초반 로직 접근에 대해 어떤 식으로 해야할지 감을 잡지 못 해서 문의를 드린 후,
다시 수업으로 돌아가서 상위 요소에 대해 개념을 공부했다.
DOM 강의를 들을때 트위틀러(twittler)를 구현하면서 CRUD에 초점을 맞추다보니
구조 조회에 접근하는 방식 자체를 가볍게 생각하고 넘어간 것 같았다.(과거의 나 왜그랬..)
1.어떻게 접근해야할까?
일단 우리의 주 목표를 설정한다.
- document 안에서 내가 제시한 className만 찾고 싶다.
<body class='Bodyclass'>
<div class='Myclass'>
<p>
<p class='Myclass'></p>
</p>
</div>
<div class='Yourclass'>
<p>
<p class='Yourclass'></p>
</p>
</div>
</body>이를테면 위와같은 형식일 때, MyClass를 가지는 요소를 찾는다고 하면, div와 마지막 p가 되므로 이것을 꺼내오고 싶은 로직을 짜야한다.
- body → 첫번째 div → 첫번째 div 안의 첫번째 p 요소 → 첫번째 div 안의 첫번째 p 안의 p 요소...
라는 흐름으로 탐색경로를 짜게 될 것인데
주목표를 조금 세분화 시켜보면
1) 부모로 시작해서 className을 탐색한다.
2) 부모가 가진 자식 요소를 전체적으로 탐색해야한다.
3) 내가 제시한 className을 갖고 있는 자식 요소를 찾았으면
4) 결과에 담아내야한다
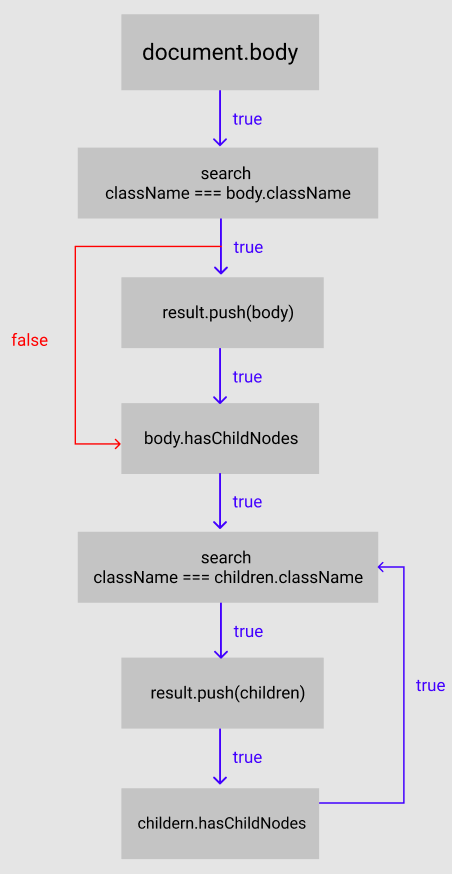
그럼 위와같은 흐름으로 로직을 짤 수 있다.
근데 여기서 반복적으로 일어나는 것은 어떤 것이고, 어느 부분에서 재귀함수를 짜야할까?
바로 "검색하는 요소가 className을 갖고 있으면 결과를 담아라"라는 부분이다.
2.알고리즘을 만들어보자.
위에서 어느정도 흐름에 대해 이해가 되었다면 정확한 알고리즘을 작성한다.
1) 최상위 요소와 결과를 담을 변수를 설정한다.
: 편의를 위해 최상위 요소 변수를 담는데 원치않으면 생략해도 된다.
2) 함수 안에 요소를 넣어 className이 동일한지 검색한다.
3) className이 동일하면 결과 변수에 값을 담아준다.
4) 들어온 요소에 자식 요소가 있는지 확인한다.
5) 자식 요소가 존재한다면, 2)를 반복한다.
6) 모든 검색이 끝나면 결과를 나타낸다.
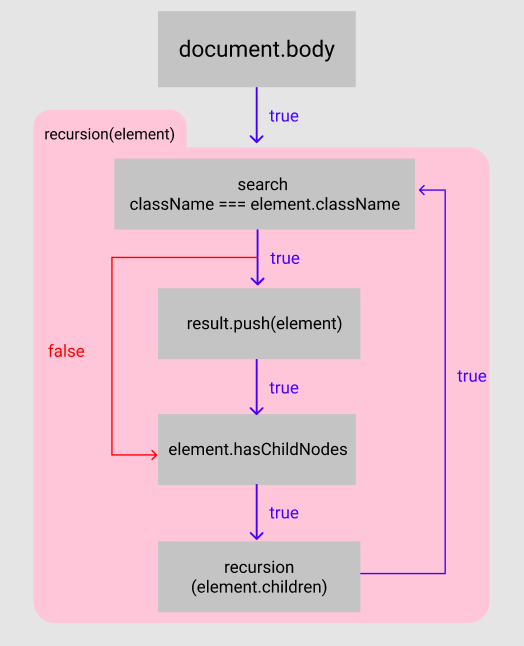
이러한 흐름을 이용하여 바탕으로 결과를 나타내면 된다.
3.코드를 짜기 전 생각해고 넘어가야할 부분
- document.body 가 자식을 가지고 있는지 어떻게 알아낼 수 있을까?
- 자식요소가 classname을 갖고 있는 것을 어떻게 알아낼 수 있을까?
참고사이트
getElementsByClassName - MDN
document.body - MDN
document.body.children - W3School
The HTML DOM Element Object - W3SChool
