통계학기초
1.[통계학 기초] 학습 계획

기본적인 통계학 지식을 얻을 수 있도록 구성된 강의입니다.수식으로 이해하는 방식 보단 개념 설명과 예시를 위주로 기초 통계학에 대한 이해가 가능합니다.파이썬 실습 코드를 활용하여 바로 실전에서 적용 가능합니다.각 주차마다 주어진 다양한 연습문제를 통해 내용을 잘 이해했
2.[통계학 기초] 1강. 데이터 분석과 통계
데이터 분석에 있어서 통계가 왜 중요한지를 배웁니다기술통계와 추론통계에 대한 개념을 이해하고 각각의 차이점을 설명할 수 있습니다통계분석 방법의 다양한 종류에 대해서 배웁니다데이터 기반의 의사결정을 내릴 수 있음!데이터 분석에서 통계는 데이터를 이해하고 해석하는 데 중요
3.[통계학 기초] 1113 세션 노트.
통계 앞쪽 이해 못하면 뒤에도 이해 못함.복슴 꼭 하는 것을 추천.실습 코드 나가니까 실습 꼭 진행.가설 세우고검증하고 해석하는 것 계속 연습해야 함.데이터의 오차범위를 어디까지 허용할 것인가.종류를 왜 분류?데이터 생김세 따라서 시각화, 해석, 통계모델 결정 방식이
4.[통계학 기초] 1114 세션 노트
신뢰수준 95% : 무작위로 표본 추출했을 때 100번 중 95번은 모집단의 값을 포함신뢰구간이 넓어지면 정확한 예측이 어렵기 때문에수업 목표 실험 A/B Test.실험 설계는 특정 가설(의도) 를 확인하거나 기각하기 위한 통계적실험을 합니다.생각한 것이 의미가 있었
5.[통계기초] 1118 세션
분석 기법 A/B마케팅 고객데이터 분석 중 가장 중요하게 비교분석 진행함1.고객 니즈 파악2\. RIO 파악 목적이거 주의 깊게 봐주시길 바랍니다. 이거 잘 보셔야 됩니다.서비스 가입율재방문율CTR등프로세스 1\. 현행 데이터 ㄴ탐색2\. 가설설정 귀무가설, 대립가설
6.[통계 기초] 1119 session
통계야 놀자 4회차 01 회귀분석이란? x 축 게임 시간 y 축 전기세 게임 시간은 원인이기에 독립 변수. 게임 시간에 따라 전기세가 달라지죠. 전기세는 종속변수가 됩니다. 그런데 우리가 게임시간이 1000시간이면 전기세는 얼마일까요? 이 관계를 파악하기 위해서
7.[통계 기초] session 1120
독립변수는 원인 종속변수는 결과귀무가설과 대립가설.회귀분석 3단계1\. 독립변수,종속변수 설정2\. 데이터 경향성 확인3\. 정합성 검증 & 결과 해석회귀분석의 결과해석 위해 세가지 검증1\. 회귀식 설명력2\. 회귀식 통계적 유의성3\. 독립변수와 종속변수 간 상관관
8.[통계기초] 세션 1121
오늘 목표통계와 머신러닝의 관계성머신러닝의 종류지도/비지도 학습의 특징과 종류데이터 분석이라는 분야는 대표적으로 통계적 가설검정과 머신러닝이 존재하고 두 가지.방법론은 긴밀하게 연관됭 ㅓ있다.정의 : 데이터 기반으로 에측 모델을 학습시키는 알고리즘 기반의 접근법목적 :
9.[통계학 기초] 3강. 유의성검정
수업 목표각각의 유의성 검정 방법들에 이해하고 특징을 파악한다신뢰구간과 가설검정의 관계에 대해 설명할 수 있다제 1종 오류와 2종 오류에 대해 이해하고 구분할 수 있다두 그룹 (A, B)과 비교하는게 포인트!1) A/B 검정이란 무엇인가?출처 : 위키백과A/B 검정은
10.[통계학 기초] 4강. 회귀
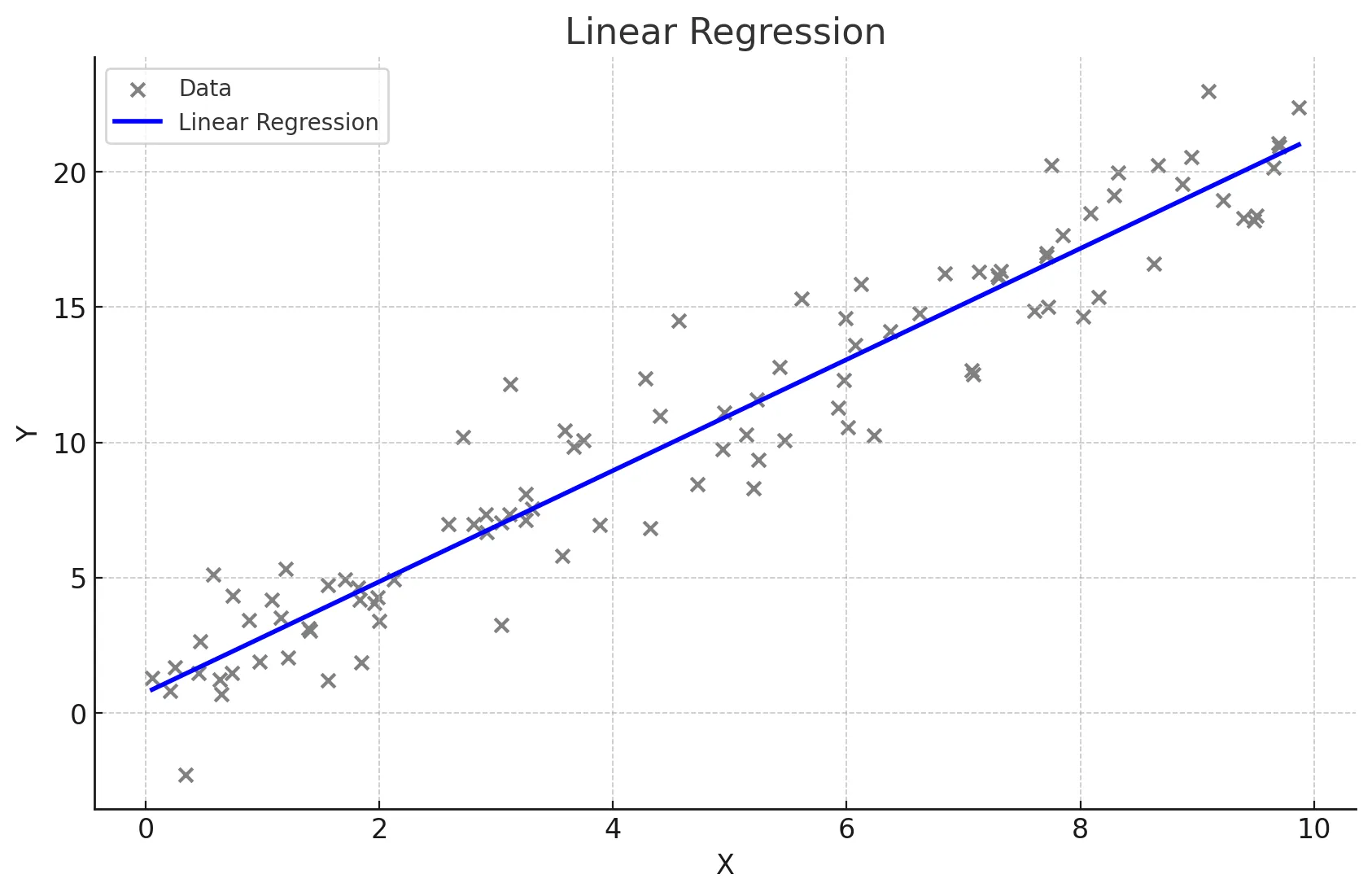
수업 목표회귀가 무엇인지에 대해 이해한다다양한 회귀의 종류에 대해서 설명할 수 있고 특징을 이해한다한개의 변수에 의한 결과를 예측하나의 독립 변수(X)와 하나의 종속 변수(Y) 간의 관계를 직선으로 모델링하는 방법.Y = β0 + β1X, 여기서 β0는 절편, β1는
11.[통계학 기초] 5강. 상관관계
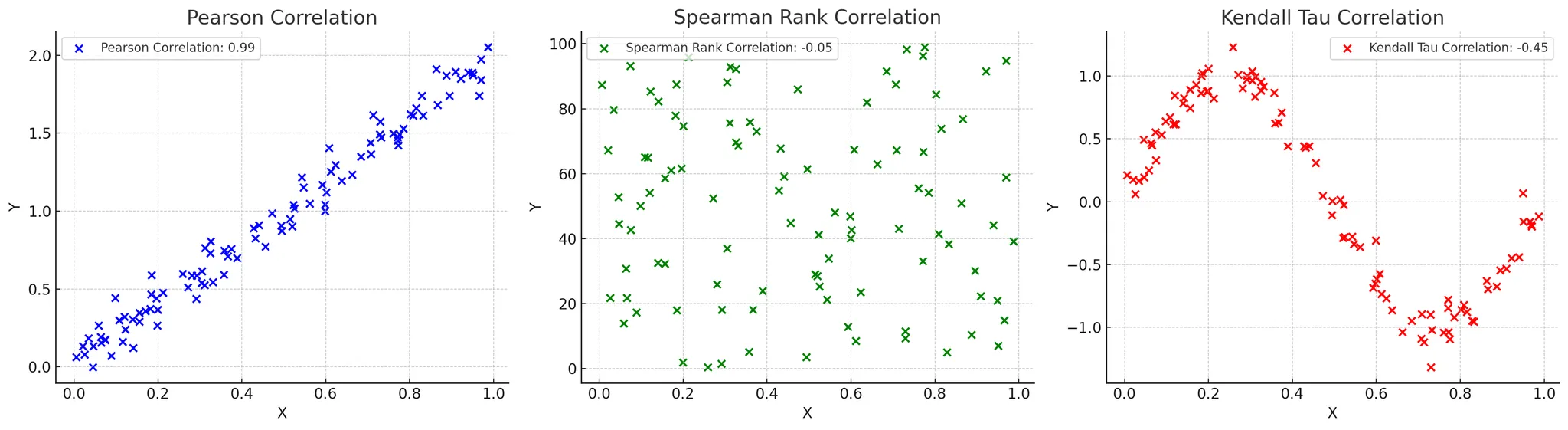
수업 목표상관관계에 대해서 이해한다다양한 상관관계 계산의 특징과 차이점을 이해하고 적용할 수 있다가장 대표적으로 많이 사용하는 상관계수!가장 왼쪽 그래프가 피어슨 상관계수 그래프!첫 번째 그래프는 파란색 점들로 나타내었으며, X와 Y의 선형 관계를 보여줍니다.그래프에서
12.[통계학 기초] 6강. 가설검정의 주의점
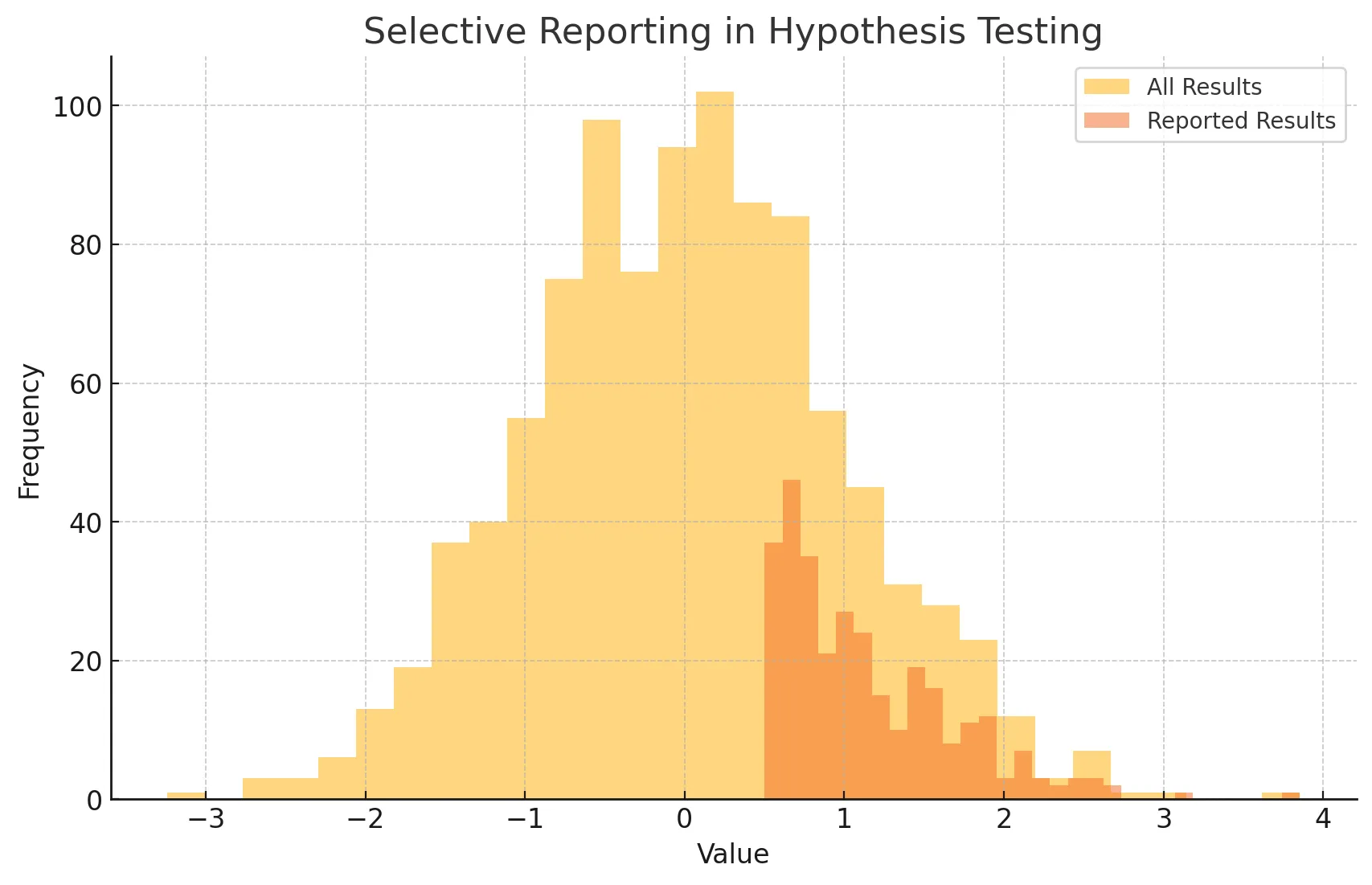
수업 목표가설검정의 다양한 주의점에 대해 이해한다이러한 주의점들을 참고하여 가설검정을 진행할 수 있다동일한 연구나 실험을 반복했을 때 일관된 결과가 나오는지 여부. 연구의 신뢰성을 높이는 중요한 요소ex) 신약을 개발할 때 실험실에서만 효과가 있는 것이 아니라 실제 상
13.[통계학] 통계야 놀자 - 1회차

수업 목표다양한 데이터의 종류를 이해합니다.편차, 분산, 표준편차의 개념을 이해합니다.표본분포와 히스토그램의 개념을 학습합니다.신뢰구간과 정규분포의 개념을 익히고 응용합니다. 다양한 형태의 데이터를 살펴봅시다.이번 수업에서 배울 것은우리는 이번 수업에서 ‘데이터 분석에
14.[통계학 기초] 카이제곱 검정
카이제곱 검정은 두 범주형 변수에 대한 분석 방법이다.다음의 세가지 검증 방법이 있다.적합도 검정 : 한 범주형 변수의 각 그룹 별 비율과 특정 상수비가 같은지 검증하는 것독립성 검정 : 두 범주형 변수가 서로 독립인지 검정하는 것동질성 검정 : 각 집단이 서로 유사한
15.[기초통계] Z-검정 vs. T-검정
데이터 분석은 단순한 숫자 계산을 넘어, 데이터에 숨어 있는 의미를 찾아내고 신뢰할 수 있는 결론을 도출하는 과정이다. 이 과정의 핵심 도구 중 하나가 바로 가설 검정이다. 특히, 두 그룹의 평균을 비교할 때 주로 사용되는 Z-검정과 T-검정은 모든 데이터 분석가가 반
16.[기초통계] MLE, 최대우도추정법
데이터 분석과 머신러닝에서 핵심적인 추정 방법 중 하나가 최대우도추정법(MLE, Maximum Likelihood Estimation)이다.MLE는 데이터가 가장 그럴듯하게 나올 수 있는 모수(Parameter)를 추정하는 방법이다.모집단(Population)의 확률
17.[기초통계] 데이터로 모수를 추정하는 방법론
데이터 분석에서 모수(Parameter) 추정은 모집단의 특성을 파악하고, 예측과 의사결정에 활용하기 위한 핵심 과정이다. 본 글에서는 기본 개념부터 대표적인 추정 방법, 실제 데이터 분석에서의 적용까지 단계별로 설명한다.모수(Parameter): 모집단의 특성을 나타
18.[기초 통계] PDF와 CDF 의 차이
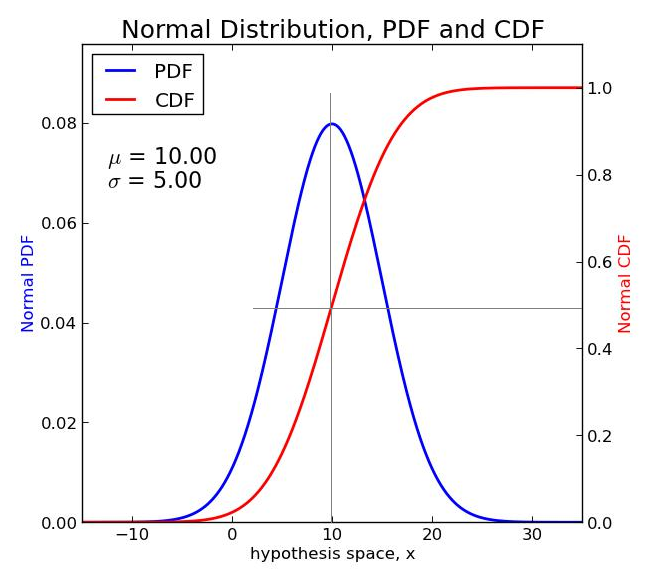
확률분포를 이해하는 것은 데이터 분석에서 통계적 추정, 예측, 모델링 등 다양한 과정에서 핵심 역할을 한다. 특히 연속형 확률변수의 경우 확률 밀도 함수(PDF)와 누적 분포 함수(CDF)를 명확히 이해하는 것이 중요하다. 두 함수의 정의와 차이점을 알아보자PDF는 확
19.[기초통계] 베이지안 통계와 빈도주의 통계의 차이
"베이지안 통계와 빈도주의 통계의 차이는 무엇일까?"A: 빈도주의(Frequentist) 통계는 확률을 무한 반복 실험에서의 상대적 빈도로 해석한다. 모수(Parameter)는 고정된 값이며, 데이터는 무작위로 변동한다고 본다. 예를 들어, 동전을 던질 때 '앞면이 나
20.[기초 통계] 공분산과 상관계수 이해하기
데이터 분석에서 두 변수 간 관계를 이해할 때 공분산과 상관계수는 가장 기본적이면서도 중요한 지표이다. 이 글에서는 두 지표의 정의, 계산 방법, 차이점과 직관적 의미를 정리한다.공분산은 두 변수가 같은 방향으로 움직이는지, 반대 방향으로 움직이는지를 나타내는 지표이다
21.미완 - [기초통계] 불편추정량
a는 b의 불편추정량이다. 라고 하면 어떻게 이해하면 돼?“a를 여러 번 계산해서 평균을 내면 b가 된다”라고 이해하면 아주아주 쉽다.불편추정량은 기대값이 모수와 같은() 편향 없는 추정량이며, 일치추정량은 표본 크기가 커질수록 추정량이 모수에 확률적으로 수렴하는()
22.미완 - 초기하분포
초기하분포와 비복원 추출은 통계·확률에서 강하게 연결된 개념이다. 개념을 분리해서 정의하고, 이후 수학적 구조까지 명확히 정리한다.⸻비복원 추출 (Sampling without replacement)비복원 추출은 한 번 뽑은 표본을 다시 모집단에 넣지 않는 방식이다.
23.미완 상관계수
아래는 그대로 블로그에 옮겨도 되는 형태로 정리한 글입니다.핵심은 “피어슨은 선형 관계”, “스피어만은 순위 기반 단조 관계”, “켄달의 타우는 순위 쌍의 일치도”, “상호정보는 비선형 의존성”으로 나누어 이해하는 것입니다.⸻상관관계의 종류와 해석: 피어슨, 스피어만,
24.미완 정규성 가정
정규성 가정정규성 가정은 “데이터나 오차가 정규분포를 따라야 한다”는 전제를 말합니다.다만 이 말은 모델마다 의미가 조금 다릅니다. 로지스틱 회귀에서는 선형회귀에서처럼 종속변수 자체나 오차항이 정규분포를 따른다고 가정하지 않습니다.핵심부터 말하면, 로지스틱 회귀는 종속