08. SQL 기본 문법 1
8.1. WHERE
WHERE절 개요
자료를 조회하거나 수정을 할 때 입력된 모든 데이터를 조회되거나 수정하는 것이 아닌 내가 원하는 데이터만 조회, 수정, 삭제를 하는 경우가 더 많습니다. 이럴 때 사용하는 SQL 문이 바로 WHERE 절 입니다. WHERE 절은 단독으로 사용하지 않고 조회, 수정, 삭제시 함께 사용됩니다.
- 기본 구조
- SELECT [DISTINCT] 칼럼명 [AS 별명] FROM 테이블명 WHERE 조건식;
- UPDATE 테이블명 SET 칼럼명=값 WHERE 조건식;
- DELETE FROM 테이블명 WHERE 조건식;- 예시
- SELECT * FROM PLAYER WHERE BACK_NO = 10;
- UPDATE PLAYER SET TEAM = '서울FC' WHERE NAME = '메시';
- DELETE FROM PLAYER WHERE NAME = '발로차';연산자 종류
연산자는 WHERE 절에서 조건이 되는 칼럼과 값을 비교할 때 사용합니다. 연산자는 기본적으로 비교 연산자, SQL 연산자, 논리 연산자, 부정 연산자 등 4가지 종류가 있습니다. WHERE 절의 조건식을 활용하면 다양한 값을 비교하여 표현할 수 있습니다.
비교 연산자
비교 연산자(=, >, >=, <, <= )는 숫자 혹은 문자 값의 대/소 그리고 동일한지를 확인할 때, 사용하는 가장 기본적인 연산자 입니다.
- host_city가 '평양' 데이터를 찾아 '평창'으로 수정해보세요.
- host_year 정보가 2019인 데이터를 찾아서 삭제해보세요.
-- 1
UPDATE olympic SET host_city = '평창' WHERE host_city = '평양';
-- 2
DELETE FROM olympic WHERE host_year = 2019;참고 - 문자 유형 비교 방법
양쪽이 모두 CHAR 타입인 경우
- 길이가 서로 다른 CHAR 타입이면 작은 쪽에 공백을 추가하여 길이를 같게 만든 후 비교
- 서로 다른 문자가 나올 때 까지 비교
- 뒤에 나오는 BLANK의 수만 다르다면 같은 값으로 결정
- 달라진 첫 번째 문자의 값에 따라 크기를 결정
한 쪽이 VARCHAR 타입인 경우- 길이도 같고 다른 문자가 없다면 같다고 판단
- 서로 다른 문자가 나올 때 까지 비교
- 길이가 다르면 짧은 것이 끝날 때까지만 비교 후 길이가 긴 것을 크다고 판단
상수값과 비교할 경우- 상수 쪽을 변수 타입과 동일하게 바꾸고 비교
- CHAR 타입이면 CHAR 비교 방식, VARCHAR 타입이면 VARCHAR 비교 방식을 적용
SQL 연산자
SQL 연산자는 기본적으로 예약되어 있는 예약어로 다양한 값에 대한 연산을 제공합니다. 해당 예약어는 테이블의 이름으로 사용해서는 안됩니다.
BETWEEN 값1 AND 값2
- 값1과 값2의 사이에 비교값이 있으면 됩니다.
- 값1 ≤ 비교값 ≤ 값2
IN (값1, 값2, ..., 값_리스트)
- 리스트에 있는 값 중에 어느 하나라도 일치하면 됩니다.
LIKE '비교 문자열' - 비교 문자열과 형태가 일치하면 됩니다.
(즉, 문자열 패턴을 기반으로 데이터를 검색하는 데 사용) - 대소문자를 구분하지 않습니다.
- WildCard 문자를 사용해서 비교할 수 있습니다. (
%,_)
%: 어떤 문자를 포함한 모든 것을 조회 (0개 이상의 문자 대체)
→ 0개 이상의 문자가 올 수 있음을 의미_: 1개 단일문자 (정확히 하나의 단일 문자 대체)
→ 1개의 문자가 있음을 의미
'커_' 패턴은 '커'로 시작하고 총 2자리 문자열과 일치 (커피, 커서)
'_도' 패턴은 '도'로 끝나는 2자리 문자열과 일치 (수도, 득도)IS NULL
- 비교 칼럼의 값이 NULL이면 됩니다.
- NULL 값임을 확인하기 위해서 사용해야합니다.
IS NOT NULL
- 비교 칼럼의 값이 값이 NULL이 아니면 됩니다.
- NULL 값이 아님을 확인하기 위해서 사용해야합니다.
NULL과 숫자 혹은 날짜를 연산하면 NULL이 됩니다.
논리 연산자
논리 연산자는 비교 연산자나 SQL 비교 연산자들로 구성된 여러 조건을 논리적으로 연결시키기 위하여 사용되는 연산자 입니다. 논리 연산자의 종류는 다음과 같습니다.
AND / OR / NOT
부정 연산자
비교 연산자와 SQL 연산자에 대하여 부정 표현을 나타내기 위한 연산자입니다. 부정 연산자는 다음과 같습니다.
부정 논리 연산자
- 같지 않다. (
!=,^=,<>) - ~와 같지 않다. (
NOT 칼럼명 =) - ~보다 크지 않다. (
NOT 칼럼명 >)
부정 SQL 연산자
- a와 b의 값 사이에 있지 않다. (
NOT BETWEEN a AND b) - list 값과 일치하지 않는다. (
NOT IN (list)) - NULL 값을 갖지 않는다. (
IS NOT NULL)
연산자의 우선순위
이러한 연산자들도 우선순위에 따라 비교 순서가 결정 됩니다. 연산자의 우선순위는 다음과 같습니다.
참고 - 연산자 우선순위
1 순위 : 괄호( )
2 순위 : NOT 연산자
3 순위 : 비교 연산자, SQL 비교 연산자
4 순위 : AND
5 순위 : OR
우선순위를 고려하지 않고 WHERE 문을 작성하면 의도하지 않은 동작이 발생할 수 있습니다. 따라서 실수하기 쉬운 논리 연산자의 경우 괄호를 사용하여 우선순위를 표시하는 것을 권장합니다.
연습문제
문제 1
| Q. 문제 | SQL문의 의미로 올바른 것은? SELECT * FROM TEST WHERE ENAME LIKE ‘_SOO’; |
|---|---|
| A. (1) | ENAME이 SOO와 같지 않은 사람을 조회한다 |
| A. (2) | 첫글자가 영문으로 시작하는 사람을 조회한다 |
| A. (3) | ENAME이 SOO인 사람을 조회한다 |
| A. (4) | ENAME이 ‘SOO’이고 앞에 첫 글자가 하나 더 있는 사람을 조회한다 |
정답
LIKE문에서 ‘_’의미는 1개 단일 글자를 의미한다
문제 2
| Q. 문제 | 아래와 같이 테이블을 생성하고 한 후, SQL문의 결과로 가장 알맞는 것은? <테이블> CREATE TABLE TEAM ( TEAM_NO CHAR(4), TEAM_NM VARCHAR2(50) NOT NULL, CONSTRAINT TEAM_PK PRIMARY KEY(TEAM_NO) ); INSERT INTO TEAM (TEAM_NO, TEAM_NM) VALUES ('D001', '마케팅팀'); INSERT INTO TEAM (TEAM_NO, TEAM_NM) VALUES ('D002', '개발팀'); COMMIT; <SQL문> SELECT COUNT(TEAM_NO) FROM TEAM WHERE TEAM_NO = 1001 ; |
|---|---|
| A. (1) | 0 |
| A. (2) | NULL |
| A. (3) | 공집합 |
| A. (4) | SQL에러 |
답
TEAM_NO는 CHAR 데이터 타입이다. WHERE조건에 숫자로 된 상수 1001을 비교하고 있다.
문제 3
| Q. 문제 | 연산자의 우선순위대로 바르게 나열한 것은? |
|---|---|
| A. (1) | 괄호 > NOT 연산자 > 비교 연산자, SQL 비교 연산자 > AND > OR |
| A. (2) | 비교 연산자, SQL 비교 연산자 > NOT 연산자 > 괄호 > AND > OR |
| A. (3) | 괄호 > 비교 연산자, SQL 비교 연산자 > NOT 연산자 > AND > OR |
| A. (4) | NOT 연산자 > 괄호 > AND > OR > 비교 연산자, SQL 비교 연산자 |
정답
괄호 > NOT > 비교, SQL > AND, OR
8.2. GROUP BY와 HAVING
집계 함수 (Aggregate Function)
집계 함수는 여러 데이터들의 정보를 집계하여 연산을 해주는 함수입니다. GROUP BY 절에 작성한 칼럼을 기준으로, 그룹으로 모인 상태에서 각 그룹의 집계를 계산하는 데 사용됩니다. 집계 함수는 SELECT, HAVING, 그리고 ORDER BY 절에 사용할 수 있습니다.
집계 함수의 기본 구조
ALL
- 모든 값을 기준으로 집계 할 때 사용하는 옵션입니다.
- 기본값이므로 생략 가능합니다.
DISTINCT - 같은 값을 하나의 데이터로 간주할 때 사용하는 옵션입니다.
- SELECT 문의 결과에서 유일한 하나의 행만 출력합니다.
집계 함수의 종류

집계함수의 특징
- 집계 함수는 COUNT(*)를 제외하고는 NULL 값은 제외합니다.
- 집계 함수는 WHERE 절에 올 수 없습니다.
WHERE 절이 GROUP BY 절 보다 먼저 수행이 되기 때문에 행들이 소그룹으로 묶이기 전에 집계 함수가 실행되어 제대로 된 집계를 할 수 없어지기 때문입니다.
GROUP BY 절
기본개념
GROUP BY 절은 데이터들을 작은 그룹으로 분류하여 해당 그룹에 대한 항목별로 통계 정보를 얻고자 할 때 사용하는 절입니다. 주로 SQL 쿼리문에서 FROM과 WHERE 뒤에 위치하게 되며 그룹별 기준을 정한 후 SELECT에 집계함수를 이용하여 원하는 데이터를 확인할 수 있습니다. 이때 집계 함수의 통계 정보에서 NULL 값은 제외됩니다.
GROUP BY 절 특징
GROUP BY 절에 적은 칼럼을 기준으로 결과 집합을 그룹화 합니다. 일반적으로 FROM TABLE 이후에 작성합니다. GROUP BY절을 사용할 때 숙지해야 할 부분에 대해 학습해 보겠습니다.
- GROUP BY 절을 사용할 때는 SELECT 절과는 다르게 ALIAS 명을 사용할 수가 없습니다.
- WHERE 절은 전체 데이터를 GROUP으로 나누기 전에 행들을 미리 주어진 조건에 맞춰 가져옵니다.
- 그럼 만약, GROUP BY로 그룹을 지은 상태에서 원하는 조건으로 필터링 하고싶다면?
이때 HAVING 절을 사용하면 됩니다. HAVING 절은 GROUP BY절의 기준 항목이나 소그룹의 집계 함수를 이용한 조건을 표시할 수 있습니다. - GROUP BY 절에 의한 소그룹 별로 만들어진 집계 데이터 중, HAVING 절에서 제한 조건을 두어 조건을 만족하는 내용만 출력할 수 있습니다.
- 원칙적으로 관계형 데이터베이스 환경에서는 ORDER BY 절을 명시해야 데이터가 정렬이 됩니다.
- GROUP BY 절보다 WHERE 절이 먼저 수행되기 때문에 집계 함수는 WHERE 절에 올 수 없습니다.
HAVING 절
기본
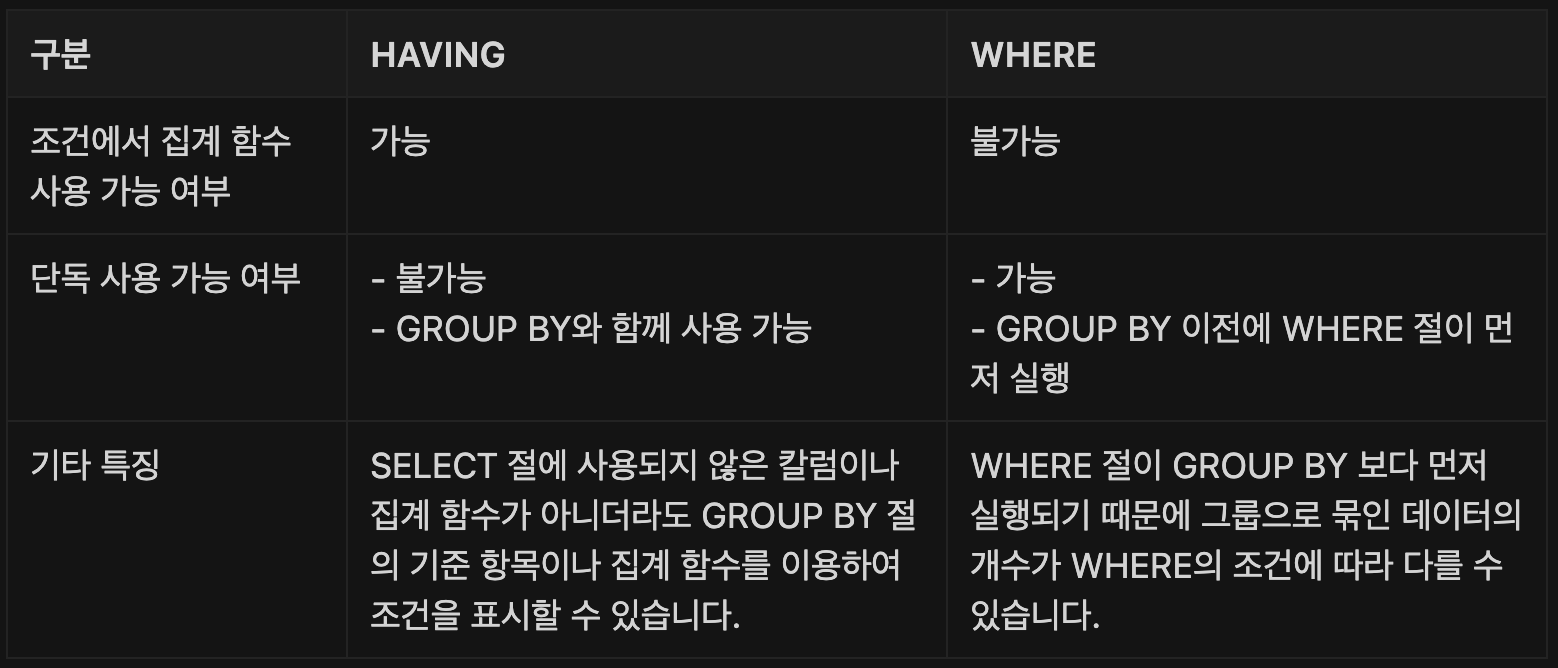
HAVING절은 WHERE절과 같이 특정 조건을 만족하는 결과 데이터만 표시를 할 수 있으나, 집계된 결과에 대해 사용한다는 것이 특징입니다.
특징
- 집계된 결과를 기준으로 조건이 필요한 경우 HAVING 절을 활용합니다.
- WHERE 절과 비슷하지만 그룹을 나타내는 결과의 행에 조건이 적용된다는 점에서 차이가 있습니다.
- GROUP BY 절과 함께 사용하여 특정한 제한 조건의 그룹화된 내용을 필터링 합니다.
HAVING 절과 WHERE절의 차이
기본 구조
HAVING 절의 위치는 GROUP BY 뒤에 오는 것이 적절합니다. HAVING 절이 GROUP BY 앞에 와도 결괏값은 동일하지만 쿼리문의 논리적 문맥의 흐름상 GROUP BY 뒤에 HAVING 절이 있는 것이 자연스럽기 때문입니다.
집계 함수와 NULL
조회 결과 중에서 NULL 이 있는 경우 집계 연산을 하기 위해 NVL 혹은 ISNULL 함수를 사용하여 0으로 변경할 수 있습니다. 다만, 이 함수를 집계 함수 내부에 넣어 사용하는 경우에는 불필요한 부하가 발생합니다. 다행히 집계 함수는 NVL, ISNULL 과 같은 함수를 내부에서 사용하지 않아도 NULL 데이터는 집계 함수의 대상에서 제외하고 함수 연산을 처리합니다.
(단, COUNT(*) 는 NULL 을 포함하여 모든 칼럼을 계산)
만약 100명의 성적 데이터 중에서 10명의 성적이 NULL이라면 AVG(성적)에서는 NULL을 제외한 90명의 데이터를 기준으로 평균값을 구하게 됩니다.
연습문제
문제 1
| Q. 문제 | 집계 함수의 종류에 대한 설명으로 옳지 않은 것은? |
|---|---|
| A. (1) | STDDEV : NULL 값을 제외한 표준 편차를 출력한다 |
| A. (2) | COUNT(*) : NULL 값을 제외한 행의 수를 출력한다 |
| A. (3) | VARIAN : NULL 값을 제외한 표현식의 분산을 출력한다 |
| A. (4) | AVG : NULL 값을 제외한 평균을 출력한다 |
답
NULL 값을 포함한 행의 수를 출력한다
문제 2
| Q. 문제 | HAVING 절과 WHERE절의 차이에 대한 설명으로 옳지 않은 것은? |
|---|---|
| A. (1) | WHERE절은 조건에서 집계 함수 사용이 가능하다 |
| A. (2) | HAVING절은 단독 사용이 불가하다 |
| A. (3) | GROUP BY 이전에 WHERE 절이 먼저 실행되어야 한다 |
| A. (4) | HAVING절은 GROUP BY와 함께 사용 가능하다 |
답
WHERE절은 조건에서 집계 함수 사용이 불가하다
문제 3
| Q. 문제 | SELECT문 실행 순서로 옳은 것은? |
|---|---|
| A. (1) | SELECT → FROM → WHERE → GROUP BY → HAVING → ORDER BY → LIMIT |
| A. (2) | SELECT → FROM → WHERE → GROUP BY → ORDER BY → HAVING → LIMIT |
| A. (3) | FROM → WHERE → GROUP BY → HAVING → SELECT → ORDER BY → LIMIT |
| A. (4) | FROM → SELECT → WHERE → GROUP BY → HAVING → ORDER BY → LIMIT |
정답
FROM > WHERE > GROUOP BY > HAVING > SELECT > ORDER BY > LIMIT
8.3. ORDER BY
ORDER BY 기본 개념
기본
ORDER BY 절은 SQL 문장으로 조회되는 데이터들을 특정 칼럼을 기준으로 정렬하여 출력하기 위해 사용합니다. 정렬하기 위해서는 칼럼명을 사용해도 되지만 SELECT 절에서 사용하는 ALIAS 명을 사용하거나 1 부터 칼럼의 순서를 정수로 명시해도 됩니다. 기본적으로 정렬은 오름차순으로 정렬이 되고 내림차순으로 정렬을 하기 위해서는 DESC 를 옵션으로 추가해 주면 됩니다.
특징
- ORDER BY 절에 기재한 칼럼 뒤에 정렬 방식을 설정할 수 있으며 아무것도 적지 않으면 기본 값은 오름차순(
ASC)으로 설정됩니다. 만약 내림차순으로 지정하려면DESC를 명시하면 됩니다. - ORDER BY 절에 칼럼명 대신에 ALIAS로 설정된 값을 사용할 수 있습니다.
데이터 별 오름차순 정렬 기준
- 숫자는 작은 값부터 정렬
- 날짜는 가장 빠른 날짜부터 정렬
NULL에 대하여 ORDER BY 했을 때 처리하는 부분이 DBMS를 제공하는 회사 별로 처리 방식이 다릅니다.
- Oracle에서는 NULL을 가장 큰 값으로 간주
- SQL Server는 NULL을 가장 작은 값으로 간주
SELECT 문장 실행 순서
GROUP BY와 ORDER BY를 동시에 사용하는 경우 SELECT 문장은 6개의 절로 구성되며 실행 순서는 다음과 같습니다.
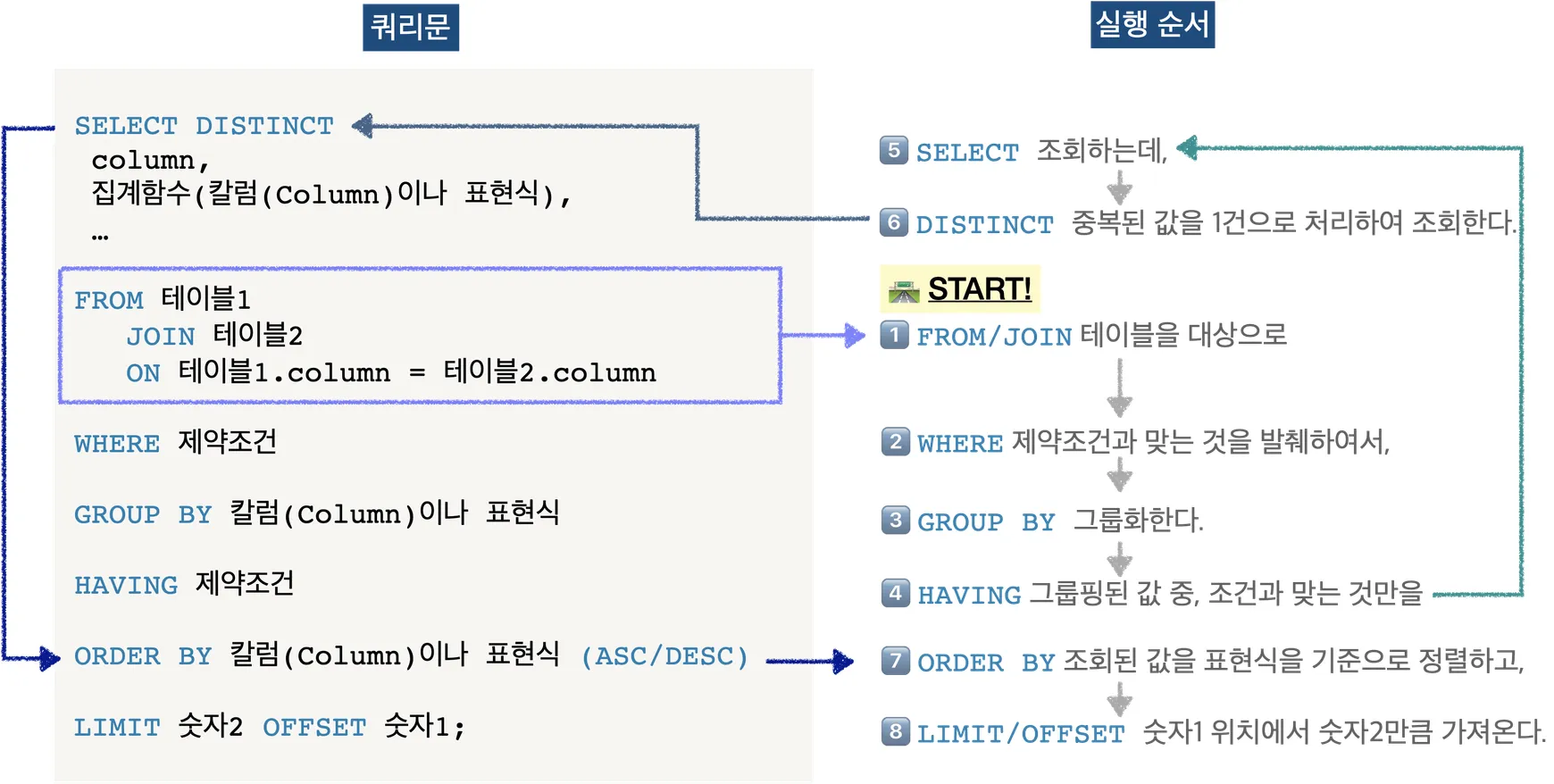
GROUP BY 절에서 그룹화될 칼럼을 정의하게 되면 데이터베이스는 일반적인 SELECT 문장처럼 FROM 절에 정의된 테이블 구조를 그대로 가져가지 않습니다. GROUP BY 절의 그룹 될 칼럼과 집계 함수에 사용될 수 있는 숫자형 데이터 칼럼들의 집합을 새로 만들게 됩니다. 그렇게 되면 GROUP BY 이후에 실행되는 SELECT 절이나 ORDER BY 절에서는 새롭게 만들어진 데이터에 접근을 하기 때문에 기존 테이블의 일반 칼럼을 사용할 경우에는 에러가 발생하게 됩니다. 다만 ORDER BY 절은 집계 함수를 이용한 정렬은 정상적으로 이루어집니다.
SELECT job, sal FROM emp GROUP BY job HAVING COUNT(*) > 0 ORDER BY sal;
--> Error 발생, sal 은 GROUP BY로 job 이 그룹화 될 것이기 때문에
-- 일반 칼럼 sal 사용으로 에러가 발생
SELECT job FROM emp GROUP BY job HAVING COUNT(*) > 0 ORDER BY sal;
--> Error 발생, ORDER BY 에서 일반 칼럼 sal 을 사용함
SELECT job FROM emp GROUP BY job HAVING COUNT(*) > 0
ORDER BY MAX(empno), MAX(mgr), SUM(sal), COUNT(deptno), MAX(hiredate);
--> 정상 조회 가능, ORDER BY 에서 집계 함수를 이용한 정렬은 가능함연습문제
문제 1
| Q. 문제 | ORDER BY절에 대한 특징으로 옳지 않은 것은? |
|---|---|
| A. (1) | 칼럼명 대신에 ALIAS로 설정된 값을 사용할 수 있다 |
| A. (2) | 오름차순의 정렬 기준 중, 숫자는 작은 값부터 정렬한다 |
| A. (3) | 내림차순의 정렬 기준 중, 날짜는 가장 오래된 날부터 정렬한다 |
| A. (4) | Oracle에서는 NULL을 가장 큰 값으로 간주한다 |
답
내림차순은 최근 날짜에서 과거 날짜 순서로 정렬하는 방식이다
문제 2
| Q. 문제 | 아래에 있는 SELECT문의 구문 중 가장 늦게 실행되는 것은? |
|---|---|
| A. (1) | SELECT |
| A. (2) | ORDER BY |
| A. (3) | WHERE |
| A. (4) | FROM |
답
ORDER BY
