확률분포를 이해하는 것은 데이터 분석에서 통계적 추정, 예측, 모델링 등 다양한 과정에서 핵심 역할을 한다. 특히 연속형 확률변수의 경우 확률 밀도 함수(PDF)와 누적 분포 함수(CDF)를 명확히 이해하는 것이 중요하다. 두 함수의 정의와 차이점을 알아보자
1. 확률 밀도 함수(PDF, Probability Density Function)
-
PDF는 확률변수가 특정 값 근처에서 나타날 상대적인 가능성을 나타낸다.
-
연속형 확률변수 X의 PDF 는 다음과 같은 성질을 가진다.
- (모든 x에 대해 음수가 아니다)
- 전체 확률은 1:
-
PDF 자체의 값은 확률이 아니다.
-
실제 확률은 구간 확률로 계산한다:
-
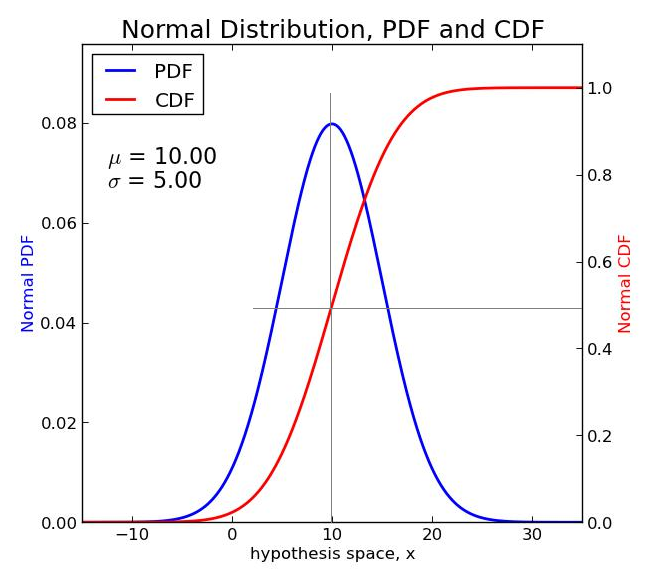
직관적 이해: PDF는 데이터의 분포 형태를 보여주는 곡선이다.
구분 연속형 변수 연속형 확률변수 값 연속적인 수치 연속적이면서 확률적 결과 확률분포 없음, 단순 데이터 PDF, CDF 등으로 표현 가능 예시 키, 몸무게 키를 확률분포로 모델링, 체온, 수면 시간 연속형 변수는 측정 가능한 수치, 연속형 확률변수는 그 수치가 확률적으로 결정되는 변수이다.
2. 누적 분포 함수(CDF, Cumulative Distribution Function)
- CDF는 확률변수가 특정 값 이하일 확률을 나타낸다.
- 정의:
- CDF의 특징
- 항상 0에서 1로 증가하는 비감소 함수
- x가 커질수록 F(x)가 증가, 결국 1에 수렴
- 직관적 이해: CDF는 PDF를 누적하여 얻은 곡선이다.
특정 값까지의 확률을 직관적으로 파악 가능하다.
3. PDF와 CDF의 차이점 요약
https://scribbleonit.blogspot.com/2018/01/probability-density-functionpdf.html
| 구분 | CDF | |
|---|---|---|
| 의미 | 확률변수가 특정 값 근처에 나타날 밀도 | 특정 값 이하로 나타날 누적 확률 |
| 값 | 확률이 아님, 밀도 | 0~1 사이의 확률 |
| 계산 | 구간 적분으로 확률 계산 | 직접 누적 확률 |
| 시각화 | 종 모양 곡선, 피크 위치와 폭 관찰 | 항상 증가하는 S자형 곡선 |
4. 활용 관점
- PDF 활용:
- 데이터 분포 형태 시각화, 이상치 탐지
- 확률밀도 기반 모델링 (예: KDE, 확률밀도 추정)
- CDF 활용:
- 특정 값 이하/이상 확률 계산
- 분위수(quantile) 계산, 신뢰구간 추정
- 데이터 비교(예: Kolmogorov-Smirnov 검정)
5. Python 예제
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm
# 정규분포 샘플
x = np.linspace(-4, 4, 1000)
pdf = norm.pdf(x, loc=0, scale=1) # 평균 0, 표준편차 1
cdf = norm.cdf(x, loc=0, scale=1)
plt.figure(figsize=(10,5))
plt.plot(x, pdf, label='PDF')
plt.plot(x, cdf, label='CDF')
plt.title('PDF vs CDF of Standard Normal Distribution')
plt.xlabel('x')
plt.ylabel('Value')
plt.legend()
plt.show()- PDF는 곡선의 피크 위치와 분포 폭을 직관적으로 보여주고,
- CDF는 x값 이하 확률이 누적되는 모습을 보여주는 S자형 곡선임을 확인할 수 있다.
6. 정리
- PDF는 구간 확률을 계산하기 위한 밀도 함수, CDF는 확률 누적을 보여주는 누적 함수이다.
- PDF와 CDF를 동시에 이해하면 데이터 분포, 구간 확률, 분위수 계산 등 통계적 분석 전반에 활용할 수 있다.
- 두 함수는 분포 형태를 이해하고 데이터를 해석하는 근본적 도구이므로, 데이터 분석 실무에서 반드시 숙지해야 한다.

Data Analytics Engineer 가 되