2 MySQL Architecture
2.1 MySQL Basic Architecture
2.1.1 Overview
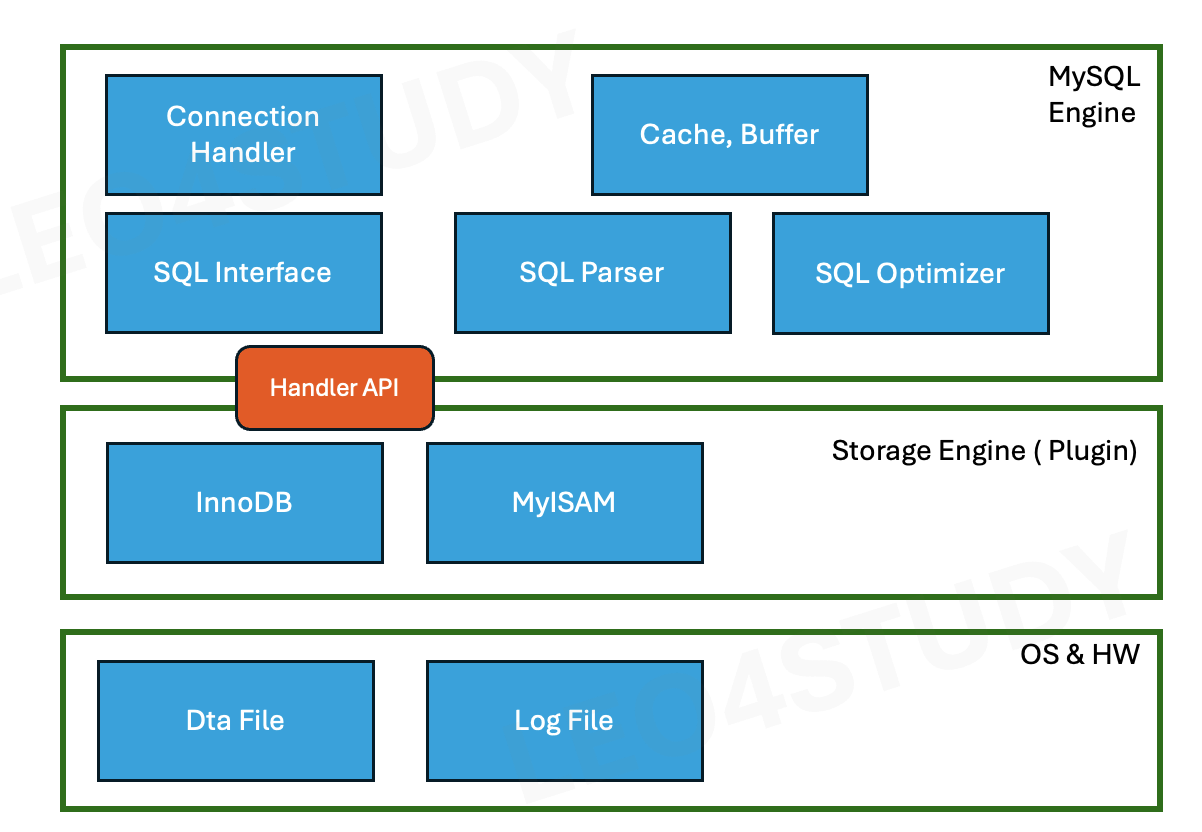
MySQL 서버의 내부 구조
2.1.2 MySQL Engine
MySQL Engine은 클라언트로부터의 요청을 받고, SQL을 분석하고 최적화하는 역할을 수행한다.
Connection Handler
- 클라이언트로부터의 접속, 쿼리요청 처리
SQL interface
- SQL을 받아준다.
SQL Parser
- SQL을 파싱하고, 전처리를 한다.
SQL Optimizer
- 쿼리 최적화와 실행계획을 짠다.
2.1.3 Storage Engine
MySQL Storage Engine은 실제 데이터를 디스크에 저장하거나, 디스크로부터 데이터를 읽는 처리를 담당한다.
Storage Engine 은 Plugin 방식으로 원하는 구현체를 선택할 수 있다. 즉, 하나의 DB 서버에서 논리적으로 Storage Engine을 선택할 수 있다. 선택은 database , table 마다 할 수 있다. create database, table 선언시에 ENGINE=$ENGINE_NAME 으로 설정한다.
SHOW ENGINES; 커맨드로 확인할 수 있다.
MySQL 은 storage engine 뿐만 아니라 다양한 기능들도 플러그인 형태로 지원한다. 인증 관련 기능, 검색용 파서, 쿼리 rewrite 플러그인 등이 있다. 기본적으로 MySQL의 표준 API 가 열려있기 때문에 가능하다.
2.1.4 Handler API
MySQL엔진의 Query Executor 가 실제 데이터를 읽거나 쓸때, Storage Engine에 요청할 때 표준인터페이스인 handler API를 통해 한다. 즉, 각 storage engine 은 구현할 때 handler API 명세를 따라 구현되어 있다. 이 표준인터페이스 때문에 플러그인 방식으로 원하는 것을 선택할 수 있다.
2.2 MySQL 스레드 구조
2.2.1 Overview
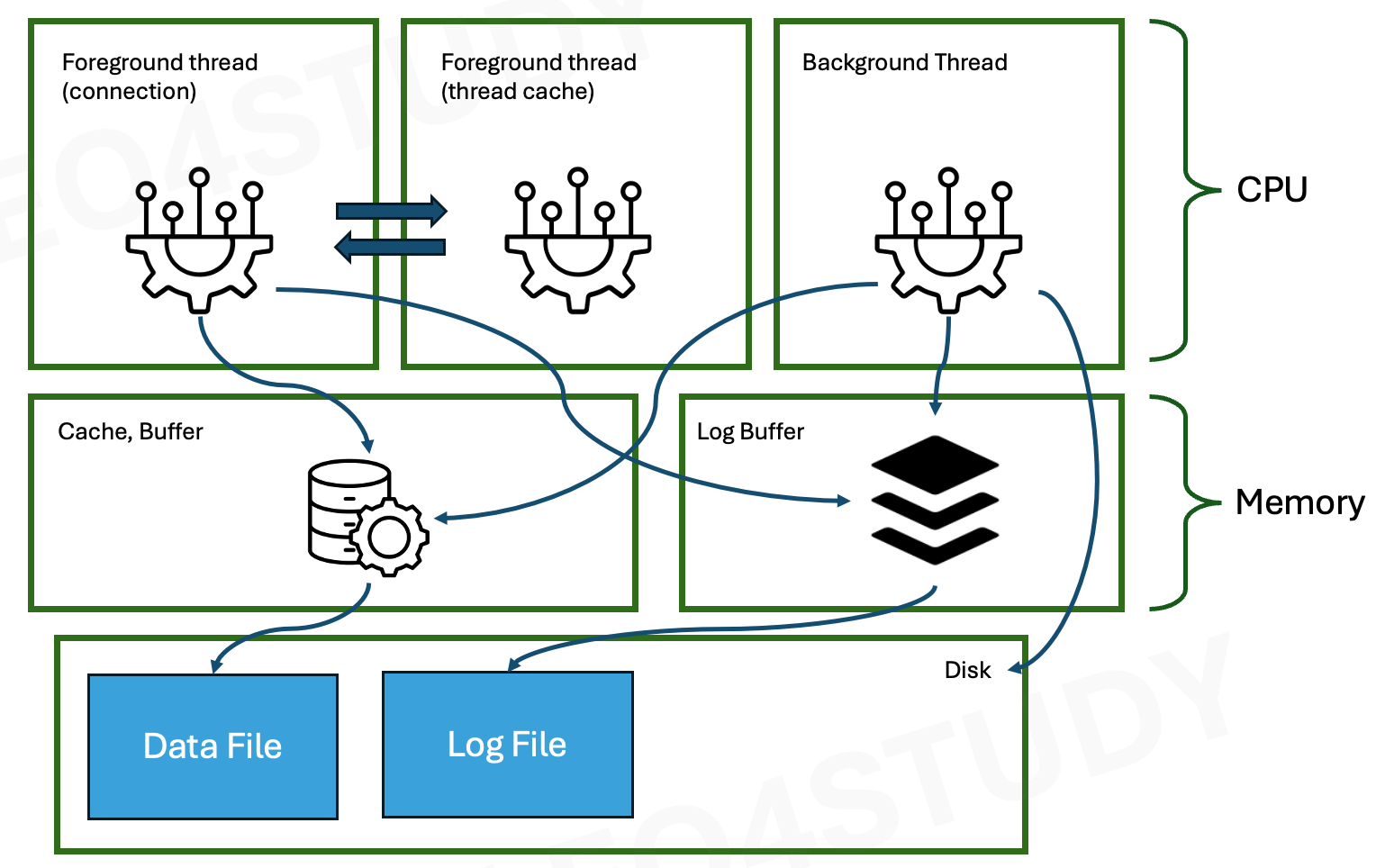
MySQL 은 멀티 프로세스가 아니라 멀티 스레드 기반으로 동작한다. 동작 방식에 따라 Foreground, Backgound 스레드로 구분한다. 실행중인 스레드는 performance_schema 데이터베이스 > threads 테이블에 기록된다.
2.2.2 Foreground Thread(Client connection)
foreground thread 는 최소한 현재 연결된 클라이언트의 수만큼 존재한다. 클라이언트의 커넥션이 종료되면, 다시 스레드 캐시로 돌아간다. 스레드 캐시에 일정 개수 이상의 스레드가 대기중이라면, 스레드 캐시에 돌아가지 않고, 스레드를 종료한다. 최대 대기 스레드수는 thread_cache_size 로 설정한다.
foreground thread 는 데이터를 데이터 버퍼나 캐시로부터 가져오고, 버퍼나 캐시에 없다면 디스크에서 읽어서 가져온다. InnoDB는 foreground thread 는 cache, buffer 까지만 접근하고 디스크에는 접근하지 않는다.
2.2.3 Background Thread
InnoDB 기준으로 background thread 는 다음 일을 한다.
- insert buffer 를 merge
- Log 를 disk에 기록
- InnoDB buffer pool의 데이터를 disk에 기록
- 디스크에 있는 데이터를 버퍼로 read
- Lock monitoring thread
원하는 읽기 쓰기 성능이 안나오거나, 주 사용용도를 예측해서 스레드 수를 조정할 수 있다.
innodb_write_io_threadsinnodb_read_io_threads
innodb 의 경우 읽기는 대부분 포그라운드 스레드에서 처리되기 때문에 innodb의 read 스레드를 늘릴일은 많지 않다. 쓰기 작업이 많거나, 지연되는 경우에
innodb_write_io_threads를 2 이상으로 세팅한다.
innodb는 지연된 쓰기 작업을 지원한다. 쓰기 작업을 버퍼에 넣고 아직 디스크에 쓰이기 전에 클라이언트에 응답할 수 있다. 버퍼에 쌓인것은 내부적으로 배치처리로 적용한다.
그렇다면 지연된 쓰기 작업이 durability(지속성)를 위협하지는 않을까 하는 의문이 들 수 있다.
예를 들어, 클라이언트에 응답한 이후 실제로 디스크에 쓰기 전에 서버가 갑자기 종료된다면, 데이터가 유실될 수 있어 보인다.
하지만 InnoDB는 이러한 상황을 대비해 redo log와 undo log를 사용한다.
- redo log는 커밋된 트랜잭션의 변경 사항을 기록해두고, 서버가 비정상적으로 종료되더라도 이를 기반으로 복구할 수 있다.
- undo log는 롤백이나 MVCC를 위한 이전 상태를 저장한다.
이러한 로그 메커니즘 덕분에 InnoDB는 ACID의 durability 특성을 유지하면서도, 쓰기 작업을 비동기적으로 처리해 클라이언트 응답 시간을 단축할 수 있다.
즉, 지연된 쓰기 작업은 성능을 최적화하면서도 RDBMS의 핵심 기능을 유지하는 안전한 방식이다.
2.3 메모리 구조
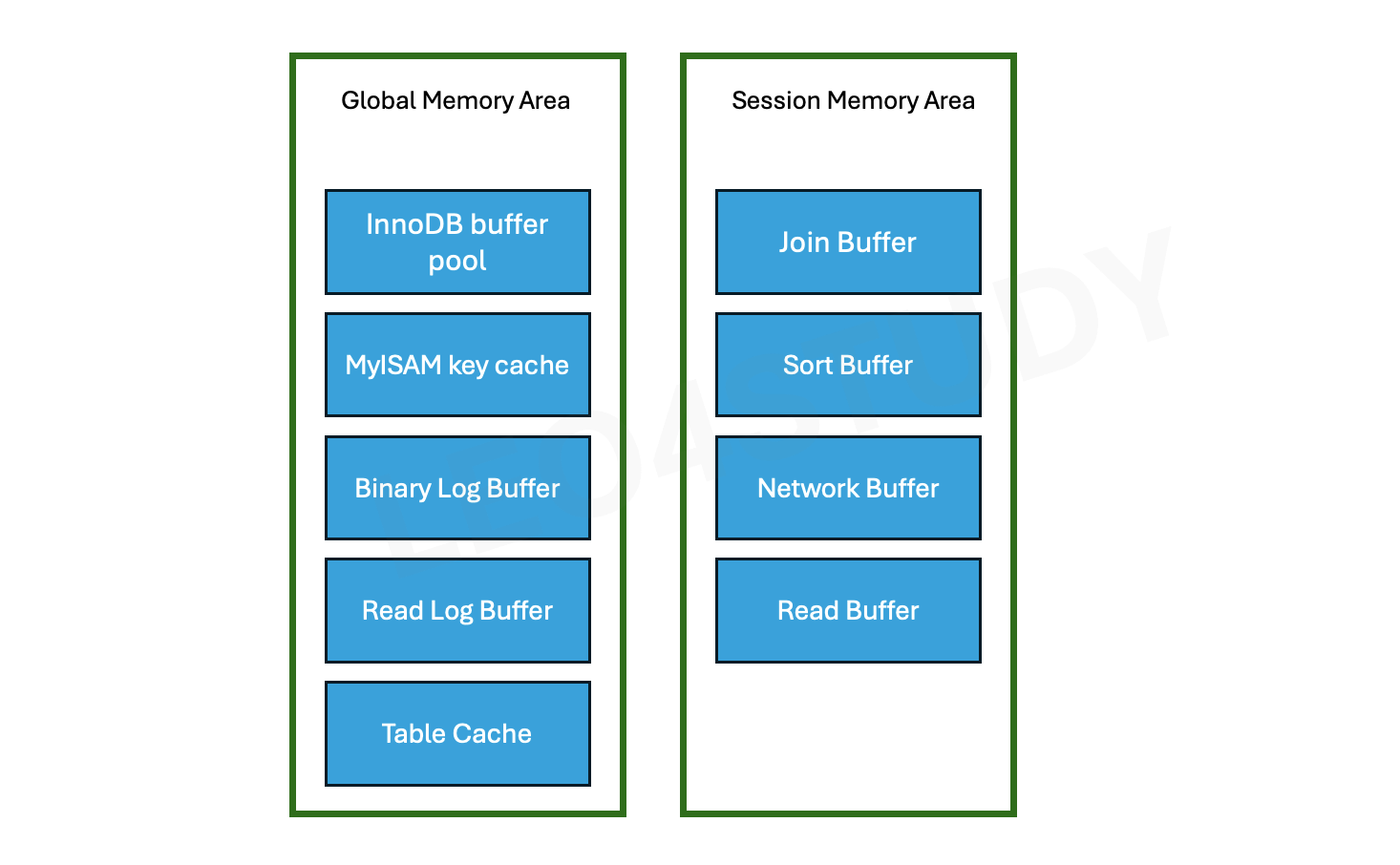
2.3.1 글로벌 메모리 영역
MySQL 서버 단체에 있는 메모리 영역
MySQL이 시작되면서 운영체제로 부터 할당 된다. 클라이언트 스레드 수와 상관없이 하나(또는 N개)의 공간이다. 모든 스레드가 공유하는 자원이다.
- 다음과 같은 내용들이 있다.
- InnoDB buffer pool
- InnoDB adaptive hash index
- InnoDB redo log buffer
- table cache
2.3.2 세션(로컬) 메모리 영역
내가 물고 있는 커넥션 안에서만 있는 메모리 영역.
클라이언트 스레드가 쿼리를 처리하는데 사용하는 메모리 영역. 각 클라이언트 스레드별로 독립적으로 할당 되고 공유되지 않는다. 각 쿼리별로 필요한 용량을 할당한다. 할당하지 않는 경우도 있다.
- Sort buffer
- Sort 쿼리가 있을 때만 할당되고 해제된다. 아예 할당이 안될수도 있다.
- Join buffer
- Join 쿼리가 있을 때만 할당되고 해제된다. 아예 할당이 안될수도 있다.
- Binary Log Cache
- Network buffer
- Connection buffer는 항상 할당되어있다.
- 캐시, 버퍼에서 쿼리 내용을 가져올 때 중간에 메모리 영역이 필요하기 때문에.
2.4 Query 실행 구조
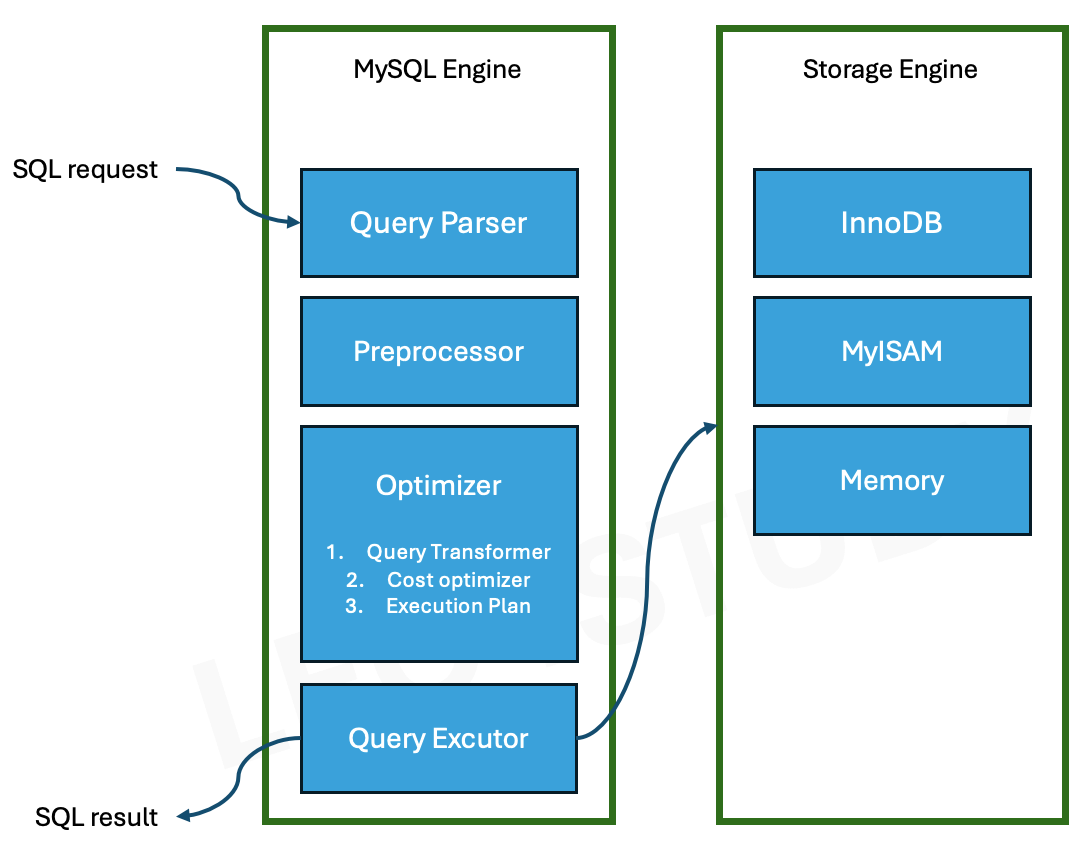
MySQL 엔진도 SQL 요청이 들어오면, 우선 클라이언트 스레드가 생성되어 요청을 처리한다.
그 후 쿼리는 파서(Query Parser)를 거쳐 구문 분석을 진행하고,
프리프로세서(Preprocessor) 단계에서 객체 이름 확인과 권한 검사를 수행한다.
이후 옵티마이저(Optimizer)가 쿼리 실행 계획을 수립하고,
이 실행 계획은 쿼리 실행기(Query Executor)로 전달된다.
쿼리 실행기는 사용 중인 스토리지 엔진(Storage Engine)에 요청을 전달하고,
스토리지 엔진은 실제로 디스크나 메모리에서 데이터를 읽거나 쓰는 작업을 수행한다.
2.4.1 Query Parser
쿼리를 토큰(인식할 수 있는 최소단위의 단어, 기호) 단위로 분리해 Tree 자료구조를 만든다. 문법 오류를 이 단계에서 검출한다.
2.4.2 Preprocessor
Parser Tree 를 기반으로 쿼리문 안에 의미적인 오류가 있는지 확인한다. 테이블 이름, 칼럼 이름, 내장함수와의 매핑 등을 확인한다.
SQL 수행할 권한이 있는지 확인한다.
2.4.3 Optimizer
쿼리를 가장 적은 비용(cost)으로 처리할 수 있도록 의사결정을 한다.
고려요소(파라미터)
- 테이블, 또는 인덱스 당 page 수
- 인덱스의 카디널리티
- Row 길이
- key 길이
- key 분포
2.4.4 Execution Engine
실행엔진은 Optimizer에게 받은 계획에 따라 핸들러에게 구체적으로 할 일(read, write)을 알려준다.
예: group by 를 처리하기 위해 임시테이블을 만든다.
- Execution Engine이 핸들러에게 임시 테이블을 만들라고 요청
- Execution Engine은 where에 일치하는 레코드를 읽어오라고 함.
- 읽어온 레코드를 1번에서 준비한 임시테이블에 저장하라고 핸들러에 요청
- 데이터가 준비된 임시 테이블에서 데이터를 읽으라는 요청을 핸들러에게 요청
- Execution Engine은 최종 결과를 사용자나 다른 모듈로 넘긴다.
2.4.5 Handler (Storage Engine)
Execution Engine의 요청에 따라 데이터를 디스크로 저장, 또는 데이터를 디스크에서 읽어오는 역할을 한다.
2.5 Query Cache
SQL의 실행 결과를 메모리에 저장하고, 동일한 SQL이 실행되면 디스크에서 읽지 않고 즉시 결과를 준다. 다만, 테이블의 데이터가 변경되면 해당 테이블과 관련된 캐시를 모두 삭제 해야했는데, 이것 때문에 오히려 성능저하가 오는 경우가 많았다. 이 때문에 MySQL 8.0 에서 Query Cache는 삭제되었다.
2.6 Thread Pool
MySQL Enterprise 버전에서만 Thread Pool을 지원한다. MySQL Community 버전을 이용하는 경우에는 Percona Server for MySQL을 이용하면 플러그인 형태로 thread_pool.so 를 설치해서 사용할 수 있다.
Percona Server 의 스레드 풀은 기본으로 장치의 CPU 코어 수 만큼 스레드 그룹을 생성한다. thread_pool_size로 조정할 수 있다. 다만, CPU 코어 수와 스레드 수를 맞추는 것이 Context Switch 가 덜 일어나므로 processor affinity 에 좋다. 이미 스레드풀이 모두 일하고 있다면 thread_pool_oversubscribe 의 수만큼 추가로 스케줄링 할 수는 있다.
스레드 그룹의 모든 스레드가 할당되어 일하고 있다면, 스레드 풀은 스레드 그룹에 새로운 스레드를 추가할지, 아니면 기존 스레드가 작업을 완료할 때까지 기다릴지를 판단한다. 스레드풀의 타이머 스레드가 주기적으로 스레드 그룹의 상태를 체크해서 thread_pool_stall_limit 시스템 변수에 정의된 (milliseconds) 기간동안 작업을 못 끝낸다면, 새로운 worker thread를 추가한다.
client의 동시요청이 많고, 응답시간이 중요한 서비스라면?
Percona Server의 스레드풀 플러그인은 선순위 큐와 후순위 큐를 이용해 특정 트랜잭션이나 쿼리를 우선 처리할 수 있는 옵션을 제공한다. 우선순위 큐에 속한 트랜잭션을 빨리 처리하면, 해당 transaction에 의한 lock이 빨리 해제되고, race condition을 낮추어서 전체적인 처리 성능을 높이자는 아이디어이다.
