[논문 리뷰]Learning Transferable Visual Models From Natural Language Supervision
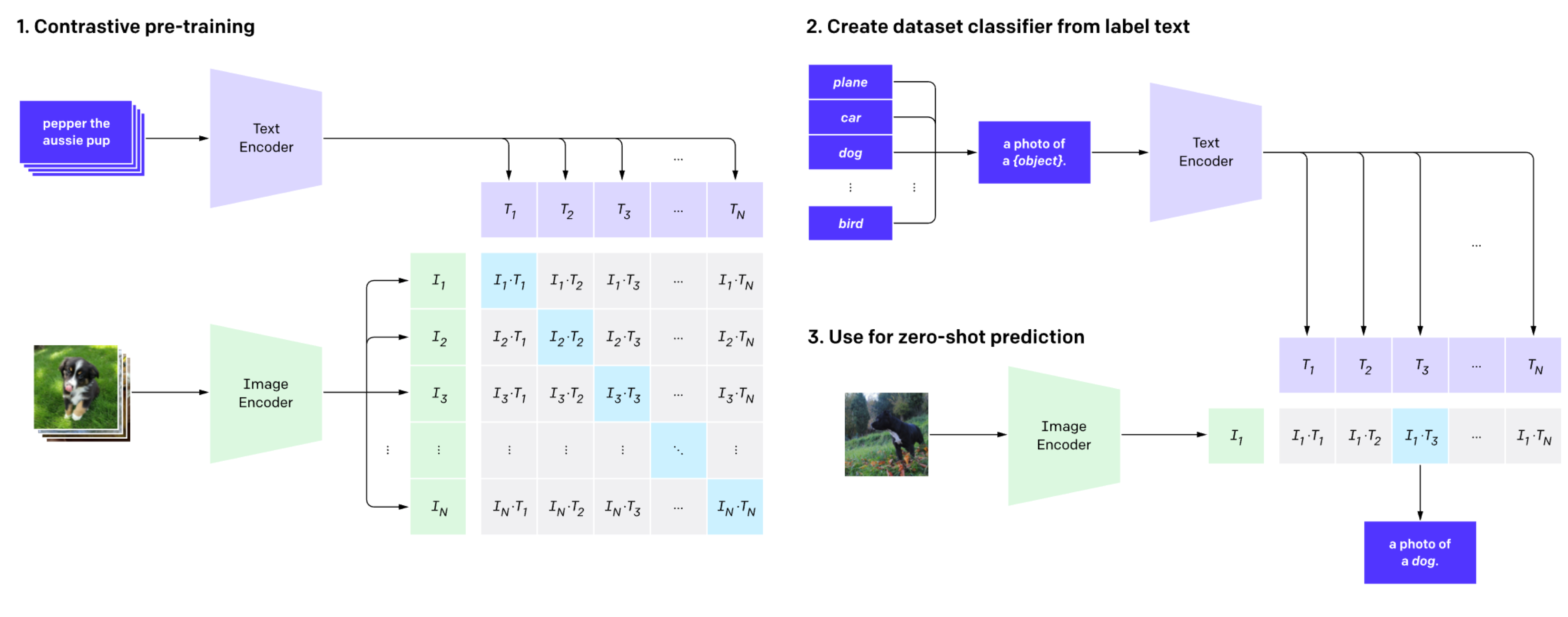
이 논문은 CLIP(Contrastive Language-Image Pre-training)이라는 모델을 소개하며, 자연어로부터의 감독(supervision)을 통해 이미지 인식 능력을 학습하는 방법을 제안합니다. 기존의 컴퓨터 비전 모델들이 고정된 레이블 세트로 학습하는 반면, CLIP은 이미지와 텍스트의 쌍을 사용해 이미지 표현을 학습하여 다양한 비전 태스크에 적용할 수 있습니다. 논문에서 제안된 방법은 4억 개의 이미지-텍스트 쌍을 통해 학습되었으며, 이를 통해 제로샷 학습(zero-shot learning) 능력을 갖추게 됩니다. 제안된 CLIP 모델은 특정 데이터셋에 대한 학습 없이도 여러 컴퓨터 비전 태스크에서 경쟁력 있는 성능을 보여줍니다. 이는 자연어 표현을 활용해 이미지에 대한 다양한 시각적 개념을 학습할 수 있도록 하며, 새로운 데이터셋에 대한 높은 전이 학습 성능을 입증합니다.
이때 언급된 제로샷 학습(zero-shot learning)은 모델이 사전에 학습한 적 없는 새로운 클래스나 작업을 수행할 수 있는 능력을 의미합니다.
미리 본 적이 없는 새로운 상황에서도 자연어 표현을 활용하여 기존의 지식과 문맥 정보를 활용해 유추할 수 있기 때문입니다.
정리)이 논문은 CLIP(Contrastive Language-Image Pre-training)이라는 모델을 소개하며 기존의 컴퓨터 비전 모델들이 고정된 레이블 세트로 학습하는 반면, CLIP은 이미지와 텍스트의 쌍을 사용해 이미지 표현을 학습하여 다양한 비전 태스크에 적용할 수 있습니다.논문에서 제안된 방법은 4억 개의 이미지-텍스트 쌍을 통해 학습되었으며,CLIP의 구조는 크게 Image encoder와 Text encoder로 이루어져 있는데 image encoder에서는 고차원이미지를 저차원 임베딩공간으로 매핑해주고 ResNet-50과 Vit를 Image encoder로 하고 있습니다.text encoder는 자연어로부터 text representation을 생성을 하고 있으며transformer를 이용하고 있습니다.그리고 각각이 매칭되는 쌍에 대해서는 코싸인 유사도를 최대화하고 매칭되지 않는 pair에 대해서는 코사인 유사도를 최소화 하는 방식으로 학습을 시켜주었습니다. 이렇게 pre-training task시에는 어떤 caption이 어떤 이미지와 대응되는지를 예측하고,이후에 pre-training이후에는 자연어를 이용하여 학습된 visual concept을 reference하는데 이용합니다. 이를 통해 제로샷 학습(zero-shot learning) 능력을 갖추게 됩니다. 이때 zero-shot learning은 사전에 학습한 적 없는 새로운 클래스나 작업을 수행할 수 있는 능력으로 미리 본 적이 없는 새로운 상황에서도 자연어 표현을 활용하여 기존의 지식과 문맥 정보를 활용해 유추하는 것입니다.
출처) https://dealicious-inc.github.io/2021/03/22/learning-transferable-visual-models.html
https://velog.io/@wsh7787/%EB%85%BC%EB%AC%B8-%EB%B6%84%EC%84%9D-Learning-Transferable-Visual-Models-From-Natural-Language-Supervision
https://www.youtube.com/watch?v=ZXrU79CUej8
https://david-kim2028.tistory.com/entry/%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0-CLIP-Learning-Transferable-Visual-Models-From-Natural-Language-Supervision
https://taeyuplab.tistory.com/16
