LSTM(Long Short Term Memory)

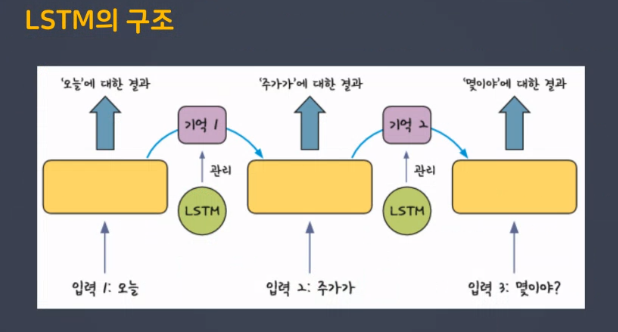
1.1 LSTM의 구조
h는 단기 상태(Short-Term state), c는 장기 상태(Long-Term state)
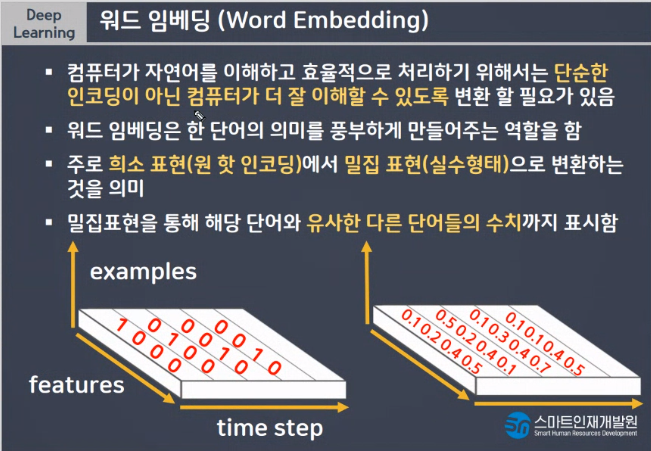
Word Embedding
- 단순한 인코딩이 아닌 컴퓨터가 더 잘 이해할 수 있도록 변환
- 주로 희소 표현(원 핫 인코딩)에서 밀집 표현(실수형태)로 변환, 낮은 용량
- 임베딩 과정을 통해서 나온 결과를 임베딩 벡터라고 함
- 케라스에도 제공하는 도구인 Embedding()은 랜덤한 값을 가지는 밀집 벡터로 변환한 뒤에 인공 신경망의 가중치를 학습
num_words
(X_train, y_train), (X_test, y_test) = reuters.load_data(num_words=1500)
# oov_char = 2 : 빈도가 낮은 단어(num_words=1500개 이하)가 2로 마스킹
model3 = Sequential() # 뼈대 생성
model3.add(Embedding(1500, 50)) # 임베딩을 진행할 단어의 수, 각 단어를 표현할 숫자의 수
# embedding layer : 단어사전, 0~1500개의 단어, 가로로는 50개
model3.add(LSTM(128, return_sequences=True))
model3.add(LSTM(128))
model3.add(Dense(32, activation='relu'))
model3.add(Dense(46, activation='softmax'))전이학습
: Transfer Learning이란? 이를 딥러닝의 분야에서는 '이미지 분류' 문제를 해결하는데 사용했던 네트워크(DNN;Deep Neural Network)를 다른 데이터셋 혹은 다른 문제(task)에 적용시켜 푸는 것을 의미
