BERT(2019) : Pre-training of Deep Bidirectional Transformers for Language Understanding
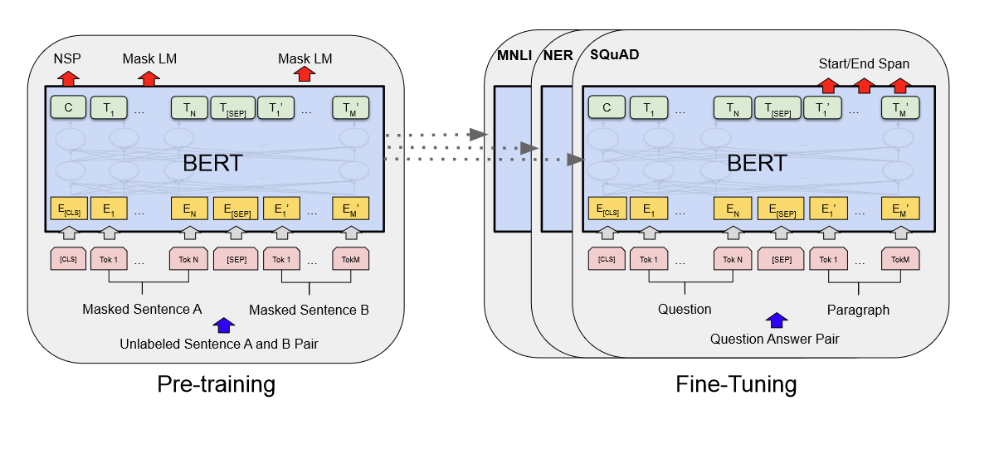
BERT는 이전의 언어 모델들과 비교하여 양방향으로 문맥을 이해할 수 있는 Bidirectional Encoder Representations from Transformers로 설계되었습니다. BERT의 중요한 특징은 양방향성으로, 문장의 왼쪽과 오른쪽 문맥을 동시에 고려하여 언어 표현을 학습합니다. 모델은 사전 훈련(Pre-training) 단계에서 "Masked Language Model(MLM)"과 "Next Sentence Prediction(NSP)"이라는 두 가지 작업을 수행하며, 이를 통해 다양한 자연어 처리 작업에서 뛰어난 성능을 보여줍니다. Fine-tuning 과정에서는 사전 훈련된 파라미터를 사용해 다양한 작업(질문 답변, 자연어 추론 등)을 수행할 수 있습니다.
BERT의 특별한 점은 사전 훈련 모델을 거의 수정하지 않고도 광범위한 작업에 적용할 수 있으며, 문장 수준과 토큰 수준의 다양한 언어 처리 작업에서 탁월한 성능을 발휘한다는 것입니다.
elmo와 같은 경우는 forward model과 backward모델을 따로 학습을 해가지고 해당하는 representation을 결합을 한 것이고,gpt는 decoder부분이
https://www.youtube.com/watch?v=30SvdoA6ApE
BERT는 이름을 통해 트랜스포머의 bidirectional encoder임을 알 수 있는데 기존 트랜스포머의 인코더 부분만을 이용해서 문맥을 양방향으로 이해해서 숫자의 형태로 바꾸어주는 딥러닝 모델입니다.기존의 gpt1과 같은 언어 모델은 왼쪽에서 오른쪽으로 읽어나가는 방식과 같은 것들은 문맥이해에 약점이 있을 수 있다고 지적하면서 양방향으로 문맥을 이해할 수 있는 BERT를 제안하게 되었습니다.모델은 사전 훈련(Pre-training) 단계에서 "Masked Language Model(MLM)",입력 문장에서 일부 단어를 무작위로 마스킹하고 마스킹된 단어의 문맥(양쪽 방향)만을 이용해 해당 단어를 예측하는 task와 "Next Sentence Prediction(NSP)",두 개의 문장 쌍이 주어졌을 때, 두 번째 문장이 첫 번째 문장 뒤에 실제로 이어지는지(IsNext) 또는 무작위 문장인지(NotNext)를 예측하는 두 가지 작업을 수행하며 pretrainig을 합니다. Fine-tuning 과정에서는 사전 훈련된 파라미터를 사용해 bert위에 layer하나씩만을 추가함으로써 두문장의 관계를 예측하는 것, 질의 및 응답과 같은 다양한 작업을 수행하는 과정을 거칩니다.
출처)
https://hyunsooworld.tistory.com/entry/%EC%B5%9C%EB%8C%80%ED%95%9C-%EC%9E%90%EC%84%B8%ED%95%98%EA%B2%8C-%EC%84%A4%EB%AA%85%ED%95%9C-%EB%85%BC%EB%AC%B8%EB%A6%AC%EB%B7%B0-BERT-Pre-training-of-Deep-Bidirectional-Transformers-for-Language-Understanding-1
https://www.youtube.com/watch?v=IwtexRHoWG0
