[논문리뷰] LwF: Learning without Forgetting
본 논문의 저자들이 언급하는 목적은 new task와 old task의 parameters를 공유하면서 forgetting 하지 않고 old task을 학습하기를 원합니다.
즉, LWF는 Distillation network와 Fine-Tuning을 결합한 것입니다.
이때 언급된 Distillation network에 대해서 설명하면 Distillation network는 딥러닝에서 사용되는 기술로, 주로 큰 모델(Teacher Model)의 지식을 작은 모델(Student Model)로 압축하는 과정에서 사용됩니다. 이 과정은 모델 압축(model compression)의 한 방법으로, 큰 모델이 학습한 정보를 보다 작은 모델에 전달하여 작은 모델이 유사한 성능을 발휘하도록 합니다.
주요 개념
Teacher Model: 사전 훈련된 큰 모델로, 일반적으로 복잡하고 많은 파라미터를 가지고 있습니다. 이 모델은 높은 성능을 발휘하지만, 계산 비용이 많이 들고 메모리도 많이 사용합니다.
Student Model: 작은 모델로, Teacher Model의 지식을 전달받아 비슷한 작업을 수행할 수 있도록 학습됩니다. 이 모델은 Teacher Model보다 훨씬 가볍고 효율적입니다.
Knowledge Distillation: 이 기술의 핵심은 Teacher Model이 예측한 확률 분포(logits)를 Student Model이 학습하도록 하는 것입니다. Teacher Model의 예측은 단순한 정답 레이블보다 더 많은 정보를 제공하며, Student Model은 이 정보를 이용해 더 나은 일반화 성능을 발휘할 수 있습니다.
Distillation network의 과정은 다음과 같습니다.
1. Teacher Model이 입력 데이터에 대해 예측 확률을 생성합니다.
2. 이 예측 확률을 Soft Target이라고 하며, 이를 Student Model이 학습합니다.
3. Student Model은 Soft Target과 원래의 정답 라벨을 모두 사용하여 학습합니다. 이 때 사용되는 손실 함수는 일반적으로 크로스 엔트로피 손실과 디스틸레이션 손실을 결합한 형태입니다.
이렇게 학습된 Student Model은 Teacher Model과 유사한 성능을 발휘하면서도 더 적은 자원을 사용해 효율적으로 동작할 수 있습니다. 이는 모바일 장치나 임베디드 시스템처럼 계산 자원이 제한된 환경에서 특히 유용합니다.
논문을 이해하기 위해서, 몇 가지 parameters를 정의할 필요가 있습니다.
-
Shared parameters: θs
: (ex. five convolutional layers and two fully connected layers for ‘AlexNet’ architecture) -
Task-specific parameters for previously learned tasks: θo
: (ex. the output layer for ImageNet classification and corresponding weights) -
Randomly initialized task specific parameters for new tasks: θn
: (ex. scene classifiers)
그리고 그림에 따라서 다른 종류와의 method상의 비교를 합니다. 그리고 특히 joint training과의 과정과는 그림상에서는 차이가 없는데 주요 다른점으로 joint training은 old dataset이 필요한 반면 learning without forgetting.즉 LwF에서는 old dataset이 필요가 없고 그에 대한 이유는 knowledge distillation의 개념이 사용되기 때문이라고 논문에서는 설명합니다. (자세히는 첫번째 출처 블로그를 참고할 것!)

LwF의 method는 distillation을 이용하며 비교적 간단한데, 먼저 새로운 data들에 대해서 old task의 output을 기존의 old task layer를 통과시켜서 나온 Yo값을 가지고 있고ㅡ new task layer의 parameter를 초기화 시킵니다. 그리고 기존의 old task에 대한 label은 distillation한 logit값 Yo를 사용하고 new task에 대한 label은 원핫벡터를 사용합니다....
experiments를 본 결과는 대부분 LwF의 성능이 fine-tunning과 feature extraction보다는 좋은 성능이었으나 joint training의 성능과는 비슷하고 places2->CUB,ImageNet->MNIST와 같이 dissimilar한 dataset의 경우는 old의 성능이 잘 나오지 못한다는 특징이 있었는데 이는 dissimilar한 dataset의 task를 수행하면서 shared parameter의 drift를 야기하고 그결과 LwF로 얻어진 old task에 대한 logit값이 과거의 정보에 대해서 충분히 설명할 수 없기 때문이다.
출처)
https://ffighting.net/deep-learning-paper-review/incremental-learning/lwf/
https://dlaguddnr.tistory.com/28
https://gbjeong96.tistory.com/40
정리)
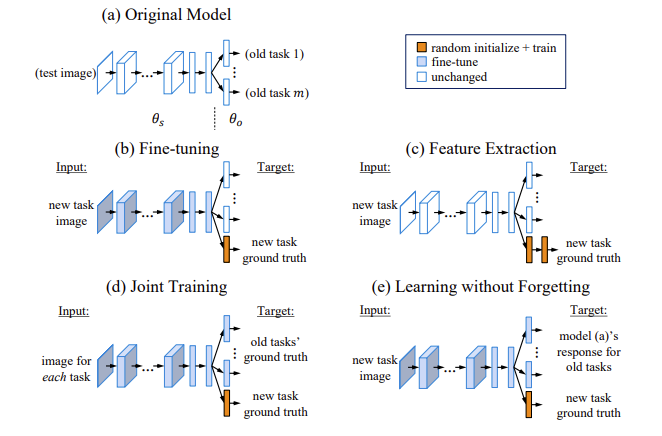
논문에서는 그림과 같이 다른 method와 비교해서 learning without forgetting 즉, LwF를 설명해줬는데 간단하게 몇개만 비교해서 보면 Shared parameters: θs, 이전에 배웠던 task에 대한 Task-specific parameters: θo ,새로운 task에 대해 랜덤하게 초기화된 task specific parameter : θn에 대해서 feature extraction은 θs와 θo이 unchanged 하기 때문에 θs는 new task의 일부 정보들을 대표하지 못하는 것을 알 수 있고, Joint Training은 모든 task들을 simultaneously 하게 training 하는 것을 목표로 합니다.
따라서, 모든 parameters θs, θo, θn들이 jointly optimized 되는 것을 알 수 있습니다. 이는 LwF에서도 동일하게 보여지는데 joint trainning과 다르게 LwF에서는 더이상 old task의 images와 labels를 사용하지 않으므로 old dataset의 필요성의 유무에 따라 달라지는 것을 알 수 있습니다.LwF는 new task의 images와 labels만 사용하여 old task와 new task에서 잘 작동하는 parameters를 학습합니다.이에 대해서 Distillation개념을 사용하는데 knowledge Distillation이란 Teacher network(이미 잘 학습된 큰 네트워크)가 Student network(task를 수행하고자 하는 작은 네트워크)에게 학습한 지식을 전달하는 것이다.작은 사이즈의 network로도 고성능을 낼 수 있도록 학습 과정에서 기존의 대형 모델의 지식을 작은 모델에 전달하는 것이 특징입니다. 
그리고 이를 바탕으로 LwF의 Outline을 보면
LWF는 new task images Xn과 responses Yo을 substitutes로 사용합니다.
Yo을 사용하면 old dataset을 요구하고 저장할 필요가 없습니다.
또한 공유된 θs의 공동 최적화 이점을 같이 제공합니다.
θs, θo, θn을 최적화 하기 위해서,해당 손실 함수를 사용합니다.
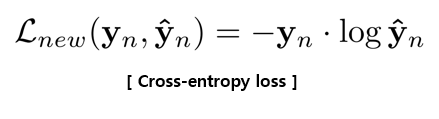
이 term은 predictions Y^n (softmax output)이 ground truth Yn ( one-hot ground truth label vector)과 일치하도록 장려합니다.

old task에 대한 knowledge를 유지하기 위해 Distillation을 적용합니다.
Q.fine tunning에 대한 설명은?
Fine-tuning에서는 θs와 θn이 new task에 있어서 최적화되지만, θo 은 unchanged 합니다.
따라서, Fine-tuning은 previously learned tasks의 performance를 하락시킵니다.
Q.T에 대해서 설명하면?
T(Temperature): Scaling 역할의 Hyperparameter
- T=1일 때, 기존 softmax function과 동일
- T 클수록, 더 soft 한 확률분포
논문에서 Hinton은 T > 1로 설정하는 것을 제안합니다.
이는 smaller logit values의 가중치를 증가시키고 네트워크가 클래스 간의 similarities( 유사성 )을 더 잘 인코딩하도록 장려합니다.
