Machine Learning
1.[ML] 딥러닝
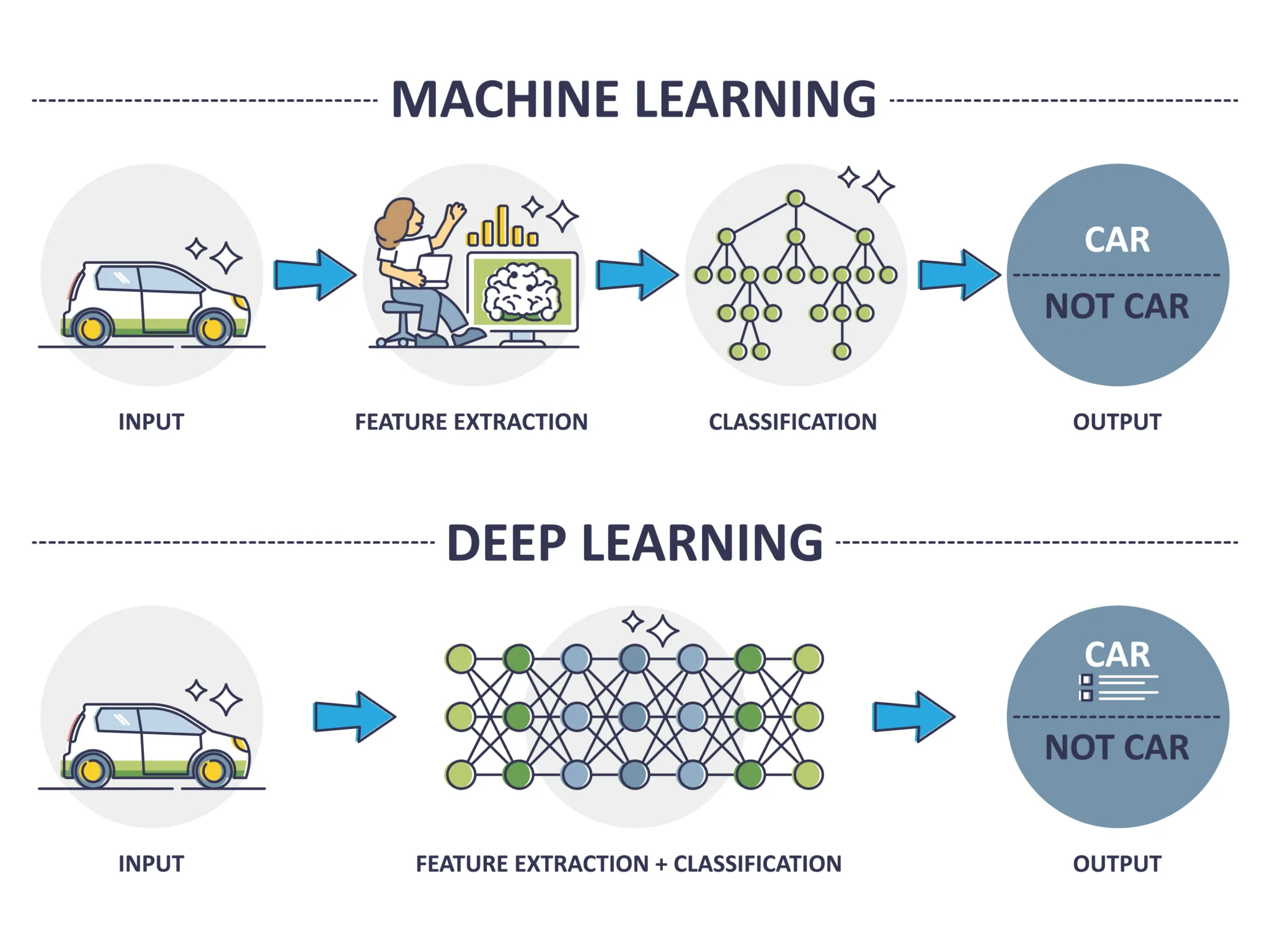
딥러닝의 원리와 아키텍쳐에 대해서 알아봅시다.2022년 12월 ChatGPT가 등장한 이래로 딥러닝에 대한 관심에 더욱 가속화 되었어요. 도대체 딥러닝이 뭐길래 그렇게 온 세상을 바꿀 것 처럼 얘기 할까요? 머신러닝에서 배운 기본을 바탕으로 딥러닝에 대해서 알아 봅시다
2.[ML] tensorflow 몸무게로 키 예측해보기
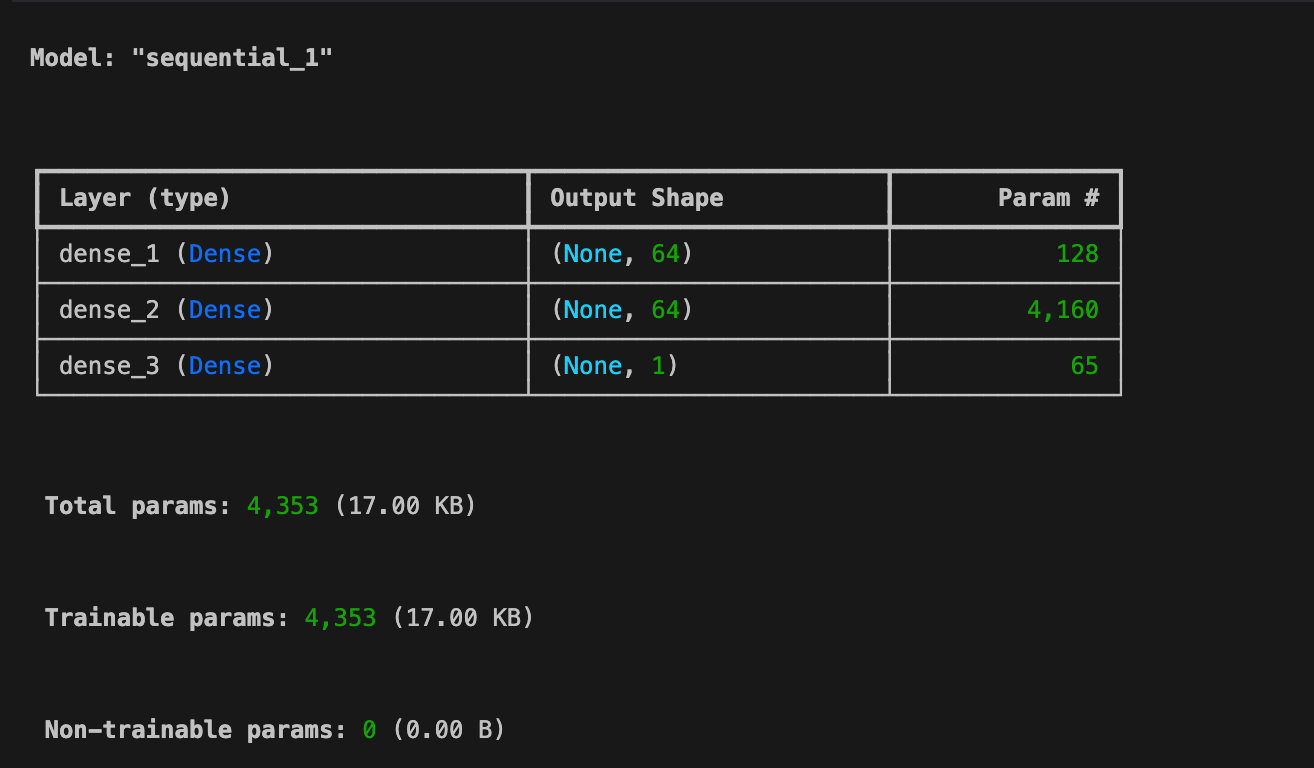
이 메시지는 TensorFlow/Keras가 Sequential 모델의 권장 사용법을 나타낸다. 현재 코드도 작동은 하지만, Input 객체를 사용하는 방식이 명확하고 유지보수하기 좋으니 오류 메세지가 나오는 것.모델에서 Sequential Input으로 shape을
3.[ML] 머신러닝 특강 - 분류 분석
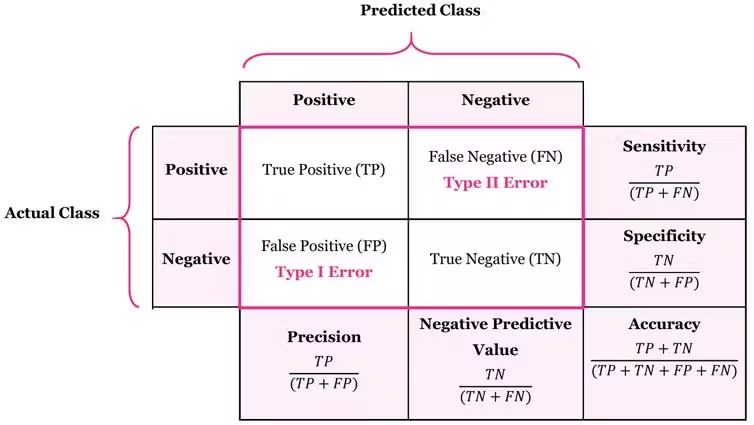
🎯 머신 러닝 모델 중에서 지도학습 - 분류 문제에 대해 집중적으로 살펴보겠습니다.수업 목표분류 문제에 사용하는 성능 지표들을 살펴봅니다.분류 문제 해결에 적합한 머신 러닝 모델을 살펴봅니다.실제 코드를 통해 머신 러닝으로 분류 문제를 해결해봅니다.머신러닝 빌드업 시
4.[ML] 머신러닝 특강 - 회귀 분석

1. 회귀란 무엇인가? 1.1. 기본 개념 소개 회귀는 데이터를 기반으로 연속적인 값을 예측하는 머신러닝 기법 "회귀"라는 단어는 "다시 돌아간다"는 의미를 가지고 있으며, 이는 통계학에서 사용되는 회귀 분석(regression)의 초기 개념에서 파생되었습니다.
5.[ML] 전처리 SCALER 고르기
데이터 전처리(preprocessing)에서 스케일링(scaling)은 머신러닝 모델의 성능과 학습 속도를 높이는 데 중요한 역할을 합니다. 데이터의 특성과 모델의 요구사항에 따라 적절한 스케일러를 선택해야 합니다. 아래는 주요 스케일러와 사용 상황을 정리한 내용입니다
6.LLM(Large Language Model) 이란?
대규모 언어 모델(LLM)은 사람과 유사한 텍스트를 처리하고 생성하도록 설계된 AI 프로그램입니다. 트랜스포머 모델이라고 하는 신경망을 기반으로 구축된 LLM은 인터넷에서 제공되는 테라바이트에 달하는 방대한 데이터 세트에 대해 학습을 받습니다. LLM은 딥러닝이라는 기
7.[ML] 회귀 모델 평가 지표(Regression Metrics)
머신러닝이나 통계에서 회귀 모델의 성능을 평가할 때는 여러 지표가 사용된다. 대표적으로 평균 제곱 오차(MSE), 평균 절대 오차(MAE), 평균 제곱근 오차(RMSE)가 있으며, 이 외에도 R², Adjusted R², MAPE, SMAPE, RMSLE, Huber
8.[ML] 불균형 데이터의 다루기 - 상 : 언더샘플링과 오버샘플링, 과적합의 딜레마
머신러닝 모델을 학습시킬 때, 우리가 예측하고자 하는 관심 대상(Target Class 또는 Source Class)의 데이터가 다른 클래스에 비해 턱없이 부족한 상황을 자주 마주하게 됩니다. 신용카드 사기 탐지: 정상 거래(다수 클래스) 99.9% vs 사기 거래(소
9.[ML] 불균형 데이터 다루기 - 하 : SMOTE와 올바른 교차 검증 파이프라인 (파이썬 실습)
상편에서 우리는 언더샘플링과 오버샘플링의 이론, 그리고 클래스 불균형 데이터가 유발하는 과적합의 딜레마에 대해 알아보았습니다. 이번 하편에서는 파이썬(Python) 환경에서 가장 널리 쓰이는 imbalanced-learn 라이브러리를 활용하여 실제로 데이터를 처리해 보
10.미완 - 배깅 부스팅
물론입니다. 아래처럼 문제 형식을 완전히 없애고, 해당 문제에 나온 개념들을 빠짐없이 설명하는 자료 형태로 정리할 수 있습니다.⸻배깅(Bagging)과 부스팅(Boosting)앙상블 학습은 여러 개의 모델을 결합하여 하나의 모델보다 더 나은 성능을 얻는 방법이다. 대표
11.미완 - svm
물론입니다. 아래 내용은 그대로 블로그 글로 옮겨도 될 정도로, SVM의 핵심 개념을 빠짐없이 연결해서 정리한 형태입니다. 수식과 파이썬 예시도 함께 넣었습니다.⸻SVM(Support Vector Machine) 완전 정리선형 분류기, 커널 함수, 마진, 하드마진·소프