1. 데이터 분석과 통계
- 데이터 분석에 있어서 통계가 왜 중요한지를 배웁니다
- 기술통계와 추론통계에 대한 개념을 이해하고 각각의 차이점을 설명할 수 있습니다
- 통계분석 방법의 다양한 종류에 대해서 배웁니다
1.1. 데이터 분석에 있어서 통계가 중요한 이유
데이터 기반의 의사결정을 내릴 수 있음!
통계가 중요한 이유
데이터를 분석하고 이를 바탕으로 결정을 내릴 수 있습니다!
- 데이터 분석에서 통계는 데이터를 이해하고 해석하는 데 중요한 역할을 합니다
- 데이터를 요약하고 패턴을 발견할 수 있습니다
- 추론을 통해 결론을 도출화는 과정을 돕습니다
- 즉, 데이터 기반의 의사결정을 내릴 수 있습니다
- 결국 기업이 보다 현명한 결정을 내리고 수익을 창출하기 위해 필요합니다
통계를 활용한 데이터 분석은 필수!
실제로 통계가 어떻게 사용되어 질까요?
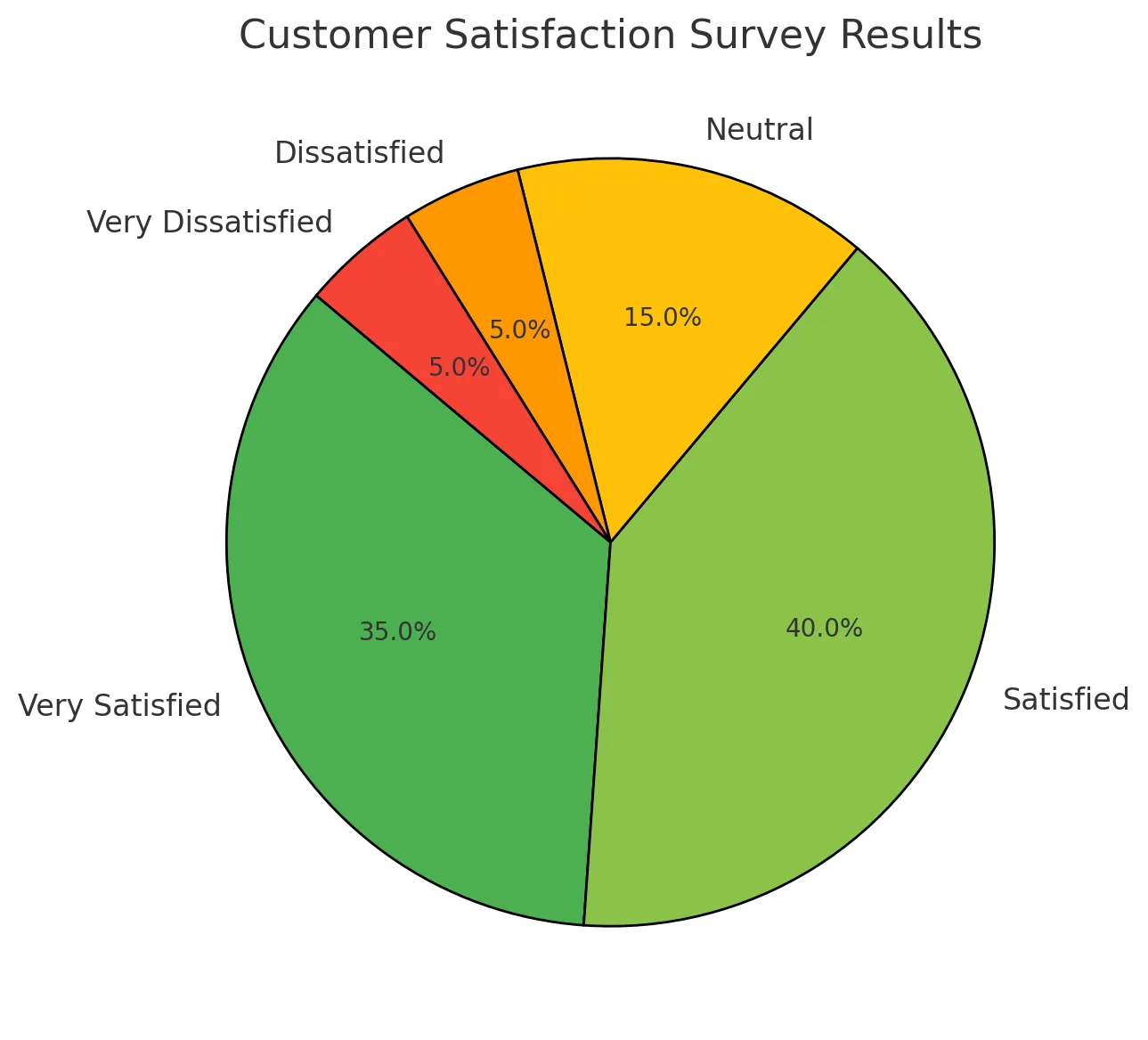
고객 만족도 설문조사 분석
설문 조사 중 고객의 불만 사항을 파악하고 이를 개선하는 데 활용할 수 있습니다.
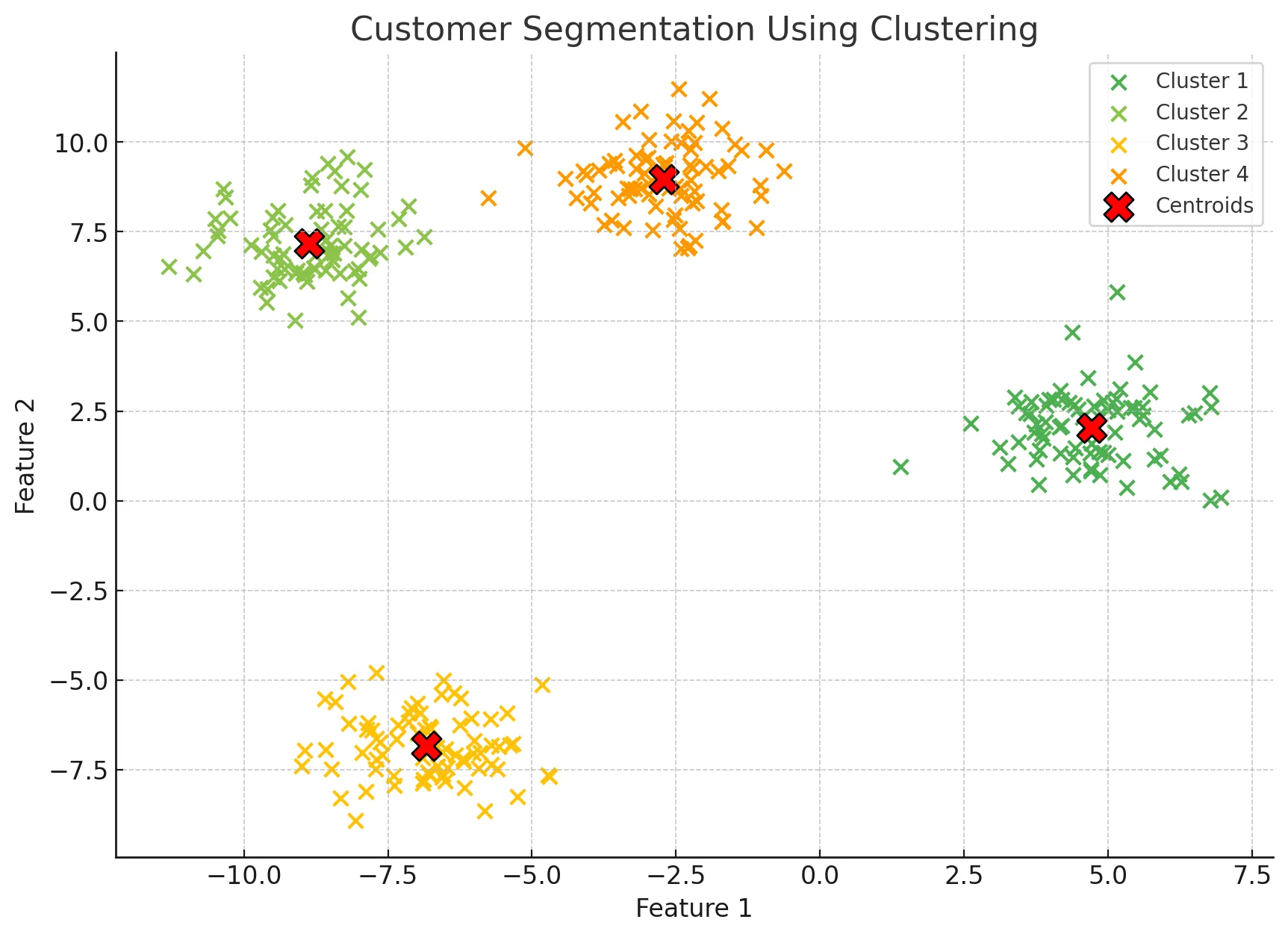
고객 유형별 세그먼트(Segment) 상품 추천
고객을 유형별로 나누어 특징을 파악하고 각 유형에 맞는 상품을 추천하는데 활용될 수 있습니다.
그 밖에도 다양한 상황에서 사용되어질 수 있습니다
- 기업의 전략을 수립하기 위해서
- 마케팅을 진행하기 위해서
- 신제품을 개발하기 위해서 등등
1.2. 기술통계와 추론통계
기술통계
데이터를 요약하고 설명하는 통계 방법
- 주로 평균, 중앙값, 분산, 표준편차 등을 사용합니다.
- 즉, 데이터를 특정 대표값으로 요약
- 데이터에 대한 대략적인 특징을 간단하고 쉽게 알 수 있음
- 단, 데이터 중 예외(이상치)라는게 항상 존재할 수 있고 데이터의 모든 부분을 확인할 수 있는 것은 아님
사람을 처음 만날 때 그 사람의 전체에 대해서 다 알 수는 없지만 기본적인 인적사항들(외모, 직업, 학력, 나이, MBTI 등)로 대략적으로 그 사람에 대한 요약을 할 수 있는 것과 같음 → 하지만 여러분들도 알다시피 대략적으로 파악할 수는 있지만 그 사람에 대한 전부를 확인한 것은 아니며 예외가 항상 존재할 수 있음
분산(Variance)이란?
- 분산은 데이터 값들이 평균으로부터 얼마나 떨어져 있는지를 나타내는 척도로, 데이터의 흩어짐 정도를 측정합니다.
- 분산이 크면 데이터가 넓게 퍼져 있고, 작으면 데이터가 평균에 가깝게 모여 있음을 의미합니다.
- 분산을 구하는 방법은 각 데이터 값에서 평균을 뺀 값을 제곱한 후, 이를 모두 더하고 데이터의 개수로 나누는 것입니다.
분산 계산 예시
예를 들어, 네 명의 학생이 받은 시험 점수가 70, 80, 90, 100이라고 가정합시다. 이들의 평균은 (70 + 80 + 90 + 100) / 4 = 85입니다.
각각의 데이터 값에서 평균을 뺀 값을 제곱하면 다음과 같습니다:
- (70 - 85)^2 = 225
- (80 - 85)^2 = 25
- (90 - 85)^2 = 25
- (100 - 85)^2 = 225
이 값을 모두 더한 후 데이터의 개수로 나누면,
분산 = (225 + 25 + 25 + 225) / 4 = 125가 됩니다.
표준편차(Standard Deviation)?
- 표준편차는 데이터 값들이 평균에서 얼마나 떨어져 있는지를 나타내는 통계적 척도로, 분산의 제곱근을 취하여 계산합니다.
- 표준편차는 데이터의 변동성을 측정하며, 값이 클수록 데이터가 평균으로부터 더 넓게 퍼져 있음을 의미합니다.
표준편차 계산 예시
네 명의 학생이 받은 시험 점수가 70, 80, 90, 100이라고 가정합니다. 이들의 평균은 85입니다.
- (70 - 85)^2 = 225
- (80 - 85)^2 = 25
- (90 - 85)^2 = 25
- (100 - 85)^2 = 225
(여기까지는 분산 계산과 동일함)
분산은 (225 + 25 + 25 + 225) / 4 = 125입니다. 표준편차는 분산의 제곱근이므로 분산에 루트(root)를 씌워 약 11.18입니다.
표준편차와 분산의 관계
- 분산과 표준편차는 동일하게 데이터의 변동성을 측정하는 두 가지 주요 척도입니다.
- 두 개념은 밀접하게 연관되어 있으며, 표준편차는 분산의 제곱근입니다.
- 분산은 데이터 값과 평균의 차이를 제곱하여 평균을 낸 값이기 때문에 제곱 단위로 표현되지만, 표준편차는 다시 제곱근을 취하여 원래 데이터 값과 동일한 단위로 변환합니다.
추론통계
표본 데이터를 통해 모집단의 특성을 추정하고 가설을 검정하는 통계 방법.
- 주로 신뢰구간, 가설검정 등을 사용합니다.
- 즉, 데이터의 일부를 가지고 데이터 전체를 추정하는 것이 핵심
ex) 비록 그 사람의 인생 전체를 다 본 것은 아니지만 대화를 진행하는 시간 동안 얻어낸 정보로 그 사람이 어떤 사람일지 알아가는 것과 같음
신뢰구간 (Confidence Interval)
- 신뢰구간은 모집단의 평균이 특정 범위 내에 있을 것이라는 확률을 나타냅니다.
- 일반적으로 95% 신뢰구간이 사용되며, 이는 모집단 평균이 95% 확률로 이 구간 내에 있음을 의미합니다.
- 만약 어떤 설문조사에서 평균 만족도가 75점이고, 신뢰구간이 70점에서 80점이라면, 우리는 95% 확률로 실제 평균 만족도가 이 범위 내에 있다고 말할 수 있습니다.
가설검정 (Hypothesis Testing)
- 가설검정은 모집단에 대한 가설을 검증하기 위해 사용됩니다. 일반적으로 두 가지 가설이 있으며, 귀무가설(H0)은 검증하고자 하는 가설이 틀렸음을 나타내는 기본 가설(변화가 없다, 효과가 없다 등)이고, 대립가설(H1)은 그 반대 가설로 주장하는 바를 나타냅니다(변화가 있다, 효과가 있다 등)입니다. p-value를 통해 귀무가설을 기각할지 여부를 결정합니다.
- 예를 들어, 새로운 교육 프로그램이 학생들의 성적에 영향을 미치는지 알고 싶다면, 귀무가설은 "프로그램이 성적에 영향을 미치지 않는다"이고, 대립가설은 "프로그램이 성적에 영향을 미친다"입니다.
실제로 기술통계와 추론통계가 어떻게 사용되어 질까요?
-
기술통계
회사의 매출 데이터를 요약하기 위해 평균 매출, 매출의 표준편차 등을 계산 -
추론통계
일부 고객의 설문조사를 통해 전체 고객의 만족도를 추정
1.3. 다양한 분석 방법
위치추정
데이터의 중심을 확인하는 방법!
- 평균, 중앙값이 대표적인 위치 추정 방법입니다
- ex) 학생들의 시험 점수에서 평균 점수, 중간 점수를 계산
변이추정
데이터들이 서로 얼마나 다른지 확인하는 방법!
분산, 표준편차, 범위(range) 등을 사용합니다
범위란?
- 범위는 데이터셋에서 가장 큰 값과 가장 작은 값의 차이를 나타내는 간단한 분포의 측도입니다.
- 범위를 통해 데이터가 어느 정도의 변동성을 가지는지 쉽게 파악할 수 있습니다.
- 범위는 계산이 간단하여 기본적인 데이터 분석에서 자주 사용됩니다.
수식
범위(R) = 최대값 - 최소값
범위 계산 예시
예를 들어, 다섯 명의 학생이 받은 시험 점수가 60, 70, 80, 90, 100이라고 가정합시다.
- 최대값은 100
- 최소값은 60.
따라서 범위는100 - 60 = 40입니다.
ex) 매출 데이터의 변이를 분석하여 비즈니스의 안정성을 평가
데이터 분포 탐색
데이터의 값들이 어떻게 이루어져 있는지 확인하기
- 히스토그램과 상자 그림(Box plot)은 데이터의 분포를 시각적으로 표현하는 대표적인 방법입니다.
- ex) 시험 점수의 분포를 히스토그램과 상자 그림으로 표현
이진 데이터와 범주 데이터 탐색
데이터들이 서로 얼마나 다른지 확인하는 방법!
- 최빈값(개수가 제일 많은 값)을 주로 사용합니다
- 파이그림과 막대 그래프는 이진 데이터와 범주 데이터의 분포를 표현하는 대표적 방법입니다.
- ex) 고객 만족도 설문에서 만족/불만족의 빈도 분석
상관관계
데이터들끼리 서로 관련이 있는지 확인하는 방법!
- 상관계수는 두 변수 간의 관계를 측정하는 방법입니다.
- 상관계수를 계산해서 -1이나 1에 가까워지면 강력한 상관관계를 가집니다.
- -0.5나 0.5를 가지면 중간정도의 상관관계를 가집니다.
- 0에 가까울 수록 상관관계가 없습니다.
ex) 공부 시간과 시험 점수 간의 상관관계를 분석
여기서 잠깐! 인과관계와 상관관계의 차이
인과관계는 상관관계와는 다르게 원인, 결과가 분명해야 함!
상관관계는 두 변수 간의 관계를 나타내며, 인과관계는 한 변수가 다른 변수에 미치는 영향을 나타낸다.
ex) 아이스크림 판매량과 익사 사고 수 간의 상관관계는 높지만, 인과관계는 아님.
두 개 이상의 변수 탐색
여러 데이터들끼리 서로 관련이 있는지 확인
- 다변량 분석은 여러 변수 간의 관계를 분석하는 방법입니다.
- ex) 여러 마케팅 채널의 광고비와 매출 간의 관계 분석
1.4. 연습문제
1번
데이터 분석에서 통계가 중요한 이유는 무엇인가요? 다음 보기 중에서 옳지 않은 것을 고르세요
1) 통계는 데이터를 이해하고 해석하는 데 도움을 준다.
2) 통계는 데이터에서 패턴을 발견하고 미래를 예측하는 도구를 제공한다.
3) 통계는 모든 데이터 분석 결과가 항상 정확하고 확실하다는 것을 보장한다.
4) 통계는 복잡한 데이터를 간단한 요약 정보로 변환할 수 있다.
통계는 확률과 추론에 기초하기 때문에 항상 불확실성이 존재합니다.
2번
다음 중 기술통계(Descriptive Statistics)에 해당하는 것은 무엇인가요?
1) 모집단의 평균을 추정하는 것
2) 데이터의 중앙값을 계산하는 것
3) 표본을 통해 모집단의 특성을 추론하는 것
4) 가설을 검증하는 것
기술통계는 데이터를 요약하고 설명하는 데 중점을 둡니다. 반면, 추론통계는 표본 데이터를 사용하여 모집단에 대한 결론을 내리는 과정입니다.
3번
다음 중 추론통계(Inferential Statistics)에 해당하는 것은 무엇인가요?
1) 데이터의 범위를 계산하는 것
2) 데이터의 분산을 계산하는 것
3) 표본을 기반으로 모집단의 평균을 추정하는 것
4) 데이터의 최빈값을 계산하는 것
추론통계는 표본 데이터를 사용하여 모집단에 대한 결론을 도출하는 과정입니다.
4번
어느 학교의 학생들 10명의 수학 점수는 다음과 같습니다: 78, 82, 85, 88, 90, 92, 94, 96, 98, 100. 이 데이터의 평균을 구하세요.
평균은 90.3
5번
4번 문제의 학생 수학 점수의 중앙값을 구하세요.
91.0
6번
4번 문제의 학생 수학 점수 데이터의 범위(Range)를 구하세요.
범위는 데이터의 최대값에서 최소값을 뺀 값입니다.
100 - 78 = 22
7번
학생들의 수학 점수와 영어 점수가 각각 다음과 같을 때, 두 변수 간의 상관관계가 양의 상관관계인지, 음의 상관관계인지, 상관관계가 없는지 설명하고 그 이유를 얘기하세요.
1. 수학 점수: 78, 82, 85, 88, 90, 92, 94, 96, 98, 100.
2. 영어 점수: 70, 75, 80, 85, 85, 90, 90, 95, 95, 100.
정답
- 양의 상관관계를 가짐.
- 수학 점수가 증가할 때 영어 점수도 증가하는 경향이 있.
8번
다음 중 인과관계(Causation)와 상관관계(Correlation)의 차이에 대한 설명으로 옳은 것은 무엇인가요
1) 상관관계는 두 변수 간의 원인과 결과를 나타내고, 인과관계는 단순한 관계를 나타낸다.
2) 인과관계는 두 변수 간의 원인과 결과를 나타내고, 상관관계는 두 변수 간의 관계가 있지만 원인과 결과를 나타내지 않는다.
3) 상관관계와 인과관계는 동일한 개념이다.
4) 인과관계는 두 변수 간의 단순한 관계를 나타내고, 상관관계는 두 변수 간의 원인과 결과를 나타낸다.
정답 및 해설
2) 인과관계는 두 변수 간의 원인과 결과를 나타내고, 상관관계는 두 변수 간의 관계가 있지만 원인과 결과를 나타내지 않는다.
- 인과관계는 하나의 변수가 다른 변수에 직접적인 영향을 미치는 것을 의미하며, 상관관계는 두 변수 간의 관계를 나타내지만, 직접적인 영향을 의미하지는 않습니다.
