Star-Schema란?
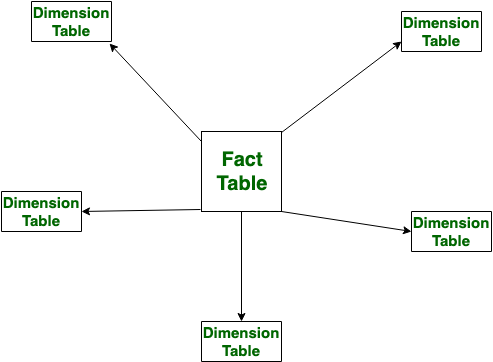
Star Schema(스타 스키마)는 데이터 웨어하우스 설계 방식 중 하나로, 주로 OLAP(Online Analytical Processing) 환경에서 다차원 분석을 위한 데이터 모델링 구조로 사용된다.
중심에 사실 테이블(Fact Table)이 있고, 이를 둘러싼 여러 개의 차원 테이블(Dimension Tables)이 별(star) 모양을 이루기 때문에 Star Schema라고 불린다.
| 구성요소 | 설명 |
|---|---|
| Fact Table (사실 테이블) | 비즈니스 이벤트나 트랜잭션의 측정값(수치) 저장. 예: 매출 금액, 수량 등. 각 행은 하나의 이벤트나 집계 단위를 나타냄. |
| Dimension Table (차원 테이블) | Fact Table의 수치를 설명하는 문맥(속성) 저장. 예: 고객, 제품, 시간, 지역 등. 보통 정규화되지 않은 형태(중복 허용)로 설계되어 조회 성능을 높임. |
예시: 매출 분석 Star Schema
- Fact Table:
Sales_Fact
customer_id,product_id,time_id,region_id(FK)sales_amount,quantity_sold
- Dimension Tables:
Customer_Dim(customer_id,name,gender,age,membership_level)Product_Dim(product_id,name,category,brand)Time_Dim(time_id,date,month,quarter,year)Region_Dim(region_id,city,state,country)
Star-Schema의 장점
| 특징 | 설명 |
|---|---|
| 단순한 구조 | 사용자나 BI 도구가 이해하고 쿼리하기 쉬움 |
| 빠른 조회 성능 | 정규화가 덜 되어 JOIN이 적고, 인덱싱 효율 높음 |
| OLAP에 적합 | 집계, 그룹화, 드릴다운 등 분석 연산에 최적화됨 |
| 확장성 | 차원을 쉽게 추가 가능 (예: 새로운 지역, 제품 등) |
Star-Schema의 단점
| 단점 | 설명 |
|---|---|
| 데이터 중복 | Dimension 테이블 내 중복 데이터가 많을 수 있음 |
| 정규화 부족 | 데이터 무결성 유지에 불리할 수 있음 |
| 복잡한 관계 표현 어려움 | 다대다 관계 표현이나 계층 구조 표현에 한계 |
Snowflake Schema란?
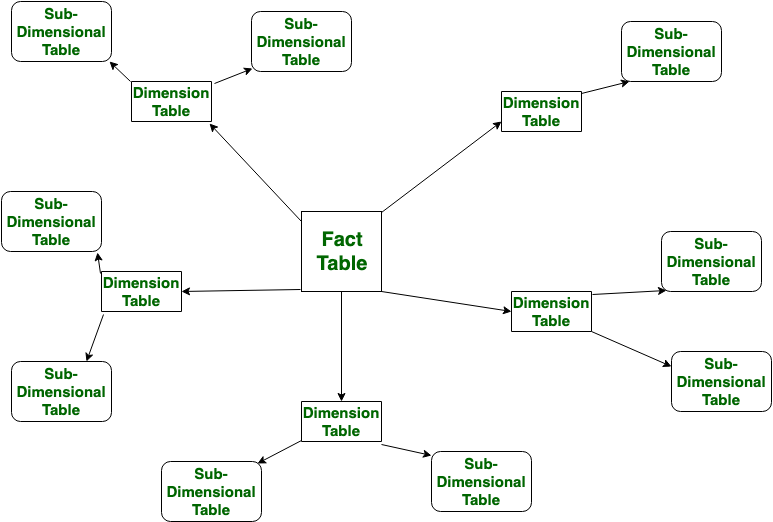
Snowflake Schema(스노우플레이크 스키마)는 Star Schema의 확장 형태로, 차원 테이블을 정규화(normalization)하여 여러 개의 관련 테이블로 분해한 구조다. 눈송이(snowflake)처럼 복잡한 구조를 가지므로 이와 같은 이름이 붙었다.
즉, 차원 테이블 내부에 중복되는 속성이 있을 경우 이를 별도의 테이블로 분리함으로써 저장 공간 절약과 데이터 무결성 유지에 유리하다.
| 구성요소 | 설명 |
|---|---|
| Fact Table | Star Schema와 동일하게 비즈니스 이벤트의 수치 데이터를 저장함 |
| Normalized Dimension Tables | 차원 테이블이 2계층 이상으로 분리되어 존재. 예: Product_Dim → Product, Category, Brand 등 |
예시: Snowflake 구조의 Product 차원 테이블
Product_Dim(product_id,product_name,category_id,brand_id)Category_Dim(category_id,category_name)Brand_Dim(brand_id,brand_name)
Snowflake Schema의 장점
| 특징 | 설명 |
|---|---|
| 저장 공간 절약 | 데이터 중복을 제거하므로 저장 효율이 높음 |
| 데이터 무결성 보장 | 정규화를 통해 관계형 무결성 유지에 유리 |
| 복잡한 관계 표현 | 계층 구조나 다대다 관계 등 세밀한 데이터 표현 가능 |
Snowflake Schema의 단점
| 단점 | 설명 |
|---|---|
| 복잡한 JOIN | 차원 테이블이 분해되어 여러 테이블을 JOIN해야 함 |
| 쿼리 성능 저하 | JOIN이 많아질수록 성능 저하 가능성 있음 |
| 설계 복잡성 증가 | 테이블 간 관계가 복잡하여 설계 및 유지보수가 어려움 |
Star Schema vs Snowflake Schema 간단 비교
| 항목 | Star Schema | Snowflake Schema |
|---|---|---|
| 정규화 수준 | 비정규화 (Denormalized) | 정규화 (Normalized) |
| 조회 성능 | 빠름 | 느릴 수 있음 |
| 설계 난이도 | 단순 | 복잡 |
| 저장 공간 | 더 큼 (중복 존재) | 더 작음 (중복 제거) |
| 데이터 무결성 | 낮음 | 높음 |
| 사용 사례 | OLAP, BI 도구 최적화 분석 환경 | 데이터 무결성 중시, 저장 효율 필요 시 |
일반적으로 분석 및 리포팅에 최적화된 환경에서는 Star Schema를 사용하고, 복잡한 관계 표현 및 데이터 무결성이 중요한 경우에는 Snowflake Schema를 고려한다.
Star Schema vs Snowflake Schema 심화비교
| 항목 | Star Schema | Snowflake Schema |
|---|---|---|
| 구조 | 중심에 Fact 테이블이 있고, 그 주변에 Dimension 테이블이 연결됨 | Fact 테이블이 정규화된 Dimension 테이블들과 연결됨 |
| 데이터 정규화 | 비정규화(Denormalized) | 정규화(Normalized) |
| 성능 | 조인이 적어 쿼리 속도가 빠름 | 다중 조인으로 인해 쿼리 속도가 느림 |
| 설계 복잡도 | 단순하고 이해하기 쉬움 | 복잡하고 계층 구조가 깊음 |
| 저장공간 사용량 | 비정규화로 인해 공간을 더 많이 사용함 | 정규화로 인해 공간 효율이 높음 |
| 데이터 중복 | 중복이 많음 | 중복이 적음 |
| 외래키 개수 | 외래키가 적음 | 외래키가 많음 |
| 사용 사례 | 빠른 조회와 간단한 쿼리에 적합 (예: 매출 분석) | 복잡한 계층과 정밀한 분석이 필요한 경우 적합 |
| 쿼리 복잡도 | 쿼리가 단순함 | 쿼리가 복잡함 (JOIN 많음) |
| 유지보수성 | 구조가 단순하여 유지보수 용이 | 구조가 복잡해 유지보수가 어려움 |
| 확장성 | 빠르게 구현 가능하지만, 대규모 데이터에서는 성능 이슈 가능 | 정규화로 인해 대규모 데이터에 더 적합 |
| BI 도구 적합성 | BI 도구와 잘 호환되며 빠른 리포팅 가능 | 정밀 분석 및 복잡한 리포팅에 적합 |
| 데이터 무결성 | 비정규화로 인해 무결성 보장 어려움 | 정규화로 인해 무결성이 높음 |
| 데이터 수정/업데이트 | 수정이 어렵고 중복 데이터로 인한 일관성 문제 발생 가능 | 수정이 용이하고 일관성 유지에 유리 |
| 학습 난이도 | 배우기 쉬움 | 배우기 어려움 |
Star Schema vs Snowflake Schema 선택 가이드
Star Schema가 적합한 경우
- 간단하고 빠른 쿼리가 필요할 때
- 소규모 또는 중간 규모의 데이터셋
- 실시간 대시보드, 빠른 리포트 생성이 중요한 소규모 비즈니스 환경
- 저장공간이 넉넉하고, 중복 데이터가 큰 문제가 아닌 경우
Snowflake Schema가 적합한 경우
- 복잡한 계층 구조를 가진 대규모 데이터
- 정규화된 데이터로 무결성을 유지해야 할 때
- 자주 업데이트되거나 유지보수가 필요한 시스템 (예: 고객, 재고 관리 시스템)
- 저장공간을 효율적으로 사용하고 싶을 때

Data Analytics Engineer 가 되