
1.자료구조 정의
- 여러 데이터들의 묶음을 어떻게 저장하고 사용할지 정의하며, 특정한 상황에 문제를 해결하는데 사용된다.
- 자료(Data) : 문자,숫자,그림 등의 형태로 된 의미 단위
- 컴퓨터의 언어
- 명령/데이터, 0과 1만 이해(이진수)
- 기계어/번역기등장(컴파일러)
데이터 타입(Data Type)
- 하나의 데이터를 어떻게 해석할지 정의
- 비트 8를 조합한 1byte단위로 데이터를 읽는다.(대표 - 아스키코드)
- 컴퓨터에 0,1로 저장되어 있는 데이터를 인간이 사용하는 여러 데이터들의 종류로 해석하기 위한 장치
- 같은 이진 데이터라도 인간의 해석에 따라 다른 데이터가 될 수 있음
- 원시타입( 정수,실수,문자,논리값 등) / 사용자 정의타입 ( 구조체, 클래스 등)
2. 스택/큐(Stack, Queue)
1) 스택(Stack)
- 쌓여있는 접시 더미와 같이 작동 = 푸쉬다운 운동
- 후입선출(LIFO : last in, first out) - 맨 위에 있는 데이터 즉, 제일 마지막에 저장한 데이터를 제일 먼저 꺼낸다.

- Top(최근에 들어온 데이터) : 데이터의 수에 따라 유동적으로 변한다. 이곳에서만 삽입/삭제/읽기 동작이 발생한다.
① 스택의 기능
- 삽입 push : 새로운 데이터를 삽입하는 작업으로 데이터가 들어오면 top값이 증가
- 삭제 pop : top이 가리키는 자료를 삭제 후, top의 값도 감소된다.
- 읽기 peek : top이 가리키는 데이터를 읽는 작업으로 top 값에는 변화가 없다.

② 스택의 실생활 사례
- 웹브라우저 방문기록(뒤로가기)
- 실행취소(가장 나중에 실행된 것부터 취소)
- 책더미
- 프링글스
추가적 고민요소
- 배열을 이용한 스택
- 연결리스트를 이용한 스택
2) 큐(Queue)
- 데이터의 제거는 가장 앞에서 수행되고, 데이터의 삽입은 가장 뒤에서 수행되는 제한된 리스트 구조
- 선입선출(FIFO : first in, first out)
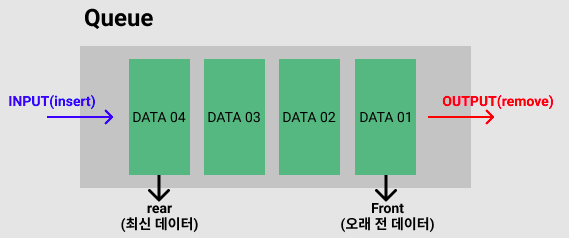
① 큐의 기능(method)
- 삽입 insert - enqueue : 새로운 데이터 삽입으로 rear에서 발생한다.
- 삭제 remove - dequeue : 데이터 제거 작업으로 front에서만 발생한다. front의 값이 rear값을 추월하면 빈 큐가 됨을 의미한다.
- 읽기 peek : front가 가리키는 데이터를 읽는 작업으로 front의 값은 변경되지 않는다.

② 큐의 실생활 사례
- 콜센터 상담 대기 혹은 은행 대기 번호표
- 지하철 탈 때 카드 찍는 경우(놀이공원 등 유사)
스택과 큐의 차이점
- 스택 최상단에서만 자료의 추가/삭제가 이뤄지나, 큐는 자료 추가와 삭제가 별도로 이뤄진다.
- 스택은 가장 마지막에 추가된 자료만 알려주나, 큐는 맨 앞의 자료를 알려주면 된다.
- 큐의 자료 추가는 뒤, 자료삭제는 앞에서 이뤄지므로 입출구가 다르다.
추가적 고민요소
- 큐를 이용한 스택 구현
- 스택을 이용한 큐 구현
- 다른 종류의 Queue, Priority Queue와 Circular Queue
참조사이트
스택/큐
3. 연결리스트/해시테이블
1) 연결 리스트(Linked List)
- 크기가 동적인 자료구조로 자료구조를 구성하는 요소(노드:Node)의 연결로 이루어진 구조
- 어떠한 임의의 지점에서 데이터 추가 및 삭제를 할 경우, O(1)(상수시간)의 시간 복잡도를 가짐
// JavaScript 에서의 연결리스트
const list = {
head: {
value: 6
next: {
value: 10
next: {
value: 12
next: {
value: 3
next: null
}
}
}
}
}
};① 노드(Node)의 구성
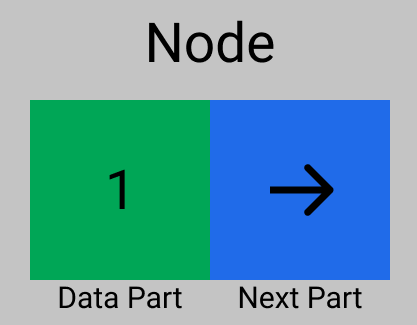
- 노드의 값(value = Data Field)
- 다음 노드에 대한 정보(next = Link Field = pointer)
② 연결리스트의 구성
- Head : 콜렉션의 시작지점
- Tail : 콜렉션의 끝 지점
- 노드
③ 연결 리스트의 기능과 특징
-
노드 생성(new Node)
-
노드 삽입 Append-addToTail : tail 뒤에 붙을 경우, tail을 찾고 다으음 노드가 새로운 노드를 가르키게 한다.(instantiation)
-
노드 삭제 remove : 특정 노드 삭제 시, 데이터 값을 기준으로 삭제. 연결된 포인트(next)를 끊어 주고, 삭제할 노드의 다음 노드를 연결해줘야한다.
-
특정 인덱스 반환 indexOf : 랜덤 액세스 불가능, 순차적으로 찾아야 한다.
-
특정 노드 존재 여부 isEmpty-contains : boolean
-
노드 크기 반환 size
-
주어진 인덱스에 있는 값을 반환하는 getNodeAt
-
추가/삭제 속도가 빠르고, 노드에 인덱스가 존재하지 않는다.. → 특정 데이터 연결리스트를 검색하고자 하면, 처음부터 전체 연결 리스트를 훑어야 한다.O(n)
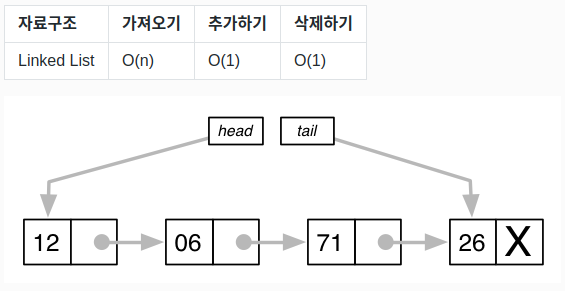
④ 연결리스트 종류
- 단일 연결 리스트(Singly-Linked List) : 요소(노드)가 오직 다음 요소로 연결된 것

- 이중 연결리스트(Doubly-Linked List) : 이전 노드와 다음 노드가 레퍼런스를 포함하고 있는 리스트

- 환형 연결리스트(Circular Linked List) : 마지막노드가 null이 아닌 첫번째 노드를 가리키는 것
⑤ 연결리스트 실제사례
- 포토샵 히스토리(ctrl+z로 이전작업 돌아가기)
- 음악 플레이어
- 꼬리물기게임
- 기차놀이
배열과 리스트의 차이
- 데이터 추가
- 3번째 공간에 값을 추가한다면, 배열은 3번째 공간에 값을 덮어씌운다.
- 리스트는 3번째 공간의 값을 뒤로 무르고, 새로운 공간을 만들어서 값을 추가한다.
- 데이터 삭제
- 3번째 공간의 값이 없어지면, 배열은 null의 값(빈공간)을 지닌다.(인덱스 유지) → 메모리 낭비
- 리스트는 빈 값을 제작하지 않고 뒤에 무른 값을 앞으로 전진시킨다.
Garbage Colletion
- 가비지(Garbage) : '정리되지않은 메모리', '유효하지 않은 메모리주소'
- 가비지 컬렉터(Garbage Collector) : '메모리 해제' → 자바스크립트에서는 아무도 참조하지 않은 메모리를 제거
참조사이트
Data Structures In The Real World — Linked List
Linked List — In typescript and C#
Data Structure - Circular Linked List
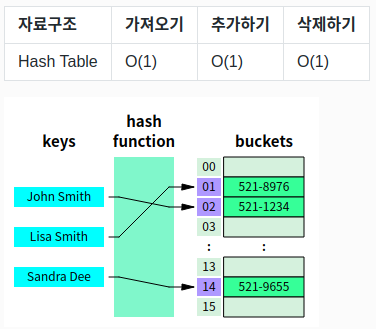
2) 해시 테이블(Hash Table = Hash Map)
① 해시테이블의 정의와 용어
-
두 가지 데이터의 관계를 연결해주는 자료구조( = 키, 값 쌍을 저장하고 있는 자료 구조)
-
키(key) : 해시 함수에 들어가기 전, 원래 데이터의 값(매핑 전 값)
→ 문자열과 같은 것으로 그 길이가 다양하다. -
해시값(hash value) : 해시함수를 통해 할당된 데이터의 값
- 값(value) : 저장소(bucket)에 저장되는 최종 값으로
hash와 매칭되어 저장된다.
- 값(value) : 저장소(bucket)에 저장되는 최종 값으로
-
-
해시함수(Hash Function)
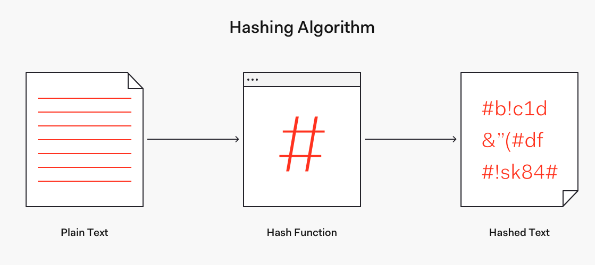
-
키(key)를 사용해 인덱스 값을 도출하는 함수로, '해싱' 작업이 포함되어있다.
간단하게 문자열을 특정 숫자로 변환해주는 작업을 지칭한다. -
해싱(hashing) : 가변크기의 입력값(key)를 '고정된 길이'의
hash로 변경하여 버킷(슬롯)에 분배해주는 과정
② 해시 테이블의 기능과 특징
- size : 해시테이블 내 담겨 있는 데이터의 양
- limit : 해시 테이블 최대 크기
→ storage의 크기 = limit
- insert : 키와 값을 해시테이블 안에 넣어준다.
- retrieve : 키(요청)을 넣으면, 가지고 있는 값을 반환
- remove : 데이터 삭제
- _resize : 배열의 사이즈를 키우거나 줄이는 역할 → 시간복잡도와 연결
- 필요할 때만 메모리 크기를 늘리고, 가능한 작은 크기를 유지(25%~75% 사이 유지)
-
해시 함수의 3가지 특징
- 항상 내가 가지고 있는 배열, 즉 스토리지 안에서 값이 나와야한다.(arr.length-1)
해시테이블의 최악의 경우- 해시테이블 확장(리사이즈)했을 때, 해싱을 다시 해야하는 문제와 동일해서 O(n)의 시간 소요
- 모든 키가 같은 버켓에 들어가 있는 것 또한 O(n)의 시간
- 언제든 같은 값을 넣었을 때, 일정한 값이 나와야한다.
→ apple을 입력했을 때 스토리지에 '1'이 저장되어있다면, 항상 apple 넣을 때마다 '1'이 나와야합니다. 출력값과 입력값이 1:1 매핑되는 것은 해시테이블의 특징이다. 단, 해시충돌이 일어날 수 있으므로 이 경우를 대비해야한다. - 해시함수는 입력값(key)를 저장하지 않고, 그때그때 값을 주면 내뱉는다.
→ 출력값으로는 입력값이 무엇인지 예측을 못 한다.
만약 출력값이 1 이 나왔을 때, 이게 apple을 넣어서 나온 1인지, avocado 넣어서 나온 1인지 알 수가 없는 것이고, 이 현상을 '해시충돌'이라고 한다. - 해시함수는 '암호화(Encryption)'과 다르다.
- 항상 내가 가지고 있는 배열, 즉 스토리지 안에서 값이 나와야한다.(arr.length-1)
③ 해시 충돌(collision)
- 해시함수가 서로 다른 두 개의 키에 대해 동일한 해시값을 나타내는 현상

- 해결방법
- 개방 해싱(open addressing)
- 해시 테이블 주소 바깥에 새로운 공간을 할당하여 문제를 수습
- 선형탐사
- 이중 해시
- 폐쇄 해싱(closed addressing)
- 처음 주어진 해시테이블 공간 내에서 문제 해결
- 버켓 : 배열의 한 요소가 다시 배열로 이뤄진다.(like 2차원배열)
- 체이닝 : 충돌된 값들을 연결리스트로 연결한 형태
- 개방 해싱(open addressing)
④ 해시 테이블의 용어
- storage : array의 형태로 이뤄진 가장 큰 저장소 - hash "table"
- bucket(slot) : storage 내부의 저장소로, 들어온 데이터에 대한 "인덱스"를 담고 있다.
- tuple : 읽기 전용. 각각의 데이터를 담고 있는 공간으로 이 데이터는 수정/추가/삭제가 불가한다. 다른 값으로 덮어씌우기는 가능.
⑤ 해시테이블 실제사례
- 사전
참조사이트
해시와 해시함수
[자료구조] Hash/HashTable/HashMap
Hash, Hashing, Hash Table(해시, 해싱 해시테이블) 자료구조의 이해
해싱, 해시함수, 해시테이블
What's Hashing About?
4. 그래프,트리,BST(Graph, Tree, BST)
1) 그래프(Graph)
- 노드(정점=vertex)와 간선(edge)으로 구성된 자료구조
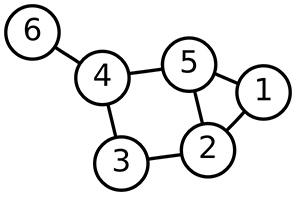
① 그래프의 종류
- 무방향 그래프(undirected)
- 연결된 2개의 노드가 대칭되는 관계의 그래프
- 간선에 방향이 없다.
- 양방향 그래프(directed)
- 비대칭 관계
- 간선에 방향이 있다.
- 그외 : 완전 그래프, 부분 그래프, 가중 그래프, 연결 그래프, 단절 그래프 등이 존재
② 그래프의 메소드
- 인접여부 adjacent(has edge) : x와 y 노드 사이의 간선이 있는지 인접 체크
- 노드 추가/삭제 add vertext
- 간선 추가/삭제 add edge
③ 그래프의 용어 외
- 차수(degree) : 정점에 부속되어 있는 간선의 수
- 진입차수(in-degree) : 특정 점정으로 갈 수 있는 간선의 수 = 정점을 머리로 하는 간선의 수
- 진출차수(out-degree) : 특정 점정에서 나갈 수 있는 간선의 수 = 정점을 꼬리로 하는 간선의 수
- 정점의 차수(degree of a node) = 진입차수 + 진출차수
- 경로(Path) : 간선에 따라 갈 수 있는 길을 순서대로 나열한 것
- 경로 길이(Path Length) : 경로를 구성하는 경로 길이
- 단순 경로(Simple path) : 모두 다른 정점으로 구성된 경로
- 사이클(cycle) : 경로의 시작 정점과 마지막 정점이 같은 경로
→ 방향 그래프면서 사이클이 없는 그래프(DAG : Directed Acyclic Graph)
④ 그래프의 표현
- 인접행렬방식(Adjacency matrix)
- 그래프의 연결관계를 '이차원 배열' 로 나타내는 방식
adj[i][j] : 노드 i에서 노드 j로 가는 간선이 있으면 1, 아니면 0
- 구현이 쉽다는 장점이 있어서 시간 복잡도가 O(1)
- 전체 노드 탐색에 O(V)의 시간이 소요
- 그래프의 연결관계를 '이차원 배열' 로 나타내는 방식
- 인접리스트방식(Adjacency list)
- 그래프의 연결 관계를 vector의 배열로 나타내는 배열
- 실제 연결된 노드에 대한 정보만 저장 → 간선의 개수에 비례하는 메모리만 차지
- 특정 노드 탐색에 O(E)의 시간 복잡도를 가짐.
- 노드의 연결 여부를 따질 때는 O(V)의 시간복잡도
⑤ 그래프 순회 알고리즘(Graph traversal algorithms)
- DFS(Depth-first search 깊이 우선 탐색)
- 시작 정점의 한 방향으로 갈 수 있는 경로가 있는 곳까지 탐색
- 더이상 갈 수 없으면, 가장 마지막에 만났던 갈림길 간선이 있는 정점으로 되돌아옴
- 다른 방향의 간선으로 탐색을 계속 반복 후, 모든 정점 방문 완료
→ 후입선출구조의 스택을 사용한다.
- BFS(Breadth-first search 너비 우선 탐색)
- 시작 정점으로부터 인접한 정점을 모두 차례로 방문 후, 방문했던 정점을 시작으로 다시 인접한 정점을 차례로 방문한다.
- 선입선출구조의 큐를 사용한다.
⑥ 그래프의 실제사례
- 지하철 노선도
- SNS 팔로우 관계
참고사이트
[자료구조] 그래프(Graph)란
그래프의 종류
[그래프] 인접 행렬과 인접 리스트
[알고리즘] 그래프 순회, 탐색
2) 트리(Tree)
- 노드로 구성된 계층적 자료구조로 최상위 노드(루트)를 만들고, 그 아래 child 노드를 추가하는 방식의 자료구조

① 트리의 용어
- 노드(node) : 트리의 구성요소
- 간선(edge=link,branch) : 노드와 노드를 잇는 선
→ 노드가 N개인 트리는 항상 N-1개의 간선(링크)를 가진다. - 루트노드(root node) : 트리의 최상위 존재하는 노드
- 맆(leaf, 단말, 터미널노드) : 차수가 0인 노드, 즉 맨 끝에 달린 노드
- 내부 노드(internal, non-terminal, branch node) : 차수가 1 이상인 노드, 리프 노드가 아닌 노드
- 부모(parent) : 부속트리(subtree)를 가진 노드
- 자식(child) : 부모에 속하는 노드
- 형제(sibling) : 부모가 같으면서 같은 depth에 존재하는 자식 노드
- 조상(ancestor)-자손(desendant) : 부모와 자식 관계를 확장한 것
- 거리(depth) : 루트 노드부터 어떤 노드에 도달하기 위해 거쳐야하는 간선의 수
- 루트노드의 depth는 '0'이다.
- 높이(height) : 루트 노드에서 가장 깊숙히 있는 노드의 깊이
- 레벨(level)
- 트리의 깊이와 정의는 비슷하나, 그 기준이 간선이 아닌 '노드의 개수'
- depth + 1 = level → 루트노드의 depth는 0이므로 레벨은 1이다.
② 트리의 특징
- 그래프의 한 종류로 '최소연결트리'로 불리며 계층모델이다.
- 방향 그래프면서 사이클이 없는 그래프(DAG : Directed Acyclic Graph)이다.
- 루트에서 어떤 노드로 가는 경로는 유일하다.
→ 2개의 정점 사이에 반드시 1개의 경로만 가진다. - 모든 자식 노드는 1개의 부모 노드만 가진다.(top-bottom or bottom-top)
- 순회의 기준은 노드를 언제 방문하느냐에 따라 갈린다.
- walking the tree : 부모와 자식노드 사이의 연결을 통해 나무의 노드를 탐색하는 것
- 전위 순회(Pre-order) : 현재 노드를 우선 방문하는 것. 자식 노드 전에 각 부모노드를 순회하는 것
- 중위 순회(In-order) : 현재 노드를 중간에 방문하는 것. 왼쪽 → 현재 노드 → 오른쪽 서브트리 순으로 순회하는 것(ex:이진트리)
- 후위 순회(Post-order) : 현재 노드를 나중에 방문 하는 것. 부모노드가 순회 하기 전, 자식노드가 순회하는 것
④ 트리의 종류
- 이진트리, 이진 탐색 트리, 균형트리 등
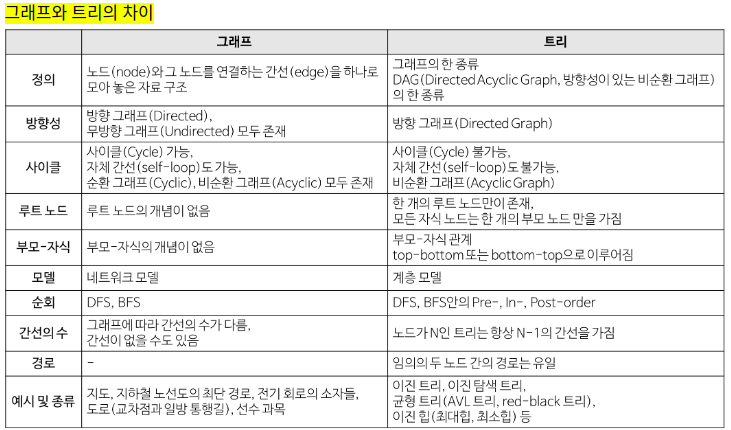
⑤ 트리와 그래프의 차이
⑥ 트리의 실제사례
- 조직도, 가계도 등
참조사이트
트리에 대하여1 / 트리에 대하여2
[Algorithm] 트리의 개념과 용어정리
3) 이진탐색트리 : BST
- 최대 2개의 자식만 갖는 트리
- 트리 구조는 재귀적이므로 자식 노드 역시 2개의 자식만 갖는다.
- 전위 순회(Pre-order) : 현재 노드 → 왼쪽 → 오른쪽
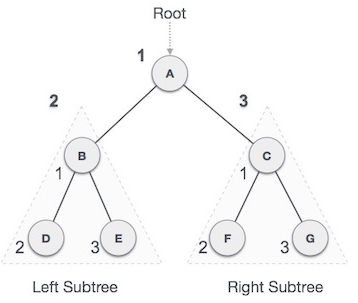
A → B → D → E → C → F → G
- 중위 순회(In-order) : 왼쪽 → 현재 노드 → 오른쪽 서브트리
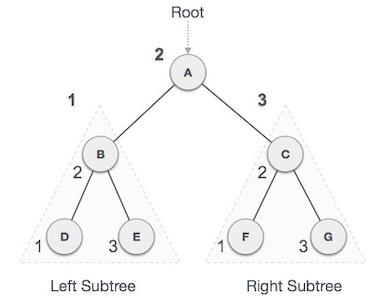
D → B → E → A → F → C → G
- 후위 순회(Post-order) : 왼쪽 → 오른쪽 → 현재노드

D → E → B → F → G → C → A
② 이진탐색트리의 특징
- 모든 왼쪽 자식들 < n <= 모든 오른쪽 자식들(모든 노드 n에 대해서는 반드시 참)
- 노드의 왼쪽 서브 트리에는 노드 값 보다 작은 값이
- 오른쪽 서브트리에는 노드 값보다 같거나 큰 값이 존재
③ 이진탐색트리의 종류
-
정 이진 트리(Full Binary Tree 또는 Strictly Binary Tree)
- 모든 노드가 0개 또는 2개의 자식 노드를 같는 트리
- 자식 노드에 1개만 가지면 정 이진 트리가 아니다.
- 노드개수 n은 최소 2h+1, 최대 2의 (h+1)승 -1, 여기서 h는 트리의 높이
n=2^(h+1)-1
-
완전 이진 트리(Complete Binary Tree)
- 자식이 모두 꽉찬 상태(자식노드가 항상 2개)로 굳이 left,right을 나눌 필요가 없다.
- 마지막 레벨은 꽉 차 있지 않아도 되지만, 왼쪽에서 오른쪽으로 채워져야한다.
- 마지막 레벨 h에서 1부터 2의 h승-1 개의 노드를 가질 수 있다.
-
포화 이진 트리(Perfect Binary Tree)
- 정 이진 트리이면서 완전 이진트리인 경우
- 모든 말단 노드는 같은 높이에 있어야하며, 마지막 단계에서 노드의 개수가 최대가 되어야한다.
-
그 외 : 무한 완전 이진 트리, 균형 이진 트리, 변질 트리
참조사이트
이진트리의 개념
순회방법에 대하여1 / 순회방법에 대하여2
이진트리 종류
시각적으로 자료구조 참고하기 좋은 사이트
- visual algo
- Data Structu9re Visualizations
- 구글검색어 : data structure visualization
그외 추가 참조사이트
data structures
7 Javascript ds
array구현 / object 구현

공부에 있어 많은 도움 됬습니다. 감사합니다.