1 전통적인 서버 아키텍처의 역사
1.1 컴퓨터의 진화
1.1.1 Process on machine
1930년대
컴퓨터가 최초에 등장했을 때는 기계가 사람이 수기로 해야할 일을 자동으로 대신해주기만 하면 되었다. 하나의 컴퓨터 머신에 수동으로 작업을 등록하고 실행시키는 방식이었다.
이후 컴퓨터 장비의 크기가 작아지고, 명령어를 입력하는 방식이 고도화 되는 방식으로 발전이 이루어졌다.
1940년대
장비의 크기가 작아지고 현대 컴퓨터의 구조를 가지게 된 데는 폰노이만 아키텍처 와 애니악 컴퓨터가 큰 영향을 미쳤다. 애니악을 통해 stored-program 이 구현이 가능했다.
1980년대
프로그램을 작성하고 구동하는 방식이 발전하는 데는 IBM의 x86 아키텍처와 microprocessor 의 개발이 큰 영향을 미쳤다.
이 환경 하에서, assembly language, high level language 의 구현과 비약적인 발전이 가능했다.

image source : https://en.wikipedia.org/wiki/Turing_machine
- 최초의 컴퓨터라 불리는 튜링 머신
First concepts of what we consider a modern computer
The Turing machine was first proposed by Alan Turing in 1936 and became the foundation for theories about computing and computers. The machine was a device that printed symbols on paper tape in a manner that emulated a person following several logical instructions. Without these fundamentals, we wouldn't have the computers we use today.
1.1.2 Remote Procedure Call
컴퓨터는 많은 일을 사람보다 빠르게 처리할 수 있으므로, 그것이 수행할 명령어만 입력해주면 되었다. 그렇다면 물리적인 제약이 없으면 더 많은 사람들이 많은 일을 빠르게 처리할 수 있을 것이다.
따라서 컴퓨터 프로그램을 원격에서 호출할 수 있도록 하자는 아이디어가 RPC(remote procedure call) 이다.
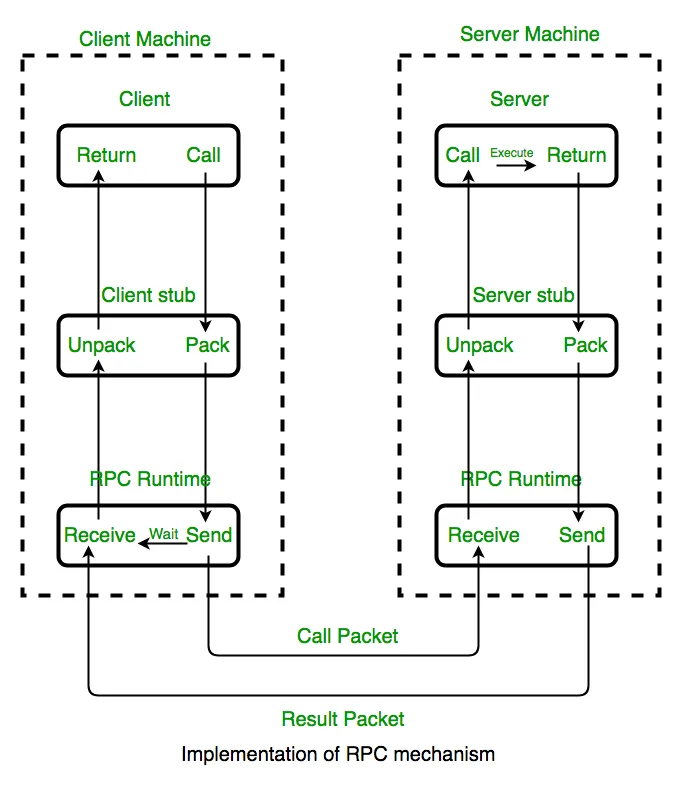
image source : https://aashikahamed.medium.com/remote-procedure-call-e1f2f9fb573d
(1980년대) RPC의 구현으로 Server-Client model(request-response protocol) 이 가능했다.
1.1.3 Database
컴퓨터의 계산능력이 검증되자, 더 많은 데이터를 처리하고자 했다. 또한 서버 클라이언트 모델이 가능하므로 서버에 대한 물리적인 위치의 제약이 사라졌다. 이런 환경에서 대용량 데이터 전문 처리장치를 개발하게 되었다.
이론적으로는 1970년대에 Relational Database Model/Management System 이 만들어졌고, 1980년대에 SQL의 표준 정립과 함께 IBM DB2가 상용 데이터베이스의 문을 열었다.
Database 의 등장으로 대량의 데이터를 빠르게 처리할 수 있었다. Database 시스템의 처리량은 Scale-Up을 통해 HW의 사이즈를 키우는 식으로 진행되었다.
1.1.4 3-Tier Architecture
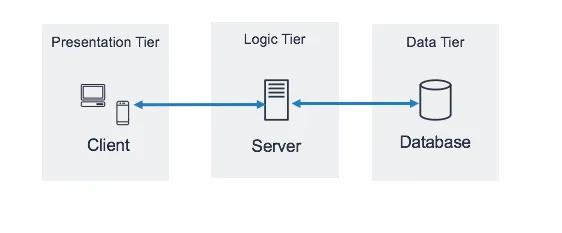
imagesource : https://docs.aws.amazon.com/images/whitepapers/latest/serverless-multi-tier-architectures-api-gateway-lambda/images/image2.png
{kind=link}
Remote Call 이 가능해지고, 데이터의 전문 처리 시스템인 Database 가 가능해짐으로 3 Tier Architecture 가 온라인(웹) 서비스 구현의 하나의 패턴이 되었다.
Presentation Tier 는 사용자 인터페이스의 영역의 기능을 할 수 있는 기술로 구성하고, Logic 에 대한 처리는 Application 서버에서, 그리고 데이터에 대한 처리는 Database로 나눠서 하자는 구조이다.
1.1.5 Web-Was-DB
Database를 통해서 데이터에 대한 저장과 처리를 집중화 시키고 효율을 높였다. 보통은 Application Server 에서는 사용자 요청을 받아주고, 데이터베이스에 데이터를 조회하고, 로직을 수행한 뒤 client에게 응답하는 구조였다.
온라인(웹) 서비스의 대부분의 요청을 보니 90% 이상이 정적인 데이터(변하지 않는 데이터)에 대한 요청이었다. 그래서 이 정적인 데이터에 대한 요청은 응답을 저장해두고 빠르게 처리하고, 실제 processing이 필요한 데이터만 Application Server, Database까지 전달해서 처리하자는 것이 3-Tier 아키텍처이다.
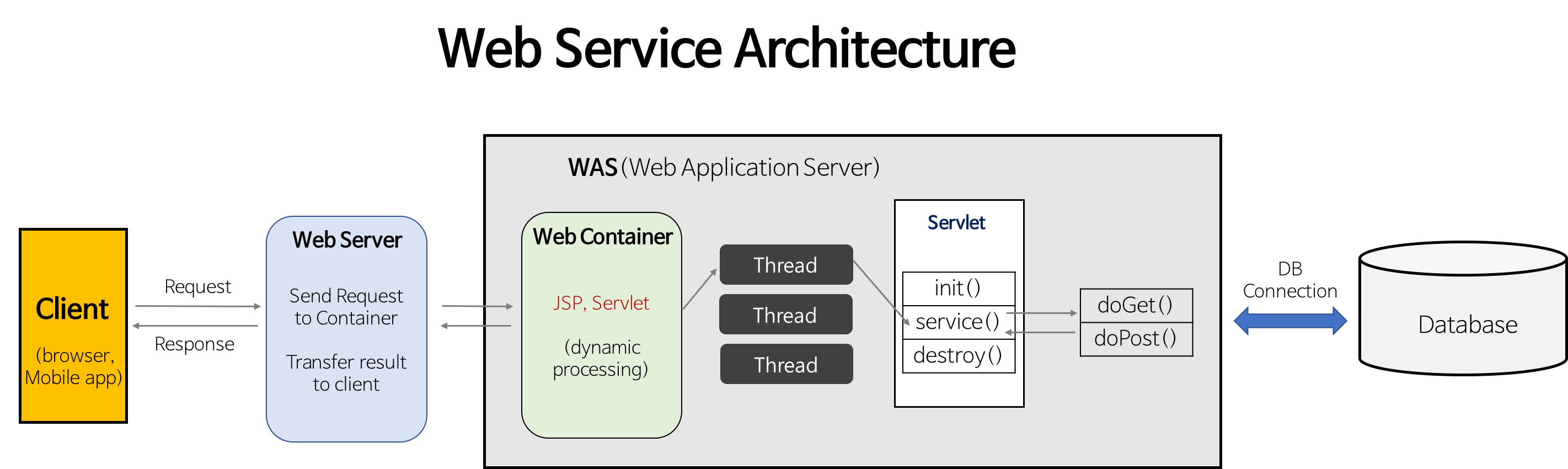
image source : https://gmlwjd9405.github.io/2018/10/27/webserver-vs-was.html
Web-Was-DB 아키텍처는 기존 구조 대비 다음과 같은 이점이 있다.
- 정적인 데이터에 대한 빠른 응답시간
- 어플리케이션 서버의 부하 감소
- 데이터베이스의 부하 감소
- Separate of Concern (Soc)
서버의 역할을 나누고, 단계별로 RPC의 처리를 이어가는 방식으로 문제를 해결했다. 단, 단일 병목점이 생긴다면 역시 scale-up으로 해결한다.
1.2 기존 방식의 한계
최초의 컴퓨터의 발전은 물리적인 사이즈를 줄이고, 프로그램의 작성과 수행방식을 편하게 하는 쪽으로 진행 되었다.
컴퓨터의 형태와 처리방식이 정해진 이후(폰노이만 아키텍처와, x86 등장 이후)로는 단일 컴퓨터의 처리방식의 효율화를 시키고, scale-up을 하는 방식으로 발전했다.
온라인 서비스가 확장 되면서 컴퓨터의 형태와 동작방식이 정해진 상태에서는 scale-up으로는 기하급수적으로 늘어나는 트래픽이나 데이터를 감당하지 못하게 되었다. 하드웨어의 성능은 시간에 따라 선형적으로 증가했다.(무어의법칙) 요구사항을 충족하지 못하는 문제를 해결해야했다. 이제 문제 해결방식은 하드웨어에서 소프트웨어로 넘어왔다.
1.3 분산 시스템이 필요한 이유
소프트웨어 개발자들은 scale-up 보다는 원격 처리 처리 장치의 수를 늘리는 scale out 전략을 생각했다. scale out을 하려면 상태를 공유하지 않아야 한다. 상태 공유를 한다면 위해 자원이 많이 소모되거나 불필요한 기술적 한계 지점이 발생했다.
단편적으로는, Application Server (remote processor)는 LoadBalancer 를 전처리 장치로 두면 상태 공유 없이 scale-out 확장하는 것이 가능했다. 하지만 온라인 서비스의 핵심이라고 할 수 있는 Database 는 대량의 데이터를 공유해야하기 때문에 쉽게 scale-out을 할 수 없었다. (Sharding 기능이 생기기 전)
따라서 데이터베이스를 중심으로 여러대의 서버로 scale-out 이 가능하면서도 상태와 데이터의 공유가 가능하고 user(client)가 사용하는 기능에는 변화가 없는 소프트웨어가 필요해졌다. (물론 데이터베이스가 아닌 시스템들도 분산시스템을 필요로 했다.)
