[논문리뷰] Human Pose Estimation via Deep Neural Networks : DeepPose
정리)
Pose estimtation은 사람의 관절 위치를 찾는 task로 기존의 local detector은 local한 part를 추론하는데, 하지만 보이지 않는 부분은 찾을 수 없다는 단점이 존재했습니다. 이를 극복하고자 고안한 방법이 convolution DNN model로써 각 관절의 전체적인 맥락을 고려하여 예측할 수 있다는 장점과 (기존의 방식은 Representation(특징검출)과 검출기 (detector)로 만든 다음, 이를 조합하는 방식이었으나 )CNN을 활용하면 단일 신경망으로 모든 관절 위치를 예측할 수 있으므로 훨씬 모델이 단순해진다는 장점이 있었습니다.
진행과정을 식과 함께 차례로 보면 다음과 같습니다.
Input Image가 CNN을 통과하면 각 관절 별로 x, y 좌표 2개씩 k개의 관절에 대해서 예측 값을 도출됩니다.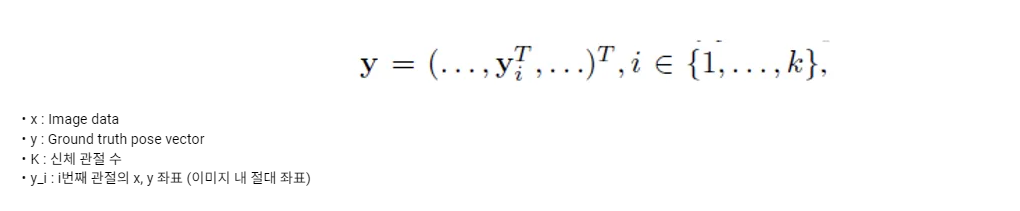
벡터 y_i는 i번째 관절의 x, y 좌표를 담은 2차원 벡터이고, 벡터 y는 이러한 y_i인 2차원 벡터 k개를 쭉 펼쳐서 이어 붙인 2k 차원의 벡터입니다.
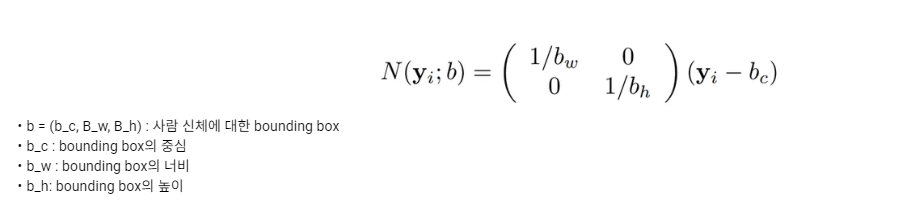
벡터 y_i는 i번째 관절의 x, y 좌표와 중심점 간의 차를 구하고, 각각을 너비와 높이로 나눠 주어 normalize하여 사용합니다.
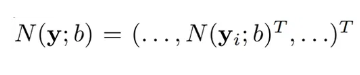
해당 normalize 과정을 Pose Vector 모두에 적용해주면 다음과 같은 normalized pose vector를 얻을 수 있습니다.
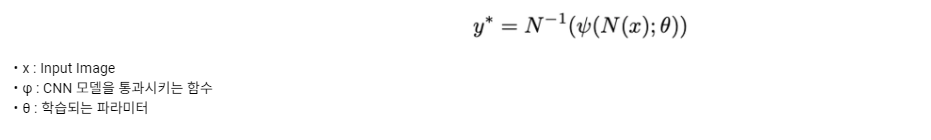
그리고, 예측 값을 원래 이미지에 찍어주기 위해서는 normalize에 대한 역 연산을 진행해야하며 수식은 다음과 같습니다.
즉, Input image와 파라미터를 통해 CNN이 normalize된 예측 값을 도출하고 이를 다시 역으로 적용하면 관절 예측 벡터인 y*를 구할 수 있게 됩니다.
그런데 다만 이런 initial stage의 경우 큰이미지를 보고 예측한 결과 값이기 때문에 정교함이 떨어질 수 있다는 단점이 있습니다. 따라서
이를 보완하기 위한 아이디어로 Cascade방식을 제안하였는데, 이는 예측 좌표를 기반으로 bounding box를 다시 그리고 crop하여 다시 CNN 모델을 통과하는 방식입니다.
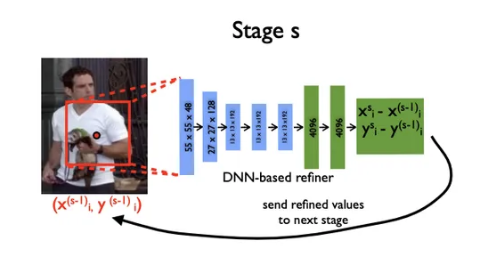
이렇게 구한 좌표 예측값을 토대로 training을 시키는데 initial 모형을 학습하여 Input Image 속 관절의 대략적인 위치를 파악한 후,관절 별로 Stage t 모형에 새로운 Bounding Box를 입력해 예측 값을 산출하고 이를 S번 반복하는 과정을 거치는 과정으로 진행됩니다.
