P08-C04 MapReduce
1 MapReduce Overview
Hadoop MapReduce 는 많은 양의 데이터 처리하는 어플리케이션을 쉽게 작성하는 것을 돕는 소프트웨어 프레임워크이다.
- 동시에 여러 머신들 또는 큰 클러스터에서 동작한다.
- 신뢰성(reliability)을 보장한다.
- 고장 감내성(fault tolerance)을 보장한다.
The Overall MapReduce Word Count Process
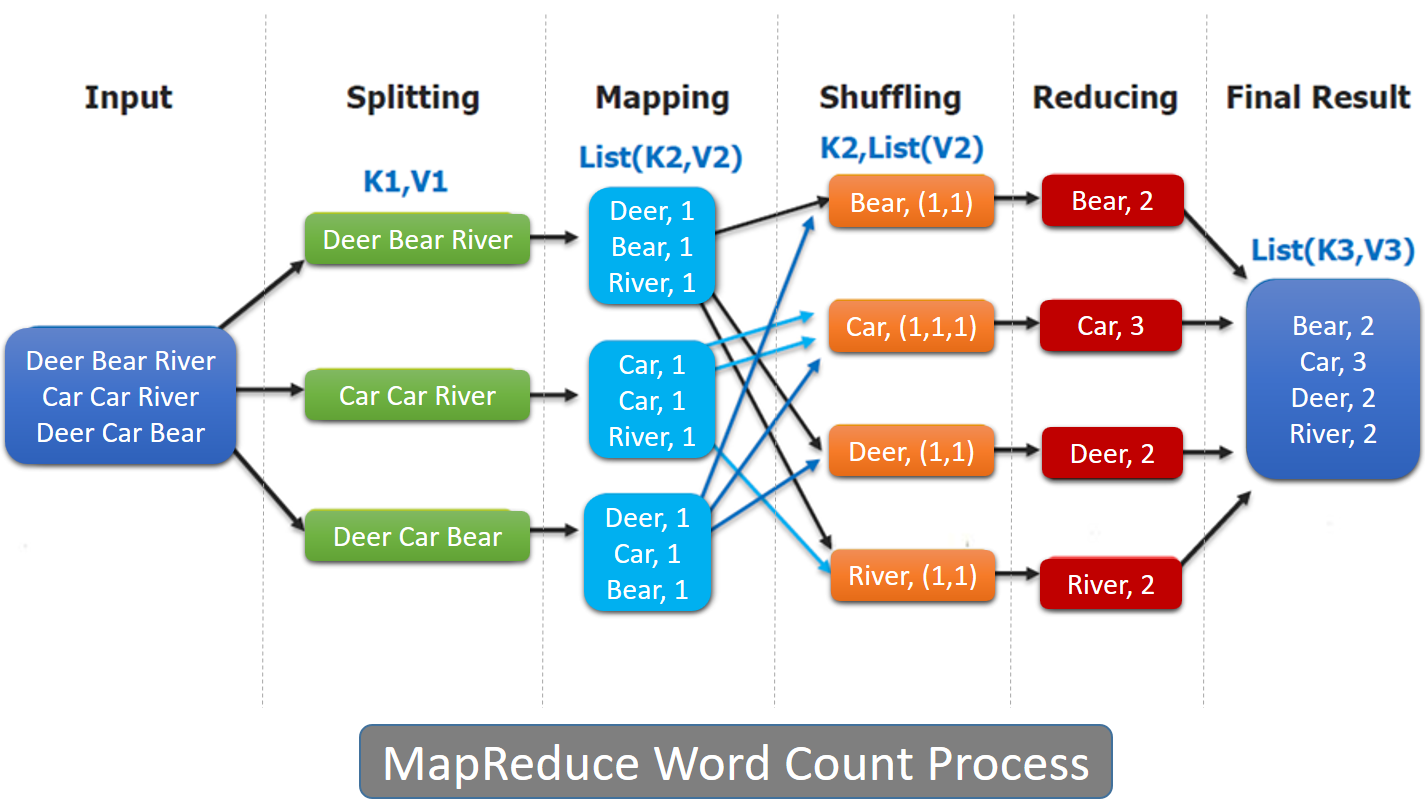
MapReduce job 은 input data-set 을 독립적인 chunk 단위로 나누고, 각 chunk에 대한 처리는 map task 에서 parallel 하게 수행된다.
map 의 output 은 정렬을 한 뒤에 reduce task 의 input 이 된다.
보통 Job의 input/output 은 모두 파일 시스템에 저장된다.
프레임워크는 task 에 대한 scheduling, monitoring, fail에 대한 재처리 등을 관리한다.
MapReduce 프레임워크와 HDFS 가 같은 노드 셋에서 동작한다면, 대개의 경우 storage node 와 computing node 는 같다.
이 방식으로 인해 task를 데이터가 있는 node 에 효과적으로 스케줄링 할 수 있고, 이 결과로 높은 aggregate bandwidth 를 가지므로 클러스터 전체적으로 대량의 데이터를 처리하는데 효과적이다.
MapReduce 프레임워크는 다음의 요소로 구성되어있다.
- 1개의 master ResourceManager
- cluster-node 당 1개의 worker NodeManager
- application 당 하나의 MRAppMaster (yarn 입장에서 AM역할)
최소한의 구성으로, 어플리케이션은 input, output location 을 지정하고, map 과 reduce 함수를 MapReduce 프레임워크에서 제공하는 interface와 abstract class 를 이용해서 구현해야한다.
- output location은 꼭 HDFS가 아니어도 되긴 하지만 기본적으로 HDFS인 경우가 많다.
구현체 외에 다른 job parameter 는 job configuration 으로 job 제출(submit)시에 설정한다.
Hadoop job client(Mapreduce를 작성한 Jar파일)는 job 과 configuration을 ResourceManager 에게 제출한다.
ResourceManager 는 다음 역할을 한다.
- application software 와 configuration 을 worker 에 나눠준다.
- 분산한 작업을 모니터링한다.
- status 또는 diagnostic information을 job-client 에게 제공한다.
Hadoop 프레임워크는 Java로 작성되었지만, MapReduce app 을 꼭 자바로만 작성할 필요는 없다.
- 결국 컨테이너에서 리소스가 할당되면 거기서 어떤 프로세스를 실행시키는 것이기 때문에 다른 언어로도 작성 할 수도 있음.
다음 도구들을 이용해서 다른 언어로도 작성할 수 있다.
- Hadoop Streaming is a utility which allows users to create and run jobs with any executables (e.g. shell utilities) as the mapper and/or the reducer.
- Hadoop Pipes is a SWIG compatible C++ API to implement MapReduce applications (non JNI™ based).
요약
하둡은 대량의 데이터를 저장하면서 메모리와 CPU 같은 리소스를 많이 점유하기 때문에, 데이터를 집계하거나 가공하는 작업을 클러스터 내부에서 실행하면 데이터가 존재하는 위치에서 직접 읽을 수 있어 네트워크 비용을 줄이고 데이터 로컬리티를 높일 수 있다. 그러나 단순히 파일을 읽고 처리한 뒤 다시 쓰는 방식은 효율이 낮았다. 이에 주목한 것이 대표적인 데이터 처리 패턴인 Map(데이터 변환)과 Reduce(데이터 집계)이며, 이를 기반으로 프로그래밍 모델을 인터페이스로 제공하고 하둡 시스템 위에서 효율적으로 실행되도록 만든 것이 MapReduce 프레임워크이다.
