07. SELECT와 함수
7.1. SELECT
SELECT
SELECT문은 다양한 옵션이 함께 적용되어 사용되기 때문에 많은 활용이 있는데, 여기서는 먼저 SELECT의 기본 형태에 대해서 알아보겠습니다.
*SQL 종류 (DDL, DML, DCL, TCL) 외에 DQL(DataQueryLanguage)로 분류하기도 해요.
SELECT문 살펴보기
SELECT 컬럼
FROM 테이블
WHERE 조건식
GROUP BY 그룹 컬럼
HAVING 그룹 조건
ORDER BY 정렬FROM → WHERE → GROUP BY → HAVING → SELECT → ORDER BY 순으로 실행
ALIAS
만약 칼럼의 명이 너무 길거나 더 구분하기 쉬운 다른 명칭으로 조회하고 싶을 때는 ALIAS를 활용할 수 있습니다. alias는 별명이라는 뜻으로 특정 칼럼이나 테이블의 이름을 바꿔서 조회할 수 있습니다. 주로 쿼리 결과의 가독성을 높이거나 복잡한 테이블명이나 컬럼명을 간략하게 표현할 때 사용됩니다
| 유형 | 부여 방식 | 설명 |
|---|---|---|
| 칼럼 | 칼럼명 AS ALIAS(앨리어스)명 | 칼럼명과 앨리어스명 사이에 AS을 써도 되고 안 써도 됨 |
| 테이블 | 테이블명 ALIAS(앨리어스)명 | 테이블과 앨리어스명 사이에 AS 사용할 수 없음 |
DISTINCT
DISTINCT는 쿼리 결과에서 중복된 값을 제거하여 고유한 값만을 반환하도록 하는 역할을 합니다. 이를 통해 특정 컬럼 또는 컬럼들의 조합에 대한 중복을 제거하여 결과를 보다 정제된 형태로 가져올 수 있습니다.
산술/합성 연산자
산술 연산자
연산자는 필드 값을 비교하거나 산술연산을 수행할 때 사용하는 키워드입니다. 다양한 연산자를 조합하여 다양하고 복잡한 쿼리를 만들 수 있지만 이번 시간에서 설명하는 연산자는 그 중 일부만 학습합니다.
+: 더하기 연산-: 빼기 연산*: 곱하기 연산/: 나누기 연산%: 나머지 연산- 연산자 우선순위
가장 높음( )→*→/→+→-가장 낮음
참고 - DUAL 테이블
실습에서 활용하는 DUAL 테이블은 데이터를 출력하기 위해 Oracle에서 제공하는 기본 테이블이며, 테이블을 생성하기 위한 특별한 작업이 필요 없습니다.
함수를 실행할 때 임시로 사용하는데 적합하며, 함수에 대한 쓰임을 알고 싶을때 값을 리턴(return)받을 수 있습니다.
SQL Server는 DUAL 테이블이 없으며 현재 데이터만 출력하기 위해서는 FROM 테이블을 생략하면 됩니다.
합성 연산자
합성 연산자는 서로 다른 두 문자를 하나의 문자열로 합칠 때 사용합니다. 이때 DBMS별로 서로 다른 기호를 사용합니다. Oracle의 경우는 || 를 이용하고 SQL Server의 경우는 + 기호를 이용하여 서로 다른 두 문자를 합치게 됩니다.
이렇게 문자와 문자를 합치는 경우는 기존 정의된 칼럼이 아닌 결과에만 임시로 새로운 칼럼을 만들어서 합쳐진 문자열을 나타냅니다.
customers 테이블에서 이름과 아이디를 제외한 나머지 모든 주소를 하나로 합쳐서 출력하기
-- 고객별 주소 테이블 생성
CREATE TABLE customers (
customer_id NUMBER PRIMARY KEY,
first_name VARCHAR2(50) NOT NULL,
last_name VARCHAR2(50) NOT NULL,
address VARCHAR2(255),
city VARCHAR2(100),
state VARCHAR2(100),
postal_code VARCHAR2(20)
);
-- 테이블 내 데이터 추가
INSERT INTO customers (customer_id, first_name, last_name, address, city, state, postal_code) VALUES
(1, 'John', 'Doe', '123 Elm St', 'Springfield', 'IL', '62701');
INSERT INTO customers (customer_id, first_name, last_name, address, city, state, postal_code) VALUES
(2, 'Jane', 'Smith', '456 Oak St', 'Springfield', 'IL', '62702');
INSERT INTO customers (customer_id, first_name, last_name, address, city, state, postal_code) VALUES
(3, 'Alice', 'Johnson', '789 Pine St', 'Decatur', 'IL', '62521');
INSERT INTO customers (customer_id, first_name, last_name, address, city, state, postal_code) VALUES
(4, 'Bob', 'Brown', '101 Maple St', 'Peoria', 'IL', '61602');
INSERT INTO customers (customer_id, first_name, last_name, address, city, state, postal_code) VALUES
(5, 'Carol', 'White', '202 Birch St', 'Champaign', 'IL', '61820');SELECT
customer_id,
first_name,
last_name,
address || city || state || postal_code AS full_address
FROM
customers;연습문제
1번
| Q. 문제 | 아래의 employees 테이블에서 모든 직원의 이름과 입사한 해를 조회하는 SQL 문을 작성하세요.employees 테이블 구조: - employee_id (사원 번호) - first_name (이름) - last_name (성) - hire_year (입사 연도) |
|---|---|
| A. (1) | SELECT first_name, last_name FROM employees; |
| A. (2) | SELECT first_name, last_name, hire_year FROM employees; |
| A. (3) | SELECT employee_id, first_name, last_name FROM employees; |
| A. (4) | SELECT first_name, last_name, start_year FROM employees; |
정답
SELECT first_name, last_name, hire_year FROM employees;
2번
| Q. 문제 | 테이블 "Students"에서 모든 학생들의 이름과 수학 성적을 조회하려고 합니다. 수학 성적을 10점씩 더한 값으로 나타내려고 합니다. 올바른 SQL문을 고르세요. |
|---|---|
| A. (1) | SELECT name, math_score + 10 |
| FROM Students; | |
| A. (2) | SELECT name, math_score AS 'Math Score + 10' |
| FROM Students; | |
| A. (3) | SELECT name, math_score * 10 |
| FROM Students; | |
| A. (4) | SELECT name, math_score + 5 |
| FROM Students; |
정답
(1)
7.2. 함수 - 단일행 함수
내장 함수 개요
데이터베이스 조작 과정에서 다양한 연산을 지원하기 위해 각 DBMS 회사 별로 제공하는 내장함수가 있습니다. 사용하는 형태가 조금씩 다르지만 핵심적인 기능은 동일합니다.
내장함수는 크게 하나의 값이 입력되어 수행되는 단일행 함수와 여러 행의 값이 입력되는 다중행 함수로 분류를 할 수 있습니다. 이러한 함수는 데이터를 변환하거나 계산하기 위해 사용되며, SELECT 문의 SELECT 절이나 WHERE 절, HAVING 절 등에서 사용될 수 있습니다.

단일행 함수의 특징
- 단일행 내에 있는 하나의 값 또는 여러 값이 입력 인수로 표현될 수 있습니다.
- 함수의 리턴 값은 항상 1개(단일 값)
- SELECT, WHERE, ORDER BY 절에 사용 가능합니다.
- 함수의 인자로 상수, 변수, 표현식이 사용 가능합니다.
- 하나의 인수를 가지는 경우도 있지만 여러 개의 인수를 가질 수도 있습니다.
- 특별한 경우가 아니면 함수의 인자로 함수를 사용하는 함수의 중첩이 가능합니다
단일행 함수의 종류 (타입에 따른 분류)
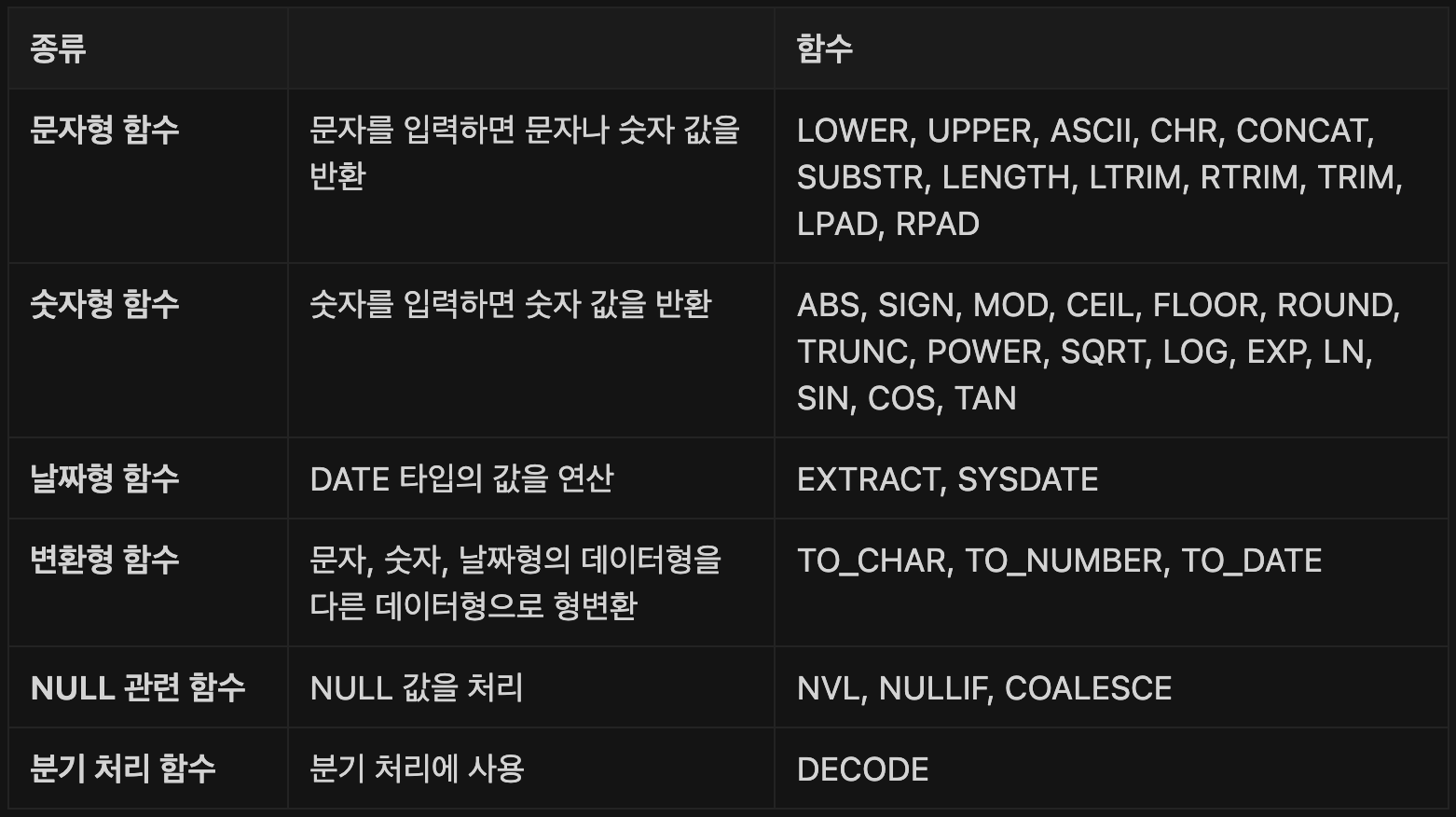
문자형 함수
문자형 함수는 텍스트를 수정하고 형식을 지정할 수 있습니다. 문자형 함수의 종류는 다음과 같습니다.
LOWER(문자열) / UPPER(문자열) / CONCAT(문자열1, 문자열2)
- LOWER : 모든 문자를 소문자로 변경하여 리턴
- UPPER : 모든 문자를 대문자로 변경하여 리턴
- CONCAT : 문자열과 문자열을 연결하여 리턴
Oracle과 MySQL에서 사용할 수 있는 함수이며, 합성 연산자||(Oracle) 과+(SQL Server) 와 동일한 결과를 출력합니다. SQL Server에서는 지원하지 않는 함수이기 때문에 SQL Server를 사용할 때는 합성 연산자+를 사용해야 합니다.
ASCII(문자)
문자나 숫자를 ASCII 코드 번호로 바꿔줍니다.
Oracle: CHR / SQL Server: CHAR(ASCII 번호)
ASCII 코드 번호를 문자나 숫자로 바꿔줍니다.
예시
-- Oracle
SELECT CHR(65) FROM DUAL;
--> 'A'실습
아래의 문장에서 숫자를 온전히 문자로 나타내 보세요.
문장 : 여러분 70, 105, 71, 104, 84, 105, 78, 103 !SELECT CHR(70) || CHR(105) || CHR(71) || CHR(104) || CHR(84) || CHR(105) || CHR(78) || CHR(103) || '!' FROM DUAL; -- FiGhTiNg !
Oracle : SUBSTR // SQL Server : SUBSTRING (문자열, m[, n])
문자열 중 m위치에서 n개의 문자 길이에 해당하는 문자를 전달해줍니다. n은 생략이 가능하며 생략한 경우 '마지막 문자'까지를 의미합니다.
-- Oracle SELECT SUBSTR('SQL Expert', 5, 3) FROM DUAL; --> 'Exp'
실습
SELECT SUBSTR('SQL is a standard language for accessing and manipulating databases.', 19, 8) FROM DUAL; -- language -- 만약 8을 생략하는 경우는 마지막까지 모두 출력 SELECT SUBSTR('SQL is a standard language for accessing and manipulating databases.', 19) FROM DUAL; -- language for accessing and manipulating databases.
LTRIM(문자열[, 지정문자])
문자열의 첫 번째 문자부터 확인해서 지정문자가 나타나면 해당 문자를 문자열에서 제거합니다. 여기서 지정문자의 기본 값은 공백값입니다. 지정 문자 생략 시 공백이 제거됩니다. SQL Server 에서는 LTRIM 함수의 지정문자를 정할 수 없고 오직 공백 제거만 가능합니다.
-- Oracle
SELECT LTRIM('xxxYYZZxYZ', 'x') FROM DUAL;
--> 'YYZZxYZ'TRIM([leading|trailing|both] 지정문자 FROM 문자열)
문자열에서 머리말, 꼬리말, 또는 양쪽에 있는 지정 문자를 제거합니다. Oracle은 LTRIM 처럼 머리말만 잘라낼 때는 leading 옵션을 주고, RTRIM처럼 꼬리말만 잘라내고 싶을 때는 trailing 옵션을 설정하면 됩니다. 기본 설정값은 both 이기 때문에 양쪽 다 잘라내게 됩니다. SQL Server 는 지정문자를 정할 수 있지만 leading, trailing 옵션은 사용할 수 없습니다.
-- Oracle -- 양쪽 제거 SELECT TRIM('x' FROM 'xxYYZZxYZxx') FROM DUAL; --> 'YYZZxYZ' -- 왼쪽 제거 (LTRIM) SELECT TRIM(leading'x' FROM 'xxYYZZxYZxx') FROM DUAL; --> YYZZxYZxx -- 오른쪽 제거 (RTRIM) SELECT TRIM(trailing 'x' FROM 'xxYYZZxYZxx') FROM DUAL; --> xxYYZZxYZ
LPAD(문자열1,n[,문자열2]) / RPAD(문자열1,n[,문자열2])
- LPAD : 문자열1을 n자리만큼 늘리고, 왼쪽 빈 공간을 문자열2로 채워서 리턴
(문자열2가 생략되면 기본값은 공백)
- RPAD : 문자열1을 n자리만큼 늘리고, 오른쪽 빈 공간을 문자열2로 채워서 리턴
(문자열2가 생략되면 기본 값은 공백)
-- Oracle
SELECT LPAD('ABC',8,'Z') FROM dual;
-- ZZZZZABC
SELECT RPAD('ABC',8) FROM dual;
-- ABC(공백 5칸)숫자형 함수
숫자형 함수는 숫자 데이터를 입력받아 처리하고 숫자를 돌려주는 함수입니다. 숫자형 함수의 종류는 다음과 같습니다.
ABS(숫자)
숫자의 절댓값을 돌려주는 함수입니다.
SIGN(숫자)
숫자의 부호를 판단하는 함수입니다. 숫자가 양수이면 1을 리턴하고, 0이면 0을 리턴, 음수면 -1을 리턴합니다. 숫자가 양수인지, 음수인지, 0인지를 구별하는 함수입니다.
MOD(숫자1, 숫자2)
숫자1을 숫자2로 나누어 나머지 값을 계산하는 함수입니다. MOD 함수는 % 연산자로도 대체 가능합니다.
Oracle : CEIL(숫자) / SQL Server : CEILING(숫자)
숫자보다 크거나 같은 최소 정수를 리턴합니다. 소수를 정수로 올림 연산할 때 사용합니다.
예시
-- Oracle SELECT CEIL(38.567) FROM DUAL; --> 39 SELECT CEIL(-38.567) FROM DUAL; --> -38
FLOOR(숫자)
숫자보다 작거나 같은 최대 정수를 리턴합니다. 소수를 정수로 내림 연산할 때 사용합니다.
-- Oracle
SELECT FLOOR(38.567) FROM DUAL;
--> 38
SELECT FLOOR(-38.567) FROM DUAL;
--> -39TRUNC(숫자 [, m])
숫자를 소수 m자리에서 잘라서 버린 값을 리턴합니다. m이 생략되면 default 값은 0입니다. SQL Server는 TRUNC 함수가 제공되지 않습니다.
-- Oracle
SELECT TRUNC(38.567, 2) FROM DUAL;
--> 38.56
SELECT TRUNC(38.567) FROM DUAL;
--> 38SIN, COS, TAN(숫자)
숫자의 삼각함수 연산을 하여 결과를 리턴합니다. 숫자는 라디안을 의미합니다.
-- Oracle
SELECT SIN(1.5708) FROM DUAL;
--> 0.99999EXP, POWER, SQRT, LOG, LN
숫자의 지수, 거듭 제곱, 제곱근, 로그, 자연 로그의 값을 리턴합니다.
- EXP(n) : e의 n제곱을 반환합니다.
- POWER(m, n) : m의 n제곱을 반환합니다.
- SQRT(n) : n의 제곱근을 반환합니다. n은 음수가 될 수 없습니다.
- LOG(m, n) : 밑을 m으로 한 n의 로그 값을 반환합니다. m은 0 또는 1이외의 정수이며 n은 양수 값으로 설정해야 합니다.
- LN(n) : n의 자연 로그 값을 반환합니다.
-- Oracle
SELECT EXP(2) FROM DUAL;
--> 7.389056
SELECT POWER(2, 3) FROM DUAL;
--> 8
SELECT SQRT(4) FROM DUAL;
--> 2
SELECT LOG(10,100) FROM DUAL;
--> 2
SELECT LN(10) FROM DUAL;
--> 2.302585날짜형 함수
데이터베이스는 날짜를 저장할 때 내부적으로 세기(Century), 년(Year), 월(Month), 일(Day), 시(Hour), 분(Minutes), 초(Seconds)와 같은 숫자 형식으로 변환하여 저장합니다. 데이터베이스는 날짜를 숫자로 저장하기에 덧셈, 뺄셈 같은 산술 연산자로도 날짜의 계산이 가능합니다.
- 날짜 + 숫자 = 날짜
- 숫자만큼의 날수를 날짜에 더하는 연산입니다.
- 날짜 - 숫자 = 날짜
- 숫자만큼의 날수를 날짜에서 빼는 연산입니다.
- 날짜1 - 날짜2 = 날짜수
- 다른 하나의 날짜에서 하나의 날짜를 빼서 나오는 일수를 구할 수 있습니다.
- 날짜 + 숫자/24 = 날짜
- 시간을 날짜에 더할 수 있습니다.
시간 형식 참고하기 👀
YYYY : 년 / MM : 월 / DD : 일 / HH24 : 24시간 / HH12 : 12시간 / MI : 분 / SS : 초
오라클 시간 표현
- 1/24 : 1시간 (1일을 24시간으로 나누기)
- 1/24/6 : 10분
- 1/24/60 : 1분 (1일 / 24시간 = 1시간 / 60 = 1분)
- 1/24/60/60 : 1초 (1일 / 24시간 = 1시간 / 60 = 1분 / 60 = 1초)
Oracle : SYSDATE / SQL Server : GETDATE()
현재 날짜와 시간을 출력합니다.
Oracle : EXTRACT(시간날짜단위 FROM 시간날짜) / SQL Server : DATEPART(시간날짜단위, 시간날짜)
날짜 데이터에서 년/월/일 데이터를 출력합니다. 시간/분/초도 가능합니다.
-- Oracle
SELECT EXTRACT(YEAR FROM DATE '2023-10-10') FROM DUAL;
--> 2023Oracle : TONUMBER(TO_CHAR(날짜정보, 데이트포멧)) / SQL Server : YEAR(날짜정보), MONTH(날짜정보), DAY(날짜정보)
-- Oracle
SELECT TO_CHAR(hire_date,'YYYY') FROM empl;
--> 1987, 1992, 2000변환형 함수
변환형 함수는 특정 데이터 타입을 다른 형태로 출력하고 싶을 때 사용되는 함수입니다. 크게 명시적인 변환 방식과 암시적인 변환 방식으로 나눌 수 있습니다.
명시적 데이터 유형 변환
데이터 변환형 함수로 데이터 유형을 변환하도록 쿼리에 명시를 해주는 경우입니다. 어떤 데이터로 변환되는지 작성이 되어있기 때문에 코드의 가독성이 좋습니다.
참고_벤더별 단일행 함수의 종류
Oracle
TO_NUMBER(문자열)
alphanumeric 문자열을 숫자로 변환TO_CHAR(숫자|날짜 [, FORMAT])
숫자나 날짜를 주어진 FORMAT 형태의 문자열 형식으로 변환TO_DATE(문자열 [, FORMAT])
문자열을 주어진 FORMAT 형태로 날짜 형식으로 변환
-- Oracle
SELECT TO_CHAR(SYSDATE, 'YYYY. MON, DAY') FROM DUAL;
SELECT TO_NUMBER('888') + TO_NUMBER('111') FROM dual;
--> 999암시적 데이터 유형 변환
암시적인 데이터 유형 변환은 '2' + 1 연산을 하려고 할 때 데이터베이스는 서로 다른 두 타입을 계산하기 쉽게 자동으로 데이터 유형을 변환하여 계산을 하는 경우를 말합니다. 사용자는 모르지만 데이터가 스스로 타입을 변경하기 때문에 편하지만 성능 저하가 발생할 수 있습니다. 또한, 자동적으로 데이터베이스가 알아서 계산하지 않는 경우와 같은 문제가 발생할 수 있습니다.
-- Oracle SELECT '2' + 1 FROM DUAL; --> 3
NULL 관련 함수
NULL의 특징
NULL은 정의되지 않은 값을 의미합니다. 숫자 0이나 빈 공백 '' 과는 다른 값입니다. 어떠한 값과 NULL과의 연산(+,-,*,/ 등)은 항상 NULL 값이 나옵니다. 따라서 NULL과 관련된 연산이나 값의 확인은 일반 연산자가 아닌 다음에 나올 함수들을 사용해야 합니다.
Oracle : NVL / SQL Server : ISNULL 함수
결괏값을 NULL이 아닌 다른 값을 얻고자 할 때 Oracle은 NVL, SQL Server는 ISNULL 함수를 사용합니다. NULL 관련 함수 중 가장 많이 사용되므로 반드시 사용방법에 대해 알아두어야 합니다.
-- Oracle NVL(NULL_판단_대상, NULL일_때_대체값) -- 값이 NULL인 경우 두 번째 지정값을 출력하고, 그렇지 않으면 대상 데이터를 출력합니다. -- SQL Server ISNULL(NULL_판단_대상, NULL일_때_대체값)
NULL과 공집합
테이블에서 조건에 맞는 데이터가 한 건도 없는 경우를 공집합이라고 부릅니다. 이때 공집합은 NULL과 다릅니다. 일치되는 데이터가 없는 것이 공집합, 값 자체가 정의되지 않은 것이 NULL 입니다.
공집합의 경우 NVL 함수를 사용해도 공집합이 출력되므로, 그룹함수와 NVL 함수를 같이 사용해서 공집합을 처리해야 합니다.
예시
-- NVL 만 사용했을 때 SELECT NVL(MGR, 9999) FROM EMP WHERE ENAME='JSC'; --> 9999가 나올것 같지만 결과는 데이터를 찾을 수 없음실제로 많이 실수 하는 부분
-- 집계 함수와 같이 사용했을 때 SELECT NVL(SUM(MGR), 9999) MGR FROM EMP WHERE ENAME='JSC'; -- MAX(MGR)의 값은 선택된 값이 없기에 NULL이 출력되고 -- 이를 NVL 함수에서 9999로 변환
NULLIF
NULLIF 함수는 특정 값을 NULL로 대체하는 경우에 유용하게 사용할 수 있습니다. NULLIF 함수는 두 조건 EXPR1과 EXPR2를 비교하고 같다면 NULL을 리턴하고, 같지 않으면 첫 번째 EXPR1을 리턴합니다.
기타 NULL 관련 함수 (COALESCE)
COALESCE 함수는 여러 값 중에서 NULL이 아닌 첫 번째 값을 찾을 때 사용합니다. 만약에 모든 값들이 NULL이라면 NULL을 리턴합니다.
COALESCE → ‘합치다’ 라는 의미 ! 이게 왜 합치는걸까?
테이블에 각각 email , uesr_mail 이라는 칼럼이 존재한다고 해보자. 칼럼명은 다르지만 사실 같은 것을 의미한다고 하자 (물론 이렇게 구성하면 안되지만, 실제 서비스에서는 상상하지 못한 일이 일어나곤 한다) 특정 로직은 email 에 저장하고 다른 로직은 user_mail 에 저장하는 식이다. 자, 이럴때 내가 이메일을 조회한다면 email 한 번 보고, user_mail 한 번 보는 두 번의 작업을 해야 한다. 이럴 때 COALESCE 를 사용하면 email 에 값이 있으면 해당 값을 리턴하고, 해당 칼럼의 값이 NULL 이면 user_mail 값을 리턴하니 마치 두개의 칼럼을 합쳐서 다루는 듯 하기때문에 이런 이름이 붙은 것
기본 구조
COALESCE(EXPR1, EXPR2, EXPR3, ...)
-- emp 테이블에서 ename, comm, sal과 comm, sal 중에서 null이 아닌 값을 조회 SELECT ename, comm, sal, COALESCE(comm, sal) coal FROM emp;
CASE 표현
CASE 문은 조건부로 값을 반환하거나 연산을 수행하는 데 사용되는 구문입니다. 주로 SELECT 문에서 사용되며, 특정 조건에 따라 다른 결과를 반환하거나 처리할 때 유용합니다.
CASE 표현은 IF-THEN-ELSE 의 조건문 논리와 유사한 방식으로 동작합니다. 이를 이용하여 SQL의 비교 연산 기능을 보완할 수 있습니다. Oracle 에서는 Decode 라는 함수를 이용하여 해당 부분을 표현합니다.
SIMPLE_CASE_EXPRESSION
-- EXPR 이 COMPARISON_EXPR과 같으면 RETIRN_EXPR을 돌려주고
-- 아니면 표현절을 리턴합니다.
CASE EXPR WHEN COMPARISON_EXPR THEN RETURN_EXPR ELSE 표현절 ENDCASE SEARCHED_CASE_EXPRESSION
CASE 다음에 WHEN 절에서 EQUAL(=) 조건 포함 여러 조건을 이용한 조건절을 사용할 수 있어 다양한 조건에 대한 결과를 설정할 수 있습니다.
-- CONDITION 이 참이면 RETURN_EXPR을 돌려주고 아니면 표현절을 리턴합니다.
CASE WHEN CONDITION THEN RETURN_EXPR ELSE 표현절 END예시
-- sal 범위로 등급을 나누는 CASE 표현
SELECT ename,
CASE
WHEN sal >= 3000 THEN 'HIGH'
WHEN sal >= 1000 THEN 'MID'
ELSE 'LOW'
END AS SALARY_GRADE
FROM emp;DECODE 함수
조건을 평가하여 값을 반환하는 함수로, 주로 간단한 조건과 대응하는 결과 값을 처리할 때 사용됩니다. DECODE 함수는 CASE 문과 유사한 역할을 수행하지만, 보다 간단한 형식으로 작성할 수 있습니다.
DECODE 함수의 첫 번째 인자로 표현식을 지정하고 표현식의 값이 기준값1 과 같다면 값1을 출력하고 기준값1과 다르다면 디폴트 값을 출력합니다. 여러 개의 기준값을 설정할 수 있으며 기본값을 설정하지 않으면 NULL 값이 반환됩니다.
기본구조
DECODE(expression, value1, result1, value2, result2, ..., default_result)
expression은 비교할 값이나 표현식입니다.value1,value2등은expression과 비교할 값입니다.result1,result2등은 각각value1,value2등과 대응하는 결과 값이나 표현식입니다.default_result는 어떠한 값도 일치하지 않을 경우 반환할 값이나 표현식입니다.
-- 기본 형태
SELECT DECODE(표현식, 기준값1, 값1 [, 기준값2, 값2, ..., default])
FROM 테이블명;- 예시
-- player 테이블에서 선수 이름과
-- position이 MF 이면 미드필더, FW 면 공격수를 리턴하고
-- 둘 다 아니라면 교체선수를 리턴합니다.
SELECT player_name,
DECODE(position, 'MF', '미드필더', 'FW', '공격수', '교체선수')
FROM player;SELECT employee_id, first_name, last_name, DECODE(job_id, 'ST_MAN', 'Store Manager', 'SA_MAN', 'Sales Manager', 'IT_PROG', 'IT Programmer', 'Other Job') AS job_title FROM employees;
연습 문제
1번
| Q. 문제 | 단일행 함수의 특징으로 잘못된 것은? |
|---|---|
| A. (1) | SELECT, WHERE, ORDER BY 절에 사용 가능하다 |
| A. (2) | 함수의 리턴 값은 항상 여러 값으로 표현될 수 있다 |
| A. (3) | 함수의 인자로 상수, 변수, 표현식이 사용 가능하다 |
| A. (4) | 함수 안에서 함수를 호출하는 중첩 사용이 가능하다 |
정답
함수의 리턴 값은 항상 1개(단일 값)
2번
| Q. 문제 | 아래의 <SQL문>에서 ❓에 들어갈 알맞은 키워드는? <SQL문> SELECT CASE WHEN 1 = 1 THEN 1 ELSE 0 ❓ AS RESULT FROM DUAL; |
|---|---|
| A. (1) | END |
| A. (2) | IN |
| A. (3) | MOD |
| A. (4) | OR |
정답
end
3번
| Q. 문제 | NULL에 대한 설명으로 옳지 않은 것은? |
|---|---|
| A. (1) | NULL과 모든 비교는 알 수 없음을 반환한다 |
| A. (2) | NULL은 값의 부재를 의미한다 |
| A. (3) | NULL은 비어있는 값 0을 의미한다 |
| A. (4) | NULL 모르는 값을 의미한다 |
정답
NULL은 숫자 0이나 빈 공백 '' 과는 다른 값이다
