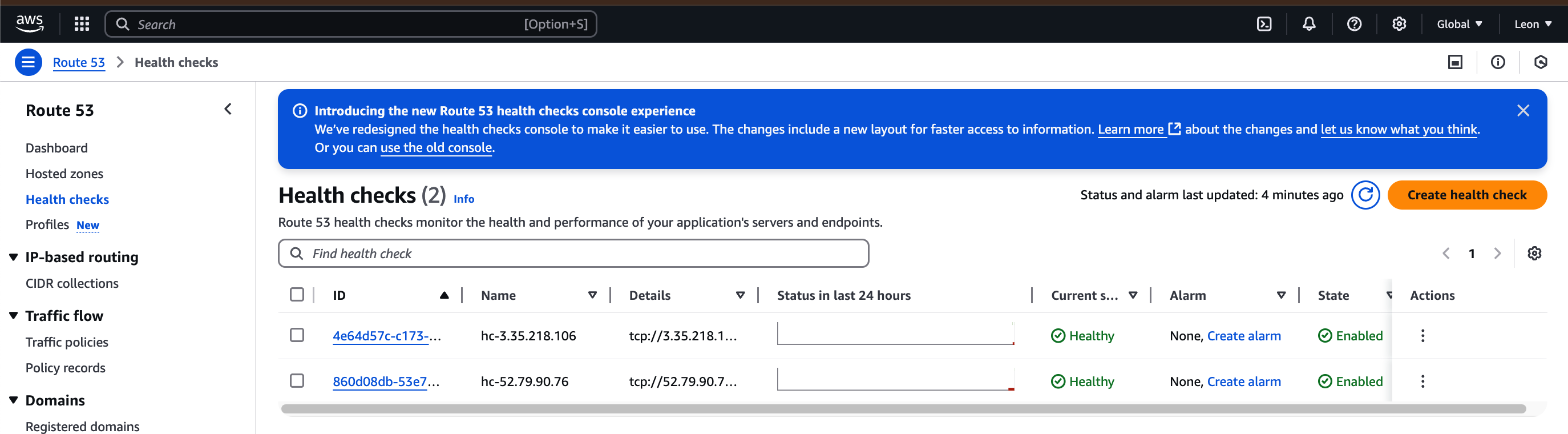
1. 헬스 체크(Health Check) 설정
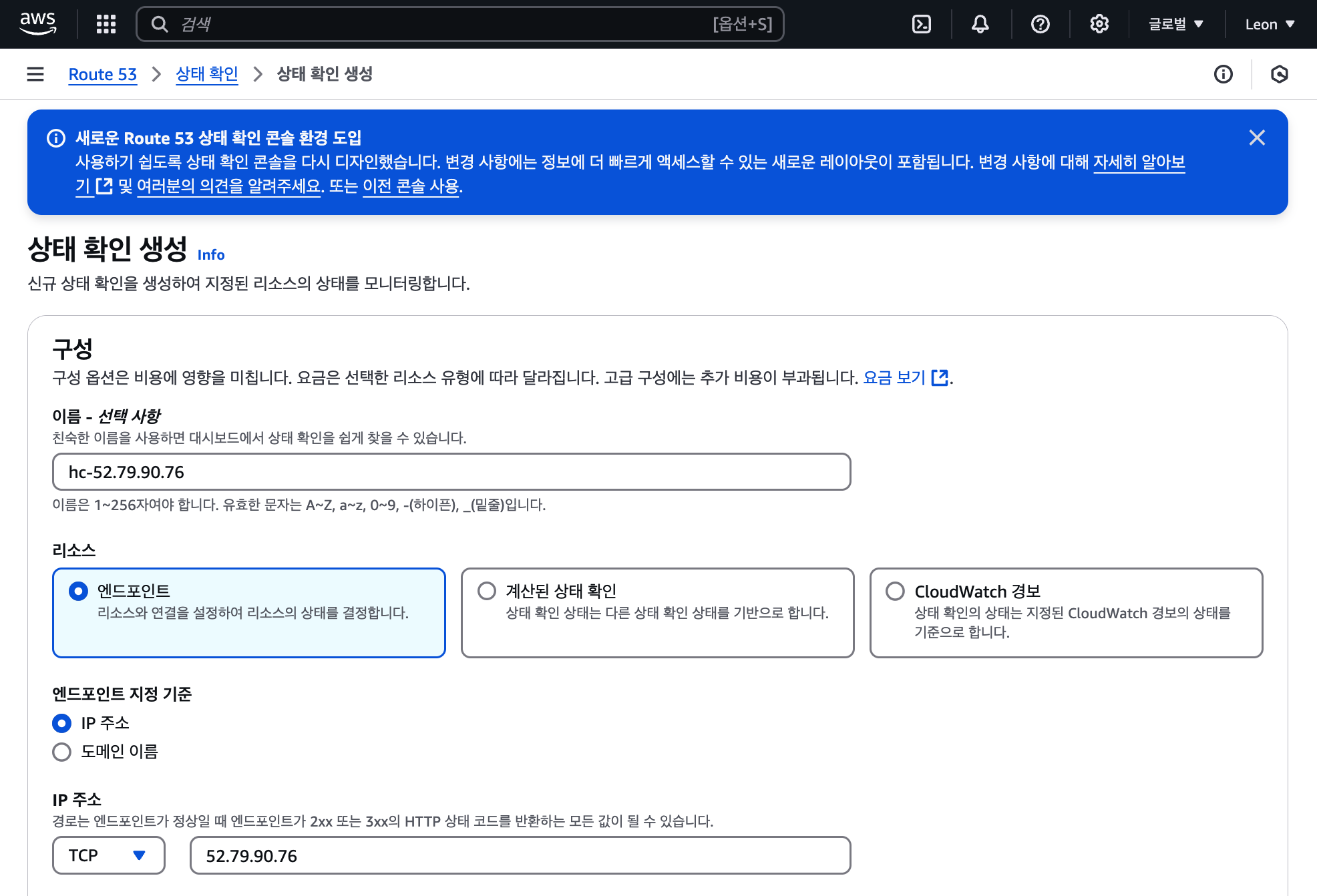
- 헬스 체크 이름은 hc-<IP주소>로 지정한다.
- 리소스는 엔드포인트, 엔드포인트 지정 기준은 IP이다.
- 프로토콜은 TCP, IP 주소는 해당 서버의 주소, 포트는 2000으로 설정한다.
포트번호는 IP주소:포트번호 형태로 입력해야 한다. 포트를 제대로 입력하지 않으면 상태가 Unhealthy로 표시되며, 메시지에는 다음과 같은 오류가 나타난다:
Failure_Connection timed out. The endpoint or the internet connection is down, or requests are being blocked by your firewall.
를 보게 될 것이다.
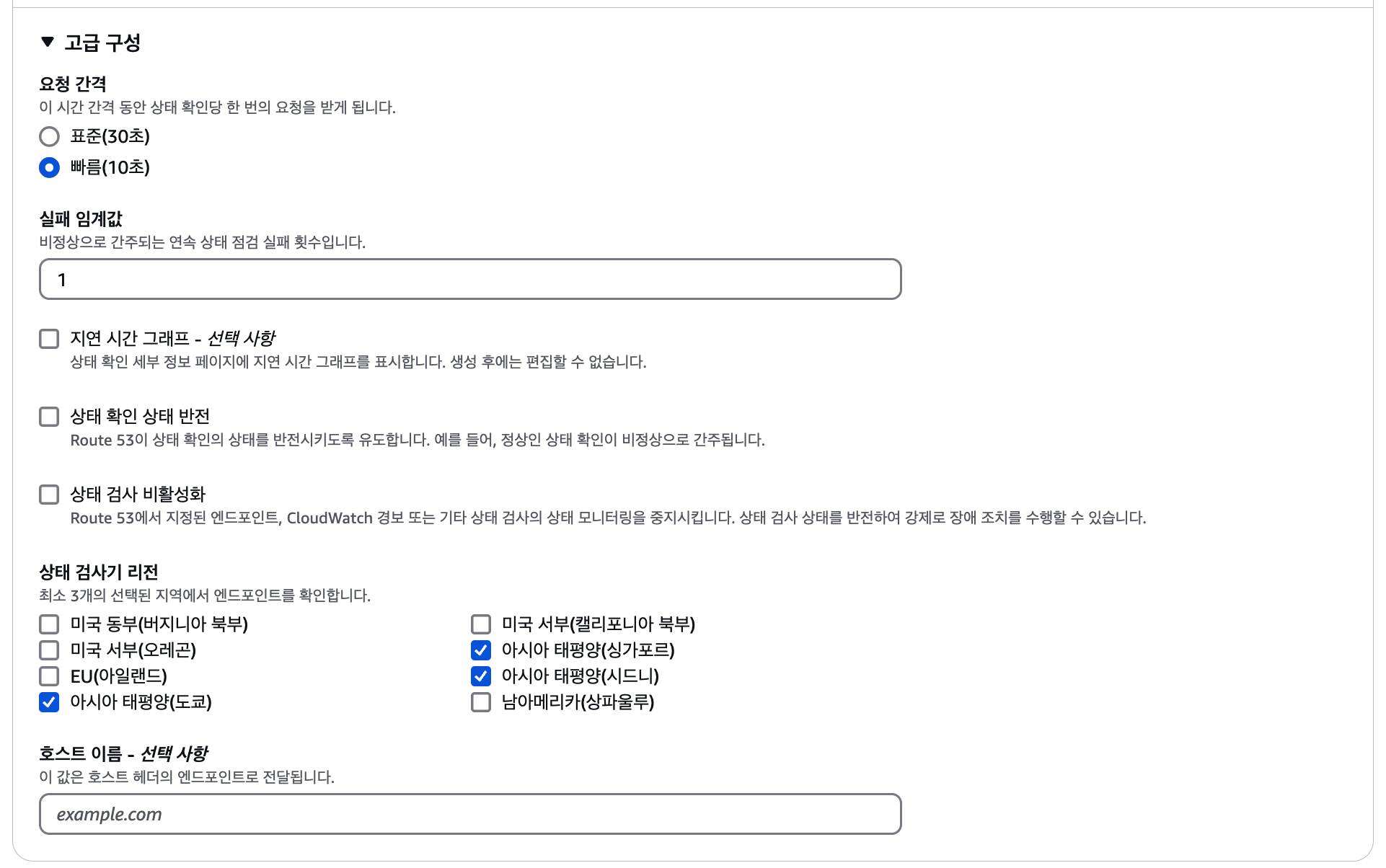
고급 설정 구성
-
요청 간격(Request interval)은 일반적으로 30초가 기본값이다.
- 실습을 위해 10초로 설정하였다.
- 이 요청은 AWS 헬스체크 서비스가 주기적으로 서버에 접근하는 것이므로 너무 짧은 간격은 과도한 비용과 부하를 유발할 수 있다.
-
Failure threshold는 기본값이 3이며, 실습을 위해 1로 설정하였다.
-
리전 선택은 기본적으로 유저 레코멘드를 따라도 되지만, 빠른 응답을 원한다면 서울 리전처럼 지리적으로 가까운 리전을 선택하는 것이 좋다.
- 태그(Tag)는 선택 사항이며, 비용 추적 등의 용도로 사용할 수 있다.
본 실습에서는 설정하지 않았다.
예전에는 Notification을 설정할 수 있는 단계가 있었으나, 현재는 바로 헬스 체크 생성이 완료된다.
2. Failover 레코드 생성 방법
hosted zone 으로 이동
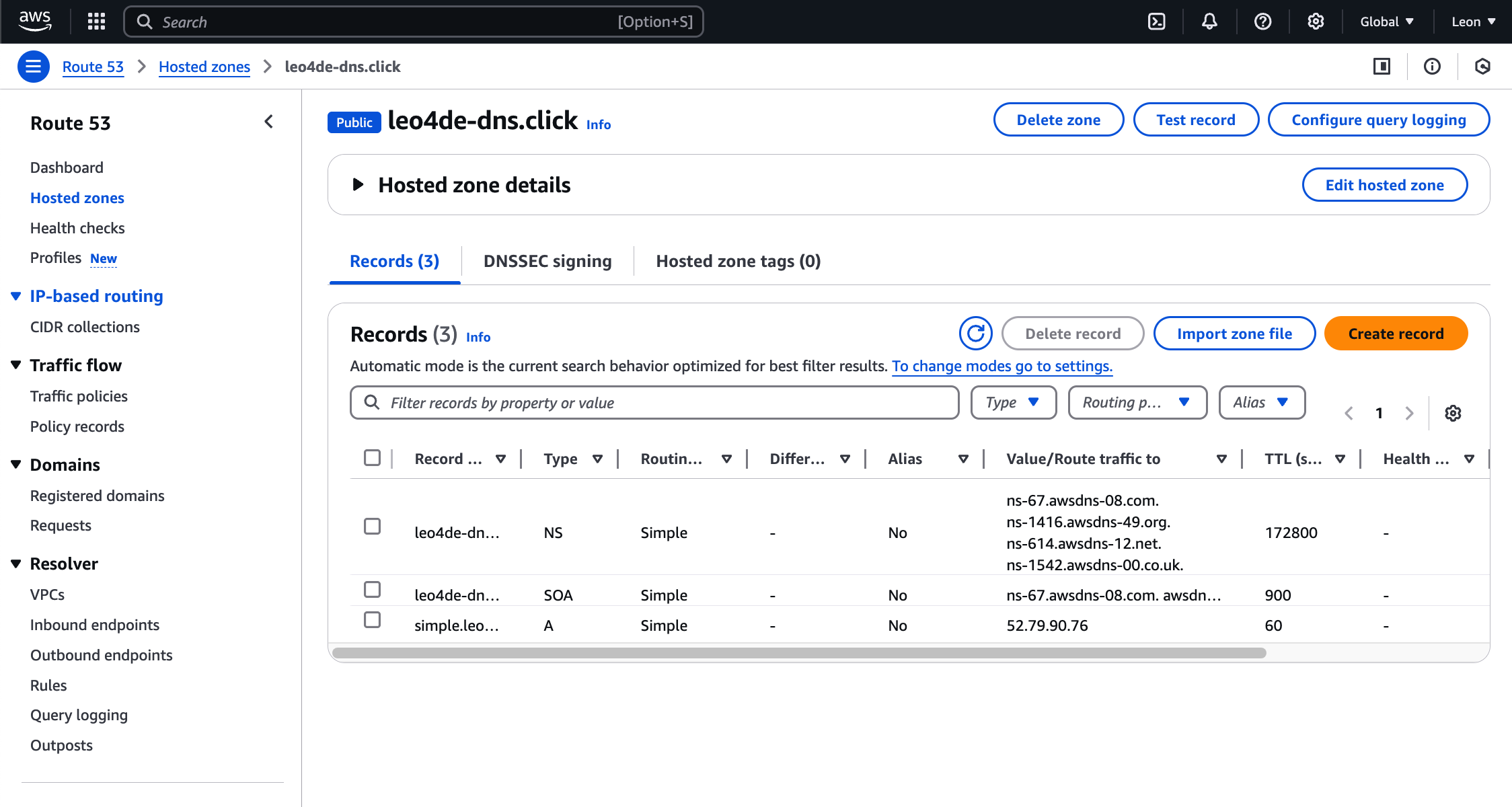
도메인 레코드 설정에 가서 Create Record를 클릭한다.
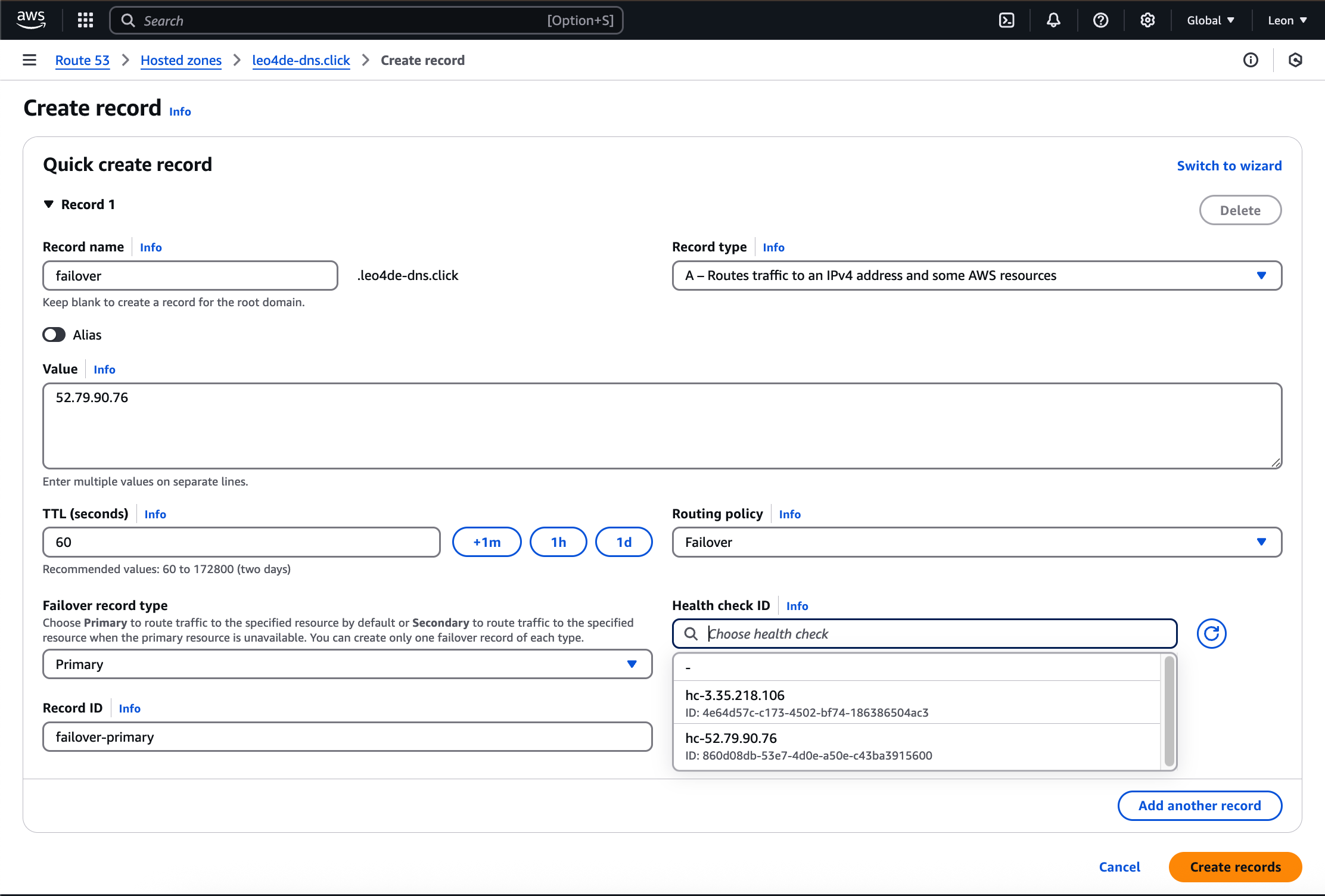
도메인 레코드 설정에서 다음과 같이 입력한다.
- Value: 기본 운영 서버의 IP 주소
- TTL(Time to Live): 1분(60초)
- Routing policy: Failover
- Failover record type: Primary
- Health check: 앞서 생성한 헬스 체크 선택
- Record ID: 해당 레코드를 구분할 수 있는 고유 ID 지정
Failover record type은 Primary, secondary 가 있다. Primary 는 가장먼저 연결하는 DNS가 여기에 연결하겠다.라는 거고 헬스체크는 아까 기본 서버의 IP주소로 미리 만들어 둔 헬스체크를 사용한다.
Record ID는 뭐냐면 같은 레코드 이름을 가진 레코드 설정에 대해서 유니크한 것을 구분하기 위해서 쓰는 아이디다. 알아볼 수 있는 ID적어주자.
Secondary 레코드 추가
이렇게 끝내는 것이 아닌
같은 도메인 이름에 대해 Add another 버튼을 눌러 secondary 레코드를 추가한다
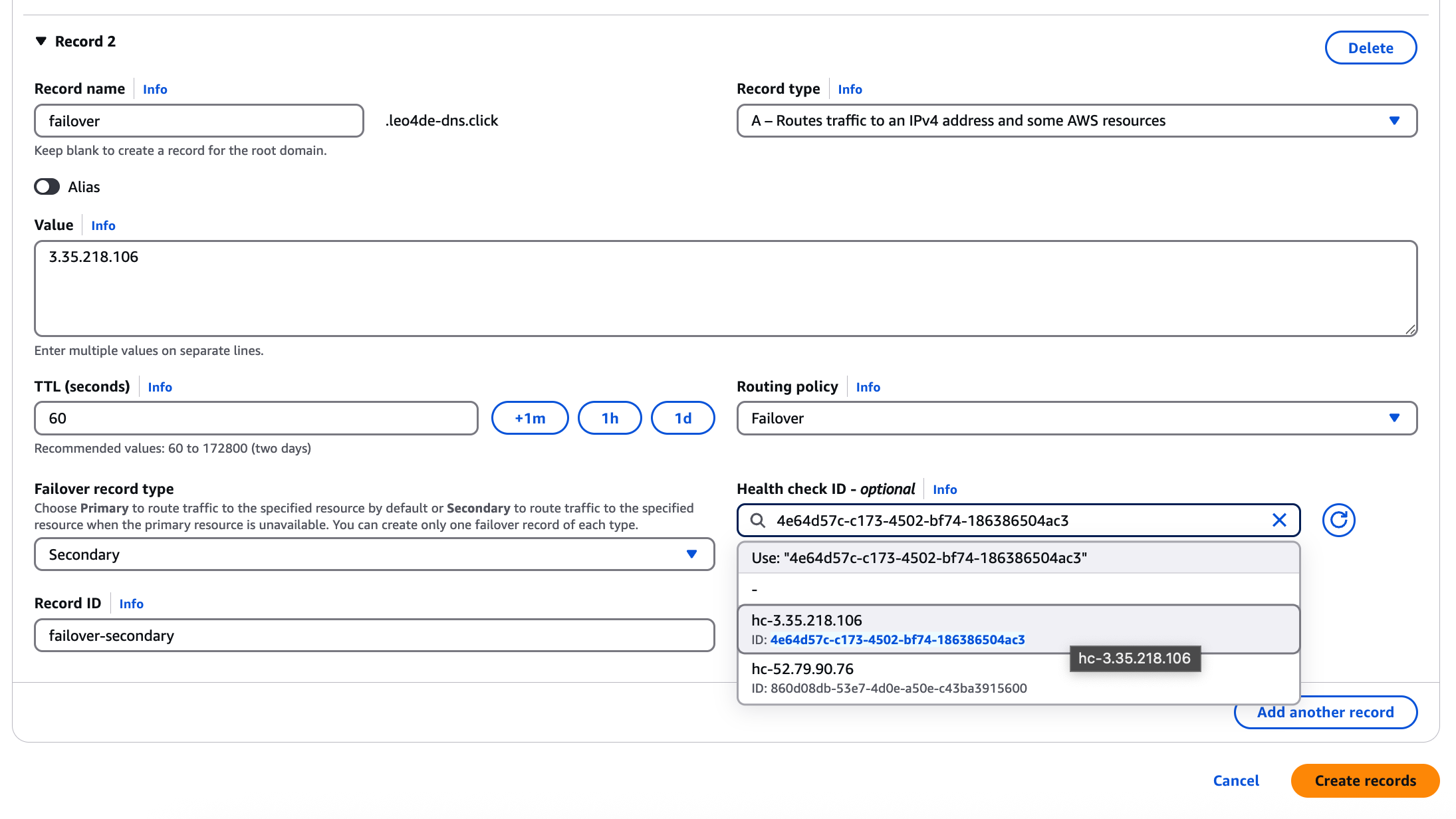
Secondary 레코드의 설정은 다음과 같다:
- Value: 두 번째 서버의 IP 주소
- TTL: 60초
- Routing policy: Failover
- Failover record type: Secondary
- Health check: 두 번째 서버에 맞는 헬스 체크 선택(아까 만들어 둠)
- Record ID: 구분 가능한 ID 지정
Primary와 Secondary를 동시에 Primary로 설정하면 1:1로 로드밸런싱하므로 주의가 필요하다.
create record.
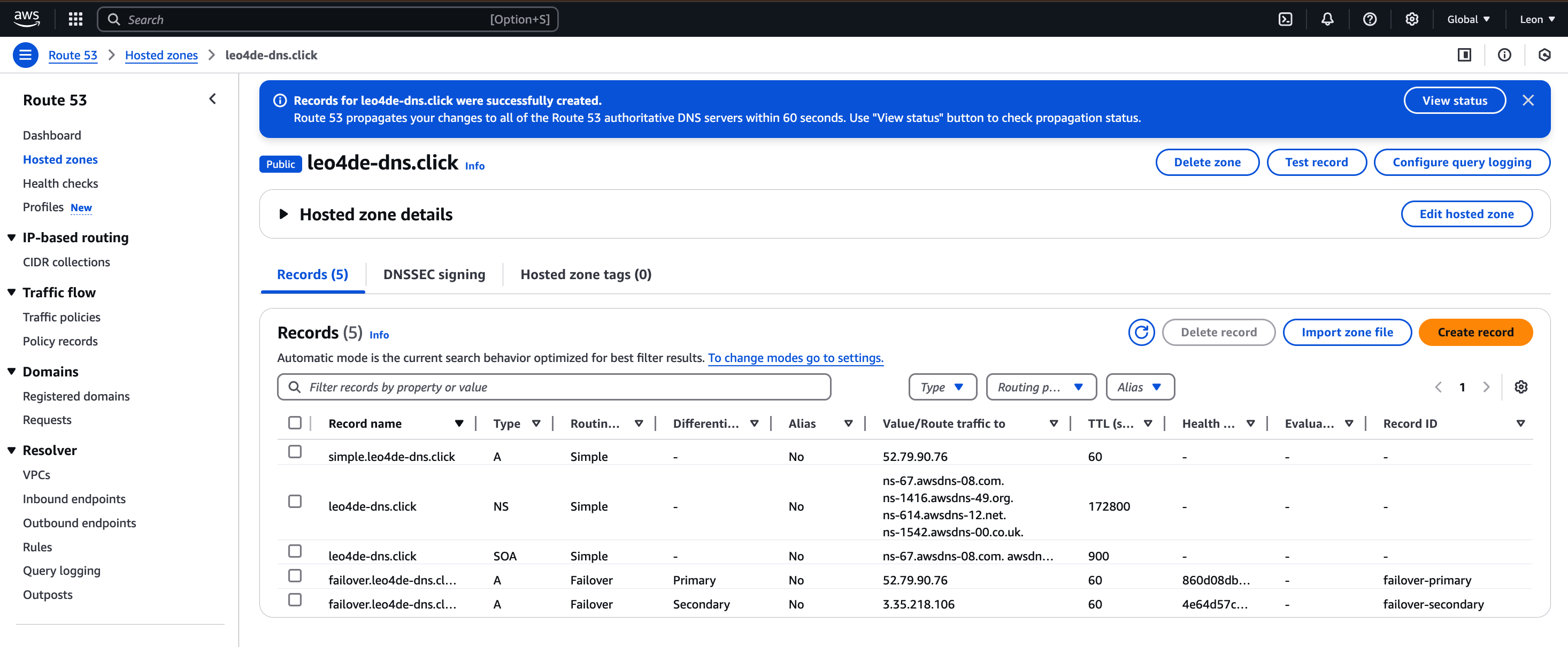
두 개의 Failover 레코드가 성공적으로 생성된 것을 확인할 수 있다.
동작 확인 (Primary Active 상태)
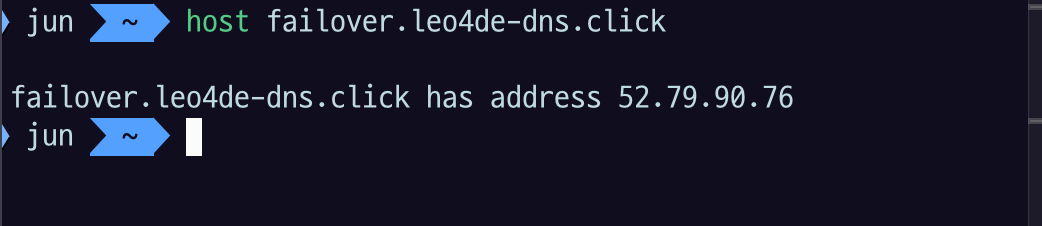
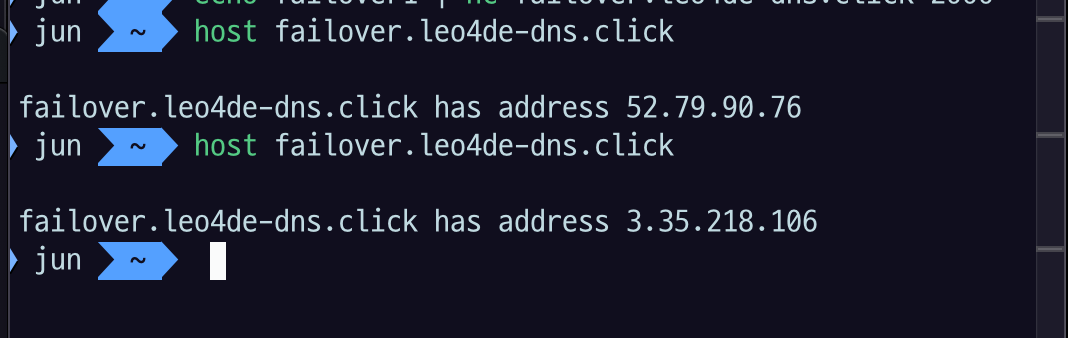
host failover.leo4de-dns.click명령어를 사용하면 현재 활성화된 주소를 확인할 수 있다.- 이때 primary 주소(
52.79.90.76)로 연결된 것을 확인할 수 있다.
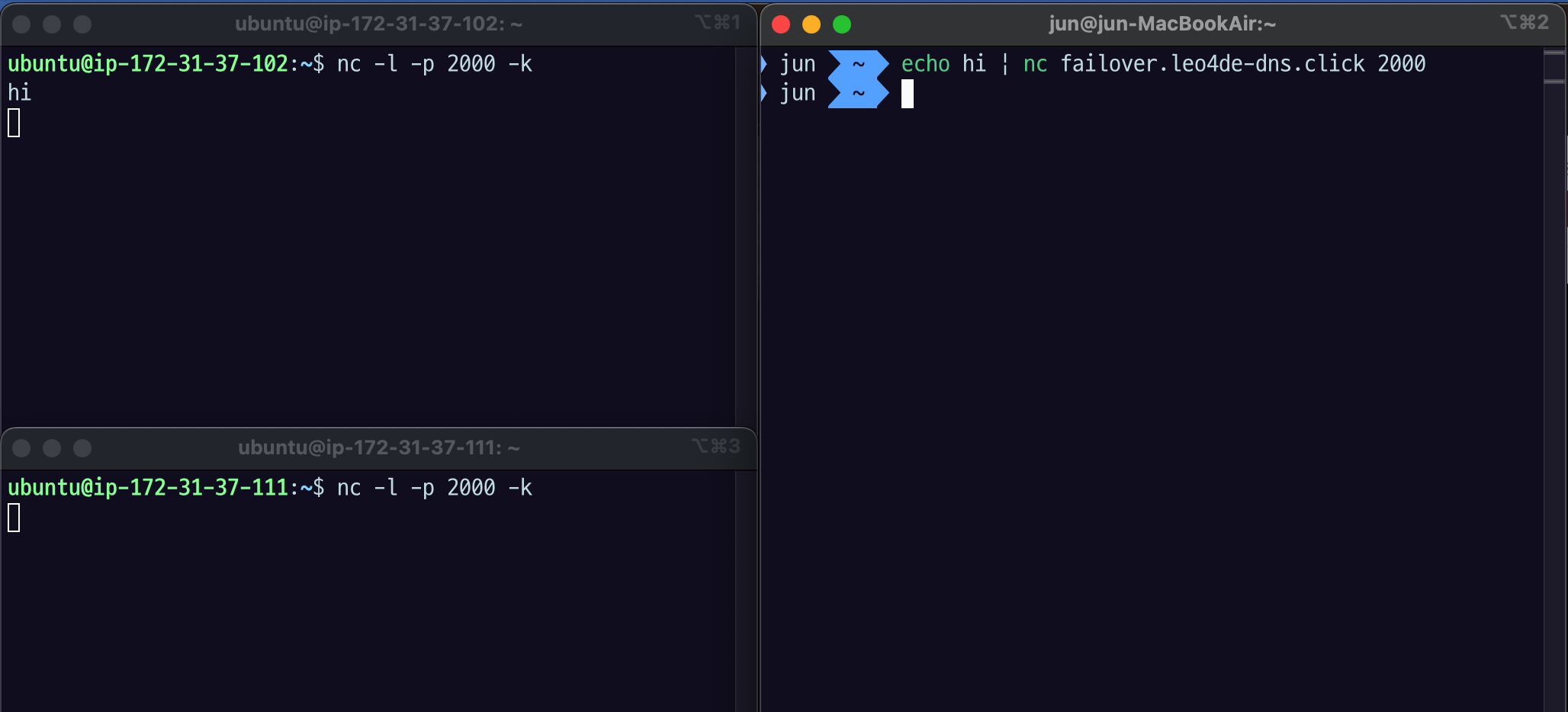
echo hi | nc failover.leo4de-dns.click 2000명령으로 메시지를 보내면, primary 서버에서 해당 메시지를 수신한다.
Primary 서버 종료 후 Failover 동작 확인
이제 primary의 프로세스를 ctrl + c로 죽인 상태로 failover가 잘 작동하는지 확인해보자.
- Primary 서버에서
ctrl + c로 netcat 프로세스를 종료한다. host명령어로 확인하면 여전히 primary 주소를 가리킨다.- 이유는 헬스 체크가 10초 간격이며, DNS 캐시로 인해 실제 반영은 더 오래 걸릴 수 있기 때문이다.
- 약간의 시간이 흐른 후 다시 확인하면, Failover 주소로 전환된 것을 확인할 수 있다.
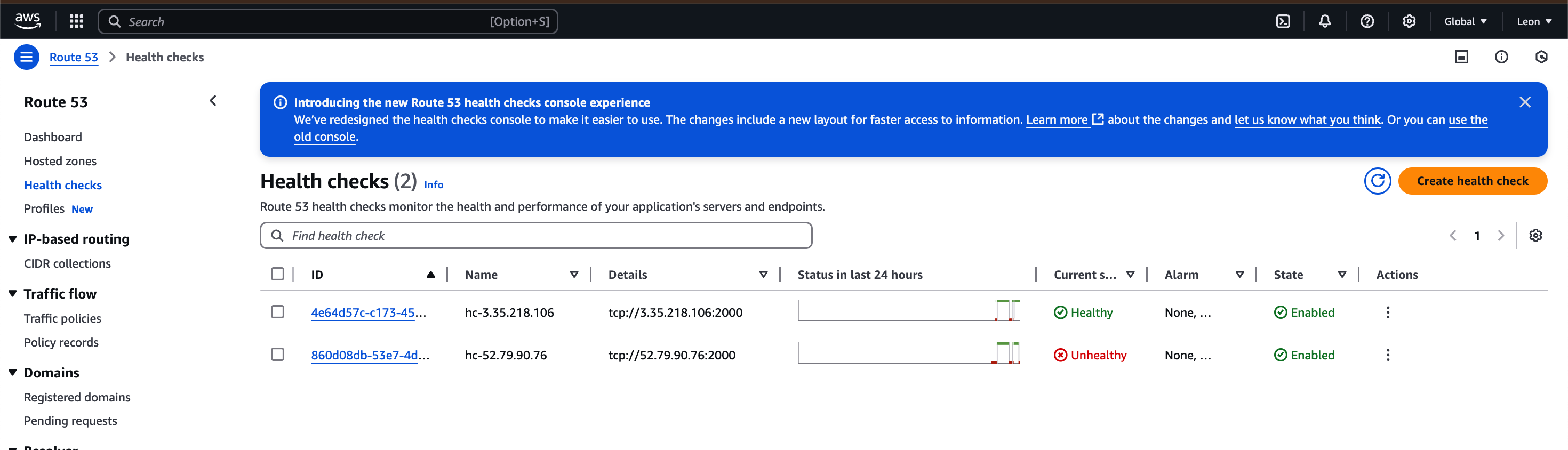
- Route 53 대시보드의 헬스 체크 상태에서 primary는
Unhealthy로 표시된다.
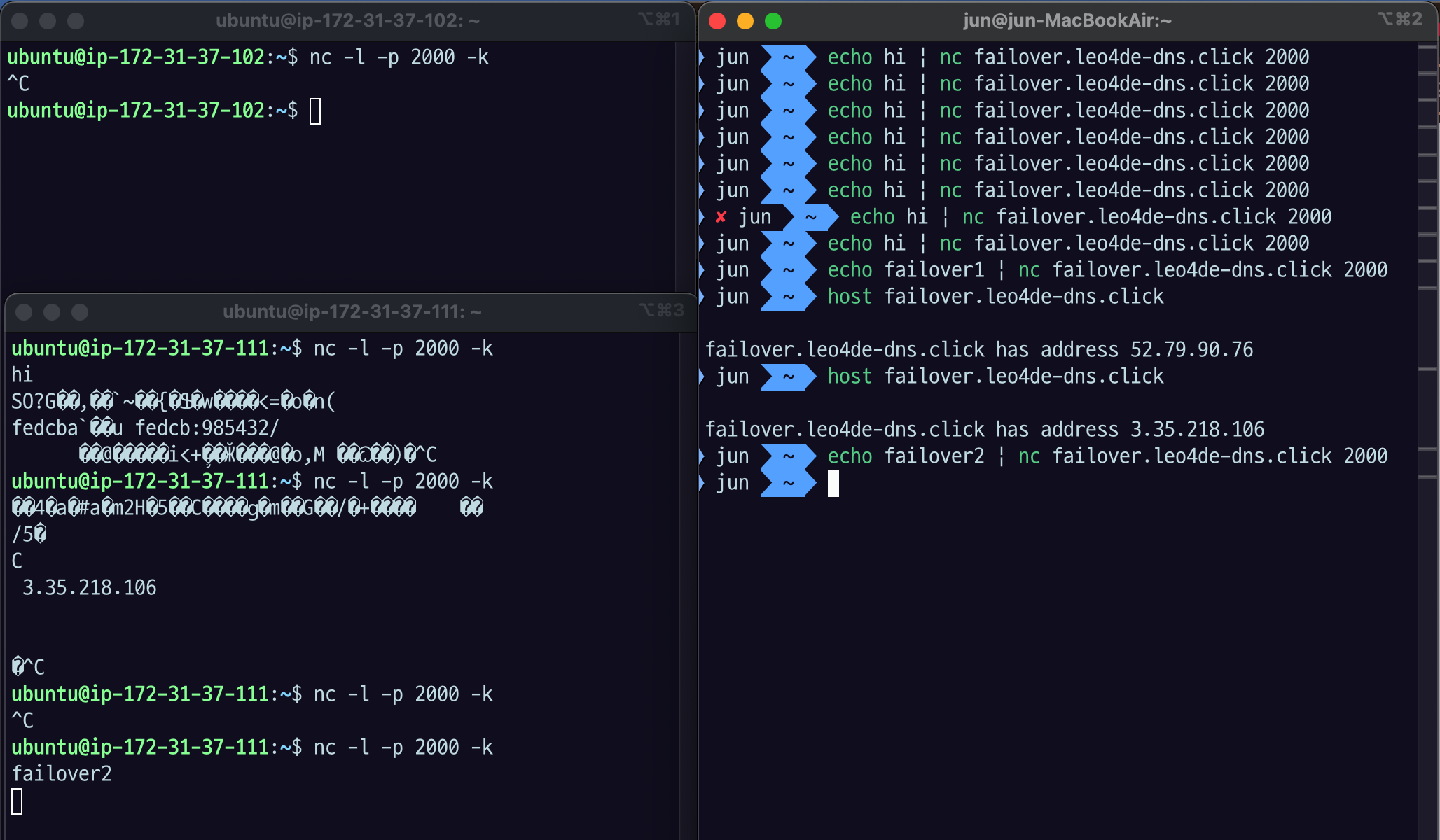
echo failover2 | nc failover.leo4de-dns.click 2000명령으로 메시지를 보내면, secondary 서버에서 수신되는 것을 확인할 수 있다.
다시 Primary 서버를 켰는데도 메시지를 못 받는 이유?
- Primary 서버에서 다시 nc -l -p 2000 -k 명령으로 리슨을 시작해도, DNS가 Failover 레코드를 다시 Primary로 전환하기까지 시간이 걸린다.
- 특히, Unhealthy → Healthy 전환은 Healthy → Unhealthy보다 훨씬 오래 걸리는 경향이 있다.
- DNS TTL이 60초로 설정되어 있고, 클라이언트 단의 DNS 캐시도 있기 때문에 전환이 늦어지는 것이다.
모든 서버가 Unhealthy인 경우
- 만약 Primary와 Failover 서버 모두 Unhealthy 상태가 되면, Route 53은 기본적으로 Primary의 주소를 응답한다.
- 이유는 DNS 자체는 요청에 대해 반드시 응답해야 하며, Failover 상태가 모두 실패해도 "routing을 하지 않는 것"이 아니라 "기본 주소를 제공"하는 방식으로 처리하기 때문이다
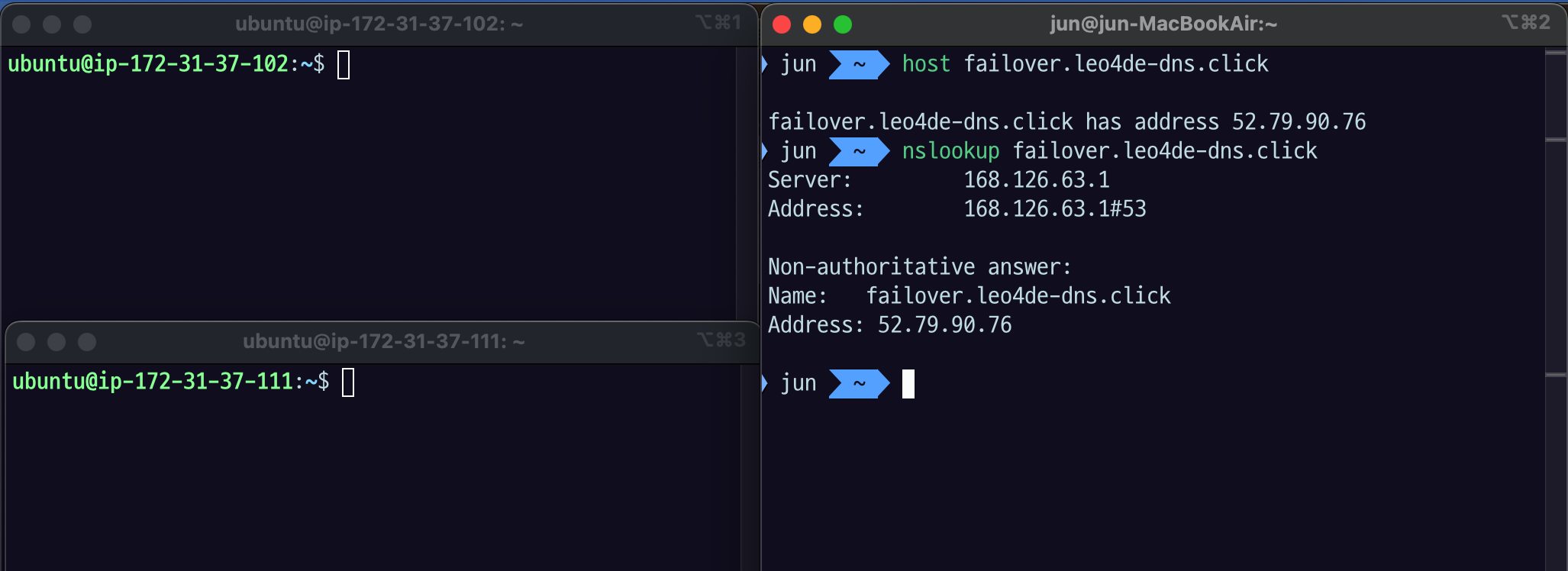
- 2번서버(failover서버)였던주소가
1번 서버 (primary서버) 주소로 바뀌었다.
Failover 구성은 서비스의 고가용성을 위한 중요한 전략이다. Route 53과 헬스 체크, Failover 레코드를 조합하면 서버가 다운되었을 때 자동으로 대체 서버로 전환되도록 설정할 수 있다.
단, 전환에는 시간 차이가 존재하며, 특히 복구(Healthy) 시에는 그 반영이 지연될 수 있으므로 이러한 동작 특성을 잘 이해하고 구성해야 한다.
나의 서비스가 절대 중단되면 안되거나 항상 최악의 경우를 대비해야 되는 경우 failover 전략을 통해서 안전한 서비스를 구현할 수 있다.
