Computer_Science
1.[운영 체제] zsh와 ~/.zshrc의 역할

Mac에서는 터미널을 실행하면 기본적으로 zsh(Z Shell)이 실행됩니다. 이때 특정 설정 파일(~/.zshrc)이 로드되면서 사용자 환경을 설정합니다. 이를 이해하기 위해 다음과 같은 개념들을 정리해 보겠습니다.사용자가 명령어를 입력하여 컴퓨터와 상호작용하는 인터
2.[CS] 폰 노이만 아키텍처와 하버드 아키텍처
강의를 보면서 공부하던 중에 폰 노이만 아키텍쳐에 대한 설명이 나왔다. 1학년 때 책에서 본 듯한 내용인데 기억이 하나도 나지 않아서 다시 정리해 보았다.컴퓨터는 프로그램을 실행하고 데이터를 처리하는 장치다. 이때 프로그램이 어떻게 실행되며, 데이터는 어떻게 이동하는가
3.[CS] Reliable Queue 정리 (with Redis)
작업(데이터)을 처리하는 도중 실패가 발생할 경우를 고려하여 신뢰성 있게 복구 가능한 큐를 말합니다.단순한 FIFO 큐와 달리 처리 중간 단계 상태를 별도 Queue로 관리하여 작업 유실을 방지합니다.RPUSH로 작업을 큐에 넣는다.BRPOPLPUSH로 job을 p하고
4.[CS] 알고리즘 시간복잡도 정리 (Big-O, Big-Ω, Big-θ)
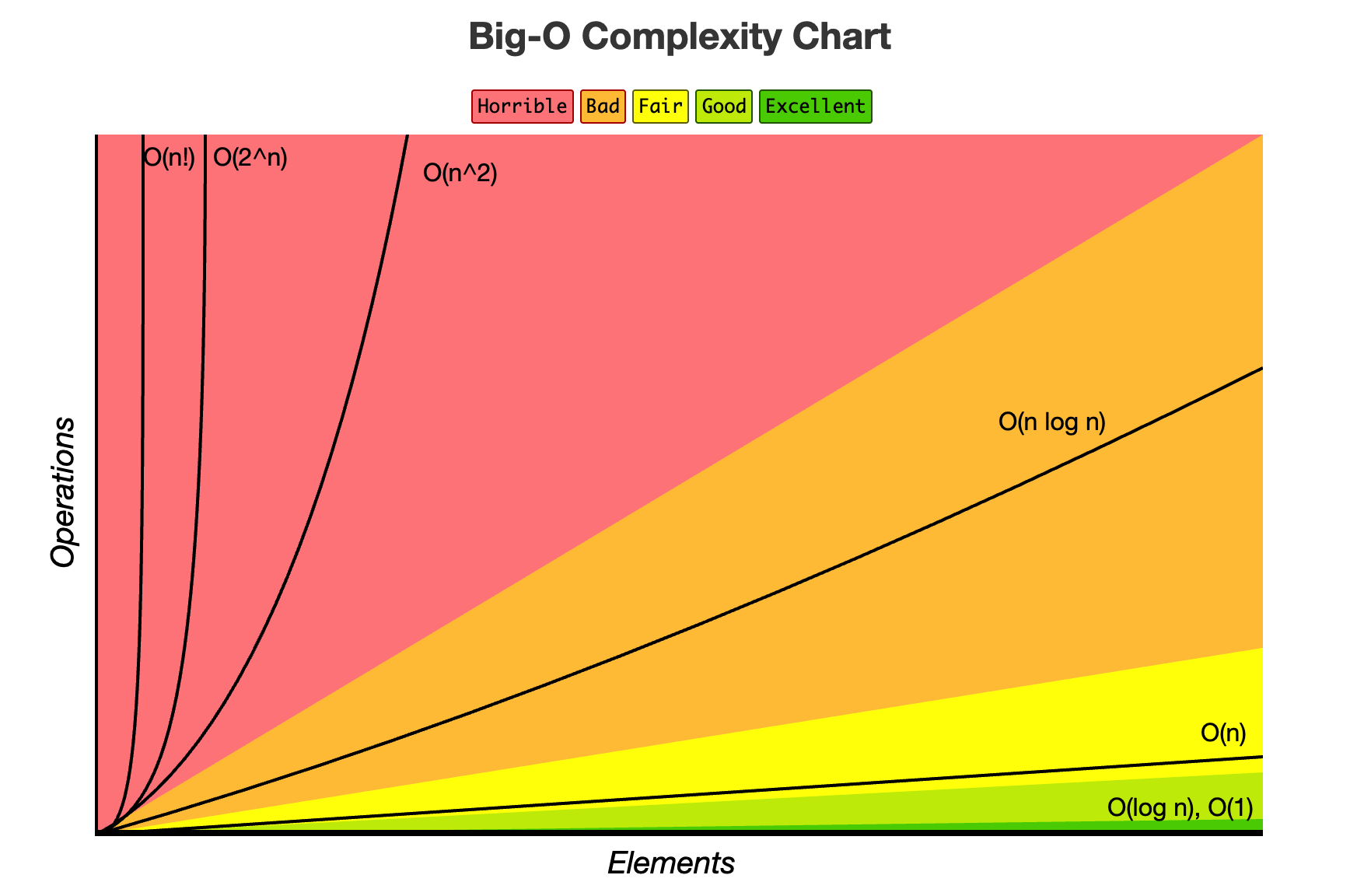
알고리즘의 성능을 정량적으로 비교할 수 있는 지표로 시간복잡도와 공간복잡도가 있다.시간복잡도(Time Complexity): 입력 크기 N이 증가할 때 연산 횟수가 얼마나 증가하는지를 나타낸다.공간복잡도(Space Complexity): 입력 크기 N이 증가할 때 필요
5.[CS] 동기와 비동기의 차이, Nginx 구조로 쉽게 이해하기
요즘 개발하다 보면 꼭 한번쯤 듣게 되는 말이 있다.“이거 비동기로 짜야 돼.” 혹은 “Nginx는 비동기니까 더 빠르다.”처음에는 “동기? 비동기? 그게 뭐야… 그냥 실행되면 되는 거 아냐?” 싶었는데, 이게 생각보다 꽤 중요했다.특히 나는 Python 백엔드 개발을
6.[CS] Context Switching이란?
Context Switching?이건 진짜 많은 개발자들이 단어는 알고 있지만 실제로 어떻게 일어나고, 왜 성능 저하를 일으키는지도 모른 채 그냥 “스레드 간 전환이잖아~” 하고 넘어가는 주제이다.근데 백엔드 개발을 하다 보면, 특히 동시성(concurrency)이나
7. 자료구조 및 알고리즘 면접 예상 문제 + 정리
MySQL에서 B+Tree 인덱스를 사용할 때, INSERT/DELETE가 비싼 이유는 무엇인가?B+Tree 인덱스의 구조적 특징이 무엇이며, 그로 인한 트레이드오프는 무엇인가?Leaf 페이지 분할(Split)이나 병합(Merge)은 언제 발생하며, 성능에 어떤 영향을
8.[Network] 멀티플렉싱(Multiplexing)이란 무엇인가
멀티플렉싱(Multiplexing)은 컴퓨터 네트워크, 운영체제, 웹 통신 등 다양한 기술 영역에서 활용되는 핵심 개념이다.여러 데이터 흐름을 하나의 경로로 통합하거나, 반대로 하나의 흐름을 여러 경로로 나누는 과정에서 사용된다.이 글에서는 멀티플렉싱의 기본 개념부터,
9.[CS] UUID란
UUID는 Universally Unique Identifier의 약자로, 전 세계에서 고유한 ID를 생성하기 위한 표준이다.128비트 크기의 값으로 구성되며, 중앙 서버 없이도 고유한 ID를 생성할 수 있다는 장점이 있다.128비트(16바이트) 고정 길이 식별자 하
10.[Network] CDN 이란?
웹 성능을 높이는 핵심 기술CDN은 웹 콘텐츠를 전 세계 여러 지역에 분산된 서버에 저장하고, 사용자와 가장 가까운 서버에서 해당 콘텐츠를 제공하는 시스템이다.이 방식은 웹사이트 로딩 속도를 높이고, 서버 부하를 줄이며, 서비스 안정성을 향상시키는 데 사용된다.사용자가
11.[CS] Thread Pool 이란?
스레드(Thread): 프로그램 내에서 실제 작업을 수행하는 실행 흐름의 단위이다. 풀(Pool): 필요한 객체를 매번 새로 생성하지 않고, 미리 생성해 둔 객체를 재사용하는 집합이다. 따라서, 스레드 풀(Thread Pool)은 미리 정해진 개수만큼 스레드를 만들
12.[CS] 효율적인 API 성능 개선 전략
서비스 규모가 작을 때는 서버(Provider)와 클라이언트(Consumer) 간의 API 통신 효율에 대해 큰 고민 없이 개발이 가능하다. 하지만 트래픽이 증가하고 데이터 요청량이 많아지면, 테이블 간 조인과 쿼리 연산이 많아지고 이는 곧 시스템 전반의 성능 저하로
13.[CS] 오버페칭? 언더페칭?
현대 웹 애플리케이션과 데이터 중심 서비스에서는 클라이언트와 서버 간의 효율적인 데이터 통신이 필수적이다. 특히 데이터 분석 시스템이나 대시보드와 같이 실시간 혹은 대용량 데이터를 다루는 환경에서는, API 설계 방식이 성능과 사용자 경험에 큰 영향을 준다. 이 글에서
14.[CS] GraphQL과 REST API
데이터 처리와 분석은 현대 애플리케이션에서 핵심적인 역할을 한다. 특히, 대규모 데이터셋을 효율적으로 요청하고 처리하는 것은 시스템 성능과 사용자 경험에 직접적인 영향을 미친다. REST API와 GraphQL은 데이터 접근을 위한 두 가지 주요 방식으로, 각각의 특성
15.[CS] 벡터화와 병렬 처리로 데이터 처리 가속화
벡터화와 병렬 처리의 개념을 이해하고, 데이터 처리 성능을 가속화하는 방법을 학습한다.파이썬을 중심으로 벡터화와 병렬 처리를 구현하며, 다른 언어에서의 활용 사례를 간단히 살펴본다.NumPy, Pandas, Joblib을 활용한 실습을 통해 성능 차이를 체감한다.대규모
16.[CS] TCP의 3-Way Handshake와 4-Way Handshake
전송 계층(Transport Layer)은 OSI 7계층 모델에서 4번째 계층으로, 애플리케이션 간의 논리적 통신을 제공한다. 상위 계층(응용 계층)이 데이터 전달의 신뢰성이나 효율성을 고려하지 않도록 하며, 데이터를 세그먼트(또는 데이터그램) 단위로 관리한다. 전송
17.[CS] SOP와 CORS + Nginx 프록시 설정 실습
SOP(Same-Origin Policy)는 웹 브라우저의 보안 메커니즘으로, 한 도메인(Origin)에서 실행되는 스크립트가 다른 도메인의 리소스에 접근하는 것을 제한한다. Origin은 프로토콜(예: HTTP, HTTPS), 도메인(예: example.com), 포
18.[CS] Thread란?
스레드는 프로세스 내에서 실행 흐름의 최소 단위이다. 하나의 프로세스는 여러 스레드를 가질 수 있으며, 이들은 메모리와 자원을 공유한다. 데이터 엔지니어링 관점에서 스레드는 대량의 데이터 처리나 병렬 작업을 효율적으로 수행하는 데 중요한 역할을 한다. 예를 들어, 데이
19.[CS] IP 프로토콜이란? (+ 네트워크 이슈 대응 방안)
인터넷 프로토콜(IP)은 네트워크에서 데이터를 주고받기 위한 핵심 규약이다. OSI 7계층 모델의 네트워크 계층(Layer 3)에 속하며, 데이터를 패킷 단위로 나누어 출발지에서 목적지까지 전달한다. 1. IP 프로토콜이란? IP 프로토콜은 송신 호스트와 수신 호스