실습 - (AWS 환경)
1.[AWS] 람다 사용한 EC2 자동 중지 방법

https://velog.io/@denver_almighty/AWS-EC2-%EC%9D%B8%EC%8A%A4%ED%84%B4%EC%8A%A4-%EC%9E%90%EB%8F%99-%EC%A4%91%EC%A7%80-%EC%84%A4%EC%A0%95-ixzo5x8f
2.[AWS] AWS와 EC2 인스턴스 소개
요즘 기업들도 IT인프라를 따로 빌딩 지어서 서버 만들고 유지보수할 인력을 관리하고 서버 수급하고 샀다 고장나면 고치고 이런 식으로 하기 어렵기 때문에 실제 투입 비용대비 효율뿐 아니라 작업 진행 속도 등 여러 비용이 많이 들기 떄문에 요즘은 원래 IDC라고 하는 서버
3.[AWS] 예상 비용 계산하기

기업이 클라우드 서비스를 활용할 때, 새로운 데이터 엔지니어링 기술(예: Apache Flink, Apache Spark 등)을 도입하려는 경우가 많다. 하지만 클라우드 서비스는 사용한 만큼 비용이 청구되기 때문에, 회사 입장에서는 얼마나 많은 비용이 발생할지 미리 예
4.[AWS] 활용 기초
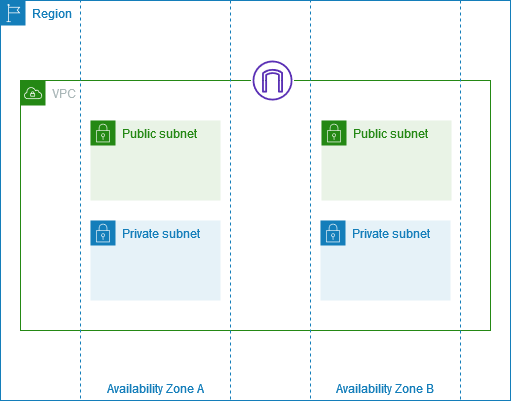
VPC(Virtual Private Cloud)는 논리적으로 분리한 서브 네트워크로 AWS 환경 내의 네트워크 최소 단위.원래는 컴퓨터에 랜선이라는 걸 꼽아야 인터넷이 연결됐었는데 그걸 네트워크라고 한다.VPC는 랜선을 뽑아 나눈 물리적인 망이 아니라 논리적으로 분리한
5.[AWS] EC2 인스턴스 생성, key 파일 저장
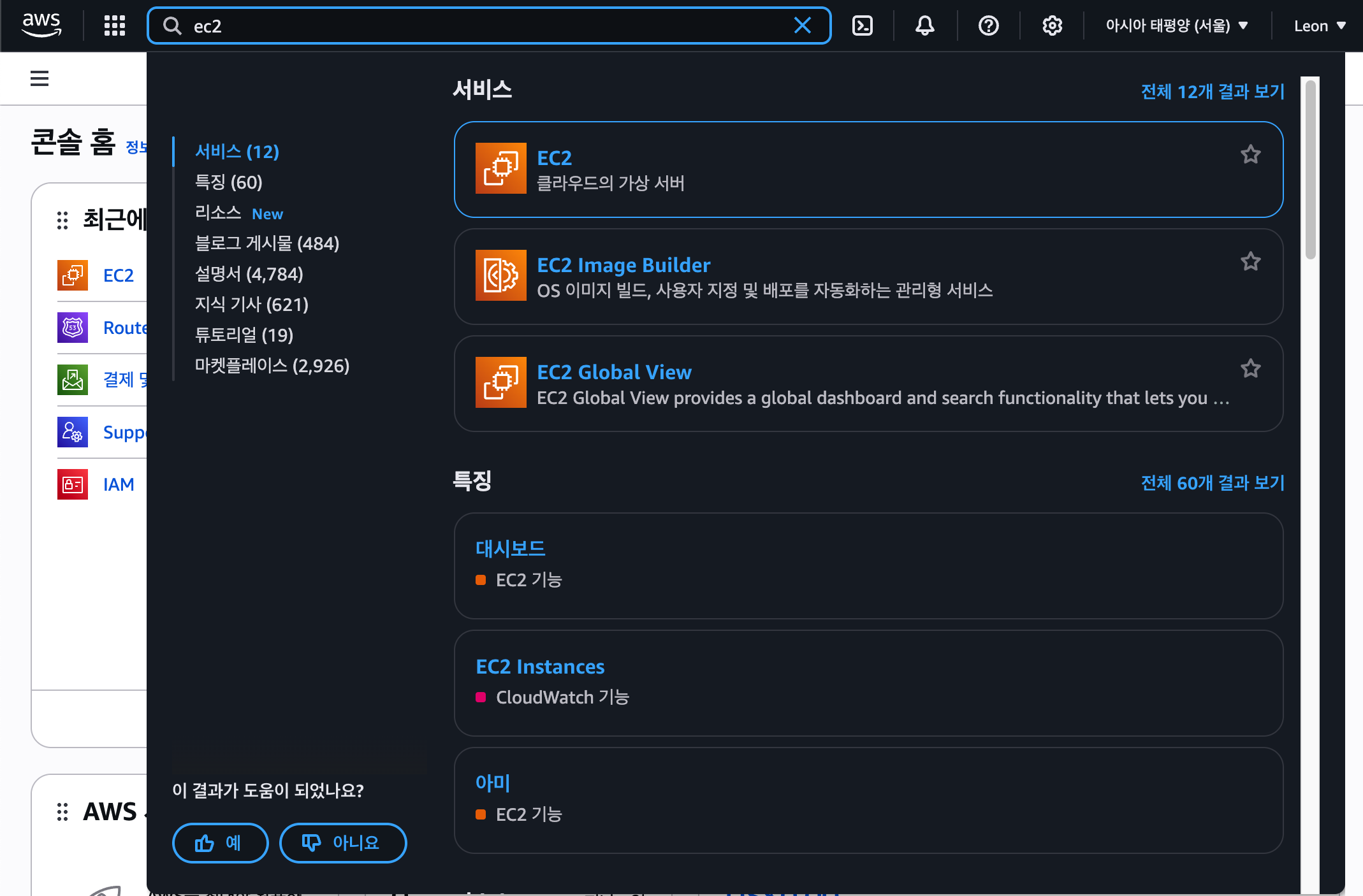
처음 aws에서 EC2를 검색한다.대시보드 페이지에서 인스턴스를 클릭해 인스턴스 페이지로 넘어갈 수 있다.우측 상단 인스턴스 시작 버튼을 눌러 인스턴스를 만들 수 있음.이름은 내가 해당 ec2인스턴스를 알아볼 수 있는 이름으로 지어주고 OS를 선택하자. 나는 실습용으로
6.[AWS] Router53 - DNS 생성, Record 설정하기
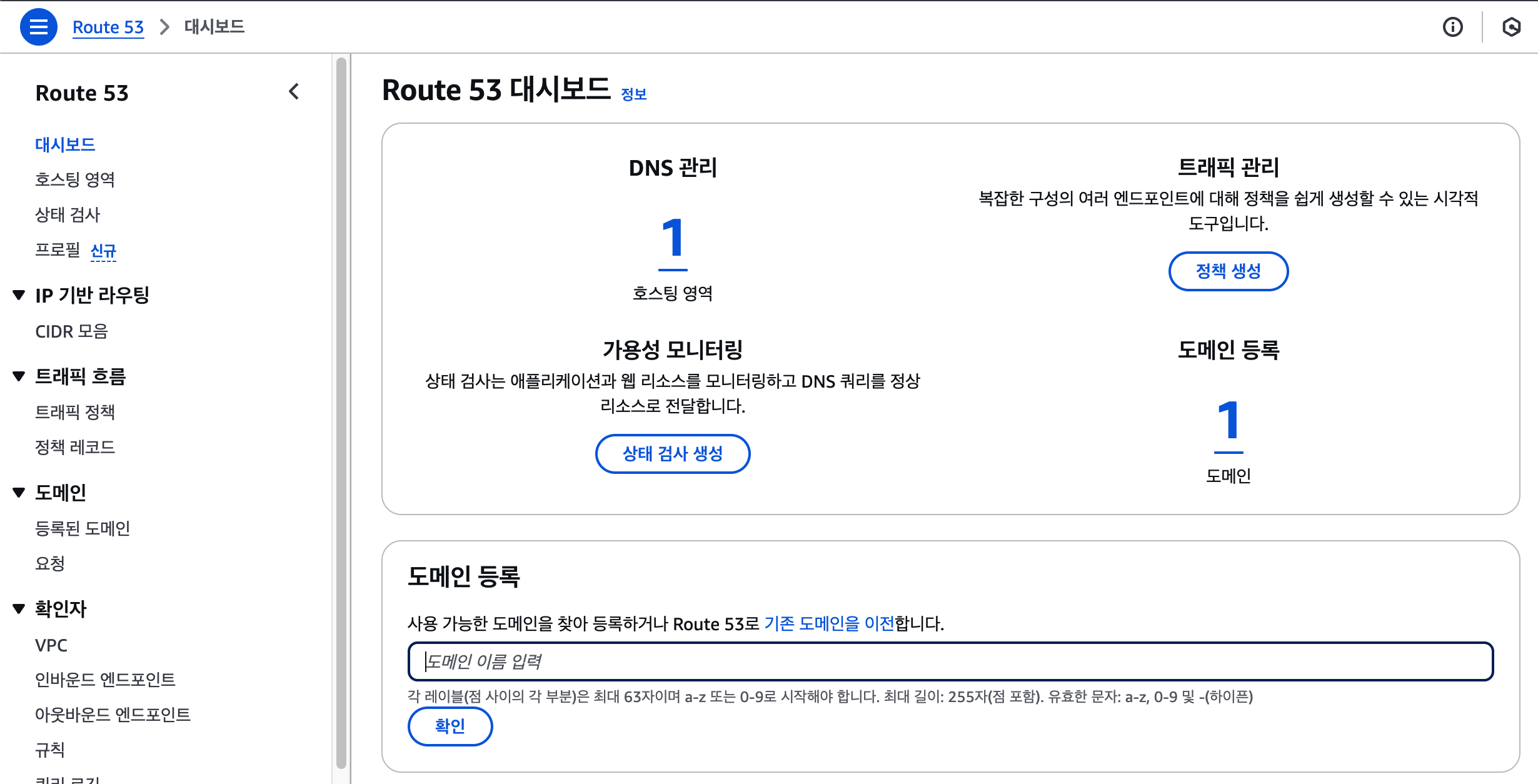
Router53에 들어가서도메인 등록에 원하는 도메인을 입력해보자.도메인 이름은 문자, 숫자, 하이픈을 포함할 수 있지만 63자보다 길 수 없다.확인으로 넘어가면 아래와 같은 화면이 나오는데내가 입력한 도메인이 사용 가능한지 여부와 사용 가능한 도메인들을 제안해준다.
7.[AWS] EC2 환경에서 Failover 실습: `nc` 명령어를 이용한 TCP 통신 테스트
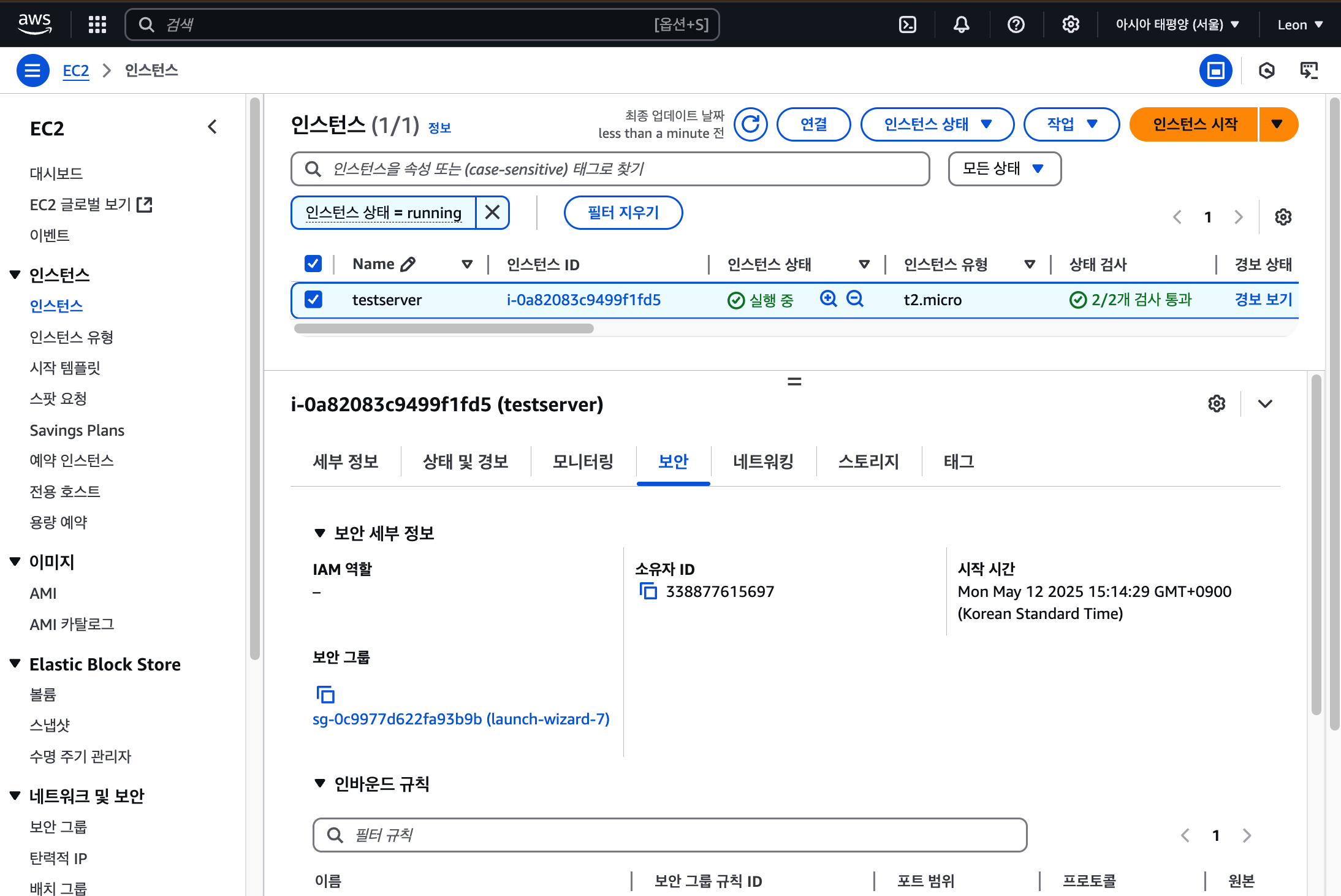
AWS EC2 환경에서 Failover를 테스트하거나, 간단한 서버-클라이언트 구조를 실습해보고 싶다면 nc (netcat)를 이용한 TCP 통신이 유용하다.이번 글에서는 EC2 인스턴스를 활용한 간단한 echo 서버 구축부터, 보안 그룹 설정, 내부 통신 방법까지 자
8.[AWS] Route 53 헬스체크와 Failover 레코드 설정 실습
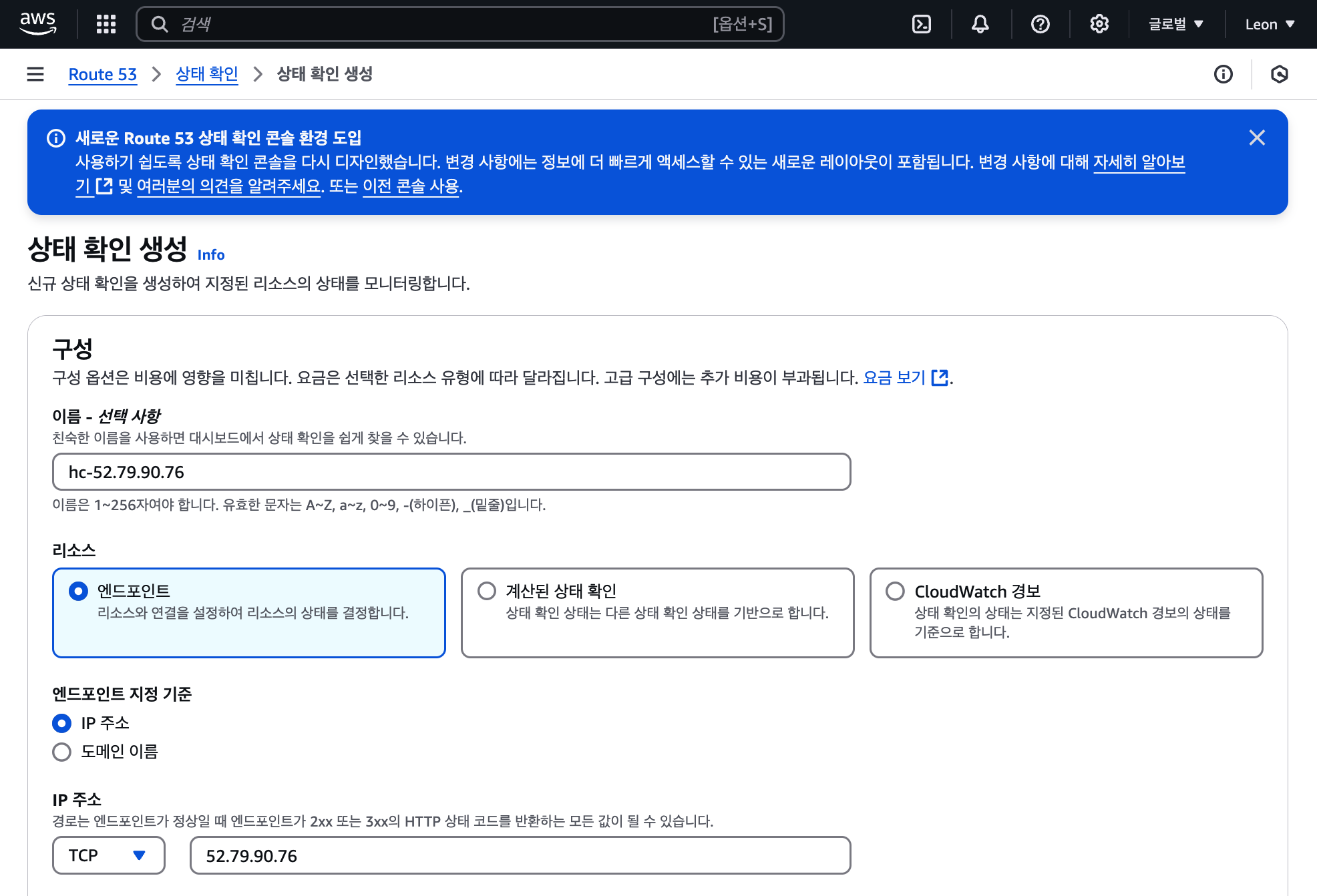
헬스 체크 이름은 hc-<IP주소>로 지정한다.리소스는 엔드포인트, 엔드포인트 지정 기준은 IP이다.프로토콜은 TCP, IP 주소는 해당 서버의 주소, 포트는 2000으로 설정한다.포트번호는 IP주소:포트번호 형태로 입력해야 한다. 포트를 제대로 입력하지 않으면
9.[AWS] Weighted Routing 실습
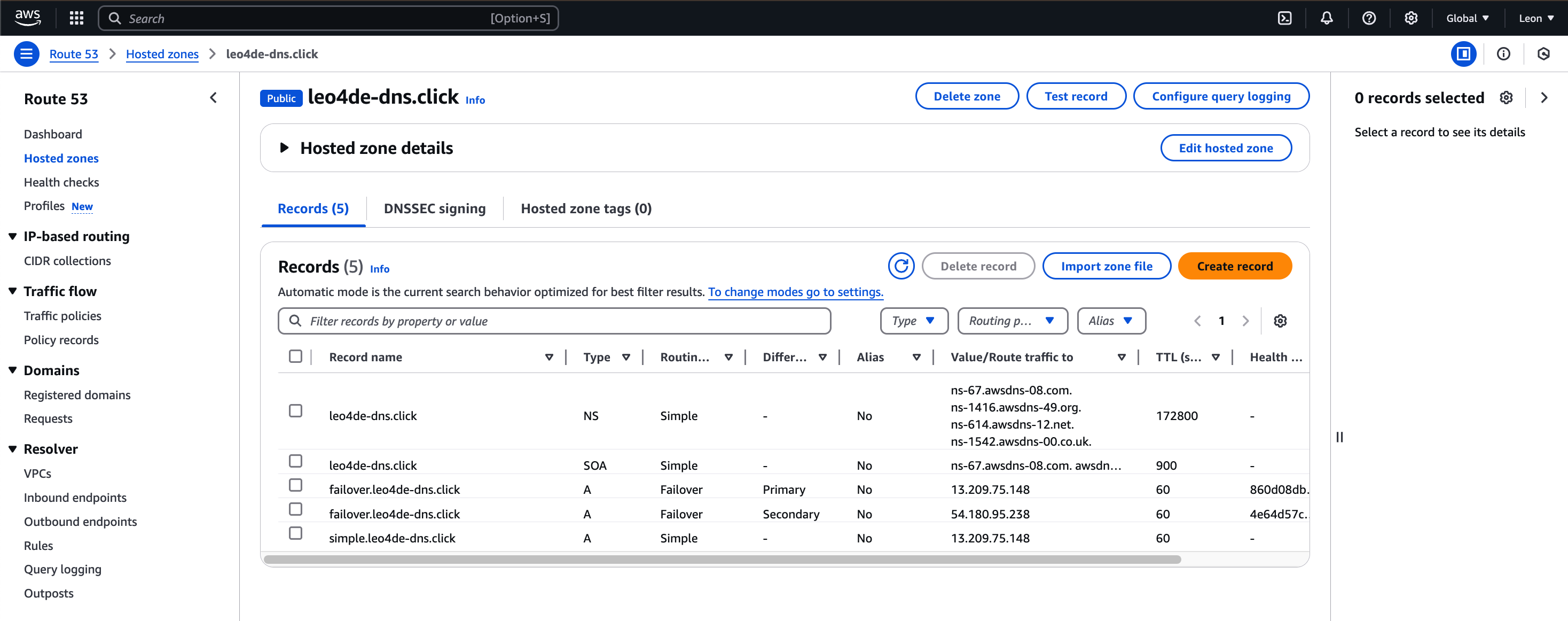
Create Record 설정Route 53 > Hosted zones > my_dns_link 에 들어가서create recrod 버튼을 클릭한다.create 설정 화면\_weighted 8subdomain을 weighted 라고 하자.value는 첫 번째 1번 서버
10.[AWS] Geo 실습
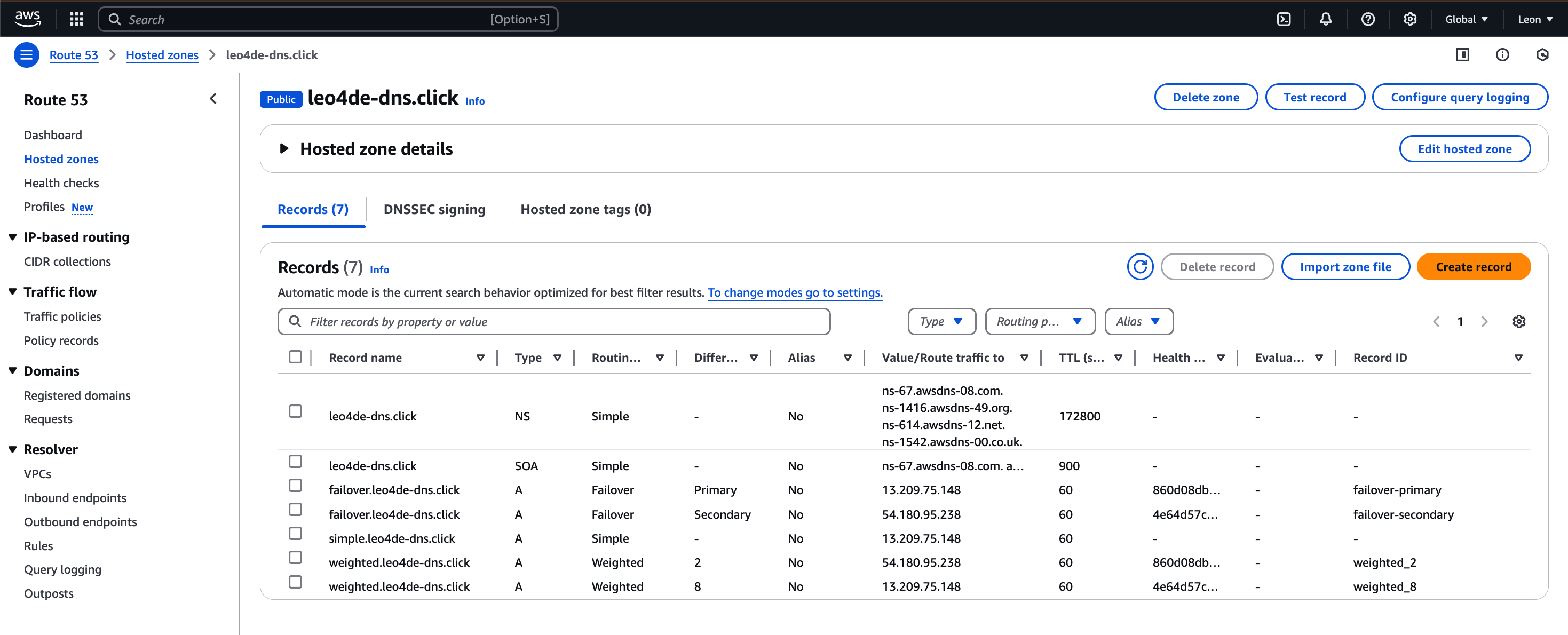
실습 전 서버 환경 확인좌측 상단이 1번 서버 (13.209.75.148),좌측 하단이 2번 서버 (54.180.95.238)이 두 서버를 사용해 줄 것이다.이번 실습에서는 Health Check를 하지 않을 것이다.create recordRoute 53 > Hoste
11.[AWS] Netwrok LoadBalancer로 부하 분산 실습
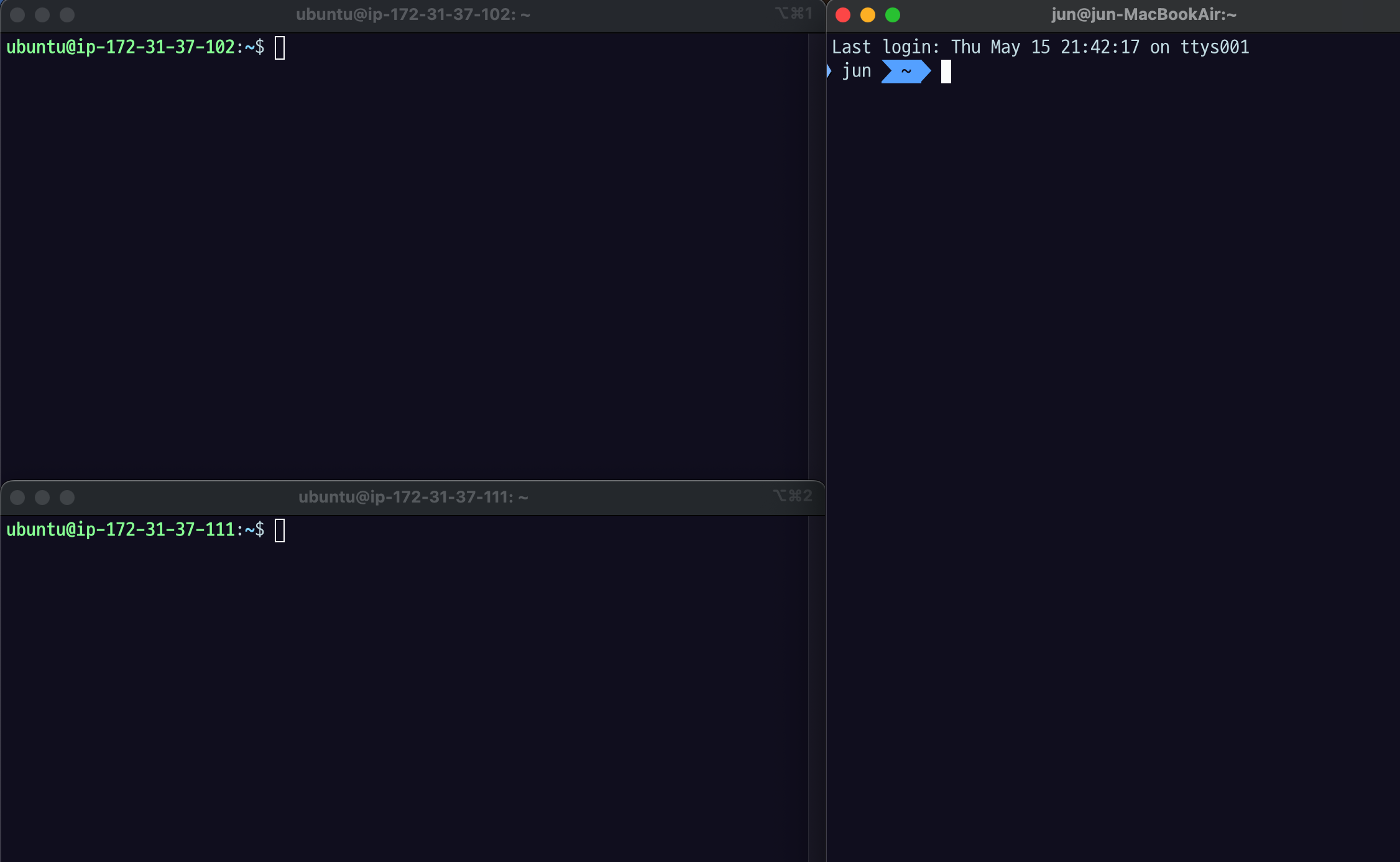
EC2 인스턴스를 두개 준비한다.왼쪽 위 1번서버 (54.180.80.57)왼쪽 아래 2번서버 (52.79.38.87)실습 하기 전에 꼭 Security Group > Inbound Rules 들어가서해당 포트 번호를 추가해주어야 한다.우리는 EC2 인스턴스를 연결할
12.[AWS] Application LoadBalancer로 부하 분산 실습
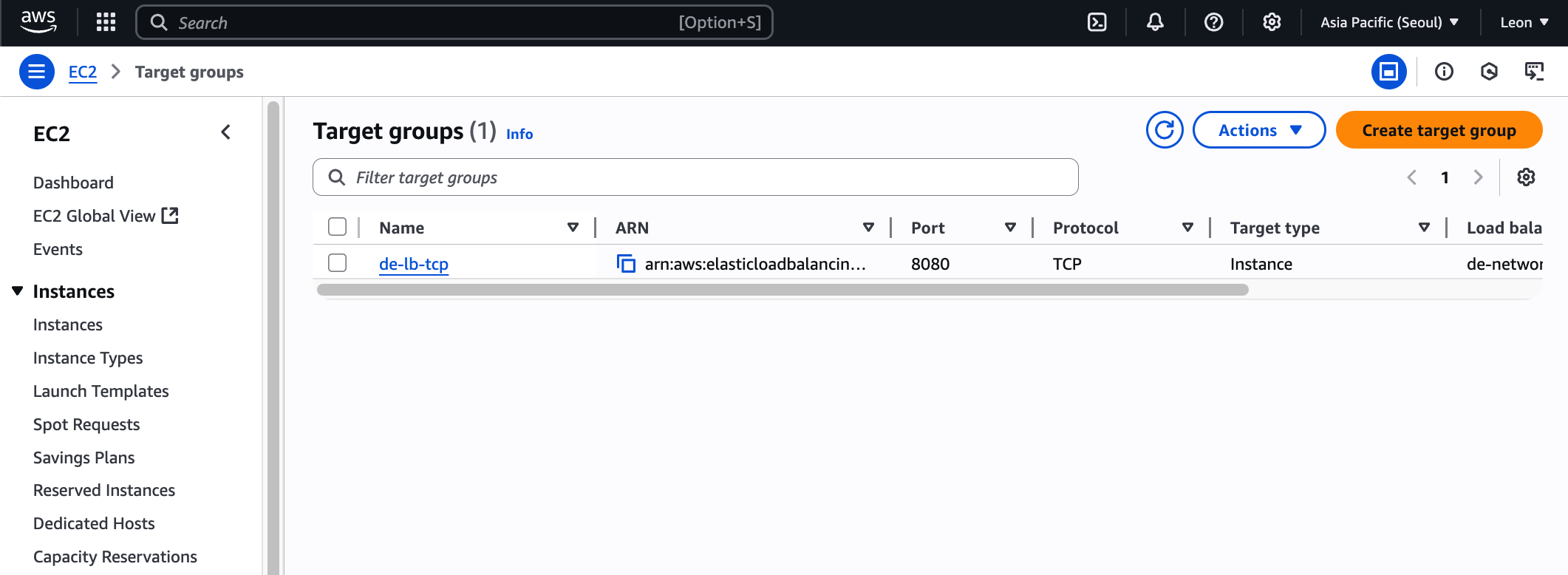
rootInterval 서비스에선 30초 권장next 클릭1번 서버만 include, 바로 create target group 클릭.똑같은 방법으로 하나 더 만든다.2번 서버만 include, create target group 클릭.둘 다 만들어진 모습.EC2 > L
13.[AWS] NGINX 세팅
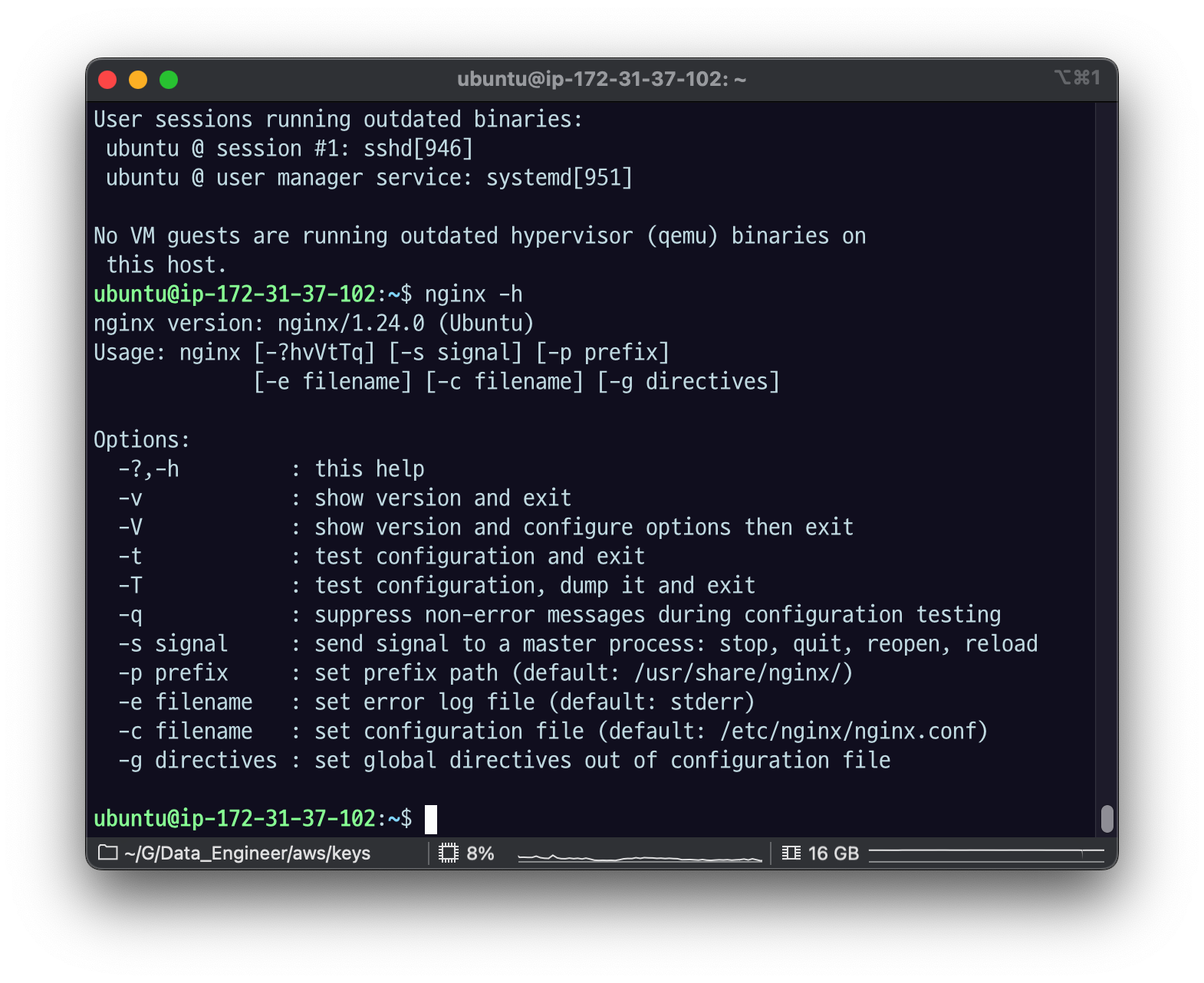
nginx/1.24.0 버전다음과 같은 에러 메세지가 나온다면, 해당 포트(default 80)을 사용중이다다음 명령어로 포트를 어떤 프로세스가 사용하고 있는지 확인한다sudo ss -tulpn | grep LISTEN이런 식으로 PID로 죽여도 되지만nginx를 활용
14.[AWS] location path별로 요청을 나누기 실습
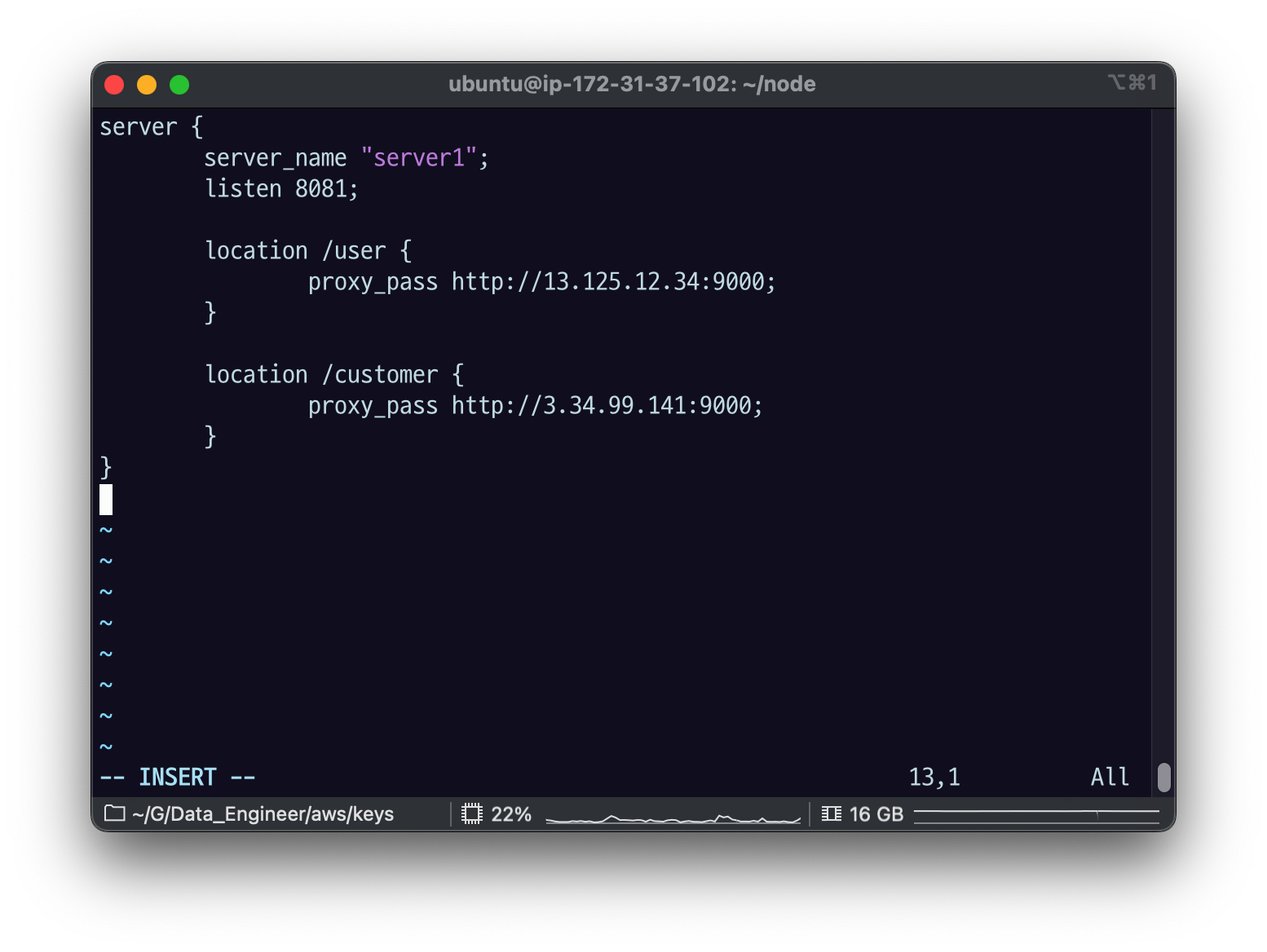
sudo vi proxy-path.conf엔진 엑스는 우리가 이제 뒤에서 배 우겠지만 시스템 레벨로 관리를 하거든요 그래서 보통은 루트 레벨 권한을 가지고 가진 유저가 이 읽기 쓰기 권한을 가지고 실제 다른 따 따따 유저나 다른 유저들은 읽는 권한만 읽는 것들이 보통입
15.[AWS] 정적 파일 서빙 실습
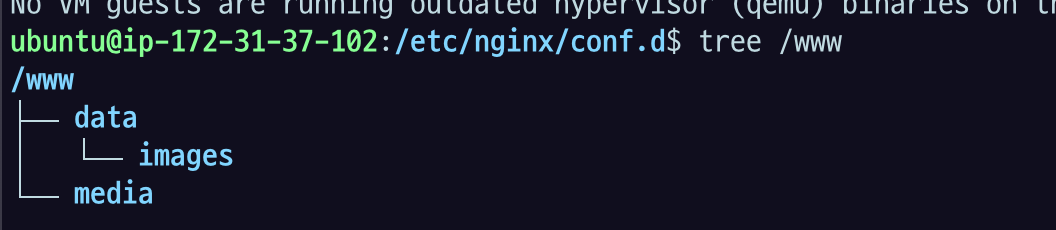
/etc/nginx/conf.d 에서 listen 8082 : 실습별로 포트 안 겹치게 하려고 임의 포트 지정. 비어있는 거 쓰면 됨.root : 이 server 블록 안에서 기본으로 볼 디렉토리 루트 패스를 의미어떤 파일의 경로가 왔을 때 www/data 부터 똑같은
16.[AWS] nginx - Load Balancing

/etc/nginx/conf.d 에서sudo vi loadbalancing.confupstream이라는 키워드로 서버의 묶음, 서버의 그룹을 지정해야함.upstream은 protocol 블록 하위에, 그리고 server 블록이랑 같을 레벨로 선언을 해 줘야 함.serv
17.[AWS] nginx - Health Check 로 자동으로 서비스 제외하기
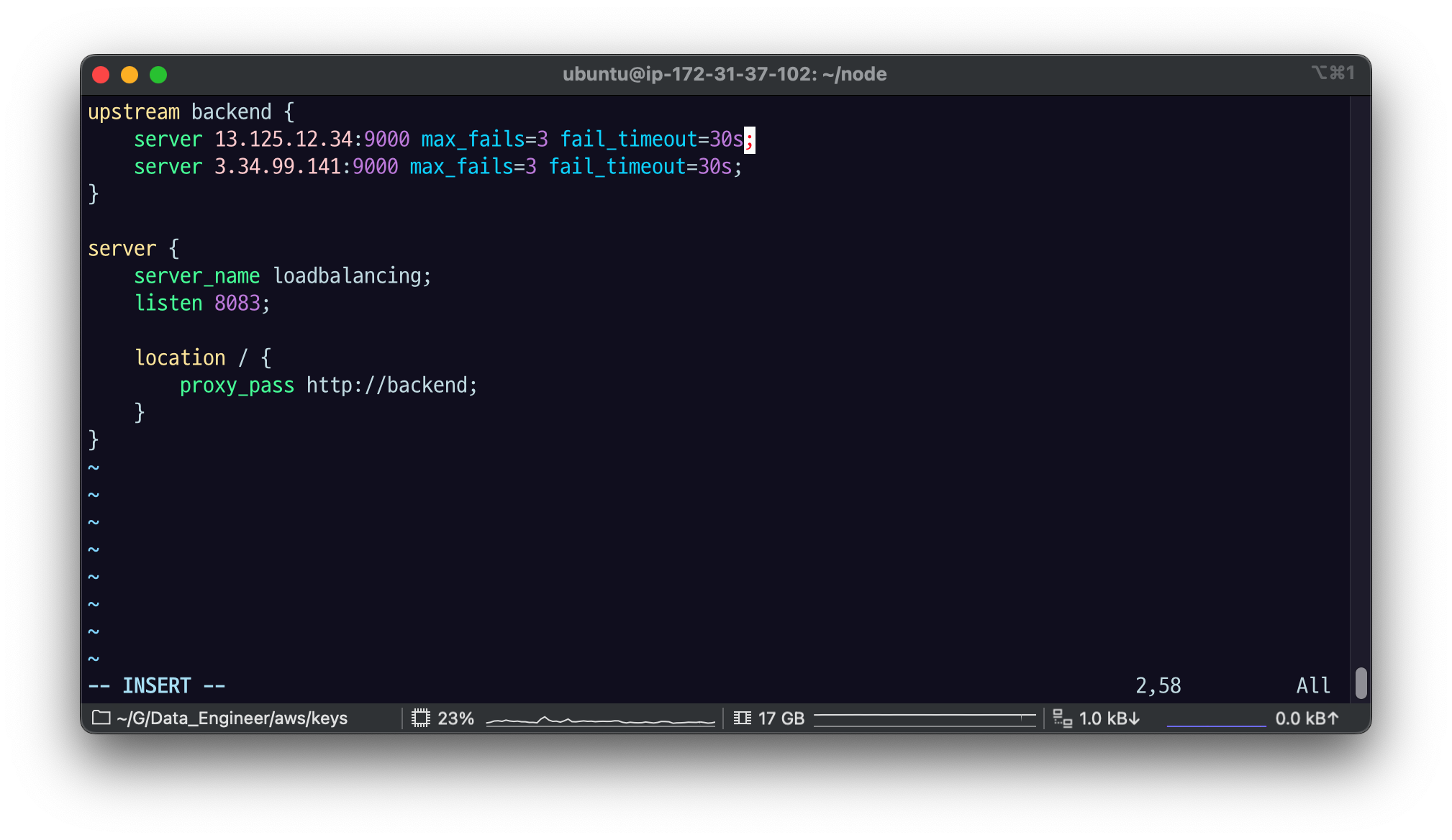
health_check 설정으로, 기준을 충족하지 못하는 서버는 자동으로 upstream 그룹에서 제외할 수 있다.wq 저장하고sudo nginx -s reload번갈아가면서 1번서버,2번서버 요청이 감.1번 서버를 죽여보자요청이 전부 2번 서버로 가는 것을 알 수 있
18.[AWS] nginx - SSL 인증서 인증하기
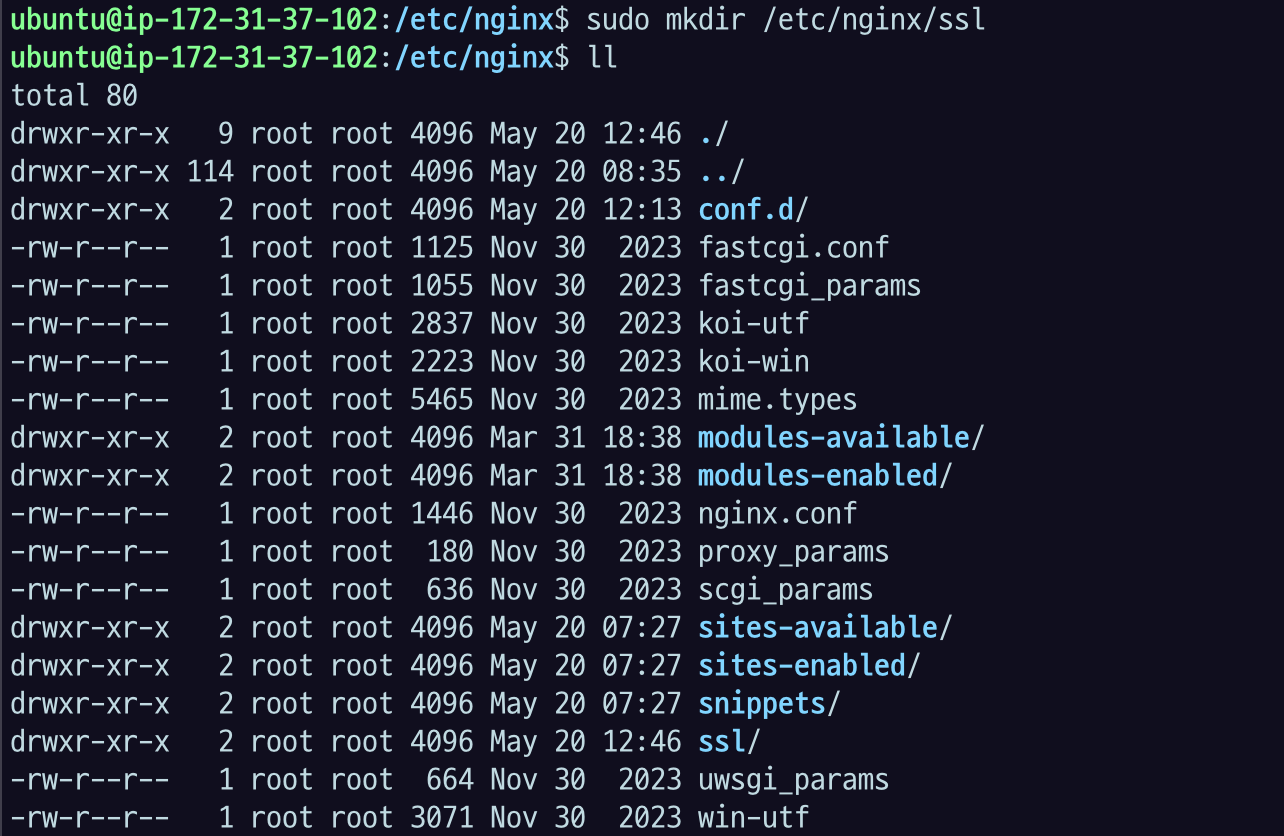
어플리케이션 서버에서 SSL로딩하지 않고 Nginx에서 대신해준다고 해서 Offloading 이라는 용어로도 쓰고 SSL termination이라고 쓰기도 한다.HTTPS 등 SSL 인증 요청이 들어왔을때, nginx 에서 인증서로 인증을 하고, proxy 하는 서버로
19.[AWS] nginx - Header 변경하기
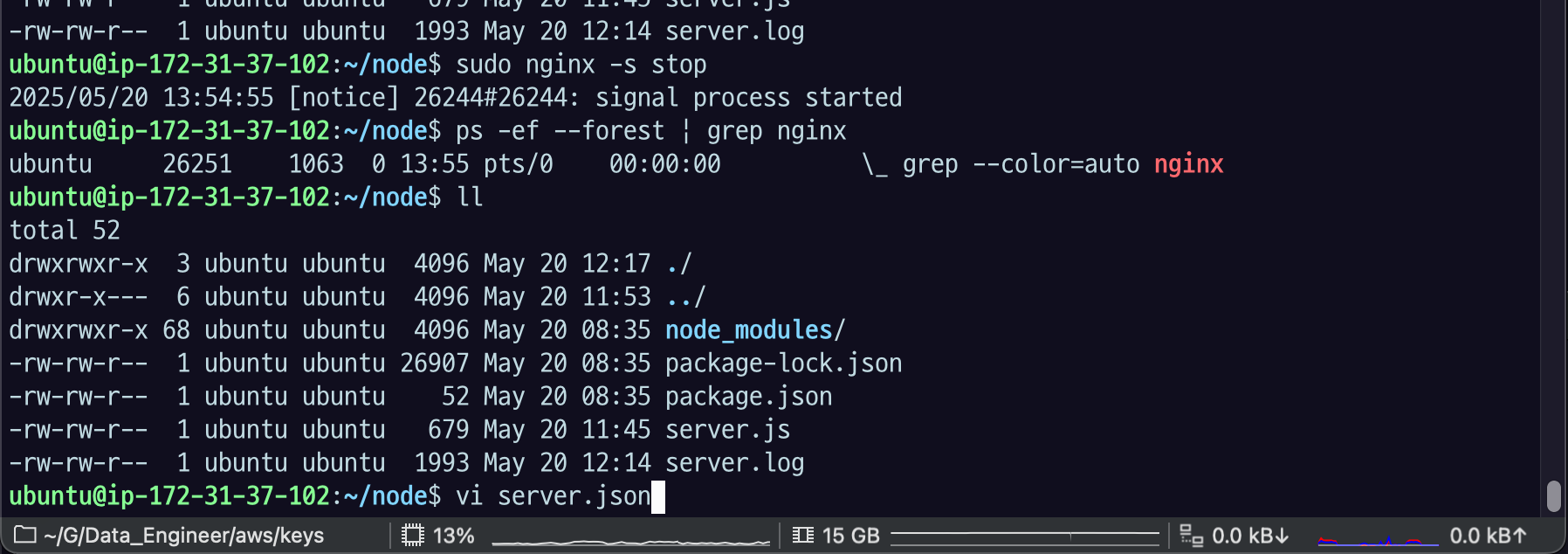
NGINX에서 header의 내용을 해석할 수 있다. proxy 에게 header 정보를 변경하거나 그대로 보낼 수도, client에게 response로 header를 추가할 수 있다.바디 - 어플리케이션 해석헤더 내용을 해석해 여러가지 동작 할 수 있음. 특히 캐시같
20.[AWS] nginx - logrotate를 사용한 점유율 관리
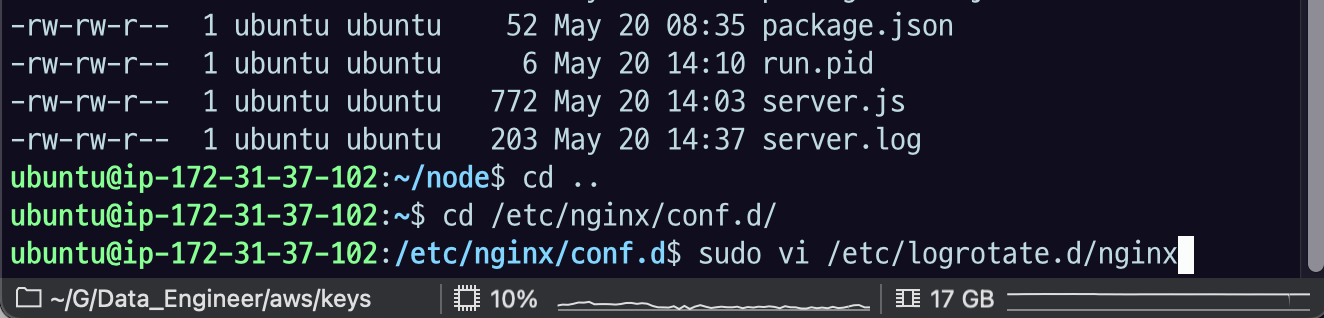
21.[AWS] nginx - systemctl로 nginx service 등록하기 & 죽지 않는 프로세스 만들기
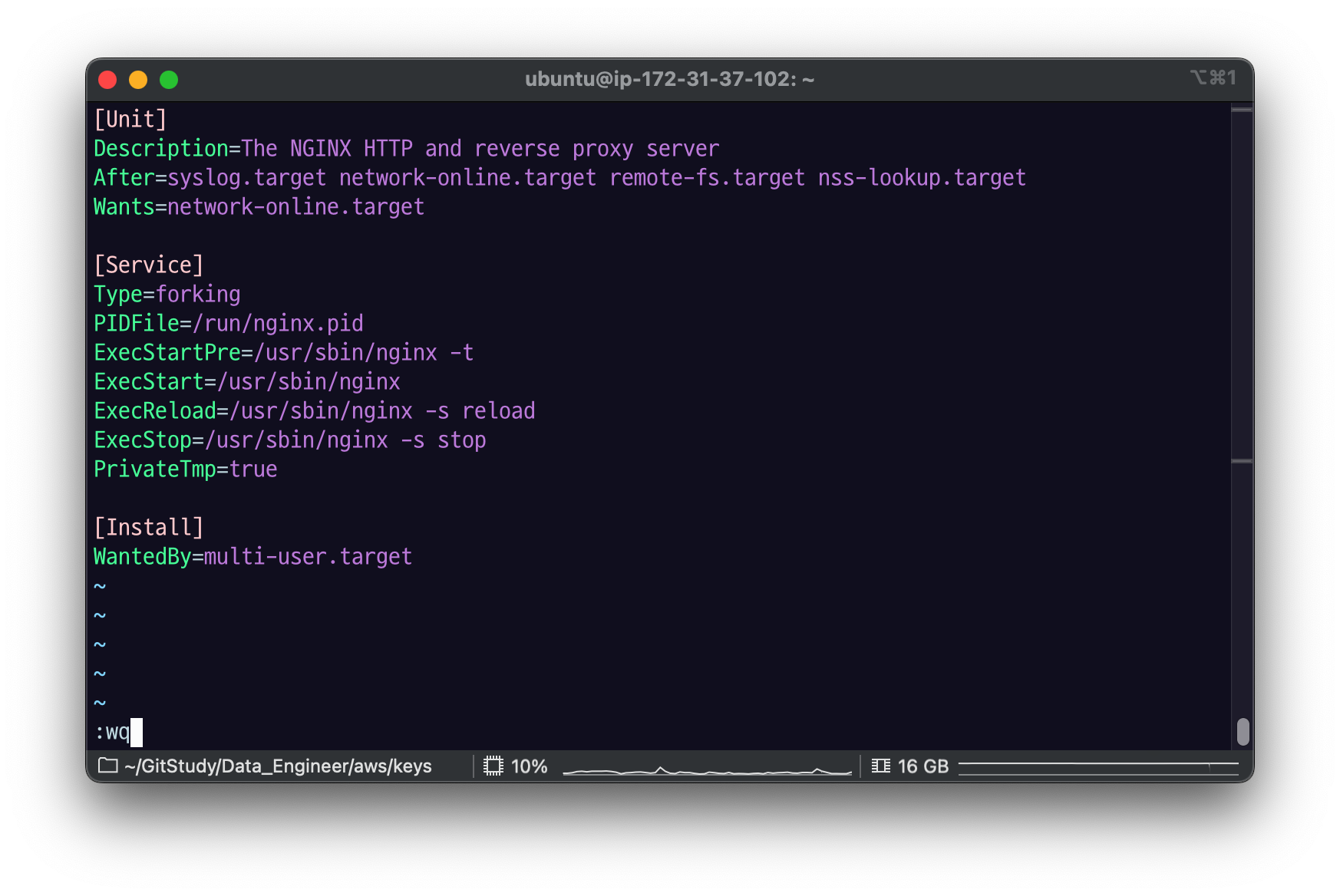
systemctl로 nginx service 등록해보자.service 설정 파일등록ExecStartPre : /usr/sbin/nginx -t, validation 해서 테스트 먼저 하기ExecStart : /usr/sbin/nginx, 시작ExecReload : /u
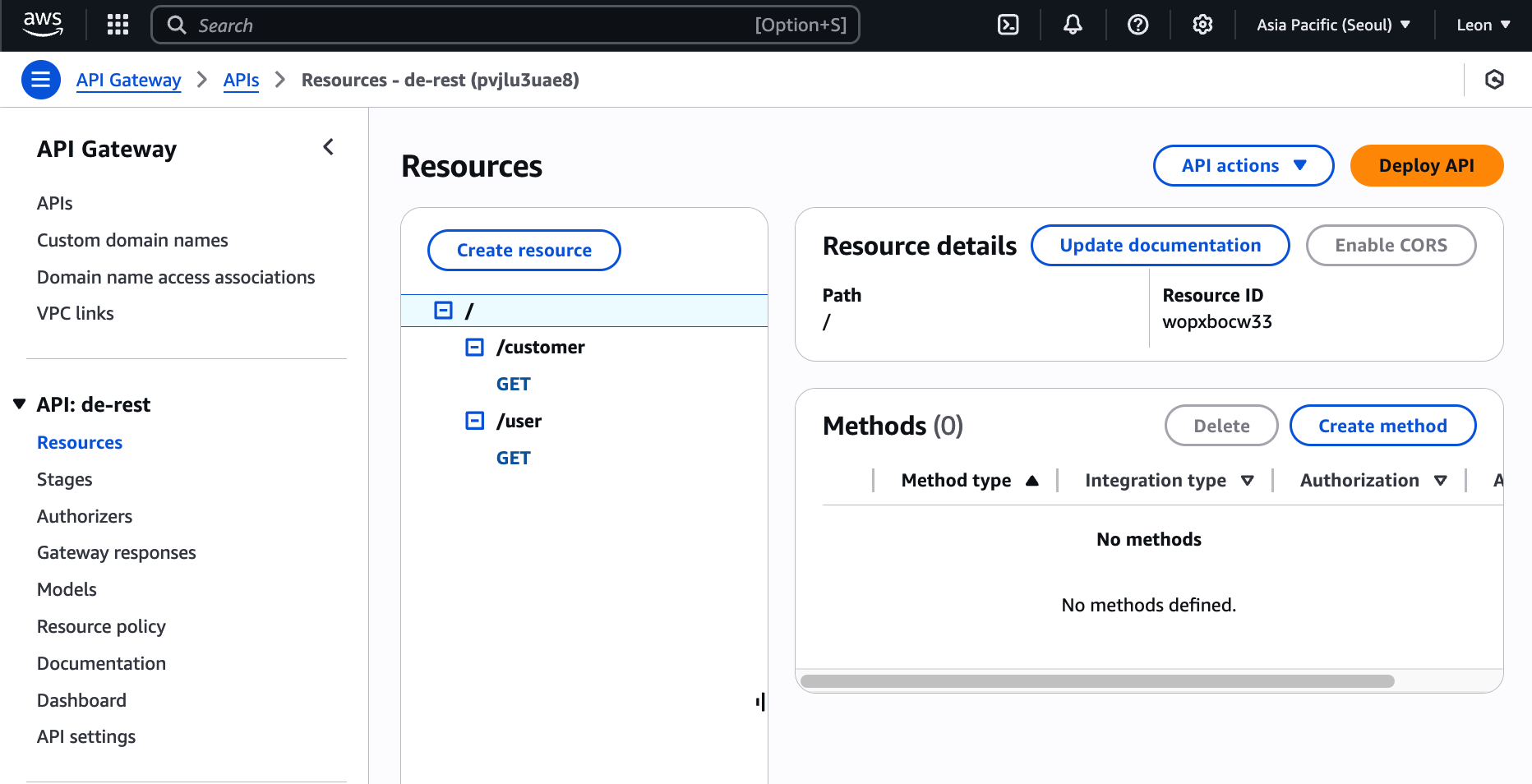
22.[AWS] AWS API Gateway 실습
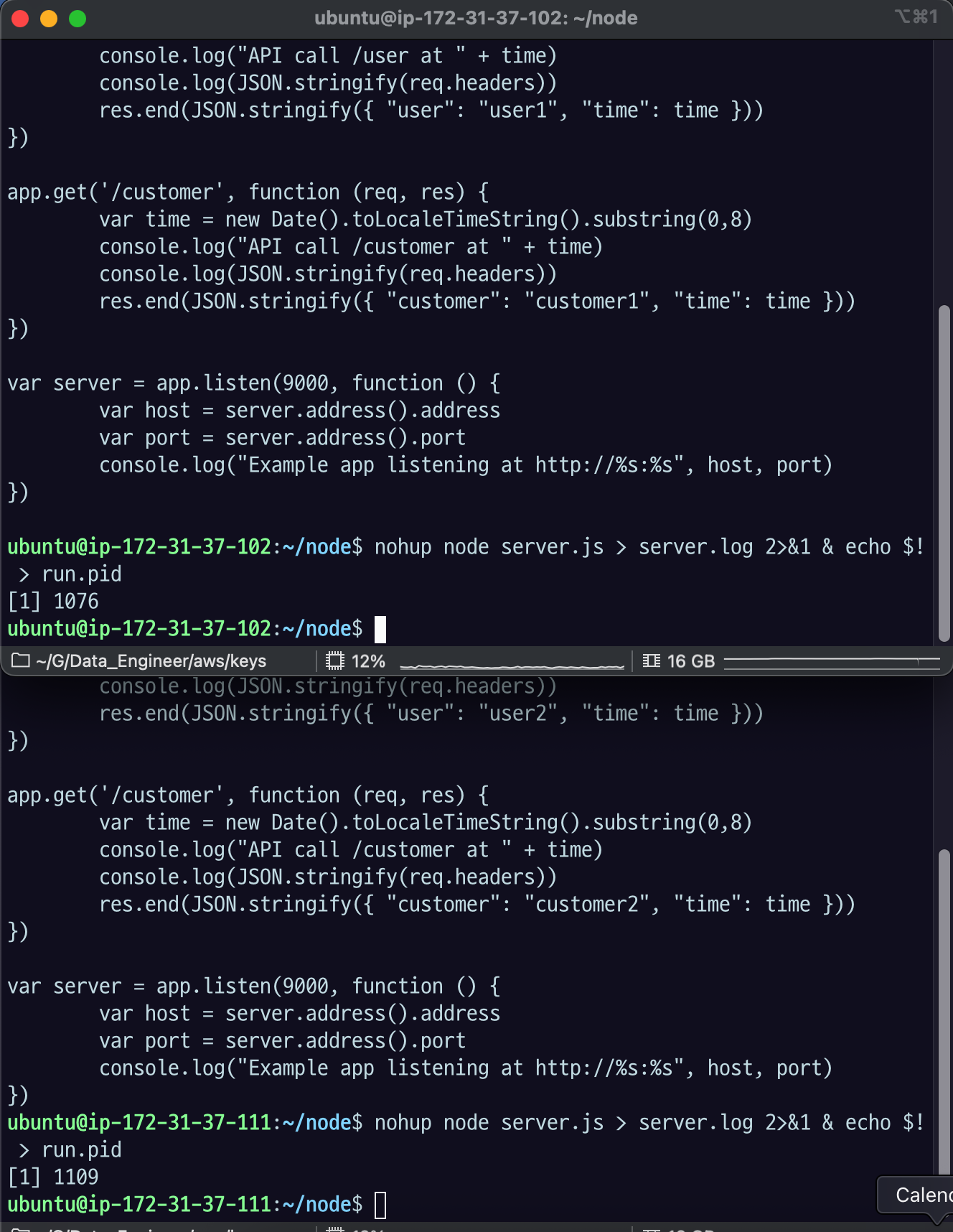
04-C07 웹서버로 콘텐츠 구분해서 서빙하기 > 2.3 실습 세팅 과 같이 두대의 EC2 서버에/user , /customer 를 서빙하는 application을 띄운다. 포트번호는 기본(9000).cd ~/nodehttps://console.aws.amaz
23.[AWS] Stage 실습
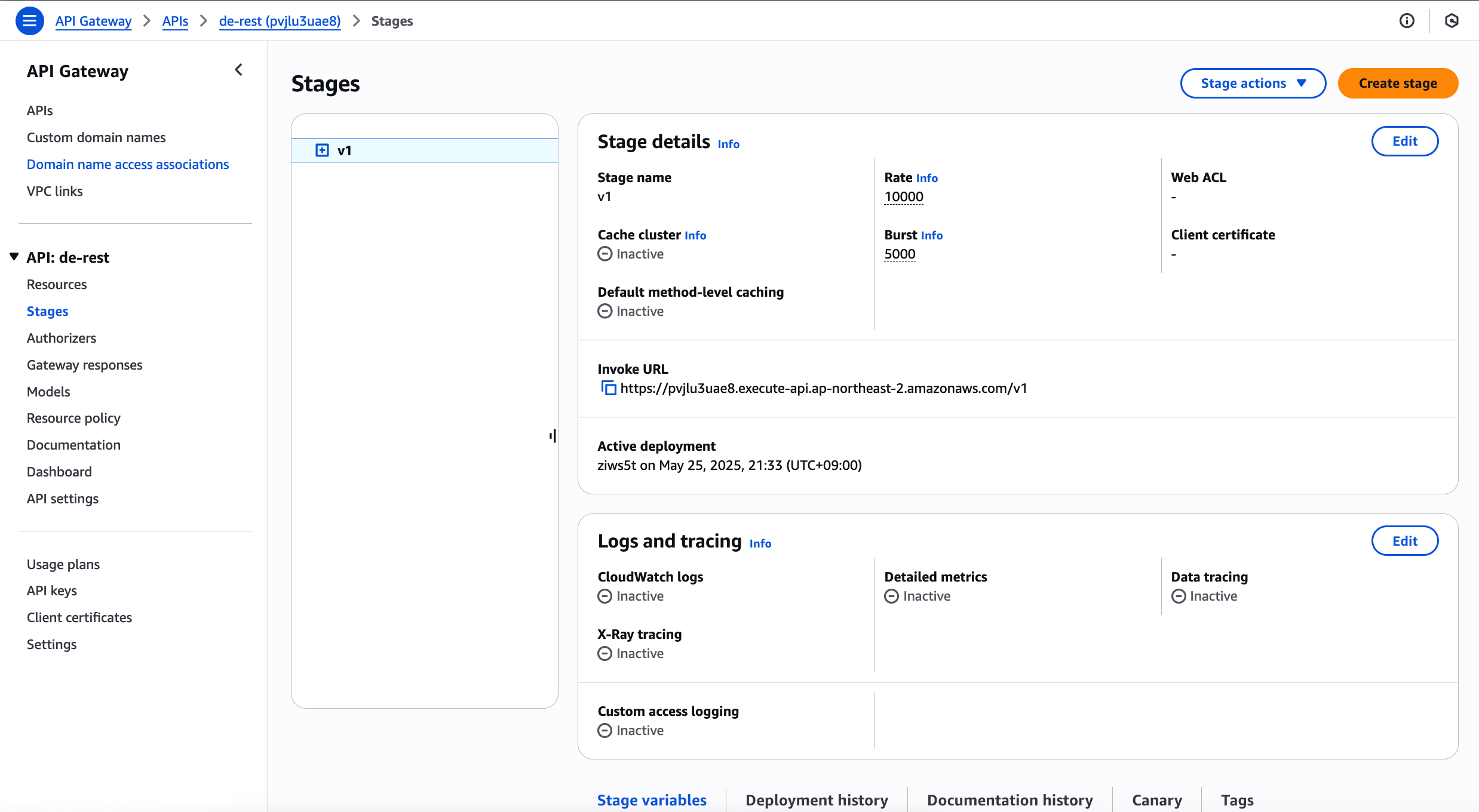
stage 는 같은 API 설정에 대해서 환경을 구분할 때 또는 버전을 구분할 때 쓴다스테이지에서 내가 생성한 API Gateway 선택하고Stages에 들어가서 Create stage 클릭Stage name : v2Deployment : 이걸 생성한다는 것은 Depl
24.[AWS] Stage Variable 활용
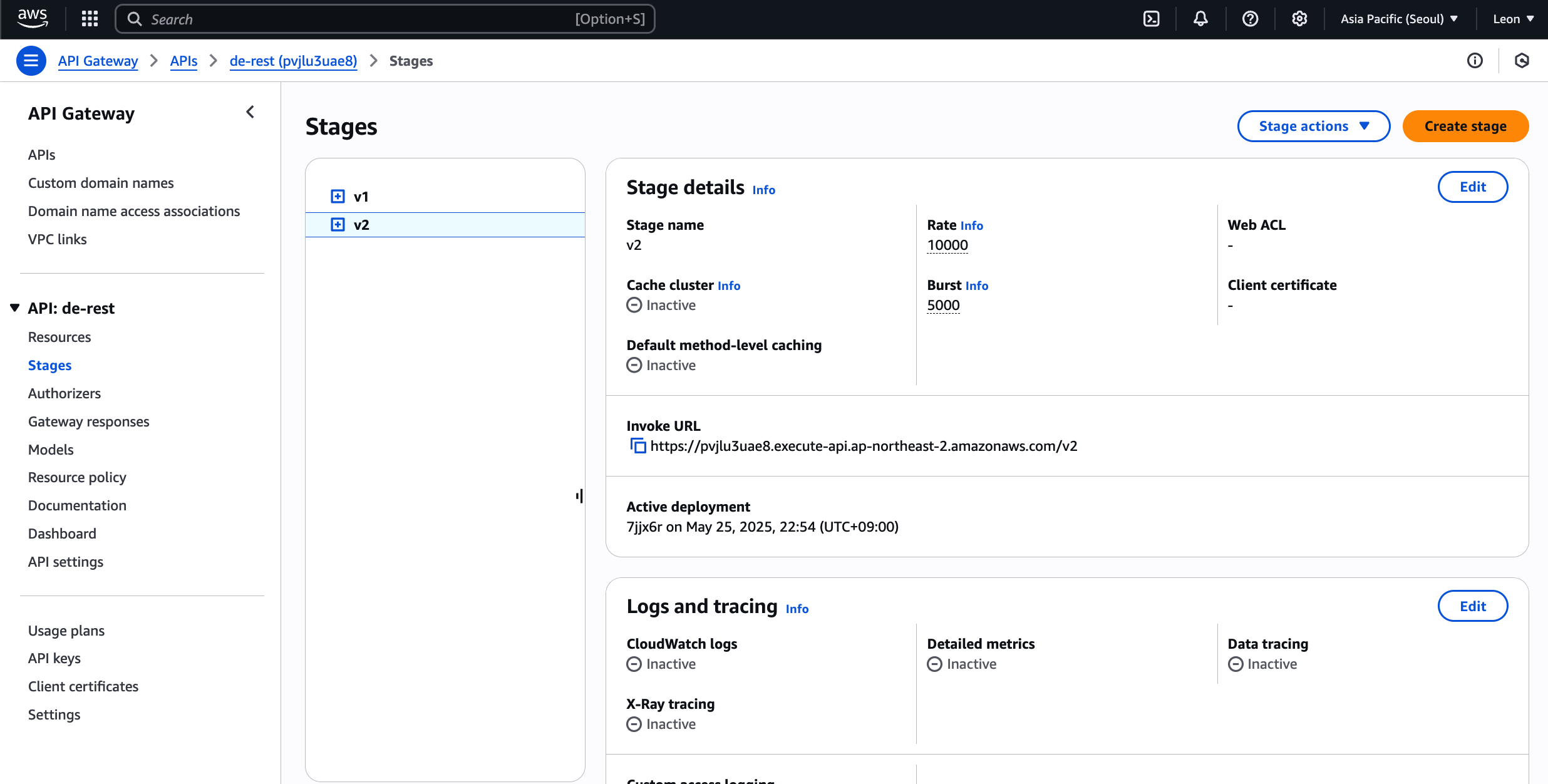
Stage 변수를 지정하고, 변수를 URI, header 등의 값으로 활용할 수 있다.Stage Variable활용처 : Stage Variable 활용처: doc미리 만들어 둔 v2의 Stage variables 메뉴에 Stage Variable 을 추가해보자.Man
25.[AWS] Stage Variable 활용
1버전을 2버전으로 다 대체한다 이런 걸 블루그린이라고 하는데AB 테스트를 할 수도 있고 아니면 여기 설정을 바꿨는데 이게 실제로 잘 동작하는지 확신이 없거나 아니면일부 지표를 미리 봐야 되는 경우에 카나리 Deploy를 쓴다.카나리 디플로이는 전체 트레픽의 일부만 카
26.[AWS] Fluentd 설치

https://docs.fluentd.org/installation/before-install여기 나온대로 설치를 해보자Increase the maximum number of file descriptors. You can check the existing co
27.[AWS] 실습용 log generator 설치 & Log 생성

Log Generator 설치이건 AMD64 아키텍쳐 맞춰 만든 거니까 ARM이면 바꿔야 함tar로 압축 해제하면 저런 파일들이 만들어지고flog\* 라는 실행파일이 생겼음$filename 을 원하는 값으로\-s 옵션으로 시간간격이 다른 여러 로그를 한번에 생성할 수
28.[AWS] Opensearch 설치
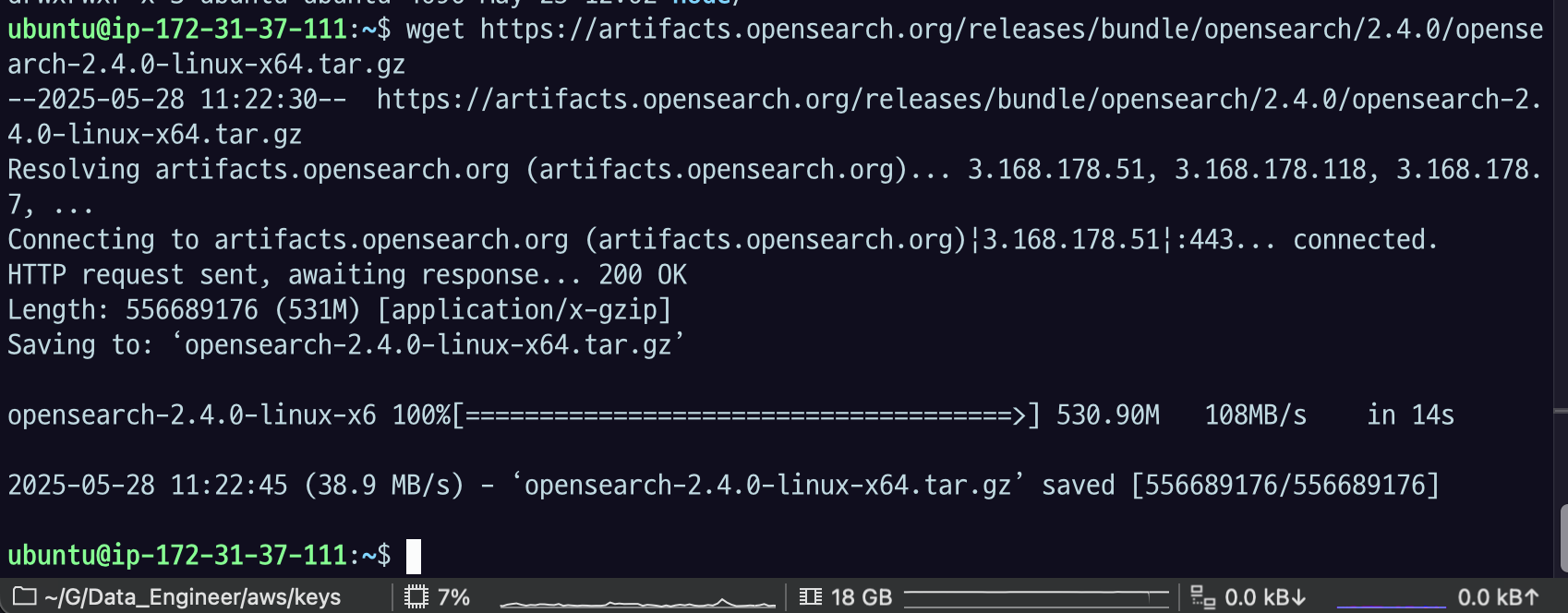
1번 서버에서는 로그를 보내고2번 서버에서는 로그를 받는데2번 서버의 설정이다.강의에서는 opensearch, opendashboard - 2.4.0 버전을 사용한다.이 강의에서는 기본적인 설치만 다룬다. 더 자세한 설치와 설정 방법은 매뉴얼을 참고.기본설치는 다음
29.[AWS] Open Dashboard(Kibana)설치
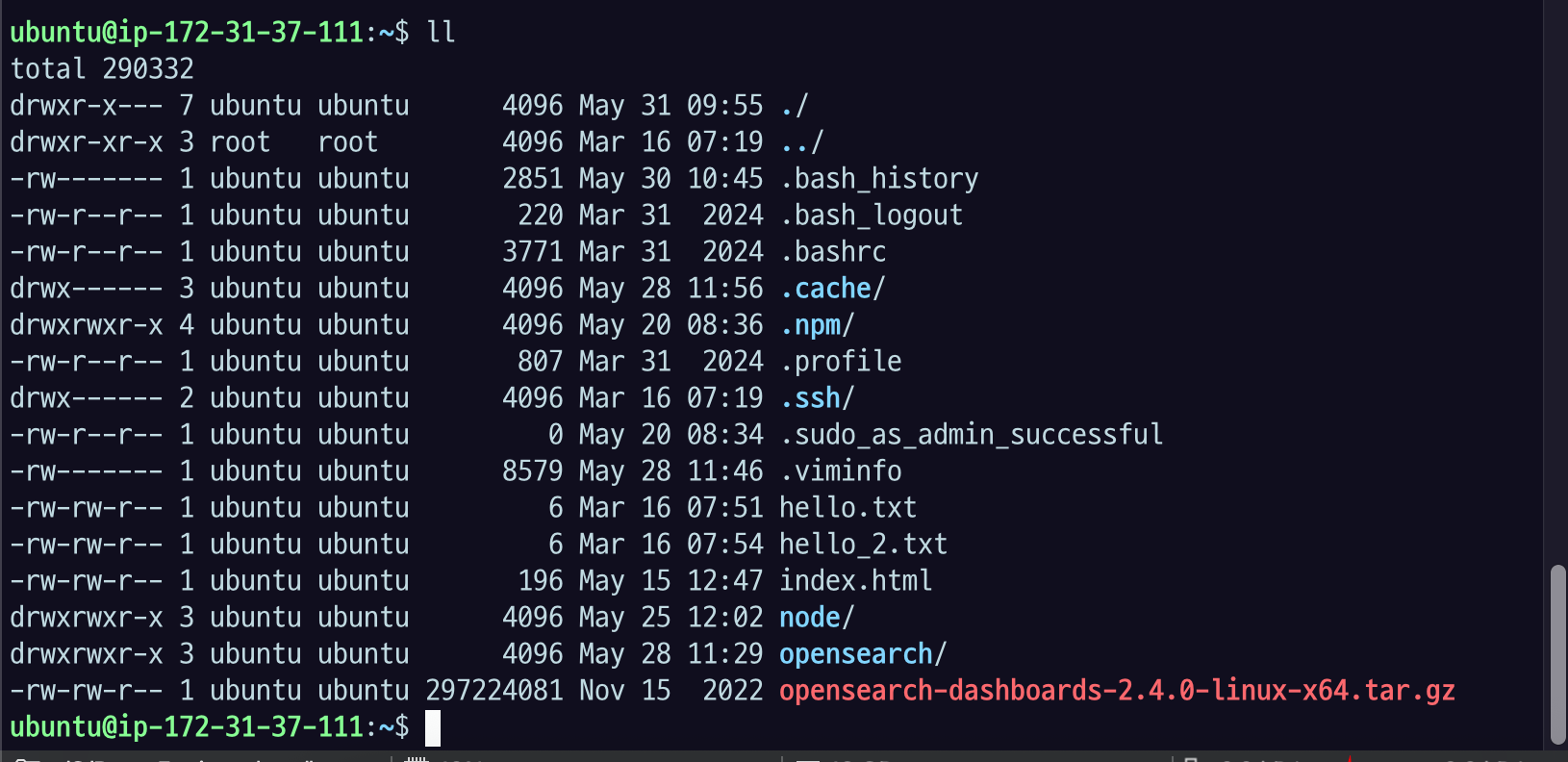
2번 서버, Elasicsearch 설치한 서버랑 같은 서버에 설치를 할 것./opensearch 디렉토리 들어가서 wget으로 다운을 받는다.설치가 완료되면 opensearch-dashboards-2.4.0-linux-x64.tar.gz 가 생길 것압축을 풀어주자op
30.[AWS] Open Dashboard 에서 인덱스 패턴 생성하기
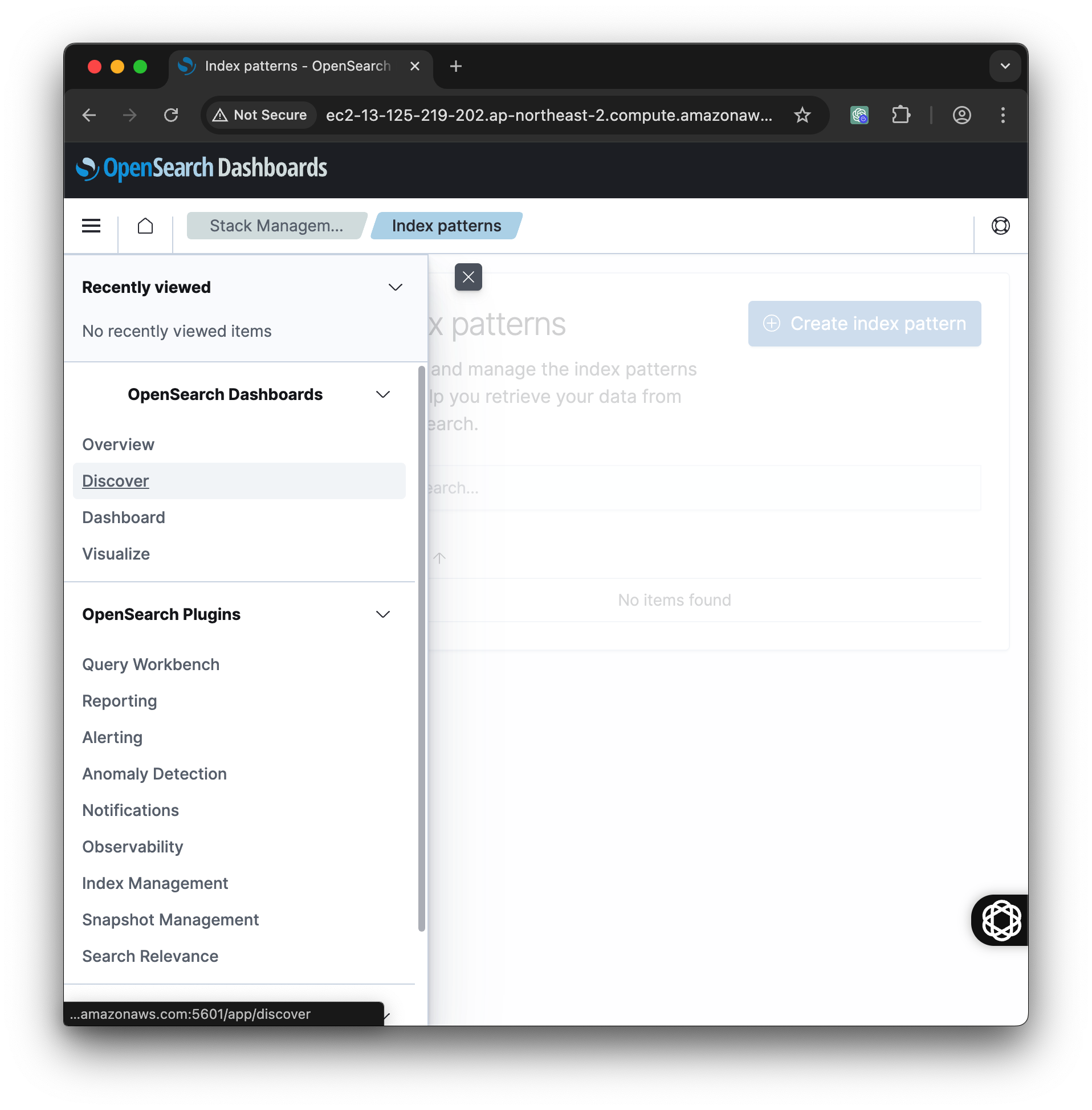
앞에 과정에서 fluentd 로 로그 파일을 읽어서 보내기를 했거나 이미 데이터를 넣은 사람들은 데이터가 들어가 있을 것. 데이터가 없으면 이 과정은 할 수 없다.가장 많이 활용하는 게 Discover 화면인데 데이터가 없어서 안되는 중.왼쪽 메뉴바 맨 아래 Manag
31.[AWS] Open Dashboard Visualize 사용하기
아까 Discover에서는 Timeline을 기준으로 봤는데 그것 말고도 여러 가지로 화면을 만들 수 있는 기능이다.Create new visualization 클릭Pie 로 실습을 해보자.json-timelog-\* 클릭이렇게 나온다.Aggregation 기준은 Co
32.[AWS] Amazon RDS Proxy 란?
Amazon RDS Proxy는 RDS (관계형 데이터베이스 서비스) 앞단에 위치하는 완전관리형 데이터베이스 연결 풀링 서비스이다.애플리케이션과 RDS 데이터베이스 사이에 중간 계층(Proxy Layer)을 두어, 데이터베이스 연결을 효율적으로 관리하고 성능, 가용성,
33.[aws] Prometheus 다운로드 및 설치
프로메테우슨느 파일을 저장하기 때문에 스토리지 용량을 추가하는 것을 권장한다.공식 매뉴얼https://github.com/prometheus/prometheus/releases/download/v2.40.6/prometheus-2.40.6.linux-amd64
34.[AWS] Grafana 설치하기
프로메테우스를 이용해서 다양한 매트릭을 수집하고 어떻게 사용하는지 확인해보자.
35.[AWS] Grafana 대시보드 구성하기

Grafana에서 대시보드를 구성하기 위해서는 다음 과정을 거친다. 매뉴얼1\. Datasource 추가하기2\. Create Dashboard3\. Create Panel in DashboardAlert 받기 위해서는 다음 과정이 필요하다. 매뉴얼이거는 이메일을 설정
36.[AWS] Node Exporter 로 Node Metric 노출 실습
Node Exporter 는 prometheus 그룹에서 만든 수직기다. prometheus 형식으로 적은 리소스로 다양한 metric을 뽑아내는 데 좋게 세팅되어 있다. 다운로드 링크(https://prometheus.io/download/버전 1.5.01.
37.[AWS] Node Monitoring Dashboard 구성하기
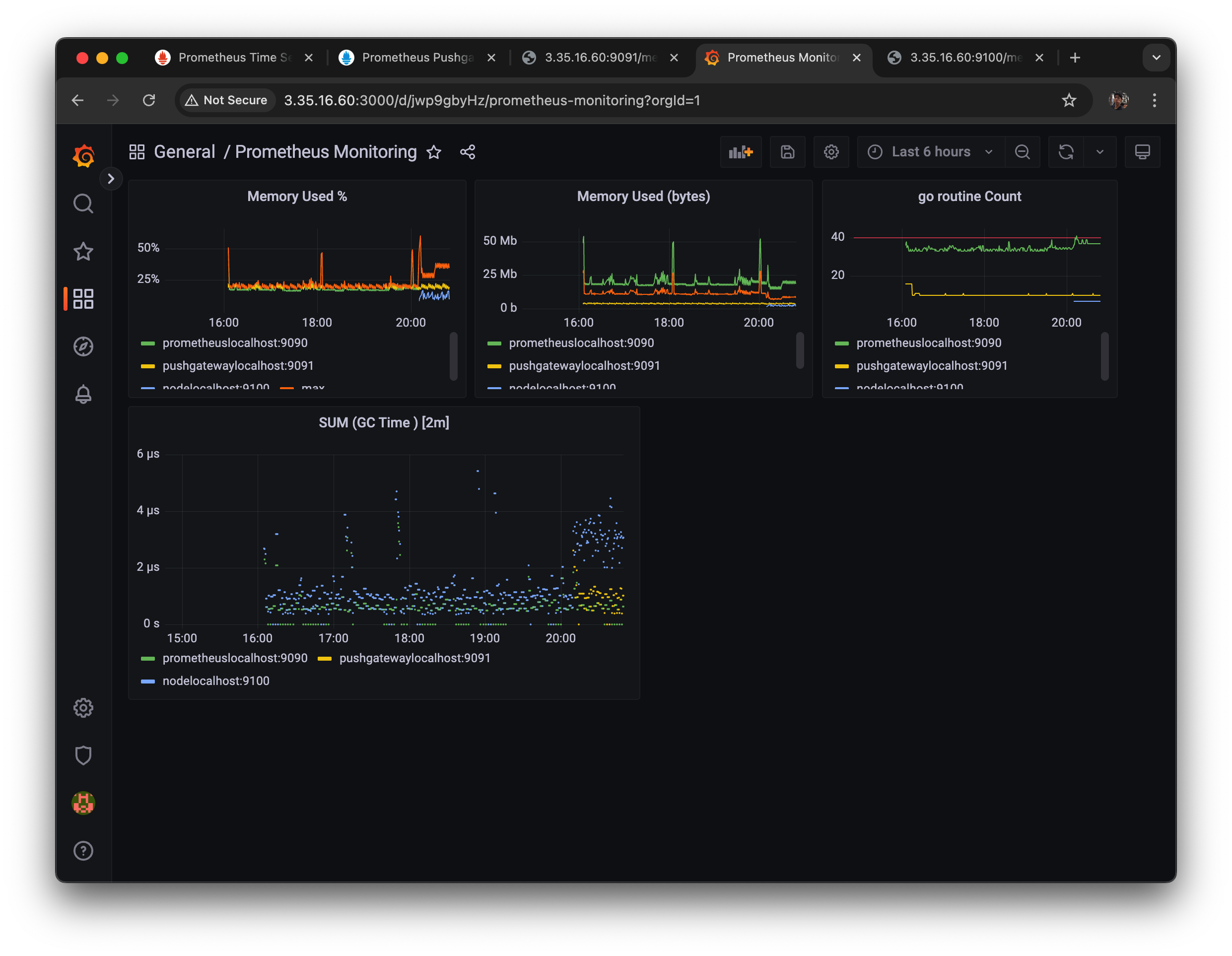
첫 번째로 grafana에서 대시보드가 어떻게 구성되는지를 알아야 함. 이 대시보드들의 전체 정보는 전부 JSON 형식으로 저장 되어 있다. 그리고 그 안에 있는 panel 정보도 다 JSON 형식으로 저장되어 있다.그리고 웹 브라우저는 그 json을 파싱해서 데이터소
38.[AWS] Application Monitoring 실습 세팅
Prometheus 에서는 각 언어별로 client library 를 제공한다. 링크Prometheus format 으로 노출할 수 있는 설정, 각 언어별로 기본 모니터링 시스템(java의 경우 JMX)을 이용해 메트릭 정보 추출, custom metric을 남기는 기
39.[AWS] Application Metric 대시보드 실습
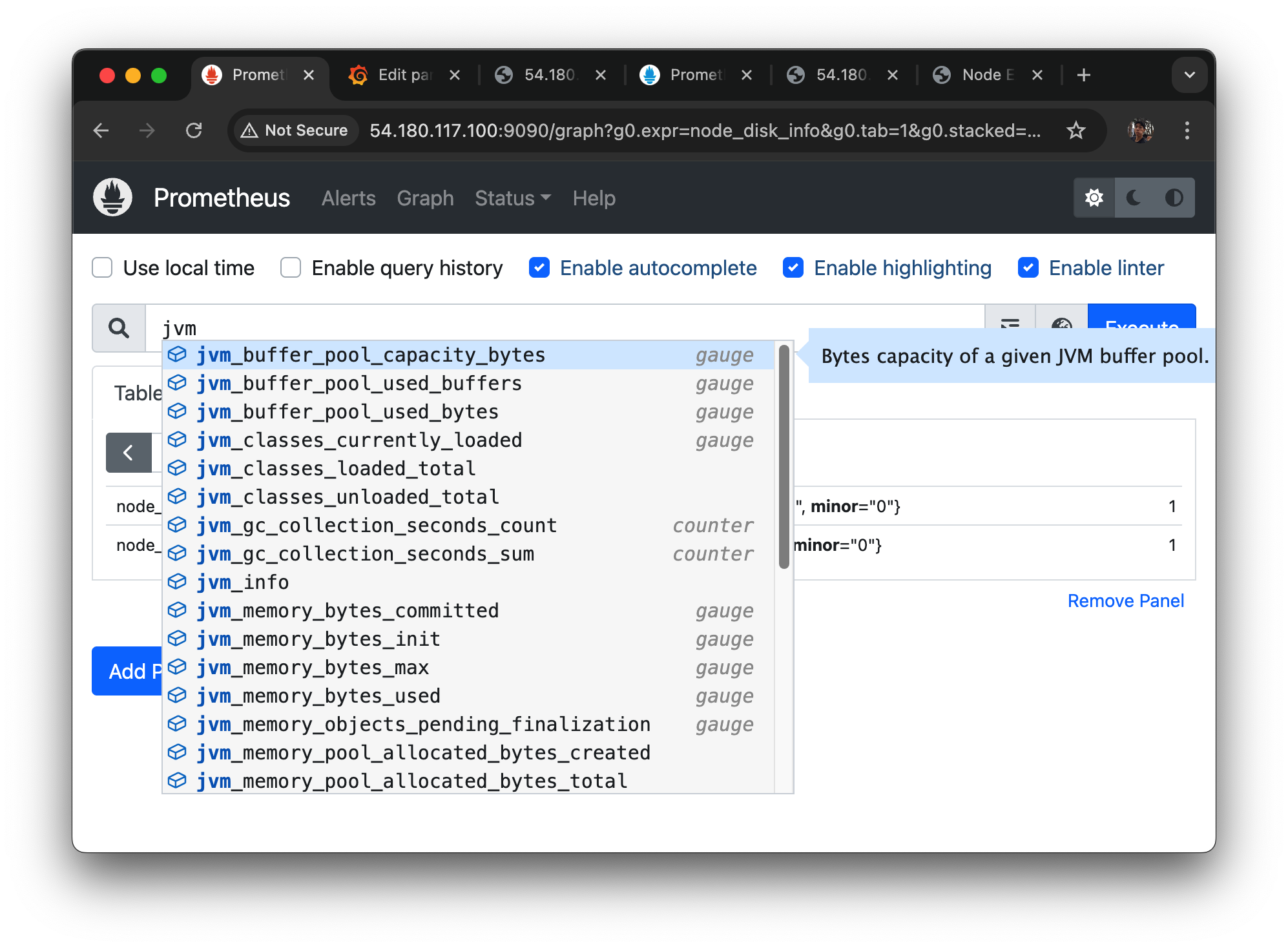
새 대시보드 만들기jvm 검색하면 나오는 매트릭들.이런 식으로 검색해서 job 별 매트릭들을 가져올 수 있다jvm_memory_bytes관련된 매트릭들을 검색해보았을 때 나오는 녀석들인데used가 heap, nonheap 있고max가 heap, nonheap 있고.ma
40.[AWS] Custom Metric 구현 실습
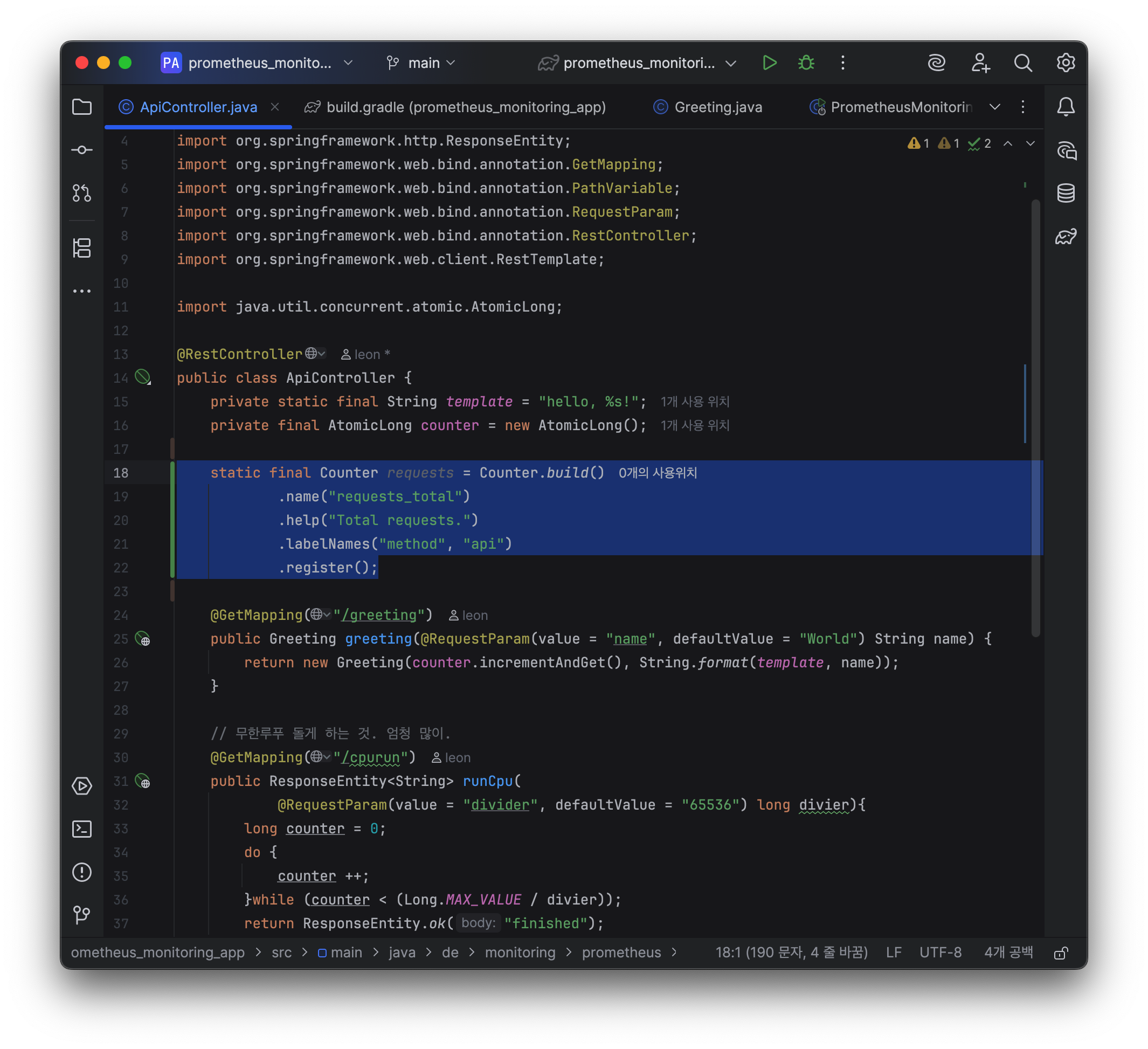
(자바의 경우)내가 원하는 매트릭 타입을 먼저 찾는다(counter, gauge, histogram, summary)매트릭 빌더 부르고name 설정하고help설정하고 (각 metric마다 label 있는 경우 labelNames를 파라미터 String의 멀티파라미터로,
41.[AWS] OpenSearch 동작 방식 실습
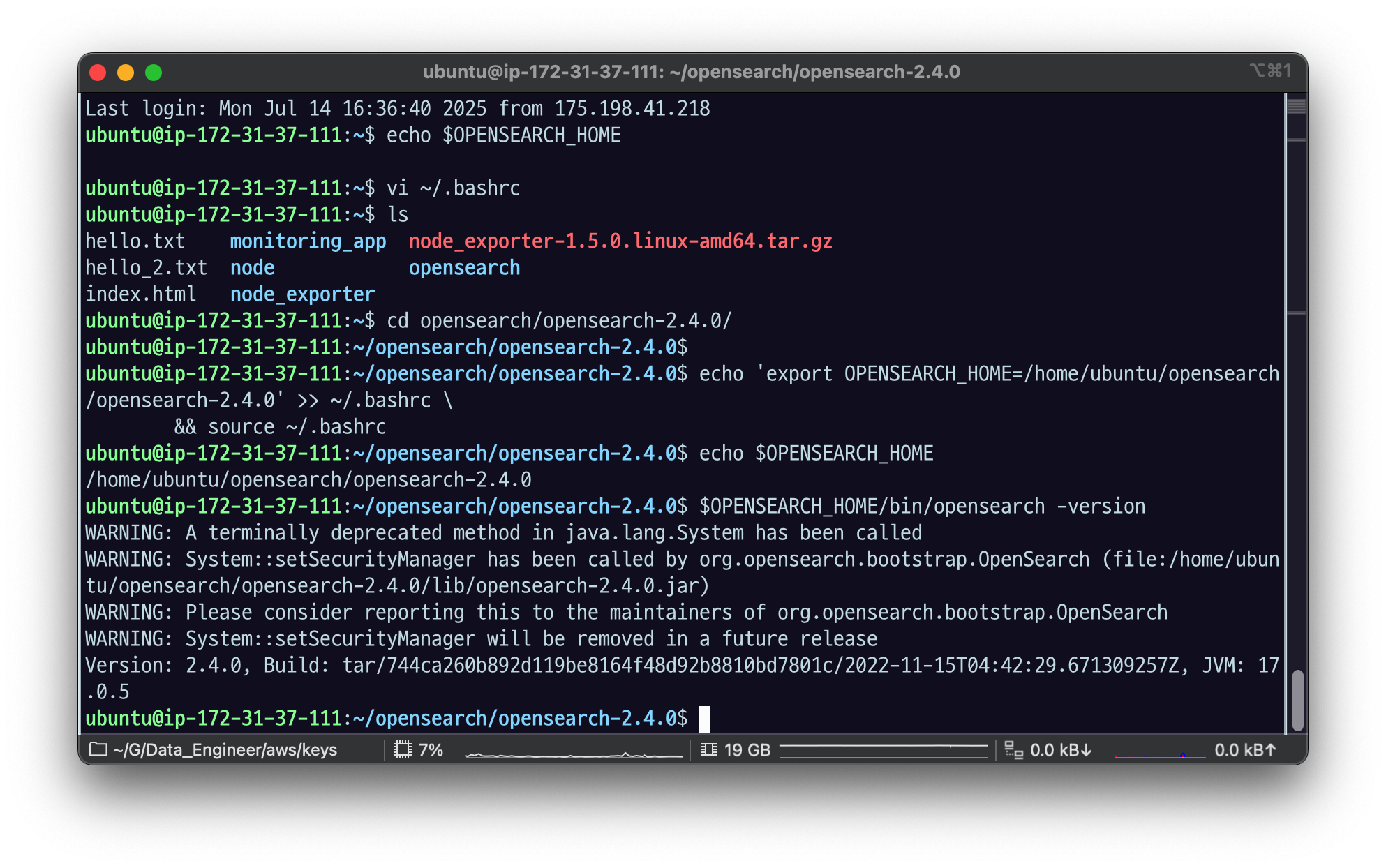
설치 확인systemctl 설정 안 해 놓았었나 보다.환경변수 설정13.209.26.28 : 오픈서치 깔린 컴터 주소웹에서 검색하면 이렇게 됨OpenSearch REST API를 사용하여 인덱스, 매핑, 도큐먼트를 직접 생성하고 삭제해보자.JSON 응답을 읽기 쉽도록
42.[AWS] OpenSearch의 텍스트 인덱싱과 전문 검색
챕터 1에서 OpenSearch의 기본적인 구성 요소와 CRUD에 대해 알아봤다. 챕터 2에서는 OpenSearch의 핵심이라고 볼 수 있는 인덱싱과 전문 검색에 대해 알아보려고 한다.앞서 OpenSearch는 필드의 매핑 타입에 따라 인덱싱하는 방법이 다르다고 설명했
43.[AWS] OpenSearch 텍스트 인덱싱 & 전문 검색 실습
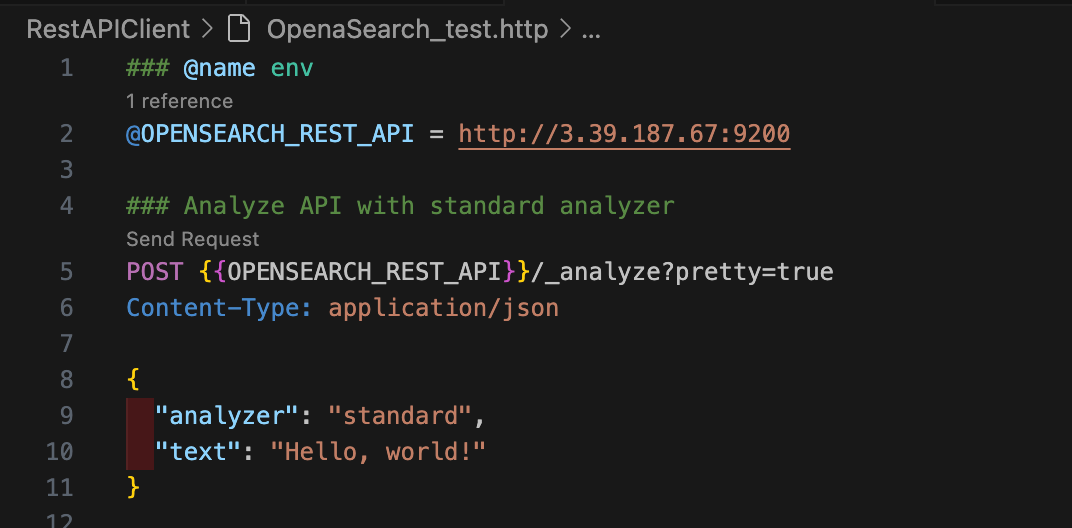
"Data Science is fun!"이라는 문장에서 "Science"라는 단어가 토큰으로 추출되었다면,그 위치 정보는 (5, 12)로 표현할 수 있다."Data Science is fun!" "Science"는 5번째 문자에서 시작해 12번째 문자에서 끝난다.
44.[AWS] OpenSearch 클러스터 구성 실습
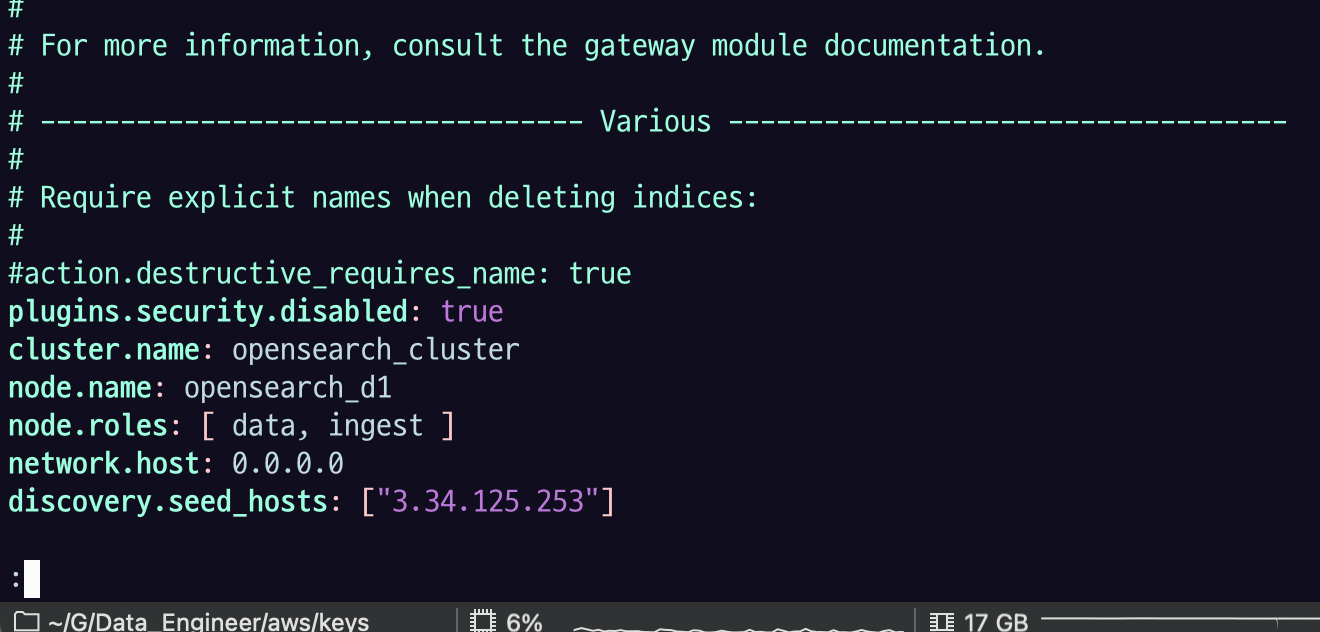
3.4 OpenSearch 클러스터 구성 실습 3.4.1 OpenSearch 클러스터 시각화 클라이언트 Elasticvue는 다음과 같은 기능을 제공하는 OpenSearch 클라이언트다. 클러스터, 노드, 샤드 상태 확인 인덱스 관리 REST API 인터페이스 스
45.[AWS] OpenSearch의 인덱스와 샤드 관리
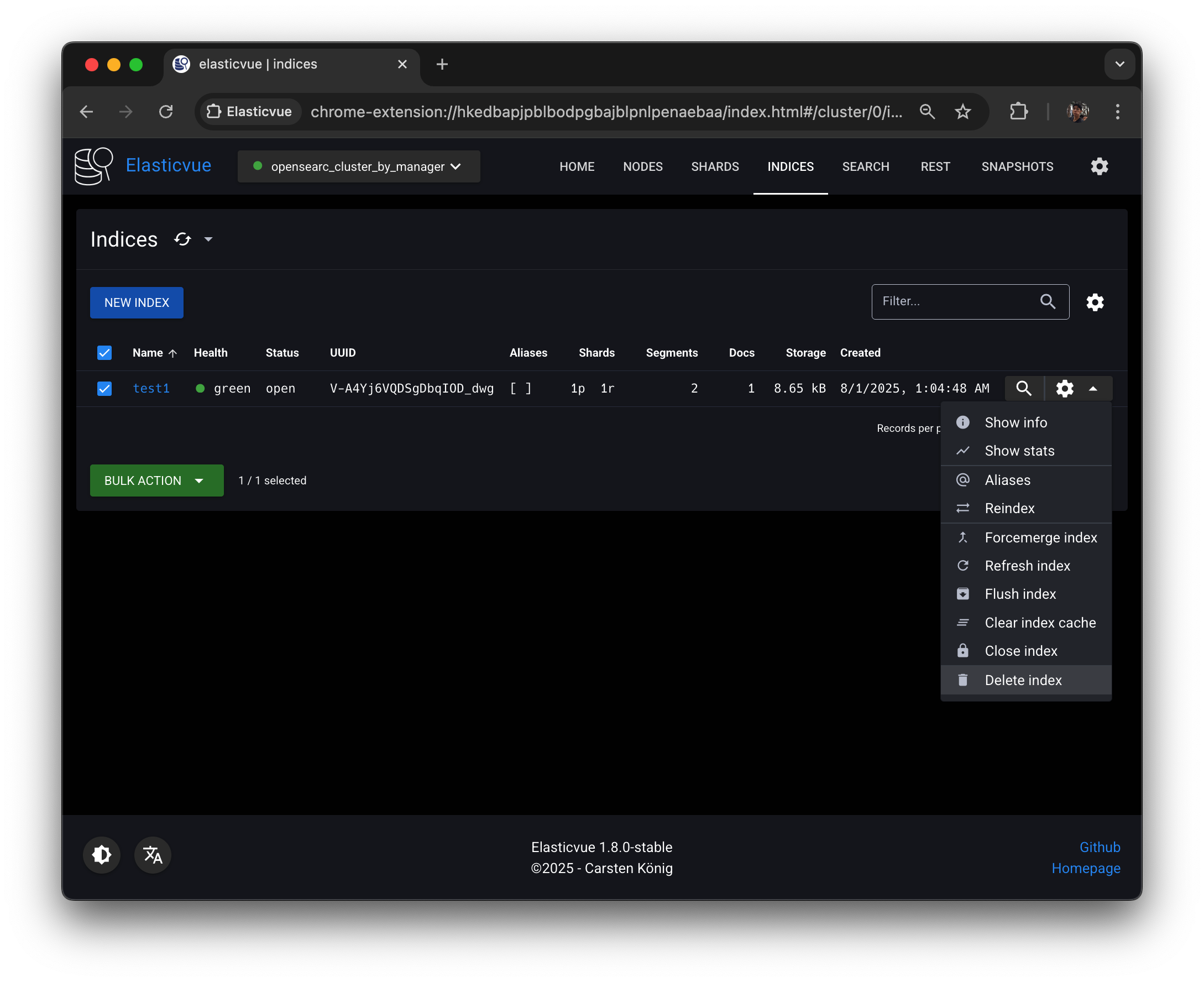
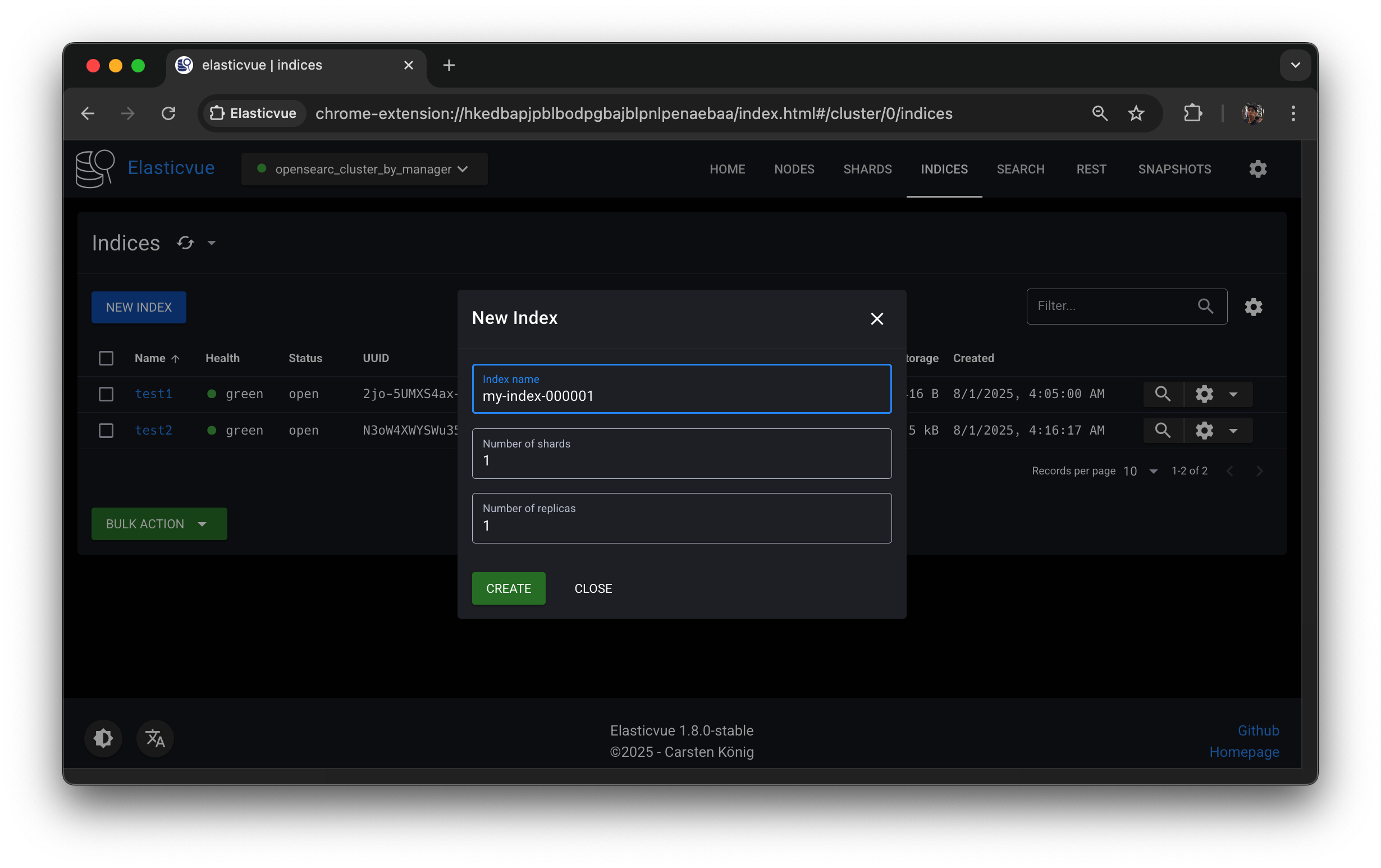
엘라스틱뷰에서는 오픈서치 api를 통해서 명령어를 날릴 수 있다.Elasticvue를 활용해서 진행할 것.INDICES 탭에 들어가면 test1이라는 인덱스가 이미 하나 있는데 delete 해주고NEW INDEX버튼 눌러서 test1 인덱스를 생성해보자. Elastic
46.[AWS] 인덱스 라이프사이클 관리 실습
인덱스가 특정 조건에 도달했을 때 새로운 인덱스를 생성하는 API다. ISM 템플릿에 rollover 조건을 설정하면 주기적으로 rollover 조건을 체크하고, 새로운 인덱스를 생성해준다. 본 강의에서는 rollover API를 직접 호출해서 수동으로 인덱스를 rol
47.[AWS] EMR BOOTSTRAP_FAILURE - OutOfMemoryError 해결
software settings RDS 접근성 (네트워크 레벨) EMR 노드가 RDS와 같은 VPC / 서브넷인가? (같은 VPC가 아니라면 SG 열어도 접근 불가) EMR 노드가 RDS와 같은 VPC / 서브넷 임. RDS Publicly accessible :
48.[AWS] Spot 인스턴스 사용을 위한 Instance Fleet 똥꼬쇼
EMR 실습 중에 port forwading으로
49.[AWS] EMR Hadoop 실습용 데이터 다운로드
2 실습용 데이터 다운로드 본 실습은 AWS EMR의 Primary(master) node 에서 진행한다. 2.1 실습용 데이터 실습용 데이터는 1987~2008년의 미국 항공편 운항 통계 데이터이다. 링크 예제 데이터의 컬럼에 대한 설명은 링크 에서 확인할 수
50.[AWS] EMR Hadoop HDFS 명령어 실습
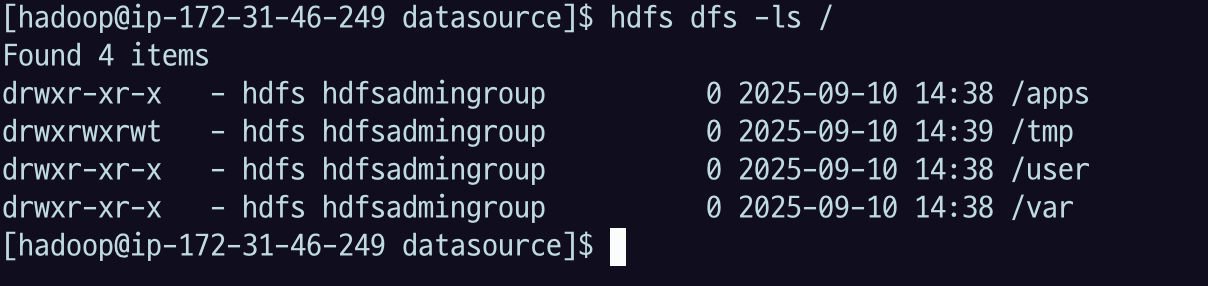
3 HDFS 명령어 실습 본 실습은 AWS EMR의 Primary(master) node 에서 진행한다. HDFS 명령어의 공식 매뉴얼 HDFS DFS (distributed file system)의 공식 매뉴얼 3.1 디렉토리, 파일 조회 3.1.1 ls
51.[AWS] EMR Hadoop - EMR 클러스터 웹 인터페이스
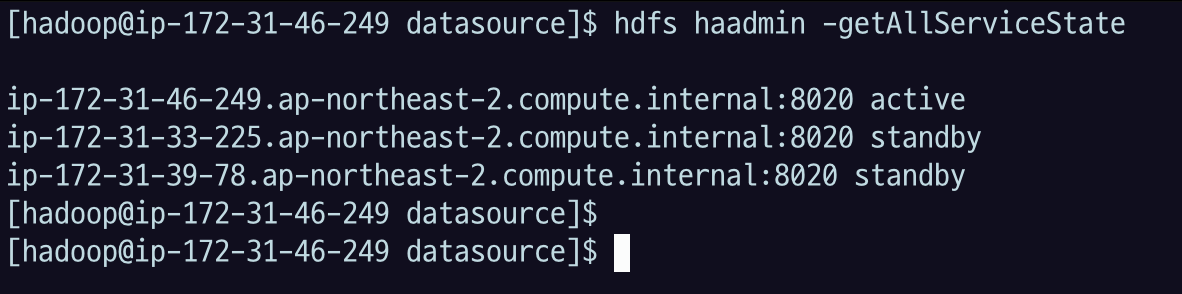
Hadoop 의 다양한 도구를 패키지로 설치했다. 각 컴포넌트별로 접근하는 인터페이스가 다르다. EMR로 구성한 경우 다음 매뉴얼로 확인한다.매뉴얼EMR 대시보드에서 Applications 를 누르면 접근할 수 있는 url 주소와 포트가 나열되어있다.EMR의 prima
52.[AWS] EMR Hadoop - HDFS이용하는 Java Application 구현
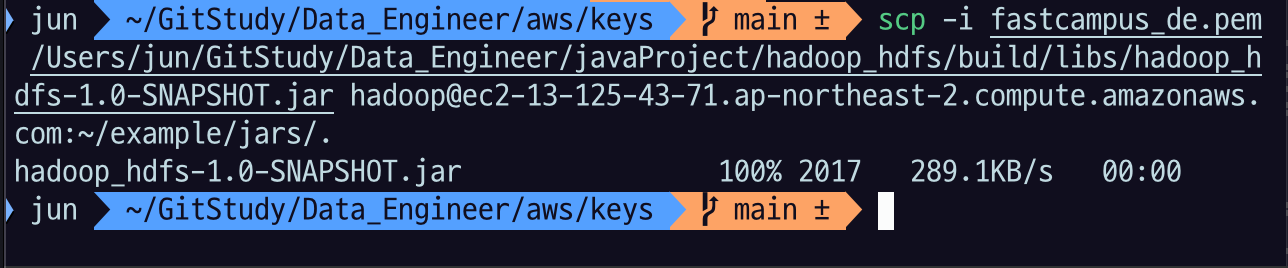
Primary 노드에 접속해서 경로 생성로컬의 jar 를 scp 로 primary 노드로 이동$key: primary node EC2 에 접속할 수 있는 key 파일$project_path: 5.1 을 수행한 java project 의 path$primary_node:
53.[AWS] Yarn Application 실습

Yanr Application에는 여러 개의 main이 있다.처음 자바 배울 때 하나의 프로그램에는 하나의 메인만 있을 수 있다고 배웠는데, 엄밀히 말하면 app에 Main이 여러 개가 담겨 있어도 별도의 프로세스로 따로따로 컨테이너에서 실행시킬 거니까 실제로 여러 개
54.[AWS] MapReduce 프로그래밍 실습
2 MapReduce 프로그래밍 > ℹ️ 실습에 사용하는 데이터는, P08-C02 AWS EMR Hadoop 실습 > 2 실습용 데이터 다운로드 에서 세팅한 데이터를 사용한다. 이렇게 조회하면 연도 별로 1987~2008.csv 파일이 있는 상태로 실습을 진행.
55.[AWS] 맵리듀스 정렬
앞선 예제에서 결과 데이터는 파일에 행으로 나누어져 있는데, 정렬이 되어있지 않다.정렬되지 않은 이유는 맵리듀스에서 사용한 키를 연월을 단순히 붙인 텍스트로 인식했기 때문이다.이것을 보조 정렬을 이용해서 월의 오름차순으로 정렬해보자.보조정렬의 구현 순서Composite
56.[AWS] Hive Client
Hive를 이용할 수 있는 방법은 많다. 기본 hive shell 에 들어가도 되고, JDBC driver 를 이용해서 SQL Client 도구들을 이용할 수도 있다. (Workbench, Datagrip 등) \- MySQL Workbench 와는 다른 것실습에
57.[AWS] HiveQL
HiveQL은 ANSI SQL 과 호환되는 부분이 많기는 하지만, RDBMS와는 차이가 많다. 따라서 SQL을 작성하는 과정에서 꼭 공식문서를 참고하는 것이 좋다.https://cwiki.apache.org/confluence/display/Hive/Langu
58.[AWS] Tez 엔진으로 성능 높이기
전통적인 MapReduce 작업의 단점을 보완해서 Hadoop 에서 mapreduce 작업을 더 빠르게 수행할 수 있도록 돕는 엔진이다.기존의 MapReduce의 단점을 해결하고, 고속화를 실현했다.불필요한 단계가 감소하여 처리가 짧아지고 스테이지 사이의 대기 시간이
59.[AWS] HBase 설치
P08-C07 HBase 실습HBase standalone 버전으로 설치한다.EC2 인스턴스를 준비한다.사전 프로그램들 set JAVA_HOMEwhich java 로 확인해본다.$host:16010 으로 hbase web UI 에 접속할 수 있다.HBase comman
60.[AWS] 메신저 서비스 HBase 설계
kakao talk 같은 메신저 서비스의 주 저장소를 HBase 로 한다고 했을 때 어떤 데이터 모델과 key 설계를 해야할지 고민해보자.User 는 무한히 많아질 수 있다.ChatRoom 은 무한히 많아질 수 있다.하나의 ChatRoom 에 속할 수 있는 참여자의 수
61.[AWS] 쇼핑몰 상품 댓글 기능 HBase 설계
쿠팡과 같은 쇼핑몰의 주 데이터 저장소를 HBase 로 한다고 했을 때, 어떤 데이터 모델과 key 설계를 해야할지 고민해보자.쿠팡의 댓글 기능을 설계해본다.댓글기능을 중심으로 요구사항을 작성해 보았다.User 는 무한히 많아질 수 있다.Product 는 무한히 많아질