1. JVM이란, JVM이 사용되는 이유
1.1 JVM이란
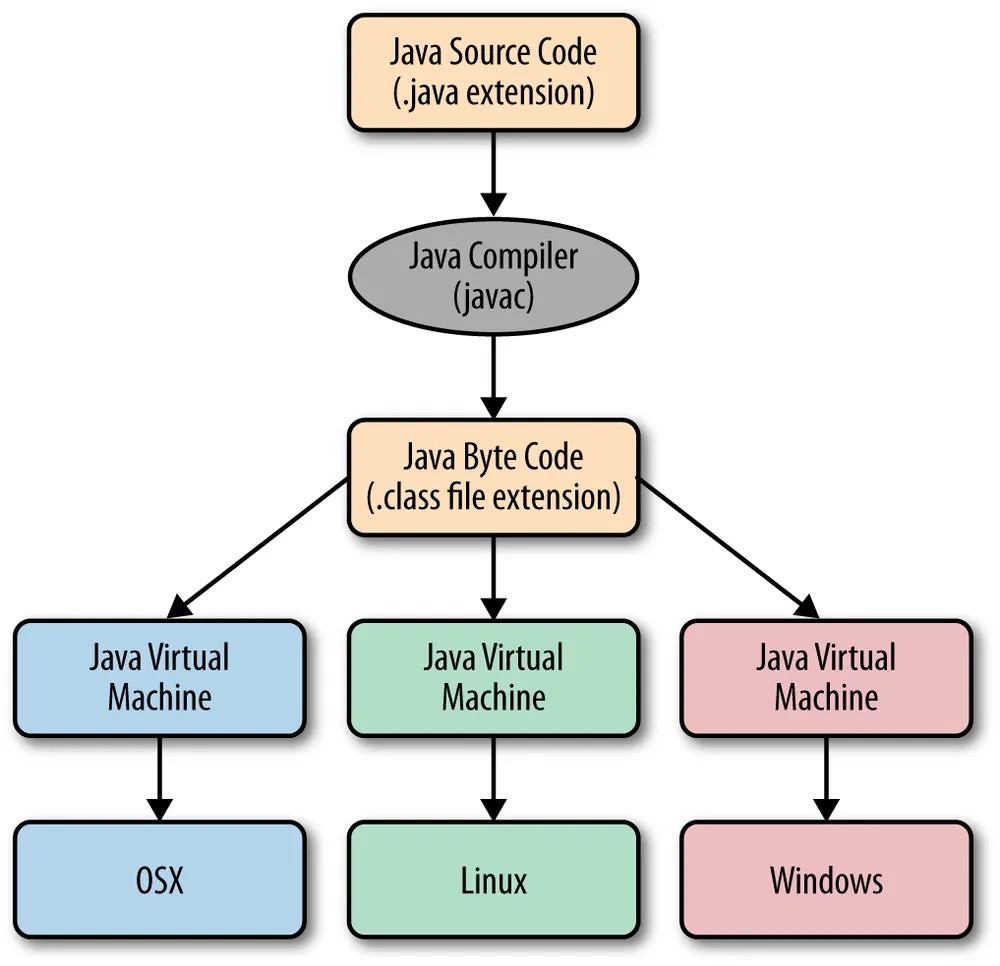
Java Virtual Machine 의 약자. Java 언어로 작성된 프로그램이 돌아갈 수 있는 가상 머신을 의미한다. 그 자체로 하나의 컴퓨터 처럼 동작한다. 내부적으로 thread 자원을 관리하고, 메모리도 주어진 메모리 안에서 알아서 관리한다.
JVM이 이해할 수 있는 machine instrcution으로 구성된 class파일 (java 코드를 컴파일해서 생성)을 읽어서 실행한다.
이미지 출처 : https://medium.com/@PrayagBhakar/lesson-2-behind-the-scenes-4df6a461f31f
class 파일에 실제로 JVM이 읽을 수 있는 머신 인스트럭션이 있다. 그 머신 인스트럭션을 JVM이 해독해서 운영체제에 맞는 실제 기계 코드에 호환되게 돌아가게 해준다.
이미지 출처 : https://notes.dmitriydubson.com/compilers/java-compile-process/
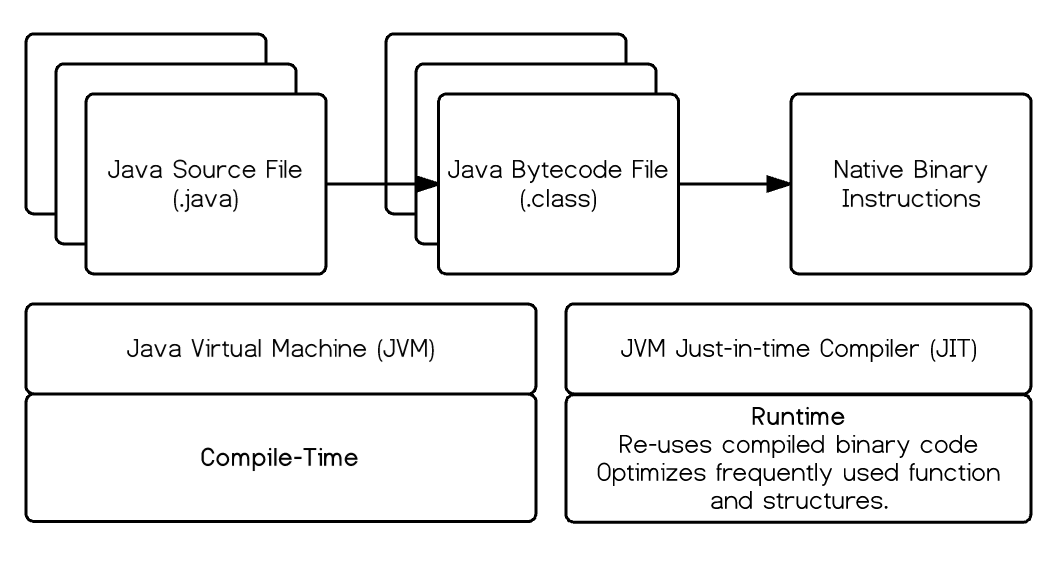
좀 더 정확하게 보면 자바 소스 파일에서
.class파일로 만들어 지는 건 컴파일 타임이고 실제 우리가 프로세스를 실행한다는 건 런타임이다.
런타임에는 JIT 컴파일러가 즉시즉시.class파일을 읽어서 머신 인스트럭션을 네이티브의 인스트럭션으로 바꿔서 실행을 해준다.
JIT(JVM Just-in-time Compiler)컴파일러, 저스틴 컴파일러라고 하는 코드가 들어온 대로 즉시즉시 실행할 수 있는 컴파일러다.
1.2 JVM이 쓰이는 이유
1.2.1 Java가 가져온 패러다임 변화
과거에는 고급 언어가 많지 않았고, Java는 "Write Once, Run Anywhere" 라는 철학으로 큰 인기를 끌었다. 기존에 널리 쓰이던 C나 C++에서는 메모리 관리가 가장 큰 어려움이었다.
개발자가 malloc과 free 같은 함수를 직접 호출해야 했고, 객체지향 프로그래밍에서는 여러 클래스와 객체 사이에서 컨텍스트가 이동하면서 메모리 참조와 해제를 관리하기가 복잡했다.
메모리를 할당했는데 해제를 하지 못하면 점유 상태가 유지되고, 이미 해제된 메모리를 참조하면 프로그램이 비정상 종료되기도 했다.
이 때문에 디버깅과 관리가 매우 어렵고, 큰 프로그램을 개발할 때 사이드 이펙트가 많아 개발 효율이 떨어졌다.Java는 이러한 문제를 해결하기 위해 가비지 컬렉션(GC) 을 제공한다.
개발자는 메모리 할당과 해제를 직접 신경 쓰지 않고 코드를 작성할 수 있고, JVM이 하드웨어와 운영체제에 맞춰 메모리를 관리한다.
또한 C나 C++에서는 플랫폼마다 별도로 빌드해야 했지만, Java는 한 번만 컴파일하면 JVM이 설치된 어떤 시스템에서도 동일하게 실행 가능하다.
JVM은 클래스 파일을 읽어 운영체제와 CPU 구조에 맞게 처리하기 때문에, 개발자는 환경 차이를 신경 쓰지 않고 코딩할 수 있다.
결과적으로 개발 속도가 빨라지고, 디버깅 시간과 난이도도 크게 줄어들게 되었다.
이것을 신경쓰지 않고 코딩할 수 있었기 때문이다.
따라서 오랜기간 안정성이 중요하고, 복잡도가 높은 시스템은 Java로 많이 개발되어 왔다.
물론 Java에도 단점은 존재한다.
C나 C++은 빌드 과정에서 바로 네이티브 머신 코드가 생성되지만, Java는 컴파일 결과물이.class파일 형태로 생성된다.
이 파일이 실제 네이티브 코드로 변환되는 과정은 런타임에서 JVM의 JIT(Just-In-Time) 컴파일러를 통해 수행되므로, 실행 속도 면에서는 C에 비해 다소 느릴 수 있다.
따라서 성능이 가장 중요한 경우에는 C로 개발하고, 안정성과 플랫폼 독립성이 중요한 경우에는 Java를 선택하는 경향이 있다.
1.2.2 JVM의 호환성과 안정성
Java가 인기를 끌면서 JVM도 시간이 지날수록 성숙해져서 속도도 빠르고, 메모리 관리도 잘하게 되었다.
30년 가까이 쌓여온 여러 운영체제와의 호환성 및 버그 수정의 이력이 JVM의 가장 강점이다.
JVM은 class 파일로 된 jvm machine instruction을 해석해서 동작한다는 것에 착안해서, Java 언어의 한계를 극복하고자 문법이 더 좋게 만들어진 언어들도, 그 결과물을 class 파일로 만들어 JVM에서 동작할 수 있도록 했다.
그래서 Java 언어의 한계는 뛰어넘고, JVM의 안정성은 취하는 전략으로 만들어진 언들로 인해 JVM은 더 다양한 분야에서 사용되게 되었다.
이러한 언어들로는 Groovy, Scala, Kotlin 등이 있다.
결국에는 어떤 언어의 컴파일(컴파일은 자바 컴파일러가 아니어도 되는 것)의 결과가 .class 파일이기만 하면 .class에 들어갈 수 있는 인스트럭션이기만 하면 이 친구는 JVM에서 돌아갈 수 있다. 아 나는 새로운 언어랑 컴파일러만 만들어야겠다. 그러면 JVM의 안정성이라는 장점을 가져갈 수 있으니까. 그런 전략으로 만들어진 언어들이 스칼라, 코틀린, 그루비 등이 있다.
스칼라는 펑셔널 프로그래밍이 가장 직관적이고 오류도 없고, 완결성을 가지는 좋은 프로그래밍이다.
코틀린은 가장 실용적인 문법을 가져다가 스칼라나 그루비, 자바에 있던 장점들만 가져온, 그리고 이상한 부분들은 버린 언어.
1.2.3 Java로 구현된 대용량 데이터 도구들
2000년대 후반부터 Single Machine의 한계를 극복하고자 개발된 많은 오픈소스들은 Java을 주 언어로 개발이 되었다.
현재 빅데이터분야에서 가장 많이 사용되는 Hadoop이 Java 로 만들어졌다.
그렇다보니 안정성있는 클라이언트 라이브러리도 Java로 만들어진 것이 가장 먼저 나오고, 가장 성숙했다.
한동안은 Hadoop을 쓰려면 Java 로 개발을 해야했다.
뿐만 아니라 Hadoop과 궁합이 좋은 리소스 매니저 Yarn의 역할도 컸다.
Yarn 또한 Java로 구현되어있어서 client API가 Java위주로 개발되었다.
따라서 Hadoop을 이용하는 대용량 분산처리 어플리케이션, 프레임워크들 또한 JVM에서 구동되는 언어들을 먼저 선택할 수 밖에 없었다.
하둡(Hadoop)은 대규모 분산 컴퓨팅 환경에서 여러 노드에 걸쳐 데이터를 처리하기 때문에, 이를 효율적으로 관리할 리소스 매니저가 필요하다.
대표적인 리소스 매니저인 YARN은 하둡 파일 시스템(HDFS)과 연동되어, 작업을 실행할 프로세스를 적절한 노드에 배치함으로써 데이터 로컬리티(Data Locality) 를 최적화하고, 작업 실행과 종료를 관리한다.YARN 또한 Java로 구현되어 있으며, 하둡 기반의 대용량 분산 처리 애플리케이션과 프레임워크들은 자연스럽게 JVM에서 실행되는 언어를 선택하게 된다.
초기 하둡 생태계에서 개발자들은 하둡을 이해하려면 Java 코드를 읽고 이해해야 했기 때문에, JVM 언어를 사용하는 것이 사실상 필수적이었다.
1.3 데이터 엔지니어링에서 Java, JVM이 중요한 이유
1.3.1 JVM에서 동작하는 데이터 엔지니어링 도구, 분산 데이터베이스들
Java
- Elasticsearch(Opensearch)
- Hadoop/Yarn
- HBase (하둡기반에서 돌아가는 대용량 빅테이블)
- Druid (큐브 스토리지)
- PrestoDB (복합 디빙)
- Cassandra (HBase와 비슷한 분산 디비)
Scala
- Kafka
- Spark
위와 같은 도구들이 Java 또는 JVM호환 언어로 개발되었다보니, 가장 먼저 지원되는 Client 라이브러리도 Java Client 일 수 밖에 없다.
따라서 신기술을 빠르게 적용하는 사람들이 Java 로 개발할 수 밖에 없었던 것이다.
1.3.2 Golang, Rust 로 대체되지 않을까요?
Golang 은 쉽고 확장성 있는 문법으로 누구나 다양한 프로그램을 개발할 수 있다.
빌드 또한 운영체제의 native library에 종속되지 않고 할 수 있다.
또한 메모리 관리를 자동으로 하는데도 포인터를 직접 쓸 수 있어서 고성능 어플리케이션을 만들 때 또한 좋다.
그런데 왜 Golang으로 만들어진 데이터 엔지니어링 도구는 별로 없는 것일까?
C, C++의 대체자 Rust. C 처럼 쉽고, C++ 보다는 복잡하지 않은, 그리고 C수준의 고성능 개발이 가능하다.
손쉬운 메모리 관리와 유연한 타입시스템. 게다가 빌드 결과물이 WASM으로 나오면 확장성까지 있다.
이제 고성능 데이터베이스는 Rust로 만들어야 하는 것 아닐까? 왜 분산 데이터베이스들은 다 Java로 만들어졌을까?
다음의 상황이 생길 경우, JVM과 그 기반언어가 데이터엔지니어링에서 가지는 지배력은 약해질 수도 있다.
- Hadoop의 절대적인 지위와 생태계가 약해진다면.
- Hadoop 수준의 성숙도와 호환성을 가지고 만들어진 분산 파일 시스템이 생긴다.
- hadoop-yarn을 대체할 분산 리소스 매니저와 파일 시스템의 조합이 다른 언어로 나온다면.
사실상 기업용에서 대용량 분산 파일 저장 시스템을 쓴다, 대용량 분산된 리소스 풀을 만들어 놓고 거기서 누구든지 원하는 작업을 얻었다 제출했다 하고싶으면 지금 무조건 선택되는 건 하둡이다.
