[논문리뷰]Deep contextualized word representations
(이전의 자연어처리,word2vec and Glove와 같은 선행학습된 단어 임베딩(단어의 의미를 숫자로 표현한 것)을 많이 사용했습니다. 그러나 문맥에 따라 임베딩을 제공하지는 못하는 경우가 많았습니다. 이에 대해서) 문맥에 따라 임베딩을 제공하는 함수인 elmo를 제안하였습니다. 이것이 가능한 것은 ELMo의 biLM구조와 이 구조의 모든 레이어 정보를 활용한다는 데에 있습니다.biLM은 순방향 LM과 역방향 LM을 합친 LM을 말하는 것으로 LM을 자연어 처리 모델에 사용하는 가장 큰 장점은 모델학습에 따로 레이블링을 할 필요가 없다는 것입니다. 단순히 다음 또는 이전 단어를 예측하기 위한 많은 양의 데이터만 있으면 됩니다.ELMo를 학습할 때 순방향 LM은 현재 가진 단어들을 통해 다음 단어를 예측하도록 학습됩니다.
역방향 LM은 뒤에 오는 단어들을 통해 앞에 있는 단어를 예측하도록 학습됩니다.ELMo는 모든레이어의 출력값을 활용해 임베딩을 만듭니다.
이는 이전의 좋은 성능의 모델들이 최상위 레이어만 사용한 것과 대조됩니다.논문에서는 상위 레이어 일수록 문맥에 의한 벡터를 출력하고,하위 레이어일수록 문법에 가까운 벡터를 출력한다고 합니다.
자 그럼, 순방향 LM이 어떻게 학습되는지 보면 문장이 주어졌을때 첫단계로 단어는 charcter임베딩으로 전환됩니다.그리고 character 임베딩은 첫 lstm셀로 입력됩니다.char임베딩을 사용하는 주된 이유는 두가지 입니다.첫째,최초임베딩은 문맥의 영향을 받지 말아야합니다.그리고 ELMo를 선행학습된 단어 임베딩을 사용한 모델과 비교하기 위해서 Glove나 Word2Vec을 사용안하기도 했구요.공평한 심사를 위해서 선행학습된 단어 임베딩을 사용하지 않았습니다.첫레이어가 문맥으로 부터 영향을 받지 않도록 설계되었지만, 이후레이어들은 문맥에 영향을 받도록 설계되었습니다. 추가적으로 첫 lstm출력은 char임베딩과 residual connection을 가지고 있습니다.
논문에서 다루지는 않았지만 residual connection은 다음 2가지의 장점을 가지고 있어요. 첫째로,상위 레이어들이 하위 레이어의 특징을 잃지 않고 활용하도록 도와주고요 두번째로는 학습 시 역전파를 통한 gradient vanishing현상을 극복하도록 도와줍니다.순방향 LM은 항상 다음 단어를 예측하도록 학습됩니다. 여기서 한가지 알고 넘어가면 좋은게 있는데요,I라는 단어 밖에 없을 때, read가 과거형이라는 정보가 없기 때문에,read를 현재형의 임베딩으로 출력할 가능성이 높습니다.이런점을 극복하고자, ELMo는 역방향 LM도 사용하는 것입니다. 두 LM을 사용함으로써, 임베딩을 보다 정확히 생성합니다.순방향 LM은 이런 방식으로 마지막 단어까지 예측합니다.그리고 역방향 LM은 단순히 방향만 반대일뿐 순방향 LM과 하는 일은 동일합니다.미래의 단어들로 이전 단어들을 예측하도록 학습됩니다.마지막 단어부터 첫 단어까지 예측을 하게 됩니다.역방향 LM은 yesterday를 알고 있기 때문에 read를 과거형으로 구분하기 쉽습니다.역방향 LM은 끝 단어부터 첫 단어까지 예측을 진행합니다.
bilm을 요약하자면 첫째, 최초 임베딩 레이어는 char임베딩을 사용하구요.lstm레이어 사이에는 residual connection이 존재합니다.
순방향LM은 다음 단어를 예측하도록, 역방향 LM은 이전 단어를 예측합니다.
자 그럼, read의 임베딩이 어떻게 생성되는지 보도록 하면 여기,read에 대한 biLM의 각 레이어별 출력 값이 있습니다.2개의 LM의 출력값을 한번에 사용하기 위해 각 레이어의 출력 값을 붙여줍니다.그리고 각 벡터에 정규화된 가중치를 곱해줍니다.이 가중치는 학습하는 동안 최적화 됩니다.
각 레이어의 벡터를 더해줘서 하나의 임베딩을 만듭니다. 문맥정보를 많이 간직한 위쪽 벡터와 문법정보를 간직한 아래쪽 벡터를 합치므로 효율적인 임베딩이 되겠습니다.elmo의 임베딩은 최상위 레이어만 사용한 다른 모델들 보다 더 나은 성능을 보여주었습니다.최종적으로 또다른 가중치인 감마 값을 곱해줍니다.감마는 특히 ELMo의 최종 레이어 출력값만을 임베딩으로 사용할 때, 더 필요하다고 합니다.
출처) https://www.youtube.com/watch?v=YZerhaFMPTw
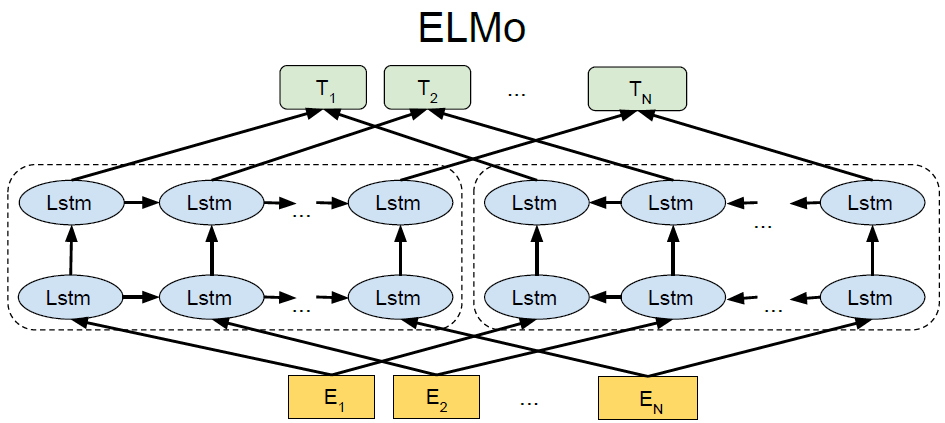
정리)이전의 자연어 처리 모델인 word2vec and Glove은 선행학습된 단어 임베딩을 많이 사용했습니다. 그리고 문맥에 따라 임베딩을 제공하지는 못하는 경우가 많았습니다.이에 대해서 문맥에 따라 임베딩을 제공하는 함수인 elmo를 제안하였습니다.이것이 가능한 것은 ELMo의 biLM구조와 이 구조의 모든 레이어 정보(각 layer의 출력,모든 LSTM 레이어의 출력)를 활용한다는 데에 있습니다.biLM은 순방향 LM과 역방향 LM을 합친 것으로 요약하자면 최초 임베딩 레이어는 최초임베딩은 문맥의 영향을 받지 말아야하므로 char임베딩을 사용하구요.lstm레이어 사이에는 residual connection이 존재합니다.
순방향LM은 다음 단어를 예측하도록, 역방향 LM은 이전 단어를 예측합니다.그리고 논문에서는 상위 레이어 일수록 문맥에 의한 벡터를 출력하고,하위 레이어일수록 문법에 가까운 벡터를 출력한다고 합니다.
