Bytes.toBytes("q");
//잭슨을 위한 ObjectMapper를 serialize, deserialize 하기 위해 하나 만듦.
protected ObjectMapper objectMapper = new ObjectMapper();
// row 형태의 value 나타나면 json deserialize 해서 클래스 타입을 제네릭 T Type으로 바꿔주는 함수.
// objectMapper.readValue할 때 클래스 이름을 넣어줘야 하기 때문에 abstract로 만들어서 각 클래스가 구현하도록 만들어 놓았음.
public abstract T readValue(byte[] raw) throws IOException;
// 초기화 할 때 connection 받도록 해놓았는데, 하나만 만들고 여러 테이블에서 공유해서 쓸 수 있음
public AbstractStorage(String tableName, Connection connection) throws IOException {
this.tableName = tableName;
// connection은 이미 활성화된 놈이여야 함
table = connection.getTable(TableName.valueOf(tableName));
}
//row key를 주면 get object 만듦. get을 설정하거나 여러 개로 만들어서 get의 LIST로 조회할 수도 있음.
public T get(byte[] rowKey) throws IOException {
Get get = new Get(rowKey);
Result result = table.get(get);
// 해당 row에 해당하는 cf, qualifier 넣어서 Getvalue해야 원본vlaue를 가져올 수 있음
byte[] raw = result.getValue(cf, qualifier);
return readValue(raw);
}
// 클래스로 만들어 둔 data type 클래스를 사용하면 좋으니 value를 받게 해 두었고, 이것에 대한 serialize를 이 안에서 하게 해 두었다.
// T 타입은 HBase데이터를 구현한 거니까 getRowKey라고 인터페이스를 구현을 했을 것. getRowKey()의 rowkey로 put 객체를 만듦.
// 리턴값이 없는데, put 도중 실패하면 reception을 던짐.
public void put(T value) throws IOException {
Put put = new Put(value.getRowKey());
// writeValueAsBytes 타입이 무엇이던지 java 타입에 맞게, json annotation에 맞게 serialize를 잘 해줄 것
put.addColumn(cf, qualifier, objectMapper.writeValueAsBytes(value));
table.put(put); // put도 list로 받을 수 있음
}
// prefix는 chatRoom id 가지고 latest값을 할 때 이걸 쓰면 됨
public List<T> scanPrefix(byte[] prefix, int limit) throws IOException {
Filter filter = new PrefixFilter(prefix);
return scan(filter, limit);
}
// value 기준 limit 개수만큼
public List<T> scan(T value, int limit, boolean isReverse) throws IOException {
CompareOperator compareOperator;
if (isReverse) {
compareOperator = CompareOperator.LESS_OR_EQUAL;
} else {
compareOperator = CompareOperator.GREATER_OR_EQUAL;
}
// 필터가 뭘 있는지 알아야 스캔할 때 여러 가지 활용하고 디자인도 잘 할 수 있음. 아래는 링크. (버전 확인 해야함)
// choose filter for your purpose from here - https://hbase.apache.org/apidocs/org/apache/hadoop/hbase/filter/package-summary.html
// 요 키로부터 몇개 줘.
Filter filter = new RowFilter(compareOperator, new BinaryComparator(value.getRowKey()));
return scan(filter, limit);
}
// scan은 대표적으로 ChatMessage의 Rowkey scan할 때 써야됨. ChatRoom, User는 보통 ID로 찍어서 get,put 할 건데, Message는 최신 몇개 줘. 그리고 내가 마지막 본 것으로부터 이전 몇개 줘. 이런 식으로 조회를 할 것. 그걸 위해서 scan 함수를 만듦.
// rowkey를 어떻게 찾아? rowkey정확하게 맞는 거 하나 찍을 수도 있고, 앞에서 ChatRoom 준다음에 그 다음에 prefix로 해서 조회할 수도 있고 그 외 다양한 필터들이 있음. 그거를 filter객체로 만들어서 넣어줌. 그래서 여기에 rowkey가 안 보이는 거는 row key에 대한 조건은 필터로 만들어서 넣기 때문에 이렇게 되어 있음.
private List<T> scan(Filter filter, int limit) throws IOException{
Scan scan = new Scan();
scan.addColumn(cf, qualifier); // 어떤 컬럼 할 건지
scan.setFilter(filter); // 어떤 필터 적용할 건지
scan.setLimit(limit); // 몇개 할 건지
ResultScanner resultScanner = table.getScanner(scan);
// resultScanner 는 iterator라서 반복문 가능
List<T> results = new ArrayList<>();
for (Result result : resultScanner) {
byte[] raw = result.getValue(cf, qualifier);
T resultValue = readValue(raw);
results.add(resultValue);
}
return results; //T의 arraylist 리턴
}
}- 실습에서는 column family 와 qualifier 를 사용하지 않기 떄문에 모두 공통으로 쓰도록 세팅했다.
de.hbase.talk.storage.UserStorage
package de.hbase.talk.storage;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import org.apache.hadoop.hbase.client.Connection;
import de.hbase.talk.data.User;
public class UserStorage extends AbstractStorage<User> {
public UserStorage(Connection connection) throws IOException {
super("user", connection);
}
@Override
public User readValue(byte[] raw) throws IOException {
// raw bytearry를 String으로 만든 다음에 user 클래스로 추론하겠다
return objectMapper.readValue(new String(raw, StandardCharsets.UTF_8), User.class);
}
}de.hbase.talk.storage.ChatRoomStorage
package de.hbase.talk.storage;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import org.apache.hadoop.hbase.client.Connection;
import de.hbase.talk.data.ChatRoom;
// AbstractStorage<ChatRoom> 라고 넣어 놓았는데, 이게 되는 이유는 ChatRoom이 HBaseData를 구현하고 있기 때문에 가능.
public class ChatRoomStorage extends AbstractStorage<ChatRoom> {
public ChatRoomStorage(Connection connection) throws IOException {
super("chatroom", connection);
}
@Override
public ChatRoom readValue(byte[] raw) throws IOException {
return objectMapper.readValue(new String(raw, StandardCharsets.UTF_8), ChatRoom.class);
}
}de.hbase.talk.storage.ChatMessageStorage
package de.hbase.talk.storage;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import org.apache.hadoop.hbase.client.Connection;
import de.hbase.talk.data.ChatMessage;
public class ChatMessageStorage extends AbstractStorage<ChatMessage> {
public ChatMessageStorage(Connection connection) throws IOException {
super("chatmessage", connection);
}
// ChatMessage.class 로 Return할 때 type추론해서 넣을 수 있게 해놓았음
@Override
public ChatMessage readValue(byte[] raw) throws IOException {
return objectMapper.readValue(new String(raw, StandardCharsets.UTF_8), ChatMessage.class);
}
}de.hbase.talk.api.ChatApi
package de.hbase.talk.api;
import java.io.IOException;
import java.util.List;
import java.util.stream.Collectors;
import org.apache.commons.lang3.RandomStringUtils;
import org.apache.hadoop.hbase.util.Bytes;
import com.linecorp.armeria.common.HttpResponse;
import com.linecorp.armeria.common.HttpStatus;
import com.linecorp.armeria.server.annotation.Get;
import com.linecorp.armeria.server.annotation.Param;
import com.linecorp.armeria.server.annotation.Post;
import de.hbase.talk.data.ChatMessage;
import de.hbase.talk.data.ChatRoom;
import de.hbase.talk.data.User;
import de.hbase.talk.storage.ChatMessageStorage;
import de.hbase.talk.storage.ChatRoomStorage;
import de.hbase.talk.storage.UserStorage;
public class ChatApi {
private UserStorage userStorage;
private ChatRoomStorage chatRoomStorage;
private ChatMessageStorage chatMessageStorage;
// user, chatRoom이나 message별로 나누는 게 클리어 한데, 메소드가 몇 개 안되니까 하나에 다 넣었음
public ChatApi(UserStorage userStorage, ChatRoomStorage chatRoomStorage,
ChatMessageStorage chatMessageStorage) {
this.userStorage = userStorage;
this.chatRoomStorage = chatRoomStorage;
this.chatMessageStorage = chatMessageStorage;
}
// post /user 요청이 오면 body는 아무 것도 안 받을 거고, 랜덤 유저 생성.
@Post("/user")
public HttpResponse createRandomUser() throws IOException {
User user = new User(RandomStringUtils.randomAlphabetic(10),
RandomStringUtils.randomAlphabetic(5),
RandomStringUtils.randomAlphabetic(5));
// exception 없이 지나가면 성공한 것
userStorage.put(user);
//ofJson 로 user 자체를 json 형태로 body를 파싱해줌
return HttpResponse.ofJson(HttpStatus.CREATED, user);
}
//createChatRoom 에 body를 주면 json 형식으로 자동으로 파싱해서 User list를 만들어 줌
@Post("/chatroom")
public HttpResponse createChatRoom(List<User> body) throws IOException {
// chatRoom id는 RandomString 10글자
ChatRoom chatRoom = new ChatRoom(RandomStringUtils.randomAlphabetic(10),
//chatRoom에 있는 user는 id만 뽑아서 다시 set으로 만드는 stream operation body.stream().map(User::getId).collect(Collectors.toSet())
);
chatRoomStorage.put(chatRoom);
return HttpResponse.ofJson(HttpStatus.CREATED, chatRoom);
}
//SendMessageRequest 라고 따로 만들었는데, ChatMessage 클래스에서 timestamp 자체를 Hbase에서 할 때도 쓰기 때문에 Jsonignore 하면 안됨. 그런데 실제 유저 요청할 때 timestamp는 서버에서 찍을 거기 때문에 timestamp 찍을 필요가 없어서 따로 만듦.
@Post("/message")
public HttpResponse sendMessage(SendMessageRequest body) throws IOException {
ChatMessage chatMessage = new ChatMessage(body.getChatRoomId(), body.getSenderUserId(),
body.getContent(), System.currentTimeMillis());
// chatMessage put할 때 Rowkey를 복잡하게 해서 Put 해야 함.
// RowKey: chatRoomId: reverseTimestamp:hashsedValue (senderUserId, content)
// 하지만 put에 들어가보면 dataclass 에 있는 getRowKey()를 써서 할 거고, ChatMessage 클래스에 이미 getRowKey() 로직을 이미 다 구현을 해 놓았기 때문에 여기다가 따로 안 해놔도 된다.
chatMessageStorage.put(chatMessage);
return HttpResponse.ofJson(HttpStatus.CREATED, chatMessage);
}
// 앞에 요청에서 next로 받은 게 getMessagesRequest 로 들어옴
@Post("/messages/get")
public HttpResponse getMessages(GetMessagesRequest getMessagesRequest)
throws IOException {
List<ChatMessage> chatMessages = chatMessageStorage.scan(getMessagesRequest.getStart(),
getMessagesRequest.getLimit() + 1, false);
return responseMessages(chatMessages, getMessagesRequest.getLimit());
}
@Get("/messages/latest")
public HttpResponse getMessagesFromLatest(@Param("chatRoomId") String chatRoomId, @Param("limit") int limit)
throws IOException {
List<ChatMessage> chatMessages = chatMessageStorage.scanPrefix(Bytes.toBytes(chatRoomId), limit + 1);
return responseMessages(chatMessages, limit);
}
private static HttpResponse responseMessages(List<ChatMessage> chatMessages, int limit) {
ChatMessage next = null;
// 10개 요청했는데 11개가 왔다면
if (chatMessages.size() > limit) {
//마지막 index값을 next에다 할당하고
next = chatMessages.get(chatMessages.size() - 1);
// 원본 list에서는 마지막 index값을 지우고
chatMessages.remove(chatMessages.size() - 1);
}
// chatMEssages랑 next를 넣어서 리턴
return HttpResponse.ofJson(HttpStatus.OK, new GetMessagesResponse(chatMessages, next));
}
}de.hbase.talk.api.SendMessageRequest
package de.hbase.talk.api;
import com.fasterxml.jackson.annotation.JsonIgnoreProperties;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.extern.jackson.Jacksonized;
@Data
@Jacksonized
@NoArgsConstructor
@Builder
@AllArgsConstructor
@JsonIgnoreProperties(ignoreUnknown = true)
public class SendMessageRequest {
String chatRoomId;
String senderUserId;
String content;
}de.hbase.talk.api.GetMessagesRequest
package de.hbase.talk.api;
import org.codehaus.jackson.annotate.JsonIgnoreProperties;
import de.hbase.talk.data.ChatMessage;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.extern.jackson.Jacksonized;
@Data // Lombok → getter/setter, toString, equals 자동 생성
@Builder // Lombok → 빌더 패턴 클래스 자동 생성
@NoArgsConstructor // Lombok → 기본 생성자 자동 생성
@AllArgsConstructor // Lombok → 모든 필드 받는 생성자 자동 생성
@Jacksonized // Lombok + Jackson → 직렬화/역직렬화 지원
@JsonIgnoreProperties(ignoreUnknown = true) // Jackson → JSON 변환 시 모르는 필드 무시
public class GetMessagesRequest {
// 이거는 어쩔 수 없이 post로, body로 받긴 하는데
private ChatMessage start; //start 지점이 되는 메세지 통째로 넣고
private int limit; // 개수를 넣게 해 두었다.
}de.hbase.talk.api.GetMessagesResponse
package de.hbase.talk.api;
import java.util.List;
import org.codehaus.jackson.annotate.JsonIgnoreProperties;
import de.hbase.talk.data.ChatMessage;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.extern.jackson.Jacksonized;
@Data
@Jacksonized
@NoArgsConstructor
@Builder
@AllArgsConstructor
@JsonIgnoreProperties(ignoreUnknown = true)
public class GetMessagesResponse {
private List<ChatMessage> chatMessages;
private ChatMessage next;
// 스크롤을 내리며 메시지를 추가로 요청할 때 사용되는 구조.
// 예를 들어, 한 번에 10개씩 가져온다면 처음 요청은 100번~91번 메시지를 반환한다.
// 이후 클라이언트는 90번부터 이전 10개를 요청해야 한다.
//
// HBase 조회 방식은 prefix 기반이므로 특정 키를 기준으로 이전/이후 데이터를 조회할 수 있다.
// 따라서 서버는 요청 개수(예: 10개)보다 하나 더 조회하여 마지막 메시지를 next에 저장한다.
// 클라이언트는 next를 기준으로 다음 요청을 이어갈 수 있다.
//
// 만약 데이터가 1번~10번까지만 있다면 next는 null이 되고,
// 클라이언트는 이를 통해 더 이상 메시지가 없음을 알 수 있다.
//
// 이 방식은 클라이언트가 인덱스 값을 직접 파싱하지 않아도 되고,
// response 객체 자체를 다음 요청에 활용할 수 있어 구현이 단순해진다.
// 또한 DB 인덱스 일관성 유지에도 유리하다.
// ChatAPI 클래스의 responseMessages()는 그걸 만드는 과정이다.
}de.hbase.talk.TalkApp
package de.hbase.talk;
import java.io.IOException;
import java.util.concurrent.CompletableFuture;
import org.apache.commons.lang3.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import com.linecorp.armeria.server.Server;
import com.linecorp.armeria.server.ServerBuilder;
import com.linecorp.armeria.server.docs.DocService;
import de.hbase.talk.api.ChatApi;
import de.hbase.talk.storage.ChatMessageStorage;
import de.hbase.talk.storage.ChatRoomStorage;
import de.hbase.talk.storage.UserStorage;
import lombok.extern.slf4j.Slf4j;
@Slf4j
public class TalkApp {
public static void main(String[] args) throws IOException {
if (args.length != 1) {
log.error("pass zookeeper quorum of HBase as first argument");
System.exit(1);
}
String zkQuorum = args[0];
if (StringUtils.isBlank(zkQuorum)) {
log.error("pass zookeeper quorum of HBase as first argument");
System.exit(1);
}
// configuration 만들면 이 친구가 자동으로 자기가 알고 있는 path랑 class path, 그리고 Hadoop dir에서 경로를 찾아 우리 HBase conf도 HBase Home에서 찾을 것
Configuration configuration = HBaseConfiguration.create();
configuration.set("hbase.master", zkQuorum+":16000"); // Hbase master port가 16000
configuration.set("hbase.zookeeper.quorum", zkQuorum);
configuration.set("hbase.zookeeper.property.clientPort", "2181");
HBaseAdmin.available(configuration); // void. exception 던지지 않으면 정상적으로 사용된 것임.
Connection connection = ConnectionFactory.createConnection(configuration);
// 우리가 사용할 테이블 log 찍기
log.info("table 'user' available: {}", connection.getAdmin().isTableAvailable(TableName.valueOf("user")));
log.info("table 'chatroom' available: {}", connection.getAdmin().isTableAvailable(TableName.valueOf("chatroom")));
log.info("table 'chatmessage' available: {}", connection.getAdmin().isTableAvailable(TableName.valueOf("chatmessage")));
UserStorage userStorage = new UserStorage(connection);
ChatRoomStorage chatRoomStorage = new ChatRoomStorage(connection);
ChatMessageStorage chatMessageStorage = new ChatMessageStorage(connection);
log.info("Storages are created.");
// armeria 서버 빌더를 이용해 8080 포트를 열고
ServerBuilder sb = Server.builder();
// Configure an HTTP port.
sb.http(8080);
Server server = sb
.annotatedService(new ChatApi(userStorage, chatRoomStorage, chatMessageStorage))
.serviceUnder("/docs", new DocService())
.build();
CompletableFuture<Void> future = server.start();
// Wait until the server is ready.
future.join();
}
}2.5 실행
빌드해서 shadowJar 를 뽑는다.
./gradlew build shadowJarSCP 를 이용해 HBase 가 설치된 노드로 jar 파일을 옮긴다.
scp -i $YOUR_KEY_FILE $YOUR_PROJECT_PATH/build/libs/de-hbase-1.0-all.jar ubuntu@$YOUR_EC2_HOST:~/HBase 주소를 파라미터로 주어 실행한다.
java -jar de-hbase-1.0-all.jar localhost$YOUR_EC2_HOST:8080/docs 에 접속해서 docs UI 를 이용해서 request 를 날리고 결과를 확인한다.
