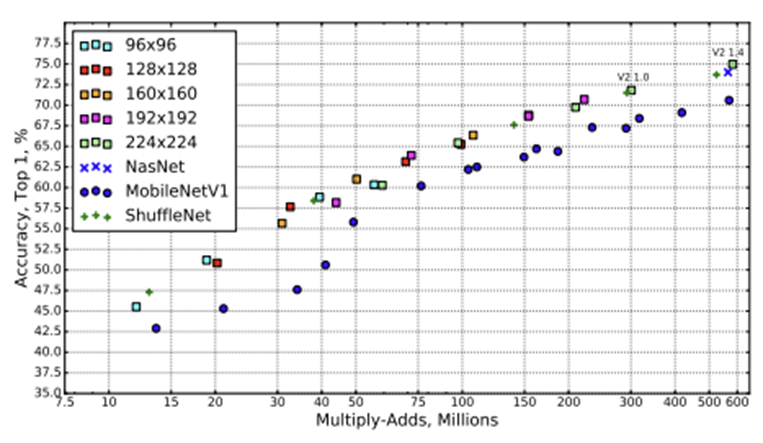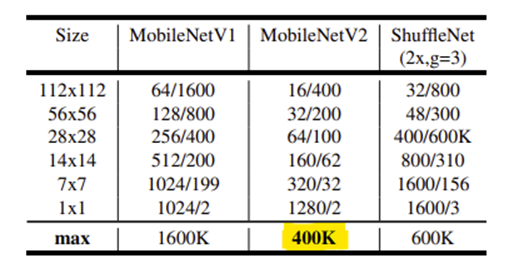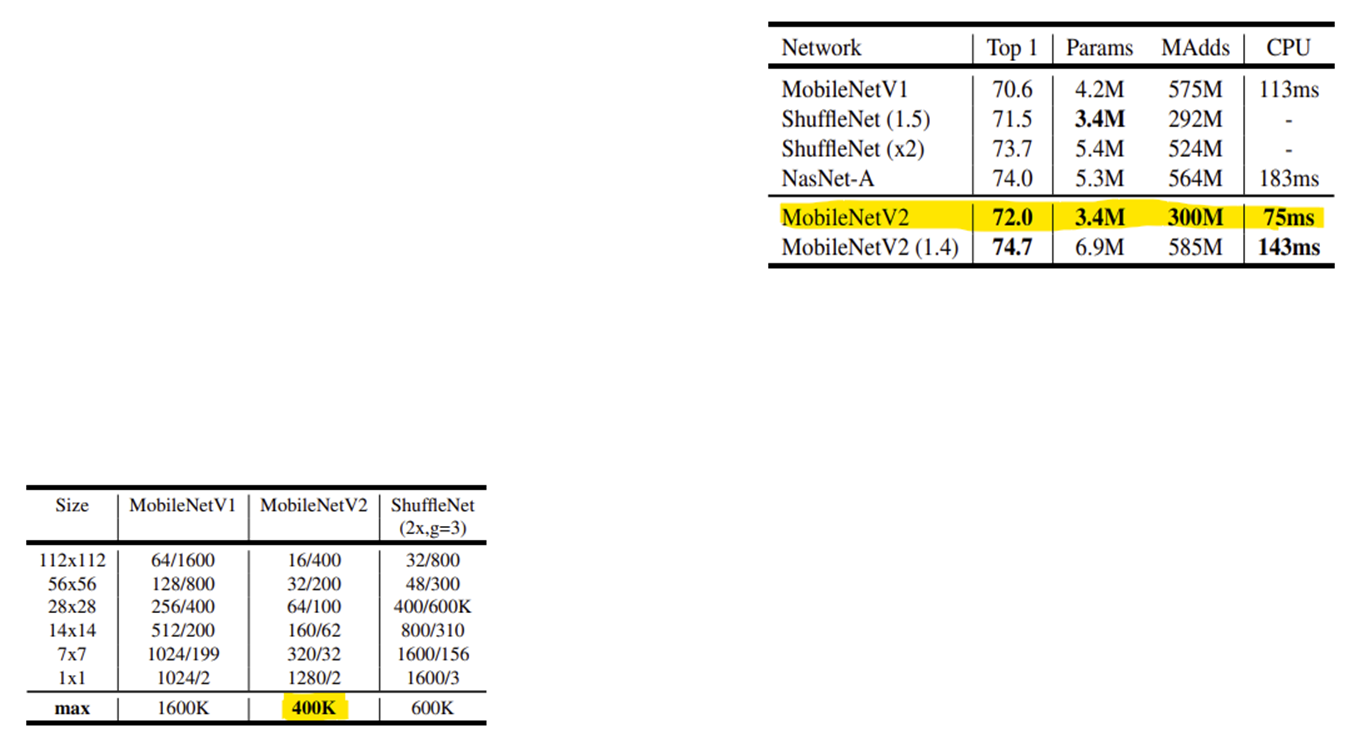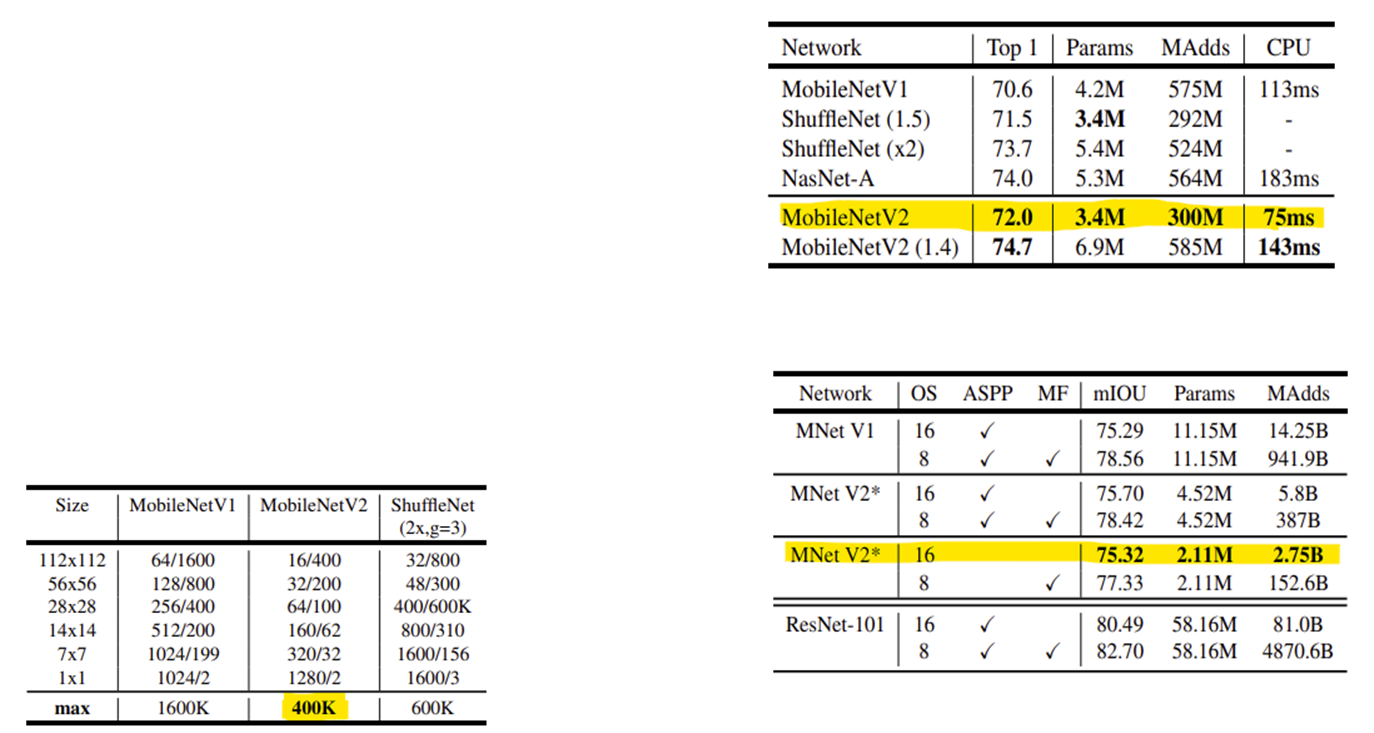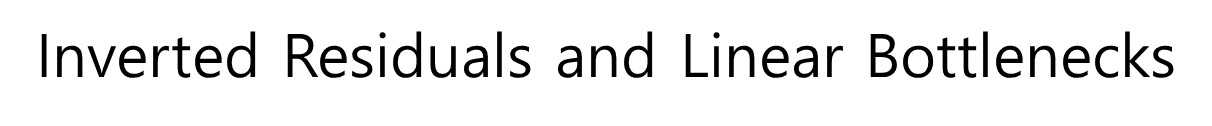
본논문에 목적은 모바일 환경에서 제한적인 리소스를 사용하면서 정확도를 유지할 수 있는 모델을 만들자는 것으로
제시된 모델은 Inverted Residual Block
기존 모델들은 성능향상에만 초점이 맞춰진 경향,리소스사용이 크고 complex(VGGNet,ResNet)
따라서 정확도는 유지하면서 메모리는 적게 사용하는 모바일 환경에 적합한 computer vision model인 MobileNetV2를 만들어 내었다는 것.
depthwise seperable convolution은 기존의 convolution을 2step으로 나누어서 진행하는 것으로
채널마다 따로 필터를 학습시키는 Depthwise Conv과 필터의 크기가 1x1로 고정된 상태로 학습함으로써 각 채널에 대한 연산만 수행하며 채널수를 조절하는 역할 을 하는 Pointwise Conv를 나누어 진행함을 통해 연산량을 위의 식처럼 줄일 수 있게 하였습니다. 이와 같은 아이디어는 MobileNetV2에서도 동일하게 진행됩니다.
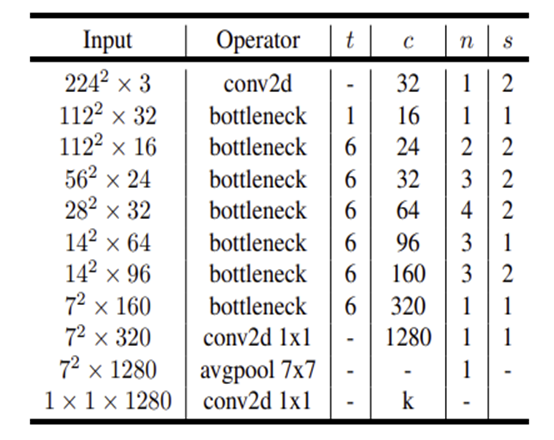
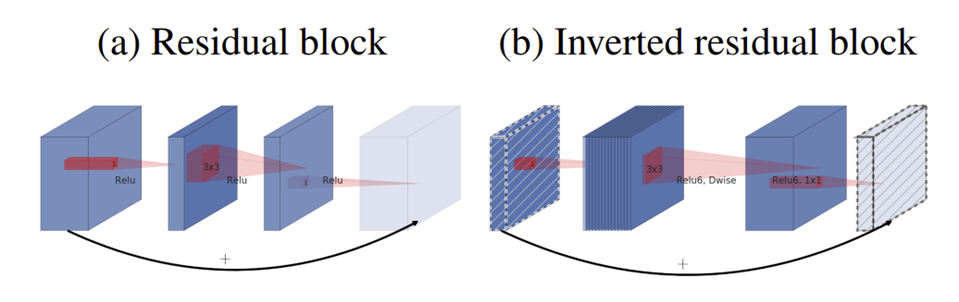
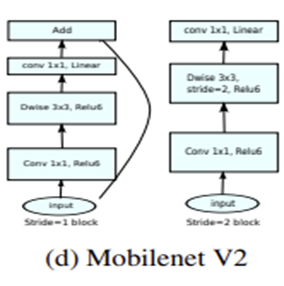
Inverted residual block은 Residual block의 layer 순서와 반대로 전개 되는데 일반적인 Residual Block이 wide-narrow-wide한 구조이면 inverted residual block은 narrow-wide-narrow한 구조로 차원확장->정보추출->차원 축소의 과정을 거칩니다. 이때 아래 식에서 보는 것과 같이 memory의 소모가 input, output의 operation에 종속적인 것인 것을 참고할 때 위와 같이 narrow-wide-narrow한 구조가 효율적인 구조인 것을 알 수 있습니다. 또한 기본적인 구조는 다음과 같이 Linear 한 BottleNeck구조를 갖추고 있고 추가적으로 stride가 1일때는 skip connection을 진행하고 stride가 1이 아닐 때는 skip connection을 진행하지 않습니다.
그리고 또한가지 확장된 채널이 축소될때 정보의 손실을 막기 위해 Relu를 사용하지않는 "Linear" bottleneck구조를 갖추고 있습니다.
Linear Bottlenecks
ReLU 변환 후에도 manifold of interest가 0이 아닌 값으로 유지되면 선형 변환에 해당하고, 음수가 아닌 값에 대해서는 선형적인 값인 것. ReLU는 input manifold에 대한 완전한 정보를 보존할 수 있지만 입력 매니폴드가 입력 공간의 저차원 부분 공간에 있는 경우에만 가능합니다.
BottleNeck구조에는 Relu를 쓰면 오히려 성능이 떨어지는 것을 확인 할 수 있음.