6 ORM
6.1 ORM 의 이해
6.1.1 ORM의 개념
ORM(Object-Relational Mapping)이란, 앞서 살펴본 JDBC에서 ResultSet과 POJO 클래스(Plain Old Java Object)를 수동으로 매핑하는 코드를 매번 작성하는 것이 번거롭기 때문에 만들어진 기술(라이브러리)이다.
즉, ORM은 데이터베이스 테이블과 자바 객체 간의 매핑을 자동화함으로써, 이러한 반복 작업을 효율적으로 처리할 수 있도록 도와주는 역할을 한다.
이름에서 추론할 수 있는 바와 같이, 객체와 Relational Model(관계형 데이터베이스 모델)을 매핑할 수 있는 기능을 가지고 있다. 하나의 테이블이 하나의 Java Class에 해당하고, FK와 같은 부가적인 기능은 함수로 제공한다.
Hibernate 로 대표되는 현대 ORM은 단순히 데이터 매핑 뿐만 아니라, 데이터의 캐시, 세션, 라이프사이클 관리 기능까지 더해져서 그 기능이 방대하다.
6.1.2 JPA
ORM의 유용성이 입증되고 나니 Hibernate, MyBatis, TopLink, CoCobase 등 ORM을 구현하는 라이브러리 또는 프레임워크가 많아졌다. 이 ORM 기술에 대한 표준화를 시도한 것이 JPA이다.
DB에 query를 날릴때 각 DB 제품별 전용 함수(get, retrieve, fetch)를 사용하는 것이 아니라 JDBC(표준인터페이스 Execute쿼리)를 사용했던 것과 마찬가지로, ORM과 관련해서 각 구현체의 함수를 따로 사용하는 것이 아니라 JPA의 인터페이스를 통해서 작성하면, ORM 구현체를 무엇을 사용하던지, 코드를 변경할 일이 없게 된다.
그림으로 보면 다음과 같다.
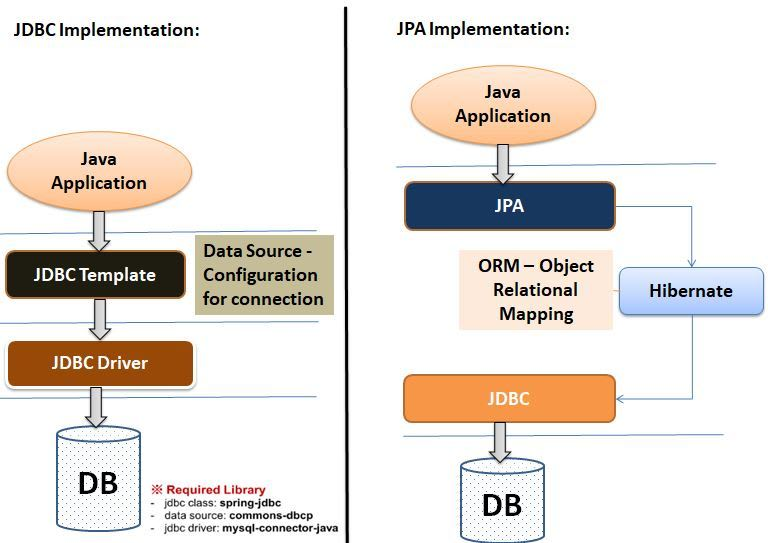
이미지 출처 : https://dev.to/urunov/how-to-handle-database-in-spring-boot-560
JDBC : 자바 어플리케이션이 있고, 우리가 JDBC 템플릿을 이용해서 JDBC 드라이버 구현체를 연결하면, 이 구현체를 갈아 끼우는 방식으로 내가 원하는 DB를 사용할 수 있다. 예를 들어, MySQL을 쓰고 싶으면 MySQL 드라이버를, PostgreSQL을 쓰고 싶으면 PostgreSQL 드라이버를 설정해서 연결하는 식이다. JDBC 템플릿은 단순히 JDBC를 좀 더 쉽게 다룰 수 있도록 도와주는 도구일 뿐, 직접적인 JDBC 드라이버 역할은 하지 않는다.
JPA : 자바 어플리케이션이 JPA라는 표준 인터페이스를 사용하면, 이 인터페이스가 실제로는 Hibernate 같은 구현체와 연결되어 동작하게 된다. JPA가 직접 데이터를 처리하는 것이 아니라, Hibernate와 같은 구현체가 그 기능을 수행하며, 이 Hibernate는 내부적으로 JDBC를 이용해서 DB에 접근한다. 이때 쓰이는 JDBC는 위에서 설명한 것처럼 드라이버 구현체를 통해 동작하게 된다.
6.1.3 왜 JPA를 안배우고 JDBC를 배웠나?
만약 RDBMS에서 데이터를 읽고 쓰는 일이 많다면, 개발 생산성 측면에서는 JPA를 쓸 수 밖에 없다. 하지만 JPA는 필수는 아니다. Java에서 RDBMS를 사용하는데 필수인 기술은 JDBC이다. JPA도 내부적으로는 JDBC를 통해서 RDBMS와 상호작용한다. 가장 말단의 구현체의 원리를 알면, 그것을 추상화하거나 감싼 라이브러리나 기술을 이해하는 깊이가 깊어진다.
뿐만 아니라, 데이터 엔지니어로 일하면서 RDBMS가 아니라 OLAP 서비스를 제공할때 JDBC 인터페이스에 맞는 기능을 제공해야할 경우가 생긴다. Java와 JDBC가 오래된 기술이라 이미 그것을 이용해서 만들어진 도구들이 많은데, 대용량 분석도구는 생긴지 얼마 안되어서 대용량 분석도구에 맞는 쿼리나 접근방식을 일일히 구현하기 어렵기 때문이다. 이때 JDBC를 한 번이라도 JPA등을 통하지 않고 직접 써본 경험이 있다면 큰 도움이 된다.
물론, JPA를 제대로 이해하고 사용하기 위해서는 배워야할 것이 많은데 그것을 이 강의에서 다루면 강의 양이 지나치게 많아지는 이유도 있다.
6.1.4 추천하는 JPA는?
빠르게 개발해야 한다면, SpringBoot의 spring-data-jpa를 추천한다. Entity 클래스와 Repository 인터페이스만 선언하면 바로 사용할 수 있어서 개발 속도가 매우 빠르다.
하지만 Spring Framework가 필요 없다면, 순수한 Hibernate JPA를 쓰는 걸 추천한다. spring-data-jpa는 JPA 기능 외에도 Spring Framework에 필요한 다양한 의존성이 함께 들어오기 때문에, 런타임에 Spring이 Bean을 로드하거나 라이프사이클을 관리하는 등 추가 동작이 많아진다. 그 결과 애플리케이션이 불필요하게 무거워지고, 리소스를 더 많이 쓰게 된다.
게다가 Spring을 쓰면 다른 라이브러리들과 의존성이 얽힐 수 있는데, 이걸 해결하려면 의존성 하나하나를 분석하고 조율해야 한다. 이런 작업은 시니어 개발자 수준의 역량이 필요할 정도로 어렵다. 그래서 굳이 Spring을 쓰지 않아도 된다면, JPA 기능에 집중된 Hibernate만 사용하는 것이 더 낫다. Hibernate는 기능적으로 충분히 풍부하면서도, Spring처럼 무거운 프레임워크에 종속되지 않기 때문이다.
6.2 Spring Data JPA 사용해보기
6.2.1 프로젝트 생성하기
IntelliJ
1. new project
2. Spring Initializer 선택
3. 원하는 프로젝트 이름 설정
4. Language: Java
5. Type: Gradle
6. JDK: 1.8
7. Java: 8
8. Packaging: Jar
9. Next
10. Spring Boot 2.7.3
11. Spring Data JPA 패키지 선택
6.2.2 의존성 추가
IntelliJ IDEA에 의해서 생성된 프로젝트의 build.gradle에 다음 설정을 추가한다.
dependencies {
implementation 'mysql:mysql-connector-java:8.0.30'
compileOnly 'org.projectlombok:lombok:1.18.24'
annotationProcessor 'org.projectlombok:lombok:1.18.24'
}6.2.3 Entity 선언하기
Entity는 DB의 table 에 매핑되는 클래스이다. 테이블의 column 정보를 member 변수로 가지고 column의 특징에 맞는 속성을 @Column annotation을 통해서 설정한다.
Entity는 모든 파라미터를 받는 Constructor와 아무것도 받지 않는 Contructor가 기본으로 있어야 한다.
@Column(name = "..."): DB 컬럼명이 Java 필드명과 다를 때 명시적으로 매핑할 수 있어, 코드 리팩토링 시 유지보수에 도움이 된다.
-@GeneratedValue : DB마다 다르게 동작할 수 있으니, 실무에서는 IDENTITY, SEQUENCE, TABLE 중 명확하게 지정하는 게 좋다.
- Lombok 사용 시 IDE 플러그인 설치와 delombok 빌드 옵션을 고려해야 한다 (특히 팀 프로젝트나 빌드 자동화 환경에서).
import java.time.LocalDateTime;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import lombok.AllArgsConstructor;
import lombok.Getter;
import lombok.NoArgsConstructor;
import lombok.ToString;
@Entity(name = "product") // 이 클래스는 DB의 'product' 테이블과 매핑된다. (name 지정 안 하면 클래스명 사용)
@AllArgsConstructor // 모든 필드를 인자로 받는 생성자 자동 생성 (Lombok)
@NoArgsConstructor // 파라미터가 없는 기본 생성자 자동 생성 (JPA 명세상 필요)
@Getter // 모든 필드에 대해 getter 메서드 자동 생성
@ToString // 객체를 출력할 때 필드 정보를 문자열로 출력 (디버깅용으로 유용)
public class Product {
@Id // 이 필드는 테이블의 기본 키(Primary Key)
// 여러 개 콤비네이션 하는 경우 ID 어노테이션을 복수개 달아주면 콤비네이션 적용 가능.
@GeneratedValue(strategy = GenerationType.AUTO)
// 기본 키 값을 자동으로 생성 (DB 벤더에 따라 전략 결정)
private Long id; //Unsigned INT 니까 Long 사용
private String name;
@Column(name = "updated_at", columnDefinition = "DATE")
// DB 컬럼명은 'updated_at'이며, 타입은 DATE로 지정
// column이라는 어노테이션에 여러 가지 옵션을 주면 실제 데이터베이스의 설정과 맞추는 작업을 할 수 있고 그래서 아주 중요하다.
private LocalDateTime updatedAt;
private String contents;
private int price;
}6.2.4 Repository 선언하기
Spring data jpa의 repository는 DB의 query를 쉽게 작성하도록 도와준다.
CRUD를 위해 기본으로 제공하는 함수가 있고, 이름의 규칙으로 원하는 함수를 쉽게 만들수도 있다.
@Query annotation을 사용하면 직접 SLQ문을 작성해서 함수에 매핑시킬 수 있는데, 함수의 파라미터를 변수로 포함할 수 있다.
import java.util.List;
import javax.transaction.Transactional;
import org.de.spring.jpa.ex.entity.Product;
import org.springframework.data.jpa.repository.Modifying;
import org.springframework.data.jpa.repository.Query;
import org.springframework.data.repository.CrudRepository;
public interface ProductRepository extends CrudRepository<Product, Long> {
List<Product> findTop10ByOrderByPriceDesc();
List<Product> findByPriceGreaterThanOrderByPriceDesc(int price);
@Modifying
@Transactional
@Query("UPDATE product p SET p.price = p.price + :plus where id = :id")
int plusPrice(Long id, int plus);
}6.2.5 예제: Spring Data JPA 활용
package org.de.spring.jpa.ex;
import java.time.LocalDateTime;
import org.de.spring.jpa.ex.entity.Product; // can be different package name
import org.de.spring.jpa.ex.repository.ProductRepository; // can be different package name
import org.springframework.boot.CommandLineRunner;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.Bean;
import lombok.extern.slf4j.Slf4j;
@SpringBootApplication
@Slf4j
public class SpringJpaExApplication {
public static void main(String[] args) {
SpringApplication.run(SpringJpaExApplication.class, args);
}
@Bean
public CommandLineRunner demo(ProductRepository productRepository) {
return args -> {
productRepository
.save(new Product(101L, "product101", LocalDateTime.now(), "content101", 101));
productRepository
.save(new Product(102L, "product102", LocalDateTime.now(), "content102", 102));
log.info("=== all records ===");
for (Product product : productRepository.findAll()) {
log.info(product.toString());
}
log.info("find by id = 101");
productRepository.findById(101L).ifPresent(it -> log.info(it.toString()));
log.info("find top 10 order by price desc");
for (Product product : productRepository.findTop10ByOrderByPriceDesc()) {
log.info(product.toString());
}
log.info("find by price greater than 10000");
for (Product product : productRepository
.findByPriceGreaterThanOrderByPriceDesc(10000)) {
log.info(product.toString());
}
log.info("plus price + 10000 where id = 101: "
+ productRepository.plusPrice(101L, 10000));
log.info("find by id = 101");
productRepository.findById(101L).ifPresent(it -> log.info(it.toString()));
};
}
}application.properties
spring.datasource.url=jdbc:mysql://${MYSQL_HOST:localhost}:3306/de-jdbc
spring.datasource.username=root
#spring.datasource.password=ThePassword
spring.application.name=spring_jpa_ex
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.jpa.show-sql=truespring.jpa.show-sql=true : 이 설정은 JPA가 실행하는 실제 SQL 쿼리문을 콘솔에 출력해준다.
- 즉, 애플리케이션이 데이터베이스에 어떤 SQL을 날리고 있는지 그대로 확인할 수 있다.
- 디버깅이나 로컬 개발 환경에서는 매우 유용한 옵션이다.
하지만 운영(서비스) 환경에서는 사용하지 않는 것이 좋다.
그 이유는 다음과 같다:
- 성능 저하: 매 쿼리 실행 시마다 로그에 출력하기 때문에 I/O 비용이 발생하고, 대량 트래픽에서는 성능 저하로 이어질 수 있다.
- 보안 이슈: 출력되는 쿼리에 민감한 데이터(예: 사용자 정보, 비밀번호 해시 등)가 포함되어 있을 경우, 로그 노출로 인해 보안 위험이 발생할 수 있다.
따라서 운영 환경에서는 spring.jpa.show-sql=false로 설정하는 것이 바람직하다.
추가 팁
운영 환경에서도 SQL 로그가 필요할 경우에는 show-sql 대신 logging.level.org.hibernate.SQL=DEBUG와 logging.level.org.hibernate.type.descriptor.sql=TRACE를 조합해서 로그 레벨로 관리하는 방법이 더 유연하고 안전하다
6.3 오류
위에 실습 코드대로 실행을 했는데 계속해서 오류가 났다
로그에 보여진 주요 오류 메세지
java.sql.SQLSyntaxErrorException: Table 'de-jdbc.hibernate_sequence' doesn't exist
로그에 나타난 오류는 Hibernate가 ID 생성을 위해 사용하는 시퀀스 테이블인 hibernate_sequence가 MySQL 데이터베이스에 존재하지 않기 때문에 발생한 것인데
Hibernate는 @GeneratedValue(strategy = GenerationType.SEQUENCE) 또는 GenerationType.AUTO를 사용할 때, hibernate_sequence 테이블을 기본적으로 참조하려고 한다. 하지만 MySQL은 기본적으로 SEQUENCE 객체를 지원하지 않고, 보통 IDENTITY 전략을 사용한다.
그래서 ID 전략을 IDENTITY 로 지정해주니 오류 없이 잘 동작하는 모습을 확인했다.
AUTO로 해 놨으면 알아서 되란 말이야..
6.3.1 왜 GenerationType.IDENTITY는 잘 작동했을까?
1) Hibernate의 ID 생성 전략 비교
| 전략 유형 | 설명 | 사용 조건 |
|---|---|---|
IDENTITY | DB의 AUTO_INCREMENT 기능 사용 | MySQL에 최적화 |
SEQUENCE | DB의 SEQUENCE 객체 사용 | PostgreSQL, Oracle 등에서 사용 |
TABLE | ID 값을 저장하는 테이블(hibernate_sequence)에서 가져옴 | 모든 DB에서 사용 가능, 설정 필요 |
AUTO | 위 전략 중 DB에 맞게 자동 선택 | DB 종류에 따라 다름 |
Hibernate에서 AUTO 전략은 보통 MySQL에서는 TABLE 전략으로 fallback하는데, 이때 hibernate_sequence라는 테이블이 필요하다. 하지만 해당 테이블이 없으면 오류가 발생한다.
2) MySQL은 SEQUENCE를 지원하지 않음
MySQL은 Oracle이나 PostgreSQL처럼 시퀀스 객체(예: CREATE SEQUENCE)를 지원하지 않기 때문에, Hibernate가 TABLE 전략으로 대체하지만, 그에 필요한 테이블(hibernate_sequence)이 없으면 아래처럼 오류가 발생한다:
java.sql.SQLSyntaxErrorException: Table 'hibernate_sequence' doesn't exist3) IDENTITY는 MySQL의 AUTO_INCREMENT를 직접 사용
@GeneratedValue(strategy = GenerationType.IDENTITY)이 설정은 DB에 insert 할 때 Hibernate가 ID 값을 직접 생성하지 않고, DB(MySQL)가 자동으로 ID를 할당하는 구조다.
예:
INSERT INTO product (name, price, ...) VALUES ('item', 1000);-- MySQL이 자동으로 ID 생성 (AUTO_INCREMENT)
Hibernate는 SELECT LAST_INSERT_ID() 등을 사용하여 생성된 값을 확인하므로 추가 설정이 전혀 필요하지 않고, hibernate_sequence 테이블도 필요 없다.
6.3.2 GenerationType.AUTO는 실제로 어떤 전략을 선택할까?
Hibernate에서 @GeneratedValue(strategy = GenerationType.AUTO)는 다음과 같이 작동한다:
- Hibernate가 사용 중인 Dialect(MySQL, PostgreSQL 등) 과
- JPA provider 버전(Hibernate 버전) 에 따라
- SEQUENCE, IDENTITY, 또는 TABLE 전략 중 하나를 자동 선택한다.
6.3.3 왜 어떤 환경에서는 잘 되고, 어떤 환경에서는 오류가 날까?
1) Hibernate 버전 차이
Hibernate 5.0 이후, 특히 5.2.x~5.6.x에서는 MySQL에서도 AUTO 전략을 사용할 경우 기본적으로 TABLE 전략으로 fallback하는 경우가 있다.
- Hibernate 5.6.x에서 MySQL + AUTO → TABLE 전략 사용 →
hibernate_sequence테이블 필요
2) Dialect 차이
- 예전에는
org.hibernate.dialect.MySQL5InnoDBDialect등을 많이 사용했지만, - 지금은
org.hibernate.dialect.MySQL8Dialect등을 사용한다.
Hibernate는 Dialect에 따라 기본 ID 전략을 다르게 해석할 수 있다.
3) 설정 차이
- application.properties/yml에서
hibernate.id.new_generator_mappings=true/false설정에 따라 ID 전략이 달라질 수 있다.
| 환경 | Hibernate 버전 | Dialect | AUTO 전략 해석 | 동작 여부 |
|---|---|---|---|---|
| 예전 환경 | 5.2.x | MySQL5Dialect | IDENTITY | ✅ 잘 동작 |
| 현재 환경 | 5.6.x | MySQL8Dialect | TABLE | ❌ hibernate_sequence 필요 (없어서 오류) |
