가설검정의 주의점
[수업 목표]
- 가설검정의 다양한 주의점에 대해 이해한다
- 이러한 주의점들을 참고하여 가설검정을 진행할 수 있다
6.1 재현 가능성
우연히 결과가 나오는 것이 아닌, 항상 일관된 결과가 나오는지 확인해야 함
1) 재현가능성이란 무엇인가?
재현 가능성
- 동일한 연구나 실험을 반복했을 때 일관된 결과가 나오는지 여부. 연구의 신뢰성을 높이는 중요한 요소
- ex) 신약을 개발할 때 실험실에서만 효과가 있는 것이 아니라 실제 상황에서도 일관된 결과가 나온다고 믿을 수 있기 때문에 개발 가능한 것
- 최근 p값에 대한 논쟁이 두드러지고 있음
- p값을 사용하지 않는 것이 좋다
- 유의수준을 0.05에서 변경하는 것이 좋다
- 가설검정 원리상의 문제나 가설검정의 잘못된 사용이 낮은 재현성으로 이어진다는 문제 발생
- 최근 논문을 다시 재현해서 실험을 해보는데 똑같은 결과가 않나오는 사례가 많은… 재현성 위기가 문제가 되고 있음
중요성
- 결과가 재현되지 않는다면 해당 가설의 신뢰도가 떨어짐
2) 재현성 위기의 원인은 무엇인가~?
실험 조건을 동일하게 조성하기 어려움
- 완전 동일하게 다시 똑같은 실험을 수행하는 것이 쉽지 않음
- 또한 가설검정 자체도 100% 검정력을 가진 것이 아니기 때문에 오차가 나타날 수 있음
가설검정 사용방법에 있어서 잘못됨
- p값이 0.05가 유도되게끔 조작하는 것이 가능 (p해킹)
- 실제로는 통계적으로 아무 의미가 없음에도 의미가 있다고 해버리는 1종 오류를 저지를 수 있음
- 0.05라는 것은 100번 중에 5번 즉, 20번 중에 1번은 귀무가설이 옳음에도 불구하고 기각될 수 있음
- 유의수준으로 통제하는 것이 중요
- 하지만, 유의수준을 너무 낮추면 베타값이 커져버리는 문제 발생…
- 따라서, 어떤 논문에서는 유의수준을 0.005로 설정하면서 데이터 수를 70% 더 늘려서 베타 값도 컨트롤 하는 방향을 제안하기도 함
- 잘못된 가설을 세우더라도 우연히 0.05보다 낮아서 가설이 맞는것처럼 보일 수도 있음. 따라서 가능한 좋은 가설을 세우는 것도 중요
6.2 p-해킹
인위적으로 p-값을 낮추지 않을 수 있도록 조심해야 합니다!
1) p-해킹이란 무엇인가?
p-해킹
- 데이터 분석을 반복하여 p-값을 인위적으로 낮추는 행위
- 유의미한 결과를 얻기 위해 다양한 변수를 시도하거나, 데이터를 계속해서 분석하는 등의 방법을 포함
문제점
- p-해킹은 데이터 분석 결과의 신뢰성을 저하시킴
2) p-해킹은 언제 조심해야하는가?
여러 가설 검정을 시도 할 때
- 여러 가설 검정을 시도하여 유의미한 p-값을 얻을 때까지 반복 분석하는 것을 조심
- p-해킹은 유의미한 결과를 얻기 위해 p-값이 0.05 이하인 결과만 선택적으로 보고하는 행위를 조심
- 데이터의 수를 늘리다보니 특정 데이터 수를 기록할때 잠깐 p값이 0.05 이하를 기록함으로 이를 바탕으로 대립가설 채택하는 것을 조심
- 즉, 결과를 보며 데이터 개수를 늘려서는 안됨
- 다양한 상황 중에서 p값이 유리하게 나오는 상황만 선별적으로 보고하는 것을 조심
- 다양한 변수를 건드리며 유리한 결과가 나올 때 다시 처음 부터 가설을 그 결과에 맞게 세우는 것
- 즉, 마음에 드는 상황만 골라서 보고해서도 안됨. 모든 결과를 다보고하거나 더 엄격한 추가실 험을 수행
- 가능한 가설을 미리 세우고 검증하는 가설검증형 방식으로 분석을 해야 하며 만약 탐색적으로 분석한 경우 가능한 모든 변수를 보고하고 본페로니 보정과 같은 방법을 사용해야 함
6.3 선택적 보고
말 그대로 선택적으로 보고하는 것!
1) 선택적 보고란 무엇인가?
선택적 보고
- 유의미한 결과만을 보고하고, 유의미하지 않은 결과는 보고하지 않는 행위
- 이는 데이터 분석의 결과를 왜곡하고, 신뢰성을 저하시킴
그림으로 확인하기!
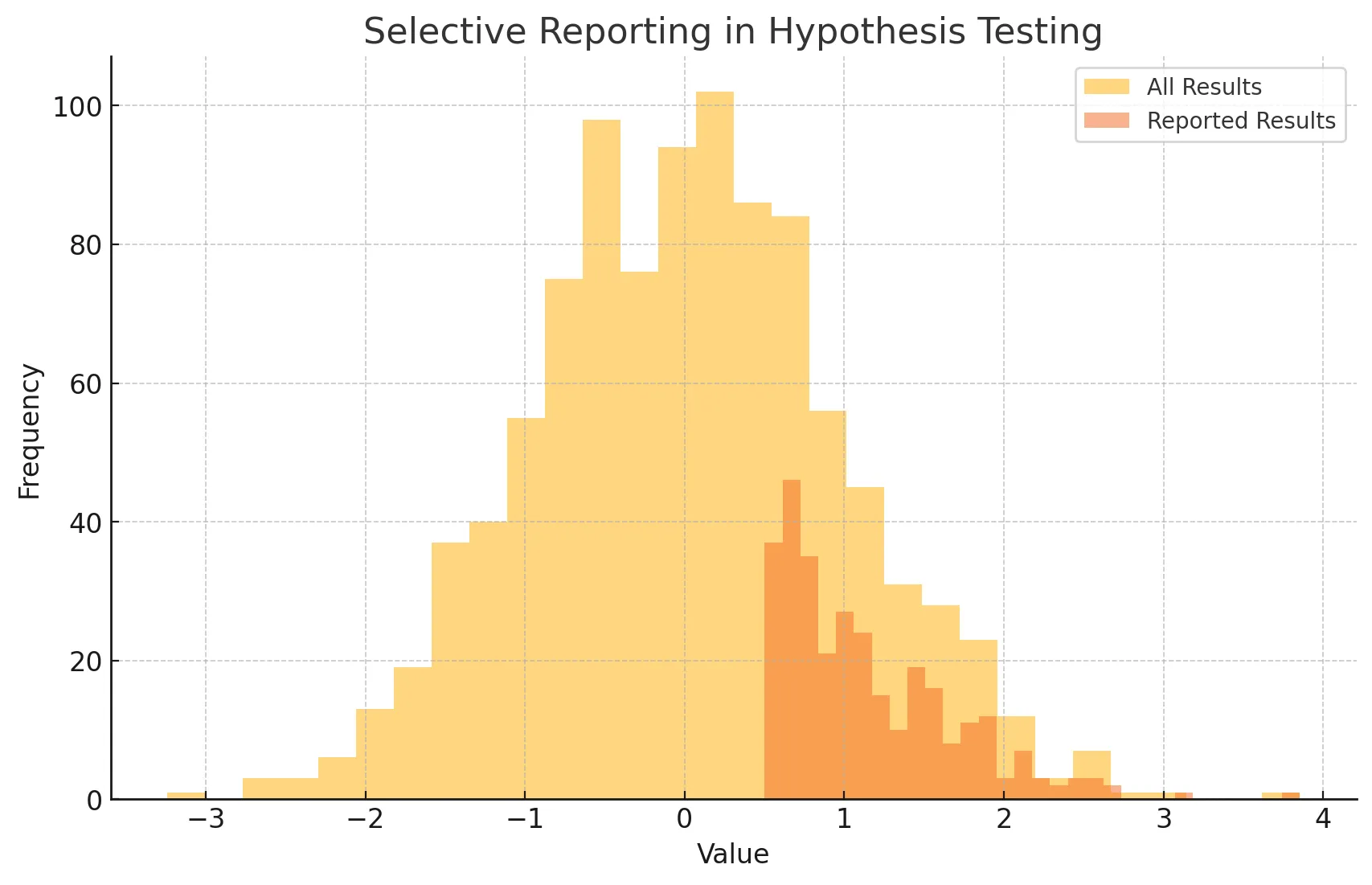
- 모든 결과와 선택적으로 보고된 결과를 히스토그램으로 나타냄
- 전체 결과와 보고된 결과의 분포가 다르면 선택적 보고의 가능성을 시사
2) 선택적 보고는 언제 조심해야하는가?
유의미한 결과만 공개 할 때
- 다수의 데이터 분석 중 유의미한 결과가 나온 실험만을 보고서에 작성하여 발표
결과를 보면서 가설을 다시 새로 설정했는데 마치 처음부터 설정한 가설이라고 얘기할 때
- 미리 가설과 실험 방법등에 대해서 설정을 한다음 연구를 수행하거나 연구하는 동안 얻어진 모든 변수와 결과에 대해서 공개하지 못할 때
6.4 자료수집 중단 시점 결정
원하는 결과가 나올 때 까지 자료를 수집하는 것을 조심!
1) 자료수집 중단 시점 결정이란 무엇인가?
자료수집 중단 시점 결정
- 데이터 수집을 시작하기 전에 언제 수집을 중단할지 명확하게 결정하지 않으면, 원하는 결과가 나올 때까지 데이터를 계속 수집할 수 있음. 이는 결과의 신뢰성을 떨어뜨림.
그림으로 확인하기!
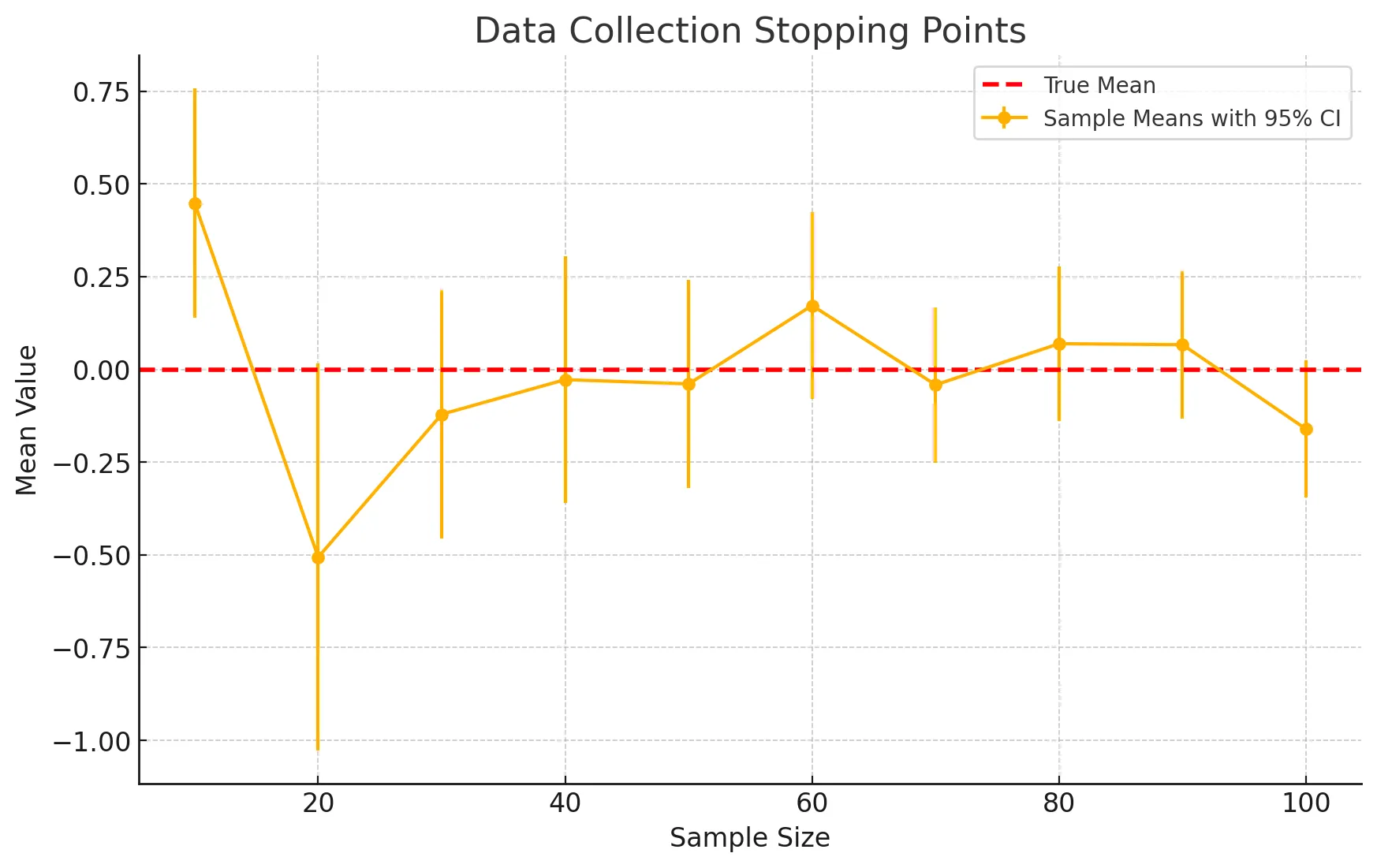
- 샘플 크기에 따른 평균값과 95% 신뢰구간을 나타낸 그래프
- 데이터 수집을 언제 멈출지 결정하는 것은 결과에 영향을 미칠 수 있음
- 이상적으로는 사전에 정해진 계획에 따라야 함
2)자료수집 중단 시점은 언제 조심해야하는가?
결과를 이미 정해놓고 그에 맞추기 위해 자료수집을 하고자 할 때
- 50명의 데이터를 수집하기로 했으나, 원하는 결과가 나오지 않자 100명까지 추가로 수집
파이썬 실습
# 데이터 수집 예시
np.random.seed(42)
data = np.random.normal(0, 1, 1000)
sample_sizes = [10, 20, 30, 40, 50, 100, 200, 300, 400, 500]
p_values = []
for size in sample_sizes:
sample = np.random.choice(data, size)
_, p_value = stats.ttest_1samp(sample, 0)
p_values.append(p_value)
# p-값 시각화
plt.plot(sample_sizes, p_values, marker='o')
plt.axhline(y=0.05, color='red', linestyle='dashed', linewidth=1)
plt.title('자료수집 중단 시점에 따른 p-값 변화')
plt.xlabel('샘플 크기')
plt.ylabel('p-값')
plt.show()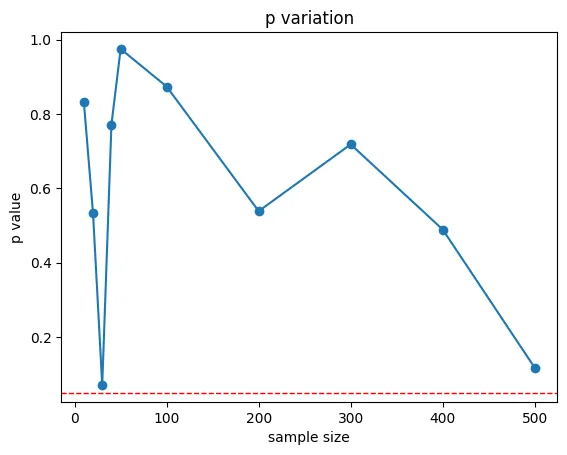
6.5 데이터 탐색과 검증 분리
검증하기 위한 데이터는 반드시 따로 분리 해놓아야 함!
1) 데이터 탐색과 검증 분리란 무엇인가?
데이터 탐색과 검증 분리
- 데이터 탐색을 통해 가설을 설정하고, 이를 검증하기 위해 별도의 독립된 데이터셋을 사용하는 것
- 이는 데이터 과적합을 방지하고 결과의 신뢰성을 높임
그림으로 확인하기!
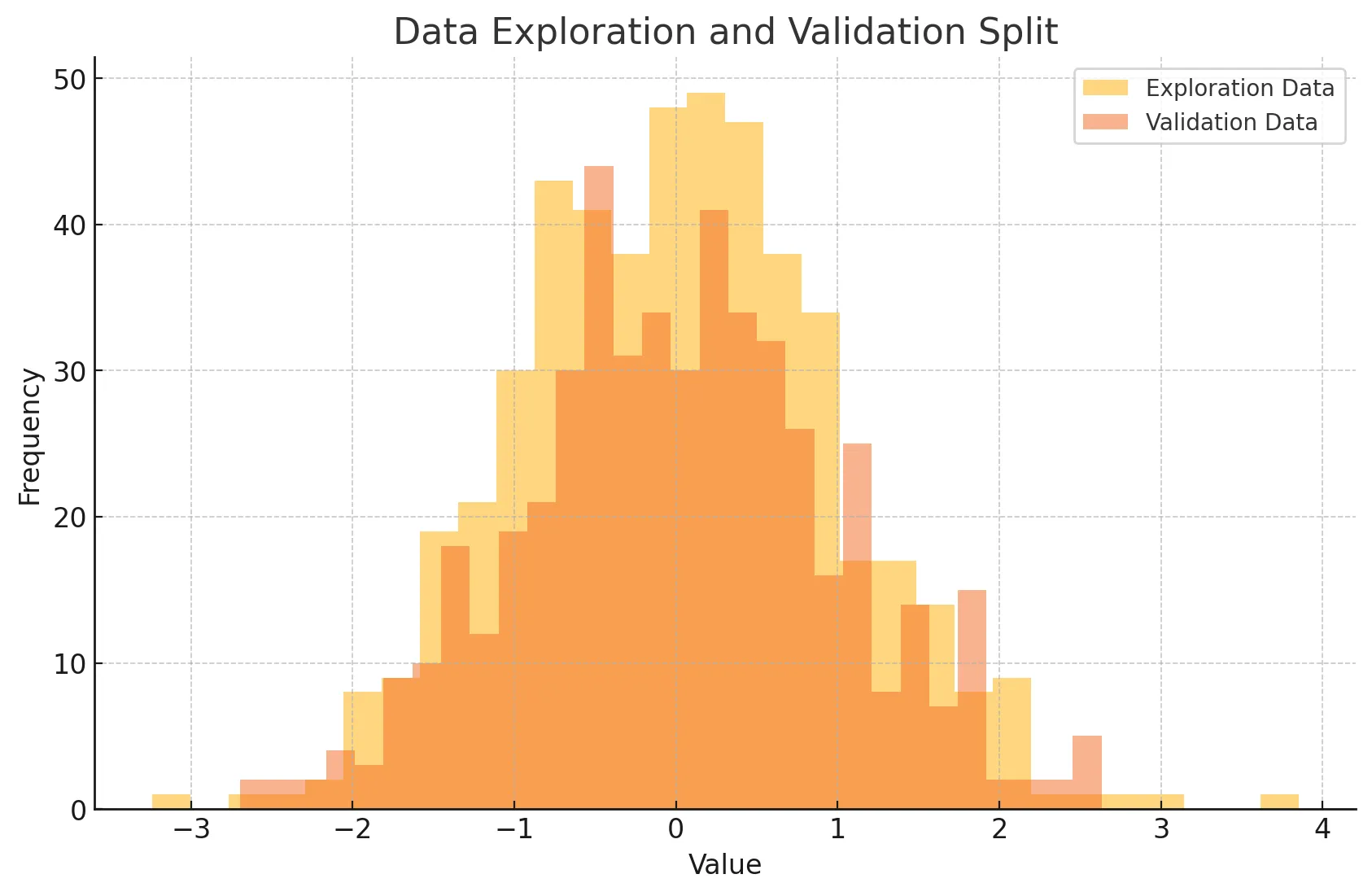
- 탐색 데이터와 검증 데이터를 히스토그램으로 나타냄
- 데이터 탐색과 검증을 분리하면 탐색 과정에서 발견된 패턴이 검증 데이터에서도 유효한지 확인 가능
- 검증 데이터는 철저하게 탐색 데이터와 구분되어져야 함
2)데이터 탐색과 검증 분리는 언제 사용해야하는가?
검증하기 위한 데이터가 따로 필요할 때
- 데이터셋을 탐색용(training)과 검증용(test)으로 분리하여 사용
파이썬 실습
from sklearn.model_selection import train_test_split
# 데이터 생성
np.random.seed(42)
X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1)
# 데이터 분할 (탐색용 80%, 검증용 20%)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 모델 학습
model = LinearRegression()
model.fit(X_train, y_train)
# 탐색용 데이터로 예측
y_train_pred = model.predict(X_train)
# 검증용 데이터로 예측
y_test_pred = model.predict(X_test)
# 탐색용 데이터 평가
train_mse = mean_squared_error(y_train, y_train_pred)
train_r2 = r2_score(y_train, y_train_pred)
print(f"탐색용 데이터 - MSE: {train_mse}, R2: {train_r2}")
# 검증용 데이터 평가
test_mse = mean_squared_error(y_test, y_test_pred)
test_r2 = r2_score(y_test, y_test_pred)
print(f"검증용 데이터 - MSE: {test_mse}, R2: {test_r2}")6.6 추가로 통계학을 공부하기 위하여
다양한 통계학 자료 추천
- 여인권 교수님의 기초통계학
- 고지마 히로유키, 세상에서 가장 쉬운 통계학 입문
- https://m.blog.naver.com/ahnsfarm/222164446352 - 아베 마사토, 통계 101 x 데이터 분석
6.7 연습문제
이번에 배운 내용을 다시 정리하기 위해 연습문제를 풀어봅시다! (정답 해설을 보지 않고 풀어보세요!)
-
재현 가능성(reproducibility)에 대한 설명으로 옳은 것을 고르세요.
1) 재현 가능성은 동일한 연구자가 동일한 실험을 여러 번 수행하여 동일한 결과를 얻는 것을 의미한다.
2) 재현 가능성은 다른 연구자가 동일한 실험 절차를 따라 실험을 수행하여 동일한 결과를 얻는 것을 의미한다.
3) 재현 가능성은 데이터 분석 과정에서 발생하는 오류를 줄이기 위한 방법이다.
4) 재현 가능성은 통계 분석의 정확성을 평가하는 기준이다.
정답 및 해설
- 정답은 2번
- 재현 가능성은 (내가 아닌)다른 연구자가 동일한 실험 절차를 따라 실험을 수행하여 동일한 결과를 얻는 것을 의미합니다. 이는 연구 결과의 신뢰성을 높이는 중요한 요소입니다.
-
p-해킹(p-hacking)의 정의에 가장 가까운 것을 고르세요.
1) 통계 분석에서 발생하는 오류를 수정하는 과정
2) 연구자가 원하는 결과를 얻기 위해 데이터를 반복적으로 분석하고 p-value를 조작하는 행위
3) 데이터를 시각화하여 결과를 해석하는 과정
4) 데이터를 수집하고 분석하는 표준 절차
정답 및 해설
- 정답은 2번
- p-해킹은 연구자가 원하는 결과를 얻기 위해 데이터를 반복적으로 분석하고 p-value를 조작하는 행위로, 이는 연구 결과의 신뢰성을 저해할 수 있습니다.
-
선택적 보고(selective reporting)이 문제인 이유로 가장 적절한 것을 고르세요.
1) 연구자가 모든 데이터를 수집하지 못할 수 있다.
2) 연구자가 연구 결과를 왜곡하여 보고할 수 있다.
3) 연구자가 데이터를 분석하는 방법을 모를 수 있다.
4) 연구자가 통계적 방법을 사용할 수 없다.
정답 및 해설
- 정답은 2번
- 선택적 보고는 연구자가 자신에게 유리한 결과만을 선택적으로 보고하는 행위로, 이는 연구 결과의 왜곡을 초래할 수 있습니다.
-
자료수집 중단 시점을 결정할 때 발생할 수 있는 문제는 무엇인가요?
1) 데이터 수집 비용이 증가한다.
2) 데이터의 신뢰도가 높아진다.
3) 연구자의 편향이 결과에 영향을 미칠 수 있다.
4) 데이터의 다양성이 감소한다.
정답 및 해설
- 정답은 3번
- 자료수집 중단 시점을 연구자가 임의로 결정할 경우, 연구자의 편향이 결과에 영향을 미칠 수 있습니다. 이는 연구의 신뢰성을 떨어뜨릴 수 있습니다.
-
데이터 탐색(exploration)과 검증(validation)을 분리하는 이유로 가장 적절한 것을 고르세요.
1) 데이터 탐색과 검증을 분리하면 데이터 분석 과정이 단순해진다.
2) 데이터 탐색과 검증을 분리하면 데이터 분석 과정에서 발생하는 오류를 줄일 수 있다.
3) 데이터 탐색과 검증을 분리하면 과적합(overfitting)을 방지하고 모델의 일반화 성능을 높일 수 있다.
4) 데이터 탐색과 검증을 분리하면 데이터 수집 비용을 절감할 수 있다.
정답 및 해설
- 정답은 3번
- 데이터 탐색과 검증을 분리하면 과적합을 방지하고, 모델이 새로운 데이터에 대해 얼마나 잘 일반화될 수 있는지를 평가할 수 있습니다.
