6 Tez 엔진으로 성능 높이기
6.1 Tez
6.1.1 Tez 의 탄생 배경
전통적인 MapReduce 작업의 단점을 보완해서 Hadoop 에서 mapreduce 작업을 더 빠르게 수행할 수 있도록 돕는 엔진이다.
기존의 MapReduce의 단점을 해결하고, 고속화를 실현했다.
불필요한 단계가 감소하여 처리가 짧아지고 스테이지 사이의 대기 시간이 없어 처리 전체가 동시에 실행되어 실행시간이 단축된다.
6.1.2 Hive 의 engine 세팅
확인
set hive.execution.engine;- 실습에서 사용하는 EMR 은 기본으로 tez 로 동작한다.
- hive 2.0 부터 tez 가 default 이다.
변경
set hive.execution.engine = mr;
set hive.execution.engine = tez;
set hive.execution.engine = spark;- spark는 tez보다 빠르기는 한데 모든 Hive Query에 대해 잘 돌지 않는 일부 예외가 있음
6.2 Tez 와 MR 비교
5.4.1 의 select query 를 mr일때, tez 일 때 수행시간과 job 수행과정을 UI로 비교해보자.
- mr 은 yarn UI 에서 확인
- tez 는 tez-ui 에서 확인
$emr-primary-node-address:8080/tez-ui
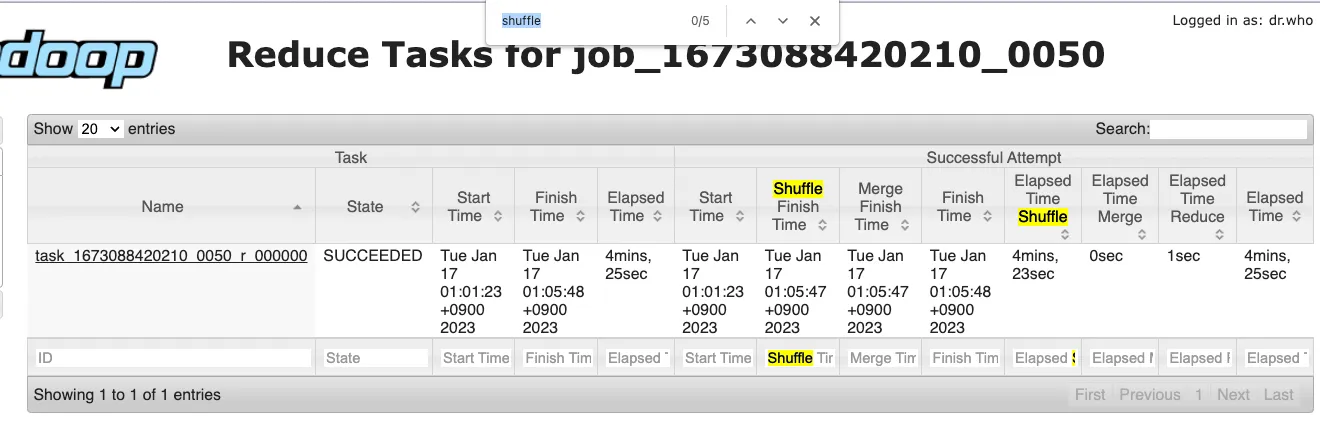
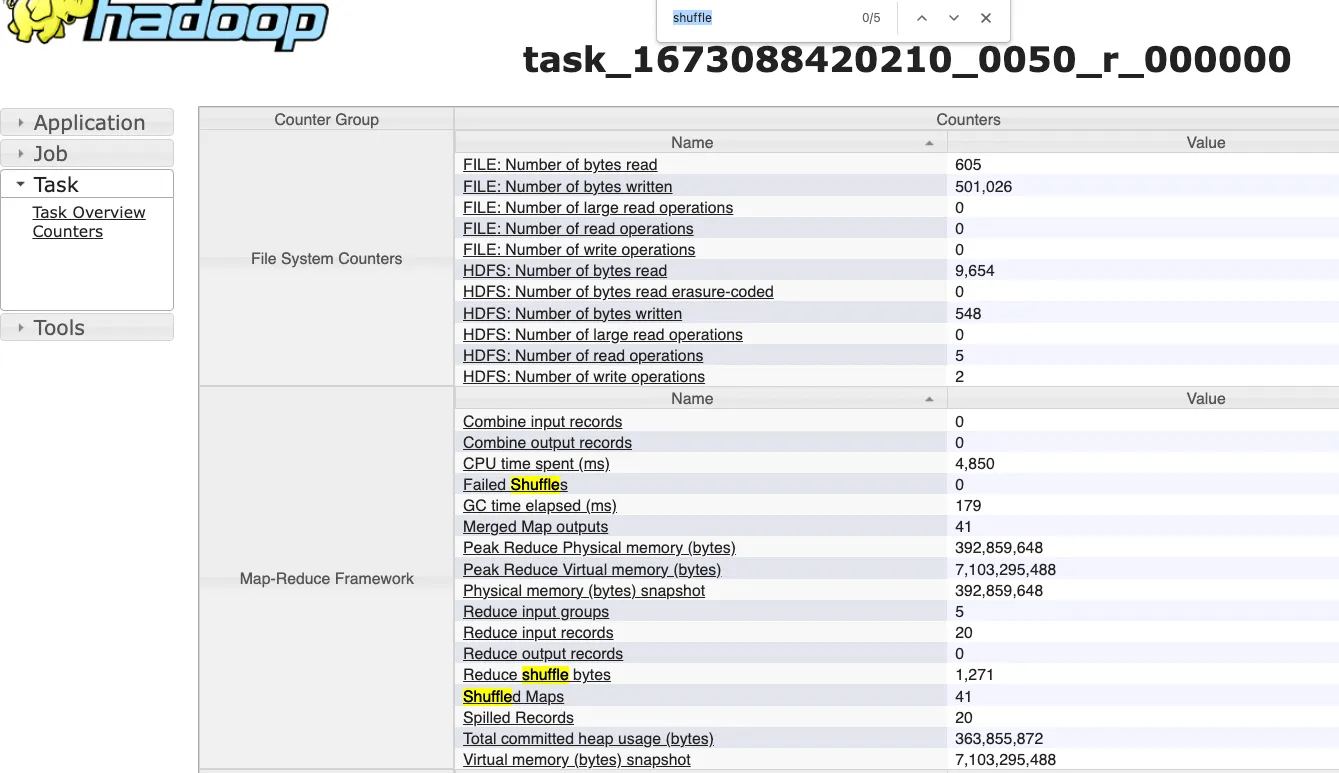
6.2.1 MR 수행결과
Shuffle 은 41회, shuffle 에 걸린 시간은 4분23초이다.
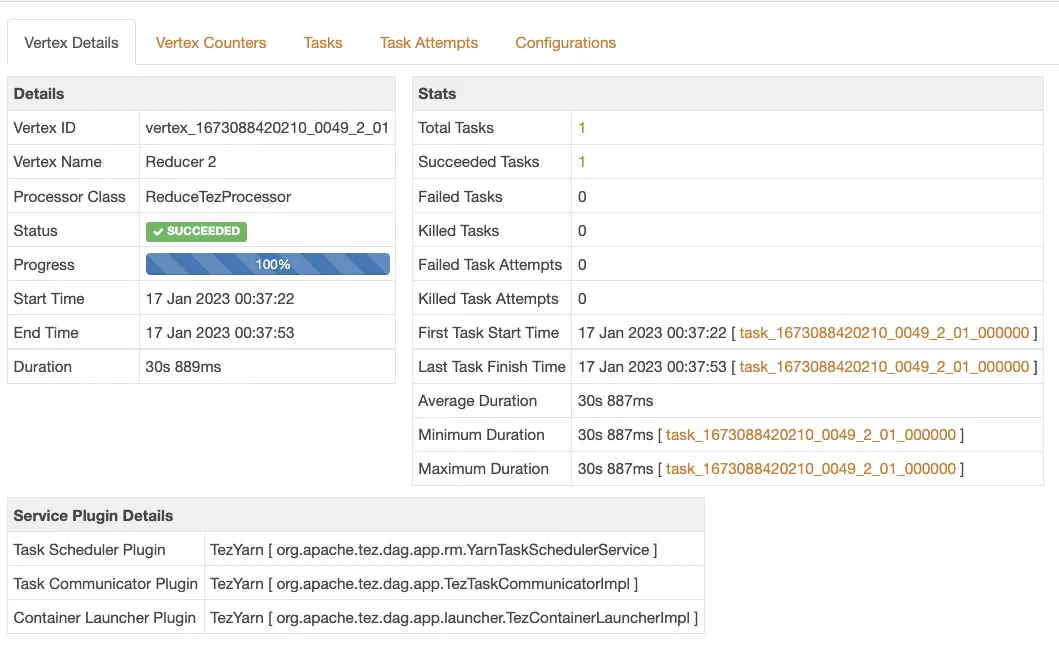
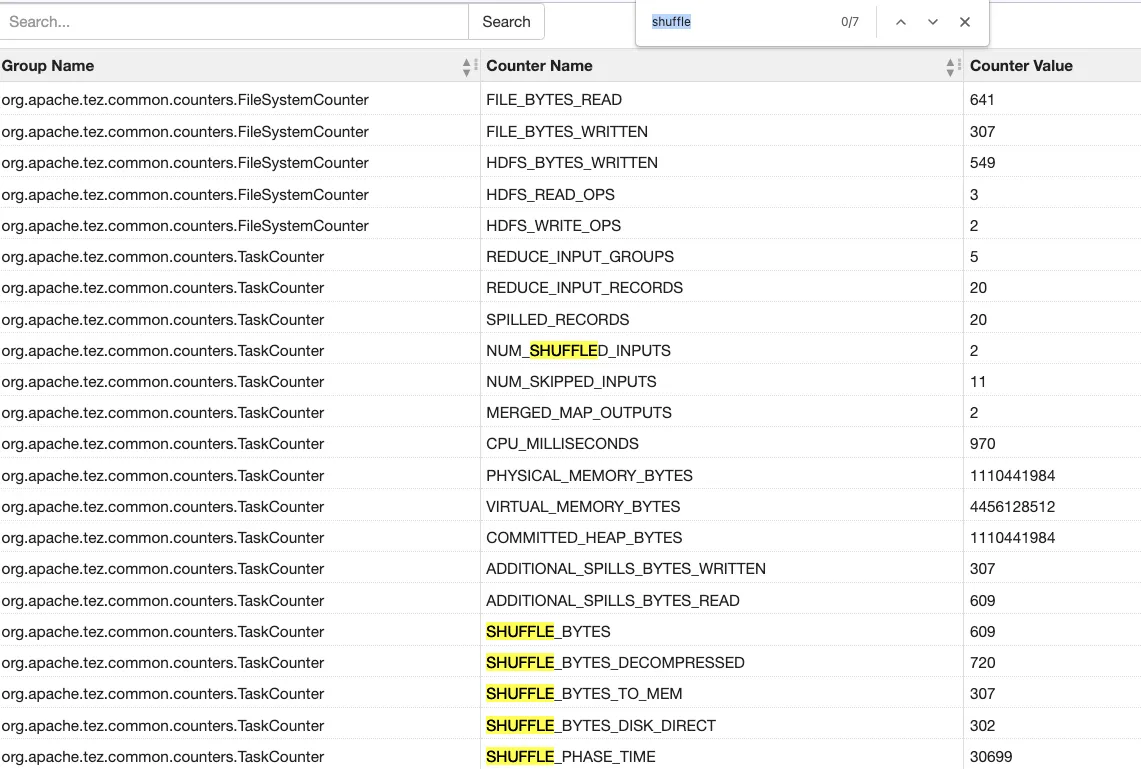
6.2.2 Tez 수행 결과
Shuffle 된 input 은 2개, shuffle 에는 30s 소요되었다.
- 같은 컨테이너에서 작업이 중간에 끊기지 않고 연속적으로 실행되는 것도 장점이며, 컨테이너를 재활용할 수 있다는 점도 장점이다. 또한 이로 인해 Shuffle 과정이 불필요하게 많이 발생하지 않아 효율성이 높아진다.
6.3 Tez 는 어떻게 동작할까
하둡에서 아파치 테즈의 데이터 처리는 MR, Hive, Pig에서 보다 빠르고 확장되었다.
이 프로젝트는 대화형 워크로드를 위한 YARN과의 진정한 통합을 위한 표준을 설정했다.
아래는 Apache Tez의 핵심 태스크에 대한 설명이다.
6.3.1 Express, model and execute processing logic
Tez는 데이터 처리를 dataflow graph로 모델링하며, 그래프의 정점(vertices)은 애플리케이션 로직을 나타내고 엣지(edges)는 데이터 이동을 나타낸다.
풍부한 dataflow definition API를 통해 사용자는 복잡한 쿼리 논리를 직관적으로 표현할 수 있다.
이 API는 아파치 하이브와 아파치 피그와 같은 더 높은 수준의 선언적 애플리케이션에 의해 생성된 쿼리 계획과 잘 맞는다.
이것이 hive 에서 execution engine으로 Tez 를 선택할 수 있는 이유이다.
- 데이터 플로우 그래프로 논리적 모델링을 수행한 뒤, 이를 API를 통해 실제 실행 단위인 물리적 모델과 연결할 수 있다는 점이다. 즉, SQL과 같은 고수준 언어에서 작성한 논리적 쿼리를 실제 실행 단위까지 효율적으로 매핑할 수 있다.
6.3.2 Model interaction between Input(E), Processor(T) and Output(L) Modules
Tez는 데이터 흐름 그래프의 각 정점(vertex)에서 실행되는 사용자 논리를 입력(Input), 프로세서(Processor), 출력(Output) 모듈의 상호작용으로 모델링한다.
Input & Output은 데이터의 형식과 데이터를 읽거나 쓰는 방법 및 위치를 결정하는데, 이는 데이터가 올바른 구조로 공급되고 저장되도록 하기 위함이다.
Processor는 이러한 입력 데이터를 변환하는 핵심 로직을 담당하며, 환된 데이터가 다시 올바른 형식으로 Output에 기록될 수 있도록 한다.
따라서 Input, Processor, Output이 각각 독립된 역할을 가지면서도, 서로 호환되는 형식을 유지해야 전체 데이터 흐름이 끊김 없이 실행될 수 있다.
Tez가 특정 데이터 형식을 강제하지 않는 이유는 다양한 데이터 소스와 목적지에 유연하게 대응하기 위해서이며, 이로 인해 사용자는 자신의 데이터 특성에 맞는 입력·출력 포맷을 선택할 수 있다.
6.3.3 Dynamically reconfigure graphs
MapReduce의 경우 데이터 처리 방식과 파티셔닝 방식을 모두 개발자가 코드로 사전에 정의해야 한다. 반면 Tez는 분산 데이터 처리가 여러 대의 컴퓨터에서 수행되고, 각 컴퓨터의 사용 가능한 자원, 데이터 위치, 실행 가능 노드 등이 실제 실행 시에 결정되기 때문에, 데이터 이동 방법을 사전에 고정적으로 정하기 어렵다.
분산 데이터 처리는 데이터 양과 처리 패턴이 동적으로 변하기 때문에 최적의 데이터 이동 방법을 사전에 결정하기 어렵다. 그러나 실행 도중 실제 데이터 크기, 분포, 클러스터 리소스 상태와 같은 런타임 정보를 확인할 수 있다면, 이를 기반으로 실행 계획을 보다 효율적으로 조정할 수 있다.
이러한 이유로 Tez는 플러그형 정점(vertex) 관리 모듈을 제공한다. 이 모듈은 런타임 정보를 수집하여 데이터 플로우 그래프(dataflow graph)를 동적으로 변경하며, 그 결과 전체 작업 성능과 클러스터 리소스 활용도를 최적화할 수 있다.
6.3.4 Optimize performance and resource management
yarn에서 리소스를 할당받고 컨테이너를 띄워서 수행을 하다 보니 yarn에서 리소스를 얻고 받납하고 이런 과정들을 좀 더 효율적으로 할 수 있도록 구현되어 있음.
YARN은 클러스터 용량 및 로드를 기반으로 하둡 클러스터의 리소스를 관리한다.
Tez 실행 엔진 프레임워크는 YARN에서 리소스를 효율적으로 획득하고 파이프라인의 모든 구성 요소를 재사용하여 불필요한 작업이 중복되지 않도록 한다.
6.3.5 API for defining directed acyclic graphs (DAGs)
Tez는 데이터 처리의 DAG를 표현하기 위해 simple java API를 정의한다.
API에는 세 가지 구성 요소가 있다.
-
DAG: 전체 작업을 방향성이 있고 cycle 이 생기지 않는 그래프 관계로 정의한다. 사용자는 각 데이터 처리 작업에 대해 DAG 개체를 생성한다. -
Vertices: 사용자 로직과 사용자 로직을 실행하는 데 필요한 리소스 및 환경을 정의한다. 사용자는 작업의 각 단계에 대해 Vertex 개체를 생성하여 DAG에 추가한다. -
Edges: 생산자(producer)와 소비자(consumer) 정점(vertices) 사이의 연결을 정의한다. 사용자는 Edge 개체를 만들고 이를 사용하여 생산자와 소비자 정점을 연결한다.- input이 되는 쪽이 생산자, 나가는 걸 받는 쪽이 소비자
6.3.6 Re-use containers
Tez는 사용자를 대신하여 YARN 위에서 프로세스로 실행되는 작업을 개별 태스크로 분리하는 전통적인 Hadoop 모델을 따른다.
이 모델에서는 프로세스 시작과 초기화, 느리게 실행되는 태스크(straggler) 처리, 그리고 YARN 리소스 관리자를 통한 컨테이너 할당 과정에서 각각 고유한 비용이 발생한다.
즉, 작업을 세분화해 유연성을 확보할 수 있지만, 그만큼 실행 시점마다 부가적인 오버헤드가 생기는 구조이다.
