[논문리뷰] Denoising Diffusion Probabilistic Models
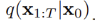
pre)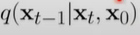
읽는법, q xt-1given xt,xo
정리) 이 논문은 diffusion model(리뷰)을 발전시킨 논문으로
Diffusion model은 parameterized Markov chain을 학습시켜 일정 시간 후에 원하는 데이터에 맞는 샘플을 만드는 모델입니다.
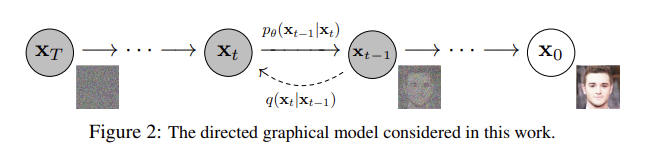
이때 Xo는 실제 데이터, XT는 최종 noise,그리고 그사이의 Xt는는 데이터에 noise가 더해진 상태의 latent variable을 의미하는데
우선, 위 그림의 오른쪽에서 왼쪽 방향으로 noise를 더해가는 forward process q를 진행합니다.그리고 그와 반대로 추정하는 reverse process p를 학습함으로써 최종 noise xT로부터 data xo를 복원하는 과정을 학습합니다. 그리고 이러한 random noise로부터 우리가 원하는 image등을 샐성할 수 있는 모델을 만들어 내는 것입니다.
forward process에서는 기본적인 diffusion model과 똑같이 data에 gaussian noise를 더하는 형태로 정의 됩니다. DDPM에서는 첨부된 식에는 있지 않으나 설명에서 알파t=1-베타t로 베타t에 대한 값으로 미리 정해진 상수로 정의하여서 forward process에서는 별도의 학습이 필요로 하지 않는다는 것을 알 수 있습니다.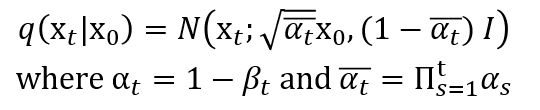
그리고 reverse process는 다음 식에서 뮤와 분산 값을 학습해야합니다. 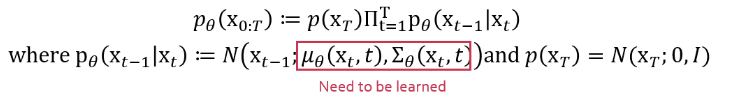
그리고 아래 diffusionmodel의 trainning loss를 최소함으로써 revere process를 학습하여 noise로 부터 data를 만들어내는데,
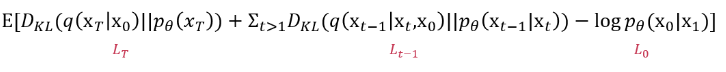
각각의 term을 나누어서 보면 LT에서 우리는 q와 p(xT)를 모두 학습이 필요하지 않은 파라미터를 가지는 정규분포로 가정했기 때문에 학습하는 동안 이 loss에 대해서는 무시해도 됩니다.
Lt-1에서는 중간단계의 noise를 지워나가는 단계로서 이를 계산하기 위해서 q term과 p term을 알아내기 위해서 분산t와 뮤t을 알아내야 합니다.이를 순서대로 살펴보면
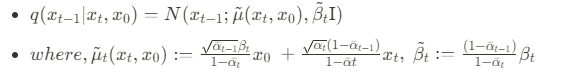
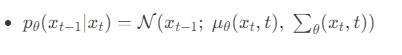
와 같은 형태로 나타낼 수 있고 구해야 되는 분산t값은 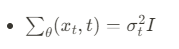
즉,p의 표준편차는 시그마t제곱I라는 상수행렬로 정의됩니다. 따라서 이에 대해서는 학습이 필요로 하지 않고, 마지막으로 p의 평균 뮤는 다음과 같이 정의 됩니다.
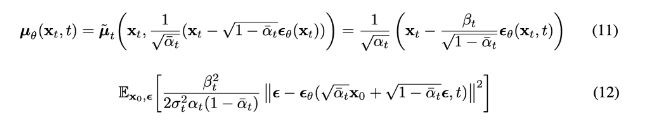
이렇게 뮤세타를 얻어내면 p세타로 부터 xt-1을 샘플링 할 수 있게 되고,Lt-1에 대해서 표현한식과 이 식을 입실론에 대한 식의 형태로 다시 표현한식까지 확인 할 수 있었습니다.그리고 이렇게 입실론으로 표현한 간단한 형태의 loss function을 통해 기존 diffusion에서 ddpm으로 변화되어 loss가 굉장히 간단한 식으로 정의되며 training하면 학습이 좀 더 잘 된다는 것을 확인할 수 있었습니다.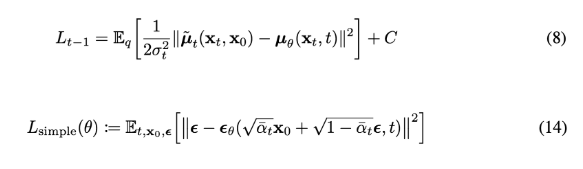
그리고 마지막으로 loss function의 마지막 구성요소인 Lo는 그냥 간단한 두 noraml 분포 사이의 KL divergence이기 때문에 다음과 같은 간단한 형태로 표현할 수 있습니다.
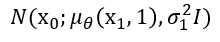
그리고 이와 같은 LTLT-1L0로 진행해 나가면서 원본데이터와 비슷한 데이터로 생성해나갑니다. 그리고 이러한 DDPM은 기존의 diffusion model의 loss term과 parameter estimation과정을 더 학습이 잘 되는 방향으로 발전시켜 기존 성능보다 좋게 고안해냈습니다.
(끝)
기존 diffusion model은 정의하기 쉽고 학습시키기 효율적이지만 고품질의 샘플을 만들지 못하였다. 반면, DDPM은 고품질의 샘플을 만들 수 있을 뿐만 아니라 다른 생성 모델 (ex. GAN)보다 더 우수한 결과를 보였다. 이것이 가능한 이유는 기존의 diffusion model의 loss term과 parameter estimation과정을 더 학습이 잘 되는 방향으로 발전시켰기 때문입니다. 또한, diffusion model의 특정 parameterization이 학습 중 여러 noise 레벨에서의 denoising score matching과 비슷하며, 샘플링 중 Langevin dynamics 문제를 푸는 것과 동등하다는 것을 보였다.
그 밖의 특징으로는
DDPM은 고품질의 샘플을 생성하지만 다른 likelihood 기반의 모델보다 경쟁력 있는 log likelihood가 없다.
DDPM의 lossless codelength가 대부분 인지할 수 없는 이미지 세부 정보를 설명하는 데 사용되었다.
Diffusion model의 샘플링이 autoregressive model의 디코딩과 유사한 점진적 디코딩이라는 것을 보였다.
출처)
https://developers-shack.tistory.com/8
https://jang-inspiration.com/ddpm-1
https://process-mining.tistory.com/188
https://process-mining.tistory.com/182
https://lcyking.tistory.com/entry/%EB%85%BC%EB%AC%B8%EB%A6%AC%EB%B7%B0-Denoising-Diffusion-Probabilistic-Models-DDPM
https://randomsampling.tistory.com/131
https://www.youtube.com/watch?v=uFoGaIVHfoE
