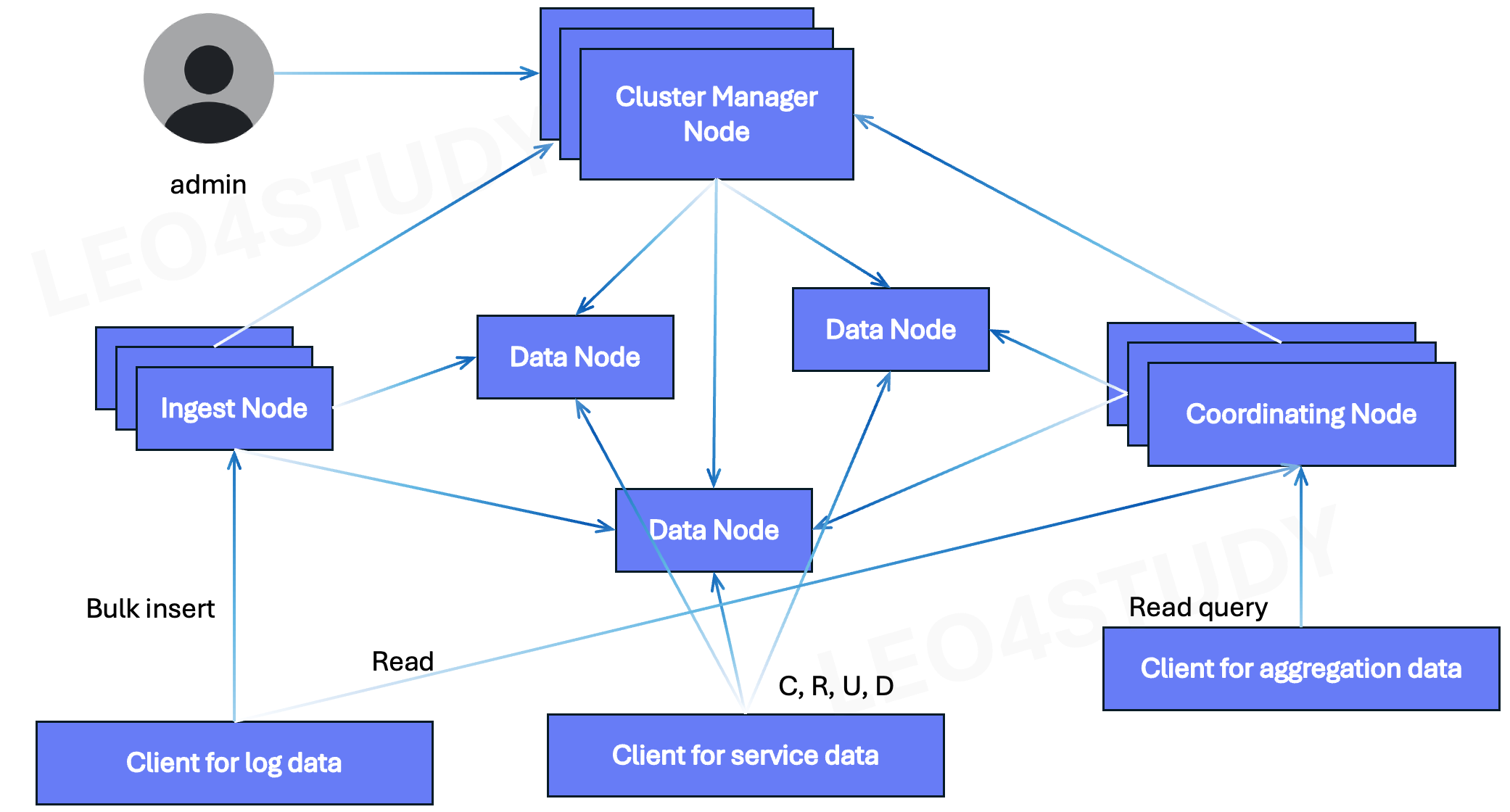
1. Coordinator Node란?
Coordinator Node는 모든 읽기(Read) 요청에서 핵심적인 역할을 수행한다.
- 데이터를 직접 저장하지 않음
- 쿼리 라우팅, 병렬 분산 처리, 결과 병합 및 정렬
- Elasticsearch의 모든 Read 요청은 반드시 Coordinator Node를 거침
"데이터를 어디서 찾을지 알고 있는 컨트롤 타워" 역할을 한다.
2. Client for Aggregation Data → Read → Coordinator Node
2.1 왜 Coordinator Node를 경유하는가?
- Aggregation 데이터는 여러 샤드에 분산 저장됨
- Coordinator Node가 쿼리를 각 샤드로 전파하고, 결과를 병합해 반환
- 통계, 그룹핑, 피벗 등 집계 중심 쿼리는 병렬 처리가 필수
2.2 예시
SELECT AVG(session_time) FROM user_metrics WHERE date BETWEEN '2025-08-01' AND '2025-08-06';2.3 데이터 흐름
[Client for aggregation data]
↓
[Coordinator Node]
↙ ↓ ↘
[DataNode1][DataNode2][DataNode3] → shard별 통계 계산
↓
결과 병합
↓
클라이언트 응답3. Client for Log Data → Read → Coordinator Node
3.1 왜 Coordinator Node를 경유하는가?
- 로그 데이터도 샤드로 분산 저장됨
- 로그 검색은 필터링, 조건 검색 등 다양한 연산 포함
- Coordinator Node는 shard 간 쿼리 분산 및 병합을 수행
3.2 예시
GET /logs/_search
{
"query": {
"match": { "error_code": "500" }
}
}3.3 데이터 흐름
[Client for log data]
↓
[Coordinator Node]
↙ ↓ ↘
[DataNode1][DataNode2][DataNode3] → shard별 로그 검색
↓
결과 병합
↓
클라이언트 응답4. Coordinator Node → Data Node
Coordinator Node는 사용자의 Read 요청을 받으면 실제 데이터를 저장하고 있는 Data Node들로 쿼리를 전달한다.
4.1 전체 흐름
[Client]
↓
[Coordinator Node] → 쿼리 라우팅 및 분산
↓ ↓ ↓
[Data Node 1] [Data Node 2] [Data Node 3]
↑ ↑ ↑
결과 결과 결과
↓ ↓ ↓
[Coordinator Node] → 결과 병합 및 정렬
↓
[Client 응답]4.2 단계별 상세 설명
-
Client는 쿼리를 Coordinator Node로 전달한다.
-
Coordinator Node는 다음을 수행한다:
- 어떤 인덱스인지 확인
- 해당 인덱스가 어떤 샤드(shard)에 분산되어 있는지 파악
- 각 샤드가 어느 Data Node에 위치해 있는지 메타데이터 조회 (Cluster Manager에 질의)
-
Coordinator Node → Data Node
- 각 샤드에 해당하는 Data Node에 쿼리를 병렬로 전송
- 예: “이 샤드에서 error_code=500 인 로그를 검색해줘”
-
Data Node는 실제 쿼리를 실행하고, 결과를 Coordinator Node에 다시 전달한다.
-
Coordinator Node는 수신한 결과를 정렬, 필터링, 병합하여 클라이언트에게 응답을 반환한다.
4.3 Node별 역할 설명
| 역할 | 설명 |
|---|---|
| Coordinator Node | 쿼리 수신, shard 분산, 결과 병합 |
| Data Node | 데이터를 실제 저장하고, 쿼리를 실행하는 주체 |
| Cluster Manager | shard의 위치 등 메타데이터만 관리. 쿼리 실행은 하지 않음 |
🔍 즉, 실제 데이터의 필터링, 집계, 정렬은 모두 Data Node에서 수행되므로, Coordinator Node → Data Node 단계는 필수적이다.
5. Coordinator Node vs Ingest Node
| 구분 | Ingest Node | Coordinator Node |
|---|---|---|
| 주 역할 | Write 시 전처리 (파싱, 필드 가공 등) | Read 시 쿼리 라우팅, 결과 병합 |
| Write 전용 | ✅ | ❌ |
| Read 전용 | ❌ | ✅ |
| 로그 전처리 | ✅ | ❌ |
| 검색, 집계 | ❌ | ✅ |
6. 핵심 요약
| 항목 | 설명 |
|---|---|
| Aggregation Data | 분석/통계 쿼리 → Coordinator Node 통해 병렬 처리 |
| Log Data | 검색/필터링 → Coordinator Node 통해 shard 병합 |
| Read 요청 시 필수 | ✅ Coordinator Node |
| Write 요청 시 필수 (로그 등) | ✅ Ingest Node |
| Coordinator → Data Node | ✅ 병렬로 쿼리 전송, 실제 조회 수행 |
결론
모든 데이터 유형에서 읽기 요청은 반드시 Coordinator Node를 경유해야 하고, 이는 로그, 집계, 서비스성 쿼리 모두에 해당되는 아키텍처 원칙이다.
또한, 실제 데이터를 저장하고 조회하는 주체는 Data Node이고,
Coordinator Node는 그 위치를 알고 병렬 쿼리 분산 → 결과 병합을 수행한다.
이 구조는 확장성 있는 분산 쿼리 시스템의 핵심 메커니즘이고,
실시간 로그 검색, 대용량 데이터 집계 등 다양한 서비스 시나리오에 최적화되어 있다.

Data Analytics Engineer 가 되