[논문리뷰]AdaShare: Learning What To Share For Efficient Deep Multi-Task Learning
초록) 자원 효율성을 고려해 최고 인식 정확도를 달성하기 위해 어떤 작업에서 무엇을 공유할지 결정하는 AdaShare라는 adaptive sharing approach를 제안하였습니다.
주요 아이디어로 multi task network에서 주어진 task에 대해 어떤 layer를 실행할지 선택하는 task-specific policy를 통해 공유 패턴을 학습
standard back-propagation을 사용하여 네트워크 가중치와 공동으로 task-specific policy를 효율적으로 최적화하는 아이디어를 갖추고 있음.
introduction) 본 논문에서는 최적의 MTL 알고리즘이 모든 작업에서 높은 정확도를 달성해야할 뿐만 아니라 task 수가 증가함에 따라 새로운 네트워크 param 수를 최대한 제한해야 한다고 주장
AdaShare
○ MTL에서 주어진 task에 대해 실행할 계층을 선택적으로 선택하는 task-specific policy를 통해 feature sharing pattern을 학습
○ deep MTL에서 여러 task(어떤 task 간에 어떤 layer를 공유할지)에 걸쳐 feature sharing pattern을 적응적으로 결정하기 위한 새롭고 차별화 가능한 접근 방식
○ Gumbel Softmax Sampling을 통해 standard backpropagation을 사용하여 네트워크 가중치와 공동으로 feature sharing pattern을 학습해 효율성 높힘
○ task 간 효과적인 knoweldge 공유를 통해 compact한 MTL 네트워크 학습을 위한 두 가지 loss term과 optimization에 도움이 되는 커리큘럼 학습 전략 소개
-
Proposed Method
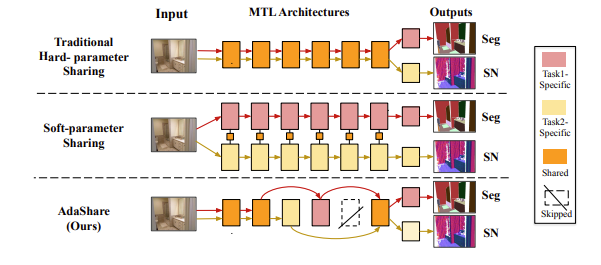
논문에서는 Residual Network(ResNet, ResNeXt, DenseNet)등의 shortcut connection의 성공에 주목하여, feature extraction할 때, 특정 task는 skip하여 negative transfer를 막을 수 있지않을까 라는 idea를 주목하였습니다. Shortcut connection여부를 residual block마다 결정하면 task-specific한 block과 knowledge share block을 나눌 수 있다고 생각하였습니다.
Multi-task learning을 위해서 task를 share할지 task-specific layer를 결정할지 자동으로 선택하고 싶고, 이를 통해서 Negative Transfer(바로 Negative Transfer 현상입니다. 사람이 보기에는 related data일지라도 neural network입장에서는 아닌 것입니다. 그래서 각 task가 서로의 성능향상에 악영향을 끼치는 경우도 상당수 존재합니다.)할 때는 해당 layer를 skip하고, Positive Transfer일 때는 layer를 share하여 성능을 높일 수 있지 않을까라고 제시하고 있습니다.
그런데 이때 해당 BLOCK 과 TASK에 대한 select-or-skip random variable를 binary값이라고 했을 때 policy를 U라고 할 때, n(U)가 2^NxK로 기하급수적으로 늘어납니다. 따라서 그렇기 떄문에 reinforce learning으로는 해결하지 어려울것이고 또한 기하급수적인 연산량과 더불어서 discrete하기 때문 미분 불가하여 gradient-based optimization하기 어렵다고 여겨졌습니다, 하지만 gumble softmax sampling을 통해서 differentiable하게 만들었습니다.
umbel Softmax Sampling은 VAE(Variational AutoEncoder)에서 generative model의 output
x
를 생성할 때의 sampling 또한 미분이 불가능하여 sampling대신에 sampling function을 구현하여 back propagation을 하게한 Reparameterization Trick중 한 방법입니다.
Reparameterization Trick은 Stochastic 한 Node를 Stochastic한 input과 Deterministic한 input으로 구별하여 이 조합을 function화 하여 deterministic한 node로 흐르게 하여 back propagation을 가능하게 하는 것을 말합니다.
Gumbel-Softmax Sampling은 Gumbel-Max Sampling에서 argmax를 통해 sampling하는 것을 softmax로 바꾸어 differentiable하게 만든 것을 의미하며, Gumbel-Max Sampling에서 Gumbel distribution을
πl,k term에 더해서 Sampling하게되면 gradient가 흐를 수 있게됩니다. -
Conclusion
○ MTL에 대한 feature sharing 전략을 적응적으로 결정하기 위한 접근 방식 제시
○ negative transfer 현상을 회피하고 positive transfer를 보강하여 MTL에 있어서 network의 parameter 수를 유지하면서 성능을 끌어올림
○ RL을 적용할 경우, search space가 커지는 현상을 Gumbel Softmax Sampling을 통해서 optimization problem으로 변환하였고, 이를 통해 computational resource를 절약할 수 있는 방법을 제시
○ standard back-propagation을 사용해 feature sharing policy와 network weight를 함께 학습하며 중요한 param을 추가하지 않고 학습
○ 여러 task에 걸쳐 최상의 성능을 달성하며 훨씬 적은 param을 가진 간결한 multi task network 학습하기 위한 두 가지 자원 관리 정규화 기법 소개
논문에서는 Residual Network(ResNet, ResNeXt, DenseNet)등의 shortcut connection의 성공에 주목하여, feature extraction할 때, 특정 task는 skip하여 negative transfer를 막을 수 있지않을까 라는 idea를 주목하였습니다. Model의 전체적인 pipeline은 다음과 같습니다.
1.맨처음부터 distribution parameter를 학습시키면 학습이 잘 되지 않으므로 curriculum learning을 도입하여 hard-parameter sharing을 통해서 network를 먼저 학습 시킵니다.
2.이후 매 l epoch에서 끝에서부터 l block까지의 distribution parameter를 학습시킵니다. (Curriculum Learning)
3.모든 policy distribution parameter가 train되면, select-or-skip decision을 하여 finetuning합니다.
출처) https://kdst.re.kr/42
https://velog.io/@sksmslhy/%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0-Adashare-Learning-What-To-Share-For-Efficient-Deep-Multi-Task-Learning
정리) 본 논문에서는 최적의 MTL 알고리즘이 모든 작업에서 높은 정확도를 달성해야할 뿐만 아니라 task 수가 증가함에 따라 새로운 네트워크 param 수를 최대한 제한해야 한다고 주장하였으며 이를 위해 앞서 설명드린 multi task learning처럼 새로운 multi task learning method를 제안하였는데 이때 극복해야되는 난데가 바로 Negative Transfer 현상으로 사람이 보기에는 related data일지라도 neural network입장에서는 아닌 것입니다. 그리고 이러한 negative Transfer현상 때문에 각 task가 서로의 성능향상에 악영향을 끼치는 경우가 생기는데 이를 해결하기 위해 knowledge sharing을 적재적소에 하는 것이 중요한데
이 논문에서는 task를 share할지 task-specific layer를 결정할지 자동으로 선택하고 싶고, 이를 통해서 Negative Transfer할 때는 해당 layer를 skip하고, Positive Transfer일 때는 layer를 share하여 성능을 높일 수 있지 않을까라고 제시하고 있습니다. 자세히 설명하자면 논문에서는 Residual Network(ResNet, ResNeXt, DenseNet)등의 shortcut connection의 성공에 주목하여, feature extraction할 때, 특정 task는 skip하여 negative transfer를 막을 수 있지않을까 라는 idea를 주목하였습니다. Shortcut connection여부를 residual block마다 결정하면 task-specific한 block과 knowledge share block을 나눌 수 있다고 생각하였습니다. 그런데 이러한 개념을 도입하면서 select-or-skip random variable의 policy,U에 대한 복잡도가 n(U)가 2^NxK 기하급수적으로 늘어났고 또한 discrete하기에 non-differentiable하여 gradient-based optimization하기 어렵다고 여겨졌습니다. 하지만 Gumbel Softmax Sampling을 통해서 differentiable하게 만들었습니다.
그럼 논문의 특징이 될 수 있는 점들을 말씀드렸고, model의 전체적인 pipline은 다음과 같습니다. 먼저 curriculum learning을 도입하여 hard-parameter sharing을 통해서 network를 먼저 학습 시킵니다. 그다음으로 매
l epoch에서 끝에서부터 l block까지의 distribution parameter를 학습시킵니다.최종적으로 모든 policy distribution parameter가 train되면, select-or-skip decision을 하여 finetuning합니다. 위와 같은 과정을 거치면서 학습해나갑니다.
Q. experiments로는 어떤 것들이 있었는가?
cross-stitch와 같은 방법과의 비교 또한 있었는데 동등하거나 더 우수한 결과를 얻으면서도 연산 효율성을 극대화 한 것을 확인 할 수 있었습니다.
